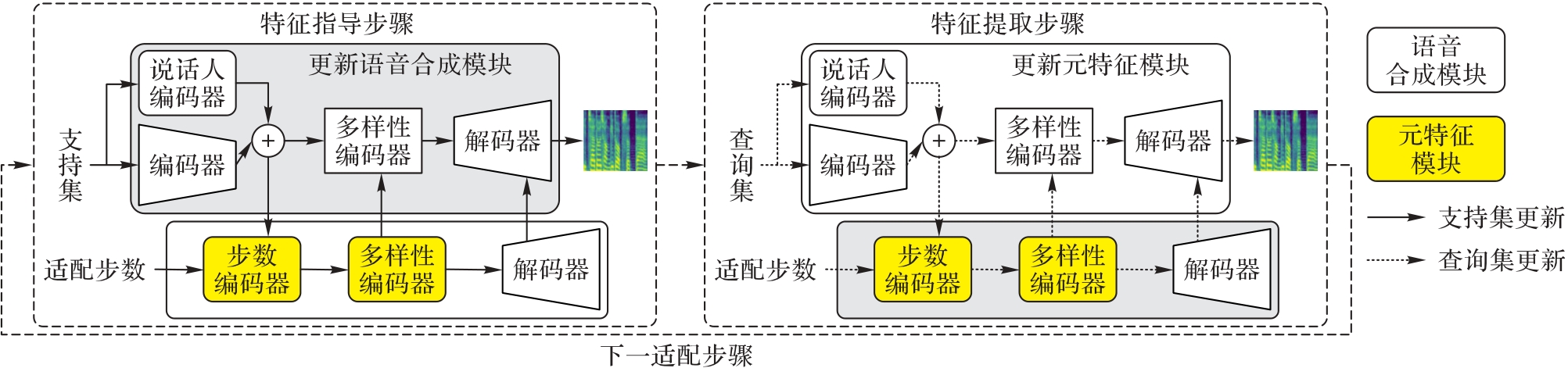
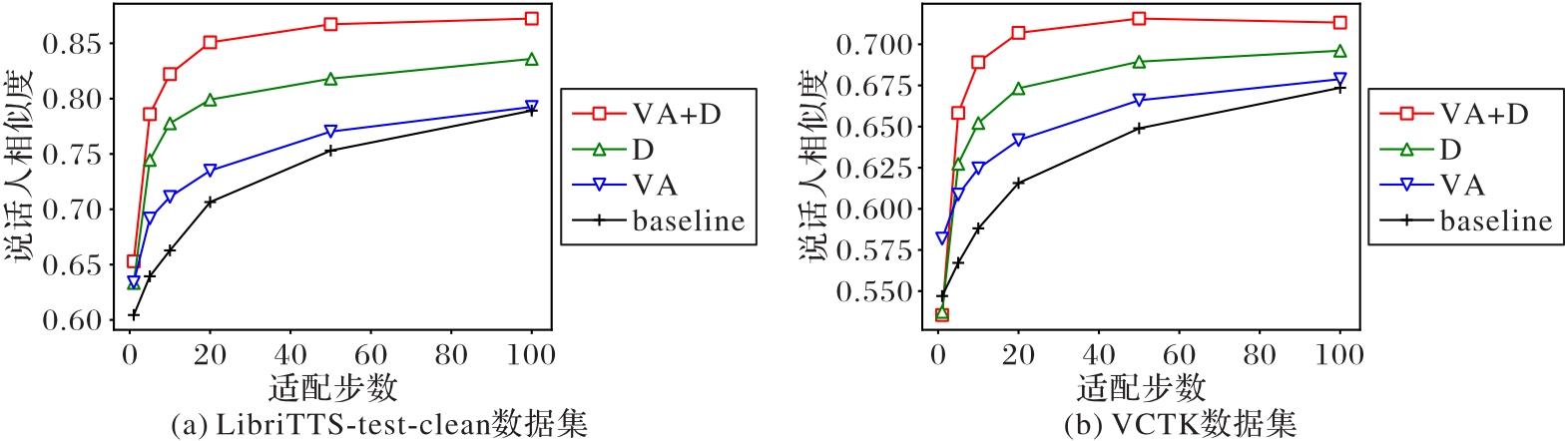
| 1 |
ARIK S Ö, DIAMOS G, GIBIANSKY A, et al. Deep Voice 2: multi-speaker neural text-to-speech[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 2966-2974.
|
| 2 |
CHEN M, TAN X, LI B, et al. AdaSpeech: adaptive text to speech for custom voice[C/OL]// Proceedings of the 9th International Conference on Learning Representations. [S.l.]: dblp, 2021 [2023-04-11]. . 10.48550/arXiv.2103.00993
|
| 3 |
WANG T, TAO J, FU R, et al. Spoken content and voice factorization for few-shot speaker adaptation[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France: International Speech Communication Association, 2020: 796-800. 10.21437/interspeech.2020-1745
|
| 4 |
ARIK S, CHEN J, PENG K, et al. Neural voice cloning with a few samples[C]// Proceedings of the 32nd International Conference on Neural Information Processing System. Red Hook: Curran Associates Inc., 2018: 10040-10050.
|
| 5 |
CHOI S, HAN S, KIM D, et al. Attentron: few-shot text-to-speech utilizing attention-based variable-length embedding[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France: International Speech Communication Association, 2020: 2007-2011. 10.21437/interspeech.2020-2096
|
| 6 |
C-M CHIEN, LIN J-H, HUANG C-Y, et al. Investigating on incorporating pretrained and learnable speaker representations for multi-speaker multi-style text-to-speech[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 8588-8592. 10.1109/icassp39728.2021.9413880
|
| 7 |
CAI Z, ZHANG C, LI M. From speaker verification to multi-speaker speech synthesis, deep transfer with feedback constraint[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France: International Speech Communication Association, 2020: 3974-3978. 10.21437/interspeech.2020-1032
|
| 8 |
AZAVI A. VAN DEN OORD, VINYALS O. Generating diverse high-fidelity images with VQ-VAE-2[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 14866-14876.
|
| 9 |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241. 10.1007/978-3-319-24574-4_28
|
| 10 |
WANG T, TAO J, FU R, et al. Bi-level speaker supervision for one-shot speech synthesis[C]// Proceedings of the 21st Annual Conference of the International Speech Communication Association. Baixas, France: International Speech Communication Association, 2020: 3989-3993. 10.21437/interspeech.2020-1737
|
| 11 |
HUYBRECHTS G, MERRITT T, COMINI G, et al. Low-resource expressive text-to-speech using data augmentation[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6593-6597. 10.1109/icassp39728.2021.9413466
|
| 12 |
HUANG S-F, LIN C-J, LIU D-R, et al. Meta-TTS: meta-learning for few-shot speaker adaptive text-to-speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 1558-1571. 10.1109/taslp.2022.3167258
|
| 13 |
VAN DEN OORD A, DIELEMAN S, ZEN H, et al. WaveNet: a generative model for raw audio[C/OL]// Proceedings of the 9th ISCA Workshop on Speech Synthesis Workshop. [S.l.]: ISCA, 2016 [2023-05-01]. . 10.21437/ssw.2016
|
| 14 |
WANG Y, SKERRY-RYAN R J, STANTON D, et al. Tacotron: towards end-to-end speech synthesis[C]// Proceedings of the 18th Annual Conference of the International Speech Communication Association. Baixas, France: International Speech Communication Association, 2017: 4006-4010. 10.21437/interspeech.2017-1452
|
| 15 |
SKERRY-RYAN R J, BATTENBERG E, XIAO Y, et al. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron[C/OL]// Proceedings of the 35th International Conference on Machine Learning. [S.l.]: ICML, 2018[2023-05-01]. .
|
| 16 |
REN Y, RUAN Y, TAN X, et al. FastSpeech: fast, robust and controllable text to speech[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 3171-3180.
|
| 17 |
REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text-to-speech[C/OL]// Proceedings of the 9th International Conference on Learning Representations. [S.l.]: ICLR, 2021[2023-05-01]. .
|
| 18 |
VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[C]// Proceedings of the 30th International Conference on Neural Information Processing System. Red Hook: Curran Associates Inc., 2016: 3637-3645.
|
| 19 |
SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 4080-4090.
|
| 20 |
ORESHKIN B N, RODRIGUEZ P, LACOSTE A. TADAM: task dependent adaptive metric for improved few-shot learning[C]// Proceedings of the 32nd International Conference on Neural Information Processing System. Red Hook: Curran Associates Inc., 2018: 719-729.
|
| 21 |
REZENDE D J, MOHAMED S, DANIHELKA I, et al. One-shot generalization in deep generative models[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR, 2016: 1521-1529.
|
| 22 |
BARTUNOV S, VETROV D. Few-shot generative modelling with generative matching networks[C]// Proceedings of the 21st International Conference on Artificial Intelligence and Statistics. New York: JMLR, 2018: 670-678.
|
| 23 |
REED S, CHEN Y, PAINE T, et al. Few-shot autoregressive density estimation: towards learning to learn distributions[C/OL]// Proceedings of the 6th International Conference on Learning Representations. [S.l.]: ICLR, 2018 [2023-05-01]. .
|
| 24 |
CHEN Y, ASSAEL Y, SHILLINGFORD B, et al. Sample efficient adaptive text-to-speech[C/OL]// Proceedings of the 7th International Conference on Learning Representations. [S.l.]: ICLR, 2019 [2023-05-01]. .
|
| 25 |
HU Q, MARCHI E, WINARSKY D, et al. Neural text-to-speech adaptation from low quality public recordings[C]// Proceedings of the 10th ISCA Speech Synthesis Workshop. Baixas, France: International Speech Communication Association, 2019: 24-28. 10.21437/ssw.2019-5
|
| 26 |
KONG J, KIM J, BAE J. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17022-17033.
|


 )
)