


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (1): 337-344.DOI: 10.11772/j.issn.1001-9081.2024010066
• 前沿与综合应用 • 上一篇
缪孜珺, 罗飞( ), 丁炜超, 董文波
), 丁炜超, 董文波
收稿日期:2024-01-19
修回日期:2024-03-15
接受日期:2024-03-25
发布日期:2024-05-09
出版日期:2025-01-10
通讯作者:
罗飞
作者简介:缪孜珺(1999—),男,浙江宁波人,硕士研究生,主要研究方向:强化学习;基金资助:
Zijun MIAO, Fei LUO(), Weichao DING, Wenbo DONG
Received:2024-01-19
Revised:2024-03-15
Accepted:2024-03-25
Online:2024-05-09
Published:2025-01-10
Contact:
Fei LUO
About author:MIAO Zijun, born in 1999, M. S. candidate. His research interests include reinforcement learning.Supported by:摘要:
为了应对交通拥堵而设计的高效交通信号控制算法能提升现有交通网络下的车辆通行效率。尽管深度强化学习算法在单路口交通信号控制问题上已展现出卓越的性能,然而这些算法在多路口环境下的应用仍然面临着重大的挑战——多智能体强化学习(MARL)算法产生的时间和空间的部分可观测性引发的非平稳性问题会导致这些算法无法稳定的收敛。因此,提出一种基于全局状态预测与公平经验重放的多路口交通信号控制算法IS-DQN。一方面,基于不同车道的车流历史信息预测多路口的全局状态,从而扩展IS-DQN的状态空间,以避免算法产生空间部分可观测性而带来非平稳性问题;另一方面,为应对传统经验重放策略的时间部分可观测性,采用蓄水池抽样算法来保证经验重放池的公正性,进而避免其中的非平稳性问题。在复杂的多路口环境下应用IS-DQN算法进行3种不同的交通压力仿真实验的结果表明:在不同交通流情况下,尤其是在中低交通流量下,相较于独立的深度强化学习算法,IS-DQN算法能得到更短的车辆平均行驶时间,并表现出了更优的收敛性能与收敛稳定性。
中图分类号:
缪孜珺, 罗飞, 丁炜超, 董文波. 基于全局状态预测与公平经验重放的交通信号控制算法[J]. 计算机应用, 2025, 45(1): 337-344.
Zijun MIAO, Fei LUO, Weichao DING, Wenbo DONG. Traffic signal control algorithm based on overall state prediction and fair experience replay[J]. Journal of Computer Applications, 2025, 45(1): 337-344.
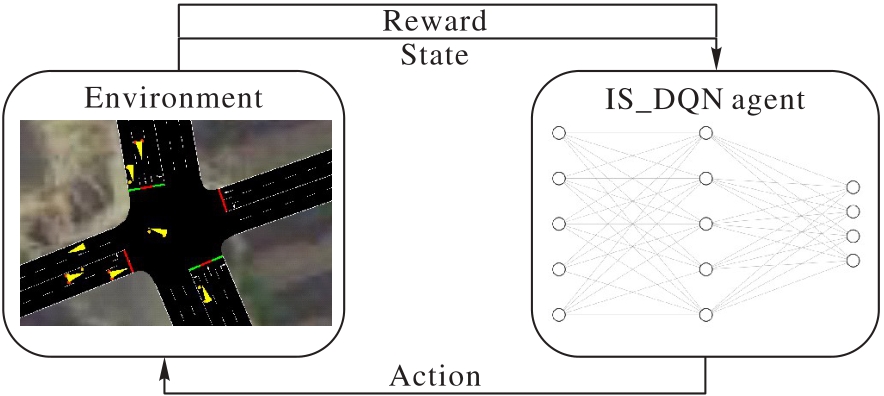
图1 交通信号控制问题MDP过程
Fig. 1 MDP process of traffic signal control problem
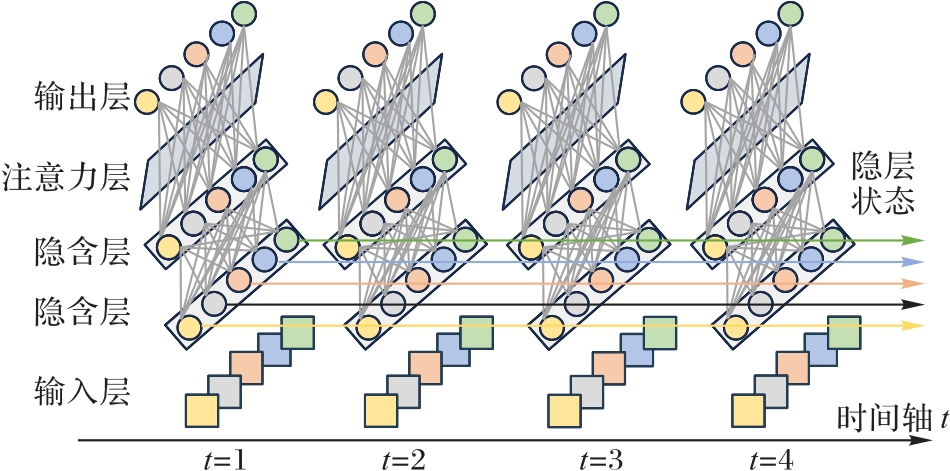
图2 IS-DQN算法中的预测网络结构
Fig. 2 Structure of prediction network in IS-DQN algorithm
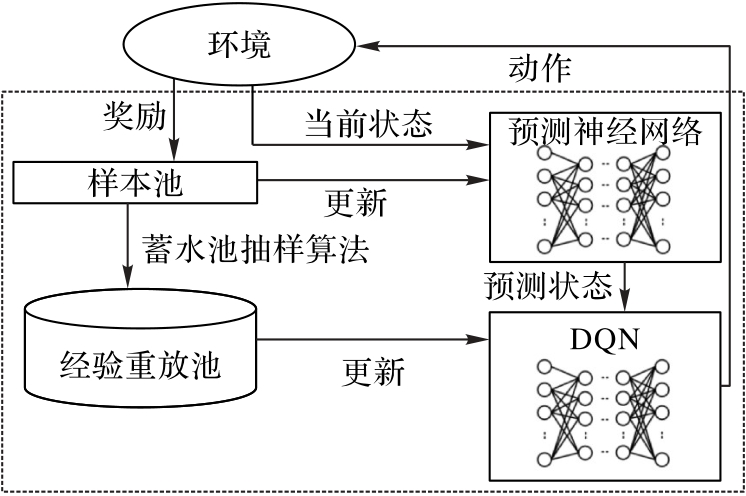
图3 IS-DQN算法的整体交互流程
Fig. 3 Overall interaction flow of IS-DQN algorithm

图4 多路口测试环境仿真图
Fig. 4 Simulation diagram of multi-intersection test environment
| 算法 | 超参数 | 值 | 含义 |
|---|---|---|---|
| FixTime | 80 | 相位周期 | |
| MaxPressure | 5 | 最小绿灯时间 | |
| SOTL | 2 | 最小绿灯时间 | |
| 4 | 车辆数阈值 | ||
| 28 | 绿灯车辆数阈值 |
表1 经典算法的超参数设置
Tab. 1 Hyperparameter setting of classical algorithms
| 算法 | 超参数 | 值 | 含义 |
|---|---|---|---|
| FixTime | 80 | 相位周期 | |
| MaxPressure | 5 | 最小绿灯时间 | |
| SOTL | 2 | 最小绿灯时间 | |
| 4 | 车辆数阈值 | ||
| 28 | 绿灯车辆数阈值 |
| 交通压力 | 路口编号 | IS-DQN | DQN | DQN-PS | DQN-ER | FixTime | MaxPressure | SOTL |
|---|---|---|---|---|---|---|---|---|
| 低流量 | 路口1 | 92.520 | 103.638 | 93.750 | 98.904 | 285.387 | 143.212 | 148.432 |
| 路口2 | 85.072 | 93.101 | 85.771 | 89.633 | 279.508 | 126.871 | 128.802 | |
| 路口3 | 73.975 | 83.960 | 74.444 | 82.593 | 272.065 | 109.183 | 109.260 | |
| 路口4 | 94.085 | 99.426 | 94.440 | 98.913 | 400.112 | 152.070 | 162.543 | |
| 路口5 | 95.291 | 99.374 | 94.877 | 96.614 | 349.340 | 140.418 | 149.679 | |
| 路口6 | 74.085 | 81.204 | 74.266 | 80.416 | 345.519 | 118.796 | 146.500 | |
| 中流量 | 路口1 | 112.058 | 121.691 | 114.467 | 117.215 | 244.768 | 156.211 | 163.154 |
| 路口2 | 106.165 | 116.094 | 108.171 | 109.196 | 216.307 | 141.574 | 153.677 | |
| 路口3 | 85.988 | 94.483 | 88.368 | 96.213 | 225.756 | 117.185 | 165.453 | |
| 路口4 | 124.960 | 141.970 | 126.198 | 135.349 | 289.689 | 171.429 | 204.084 | |
| 路口5 | 108.599 | 113.521 | 110.960 | 115.294 | 286.784 | 143.639 | 178.838 | |
| 路口6 | 91.078 | 107.781 | 92.318 | 100.988 | 258.487 | 135.075 | 206.624 | |
| 高流量 | 路口1 | 129.778 | 128.808 | 127.764 | 131.759 | 276.707 | 166.963 | 146.500 |
| 路口2 | 125.551 | 123.464 | 124.294 | 131.589 | 208.357 | 149.933 | 162.850 | |
| 路口3 | 107.029 | 109.390 | 114.653 | 114.301 | 201.837 | 124.199 | 173.341 | |
| 路口4 | 164.431 | 161.762 | 161.873 | 166.006 | 336.926 | 188.821 | 200.651 | |
| 路口5 | 118.135 | 117.691 | 121.091 | 121.621 | 388.053 | 148.797 | 163.518 | |
| 路口6 | 130.814 | 141.184 | 130.136 | 133.617 | 242.165 | 145.862 | 197.414 |
表2 不同算法在不同交通压力下优化后的平均行驶时间 ( s)
Tab. 2 Average driving time optimized by different algorithms under different traffic pressure
| 交通压力 | 路口编号 | IS-DQN | DQN | DQN-PS | DQN-ER | FixTime | MaxPressure | SOTL |
|---|---|---|---|---|---|---|---|---|
| 低流量 | 路口1 | 92.520 | 103.638 | 93.750 | 98.904 | 285.387 | 143.212 | 148.432 |
| 路口2 | 85.072 | 93.101 | 85.771 | 89.633 | 279.508 | 126.871 | 128.802 | |
| 路口3 | 73.975 | 83.960 | 74.444 | 82.593 | 272.065 | 109.183 | 109.260 | |
| 路口4 | 94.085 | 99.426 | 94.440 | 98.913 | 400.112 | 152.070 | 162.543 | |
| 路口5 | 95.291 | 99.374 | 94.877 | 96.614 | 349.340 | 140.418 | 149.679 | |
| 路口6 | 74.085 | 81.204 | 74.266 | 80.416 | 345.519 | 118.796 | 146.500 | |
| 中流量 | 路口1 | 112.058 | 121.691 | 114.467 | 117.215 | 244.768 | 156.211 | 163.154 |
| 路口2 | 106.165 | 116.094 | 108.171 | 109.196 | 216.307 | 141.574 | 153.677 | |
| 路口3 | 85.988 | 94.483 | 88.368 | 96.213 | 225.756 | 117.185 | 165.453 | |
| 路口4 | 124.960 | 141.970 | 126.198 | 135.349 | 289.689 | 171.429 | 204.084 | |
| 路口5 | 108.599 | 113.521 | 110.960 | 115.294 | 286.784 | 143.639 | 178.838 | |
| 路口6 | 91.078 | 107.781 | 92.318 | 100.988 | 258.487 | 135.075 | 206.624 | |
| 高流量 | 路口1 | 129.778 | 128.808 | 127.764 | 131.759 | 276.707 | 166.963 | 146.500 |
| 路口2 | 125.551 | 123.464 | 124.294 | 131.589 | 208.357 | 149.933 | 162.850 | |
| 路口3 | 107.029 | 109.390 | 114.653 | 114.301 | 201.837 | 124.199 | 173.341 | |
| 路口4 | 164.431 | 161.762 | 161.873 | 166.006 | 336.926 | 188.821 | 200.651 | |
| 路口5 | 118.135 | 117.691 | 121.091 | 121.621 | 388.053 | 148.797 | 163.518 | |
| 路口6 | 130.814 | 141.184 | 130.136 | 133.617 | 242.165 | 145.862 | 197.414 |

图5 各算法在低交通流量下的收敛过程
Fig. 5 Convergence process of each algorithm under low traffic flow
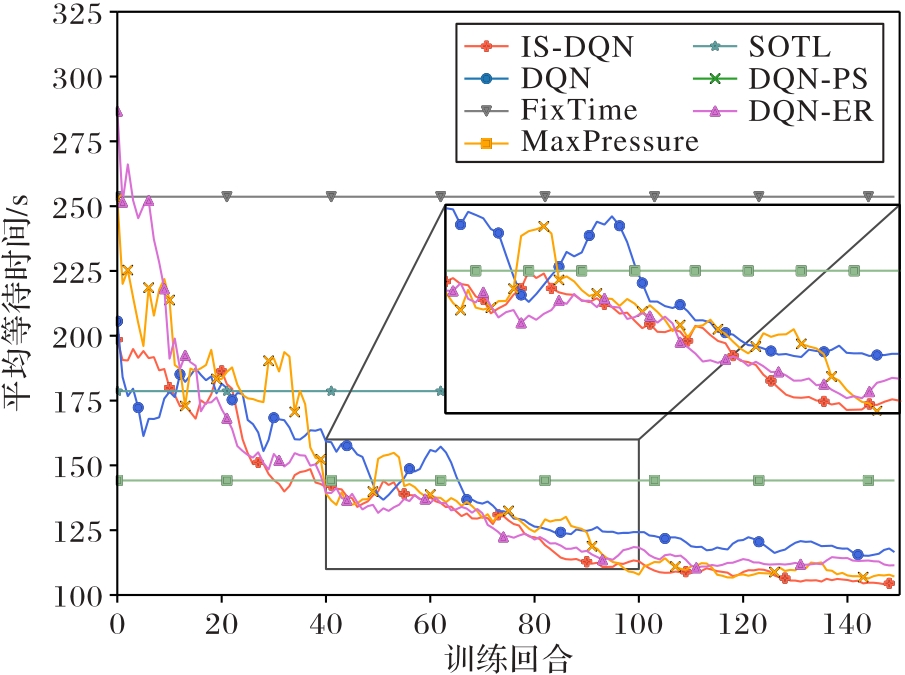
图6 各算法在中交通流量下的收敛过程
Fig. 6 Convergence process of each algorithm under medium traffic flow

图7 各算法在高交通流量下的收敛过程
Fig. 7 Convergence process of each algorithm under high traffic flow
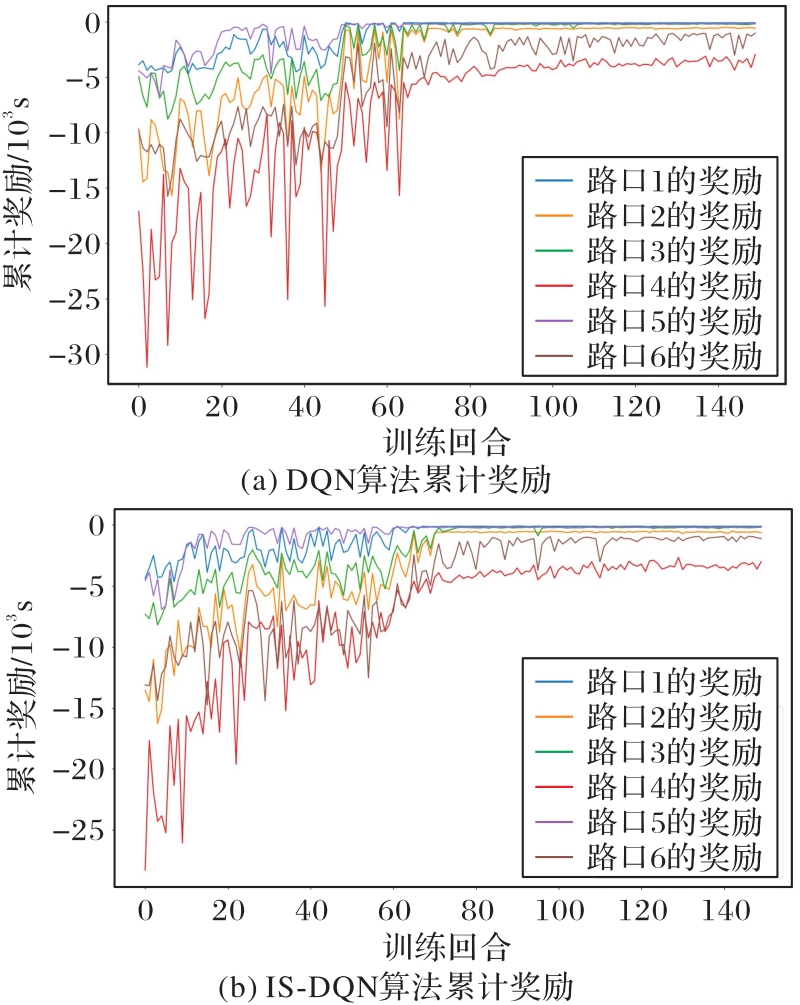
图8 DQN与IS-DQN算法在中交通流量下的累计奖励
Fig. 8 Cumulative rewards of DQN and IS-DQN algorithms under medium traffic flow
| 1 | KŐVÁRI B, KOLAT M, BÉCSI T, et al. Competitive multi-agent reinforcement learning for traffic signal control [C]// Proceedings of the IEEE 20th Jubilee International Symposium on Intelligent Systems and Informatics. Piscataway: IEEE, 2022: 361-366. |
| 2 | NOAEEM M, NAIK A, GOODMAN L, et al. Reinforcement learning in urban network traffic signal control: a systematic literature review [J]. Expert Systems with Applications, 2022, 199: No.116830. |
| 3 | MA D, XIAO J, SONG X, et al. A back-pressure-based model with fixed phase sequences for traffic signal optimization under oversaturated networks [J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(9): 5577-5588. |
| 4 | DUCROCQ R, FARHI N. Deep reinforcement Q-learning for intelligent traffic signal control with partial detection [J]. International Journal of Intelligent Transportation Systems Research, 2023, 21(1): 192-206. |
| 5 | HAN G, LIU X, WANG H, et al. An attention reinforcement learning-based strategy for large-scale adaptive traffic signal control system [J]. Journal of Transportation Engineering, Part A: Systems, 2024, 150(3): No.04024001. |
| 6 | YAZDANI M, SARVI M, BAGLOEE S A, et al. Intelligent Vehicle Pedestrian Light (IVPL): a deep reinforcement learning approach for traffic signal control [J]. Transportation Research Part C: Emerging Technologies, 2023, 149: No.103991. |
| 7 | ZHU R, LI L, WU S, et al. Multi-agent broad reinforcement learning for intelligent traffic light control [J]. Information Sciences, 2023, 619: 509-525. |
| 8 | KOLAT M, KŐVÁRI B, BÉCSI T, et al. Multi-agent reinforcement learning for traffic signal control: a cooperative approach [J]. Sustainability, 2023, 15(4): No.3479. |
| 9 | ZHANG K, YANG Z, BAŞAR T. Multi-agent reinforcement learning: a selective overview of theories and algorithms [M]// VAMVOUDAKIS K G, WAN Y, LEWIS F L, et al. Handbook of reinforcement learning and control, SSDC 325. Cham: Springer, 2021: 321-384. |
| 10 | YANG S. Hierarchical graph multi-agent reinforcement learning for traffic signal control [J]. Information Sciences, 2023, 634: 55-72. |
| 11 | YANG S, YANG B. An inductive heterogeneous graph attention-based multi-agent deep graph infomax algorithm for adaptive traffic signal control [J]. Information Fusion, 2022, 88: 249-262. |
| 12 | ZHAO Z, WANG K, WANG Y, et al. Enhancing traffic signal control with composite deep intelligence [J]. Expert Systems with Applications, 2024, 244: No.123020. |
| 13 | GUO J, CHENG L, WANG S. CoTV: cooperative control for traffic light signals and connected autonomous vehicles using deep reinforcement learning [J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(10): 10501-10512. |
| 14 | REN F, DONG W, ZHAO X, et al. Two-layer coordinated reinforcement learning for traffic signal control in traffic network [J]. Expert Systems with Applications, 2024, 235: No.121111. |
| 15 | BOKADE R, JIN X, AMATO C. Multi-agent reinforcement learning based on representational communication for large-scale traffic signal control [J]. IEEE Access, 2023, 11: 47646-47658. |
| 16 | FANG J, YOU Y, XU M, et al. Multi-objective traffic signal control using network-wide agent coordinated reinforcement learning [J]. Expert Systems with Applications, 2023, 229(Pt A): No.120535. |
| 17 | STONE P, KAMINKA G A, KRAUS S, et al. Ad hoc autonomous agent teams: collaboration without pre-coordination [C]// Proceedings of the 24th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2010: 1504-1509. |
| 18 | GMYTRASIEWICZ P J, DOSHI P. A framework for sequential planning in multi-agent settings [J]. Journal of Artificial Intelligence Research, 2005, 24: 49-79. |
| 19 | HERNANDEZ-LEAL P, KAISERS M, BAARSLAG T, et al. A survey of learning in multiagent environments: dealing with non-stationarity [EB/OL]. [2023-08-10]. . |
| 20 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay [EB/OL]. [2023-08-03]. . |
| 21 | TESAURO G. Extending Q-learning to general adaptive multi-agent systems [C]// Proceedings of the 16th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2003: 871-878. |
| 22 | ABBASIMEHR H, PAKI R. Improving time series forecasting using LSTM and attention models [J]. Journal of Ambient Intelligence and Humanized Computing, 2022, 13(1): 673-691. |
| 23 | TANG Z, NAPHADE M, LIU M Y, et al. CityFlow: a city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8789-8798. |
| 24 | ZHENG G, XIONG Y, ZANG X, et al. Learning phase competition for traffic signal control [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 1963-1972. |
| 25 | COOLS S B, GERSHENSON C, D’HOOGHE B. Self-organizing traffic lights: a realistic simulation [M]// PROKOPENKO M. Advances in applied self-organizing systems, AI&KP. London: Springer, 2013: 45-55. |
| 26 | LEVIN M W. Max-Pressure traffic signal timing: a summary of methodological and experimental results [J]. Journal of Transportation Engineering, Part A: Systems, 2023, 149(4): No.7578. |
| [1] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [2] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [3] | 周毅, 高华, 田永谌. 基于裁剪优化和策略指导的近端策略优化算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2334-2341. |
| [4] | 田润泽, 周宇龙, 朱洪, 薛岗. 基于局部信息的服务迁移路径选择算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2168-2174. |
| [5] | 马天, 席润韬, 吕佳豪, 曾奕杰, 杨嘉怡, 张杰慧. 基于深度强化学习的移动机器人三维路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2055-2064. |
| [6] | 徐泽鑫, 杨磊, 李康顺. 较短的长序列时间序列预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1824-1831. |
| [7] | 吕锡婷, 赵敬华, 荣海迎, 赵嘉乐. 基于Transformer和关系图卷积网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1760-1766. |
| [8] | 赵晓焱, 韩威, 张俊娜, 袁培燕. 基于异步深度强化学习的车联网协作卸载策略[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1501-1510. |
| [9] | 唐睿, 庞川林, 张睿智, 刘川, 岳士博. D2D通信增强的蜂窝网络中基于DDPG的资源分配[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1562-1569. |
| [10] | 秦鑫彤, 宋政育, 侯天为, 王飞越, 孙昕, 黎伟. 基于自适应p持续的移动自组网信道接入和资源分配算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 863-868. |
| [11] | 李源潮, 陶重犇, 王琛. 基于最大熵深度强化学习的双足机器人步态控制方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 445-451. |
| [12] | 罗歆然, 李天瑞, 贾真. 基于自注意力机制与词汇增强的中文医学命名实体识别[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 385-392. |
| [13] | 邓辅秦, 官桧锋, 谭朝恩, 付兰慧, 王宏民, 林天麟, 张建民. 基于请求与应答通信机制和局部注意力机制的多机器人强化学习路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 432-438. |
| [14] | 余家宸, 杨晔. 基于裁剪近端策略优化算法的软机械臂不规则物体抓取[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3629-3638. |
| [15] | 花晓雨, 李冬芬, 付优, 毕可骏, 应时, 王瑞锦. 结合层次图神经网络与长短期记忆的产业链风险评估预警模型[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3223-3231. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||