


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (11): 3564-3572.DOI: 10.11772/j.issn.1001-9081.2021122153
所属专题: 第二十一届中国虚拟现实大会
蔡兴泉, 封丁惟, 王通, 孙辰, 孙海燕( )
)
收稿日期:2021-12-21
修回日期:2022-01-21
接受日期:2022-01-26
发布日期:2022-03-02
出版日期:2022-11-10
通讯作者:
孙海燕
作者简介:蔡兴泉(1980—),男,山东济南人,教授,博士,CCF高级会员,主要研究方向:虚拟现实、人机互动、深度学习基金资助:
Xingquan CAI, Dingwei FENG, Tong WANG, Chen SUN, Haiyan SUN()
Received:2021-12-21
Revised:2022-01-21
Accepted:2022-01-26
Online:2022-03-02
Published:2022-11-10
Contact:
Haiyan SUN
About author:CAI Xingquan, born in 1980, Ph. D., professor. His research interests include virtual reality, human-computer interaction, deep learning.Supported by:摘要:
针对一般的暴力行为检测方法模型参数量大、计算复杂度高、准确率较低等问题,提出一种基于时间注意力机制和EfficientNet的视频暴力行为检测方法。首先将通过对数据集进行预处理计算得到的前景图输入到网络模型中提取视频特征,同时利用轻量化EfficientNet提取前景图中的帧级空间暴力特征,并利用卷积长短时记忆网络(ConvLSTM)进一步提取视频序列的全局时空特征;接着,结合时间注意力机制,计算得到视频级特征表示;最后将视频级特征表示映射到分类空间,并利用Softmax分类器进行视频暴力行为分类并输出检测结果,实现视频的暴力行为检测。实验结果表明,该方法能够减少模型参数量,降低计算复杂度,在有限的资源下提高暴力行为检测准确率,提升模型的综合性能。
中图分类号:
蔡兴泉, 封丁惟, 王通, 孙辰, 孙海燕. 基于时间注意力机制和EfficientNet的视频暴力行为检测[J]. 计算机应用, 2022, 42(11): 3564-3572.
Xingquan CAI, Dingwei FENG, Tong WANG, Chen SUN, Haiyan SUN. Violence detection in video based on temporal attention mechanism and EfficientNet[J]. Journal of Computer Applications, 2022, 42(11): 3564-3572.
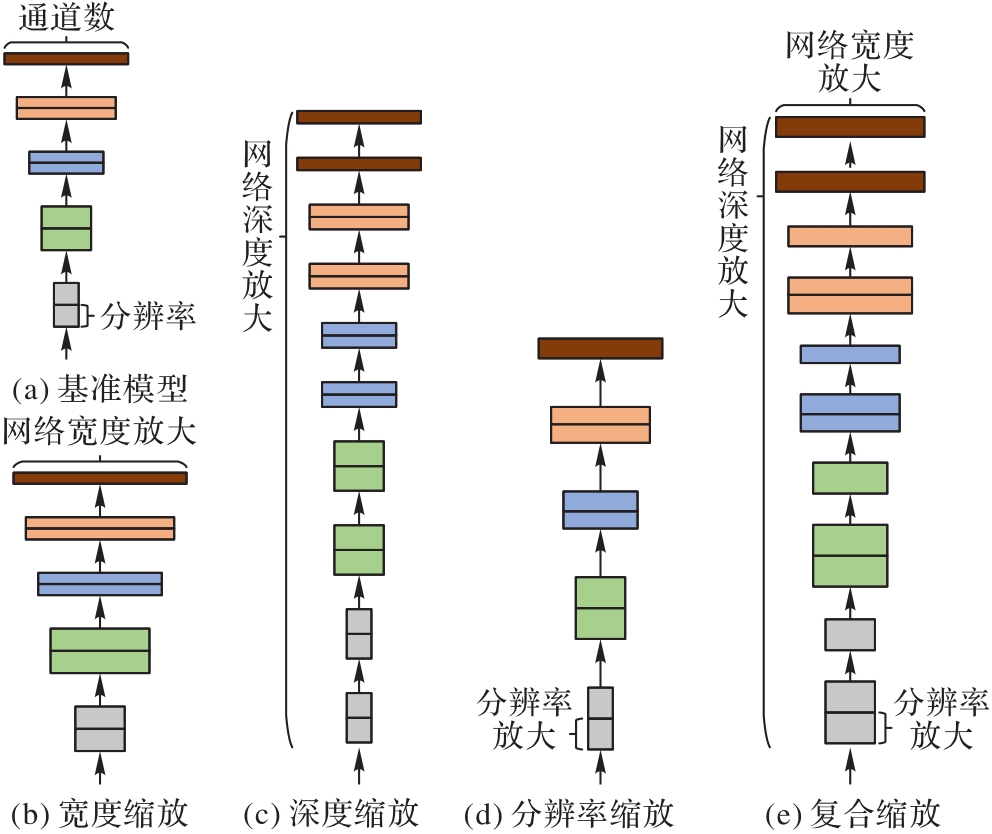
图1 EfficientNet模型复合缩放方法示意图
Fig. 1 Schematic diagram of composite scaling method of EfficientNet model

图2 EfficientNet?B0的网络结构
Fig. 2 Network structure of EfficientNet?B0
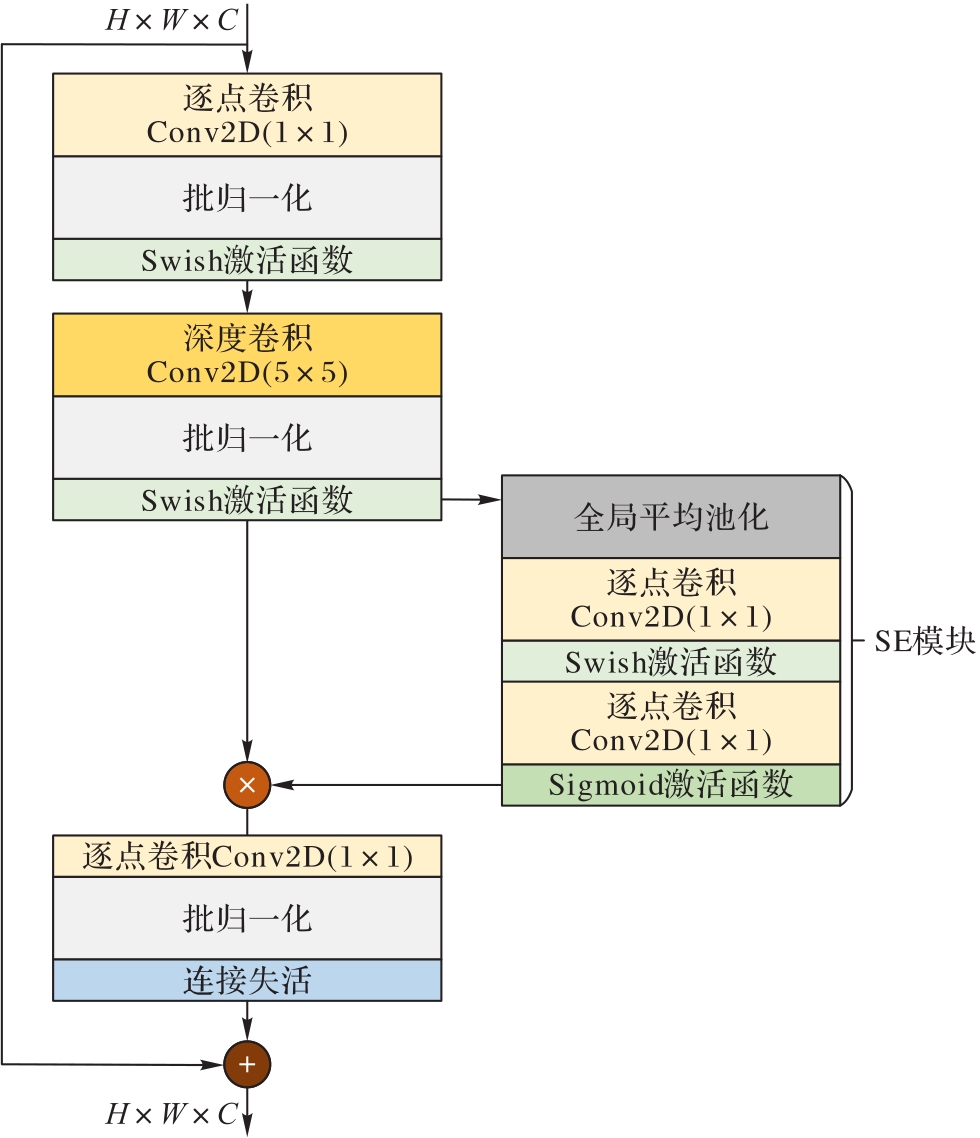
图3 MBConv模块结构
Fig. 3 Structure of MBConv module
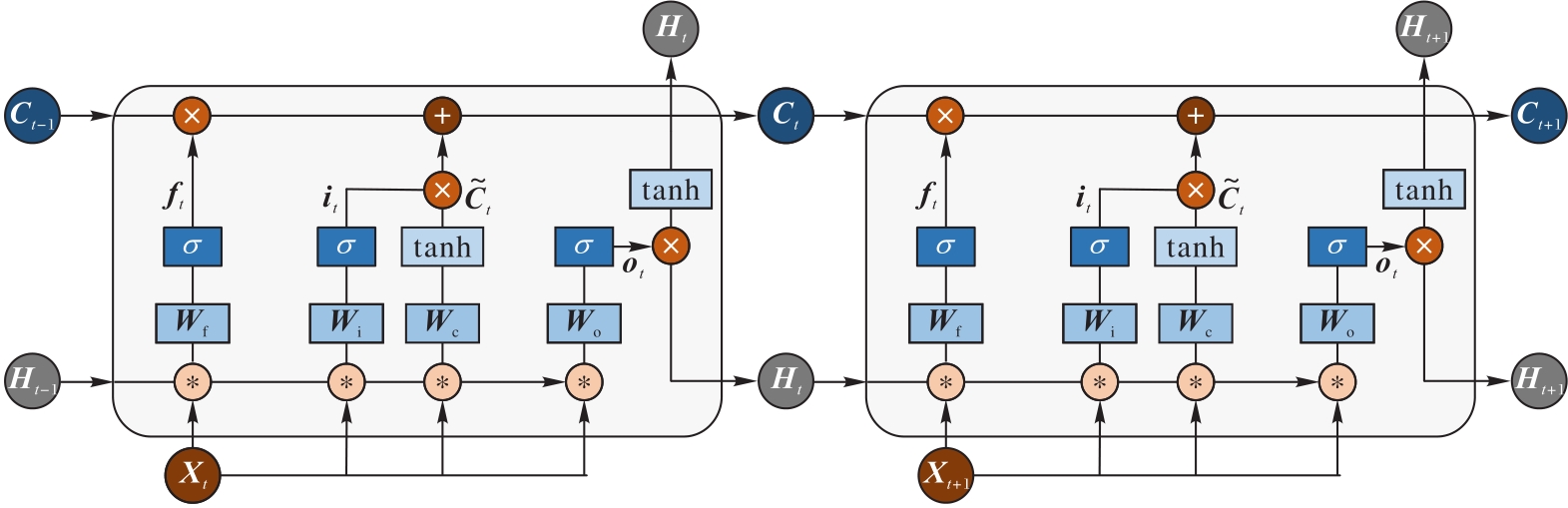
图4 ConvLSTM网络记忆单元内部结构
Fig. 4 Internal structure of ConvLSTM memory unit
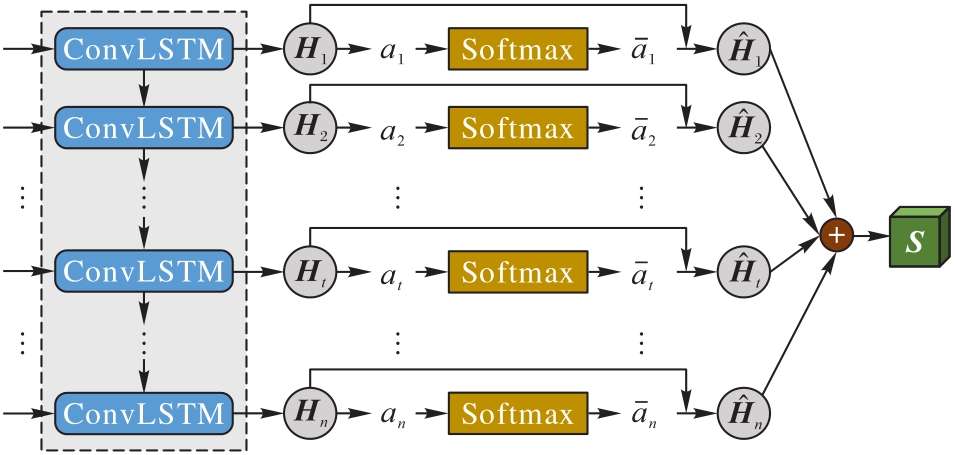
图5 时间注意力机制模型
Fig. 5 Temporal attention mechanism model
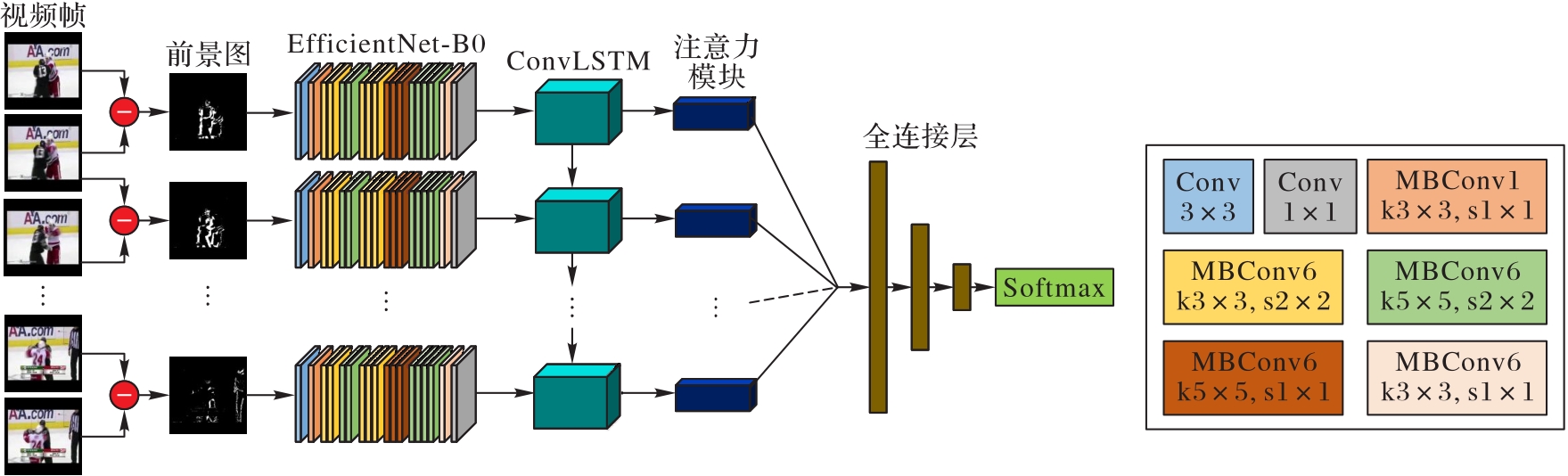
图6 本文算法的网络模型结构
Fig. 6 Network model structure of the proposed algorithm

图7 本文算法的训练和测试流程
Fig. 7 Training and testing flow of the proposed algorithm
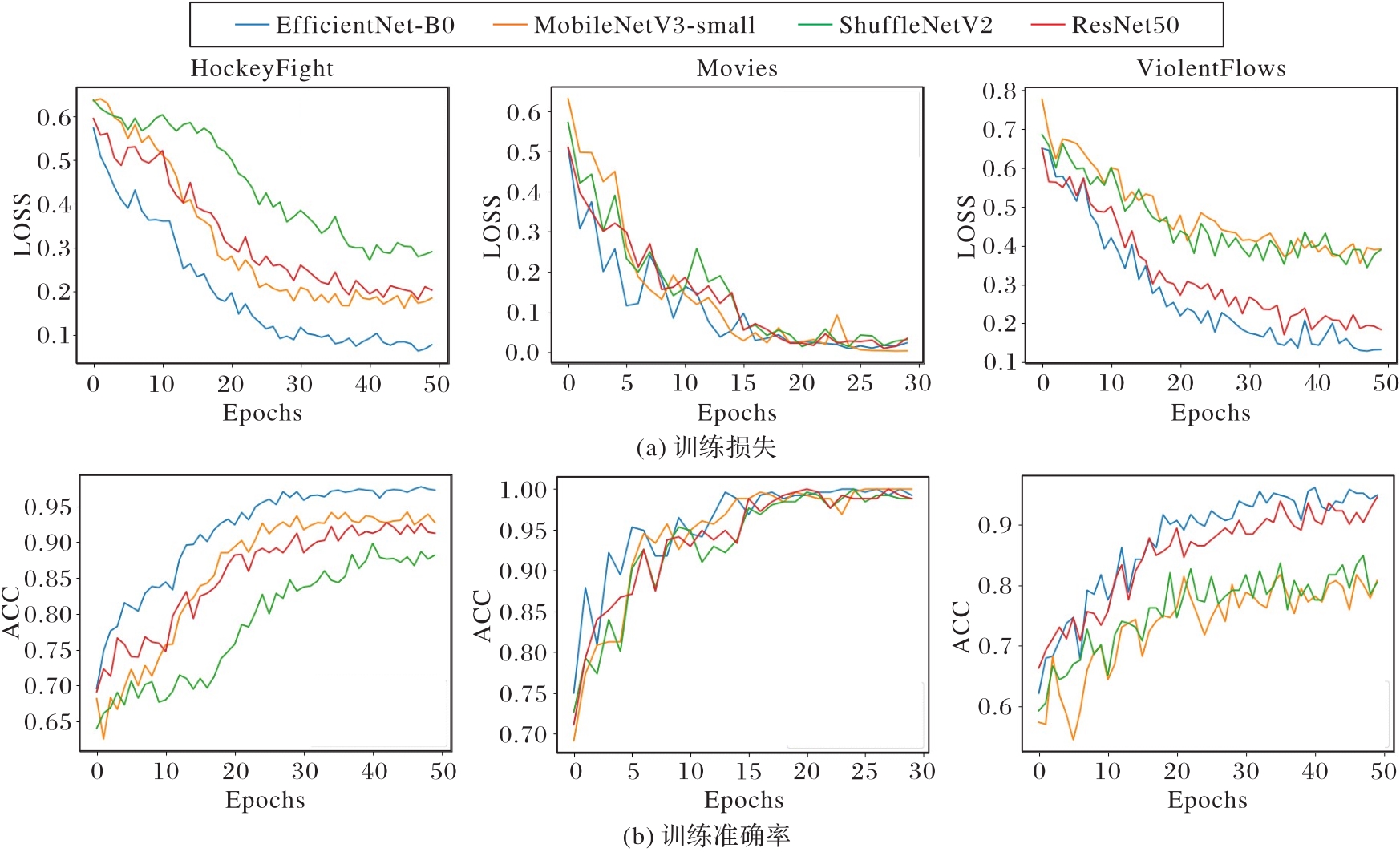
图8 训练损失与准确率对比
Fig. 8 Comparison of training loss and accuracy
| 网络模型 | HockeyFight | Movies | ViolentFlows | |||
|---|---|---|---|---|---|---|
| × | √ | × | √ | × | √ | |
| EfficientNet‑B0 | 92.5 | 94.5 | 100.0 | 100.0 | 90.0 | 94.0 |
| ResNet50 | 89.0 | 93.0 | 100.0 | 100.0 | 90.0 | 92.0 |
| MobileNetV3-mall | 80.0 | 83.0 | 95.0 | 97.5 | 81.0 | 82.0 |
| ShuffleNetV2 | 80.0 | 81.0 | 97.5 | 100.0 | 78.0 | 80.0 |
表1 添加注意力机制前后的准确率对比 ( %)
Tab. 1 Comparison of accuracy before and after adding attention mechanism
| 网络模型 | HockeyFight | Movies | ViolentFlows | |||
|---|---|---|---|---|---|---|
| × | √ | × | √ | × | √ | |
| EfficientNet‑B0 | 92.5 | 94.5 | 100.0 | 100.0 | 90.0 | 94.0 |
| ResNet50 | 89.0 | 93.0 | 100.0 | 100.0 | 90.0 | 92.0 |
| MobileNetV3-mall | 80.0 | 83.0 | 95.0 | 97.5 | 81.0 | 82.0 |
| ShuffleNetV2 | 80.0 | 81.0 | 97.5 | 100.0 | 78.0 | 80.0 |
| 网络模型 | 参数量/MB | HockeyFight | Movies | ViolentFlows | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 训练时间/h | 预测时间/s | 准确率/% | 训练时间/min | 预测时间/s | 准确率/% | 训练时间/h | 预测时间/s | 准确率/% | ||
| EfficientNet‑B0 | 16.20 | 5.6 | 35.7 | 94.5 | 39.5 | 9.7 | 100.0 | 1.4 | 13.6 | 94 |
| ResNet50 | 94.36 | 7.4 | 41.1 | 93.0 | 44.5 | 13.9 | 100.0 | 1.5 | 15.0 | 92 |
| MobileNetV3‑small | 9.20 | 4.9 | 36.7 | 83.0 | 34.1 | 8.4 | 97.5 | 1.1 | 10.3 | 82 |
| ShuffleNetV2 | 16.08 | 4.8 | 38.8 | 81.0 | 34.7 | 9.7 | 100.0 | 1.1 | 15.0 | 80 |
表2 不同网络模型的参数量、预测时间和准确率对比
Tab. 2 Comparison of parameter quantities, prediction times and accuracies of different netwok models
| 网络模型 | 参数量/MB | HockeyFight | Movies | ViolentFlows | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 训练时间/h | 预测时间/s | 准确率/% | 训练时间/min | 预测时间/s | 准确率/% | 训练时间/h | 预测时间/s | 准确率/% | ||
| EfficientNet‑B0 | 16.20 | 5.6 | 35.7 | 94.5 | 39.5 | 9.7 | 100.0 | 1.4 | 13.6 | 94 |
| ResNet50 | 94.36 | 7.4 | 41.1 | 93.0 | 44.5 | 13.9 | 100.0 | 1.5 | 15.0 | 92 |
| MobileNetV3‑small | 9.20 | 4.9 | 36.7 | 83.0 | 34.1 | 8.4 | 97.5 | 1.1 | 10.3 | 82 |
| ShuffleNetV2 | 16.08 | 4.8 | 38.8 | 81.0 | 34.7 | 9.7 | 100.0 | 1.1 | 15.0 | 80 |
| 算法 | HockeyFight | Movies | ViolentFlows |
|---|---|---|---|
| ViF+OViF[ | 87.50 | — | 88.00 |
| Three streams+LSTM[ | 93.70 | — | — |
| VIPS[ | — | 96.91 | 86.61 |
| D3DConvNet[ | 94.25 | — | 92.00 |
| DiMOLIF[ | 88.60 | — | 85.83 |
| LaSIFT+BoW[ | 94.42 | 94.95 | 93.12 |
| MoWLD+Sparce Coding[ | 93.70 | — | 86.39 |
| Gracia+ViF[ | 92.23 | — | 88.67 |
| HOMO[ | 89.30 | — | 76.83 |
| DWT+CNN+BiLSTM[ | 94.06 | — | — |
| 3DHOG+KELM+SVM[ | 92.40 | 99.98 | — |
| 本文算法 | 94.50 | 100.00 | 94.00 |
表3 不同算法的准确率对比 ( %)
Tab. 3 Comparison of accuracy of different algorithms
| 算法 | HockeyFight | Movies | ViolentFlows |
|---|---|---|---|
| ViF+OViF[ | 87.50 | — | 88.00 |
| Three streams+LSTM[ | 93.70 | — | — |
| VIPS[ | — | 96.91 | 86.61 |
| D3DConvNet[ | 94.25 | — | 92.00 |
| DiMOLIF[ | 88.60 | — | 85.83 |
| LaSIFT+BoW[ | 94.42 | 94.95 | 93.12 |
| MoWLD+Sparce Coding[ | 93.70 | — | 86.39 |
| Gracia+ViF[ | 92.23 | — | 88.67 |
| HOMO[ | 89.30 | — | 76.83 |
| DWT+CNN+BiLSTM[ | 94.06 | — | — |
| 3DHOG+KELM+SVM[ | 92.40 | 99.98 | — |
| 本文算法 | 94.50 | 100.00 | 94.00 |
| 1 | SUDHAKARAN S, LANZ O. Learning to detect violent videos using convolutional long short-term memory[C]// Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2017: 1-6. 10.1109/avss.2017.8078468 |
| 2 | 杨亚虎,王瑜,陈天华. 基于深度学习的远程视频监控异常图像检测[J]. 电讯技术, 2021, 61(2): 203-210. 10.3969/j.issn.1001-893x.2021.02.012 |
| YANG Y H, WANG Y, CHEN T H. Detection of abnormal remote video surveillance image based on deep learning[J]. Telecommunication Engineering, 2021, 61(2): 203-210. 10.3969/j.issn.1001-893x.2021.02.012 | |
| 3 | 卢修生,姚鸿勋. 视频中动作识别任务综述[J]. 智能计算机与应用, 2020, 10(3): 406-411. 10.3969/j.issn.2095-2163.2020.03.089 |
| LU X S, YAO H X. A survey of action recognition in videos[J]. Intelligent Computer and Applications, 2020, 10(3): 406-411. 10.3969/j.issn.2095-2163.2020.03.089 | |
| 4 | 谭等泰,王炜,王轶群. 治安监控视频中暴力行为的识别与检测[J]. 中国人民公安大学学报(自然科学版), 2021, 27(2): 94-100. 10.3969/j.issn.1007-1784.2021.02.014 |
| TAN D T, WANG W, WANG Y Q. Recognition and detection of violence in public security surveillance video[J]. Journal of People’s Public Security University of China (Science and Technology), 2021, 27(2): 94-100. 10.3969/j.issn.1007-1784.2021.02.014 | |
| 5 | SARMAN S, SERT M. Audio based violent scene classification using ensemble learning[C]// Proceedings of the 6th International Symposium on Digital Forensic and Security. Piscataway: IEEE, 2018: 1-5. 10.1109/isdfs.2018.8355393 |
| 6 | 杨吕祥. 基于改进的CRNN的暴力音频事件检测方法研究[D]. 武汉:武汉理工大学, 2019. |
| YANG L X. Research on violent sound event detection based on improved CRNN[D]. Wuhan: Wuhan University of Technology, 2019. | |
| 7 | ACAR E, HOPFGARTNER F, ALBAYRAK S. Violence detection in Hollywood movies by the fusion of visual and mid-level audio cues[C]// Proceedings of the 21st ACM International Conference on Multimedia. New York: ACM, 2013: 717-720. 10.1145/2502081.2502187 |
| 8 | 谷学汇. 基于信息融合算法的暴力视频内容识别[J]. 济南大学学报(自然科学版), 2019, 33(3): 224-228. 10.13349/j.cnki.jdxbn.2019.03.005 |
| GU X H. Information composite technology in violent video content recognition[J]. Journal of University of Jinan (Science and Technology), 2019, 33(3): 224-228. 10.13349/j.cnki.jdxbn.2019.03.005 | |
| 9 | GAO Y, LIU H, SUN X H, et al. Violence detection using oriented violent flows[J]. Image and Vision Computing, 2016, 48/49: 37-41. 10.1016/j.imavis.2016.01.006 |
| 10 | 宋凯. 面向视频监控的暴力行为检测技术研究[D]. 哈尔滨:哈尔滨工程大学, 2018. |
| SONG K. Research on detection technology of violence in the background of monitoring[D]. Harbin: Harbin Engineering University, 2018. | |
| 11 | MABROUK A BEN, ZAGROUBA E. Spatio-temporal feature using optical flow based distribution for violence detection[J]. Pattern Recognition Letters, 2017, 92: 62-67. 10.1016/j.patrec.2017.04.015 |
| 12 | ZHANG T, JIA W J, YANG B Q, et al. MoWLD: a robust motion image descriptor for violence detection[J]. Multimedia Tools and Applications, 2017, 76(1): 1419-1438. 10.1007/s11042-015-3133-0 |
| 13 | 丁春辉. 基于深度学习的暴力检测及人脸识别方法研究[D]. 合肥:中国科学技术大学, 2017. |
| DING C H. Violence detection and face recognition based on deep learning method[D]. Hefei: University of Science and Technology of China, 2017. | |
| 14 | DONG Z H, QIN J, WANG Y H. Multi-stream deep networks for person to person violence detection in videos[C]// Proceedings of the 2016 Chinese Conference on Pattern Recognition, CCIS 662. Singapore: Springer, 2016: 517-531. |
| 15 | CHATTERJEE R, HALDER R. Discrete wavelet transform for CNN-BiLSTM-based violence detection[C]// Proceedings of the 2020 International Conference on Emerging Trends and Advances in Electrical Engineering and Renewable Energy, LNEE 708. Singapore: Springer, 2021: 41-52. |
| 16 | SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation now casting[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 802-810. |
| 17 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | HAN K, WANG Y H, TIAN Q, et al. GhostNet: more features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586. 10.1109/cvpr42600.2020.00165 |
| 19 | 刘超军,段喜萍,谢宝文. 应用GhostNet卷积特征的ECO目标跟踪算法改进[J]. 激光技术, 2022, 46(2):239-247. 10.7510/jgjs.issn.1001-3806.2022.02.015 |
| LIU C J, DUAN X P, XIE B W. Improvement of ECO target tracking algorithm based on GhostNet convolution feature[J]. Laser Technology, 2022, 46(2):239-247. 10.7510/jgjs.issn.1001-3806.2022.02.015 | |
| 20 | WEI B Y, SHEN X L, YUAN Y L. Remote sensing scene classification based on improved GhostNet[J]. Journal of Physics: Conference Series, 2020, 1621: No.012091. 10.1088/1742-6596/1621/1/012091 |
| 21 | TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114. |
| 22 | 尹梓睿,张索非,张磊,等. 适于行人重识别的二分支EfficientNet网络设计[J]. 信号处理, 2020, 36(9): 1481-1488. |
| YIN Z R, ZHANG S F, ZHANG L, et al. Design of a two-branch EfficientNet for person re-identification[J]. Journal of Signal Processing, 2020, 36(9): 1481-1488. | |
| 23 | 曹毅,刘晨,盛永健,等. 基于三维图卷积与注意力增强的行为识别模型[J]. 电子与信息学报, 2021, 43(7): 2071-2078. 10.11999/JEIT200448 |
| CAO Y, LIU C, SHENG Y J, et al. Action recognition model based on 3D graph convolution and attention enhanced[J]. Journal of Electronics and Information Technology, 2021, 43(7): 2071-2078. 10.11999/JEIT200448 | |
| 24 | 梁智杰. 聋哑人手语识别关键技术研究[D]. 武汉:华中师范大学, 2019. |
| LIANG Z J. Research on key technologies of sign language recognition for deaf-mutes[D]. Wuhan: Central China Normal University, 2019. | |
| 25 | HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324. 10.1109/iccv.2019.00140 |
| 26 | MA N N, ZHANG X Y, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 122-138. |
| 27 | MOHAMMADI S, PERINA A, KIANI H, et al. Angry crowds: detecting violent events in videos[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9911. Cham: Springer, 2016: 3-18. |
| 28 | SENST T, EISELEIN V, KUHN A, et al. Crowd violence detection using global motion-compensated Lagrangian features and scale sensitive video-level representation[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(12): 2945-2956. 10.1109/tifs.2017.2725820 |
| 29 | MAHMOODI J, SALAJEGHE A. A classification method based on optical flow for violence detection[J]. Expert Systems with Applications, 2019, 127: 121-127. 10.1016/j.eswa.2019.02.032 |
| 30 | 于京. 特殊视频内容分析算法研究[D]. 北京:北京交通大学, 2020. |
| YU J. Study on content analysis algorithms in special video[D]. Beijing: Beijing Jiaotong University, 2020. |
| [1] | 尹聪, 胡汉平. 基于时间注意力机制的时滞混沌系统参数辨识模型[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 842-847. |
| [2] | 屈景怡, 杨柳, 陈旭阳, 王茜. 基于时空序列的Conv-LSTM航班延误预测模型[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3275-3282. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||