


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 963-971.DOI: 10.11772/j.issn.1001-9081.2024040443
党伟超, 范英豪( ), 高改梅, 刘春霞
), 高改梅, 刘春霞
收稿日期:2024-04-12
修回日期:2024-06-25
接受日期:2024-06-28
发布日期:2025-03-17
出版日期:2025-03-10
通讯作者:
范英豪
作者简介:党伟超(1974—),男,山西运城人,副教授,博士,CCF会员,主要研究方向:智能计算、软件可靠性基金资助:
Weichao DANG, Yinghao FAN(), Gaimei GAO, Chunxia LIU
Received:2024-04-12
Revised:2024-06-25
Accepted:2024-06-28
Online:2025-03-17
Published:2025-03-10
Contact:
Yinghao FAN
About author:DANG Weichao, born in 1974, Ph. D., associate professor. His research interests include intelligent computing, software reliability.Supported by:摘要:
针对现有的弱监督动作定位研究中将视频片段视为单独动作实例独立处理带来的动作分类及定位不准确问题,提出一种融合时序与全局上下文特征增强的弱监督动作定位方法。首先,构建时序特征增强分支以利用膨胀卷积扩大感受野,并引入注意力机制捕获视频片段间的时序依赖性;其次,设计基于高斯混合模型(GMM)的期望最大化(EM)算法捕获视频的上下文信息,同时利用二分游走传播进行全局上下文特征增强,生成高质量的时序类激活图(TCAM)作为伪标签在线监督时序特征增强分支;再次,通过动量更新网络得到体现视频间动作特征的跨视频字典;最后,利用跨视频对比学习提高动作分类的准确性。实验结果表明,交并比(IoU)取0.5时,所提方法在THUMOS’14和ActivityNet v1.3数据集上分别取得了42.0%和42.2%的平均精度均值(mAP),相较于CCKEE (Cross-video Contextual Knowledge Exploration and Exploitation)方法,在mAP分别提升了2.6与0.6个百分点,验证了所提方法的有效性。
中图分类号:
党伟超, 范英豪, 高改梅, 刘春霞. 融合时序与全局上下文特征增强的弱监督动作定位[J]. 计算机应用, 2025, 45(3): 963-971.
Weichao DANG, Yinghao FAN, Gaimei GAO, Chunxia LIU. Weakly supervised action localization based on temporal and global contextual feature enhancement[J]. Journal of Computer Applications, 2025, 45(3): 963-971.
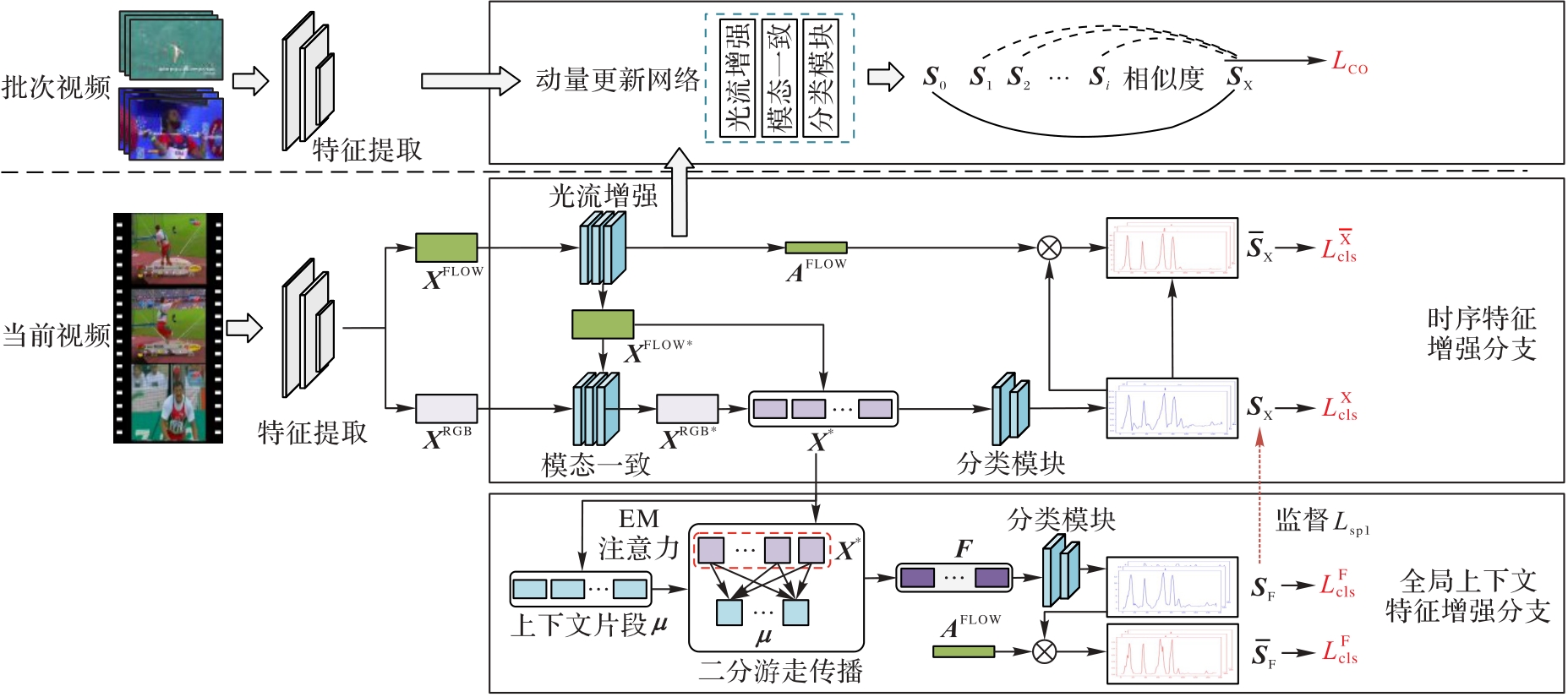
图1 本文模型的整体框架
Fig. 1 Overall framework of proposed model

图2 光流增强模块
Fig. 2 Optical flow enhancement module

图3 模态一致模块
Fig. 3 Modal consistency module

图4 EM注意力与二分游走传播
Fig. 4 EM attention and binary walk propagation

图5 动量更新网络
Fig. 5 Momentum update network
| IoU | mAP/% | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W-TALC | A2CL-PT | FAC-Net | CoLA | AUMN | DCC | BasNet | D2-Net | ASM-Loc | TBUPL | P-MIL | DTRP-Loc | CCKEE | 本文方法 | |
| 平均 | 34.4 | 37.8 | 42.2 | 40.9 | 41.5 | 44.0 | 35.3 | 51.5 | 45.1 | 43.4 | 47.1 | 47.0 | 46.8 | 48.0 |
| 0.1 | 55.2 | 61.2 | 67.6 | 66.2 | 66.2 | 69.0 | 58.2 | 65.7 | 71.2 | 70.5 | 71.8 | 71.4 | 72.6 | 73.1 |
| 0.2 | 49.6 | 56.1 | 62.1 | 59.5 | 61.9 | 63.8 | 52.3 | 60.2 | 65.5 | 64.4 | 67.5 | 66.0 | 67.1 | 67.6 |
| 0.3 | 40.1 | 48.1 | 52.6 | 51.5 | 54.9 | 55.9 | 44.6 | 52.3 | 57.1 | 55.2 | 58.9 | 58.0 | 59.5 | 59.6 |
| 0.4 | 31.1 | 39.0 | 44.3 | 41.9 | 44.4 | 45.9 | 36.0 | 43.4 | 46.8 | 44.8 | 49.0 | 49.3 | 49.3 | 50.3 |
| 0.5 | 22.8 | 30.1 | 33.4 | 32.2 | 33.3 | 35.7 | 27.0 | 36.0 | 36.6 | 33.7 | 40.0 | 41.4 | 39.4 | 42.0 |
| 0.6 | — | 19.2 | 22.5 | 22.0 | 20.5 | 24.3 | 18.6 | — | 25.2 | 22.9 | 27.1 | 28.0 | 26.5 | 28.6 |
| 0.7 | 7.6 | 10.6 | 12.7 | 13.1 | 9.0 | 13.7 | 10.4 | — | 13.4 | 12.2 | 15.1 | 15.0 | 13.4 | 14.9 |
表1 不同方法在THUMOS’14数据集上的检测结果
Tab. 1 Detection results of different methods on THUMOS’14 dataset
| IoU | mAP/% | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W-TALC | A2CL-PT | FAC-Net | CoLA | AUMN | DCC | BasNet | D2-Net | ASM-Loc | TBUPL | P-MIL | DTRP-Loc | CCKEE | 本文方法 | |
| 平均 | 34.4 | 37.8 | 42.2 | 40.9 | 41.5 | 44.0 | 35.3 | 51.5 | 45.1 | 43.4 | 47.1 | 47.0 | 46.8 | 48.0 |
| 0.1 | 55.2 | 61.2 | 67.6 | 66.2 | 66.2 | 69.0 | 58.2 | 65.7 | 71.2 | 70.5 | 71.8 | 71.4 | 72.6 | 73.1 |
| 0.2 | 49.6 | 56.1 | 62.1 | 59.5 | 61.9 | 63.8 | 52.3 | 60.2 | 65.5 | 64.4 | 67.5 | 66.0 | 67.1 | 67.6 |
| 0.3 | 40.1 | 48.1 | 52.6 | 51.5 | 54.9 | 55.9 | 44.6 | 52.3 | 57.1 | 55.2 | 58.9 | 58.0 | 59.5 | 59.6 |
| 0.4 | 31.1 | 39.0 | 44.3 | 41.9 | 44.4 | 45.9 | 36.0 | 43.4 | 46.8 | 44.8 | 49.0 | 49.3 | 49.3 | 50.3 |
| 0.5 | 22.8 | 30.1 | 33.4 | 32.2 | 33.3 | 35.7 | 27.0 | 36.0 | 36.6 | 33.7 | 40.0 | 41.4 | 39.4 | 42.0 |
| 0.6 | — | 19.2 | 22.5 | 22.0 | 20.5 | 24.3 | 18.6 | — | 25.2 | 22.9 | 27.1 | 28.0 | 26.5 | 28.6 |
| 0.7 | 7.6 | 10.6 | 12.7 | 13.1 | 9.0 | 13.7 | 10.4 | — | 13.4 | 12.2 | 15.1 | 15.0 | 13.4 | 14.9 |
| IoU | mAP/% | |||||||
|---|---|---|---|---|---|---|---|---|
| AUMN | FAC-Net | DGCNN | DCC | ASM-Loc | P-MIL | CCKEE | 本文方法 | |
| AVG | 23.5 | 24.0 | 23.9 | 24.3 | 25.1 | 25.5 | 25.3 | 25.5 |
| 0.50 | 38.5 | 37.6 | 37.2 | 38.8 | 41.0 | 41.8 | 41.6 | 42.2 |
| 0.75 | 23.5 | 24.2 | 23.8 | 24.2 | 24.9 | 25.4 | 25.1 | 25.3 |
| 0.95 | 5.2 | 6.0 | 5.8 | 5.7 | 6.2 | 5.2 | 6.5 | 6.5 |
表2 不同方法在ActivityNet v1.3数据集上的检测结果
Tab. 2 Detection results of different methods on ActivityNet v1.3 dataset
| IoU | mAP/% | |||||||
|---|---|---|---|---|---|---|---|---|
| AUMN | FAC-Net | DGCNN | DCC | ASM-Loc | P-MIL | CCKEE | 本文方法 | |
| AVG | 23.5 | 24.0 | 23.9 | 24.3 | 25.1 | 25.5 | 25.3 | 25.5 |
| 0.50 | 38.5 | 37.6 | 37.2 | 38.8 | 41.0 | 41.8 | 41.6 | 42.2 |
| 0.75 | 23.5 | 24.2 | 23.8 | 24.2 | 24.9 | 25.4 | 25.1 | 25.3 |
| 0.95 | 5.2 | 6.0 | 5.8 | 5.7 | 6.2 | 5.2 | 6.5 | 6.5 |
| IoU | mAP/% | |||
|---|---|---|---|---|
| 基线 | 时序特征增强 | 全局上下文特征增强 | 动量更新网络 | |
| AVG | 44.3 | 46.5 | 47.6 | 48.1 |
| 0.1 | 69.2 | 72.2 | 73.0 | 73.1 |
| 0.3 | 54.2 | 57.8 | 59.2 | 59.6 |
| 0.5 | 38.4 | 39.7 | 41.0 | 42.0 |
| 0.7 | 12.9 | 13.6 | 14.6 | 14.9 |
表3 不同分支的消融实验结果
Tab. 3 Ablation experimental results of different branches
| IoU | mAP/% | |||
|---|---|---|---|---|
| 基线 | 时序特征增强 | 全局上下文特征增强 | 动量更新网络 | |
| AVG | 44.3 | 46.5 | 47.6 | 48.1 |
| 0.1 | 69.2 | 72.2 | 73.0 | 73.1 |
| 0.3 | 54.2 | 57.8 | 59.2 | 59.6 |
| 0.5 | 38.4 | 39.7 | 41.0 | 42.0 |
| 0.7 | 12.9 | 13.6 | 14.6 | 14.9 |
| 膨胀卷积层数k | IoU | mAP/% | AVG(0.1:0.5)/% |
|---|---|---|---|
| 0 | 0.1 | 71.6 | 56.8 |
| 0.3 | 57.7 | ||
| 0.5 | 40.7 | ||
| 1 | 0.1 | 72.2 | 57.4 |
| 0.3 | 58.0 | ||
| 0.5 | 41.1 | ||
| 2 | 0.1 | 72.9 | 57.6 |
| 0.3 | 57.9 | ||
| 0.5 | 41.3 | ||
| 3 | 0.1 | 73.1 | 58.5 |
| 0.3 | 59.6 | ||
| 0.5 | 42.0 | ||
| 4 | 0.1 | 72.7 | 57.2 |
| 0.3 | 57.6 | ||
| 0.5 | 40.8 |
表4 光流增强模块中不同膨胀卷积层数的消融实验结果
Tab. 4 Ablation experimental results of different dilated convolutional layers in optical flow enhancement module
| 膨胀卷积层数k | IoU | mAP/% | AVG(0.1:0.5)/% |
|---|---|---|---|
| 0 | 0.1 | 71.6 | 56.8 |
| 0.3 | 57.7 | ||
| 0.5 | 40.7 | ||
| 1 | 0.1 | 72.2 | 57.4 |
| 0.3 | 58.0 | ||
| 0.5 | 41.1 | ||
| 2 | 0.1 | 72.9 | 57.6 |
| 0.3 | 57.9 | ||
| 0.5 | 41.3 | ||
| 3 | 0.1 | 73.1 | 58.5 |
| 0.3 | 59.6 | ||
| 0.5 | 42.0 | ||
| 4 | 0.1 | 72.7 | 57.2 |
| 0.3 | 57.6 | ||
| 0.5 | 40.8 |
| 实验序号 | AVG(0.1:0.7)/% | |||||
|---|---|---|---|---|---|---|
| 1 | √ | √ | × | × | × | 29.5 |
| 2 | √ | √ | √ | × | × | 36.6 |
| 3 | √ | √ | × | √ | × | 44.1 |
| 4 | √ | √ | × | × | √ | 41.6 |
| 5 | √ | √ | √ | √ | × | 46.5 |
| 6 | √ | √ | √ | × | √ | 43.6 |
| 7 | √ | √ | × | √ | √ | 44.3 |
| 8 | √ | √ | √ | √ | √ | 46.5 |
表5 Lnorm、Lguide和Lmil的消融实验结果
Tab. 5 Ablation experimental results of Lnorm, Lguide and Lmil
| 实验序号 | AVG(0.1:0.7)/% | |||||
|---|---|---|---|---|---|---|
| 1 | √ | √ | × | × | × | 29.5 |
| 2 | √ | √ | √ | × | × | 36.6 |
| 3 | √ | √ | × | √ | × | 44.1 |
| 4 | √ | √ | × | × | √ | 41.6 |
| 5 | √ | √ | √ | √ | × | 46.5 |
| 6 | √ | √ | √ | × | √ | 43.6 |
| 7 | √ | √ | × | √ | √ | 44.3 |
| 8 | √ | √ | √ | √ | √ | 46.5 |
| 方法 | 迭代次数 | 批次大小 | 训练时间/s | 参数量/106 |
|---|---|---|---|---|
| FAC-Net | 100 | 10 | 752 | 2.12 |
| ASM-Loc | 800 | 16 | 2 640 | 12.63 |
| P-MIL | 200 | 10 | 1 380 | 9.47 |
| 本文方法 | 150 | 10 | 1 439 | 8.55 |
表6 不同方法在THUMOS’14数据集上的时间效率实验结果
Tab. 6 Time efficiency experimental results of different methods on THUMOS’14 dataset
| 方法 | 迭代次数 | 批次大小 | 训练时间/s | 参数量/106 |
|---|---|---|---|---|
| FAC-Net | 100 | 10 | 752 | 2.12 |
| ASM-Loc | 800 | 16 | 2 640 | 12.63 |
| P-MIL | 200 | 10 | 1 380 | 9.47 |
| 本文方法 | 150 | 10 | 1 439 | 8.55 |
| 1 | SULTANI W, CHEN C, SHAH M. Real-world anomaly detection in surveillance videos[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6479-6488. |
| 2 | HU W, XIE N, LI L, et al. A survey on visual content-based video indexing and retrieval[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2011, 41(6): 797-819. |
| 3 | SHOU Z, CHAN J, ZAREIAN A, et al. CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1417-1426. |
| 4 | LIN T, ZHAO X, SU H, et al. BSN: boundary sensitive network for temporal action proposal generation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 3-21. |
| 5 | ZHAO Y, XIONG Y, WANG L, et al. Temporal action detection with structured segment networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2933-2942. |
| 6 | CHAO Y W, VIJAYANARASIMHAN S, SEYBOLD B, et al. Rethinking the Faster R-CNN architecture for temporal action localization[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:1130-1139. |
| 7 | LONG F, YAO T, QIU Z, et al. Gaussian temporal awareness networks for action localization[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 344-353. |
| 8 | ZENG R, HUANG W, GAN C, et al. Graph convolutional networks for temporal action localization[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7093-7102. |
| 9 | 胡聪,华钢. 基于注意力机制的弱监督动作定位方法[J]. 计算机应用, 2022, 42(3):960-967. |
| HU C, HUA G. Weakly supervised action localization method based on attention mechanism[J]. Journal of Computer Applications, 2022, 42(3): 960-967. | |
| 10 | 任冬伟,王旗龙,魏云超,等. 视觉弱监督学习研究进展[J]. 中国图象图形学报, 2022, 27(6):1768-1798. |
| REN D W, WANG Q L, WEI Y C, et al. Progress in weakly supervised learning for visual understanding[J]. Journal of Image and Graphics, 2022, 27(6): 1768-1798. | |
| 11 | WANG L, XIONG Y, LIN D, et al. UntrimmedNets for weakly supervised action recognition and detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6402-6411. |
| 12 | NGUYEN P, HAN B, LIU T, et al. Weakly supervised action localization by sparse temporal pooling network[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6752-6761. |
| 13 | PAUL S, ROY S, ROY-CHOWDHURY A K. W-TALC: weakly-supervised temporal activity localization and classification[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 588-607. |
| 14 | CARREIRA J, ZISSERMAN A. Quo Vadis, action recognition? A new model and the kinetics dataset[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4724-4733. |
| 15 | LUO Z, GUILLORY D, SHI B, et al. Weakly-supervised action localization with expectation-maximization multi-instance learning[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12374. Cham: Springer, 2020:729-745. |
| 16 | PARDO A, ALWASSEL H, HEILBRON F C, et al. RefineLoc: iterative refinement for weakly-supervised action localization[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3318-3327. |
| 17 | YANG W, ZHANG T, YU X, et al. Uncertainty guided collaborative training for weakly supervised temporal action detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021:53-63. |
| 18 | ZHAI Y, WANG L, TANG W, et al. Two-stream consensus network for weakly-supervised temporal action localization[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12351. Cham: Springer, 2020: 37-54. |
| 19 | MIN K, CORSO J J. Adversarial background-aware loss for weakly-supervised temporal activity localization[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020: 283-299. |
| 20 | HUANG L, WANG L, LI H. Foreground-action consistency network for weakly supervised temporal action localization[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 7982-7991. |
| 21 | CHEN X, HE K. Exploring simple Siamese representation learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15745-15753. |
| 22 | CARON M, BOJANOWSKI P, JOULIN A, et al. Deep clustering for unsupervised learning of visual features[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 139-156. |
| 23 | TAO L, WANG X, YAMASAKI T. An improved inter-intra contrastive learning framework on self-supervised video representation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(8): 5266-5280. |
| 24 | XU B, SHU X, ZHANG J, et al. Spatiotemporal decouple-and-squeeze contrastive learning for semisupervised skeleton-based action recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 11035-11048. |
| 25 | CHEN Z, LIN K Y, ZHENG W S. Consistent intra-video contrastive learning with asynchronous long-term memory bank[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(3): 1168-1180. |
| 26 | ZHANG C, CAO M, YANG D, et al. CoLA: weakly-supervised temporal action localization with snippet contrastive learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 16005-16014. |
| 27 | LUO W, ZHANG T, YANG W, et al. Action unit memory network for weakly supervised temporal action localization[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9964-9974. |
| 28 | LI J, YANG T, JI W, et al. Exploring denoised cross-video contrast for weakly-supervised temporal action localization[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19882-19892. |
| 29 | ZACH C, POCK T, BISCHOF H. A duality based approach for realtime TV-L 1 optical flow[C]// Proceedings of the 2007 DAGM Symposium, LNCS 4713. Berlin: Springer, 2007: 214-223. |
| 30 | KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset[EB/OL]. [2024-04-09]. . |
| 31 | HE K M, FAN H Q, WU Y X, et al. Momentum contrast for unsupervised visual representation learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9729-9738. |
| 32 | LEE P, UH Y, BYUN H. Background suppression network for weakly-supervised temporal action localization[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 11320-11327. |
| 33 | IDREES H, ZAMIR A R, JIANG Y G, et al. The THUMOS challenge on action recognition for videos “in the wild”[J]. Computer Vision and Image Understanding, 2017, 155: 1-23. |
| 34 | HEILBRON F C, ESCORCIA V, GHANEM B, et al. ActivityNet: a large-scale video benchmark for human activity understanding[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 961-970. |
| 35 | NARAYAN S, CHOLAKKAL H, HAYAT M, et al. D2-Net: weakly-supervised action localization via discriminative embeddings and denoised activations[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13588-13597. |
| 36 | HE B, YANG X, KANG L, et al. ASM-Loc: action-aware segment modeling for weakly-supervised temporal action localization[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13915-13925. |
| 37 | ZHANG S, ZHAO C. Cross-video contextual knowledge exploration and exploitation for ambiguity reduction in weakly supervised temporal action localization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(6): 4568-4580. |
| 38 | SHI H, ZHANG X Y, LI C, et al. Dynamic graph modeling for weakly-supervised temporal action localization[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 3820-3828. |
| 39 | TANG Y, GE J, GUO K, et al. Towards better utilization of pseudo labels for weakly supervised temporal action localization[J]. Information Sciences, 2023, 623: 693-708. |
| 40 | REN H, YANG W, ZHANG T, et al. Proposal-based multiple instance learning for weakly-supervised temporal action localization[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023:2394-2404. |
| 41 | HUANG J, KONG M, CHEN L, et al. Temporal RPN learning for weakly-supervised temporal action localization[C]// Proceedings of the 15th Asian Conference on Machine Learning. New York: JMLR.org, 2024: 470-485. |
| [1] | 杨本臣, 李浩然, 金海波. 级联融合与增强重建的多聚焦图像融合网络[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 594-600. |
| [2] | 谢斌红, 高婉银, 陆望东, 张英俊, 张睿. 小样本相似性匹配特征增强的密集目标计数网络[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 403-410. |
| [3] | 王杰, 孟华. 基于点云整体拓扑结构的图像分类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1107-1113. |
| [4] | 李新叶, 侯晔凝, 孔英会, 燕志旗. 结合特征融合与增强注意力的少样本目标检测[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 745-751. |
| [5] | 陈佳, 张鸿. 基于特征增强和语义相关性匹配的图像文本检索方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 16-23. |
| [6] | 袁国龙, 张玉金, 刘洋. 基于残差反馈和自注意力的图像篡改取证网络[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2925-2931. |
| [7] | 鲁斌, 柳杰林. 基于特征增强的三维点云语义分割[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1818-1825. |
| [8] | 罗芳, 刘阳, 何道森. 复杂场景下自适应特征融合的多尺度船舶检测[J]. 《计算机应用》唯一官方网站, 2023, 43(11): 3587-3593. |
| [9] | 谭湘粤, 胡晓, 杨佳信, 向俊将. 基于递进式特征增强聚合的伪装目标检测[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2192-2200. |
| [10] | 温静, 李强. 基于时空上下文信息增强的目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3565-3570. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||