


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (5): 1428-1436.DOI: 10.11772/j.issn.1001-9081.2023050803
Special Issue: 人工智能; 2023年中国计算机学会人工智能会议(CCFAI 2023)
• 2023 CCF Conference on Artificial Intelligence (CCFAI 2023) • Previous Articles Next Articles
Mingzhu LEI1, Hao WANG1, Rong JIA1, Lin BAI1, Xiaoying PAN1,2( )
)
Received:2023-06-25
Revised:2023-07-30
Accepted:2023-08-02
Online:2023-08-03
Published:2024-05-10
Contact:
Xiaoying PAN
About author:LEI Mingzhu, born in 1999, M. S. candidate. Her research interests include evolutionary computation, data mining.Supported by:
雷明珠1, 王浩1, 贾蓉1, 白琳1, 潘晓英1,2()
通讯作者:
潘晓英
作者简介:雷明珠(1999—),女,陕西咸阳人,硕士研究生,CCF会员,主要研究方向:进化计算、数据挖掘基金资助:CLC Number:
Mingzhu LEI, Hao WANG, Rong JIA, Lin BAI, Xiaoying PAN. Oversampling algorithm based on synthesizing minority class samples using relationship between features[J]. Journal of Computer Applications, 2024, 44(5): 1428-1436.
雷明珠, 王浩, 贾蓉, 白琳, 潘晓英. 基于特征间关系合成少数类样本的过采样算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1428-1436.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023050803
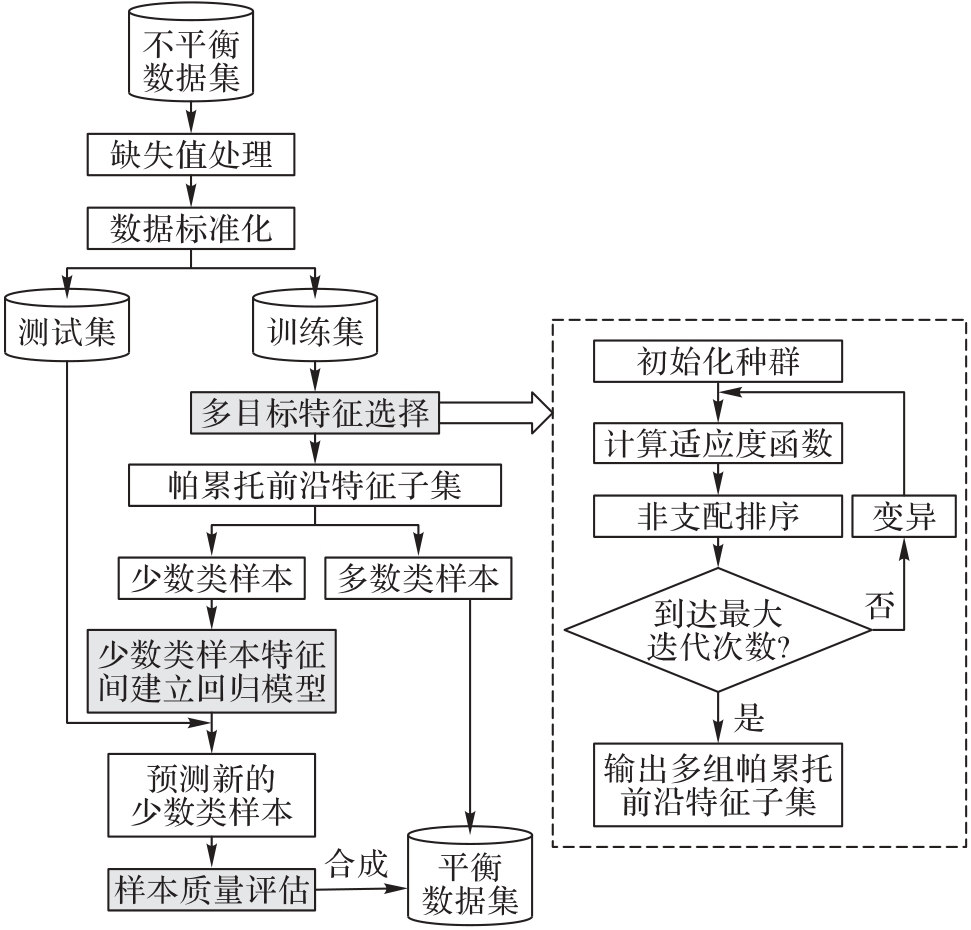
Fig. 1 Framework of SABRF
| 标签 | 特征 | 模型 | 预测的新特征值 |
|---|---|---|---|
| F1 | F2~F5 | Model1 | Model1预测新的F1' |
| F2 | F1,F3~F5 | Model2 | Model2预测新的F2' |
| F3 | F1,F2,F4~F5 | Model3 | Model3预测新的F3' |
| F4 | F1,F2,F3,F5 | Model4 | Model4预测新的F4' |
| F5 | F1~F4 | Model5 | Model5预测新的F5' |
Tab. 1 Construction process of oversampling model
| 标签 | 特征 | 模型 | 预测的新特征值 |
|---|---|---|---|
| F1 | F2~F5 | Model1 | Model1预测新的F1' |
| F2 | F1,F3~F5 | Model2 | Model2预测新的F2' |
| F3 | F1,F2,F4~F5 | Model3 | Model3预测新的F3' |
| F4 | F1,F2,F3,F5 | Model4 | Model4预测新的F4' |
| F5 | F1~F4 | Model5 | Model5预测新的F5' |
| 类别 | 数据集 | 样本数 | 特征数 | 少数 类数 | 多数 类数 | 不平衡 比率 |
|---|---|---|---|---|---|---|
UCI 数据集 | heart | 269 | 13 | 119 | 150 | 1.26 |
| ionosphere | 351 | 34 | 126 | 225 | 1.79 | |
| pima | 768 | 8 | 268 | 500 | 1.87 | |
| glass | 214 | 9 | 51 | 163 | 3.18 | |
| vehicle | 846 | 18 | 199 | 647 | 3.25 | |
| segment | 2 310 | 19 | 330 | 1 980 | 6.00 | |
真实 数据集 | thrombus | 15 856 | 343 | 528 | 15 328 | 29.10 |
Tab. 2 Description of seven experimental imbalanced datasets
| 类别 | 数据集 | 样本数 | 特征数 | 少数 类数 | 多数 类数 | 不平衡 比率 |
|---|---|---|---|---|---|---|
UCI 数据集 | heart | 269 | 13 | 119 | 150 | 1.26 |
| ionosphere | 351 | 34 | 126 | 225 | 1.79 | |
| pima | 768 | 8 | 268 | 500 | 1.87 | |
| glass | 214 | 9 | 51 | 163 | 3.18 | |
| vehicle | 846 | 18 | 199 | 647 | 3.25 | |
| segment | 2 310 | 19 | 330 | 1 980 | 6.00 | |
真实 数据集 | thrombus | 15 856 | 343 | 528 | 15 328 | 29.10 |

Fig. 2 Relationship between sample evaluation metrics and classification results
| 数据集 | λ | DIS | |||
|---|---|---|---|---|---|
| heart | 0.15 | 0.953 2 | 0.789 3 | 0.833 3 | 0.858 6 |
| ionosphere | 0.30 | 0.944 7 | 0.459 2 | 0.987 3 | 0.797 1 |
| pima | 0.10 | 0.981 7 | 0.177 1 | 1.000 0 | 0.719 6 |
| glass | 0.15 | 0.962 9 | 0.180 4 | 1.000 0 | 0.714 4 |
| vehicle | 0.47 | 0.755 9 | 0.341 9 | 0.908 1 | 0.668 6 |
| segment | 0.37 | 0.781 9 | 0.405 1 | 0.925 0 | 0.704 0 |
| thrombus | 0.20 | 0.731 2 | 0.752 4 | 0.933 2 | 0.651 5 |
Tab. 3 Evaluation results of SABRF resampling to generate new samples
| 数据集 | λ | DIS | |||
|---|---|---|---|---|---|
| heart | 0.15 | 0.953 2 | 0.789 3 | 0.833 3 | 0.858 6 |
| ionosphere | 0.30 | 0.944 7 | 0.459 2 | 0.987 3 | 0.797 1 |
| pima | 0.10 | 0.981 7 | 0.177 1 | 1.000 0 | 0.719 6 |
| glass | 0.15 | 0.962 9 | 0.180 4 | 1.000 0 | 0.714 4 |
| vehicle | 0.47 | 0.755 9 | 0.341 9 | 0.908 1 | 0.668 6 |
| segment | 0.37 | 0.781 9 | 0.405 1 | 0.925 0 | 0.704 0 |
| thrombus | 0.20 | 0.731 2 | 0.752 4 | 0.933 2 | 0.651 5 |

Fig. 3 Distribution diagrams of datasets glass and segment under different sampling methods
| 数据集 | 指标 | 方差 | 最大值 | 最小值 | 平均值 |
|---|---|---|---|---|---|
| heart | AUC | 7.633 4E-04 | 0.893 9 | 0.857 7 | 0.875 8 |
| F1_score | 6.223 6E-04 | 0.869 9 | 0.796 0 | 0.833 0 | |
| G_mean | 6.270 0E-04 | 0.865 2 | 0.792 7 | 0.828 9 | |
| ionosphere | AUC | 6.663 4E-04 | 0.957 3 | 0.945 6 | 0.949 7 |
| F1_score | 8.613 0E-04 | 0.924 0 | 0.841 7 | 0.883 5 | |
| G_mean | 6.826 7E-04 | 0.918 2 | 0.843 4 | 0.881 1 | |
| pima | AUC | 1.202 0E-04 | 0.800 9 | 0.783 7 | 0.793 8 |
| F1_score | 1.558 4E-03 | 0.755 1 | 0.679 2 | 0.723 8 | |
| G_mean | 1.348 3E-04 | 0.735 7 | 0.721 6 | 0.732 1 | |
| glass | AUC | 1.835 8E-03 | 0.970 5 | 0.955 0 | 0.962 8 |
| F1_score | 1.705 8E-03 | 0.944 7 | 0.850 1 | 0.897 4 | |
| G_mean | 5.509 7E-03 | 0.918 7 | 0.868 5 | 0.893 6 | |
| vehicle | AUC | 1.393 2E-05 | 0.994 8 | 0.978 3 | 0.994 0 |
| F1_score | 2.345 9E-04 | 0.953 5 | 0.912 8 | 0.933 1 | |
| G_mean | 1.414 0E-04 | 0.978 3 | 0.944 8 | 0.961 6 | |
| segment | AUC | 1.100 2E-05 | 0.999 9 | 0.999 2 | 0.999 8 |
| F1_score | 1.156 2E-05 | 0.999 9 | 0.995 7 | 0.998 7 | |
| G_mean | 0.182 7E-06 | 0.999 9 | 0.994 9 | 0.997 5 | |
| thrombus | AUC | 3.418 8E-05 | 0.981 6 | 0.977 0 | 0.980 1 |
| F1_score | 8.167 5E-06 | 0.989 2 | 0.980 7 | 0.981 4 | |
| G_mean | 1.816 3E-03 | 0.864 7 | 0.810 4 | 0.843 9 |
Tab. 4 Classification results of SABRF algorithm
| 数据集 | 指标 | 方差 | 最大值 | 最小值 | 平均值 |
|---|---|---|---|---|---|
| heart | AUC | 7.633 4E-04 | 0.893 9 | 0.857 7 | 0.875 8 |
| F1_score | 6.223 6E-04 | 0.869 9 | 0.796 0 | 0.833 0 | |
| G_mean | 6.270 0E-04 | 0.865 2 | 0.792 7 | 0.828 9 | |
| ionosphere | AUC | 6.663 4E-04 | 0.957 3 | 0.945 6 | 0.949 7 |
| F1_score | 8.613 0E-04 | 0.924 0 | 0.841 7 | 0.883 5 | |
| G_mean | 6.826 7E-04 | 0.918 2 | 0.843 4 | 0.881 1 | |
| pima | AUC | 1.202 0E-04 | 0.800 9 | 0.783 7 | 0.793 8 |
| F1_score | 1.558 4E-03 | 0.755 1 | 0.679 2 | 0.723 8 | |
| G_mean | 1.348 3E-04 | 0.735 7 | 0.721 6 | 0.732 1 | |
| glass | AUC | 1.835 8E-03 | 0.970 5 | 0.955 0 | 0.962 8 |
| F1_score | 1.705 8E-03 | 0.944 7 | 0.850 1 | 0.897 4 | |
| G_mean | 5.509 7E-03 | 0.918 7 | 0.868 5 | 0.893 6 | |
| vehicle | AUC | 1.393 2E-05 | 0.994 8 | 0.978 3 | 0.994 0 |
| F1_score | 2.345 9E-04 | 0.953 5 | 0.912 8 | 0.933 1 | |
| G_mean | 1.414 0E-04 | 0.978 3 | 0.944 8 | 0.961 6 | |
| segment | AUC | 1.100 2E-05 | 0.999 9 | 0.999 2 | 0.999 8 |
| F1_score | 1.156 2E-05 | 0.999 9 | 0.995 7 | 0.998 7 | |
| G_mean | 0.182 7E-06 | 0.999 9 | 0.994 9 | 0.997 5 | |
| thrombus | AUC | 3.418 8E-05 | 0.981 6 | 0.977 0 | 0.980 1 |
| F1_score | 8.167 5E-06 | 0.989 2 | 0.980 7 | 0.981 4 | |
| G_mean | 1.816 3E-03 | 0.864 7 | 0.810 4 | 0.843 9 |
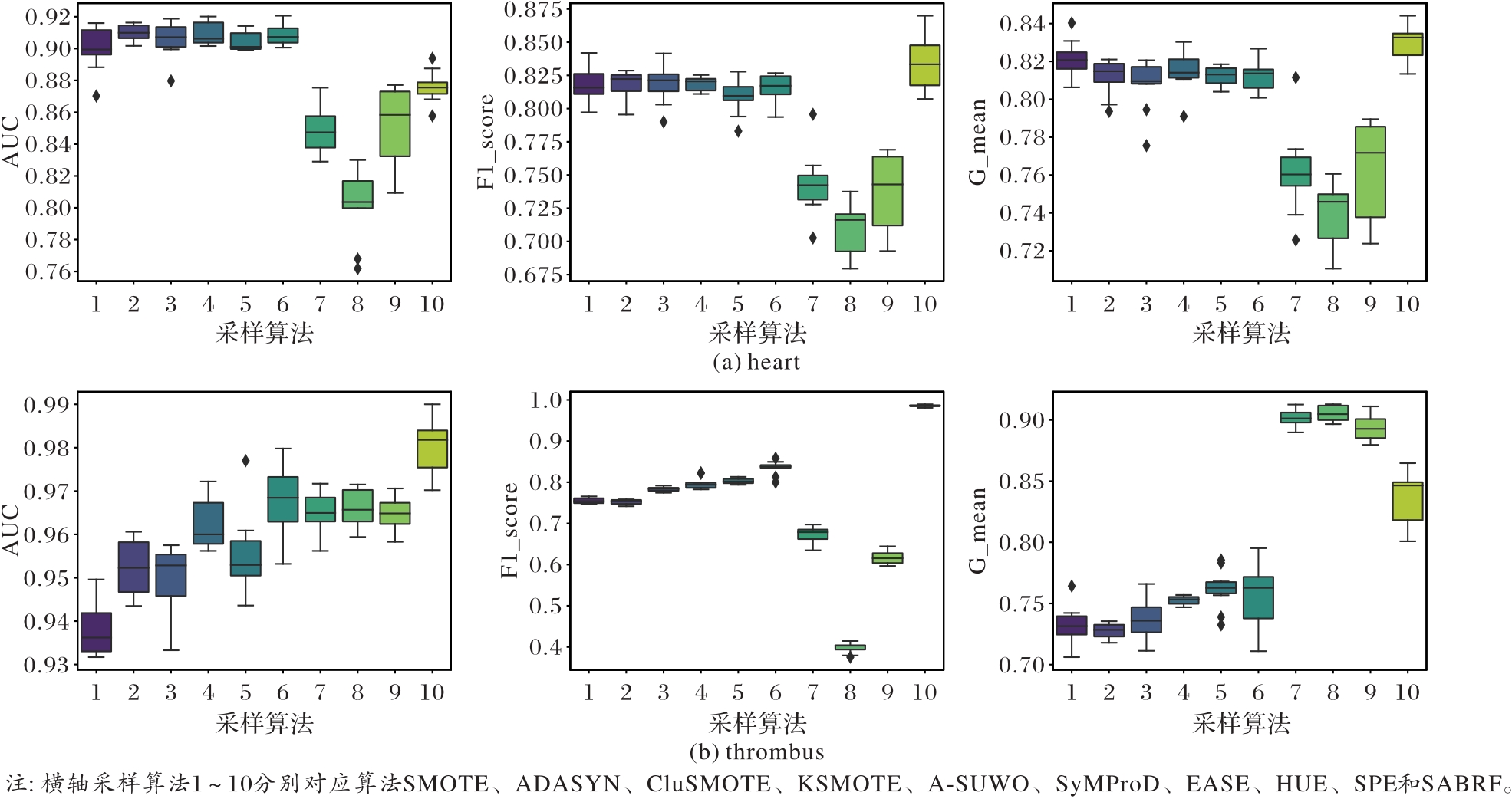
Fig. 4 Box plots of AUC, F1_score, and G_mean for heart and thrombus with 30 independent runs under different sampling algorithms
| 数据集 | 指标 | SMOTE | ADASYN | CluSMOTE | KSMOTE | A-SUWO | SyMProD | EASE | HUE | SPE | SABRF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| heart | AUC | 0.909 5 | 0.910 7 | 0.909 1 | 0.909 7 | 0.906 3 | 0.909 8 | 0.848 7 | 0.801 6 | 0.850 8 | 0.875 8 |
| F1_score | 0.819 9 | 0.818 9 | 0.817 1 | 0.817 6 | 0.812 8 | 0.816 7 | 0.743 2 | 0.710 2 | 0.737 8 | 0.833 0 | |
| G_mean | 0.821 1 | 0.814 6 | 0.815 1 | 0.817 4 | 0.812 1 | 0.811 8 | 0.761 6 | 0.738 9 | 0.763 1 | 0.828 9 | |
| ionosphere | AUC | 0.976 3 | 0.976 8 | 0.860 2 | 0.863 9 | 0.836 3 | 0.863 0 | 0.957 7 | 0.950 1 | 0.919 3 | 0.949 7 |
| F1_score | 0.898 6 | 0.893 7 | 0.786 0 | 0.794 5 | 0.785 3 | 0.796 3 | 0.897 2 | 0.869 5 | 0.818 3 | 0.883 5 | |
| G_mean | 0.927 8 | 0.924 5 | 0.831 2 | 0.836 4 | 0.820 7 | 0.837 5 | 0.921 1 | 0.900 5 | 0.853 3 | 0.881 1 | |
| pima | AUC | 0.828 9 | 0.826 1 | 0.827 5 | 0.827 2 | 0.829 2 | 0.829 0 | 0.789 4 | 0.774 3 | 0.786 2 | 0.793 8 |
| F1_score | 0.684 6 | 0.677 8 | 0.683 9 | 0.685 9 | 0.682 9 | 0.687 2 | 0.666 5 | 0.614 3 | 0.623 3 | 0.723 8 | |
| G_mean | 0.748 3 | 0.739 8 | 0.747 3 | 0.750 3 | 0.745 9 | 0.751 4 | 0.739 4 | 0.696 2 | 0.704 1 | 0.732 1 | |
| glass | AUC | 0.922 5 | 0.923 3 | 0.923 8 | 0.932 6 | 0.919 0 | 0.937 2 | 0.960 3 | 0.962 3 | 0.958 3 | 0.962 8 |
| F1_score | 0.761 1 | 0.740 7 | 0.774 2 | 0.791 2 | 0.744 2 | 0.805 8 | 0.862 3 | 0.854 7 | 0.875 3 | 0.897 4 | |
| G_mean | 0.826 4 | 0.805 5 | 0.839 3 | 0.854 5 | 0.812 5 | 0.866 4 | 0.912 3 | 0.925 6 | 0.910 5 | 0.893 6 | |
| vehicle | AUC | 0.993 7 | 0.991 3 | 0.993 6 | 0.993 8 | 0.992 1 | 0.993 5 | 0.991 3 | 0.991 2 | 0.992 4 | 0.994 0 |
| F1_score | 0.932 5 | 0.873 2 | 0.932 5 | 0.934 2 | 0.922 2 | 0.926 0 | 0.910 4 | 0.913 3 | 0.904 2 | 0.933 1 | |
| G_mean | 0.967 0 | 0.952 6 | 0.966 4 | 0.968 0 | 0.960 9 | 0.966 9 | 0.942 9 | 0.951 5 | 0.940 2 | 0.961 6 | |
| segment | AUC | 0.993 4 | 0.990 9 | 0.992 7 | 0.988 2 | 0.989 9 | 0.990 6 | 0.999 3 | 0.998 2 | 0.999 7 | 0.999 8 |
| F1_score | 0.817 4 | 0.820 8 | 0.818 7 | 0.820 5 | 0.807 7 | 0.821 2 | 0.996 1 | 0.993 4 | 0.994 6 | 0.998 7 | |
| G_mean | 0.957 5 | 0.957 8 | 0.957 6 | 0.955 4 | 0.954 0 | 0.956 2 | 0.997 2 | 0.995 9 | 0.996 1 | 0.997 5 | |
| thrombus | AUC | 0.941 2 | 0.953 3 | 0.954 2 | 0.963 1 | 0.958 7 | 0.968 8 | 0.958 3 | 0.965 1 | 0.964 8 | 0.980 1 |
| F1_score | 0.756 8 | 0.748 9 | 0.783 7 | 0.796 8 | 0.803 2 | 0.834 6 | 0.671 1 | 0.398 8 | 0.617 6 | 0.981 4 | |
| G_mean | 0.732 4 | 0.726 5 | 0.743 9 | 0.753 6 | 0.758 9 | 0.765 6 | 0.901 7 | 0.905 4 | 0.893 3 | 0.843 9 |
Tab. 5 Result comparison between SABRF and other sampling algorithms
| 数据集 | 指标 | SMOTE | ADASYN | CluSMOTE | KSMOTE | A-SUWO | SyMProD | EASE | HUE | SPE | SABRF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| heart | AUC | 0.909 5 | 0.910 7 | 0.909 1 | 0.909 7 | 0.906 3 | 0.909 8 | 0.848 7 | 0.801 6 | 0.850 8 | 0.875 8 |
| F1_score | 0.819 9 | 0.818 9 | 0.817 1 | 0.817 6 | 0.812 8 | 0.816 7 | 0.743 2 | 0.710 2 | 0.737 8 | 0.833 0 | |
| G_mean | 0.821 1 | 0.814 6 | 0.815 1 | 0.817 4 | 0.812 1 | 0.811 8 | 0.761 6 | 0.738 9 | 0.763 1 | 0.828 9 | |
| ionosphere | AUC | 0.976 3 | 0.976 8 | 0.860 2 | 0.863 9 | 0.836 3 | 0.863 0 | 0.957 7 | 0.950 1 | 0.919 3 | 0.949 7 |
| F1_score | 0.898 6 | 0.893 7 | 0.786 0 | 0.794 5 | 0.785 3 | 0.796 3 | 0.897 2 | 0.869 5 | 0.818 3 | 0.883 5 | |
| G_mean | 0.927 8 | 0.924 5 | 0.831 2 | 0.836 4 | 0.820 7 | 0.837 5 | 0.921 1 | 0.900 5 | 0.853 3 | 0.881 1 | |
| pima | AUC | 0.828 9 | 0.826 1 | 0.827 5 | 0.827 2 | 0.829 2 | 0.829 0 | 0.789 4 | 0.774 3 | 0.786 2 | 0.793 8 |
| F1_score | 0.684 6 | 0.677 8 | 0.683 9 | 0.685 9 | 0.682 9 | 0.687 2 | 0.666 5 | 0.614 3 | 0.623 3 | 0.723 8 | |
| G_mean | 0.748 3 | 0.739 8 | 0.747 3 | 0.750 3 | 0.745 9 | 0.751 4 | 0.739 4 | 0.696 2 | 0.704 1 | 0.732 1 | |
| glass | AUC | 0.922 5 | 0.923 3 | 0.923 8 | 0.932 6 | 0.919 0 | 0.937 2 | 0.960 3 | 0.962 3 | 0.958 3 | 0.962 8 |
| F1_score | 0.761 1 | 0.740 7 | 0.774 2 | 0.791 2 | 0.744 2 | 0.805 8 | 0.862 3 | 0.854 7 | 0.875 3 | 0.897 4 | |
| G_mean | 0.826 4 | 0.805 5 | 0.839 3 | 0.854 5 | 0.812 5 | 0.866 4 | 0.912 3 | 0.925 6 | 0.910 5 | 0.893 6 | |
| vehicle | AUC | 0.993 7 | 0.991 3 | 0.993 6 | 0.993 8 | 0.992 1 | 0.993 5 | 0.991 3 | 0.991 2 | 0.992 4 | 0.994 0 |
| F1_score | 0.932 5 | 0.873 2 | 0.932 5 | 0.934 2 | 0.922 2 | 0.926 0 | 0.910 4 | 0.913 3 | 0.904 2 | 0.933 1 | |
| G_mean | 0.967 0 | 0.952 6 | 0.966 4 | 0.968 0 | 0.960 9 | 0.966 9 | 0.942 9 | 0.951 5 | 0.940 2 | 0.961 6 | |
| segment | AUC | 0.993 4 | 0.990 9 | 0.992 7 | 0.988 2 | 0.989 9 | 0.990 6 | 0.999 3 | 0.998 2 | 0.999 7 | 0.999 8 |
| F1_score | 0.817 4 | 0.820 8 | 0.818 7 | 0.820 5 | 0.807 7 | 0.821 2 | 0.996 1 | 0.993 4 | 0.994 6 | 0.998 7 | |
| G_mean | 0.957 5 | 0.957 8 | 0.957 6 | 0.955 4 | 0.954 0 | 0.956 2 | 0.997 2 | 0.995 9 | 0.996 1 | 0.997 5 | |
| thrombus | AUC | 0.941 2 | 0.953 3 | 0.954 2 | 0.963 1 | 0.958 7 | 0.968 8 | 0.958 3 | 0.965 1 | 0.964 8 | 0.980 1 |
| F1_score | 0.756 8 | 0.748 9 | 0.783 7 | 0.796 8 | 0.803 2 | 0.834 6 | 0.671 1 | 0.398 8 | 0.617 6 | 0.981 4 | |
| G_mean | 0.732 4 | 0.726 5 | 0.743 9 | 0.753 6 | 0.758 9 | 0.765 6 | 0.901 7 | 0.905 4 | 0.893 3 | 0.843 9 |
| 1 | HUYNH T, NIBALI A, HE Z. Semi-supervised learning for medical image classification using imbalanced training data[J]. Computer Methods and Programs in Biomedicine, 2022, 216: 106628. 10.1016/j.cmpb.2022.106628 |
| 2 | JIANG X, GE Z. Data augmentation classifier for imbalanced fault classification[J]. IEEE Transactions on Automation Science and Engineering, 2021, 18(3): 1206-1217. 10.1109/tase.2020.2998467 |
| 3 | LIU Y, ZENG Q, LI B, et al. Anticipating financial distress of high‑tech startups in the European Union: a machine learning approach for imbalanced samples[J]. Journal of Forecasting, 2022, 41(6): 1131-1155. 10.1002/for.2852 |
| 4 | DING H, CHEN L, DONG L, et al. Imbalanced data classification: a KNN and generative adversarial networks-based hybrid approach for intrusion detection[J]. Future Generation Computer Systems, 2022, 131: 240-254. 10.1016/j.future.2022.01.026 |
| 5 | LIU M, MIAO L, ZHANG D. Two-stage cost-sensitive learning for software defect prediction[J]. IEEE Transactions on Reliability, 2014, 63(2): 676-686. 10.1109/tr.2014.2316951 |
| 6 | LIU J, LI Y-F, ZIO E. A SVM framework for fault detection of the braking system in a high speed train[J]. Mechanical Systems and Signal Processing, 2017, 87: 401-409. 10.1016/j.ymssp.2016.10.034 |
| 7 | LIAN C, RUAN S, DENŒUX T, et al. Robust cancer treatment outcome prediction dealing with small-sized and imbalanced data from FDG-PET images[C]// Proceedings of the 2016 International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2016: 61-69. 10.1007/978-3-319-46723-8_8 |
| 8 | BAGUI S, LI K. Resampling imbalanced data for network intrusion detection datasets[J]. Journal of Big Data, 2021, 8(1): No.6. 10.1186/s40537-020-00390-x |
| 9 | AN Z, JIANG X, CAO J, et al. Self-learning transferable neural network for intelligent fault diagnosis of rotating machinery with unlabeled and imbalanced data[J]. Knowledge-Based Systems, 2021, 230: 107374. 10.1016/j.knosys.2021.107374 |
| 10 | KOVÁCS G. An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets[J]. Applied Soft Computing, 2019, 83: 105662. 10.1016/j.asoc.2019.105662 |
| 11 | HE H, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning[C]// Proceedings of the 2008 IEEE International Joint Conference on Neural Networks. Piscataway: IEEE, 2008: 1322-1328. 10.1109/ijcnn.2008.4633969 |
| 12 | YU H, NI J, ZHAO J. ACOSampling: an ant colony optimization-based undersampling method for classifying imbalanced DNA microarray data[J]. Neurocomputing, 2013, 101: 309-318. 10.1016/j.neucom.2012.08.018 |
| 13 | NG W W Y, HU J, YEUNG D S, et al. Diversified sensitivity-based undersampling for imbalance classification problems[J]. IEEE Transactions on Cybernetics, 2014, 45(11): 2402-2412. 10.1109/tcyb.2014.2372060 |
| 14 | YU H, SUN C, YANG X, et al. Fuzzy support vector machine with relative density information for classifying imbalanced data[J]. IEEE Transactions on Fuzzy Systems, 2019, 27(12): 2353-2367. 10.1109/tfuzz.2019.2898371 |
| 15 | BATUWITA R, PALADE V. FSVM-CIL: fuzzy support vector machines for class imbalance learning[J]. IEEE Transactions on Fuzzy Systems, 2010, 18(3): 558-571. 10.1109/tfuzz.2010.2042721 |
| 16 | WANG Z, WANG B, CHENG Y, et al. Cost-sensitive fuzzy multiple kernel learning for imbalanced problem[J]. Neurocomputing, 2019, 366: 178-193. 10.1016/j.neucom.2019.06.065 |
| 17 | YU H, SUN D, XI X, et al. Fuzzy one-class extreme auto-encoder[J]. Neural Processing Letters, 2019, 50: 701-727. 10.1007/s11063-018-9952-z |
| 18 | WANG C, HU Q, WANG X, et al. Feature selection based on neighborhood discrimination index[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(7): 2986-2999. 10.1109/tnnls.2018.2830700 |
| 19 | SHAHEE S A, ANANTHAKUMAR U. An effective distance based feature selection approach for imbalanced data[J]. Applied Intelligence, 2020, 50(3): 717-745. 10.1007/s10489-019-01543-z |
| 20 | LIU Y, WANG Y, REN X, et al. A classification method based on feature selection for imbalanced data[J]. IEEE Access, 2019, 7: 81794-81807. 10.1109/access.2019.2923846 |
| 21 | ZHANG Y, LIU G, LUAN W, et al. An approach to class imbalance problem based on stacking and inverse random under sampling methods[C]// Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control. Piscataway: IEEE, 2018: 1-6. 10.1109/icnsc.2018.8361344 |
| 22 | BRANKOVIC A, FALSONE A, PRANDINI M, et al. A feature selection and classification algorithm based on randomized extraction of model populations[J]. IEEE Transactions on Cybernetics, 2018, 48(4): 1151-1162. 10.1109/tcyb.2017.2682418 |
| 23 | CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-357. 10.1613/jair.953 |
| 24 | BARUA S, ISLAM M M, YAO X, et al. MWMOTE: majority weighted minority oversampling technique for imbalanced data set learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(2): 405-425. 10.1109/tkde.2012.232 |
| 25 | MATHEW J, LUO M, PANG C K, et al. Kernel-based SMOTE for SVM classification of imbalanced datasets[C]// Proceedings of the 41st Annual Conference of the IEEE Industrial Electronics Society. Piscataway: IEEE, 2015: 001127-001132. 10.1109/iecon.2015.7392251 |
| 26 | MATHEW J, PANG C K, LUO M, et al. Classification of imbalanced data by oversampling in kernel space of support vector machines[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4065-4076. 10.1109/tnnls.2017.2751612 |
| 27 | HAN H, WANG W-Y, MAO B-H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C]// Proceedings of the 2005 International Conference on Intelligent Computing. Berlin: Springer, 2005: 878-887. 10.1007/11538059_91 |
| 28 | BUNKHUMPORNPAT C, SINAPIROMSARAN K, LURSINSAP C. Safe-level-SMOTE: safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem[C]// Proceedings of the 2009 Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin: Springer, 2009: 475-482. 10.1007/978-3-642-01307-2_43 |
| 29 | XU X, CHEN W, SUN Y. Over-sampling algorithm for imbalanced data classification[J]. Journal of Systems Engineering and Electronics, 2019, 30(6): 1182-1191. 10.21629/jsee.2019.06.12 |
| 30 | DENG D. DBSCAN clustering algorithm based on density[C]// Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation. Piscataway: IEEE, 2020: 949-953. 10.1109/ifeea51475.2020.00199 |
| 31 | GUZMÁN-PONCE A, SÁNCHEZ J S, VALDOVINOS R M, et al. DBIG-US: a two-stage under-sampling algorithm to face the class imbalance problem[J]. Expert Systems with Applications, 2021, 168: 114301. 10.1016/j.eswa.2020.114301 |
| 32 | YU H, SUN C, YANG X, et al. LW-ELM: a fast and flexible cost-sensitive learning framework for classifying imbalanced data[J]. IEEE Access, 2018, 6: 28488-28500. 10.1109/access.2018.2839340 |
| 33 | ZHAO L, SHANG Z, QIN A, et al. A cost-sensitive meta-learning classifier: SPFCNN-Miner[J]. Future Generation Computer Systems, 2019, 100: 1031-1043. 10.1016/j.future.2019.05.080 |
| 34 | FENG F, LI K-C, SHEN J, et al. Using cost-sensitive learning and feature selection algorithms to improve the performance of imbalanced classification[J]. IEEE Access, 2020, 8: 69979-69996. 10.1109/access.2020.2987364 |
| 35 | GAN D, SHEN J, AN B, et al. Integrating TANBN with cost sensitive classification algorithm for imbalanced data in medical diagnosis[J]. Computers & Industrial Engineering, 2020, 140: 106266. 10.1016/j.cie.2019.106266 |
| 36 | RASKUTTI B, KOWALCZYK A. Extreme re-balancing for SVMs: a case study[J]. ACM SIGKDD Explorations Newsletter, 2004, 6(1): 60-69. 10.1145/1007730.1007739 |
| 37 | HE X, MOUROT G, MAQUIN D, et al. Multi-task learning with one-class SVM[J]. Neurocomputing, 2014, 133: 416-426. 10.1016/j.neucom.2013.12.022 |
| 38 | CHAWLA N V, LAZAREVIC A, HALL L O, et al. SMOTEBoost: improving prediction of the minority class in boosting[C]// Proceedings of the 2003 European Conference on Principles of Data Mining and Knowledge Discovery. Berlin: Springer, 2003: 107-119. 10.1007/978-3-540-39804-2_12 |
| 39 | SUN J, LANG J, FUJITA H, et al. Imbalanced enterprise credit evaluation with DTE-SBD: decision tree ensemble based on SMOTE and bagging with differentiated sampling rates[J]. Information Sciences, 2018, 425: 76-91. 10.1016/j.ins.2017.10.017 |
| 40 | HARTATI E P, ADIWIJAYA, BIJAKSANA M A. Handling imbalance data in churn prediction using combined SMOTE and RUS with bagging method[J]. Journal of Physics: Conference Series, 2018, 971(1): 012007. 10.1088/1742-6596/971/1/012007 |
| 41 | LU W, LI Z, CHU J. Adaptive ensemble undersampling-boost: a novel learning framework for imbalanced data[J]. Journal of Systems and Software, 2017, 132: 272-282. 10.1016/j.jss.2017.07.006 |
| 42 | 西安邮电大学.基于特征间关系合成少数类样本的不平衡数据处理方法:CN202111163070.5[P].2022-03-08. |
| Xi’an University of Posts and Telecommunications. Imbalanced data processing method for synthesizing minority class samples based on feature relationships: CN202111163070.5[P].2022-03-08. | |
| 43 | CIESLAK D A, CHAWLA N V, STRIEGEL A. Combating imbalance in network intrusion datasets[C]// Proceedings of the 2006 IEEE International Conference on Granular Computing. Piscataway: IEEE, 2006: 732-737. 10.1109/grc.2006.1635735 |
| 44 | DOUZAS G, BACAO F, LAST F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE[J]. Information Sciences, 2018, 465: 1-20. 10.1016/j.ins.2018.06.056 |
| 45 | NEKOOEIMEHR I, LAI-YUEN S K. Adaptive Semi-Unsupervised Weighted Oversampling (A-SUWO) for imbalanced datasets[J]. Expert Systems with Applications, 2016, 46:405-416. 10.1016/j.eswa.2015.10.031 |
| 46 | KUNAKORNTUM I, HINTHONG W, PHUNCHONGHARN P. A synthetic minority based on probabilistic distribution (SyMProD) oversampling for imbalanced datasets[J]. IEEE Access, 2020, 8: 114692-114704. 10.1109/access.2020.3003346 |
| 47 | REN J, WANG Y, MAO M, et al. Equalization ensemble for large scale highly imbalanced data classification[J]. Knowledge-Based Systems, 2022, 242: 108295. 10.1016/j.knosys.2022.108295 |
| 48 | NG W W Y, XU S, ZHANG J, et al. Hashing-based undersampling ensemble for imbalanced pattern classification problems[J]. IEEE Transactions on Cybernetics, 2022, 52(2): 1269-1279. 10.1109/tcyb.2020.3000754 |
| 49 | LIU Z, CAO W, GAO Z, et al. Self-paced ensemble for highly imbalanced massive data classification[C]// Proceedings of the 2020 IEEE 36th International Conference on Data Engineering. Piscataway: IEEE, 2020: 841-852. 10.1109/icde48307.2020.00078 |
| [1] | Qiangkui LENG, Xuezi SUN, Xiangfu MENG. Oversampling method for imbalanced data based on sample potential and noise evolution [J]. Journal of Computer Applications, 2024, 44(8): 2466-2475. |
| [2] | Hong CHEN, Bing QI, Haibo JIN, Cong WU, Li’ang ZHANG. Class-imbalanced traffic abnormal detection based on 1D-CNN and BiGRU [J]. Journal of Computer Applications, 2024, 44(8): 2493-2499. |
| [3] | Lin GAO, Yu ZHOU, Tak Wu KWONG. Evolutionary bi-level adaptive local feature selection [J]. Journal of Computer Applications, 2024, 44(5): 1408-1414. |
| [4] | Dapeng XU, Xinmin HOU. Feature selection method for graph neural network based on network architecture design [J]. Journal of Computer Applications, 2024, 44(3): 663-670. |
| [5] | Shengjie MENG, Wanjun YU, Ying CHEN. Feature selection algorithm for high-dimensional data with maximum correlation and maximum difference [J]. Journal of Computer Applications, 2024, 44(3): 767-771. |
| [6] | Lin SUN, Menghan LIU. K-means clustering based on adaptive cuckoo optimization feature selection [J]. Journal of Computer Applications, 2024, 44(3): 831-841. |
| [7] | Jingxin LIU, Wenjing HUANG, Liangsheng XU, Chong HUANG, Jiansheng WU. Unsupervised feature selection model with dictionary learning and sample correlation preservation [J]. Journal of Computer Applications, 2024, 44(12): 3766-3775. |
| [8] | Tian HE, Zongxin SHEN, Qianqian HUANG, Yanyong HUANG. Adaptive learning-based multi-view unsupervised feature selection method [J]. Journal of Computer Applications, 2023, 43(9): 2657-2664. |
| [9] | Xiang GUO, Wengang JIANG, Yuhang WANG. Encrypted traffic classification method based on improved Inception-ResNet [J]. Journal of Computer Applications, 2023, 43(8): 2471-2476. |
| [10] | Dongliang MU, Meng HAN, Ang LI, Shujuan LIU, Zhihui GAO. Overview of classification methods for complex data streams with concept drift [J]. Journal of Computer Applications, 2023, 43(6): 1664-1675. |
| [11] | Lin SUN, Jinxu HUANG, Jiucheng XU. Feature selection for imbalanced data based on neighborhood tolerance mutual information and whale optimization algorithm [J]. Journal of Computer Applications, 2023, 43(6): 1842-1854. |
| [12] | Zhenhua YU, Zhengqi LIU, Ying LIU, Cheng GUO. Feature selection method based on self-adaptive hybrid particle swarm optimization for software defect prediction [J]. Journal of Computer Applications, 2023, 43(4): 1206-1213. |
| [13] | Yi JIANG, Shuping WU, Kun HU, Linbo LONG. Imbalanced data classification method based on Lasso and constructive covering algorithm [J]. Journal of Computer Applications, 2023, 43(4): 1086-1093. |
| [14] | Lin SUN, Tianjiao MA, Zhan’ao XUE. Multilabel feature selection algorithm based on Fisher score and fuzzy neighborhood entropy [J]. Journal of Computer Applications, 2023, 43(12): 3779-3789. |
| [15] | Jingcheng XU, Xuebin CHEN, Yanling DONG, Jia YANG. DDoS attack detection by random forest fused with feature selection [J]. Journal of Computer Applications, 2023, 43(11): 3497-3503. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||