


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (2): 608-614.DOI: 10.11772/j.issn.1001-9081.2022010100
所属专题: 多媒体计算与计算机仿真
李文举, 张干, 崔柳( ), 储王慧
), 储王慧
收稿日期:2022-01-25
修回日期:2022-04-25
接受日期:2022-04-26
发布日期:2022-05-31
出版日期:2023-02-10
通讯作者:
崔柳
作者简介:李文举(1964—),男,辽宁营口人,教授,博士,CCF会员,主要研究方向:计算机视觉、模式识别、智能检测基金资助:
Wenju LI, Gan ZHANG, Liu CUI(), Wanghui CHU
Received:2022-01-25
Revised:2022-04-25
Accepted:2022-04-26
Online:2022-05-31
Published:2023-02-10
Contact:
Liu CUI
About author:LI Wenju, born in 1964, Ph. D., professor. His research interests include computer vision, pattern recognition, intelligent detection.Supported by:摘要:
针对交通标志识别模型检测速度与识别精度不均衡,以及受遮挡目标和小目标难以检测的问题,对YOLOv5模型进行改进,提出一种基于坐标注意力(CA)的轻量级交通标志识别模型。首先,通过在主干网络中融入CA机制,有效地捕获位置信息和通道之间的关系,从而更准确地获取感兴趣区域,避免过多的计算开销;然后,通过在特征融合网络中加入跨层连接,在不增加成本的情况下融合更多的特征信息,提高网络的特征提取能力,并改善对遮挡目标的检测效果;最后,引入改进的CIoU函数计算定位损失,以缓解检测过程中样本尺寸分布不均衡的现象,并进一步提高对小目标的识别精度。在TT100K数据集上应用所提模型时,识别精度达到了91.5%,召回率达到了86.64%,与传统的YOLOv5n模型相比分别提高了20.96%和11.62%,且帧处理速率达到了140.84 FPS。实验结果比较充分地验证了所提模型在真实场景中对交通标志检测与识别的准确性与实时性。
中图分类号:
李文举, 张干, 崔柳, 储王慧. 基于坐标注意力的轻量级交通标志识别模型[J]. 计算机应用, 2023, 43(2): 608-614.
Wenju LI, Gan ZHANG, Liu CUI, Wanghui CHU. Lightweight traffic sign recognition model based on coordinate attention[J]. Journal of Computer Applications, 2023, 43(2): 608-614.

图1 坐标注意力模块结构
Fig. 1 Structure of coordinate attention module

图2 三种不同的特征金字塔网络结构
Fig. 2 Structures of three different feature pyramid networks

图3 改进的YOLOv5网络结构
Fig. 3 Structure of improved YOLOv5 network
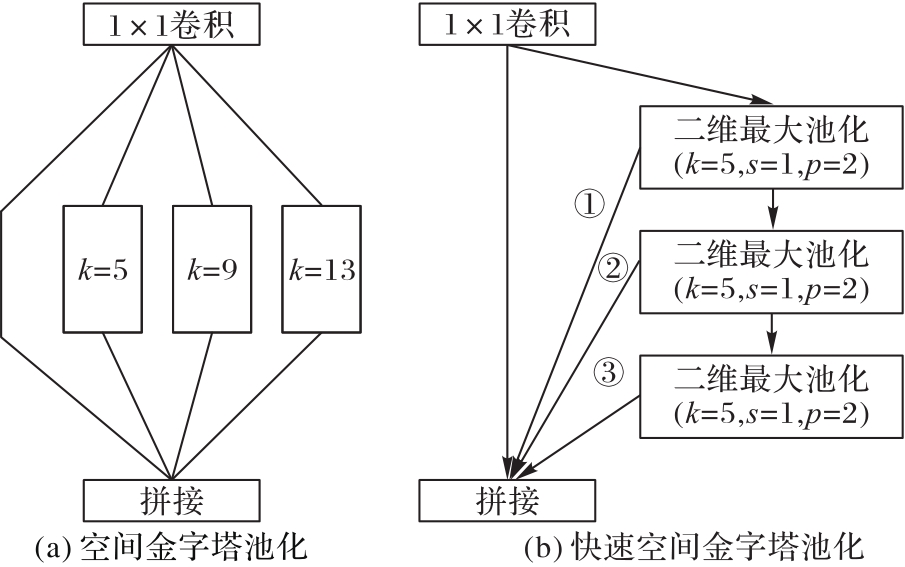
图4 两种空间金字塔池化对比
Fig. 4 Comparison of two spatial pyramids pooling
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv5n | 0.756 4 | 0.776 2 | 333.33 | 1.820 | 3.85 |
| YOLOv5s | 0.820 3 | 0.859 0 | 250.00 | 7.140 | 14.00 |
| YOLOv5m | 0.825 6 | 0.880 1 | 128.20 | 21.040 | 40.60 |
| YOLOv5l | 0.830 0 | 0.890 0 | 75.75 | 46.370 | 80.90 |
| YOLOv5x | 0.853 0 | 0.913 0 | 44.64 | 86.510 | 165.00 |
YOLOv5n (1 280×1 280) | 0.868 1 | 0.850 0 | 156.25 | 1.824 | 4.44 |
表1 传统YOLOv5模型的训练结果对比
Tab. 1 Training results comparison of traditional YOLOv5 models
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv5n | 0.756 4 | 0.776 2 | 333.33 | 1.820 | 3.85 |
| YOLOv5s | 0.820 3 | 0.859 0 | 250.00 | 7.140 | 14.00 |
| YOLOv5m | 0.825 6 | 0.880 1 | 128.20 | 21.040 | 40.60 |
| YOLOv5l | 0.830 0 | 0.890 0 | 75.75 | 46.370 | 80.90 |
| YOLOv5x | 0.853 0 | 0.913 0 | 44.64 | 86.510 | 165.00 |
YOLOv5n (1 280×1 280) | 0.868 1 | 0.850 0 | 156.25 | 1.824 | 4.44 |
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv5n-P6 | 0.815 7 | 0.820 0 | 263.15 | 3.172 | 6.51 |
| YOLOv5s-P6 | 0.840 1 | 0.835 1 | 208.30 | 12.480 | 24.30 |
| YOLOv5m-P6 | 0.865 4 | 0.854 9 | 111.11 | 35.530 | 68.30 |
| YOLOv5l-P6 | 0.872 3 | 0.871 0 | 68.02 | 76.500 | 146.00 |
| YOLOv5x-P6 | 0.8762 | 0.8786 | 40.32 | 140.450 | 268.00 |
YOLOv5n-P6 (1 280×1 280) | 0.875 0 | 0.852 0 | 149.25 | 3.180 | 7.13 |
表2 不同深度的YOLOv5-P6模型的训练结果对比
Tab. 2 Training results comparison of YOLOv5-P6 models with different depths
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv5n-P6 | 0.815 7 | 0.820 0 | 263.15 | 3.172 | 6.51 |
| YOLOv5s-P6 | 0.840 1 | 0.835 1 | 208.30 | 12.480 | 24.30 |
| YOLOv5m-P6 | 0.865 4 | 0.854 9 | 111.11 | 35.530 | 68.30 |
| YOLOv5l-P6 | 0.872 3 | 0.871 0 | 68.02 | 76.500 | 146.00 |
| YOLOv5x-P6 | 0.8762 | 0.8786 | 40.32 | 140.450 | 268.00 |
YOLOv5n-P6 (1 280×1 280) | 0.875 0 | 0.852 0 | 149.25 | 3.180 | 7.13 |
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
YOLOv5n-P6+ 坐标注意力 | 0.847 0 | 0.833 5 | 232.56 | 3.210 | 6.6 |
YOLOv5s-P6+ 坐标注意力 | 0.851 9 | 0.836 3 | 217.39 | 12.620 | 24.5 |
YOLOv5m-P6+ 坐标注意力 | 0.835 2 | 0.815 8 | 107.53 | 35.930 | 69.1 |
YOLOv5l-P6+ 坐标注意力 | 0.826 0 | 0.811 2 | 64.52 | 77.390 | 148.0 |
YOLOv5x-P6+ 坐标注意力 | 0.823 2 | 0.800 3 | 36.63 | 142.140 | 272.0 |
YOLOv5n-P6+ 坐标注意力(1 280×1 280) | 0.8987 | 0.8535 | 144.93 | 3.216 | 7.22 |
表3 不同深度的YOLOv5-P6模型结合坐标注意力的训练结果对比
Tab. 3 Training results comparison of YOLOv5-P6 models with different depths combined with coordinate attention
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
YOLOv5n-P6+ 坐标注意力 | 0.847 0 | 0.833 5 | 232.56 | 3.210 | 6.6 |
YOLOv5s-P6+ 坐标注意力 | 0.851 9 | 0.836 3 | 217.39 | 12.620 | 24.5 |
YOLOv5m-P6+ 坐标注意力 | 0.835 2 | 0.815 8 | 107.53 | 35.930 | 69.1 |
YOLOv5l-P6+ 坐标注意力 | 0.826 0 | 0.811 2 | 64.52 | 77.390 | 148.0 |
YOLOv5x-P6+ 坐标注意力 | 0.823 2 | 0.800 3 | 36.63 | 142.140 | 272.0 |
YOLOv5n-P6+ 坐标注意力(1 280×1 280) | 0.8987 | 0.8535 | 144.93 | 3.216 | 7.22 |

图5 改进的损失函数与CIoU的训练效果对比
Fig. 5 Comparison of training effect between improved loss function and CIoU

图6 本文模型的训练过程演化图
Fig. 6 Training process evolution diagram of the proposed model
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv3 | 0.820 0 | 0.831 4 | 36.76 | 58.74 | 237.00 |
| RetinaNet-NeXt | 0.874 5 | 0.790 0 | |||
| YOLOv3-A | 0.885 0 | 0.922 0 | 1.25 | ||
| YOLOv4 | 0.869 0 | 0.889 0 | 35.84 | 244.00 | |
| YOLOX-Nano | 0.613 0 | 349.65 | 2.25 | 17.40 | |
| Faster R-CNN | 0.715 0 | 0.765 0 | 11.11 | 159.54 | |
| FA-SSD | 0.802 0 | 13.60 | |||
YOLOv5n-P6+ 坐标注意力+ 跨层连接 (1 280×1 280) | 0.910 5 | 0.855 0 | 140.84 | 3.26 | 7.32 |
| 本文模型 | 0.915 0 | 0.866 4 | 140.84 | 3.26 | 7.32 |
表4 本文模型与其他最新模型的训练结果对比
Tab. 4 Comparison of training results between the proposed model and other latest models
| 模型 | 精度 | 召回率 | 帧处理 速率/FPS | 参数量/106 | 模型 大小/MB |
|---|---|---|---|---|---|
| YOLOv3 | 0.820 0 | 0.831 4 | 36.76 | 58.74 | 237.00 |
| RetinaNet-NeXt | 0.874 5 | 0.790 0 | |||
| YOLOv3-A | 0.885 0 | 0.922 0 | 1.25 | ||
| YOLOv4 | 0.869 0 | 0.889 0 | 35.84 | 244.00 | |
| YOLOX-Nano | 0.613 0 | 349.65 | 2.25 | 17.40 | |
| Faster R-CNN | 0.715 0 | 0.765 0 | 11.11 | 159.54 | |
| FA-SSD | 0.802 0 | 13.60 | |||
YOLOv5n-P6+ 坐标注意力+ 跨层连接 (1 280×1 280) | 0.910 5 | 0.855 0 | 140.84 | 3.26 | 7.32 |
| 本文模型 | 0.915 0 | 0.866 4 | 140.84 | 3.26 | 7.32 |

图7 不同模型的检测效果对比
Fig. 7 Comparison of detection effects of different models

图8 一些检测错误的示例
Fig. 8 Some examples of detection error
| 1 | HE S H, CHEN L, ZHANG S Y, et al. Automatic recognition of traffic signs based on visual inspection[J]. IEEE Access, 2021, 9: 43253-43261. 10.1109/access.2021.3059052 |
| 2 | 于硕. 交通标志识别技术综述[J]. 科技资讯, 2019, 17(6): 15-16. |
| YU S. Overview of traffic sign recognition technology[J]. Science and Technology Information, 2019, 17(6): 15-16. | |
| 3 | FLEYEH H, BISWAS R, DAVAMI E. Traffic sign detection based on AdaBoost color segmentation and SVM classification[C]// Proceedings of the EuroCon 2013. Piscataway: IEEE, 2013: 2005-2010. 10.1109/eurocon.2013.6625255 |
| 4 | 杜影丽,贾永红,韩静敏. 自然场景车载视频道路交通限速标志的检测与识别方法[J]. 测绘地理信息, 2018, 43(2): 32-34, 37. 10.14188/j.2095-6045.2018018 |
| DU Y L, JIA Y H, HAN J M. A detection and recognition method for traffic speed limit signs based on vehicle videos[J]. Journal of Geomatics, 2018, 43(2): 32-34, 37. 10.14188/j.2095-6045.2018018 | |
| 5 | 陈名松,吴冉冉,张泽功,等. 基于改进CapsNet的交通标志分类模型[J]. 计算机应用研究, 2020, 37(S2):367-368, 371. |
| CHEN M S, WU R R, ZHANG Z G, et al. Traffic sign classification model based on improved CapsNet[J]. Application Research of Computers, 2020, 37(S2):367-368, 371. | |
| 6 | 郭璠,张泳祥,唐琎,等. YOLOv3-A:基于注意力机制的交通标志检测网络[J]. 通信学报, 2021, 42(1):87-99. |
| GUO F, ZHANG Y X, TANG J, et al. YOLOv3-A: a traffic sign detection network based on attention mechanism[J]. Journal on Communications, 2021, 42(1):87-99. | |
| 7 | JIN Y M, FU Y S, WANG W Q, et al. Multi-feature fusion and enhancement single shot detector for traffic sign recognition[J]. IEEE Access, 2020, 8: 38931-38940. 10.1109/access.2020.2975828 |
| 8 | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1571-1580. 10.1109/cvprw50498.2020.00203 |
| 9 | HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13708-13717. 10.1109/cvpr46437.2021.01350 |
| 10 | TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10778-10787. 10.1109/cvpr42600.2020.01079 |
| 11 | LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768. 10.1109/cvpr.2018.00913 |
| 12 | ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 12993-13000. 10.1609/aaai.v34i07.6999 |
| 13 | ZHU Z, LIANG D, ZHANG S H, et al. Traffic-sign detection and classification in the wild[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2110-2118. 10.1109/cvpr.2016.232 |
| 14 | XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 2048-2057. 10.1109/cvpr.2015.7298935 |
| 15 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 16 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 17 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 18 | HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. 10.1109/tpami.2015.2389824 |
| 19 | JIANG B R, LUO R X, MAO J Y, et al. Acquisition of localization confidence for accurate object detection[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 816-832. |
| 20 | REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 658-666. 10.1109/cvpr.2019.00075 |
| 21 | 龚祎垄,吴勇,陈铭峥. 针对TT100K交通标志数据集的扩增策略[J]. 福建电脑, 2019, 35(11):70-71. |
| GONG Y L, WU Y, CHEN M Z. An enlargement strategy for TT100K traffic sign data set[J]. Journal of Fujian Computer, 2019, 35(11):70-71. | |
| 22 | 张干,李文举,张耀星. 基于改进的YOLOv5算法的交通标志识别[C]// 21全国仿真技术学术会议论文集. 北京: 计算机仿真杂志社, 2021:182-185, 249. 10.1109/iccnea50255.2020.00021 |
| ZHANG G, LI W J, ZHANG Y X. Traffic sign recognition based on improved YOLOv5 algorithm[C]// Proceedings of the 2021 China Simulation Technology Conference. Beijing: Periodical Office of Computer Simulation, 2021:182-185, 249. 10.1109/iccnea50255.2020.00021 |
| [1] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [2] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [3] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [4] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [5] | 李烨恒, 罗光圣, 苏前敏. 基于改进YOLOv5的Logo检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2580-2587. |
| [6] | 刘瑞华, 郝子赫, 邹洋杨. 基于多层级精细特征融合的步态识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2250-2257. |
| [7] | 孔哲, 李寒, 甘少伟, 孔明茹, 何冰涛, 郭子钰, 金督程, 邱兆文. 基于非对称多解码器和注意力模块的三维肾脏影像结构分割模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2216-2224. |
| [8] | 程小辉, 黄云天, 张瑞芳. 基于多尺度和加权坐标注意力的轻量化红外道路场景检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1927-1934. |
| [9] | 刘越, 刘芳, 武奥运, 柴秋月, 王天笑. 基于自注意力机制与图卷积的3D目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1972-1977. |
| [10] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [11] | 韩贵金, 张馨渊, 张文涛, 黄娅. 基于多特征融合的自监督图像配准算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1597-1604. |
| [12] | 李鑫, 孟乔, 皇甫俊逸, 孟令辰. 基于分离式标签协同学习的YOLOv5多属性分类[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1619-1628. |
| [13] | 宋霄罡, 张冬冬, 张鹏飞, 梁莉, 黑新宏. 面向复杂施工环境的实时目标检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1605-1612. |
| [14] | 李鸿天, 史鑫昊, 潘卫国, 徐成, 徐冰心, 袁家政. 融合多尺度和注意力机制的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1437-1444. |
| [15] | 李威, 陈玲, 徐修远, 朱敏, 郭际香, 周凯, 牛颢, 张煜宸, 易珊烨, 章毅, 罗凤鸣. 基于多任务学习的间质性肺病分割算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1285-1293. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||