


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (12): 3867-3875.DOI: 10.11772/j.issn.1001-9081.2023111707
李博1,2, 黄建强1,2( ), 黄东强1,2, 王晓英1
), 黄东强1,2, 王晓英1
收稿日期:2023-12-11
修回日期:2024-02-07
接受日期:2024-03-01
发布日期:2024-05-30
出版日期:2024-12-10
通讯作者:
黄建强
作者简介:李博(1998—),男,山东菏泽人,硕士研究生,CCF会员,主要研究方向:高性能计算基金资助:
Bo LI1,2, Jianqiang HUANG1,2(), Dongqiang HUANG1,2, Xiaoying WANG1
Received:2023-12-11
Revised:2024-02-07
Accepted:2024-03-01
Online:2024-05-30
Published:2024-12-10
Contact:
Jianqiang HUANG
About author:LI Bo, born in 1998, M. S. candidate. His research interests include high performance computing.Supported by:摘要:
稀疏矩阵向量乘(SpMV)是一种重要的数值线性代数运算,现有的优化存在预处理及通信时间考虑不全面、存储结构不具有普适性等问题。为了解决这些问题,提出异构平台下SpMV的自适应优化方案。所提方案利用皮尔逊相关系数确定相关度高的特征参数,并使用基于梯度提升决策树(GBDT)的极端梯度提升(XGBoost)和轻量级梯度提升(LightGBM)算法训练预测模型,以确定某一稀疏矩阵更优的存储格式。利用网格搜索确定模型训练时更优的模型超参数,使这2种算法选择更适合的存储结构的准确率都超过85%。此外,对于预测存储结构为混合(HYB)格式的稀疏矩阵,在GPU和CPU上分别计算其中的等长列(ELL)与坐标(COO)存储格式部分,建立基于CPU+GPU的并行混合计算模式;同时为小数据量的稀疏矩阵选择硬件平台,提高运算速度。实验结果表明,自适应计算优化相较于cuSPARSE库中的压缩稀疏行(CSR)存储格式计算的平均加速比可以达到1.4,相较于按照HYB和ELL存储格式计算的平均加速比则可以分别达到2.1和2.6。
中图分类号:
李博, 黄建强, 黄东强, 王晓英. 基于异构平台的稀疏矩阵向量乘自适应计算优化[J]. 计算机应用, 2024, 44(12): 3867-3875.
Bo LI, Jianqiang HUANG, Dongqiang HUANG, Xiaoying WANG. Adaptive computing optimization of sparse matrix-vector multiplication based on heterogeneous platforms[J]. Journal of Computer Applications, 2024, 44(12): 3867-3875.
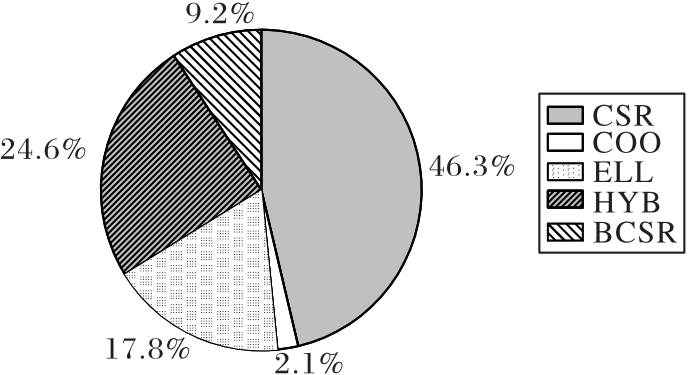
图1 最优存储格式所占的比例
Fig. 1 Proportion of optimal storage formats
| 特征参数 | 参数描述 | 时间复杂度 |
|---|---|---|
| nnz | 矩阵总非零元素数量 | O(1) |
| m | 矩阵行数 | O(1) |
| n | 矩阵列数 | O(1) |
| max_nnz | 所有行中的非零元素数的最大值 | O(nnz) |
| min_nnz | 所有行中的非零元素数的最小值 | O(nnz) |
| mid_nnz | 组宽(max_nnz-min_nnz)/m | O(1) |
| row_mu | 平均每行非零元素 | O(1) |
| col_mu | 平均每列非零元素 | O(1) |
| sd | 每行非零元素的标准偏差 | O(nnz) |
| Rsd | 矩阵的变异系数sd/row_mu | O(1) |
表1 选取的特征参数
Tab. 1 Selected feature parameters
| 特征参数 | 参数描述 | 时间复杂度 |
|---|---|---|
| nnz | 矩阵总非零元素数量 | O(1) |
| m | 矩阵行数 | O(1) |
| n | 矩阵列数 | O(1) |
| max_nnz | 所有行中的非零元素数的最大值 | O(nnz) |
| min_nnz | 所有行中的非零元素数的最小值 | O(nnz) |
| mid_nnz | 组宽(max_nnz-min_nnz)/m | O(1) |
| row_mu | 平均每行非零元素 | O(1) |
| col_mu | 平均每列非零元素 | O(1) |
| sd | 每行非零元素的标准偏差 | O(nnz) |
| Rsd | 矩阵的变异系数sd/row_mu | O(1) |
| Pearson系数 | 相关性判断 |
|---|---|
| (0.8,1.0] | 极强相关 |
| (0.6,0.8] | 强相关 |
| (0.4,0.6] | 中等相关 |
| (0.2,0.4] | 弱相关 |
| (0.0,0.2] | 极弱相关 |
表2 Pearson判断相关性
Tab. 2 Pearson determining correlation
| Pearson系数 | 相关性判断 |
|---|---|
| (0.8,1.0] | 极强相关 |
| (0.6,0.8] | 强相关 |
| (0.4,0.6] | 中等相关 |
| (0.2,0.4] | 弱相关 |
| (0.0,0.2] | 极弱相关 |

图2 前5种特征参数对应每种存储格式的Pearson
Fig. 2 Pearson for each storage format corresponding to the first five feature parameters
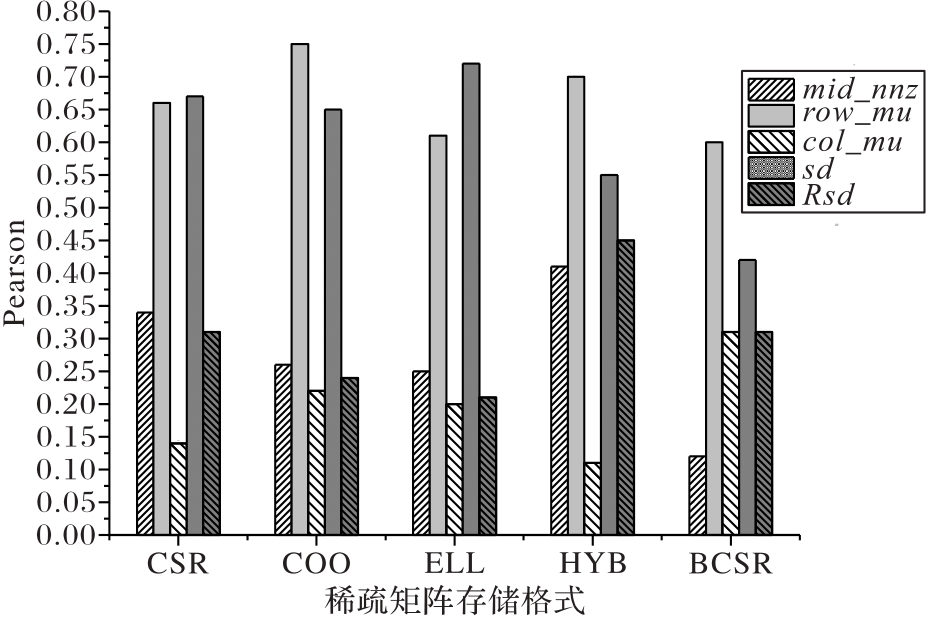
图3 后5种特征参数对应每种存储格式的Pearson
Fig. 3 Pearson for each storage format corresponding to the last five feature parameters

图4 非最优格式相较于最优格式在不同阶段所需时间的比值
Fig. 4 Ratio of time required for non-optimal formats to optimal format at different stages

图5 模型训练过程
Fig. 5 Model training process
| 模型种类 | 不使用网格化搜索 | 使用网格化搜索 |
|---|---|---|
| XGBoost | 85 | 89 |
| LightGBM | 83 | 87 |
表3 模型分类的准确率 ( %)
Tab. 3 Accuracy of model classification
| 模型种类 | 不使用网格化搜索 | 使用网格化搜索 |
|---|---|---|
| XGBoost | 85 | 89 |
| LightGBM | 83 | 87 |

图6 在GPU和CPU上计算GFlops占比更大的存储格式
Fig. 6 Calculating storage formats with larger proportion of GFlops on GPU and CPU

图7 在P100和CPU上计算GFlops占比更大的存储格式
Fig. 7 Calculating storage formats with larger proportion of GFlops on P100 and CPU
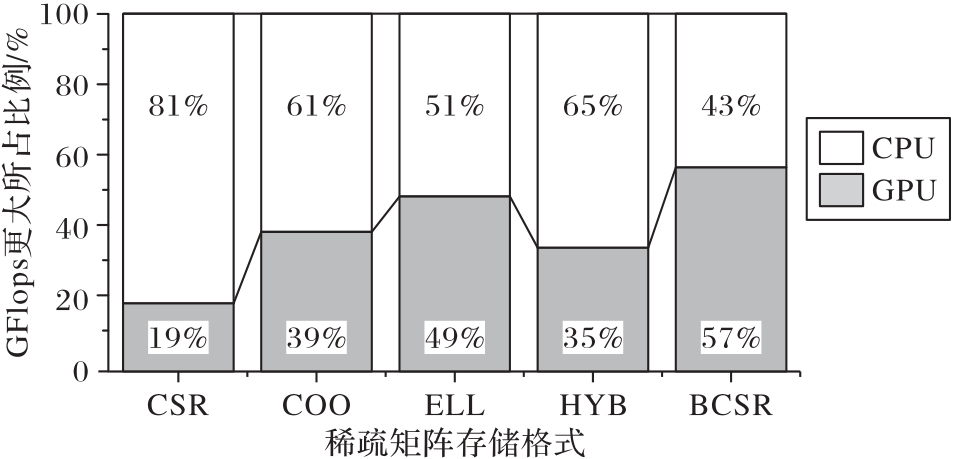
图8 在RTX A5000和CPU上计算GFlops占比更大的存储格式
Fig. 8 Calculating storage formats with larger proportion of GFlops on RTX A5000 and CPU
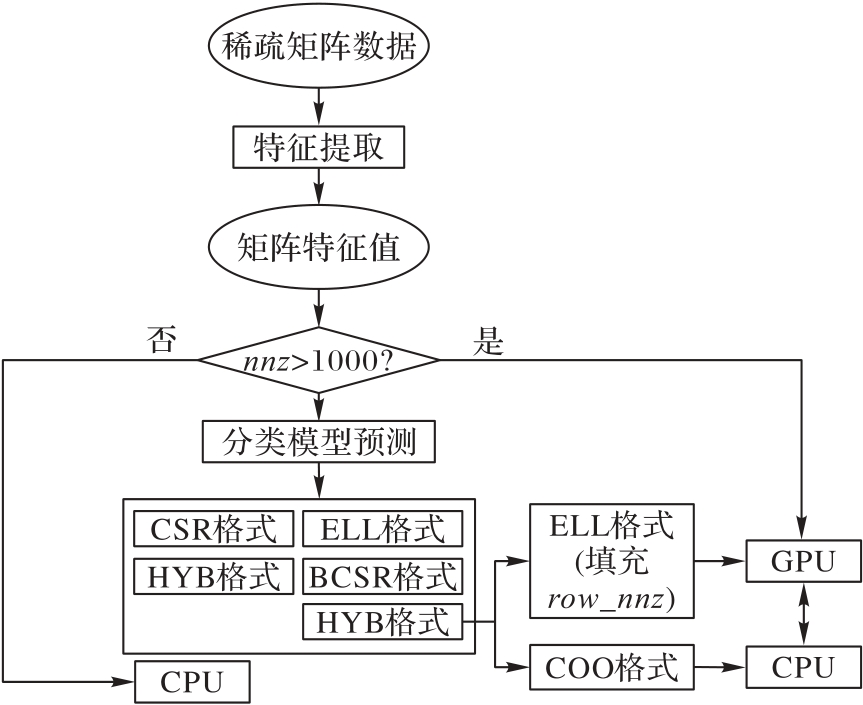
图9 基于异构平台的SpMV自适应计算优化流程
Fig. 9 SpMV adaptive computing optimization process based on heterogeneous platforms
| 性能指标 | cuSPARSE | 自适应 计算优化 | ||
|---|---|---|---|---|
| CSR | HYB | ELL | ||
| GFlops | 20.5 | 13.7 | 11.0 | 28.7 |
| 加速比 | 1.4 | 2.1 | 2.6 | 1.0 |
表4 平均GFlops和加速比
Tab. 4 Average GFlops and speedup ratio
| 性能指标 | cuSPARSE | 自适应 计算优化 | ||
|---|---|---|---|---|
| CSR | HYB | ELL | ||
| GFlops | 20.5 | 13.7 | 11.0 | 28.7 |
| 加速比 | 1.4 | 2.1 | 2.6 | 1.0 |

图10 不同计算方式下的性能
Fig. 10 Performance under different computing methods
| 稀疏矩阵 | 矩阵维度 | 总非零元数 | 平均行 非零元数 |
|---|---|---|---|
| HB/shercuman2 | 1 080×1 080 | 23 094 | 21.38 |
| SNAP/ sx-askubuntu | 159 316×159 316 | 3.75 | |
| MathWorks/Sieber | 2 290×2 290 | 6.49 | |
| DIMACS10/delaunay_n11 | 2 048×2 048 | 12 254 | 5.98 |
| HB/nos4 | 100×100 | 594 | 5.94 |
表5 稀疏矩阵参数
Tab. 5 Sparse matrix parameters
| 稀疏矩阵 | 矩阵维度 | 总非零元数 | 平均行 非零元数 |
|---|---|---|---|
| HB/shercuman2 | 1 080×1 080 | 23 094 | 21.38 |
| SNAP/ sx-askubuntu | 159 316×159 316 | 3.75 | |
| MathWorks/Sieber | 2 290×2 290 | 6.49 | |
| DIMACS10/delaunay_n11 | 2 048×2 048 | 12 254 | 5.98 |
| HB/nos4 | 100×100 | 594 | 5.94 |

图11 不同计算方式下各稀疏矩阵的GFlops
Fig. 11 GFlops of sparse matrices under different computing methods

图12 不同阶段用时占总时间的比例
Fig. 12 Proportions of time spent in different stages to total time
| 存储格式 | CSR | ELL | HYB | BCSR |
|---|---|---|---|---|
| P100 | 1.1 | 2.0 | 1.7 | 2.4 |
| RTX A500 | 1.7 | 1.8 | 2.8 | 2.2 |
表6 在另外2种架构下的加速比
Tab. 6 Speedup ratios under other two architectures
| 存储格式 | CSR | ELL | HYB | BCSR |
|---|---|---|---|---|
| P100 | 1.1 | 2.0 | 1.7 | 2.4 |
| RTX A500 | 1.7 | 1.8 | 2.8 | 2.2 |
| 1 | LI K, YANG W, LI K. Performance analysis and optimization for SpMV on GPU using probabilistic modeling [J]. IEEE Transactions on Parallel and Distributed Systems, 2015, 26(1): 196-205. |
| 2 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. [2023-11-20].. |
| 3 | CHEN J, MA T, XIAO C. FastGCN: fast learning with graph convolutional networks via importance sampling[EB/OL]. (2018-01-30) [2023-11-20].. |
| 4 | 盛伟,王保云,何苗,等. 基于评分相似性的群稀疏矩阵分解推荐算法[J]. 计算机应用, 2017, 37(5): 1397-1401. |
| SHENG W, WANG B Y, HE M, et al. Score similarity based matrix factorization recommendation algorithm with group sparsity[J]. Journal of Computer Applications, 2017, 37(5): 1397-1401. | |
| 5 | MUHAMMED T, MEHMOOD R, ALBESHRI A, et al. SURAA: a novel method and tool for load balanced and coalesced SpMV computations on GPUs[J]. Applied Sciences, 2019, 9(5): No.947. |
| 6 | CUI H, WANG N, WANG Y, et al. An effective SPMV based on block strategy and hybrid compression on GPU [J]. The Journal of Supercomputing, 2022, 78(5): 6318-6339. |
| 7 | CHU G, HE Y, DONG L, et al. Efficient algorithm design of optimizing SpMV on GPU[C]// Proceedings of the 32nd International Symposium on High-Performance Parallel and Distributed Computing. New York: ACM, 2023: 115-128. |
| 8 | DU Y, HU Y, ZHOU Z, et al. High-performance sparse linear algebra on HBM-equipped FPGAs using HLS: a case study on SpMV[C]// Proceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. New York: ACM, 2022: 54-64. |
| 9 | AHMED M, USMAN S, SHAH N A, et al. AAQAL: a machine learning-based tool for performance optimization of parallel SPMV computations using block CSR[J]. Applied Sciences, 2022, 12(14): No.7073. |
| 10 | GUO P, ZHANG C. Performance prediction for CSR-based SpMV on GPUs using machine learning [C]// Proceedings of the IEEE 4th International Conference on Computer and Communications. Piscataway: IEEE, 2018: 1956-1960. |
| 11 | GROSSMAN M, THIELE C, ARAYA-POLO M, et al. A survey of sparse matrix-vector multiplication performance on large matrices[EB/OL]. [2023-11-20].. |
| 12 | NIU Y, LU Z, DONG M, et al. TileSpMV: a tiled algorithm for sparse matrix-vector multiplication on GPUs [C]// Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE, 2021: 68-78. |
| 13 | LI Y, XIE P, CHEN X, et al. VBSF: a new storage format for SIMD sparse matrix-vector multiplication on modern processors[J]. The Journal of Supercomputing, 2020, 76(3): 2063-2081. |
| 14 | BIAN H, HUANG J, DONG R, et al. CSR2: a new format for SIMD-accelerated SpMV [C]// Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing. Piscataway: IEEE, 2020: 350-359. |
| 15 | LIU W, VINTER B. CSR5: an efficient storage format for cross-platform sparse matrix-vector multiplication [C]// Proceedings of the 29th ACM International Conference on Supercomputing. New York: ACM, 2015: 339-350. |
| 16 | KOURTIS K, KARAKASIS V, GOUMAS G, et al. CSX: an extended compression format for SpMV on shared memory systems[J]. ACM SIGPLAN Notices, 2011, 46(8): 247-256. |
| 17 | BENATIA A, JI W, WANG Y, et al. BestSF: a sparse meta-format for optimizing SpMV on GPU [J]. ACM Transactions on Architecture and Code Optimization, 2018, 15(3): No.29. |
| 18 | OLIVER J, AYGUADÉE, MARTORELL X, et al. b8c: an FPGA-friendly sparse matrix representation suitable for the SpMV kernel [C]// Proceedings of the 9th BSC Doctoral Symposium. [S.l.]: Barcelona Supercomputing Center, 2022: 70-71. |
| 19 | PAGE B A, KOGGE P M. Scalability of Sparse Matrix dense Vector multiply (SpMV) on a migrating thread architecture [C]// Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops. Piscataway: IEEE, 2020: 483-488. |
| 20 | MERRILL D, GARLAND M. Merge-based Sparse Matrix-Vector multiplication (SpMV) using the CSR storage format [J]. ACM SIGPLAN Notices, 2016, 51(8): No.43. |
| 21 | GUO P, WANG L. Accurate cross-architecture performance modeling for Sparse Matrix-Vector multiplication (SpMV) on GPUs[J]. Concurrency and Computation: Practice and Experience, 2015, 27(13): 3281-3294. |
| 22 | 张健飞,沈德飞. 基于GPU的稀疏线性系统的预条件共轭梯度法[J]. 计算机应用, 2013, 33(3): 825-829. |
| ZHANG J F, SHEN D F. GPU-based preconditioned conjugate gradient method for solving sparse linear systems[J]. Journal of Computer Applications, 2013, 33(3): 825-829. | |
| 23 | 杨鹏,赵辉,鲍忠贵. 基于双十字链表存储的共享资源矩阵方法特性研究[J]. 计算机应用, 2016, 36(3): 653-656. |
| YANG P, ZHAO H, BAO Z G. Research on properties of shared resource matrix method based on double cross linked list [J]. Journal of Computer Applications, 2016, 36(3): 653-656. | |
| 24 | FURUHATA R, ZHAO M, AGUNG M, et al. Improving the accuracy in SpMV implementation selection with machine learning[C]// Proceedings of the 8th International Symposium on Computing and Networking Workshops. Piscataway: IEEE, 2020: 172-177. |
| 25 | ANZT H, TOMOV S, DONGARRA J. On the performance and energy efficiency of sparse linear algebra on GPUs [J]. The International Journal of High Performance Computing Applications, 2017, 31(5): 375-390. |
| 26 | DAGA M, GREATHOUSE J L. Structural agnostic SpMV: adapting CSR-adaptive for irregular matrices [C]// Proceedings of the IEEE 22nd International Conference on High Performance Computing. Piscataway: IEEE, 2015: 64-74. |
| 27 | DANG H V, SCHMIDT B. The sliced COO format for sparse matrix-vector multiplication on CUDA-enabled GPUs [J]. Procedia Computer Science, 2012, 9: 57-66. |
| 28 | ZHANG Y, YANG W, LI K, et al. Performance analysis and optimization for SpMV based on aligned storage formats on an ARM processor[J]. Journal of Parallel and Distributed Computing, 2021, 158: 126-137. |
| 29 | KARAKASIS V, GOUMAS G, KOZIRIS N. Exploring the effect of block shapes on the performance of sparse kernels[C]// Proceedings of the 2009 IEEE International Symposium on Parallel and Distributed Processing. Piscataway: IEEE, 2009: 1-8. |
| 30 | PAGE B A, KOGGE P M. Scalability of hybrid Sparse Matrix dense Vector (SpMV) multiplication [C]// Proceedings of the 2018 International Conference on High Performance Computing and Simulation. Piscataway: IEEE, 2018: 406-414. |
| 31 | KOLODZIEJ S P, AZNAVEH M, BULLOCK M, et al. The SuiteSparse matrix collection website interface [J]. Journal of Open Source Software, 2019, 4(35): 1244. |
| 32 | BENESTY J, CHEN J, HUANG Y, et al. Pearson correlation coefficient [M]// COHEN I, HUANG Y, CHEN J, et al. Noise reduction in speech processing. Berlin: Springer, 2009: 1-4. |
| 33 | 惠子薇,何坤,冯犇,等. 基于视觉特性的图像质量评价[J]. 计算机工程, 2023, 49(7): 189-195. |
| HUI Z W, HE K, FENG B, et al. Image quality assessment based on visual characteristics[J]. Computer Engineering, 2023, 49(7): 189-195. | |
| 34 | LIANG W, LUO S, ZHAO G, et al. Predicting hard rock pillar stability using GBDT, XGBoost, and LightGBM algorithms [J]. Mathematics, 2020, 8(5): No.765. |
| 35 | CHEN T, HE T, BENESTY M, et al. XGBoost: extreme gradient boosting [EB/OL]. [2023-12-02].. |
| 36 | KE G, MENG Q, FINLEY T, et al. LightGBM: a highly efficient gradient boosting decision tree[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 3149-3157. |
| 37 | SHUAI Y, ZHENG Y, HUANG H. Hybrid software obsolescence evaluation model based on PCA-SVM-GridSearchCV[C]// Proceedings of the IEEE 9th International Conference on Software Engineering and Service Science. Piscataway: IEEE, 2018: 449-453. |
| 38 | CAO T T, TANG K, MOHAMED A, et al. Parallel banding algorithm to compute exact distance transform with the GPU [C]// Proceedings of the 2010 ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games. New York: ACM, 2010: 83-90. |
| [1] | 雷明珠, 王浩, 贾蓉, 白琳, 潘晓英. 基于特征间关系合成少数类样本的过采样算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1428-1436. |
| [2] | 杨成昊, 胡节, 王红军, 彭博. 基于注意力机制的不完备多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3784-3789. |
| [3] | 涂进兴, 李志雄, 黄建强. 基于GPU对角稀疏矩阵向量乘法的动态划分算法[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3521-3529. |
| [4] | 包银鑫, 曹阳, 施佺. 基于改进时空残差卷积神经网络的城市路网短时交通流预测[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 258-264. |
| [5] | 祝承, 赵晓琦, 赵丽萍, 焦玉宏, 朱亚飞, 陈建英, 周伟, 谭颖. 基于谱聚类半监督特征选择的功能磁共振成像数据分类[J]. 计算机应用, 2021, 41(8): 2288-2293. |
| [6] | 高媛, 王淑敏, 孙建飞. 基于用户兴趣相似性的节点移动模型[J]. 计算机应用, 2015, 35(9): 2457-2460. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||