


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (11): 3713-3720.DOI: 10.11772/j.issn.1001-9081.2024111662
• 多媒体计算与计算机仿真 • 上一篇
林峻屹, 陈明轩( ), 高永彬
), 高永彬
收稿日期:2024-11-22
修回日期:2025-04-09
接受日期:2025-04-17
发布日期:2025-04-22
出版日期:2025-11-10
通讯作者:
陈明轩
作者简介:林峻屹(1999—),男,山东烟台人,硕士研究生,主要研究方向:人-物交互检测基金资助:
Junyi LIN, Mingxuan CHEN(), Yongbin GAO
Received:2024-11-22
Revised:2025-04-09
Accepted:2025-04-17
Online:2025-04-22
Published:2025-11-10
Contact:
Mingxuan CHEN
About author:LIN Junyi, born in 1999, M. S. candidate. His research interests include human-object interaction detection.Supported by:摘要:
人-物交互(HOI)检测任务的核心在于识别图像中的人物和物体,并准确分类它们之间的交互关系,这对于深化场景理解至关重要;但现有算法在处理复杂关系时,由于缺乏局部信息导致错误关联,难以区分细粒度操作。因此,设计一种局部特征增强的感知模块(LFPM),通过结合局部和非局部特征的相互作用增强模型对局部特征信息的捕获能力。该模块包含了3个关键部分:降采样聚合分支模块(DAM)、细粒度特征分支(FGFB)模块以及多尺度小波卷积(MSWC)模块。其中,DAM通过降采样获得低频特征,聚合非局部结构信息;FGFB模块并行执行卷积操作,补充DAM对局部信息的提取;MSWC模块进一步在空间和通道维度上优化输出特征,使特征表达更加精细完整。此外,为解决Transformer在局部空间和通道特征挖掘方面的不足,引入空间和通道挤压注意力(scSE)模块。该模块在空间和通道维度上分配注意力,可增强模型对局部显著区域的敏感性,有效提升HOI检测的精度。最后整合LFPM、scSE以及Transformer架构构成局部特征增强感知模型(LFEP)框架。实验结果表明,与SQA(Strong guidance Query with self-selected Attention)算法相比,LFEP框架在V-COCO数据集上的平均精度(AP)提升了1.1个百分点,在HICO-DET数据集上的平均精度均值(mAP)提升了0.49个百分点,消融实验也验证了LEEP中各模块的有效性。
中图分类号:
林峻屹, 陈明轩, 高永彬. 融合局部特征增强感知的人-物交互检测算法[J]. 计算机应用, 2025, 45(11): 3713-3720.
Junyi LIN, Mingxuan CHEN, Yongbin GAO. Human-object interaction detection algorithm by fusing local feature enhanced perception[J]. Journal of Computer Applications, 2025, 45(11): 3713-3720.

图1 细节感知能力示意图
Fig. 1 Schematic diagram of detail perception ability

图2 增强局部显著区域敏感性能力示意图
Fig. 2 Schematic diagram of ability to enhance sensitivity of local salient regions
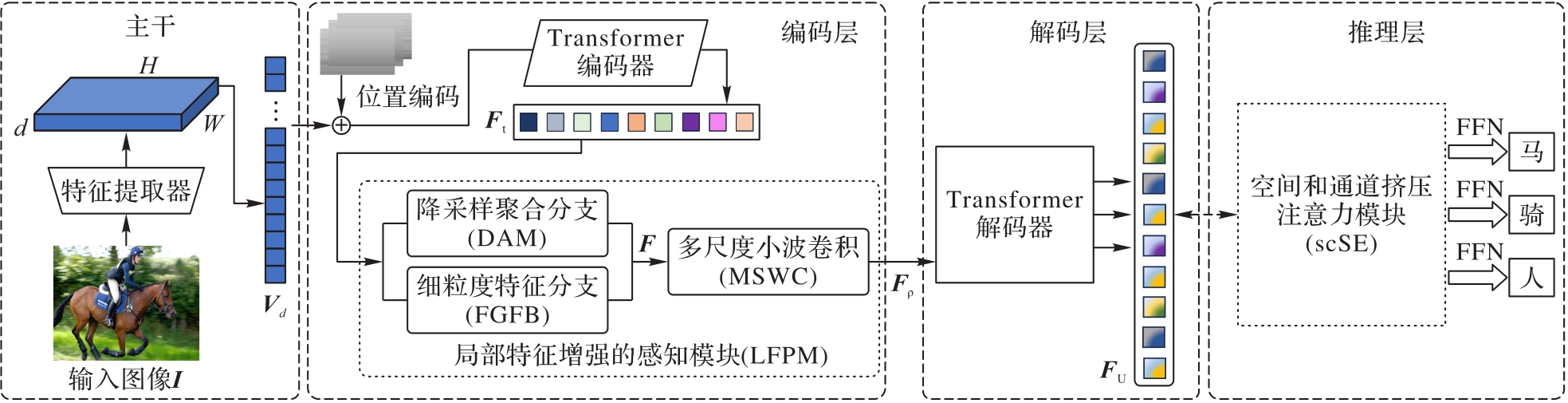
图3 LFEP的总体架构
Fig. 3 General architecture of LFEP
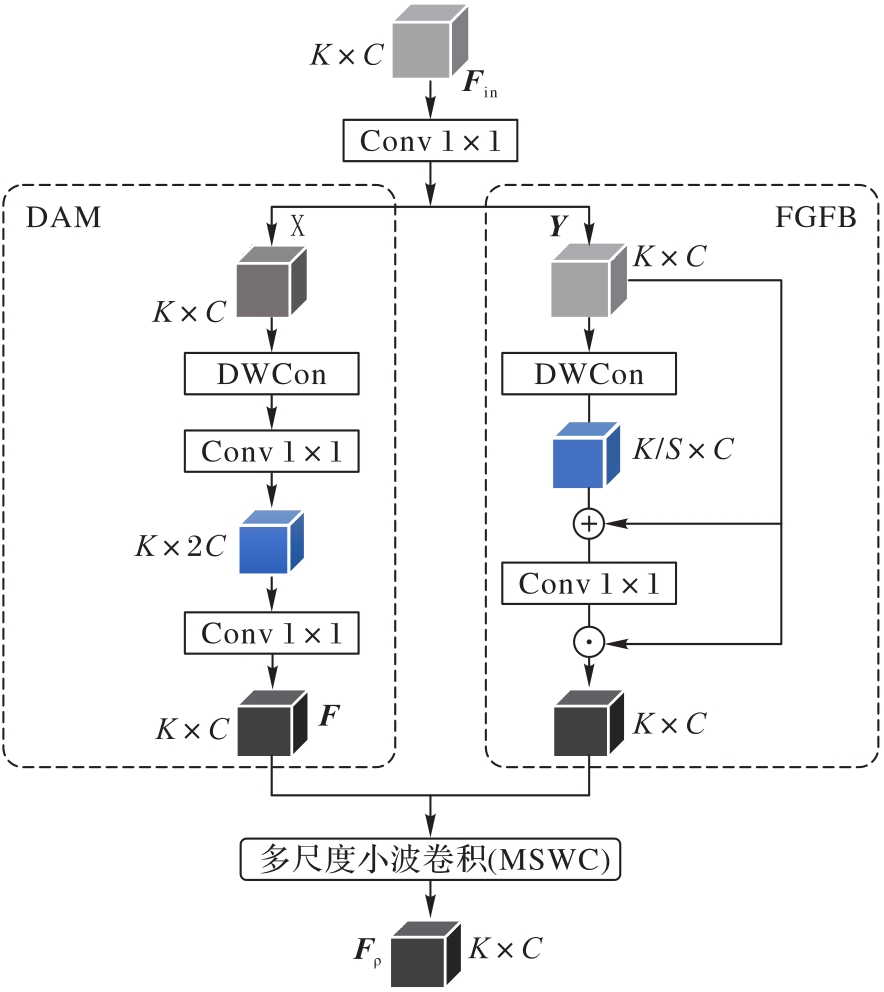
图4 LFPM的总体架构
Fig. 4 General architecture of LFPM
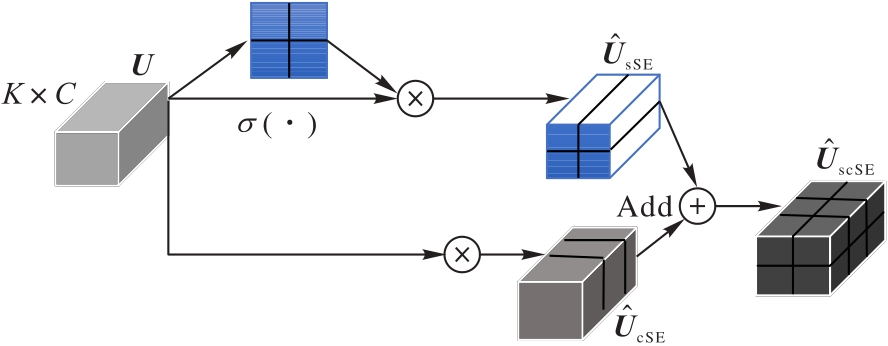
图5 scSE注意力模块总体架构
Fig. 5 General architecture of scSE attention module
| 方法 | 默认 | 已知类 | |||||
|---|---|---|---|---|---|---|---|
| 完整类 | 稀有类 | 非稀有类 | 完整类 | 稀有类 | 非稀有类 | ||
| 一阶段方法 | UnionDet[ | 17.58 | 11.72 | 19.33 | 19.76 | 14.68 | 21.27 |
| IPNet[ | 19.56 | 12.79 | 21.58 | 22.05 | 15.77 | 23.92 | |
| PPDM[ | 21.94 | 13.97 | 24.32 | 24.81 | 17.09 | 27.12 | |
| AS-Net[ | 24.40 | 22.39 | 25.01 | 27.41 | 25.44 | 28.00 | |
| QPIC[ | 29.07 | 21.85 | 31.23 | 31.68 | 24.14 | 33.93 | |
| CDT[ | — | — | — | ||||
| SQAB[ | 30.82 | 24.92 | 32.58 | 33.58 | 27.19 | 35.49 | |
| SQA[ | 31.99 | 25.88 | 32.62 | 35.12 | 32.74 | — | |
| 两阶段方法 | TIN[ | 17.03 | 13.42 | 18.11 | 19.17 | 15.51 | 20.26 |
| DRG[ | 19.26 | 17.74 | 19.71 | 23.40 | 21.75 | 23.89 | |
| ACP[ | 20.59 | 15.92 | 21.98 | — | — | — | |
| DJRN[ | 21.34 | 18.53 | 22.18 | 23.69 | 20.64 | 24.60 | |
| IDN[37] | 23.36 | 22.47 | 23.63 | 26.43 | 25.01 | 26.85 | |
| FCL[ | 25.27 | 20.57 | 26.67 | 27.71 | 22.34 | 28.93 | |
| TMHOI[ | 26.95 | 21.28 | 28.56 | — | — | — | |
| OCN[ | — | — | — | ||||
| LFEP | 32.48 | 27.12 | 34.05 | 35.09 | 29.58 | 36.16 | |
表1 不同方法在HICO-DET测试集上的mAP对比 ( %)
Tab. 1 mAp comparison of different methods on HICO-DET test set
| 方法 | 默认 | 已知类 | |||||
|---|---|---|---|---|---|---|---|
| 完整类 | 稀有类 | 非稀有类 | 完整类 | 稀有类 | 非稀有类 | ||
| 一阶段方法 | UnionDet[ | 17.58 | 11.72 | 19.33 | 19.76 | 14.68 | 21.27 |
| IPNet[ | 19.56 | 12.79 | 21.58 | 22.05 | 15.77 | 23.92 | |
| PPDM[ | 21.94 | 13.97 | 24.32 | 24.81 | 17.09 | 27.12 | |
| AS-Net[ | 24.40 | 22.39 | 25.01 | 27.41 | 25.44 | 28.00 | |
| QPIC[ | 29.07 | 21.85 | 31.23 | 31.68 | 24.14 | 33.93 | |
| CDT[ | — | — | — | ||||
| SQAB[ | 30.82 | 24.92 | 32.58 | 33.58 | 27.19 | 35.49 | |
| SQA[ | 31.99 | 25.88 | 32.62 | 35.12 | 32.74 | — | |
| 两阶段方法 | TIN[ | 17.03 | 13.42 | 18.11 | 19.17 | 15.51 | 20.26 |
| DRG[ | 19.26 | 17.74 | 19.71 | 23.40 | 21.75 | 23.89 | |
| ACP[ | 20.59 | 15.92 | 21.98 | — | — | — | |
| DJRN[ | 21.34 | 18.53 | 22.18 | 23.69 | 20.64 | 24.60 | |
| IDN[37] | 23.36 | 22.47 | 23.63 | 26.43 | 25.01 | 26.85 | |
| FCL[ | 25.27 | 20.57 | 26.67 | 27.71 | 22.34 | 28.93 | |
| TMHOI[ | 26.95 | 21.28 | 28.56 | — | — | — | |
| OCN[ | — | — | — | ||||
| LFEP | 32.48 | 27.12 | 34.05 | 35.09 | 29.58 | 36.16 | |
| 方法 | 方法 | ||||
|---|---|---|---|---|---|
| UnionDet[ | 47.5 | 56.2 | HOTR[ | 55.2 | 64.4 |
| TIN[ | 47.8 | 54.2 | QPIC[ | 58.8 | 61.0 |
| IPNet[ | 51.0 | — | CDT[ | 61.43 | — |
| DRG[ | 51.0 | — | SQAB[ | — | |
| FCL[ | 52.4 | — | OCN[ | — | |
| ACP[ | 52.9 | — | SQA[ | — | |
| IDN[37] | 53.3 | 60.3 | LFEP | 66.5 | 68.8 |
| AS-Net[ | 53.9 | — |
表2 不同方法在V-COCO测试集上的效果对比 ( %)
Tab. 2 Comparison of effectiveness of different methods on V-COCO test set
| 方法 | 方法 | ||||
|---|---|---|---|---|---|
| UnionDet[ | 47.5 | 56.2 | HOTR[ | 55.2 | 64.4 |
| TIN[ | 47.8 | 54.2 | QPIC[ | 58.8 | 61.0 |
| IPNet[ | 51.0 | — | CDT[ | 61.43 | — |
| DRG[ | 51.0 | — | SQAB[ | — | |
| FCL[ | 52.4 | — | OCN[ | — | |
| ACP[ | 52.9 | — | SQA[ | — | |
| IDN[37] | 53.3 | 60.3 | LFEP | 66.5 | 68.8 |
| AS-Net[ | 53.9 | — |

图6 可视化测试结果
Fig. 6 Visualization test results
| 方法 | mAP/% | |
|---|---|---|
| 默认 | 已知类 | |
| BaseLine | 30.75 | 33.12 |
| BaseLine+LFPM | 31.61 | 34.26 |
| BaseLine+MSWC | 31.20 | 33.60 |
| BaseLine+LFPM+MSWC | 32.08 | 34.63 |
| BaseLine+scSE | 31.16 | 33.62 |
| LFEP | 32.48 | 35.09 |
表3 各模块在HICO-DET数据集上的消融实验结果
Tab. 3 Ablation experiment results on HICO-DET dataset for each module
| 方法 | mAP/% | |
|---|---|---|
| 默认 | 已知类 | |
| BaseLine | 30.75 | 33.12 |
| BaseLine+LFPM | 31.61 | 34.26 |
| BaseLine+MSWC | 31.20 | 33.60 |
| BaseLine+LFPM+MSWC | 32.08 | 34.63 |
| BaseLine+scSE | 31.16 | 33.62 |
| LFEP | 32.48 | 35.09 |
| [1] | SADEGHI M A, FARHADI A. Recognition using visual phrases[C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2011: 1745-1752. |
| [2] | IFTEKHAR A S M, KUMAR S, McEVER R A, et al. GTNet: guided transformer network for detecting human-object interactions[C]// Proceedings of the SPIE 12527, Pattern Recognition and Tracking XXXIV. Bellingham, WA: SPIE, 2023: No.125270Q. |
| [3] | CAO Y, TANG Q, YANG F, et al. Re-mine, learn and reason: exploring the cross-modal semantic correlations for language-guided HOI detection[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 23435-23446. |
| [4] | ZHONG X, DING C, QU X, et al. Polysemy deciphering network for robust human-object interaction detection[J]. International Journal of Computer Vision, 2021, 129(6): 1910-1929. |
| [5] | YANG Y, ZHUANG Y, PAN Y. Multiple knowledge representation for big data artificial intelligence: framework, applications, and case studies[J]. Frontiers of Information Technology and Electronic Engineering, 2021, 22(12): 1551-1558. |
| [6] | ZHANG A, LIAO Y, LIU S, et al. Mining the benefits of two-stage and one-stage HOI detection[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 17209-17220. |
| [7] | 龚勋,张志莹,刘璐,等.人物交互检测研究进展综述[J].西南交通大学学报,2022,57(4):693-704. |
| GONG X, ZHANG Z Y, LIU L, et al. A survey of human-object interaction detection[J]. Journal of Southwest Jiaotong University, 2022, 57(4): 693-704. | |
| [8] | GUPTA S, MALIK J. Visual semantic role labeling[EB/OL]. [2024-09-20].. |
| [9] | CHAO Y W, LIU Y, LIU X, et al. Learning to detect human-object interactions[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 381-389. |
| [10] | ZHENG S, XU B, JIN Q. Open-category human-object interaction pre-training via language modeling framework[C]// Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19392-19402. |
| [11] | ZOU C, WANG B, HU Y, et al. End-to-end human object interaction detection with HOI Transformer[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11820-11829. |
| [12] | LIAO Y, LIU S, WANG F, et al. PPDM: parallel point detection and matching for real-time human-object interaction detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 479-487. |
| [13] | KIM B, CHOI T, KANG J, et al. UnionDet: union-level detector towards real-time human-object interaction detection[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12360. Cham: Springer, 2020: 498-514. |
| [14] | ZOU C, WANG B, HU Y, et al. Cascaded decoding network for HOI detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11825-11834. |
| [15] | CHEN M, LIAO Y, LIU S, et al. Reformulating HOI detection as adaptive set prediction[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9000-9009. |
| [16] | ZHONG X, DING C, QU X, et al. Polysemy deciphering network for human-object interaction detection[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12365. Cham: Springer, 2020: 69-85. |
| [17] | GKIOXARI G, GIRSHICK R, DOLLÁR P, et al. Detecting and recognizing human-object interactions[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8359-8367. |
| [18] | ZHANG Y, PAN Y, YAO T, et al. Exploring structure-aware Transformer over interaction proposals for human-object interaction detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19526-19535. |
| [19] | ZHANG F Z, CAMPBELL D, GOULD S. Efficient two-stage detection of human-object interactions with a novel Unary-Pairwise Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20072-20080. |
| [20] | ZHOU D, LIU Z, WANG J, et al. Human-object interaction detection via Disentangled Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19546-19555. |
| [21] | GAO C, XU J, ZOU Y, et al. DRG: dual relation graph for human-object interaction detection[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12357. Cham: Springer, 2020: 696-712. |
| [22] | ZHANG F Z, CAMPBELL D, GOULD S. Spatially conditioned graphs for detecting human-object interactions[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13299-13307. |
| [23] | PARK N, KIM S. How do Vision Transformers work?[EB/OL]. [2025-01-13].. |
| [24] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units (GELUs)[EB/OL]. [2024-11-09].. |
| [25] | KUHN H W. The Hungarian method for the assignment problem[M]// JÜNGERM, LIEBLINGT M, NADDEFD, alet. 50 years of integer programming 1958 — 2008. Berlin: Springer, 2010: 29-47. |
| [26] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1. Cambridge: MIT Press, 2015: 91-99. |
| [27] | REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 658-666. |
| [28] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. |
| [29] | WANG T, YANG T, DANELLJAN M, et al. Learning human-object interaction detection using interaction points[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4115-4124. |
| [30] | TAMURA M, OHASHI H, YOSHINAGA T. QPIC: query-based pairwise human-object interaction detection with image-wide contextual information[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10405-10414. |
| [31] | ZONG D, SU S. Zero-shot human-object interaction detection via similarity propagation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 17805-17816. |
| [32] | LI J, LAI H, GAO G, et al. SQAB: specific query anchor boxes for human-object interaction detection[J]. Displays, 2023, 80: No.102570. |
| [33] | ZHANG F, SHENG L, GUO B, et al. SQA: strong guidance query with self-selected attention for human-object interaction detection[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [34] | LI Y L, ZHOU S, HUANG X, et al. Transferable interactiveness knowledge for human-object interaction detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3580-3589. |
| [35] | KIM D J, SUN X, CHOI J, et al. Detecting human-object interactions with action co-occurrence priors[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12366. Cham: Springer, 2020: 718-736. |
| [36] | LI Y L, LIU X, LU H, et al. Detailed 2D-3D joint representation for human-object interaction[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10163-10172. |
| 37 LI Y L, LIU X, WU X, et al. HOI analysis: integrating and decomposing human-object interaction[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 5011-5022. | |
| [38] | HOU Z, YU B, QIAO Y, et al. Detecting human-object interaction via fabricated compositional learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 14641-14650. |
| [39] | ZHU L, LAN Q, VELASQUEZ A, et al. TMHOI: translational model for human-object interaction detection[EB/OL]. [2024-06-20].. |
| [40] | YUAN H, WANG M, NI D, et al. Detecting human-object interactions with object-guided cross-modal calibrated semantics[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 3206-3214. |
| [41] | KIM B, LEE J, KANG J, et al. HOTR: end-to-end human-object interaction detection with transformers[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 74-83. |
| [1] | 范亚州, 李卓. 能耗约束下分层联邦学习模型质量优化的节点协作机制[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1589-1594. |
| [2] | 宗伟, 赵悦, 李尹, 徐晓娜. 端到端语音到语音翻译的优化方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1363-1371. |
| [3] | 谢冬梅, 边昕烨, 于连飞, 刘文博, 王子灵, 曲志坚, 于家峰. 基于图编码与改进流注意力的编码sORFs预测方法DeepsORF[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 546-555. |
| [4] | 蒋铭, 王琳钦, 赖华, 高盛祥. 基于编辑约束的端到端越南语文本正则化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 362-370. |
| [5] | 付强, 徐振平, 盛文星, 叶青. 结合字节级别字节对编码的端到端中文语音识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 318-324. |
| [6] | 赵晓焱, 匡燕, 王梦含, 袁培燕. 基于知识图谱的端到端内容共享机制[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 995-1001. |
| [7] | 刘聪, 万根顺, 高建清, 付中华. 基于韵律特征辅助的端到端语音识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 380-384. |
| [8] | 杨磊, 赵红东, 于快快. 基于多头注意力机制的端到端语音情感识别[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1869-1875. |
| [9] | 郭帅, 苏旸. 基于数据流的加密流量分类方法[J]. 计算机应用, 2021, 41(5): 1386-1391. |
| [10] | 吴赛赛, 梁晓贺, 谢能付, 周爱莲, 郝心宁. 面向领域实体关系联合抽取的标注方法[J]. 计算机应用, 2021, 41(10): 2858-2863. |
| [11] | 胡学敏, 童秀迟, 郭琳, 张若晗, 孔力. 基于深度视觉注意神经网络的端到端自动驾驶模型[J]. 计算机应用, 2020, 40(7): 1926-1931. |
| [12] | 陈修凯, 陆志华, 周宇. 基于卷积编解码器和门控循环单元的语音分离算法[J]. 计算机应用, 2020, 40(7): 2137-2141. |
| [13] | 贾永超, 何小卫, 郑忠龙. 融合重检测机制的卷积回归网络目标跟踪算法[J]. 计算机应用, 2019, 39(8): 2247-2251. |
| [14] | 文凯, 谭笑. 基于用户偏好与副本阈值的端到端缓存算法[J]. 计算机应用, 2019, 39(7): 2051-2055. |
| [15] | 邱泽宇, 屈丹, 张连海. 基于WaveNet的端到端语音合成方法[J]. 计算机应用, 2019, 39(5): 1325-1329. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||