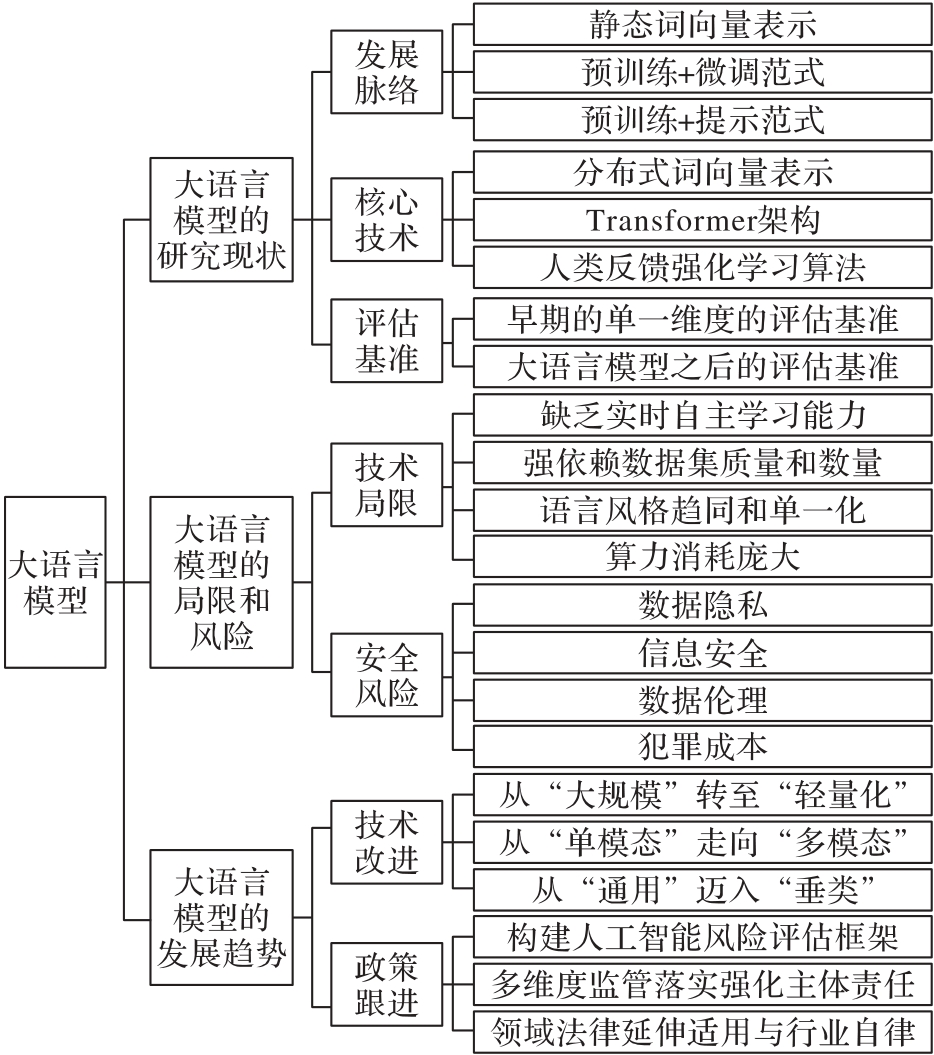
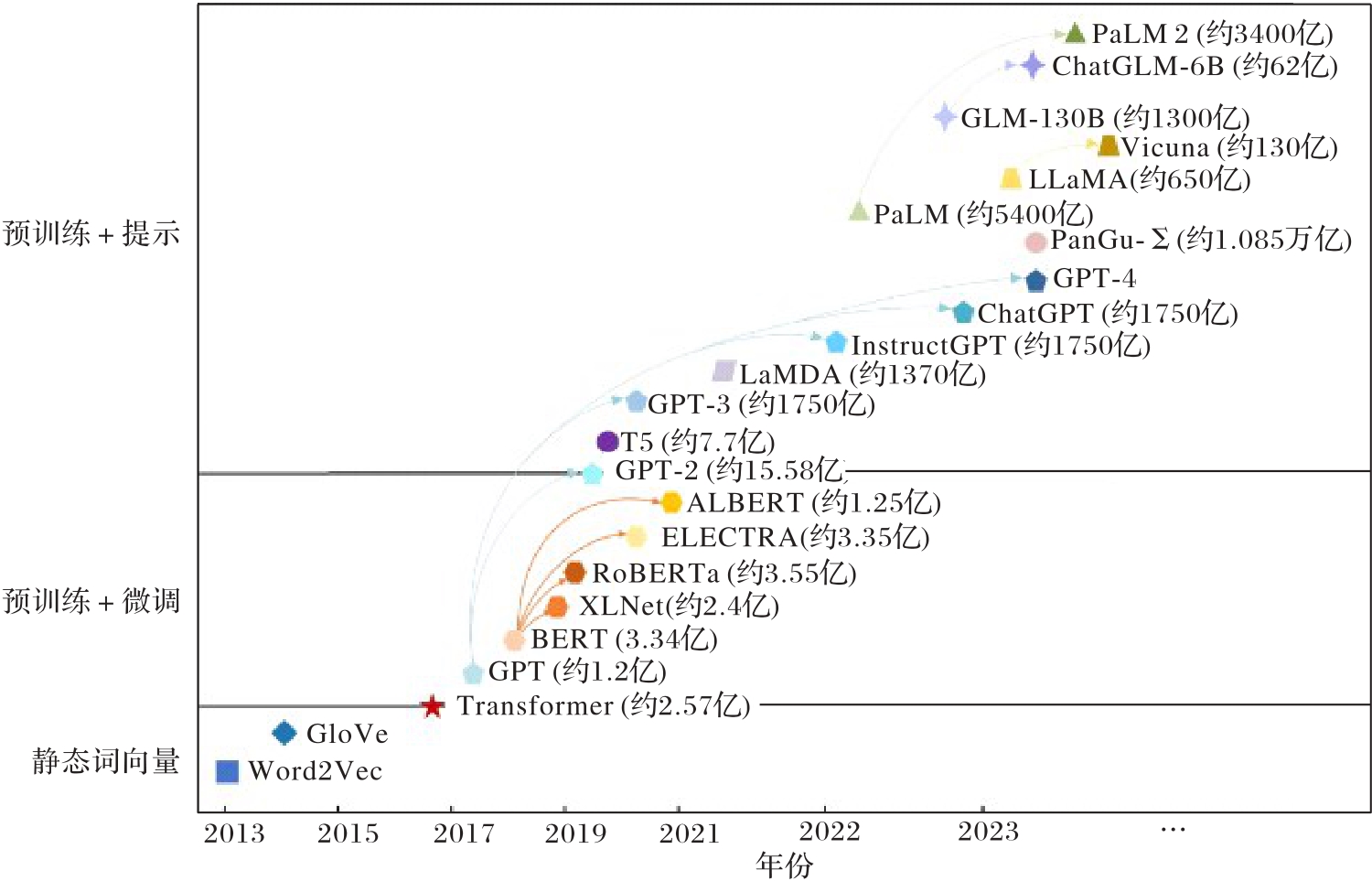
| 1 |
WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models [EB/OL]. [2023-03-10]. .
|
| 2 |
GOERTZEL B. Artificial general intelligence: concept, state of the art, and future prospects [J]. Journal of Artificial General Intelligence, 2014, 5(1): 1-46.
|
| 3 |
OpenAI. ChatGPT plugins [EB/OL]. [2023-05-05]. .
|
| 4 |
VAN DIS E A M, BOLLEN J, ZUIDEMA W, et al. ChatGPT: five priorities for research [J]. Nature, 2023, 614(7947): 224-226.
|
| 5 |
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL]. [2023-02-23] .
|
| 6 |
PENNINGTON J, SOCHER R, MANNING C. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543.
|
| 7 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
|
| 8 |
DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186.
|
| 9 |
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2023-05-30]. .
|
| 10 |
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. The Journal of Machine Learning Research, 2020, 21(1):5485-5551.
|
| 11 |
YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding [C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5753-5763.
|
| 12 |
LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2023-02-23]. .
|
| 13 |
LAN Z, CHEN M, GOODMAN S, et al. ALBERT: A lite BERT for selfsupervised learning of language representations [EB/OL]. [2023-05-30]. .
|
| 14 |
CLARK K, M-T LUONG, LE Q V, et al. ELECTRA: pre-training text encoders as discriminators rather than generators [EB/OL]. [2023-05-30]. .
|
| 15 |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2023-05-30]. .
|
| 16 |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901.
|
| 17 |
OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback [EB/OL]. [2023-02-23]. .
|
| 18 |
CHEN M, TWOREK J, JUN H, et al. Evaluating large language models trained on code [EB/OL]. [2023-02-23]. .
|
| 19 |
OpenAI. GPT-4 technical report [EB/OL]. [2023-06-07]. .
|
| 20 |
THOPPILAN R, DE FREITAS D, HALL J, et al. LaMDA: language models for dialog applications [EB/OL]. [2023-06-07]. .
|
| 21 |
CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways [EB/OL]. [2023-06-07]. .
|
| 22 |
ANIL R, DAI A M, FIRAT O, et al. PaLM 2 technical report [EB/OL]. [2023-06-07]. .
|
| 23 |
TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models [EB/OL]. [2023-06-07]. .
|
| 24 |
The Vicuna Team. Vicuna: an open-source chatbot impressing GPT-4 with 90%* ChatGPT quality [EB/OL]. [2023-06-07]. .
|
| 25 |
SMITH S, PATWARY M, NORICK B, et al. Using DeepSpeed and Megatron to train Megatron-Turing NLG 530B, a large-scale generative language model [EB/OL]. [2023-07-05]. .
|
| 26 |
ZENG W, REN X, SU T, et al. PanGu‑α: large-scale autoregressive pretrained Chinese language models with auto-parallel computation [EB/OL]. [2023-02-23]. .
|
| 27 |
REN X, ZHOU P, MENG X, et al. PanGu‑Σ: towards trillion parameter language model with sparse heterogeneous computing [EB/OL]. [2023-06-07]. .
|
| 28 |
DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [EB/OL]. [2023-07-05]. .
|
| 29 |
ZENG A, LIU X, DU Z, et al. GLM-130B: an open bilingual pre-trained model [EB/OL]. [2023-07-05]. .
|
| 30 |
XIONG H, WANG S, ZHU Y, et al. DoctorGLM: fine-tuning your Chinese doctor is not a Herculean task [EB/OL]. [2023-07-05]. .
|
| 31 |
STIENNON N, OUYANG L, WU J, et al. Learning to summarize with human feedback [C]// Proceedings of the 34th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 3008-3021.
|
| 32 |
WU Z, HU Y, SHI W, et al. Fine-grained human feedback gives better rewards for language model training [EB/OL]. [2023-06-15]. .
|
| 33 |
DONG H, XIONG W, GOYAL D, et al. RAFT: reward ranked fine tuning for generative foundation model alignment [EB/OL]. [2023-06-14]. .
|
| 34 |
YUAN Z, YUAN H, TAN C, et al. RRHF: rank responses to align language models with human feedback without tears [EB/OL]. [2023-06-14]. .
|
| 35 |
RAFAILOV R, SHARMA A, MITCHELL E, et al. Direct preference optimization: your language model is secretly a reward model [EB/OL]. [2023-06-14]. .
|
| 36 |
HENDRYCKS D, BURNS C, BASART S, et al. Measuring massive multitask language understanding [C/OL]// Proceedings of the 9th International Conference on Learning Representations. 2021 [2023-05-30]. .
|
| 37 |
WANG A, PRUKSACHATKUN Y, NANGIA N, et al. SuperGLUE: a stickier benchmark for general-purpose language understanding systems [C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 3261-3275.
|
| 38 |
SRIVASTAVA A, RASTOGI A, RAO A, et al. Beyond the imitation game: quantifying and extrapolating the capabilities of language models [EB/OL]. [2023-02-25]. .
|
| 39 |
ZHONG W, CUI R, GUO Y, et al. AGIEval: a human-centric benchmark for evaluating foundation models [EB/OL]. [2023-06-27]. .
|
| 40 |
ZENG H. Measuring massive multitask Chinese understanding [EB/OL]. [2023-06-27]. .
|
| 41 |
HUANG Y, BAI Y, ZHU Z, et al. C-EVAL: a multi-level multi-discipline Chinese evaluation suite for foundation models [EB/OL]. [2023-06-27]. .
|
| 42 |
FU C, CHEN P, SHEN Y, et al. MME: a comprehensive evaluation benchmark for multimodal large language models [EB/OL]. [2023-06-27]. .
|
| 43 |
XU P, SHAO W, ZHANG K, et al. LVLM-eHub: a comprehensive evaluation benchmark for large vision-language models [EB/OL]. [2023-06-27]. .
|
| 44 |
LIANG P, BOMMASANI R, LEE T, et al. Holistic evaluation of language models [EB/OL]. [2023-06-08]. .
|
| 45 |
CHIA Y K, HONG P, BING L, et al. INSTRUCTEVAL: towards holistic evaluation of instruction-tuned large language models [EB/OL]. [2023-06-27]. .
|
| 46 |
LIU Y, ITER D, XU Y, et al. G-Eval: NLG evaluation using GPT-4 with better human alignment [EB/OL]. (2023-05-23)[2023-06-27]. .
|
| 47 |
LIU C, JIN R, REN Y, et al. M3 KE: a massive multi-level multi-subject knowledge evaluation benchmark for chinese large language models [EB/OL]. [2023-06-27]. .
|
| 48 |
DAVID ROZADO. The political orientation of the ChatGPT AI system 2022 [EB/OL]. [2023-03-09]. .
|
| 49 |
WEI J, WANG X, SCHUURMANS D, et al. Chain of thought prompting elicits reasoning in large language models [C/OL]//Proceedings of the 36th Conference on Neural Information Processing Systems. 2022[2023-05-30]. .
|
| 50 |
KAPLAN J, McCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models [EB/OL]. [2023-02-23]. .
|
| 51 |
TAO C, HOU L, ZHANG W, et al. Compression of generative pre-trained language models via quantization [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2022: 4821-4836.
|
| 52 |
HE Y, ZHANG X, SUN J. Channel pruning for accelerating very deep neural networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1398-1406.
|
| 53 |
WEN W, WU C, WANG Y, et al. Learning structured sparsity in deep neural networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 2082-2090.
|
| 54 |
HUANG S, DONG L, WANG W, et al. Language is not all you need: aligning perception with language models [EB/OL]. [2023-06-21]. .
|
| 55 |
SOLAIMAN I, BRUNDAGE M, CLARK J, et al. Release strategies and the social impacts of language models [EB/OL]. [2023-02-23]. .
|
| 56 |
曹建峰.迈向可信AI: ChatGPT类生成式人工智能的治理挑战及应对[J]. 上海政法学院学报(法治论丛), 2023, 38(4): 28-42.
|
|
CAO J F. Towards trustworthy AI: governance challenges and responses for generative AI like ChatGPT [J]. Journal of Shanghai University of Political Science and Law (The Rule of Law Forum), 2023, 38(4):28-42.
|
| 57 |
支振锋.生成式人工智能大模型的信息内容治理[J].政法论坛,2023,41(4):34-48.
|
|
ZHI Z F. Information content governance of large model of generative artificial intelligence [J]. Tribune of Political Science and Law, 2023, 41(4):34-48.
|


 ), 胡玲1, 赵佳艺1, 杜宛泽2, 王文清2
), 胡玲1, 赵佳艺1, 杜宛泽2, 王文清2