


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1077-1085.DOI: 10.11772/j.issn.1001-9081.2025050563
王德龙1,2, 汪颢懿1,2( ), 张青川1,2, 宋泽羲1,2
), 张青川1,2, 宋泽羲1,2
收稿日期:2025-05-26
修回日期:2025-08-07
接受日期:2025-08-08
发布日期:2025-08-15
出版日期:2026-04-10
通讯作者:
汪颢懿
作者简介:王德龙(2000—),男,山东青岛人,硕士研究生,主要研究方向:自然语言处理、深度学习基金资助:
Delong WANG1,2, Haoyi WANG1,2(), Qingchuan ZHANG1,2, Zexi SONG1,2
Received:2025-05-26
Revised:2025-08-07
Accepted:2025-08-08
Online:2025-08-15
Published:2026-04-10
Contact:
Haoyi WANG
About author:WANG Delong, born in 2000, M. S. candidate. His research interests include natural language processing, deep learning.Supported by:摘要:
为提升多模态事件抽取方法中不同模态特征之间的对齐精度与融合效率,增强模型对图像与文本语义关系的理解能力,提出一种基于双通道“文本?图像”特征门控融合机制的多模态事件抽取模型MEE-DF(Multimodal Event Extraction based on Dual-channel Fusion)。首先,拓展图像生成文本描述通道,挖掘图像中隐含的事件论元,完善事件抽取的信息表示;其次,构建局部约束注意力(LCCA)机制,生成几何对齐图嵌入图像信息,提取高区分度的图像特征;再次,构建基于交互注意力图的对抗门控机制,进行文本实体与图像对象的细粒度对齐;最后,使用双通道融合特征策略,筛选重要Patch特征,去除冗余信息,提高特征整合效率。在MEED和M2E2公开数据集上的实验结果表明,MEE-DF在事件类型检测任务上F1值分别达到90.9%和88.8%,在事件论元抽取(EAE)任务上F1值分别达到73.3%和68.1%,优于现有的事件抽取模型,消融实验结果进一步表明MEE-DF的各模块对事件抽取性能提升均有显著贡献。
中图分类号:
王德龙, 汪颢懿, 张青川, 宋泽羲. 基于文本‒图像双通道特征门控融合机制的多模态事件抽取[J]. 计算机应用, 2026, 46(4): 1077-1085.
Delong WANG, Haoyi WANG, Qingchuan ZHANG, Zexi SONG. Multimodal event extraction based on text-image dual-channel feature gated fusion mechanism[J]. Journal of Computer Applications, 2026, 46(4): 1077-1085.

图1 图像信息补充论元的示例
Fig. 1 Example of image information supplementing arguments
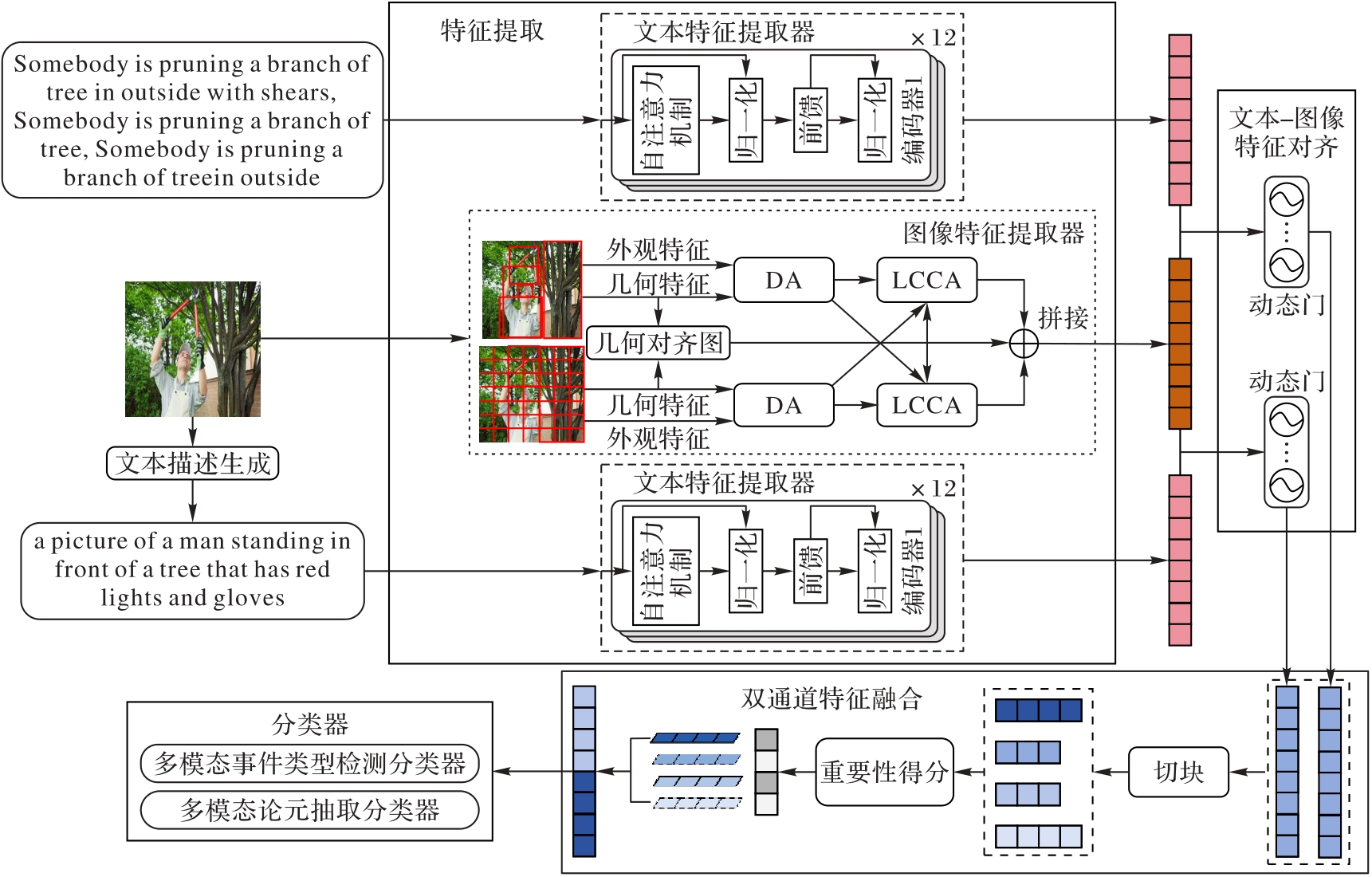
图2 MEE-DF的结构
Fig. 2 Structure of MEE-DF
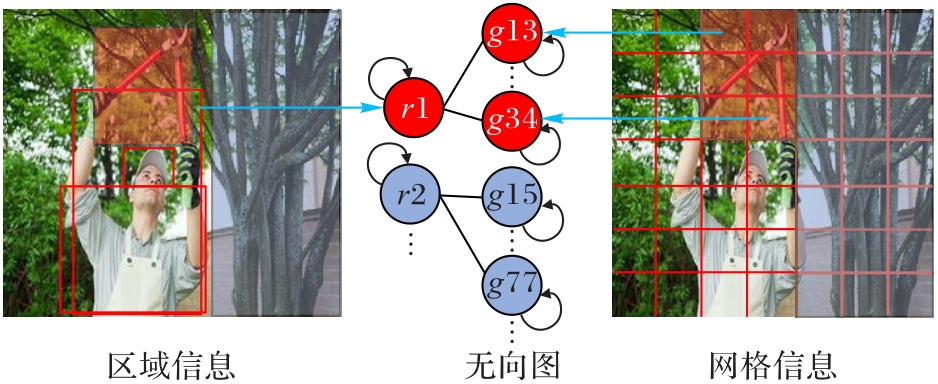
图3 几何对齐图示例
Fig. 3 Example of geometric alignment graphs
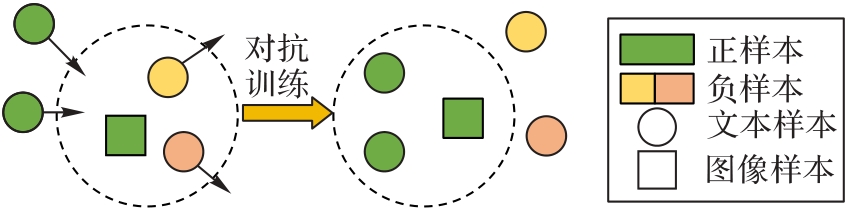
图4 对抗训练
Fig. 4 Adversarial training
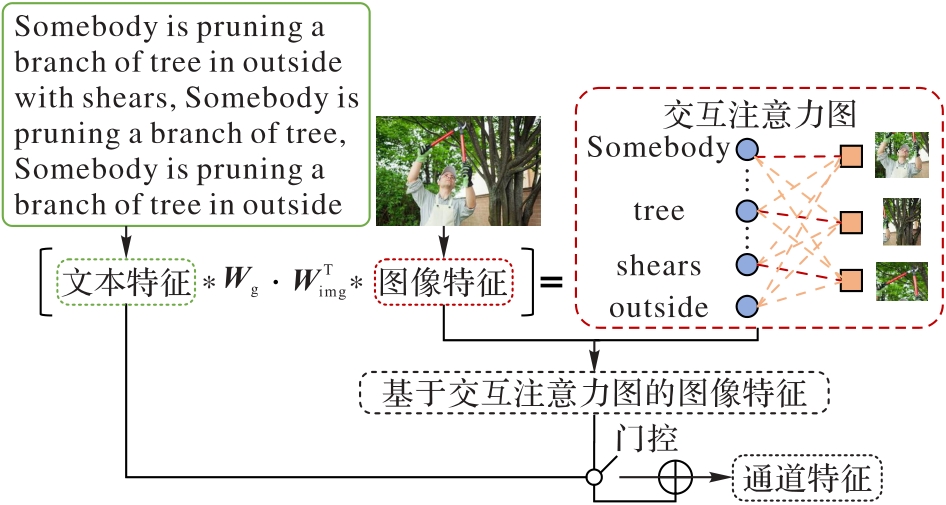
图5 基于交互注意力图的门控机制
Fig. 5 Gating mechanism based on interactive attention maps
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| DRMM | 80.1 | 79.4 | 79.7 | — | — | — |
| TabEAE | — | — | — | 68.1 | 72.3 | 70.1 |
| PAIE | — | — | — | 65.3 | 70.5 | 67.8 |
| MEE-DF | 92.6 | 89.6 | 90.9 | 76.5 | 70.6 | 73.3 |
表1 MEED数据集上不同模型的性能对比 (%)
Tab. 1 Performance comparison of different models on MEED dataset
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| DRMM | 80.1 | 79.4 | 79.7 | — | — | — |
| TabEAE | — | — | — | 68.1 | 72.3 | 70.1 |
| PAIE | — | — | — | 65.3 | 70.5 | 67.8 |
| MEE-DF | 92.6 | 89.6 | 90.9 | 76.5 | 70.6 | 73.3 |
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| VALHALLA | 17.5 | 24.6 | 19.2 | 10.5 | 15.1 | 10.8 |
| DRMM | 80.0 | 77.4 | 78.7 | 45.1 | 57.3 | 50.5 |
| RMMT | 36.1 | 24.0 | 26.4 | 12.9 | 12.4 | 11.7 |
| Theia | 51.8 | 53.1 | 52.5 | 16.3 | 18.4 | 16.4 |
| AFSSAG | 56.4 | 52.6 | 54.4 | 48.4 | 18.2 | 26.5 |
| MEE-DF | 90.2 | 87.5 | 88.8 | 70.5 | 66.1 | 68.1 |
表2 M2E2数据集上不同模型的性能对比 (%)
Tab. 2 Performance comparison of different models on M2E2 dataset
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| VALHALLA | 17.5 | 24.6 | 19.2 | 10.5 | 15.1 | 10.8 |
| DRMM | 80.0 | 77.4 | 78.7 | 45.1 | 57.3 | 50.5 |
| RMMT | 36.1 | 24.0 | 26.4 | 12.9 | 12.4 | 11.7 |
| Theia | 51.8 | 53.1 | 52.5 | 16.3 | 18.4 | 16.4 |
| AFSSAG | 56.4 | 52.6 | 54.4 | 48.4 | 18.2 | 26.5 |
| MEE-DF | 90.2 | 87.5 | 88.8 | 70.5 | 66.1 | 68.1 |
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| MEE-DF_1 | 89.2 | 85.4 | 87.2 | 75.4 | 68.8 | 72.1 |
| MEE-DF_2 | 87.3 | 83.9 | 85.6 | 74.8 | 67.9 | 71.2 |
| MEE-DF_3 | 85.9 | 79.6 | 82.6 | 74.6 | 68.2 | 71.0 |
| MEE-DF_4 | 90.5 | 88.1 | 89.3 | 75.3 | 69.9 | 72.6 |
| MEE-DF_5 | 88.4 | 85.1 | 86.7 | 75.2 | 68.5 | 71.7 |
| MEE-DF | 92.6 | 89.6 | 90.9 | 76.5 | 70.6 | 73.3 |
表3 MEED数据集上不同模型的消融实验结果 ( %)
Tab. 3 Ablation experimental results of different models on MEED dataset
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| MEE-DF_1 | 89.2 | 85.4 | 87.2 | 75.4 | 68.8 | 72.1 |
| MEE-DF_2 | 87.3 | 83.9 | 85.6 | 74.8 | 67.9 | 71.2 |
| MEE-DF_3 | 85.9 | 79.6 | 82.6 | 74.6 | 68.2 | 71.0 |
| MEE-DF_4 | 90.5 | 88.1 | 89.3 | 75.3 | 69.9 | 72.6 |
| MEE-DF_5 | 88.4 | 85.1 | 86.7 | 75.2 | 68.5 | 71.7 |
| MEE-DF | 92.6 | 89.6 | 90.9 | 76.5 | 70.6 | 73.3 |
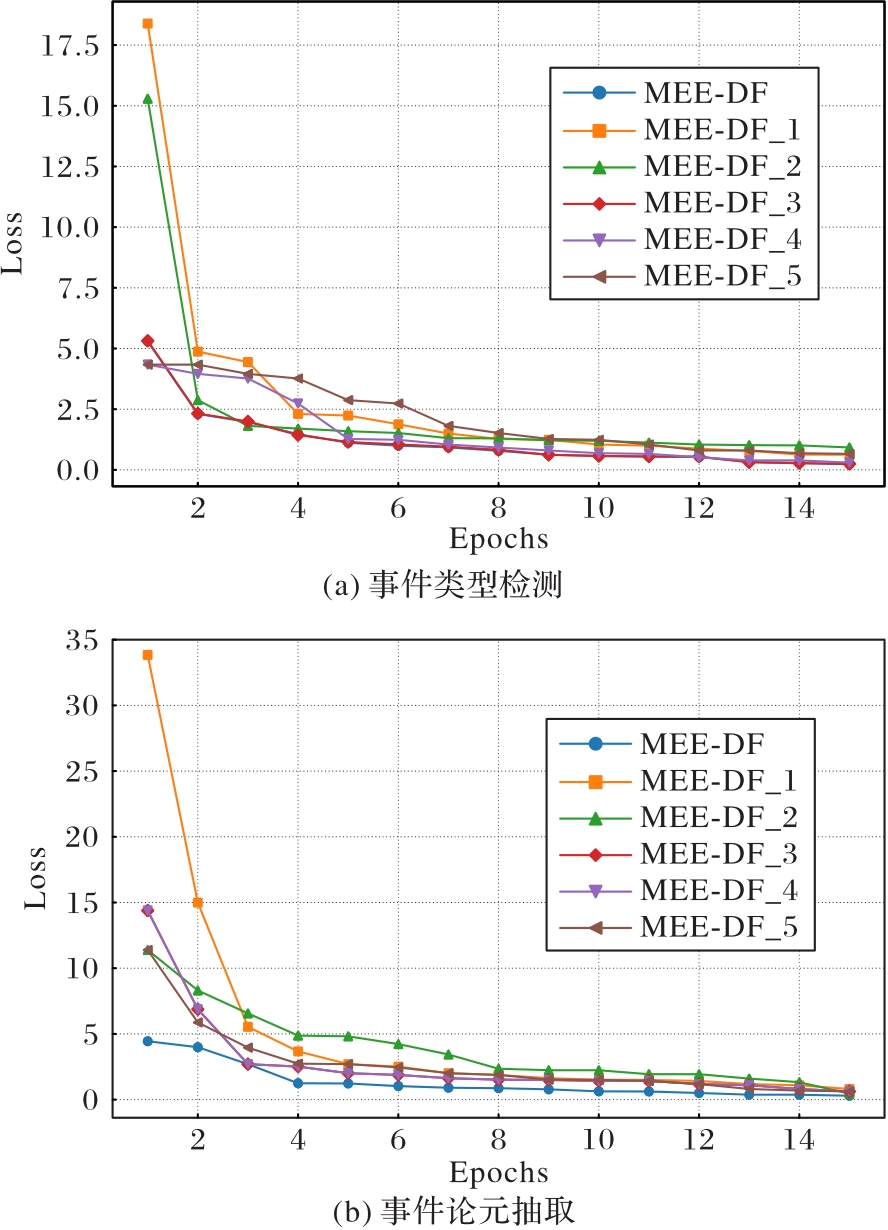
图6 MEED数据集上不同模型的损失曲线
Fig. 6 Loss curves of different models on MEED dataset
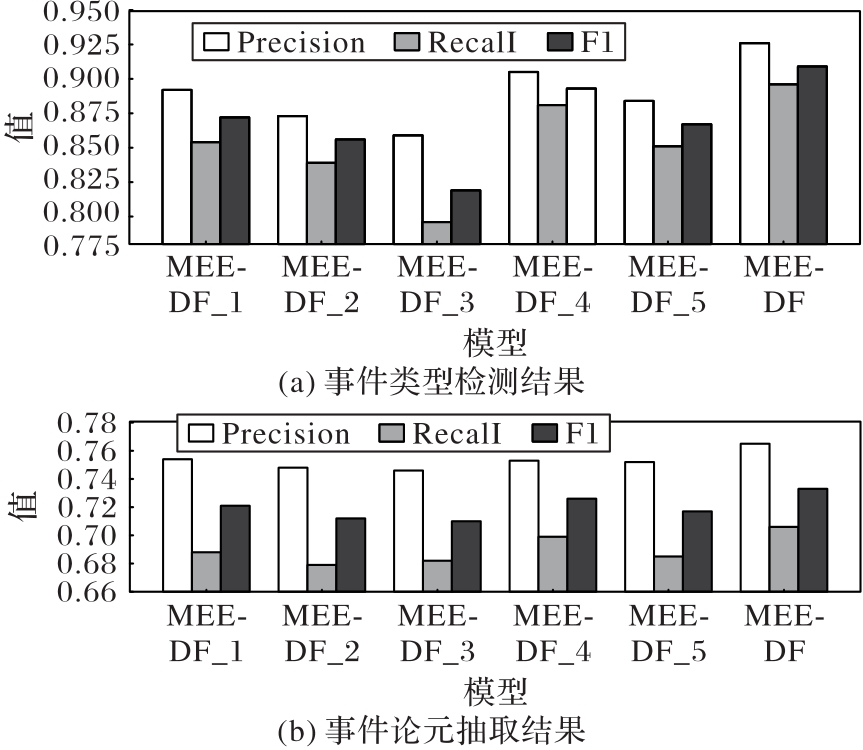
图7 MEED数据集上消融实验中不同模型的性能可视化
Fig. 7 Performance visualization of different models in ablation experiments on MEED dataset
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| MEE-DF_1 | 88.5 | 85.8 | 87.1 | 68.5 | 64.7 | 66.6 |
| MEE-DF_2 | 88.2 | 85.3 | 86.7 | 68.0 | 64.1 | 66.0 |
| MEE-DF_3 | 89.3 | 86.5 | 87.9 | 68.9 | 64.2 | 66.5 |
| MEE-DF_4 | 89.6 | 86.8 | 88.2 | 69.7 | 65.4 | 67.4 |
| MEE-DF_5 | 88.4 | 85.3 | 86.8 | 67.2 | 63.6 | 65.4 |
| MEE-DF | 90.2 | 87.5 | 88.8 | 70.5 | 66.1 | 68.1 |
表4 M2E2数据集上不同模型的消融实验结果 (%)
Tab. 4 Ablation experimental results of different models on M2E2 dataset
| 模型 | 事件类型检测 | 事件论元抽取 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| MEE-DF_1 | 88.5 | 85.8 | 87.1 | 68.5 | 64.7 | 66.6 |
| MEE-DF_2 | 88.2 | 85.3 | 86.7 | 68.0 | 64.1 | 66.0 |
| MEE-DF_3 | 89.3 | 86.5 | 87.9 | 68.9 | 64.2 | 66.5 |
| MEE-DF_4 | 89.6 | 86.8 | 88.2 | 69.7 | 65.4 | 67.4 |
| MEE-DF_5 | 88.4 | 85.3 | 86.8 | 67.2 | 63.6 | 65.4 |
| MEE-DF | 90.2 | 87.5 | 88.8 | 70.5 | 66.1 | 68.1 |
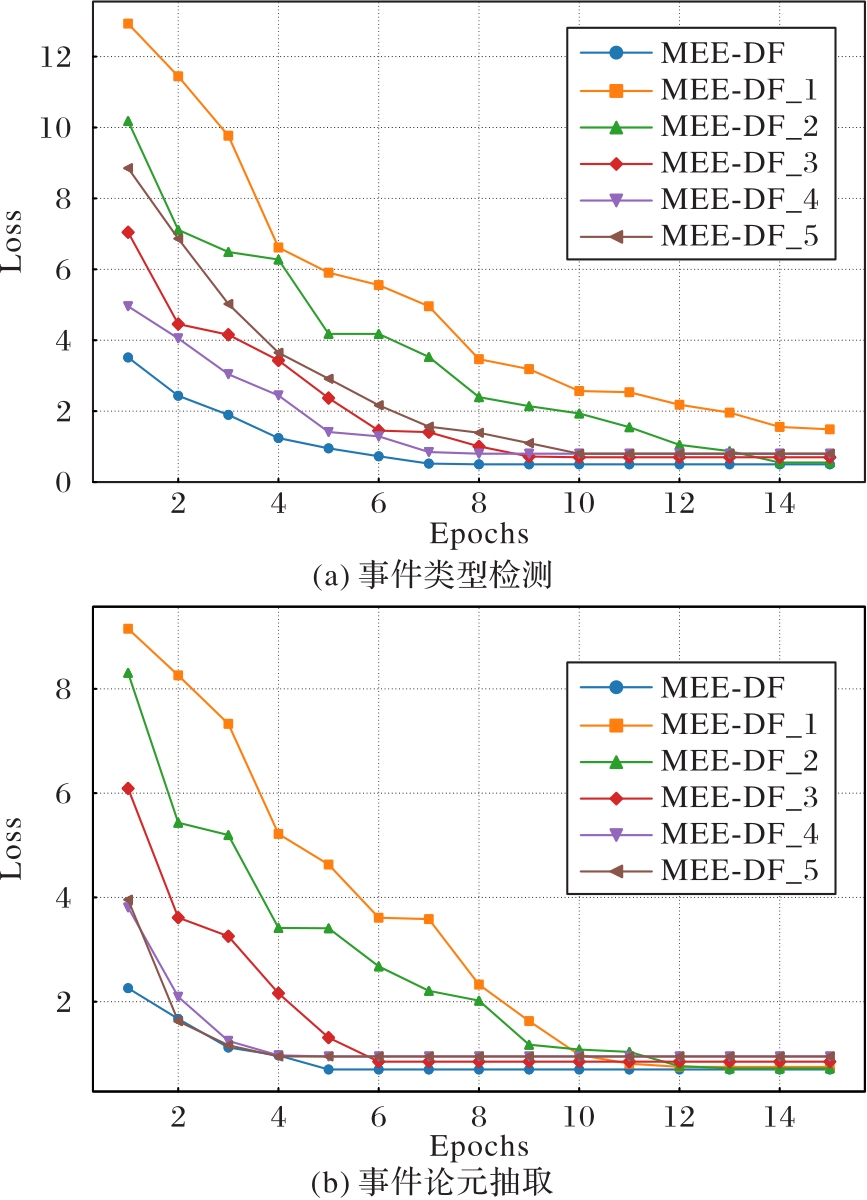
图8 M2E2数据集上不同模型的损失曲线
Fig. 8 Loss curves of different models on M2E2 dataset
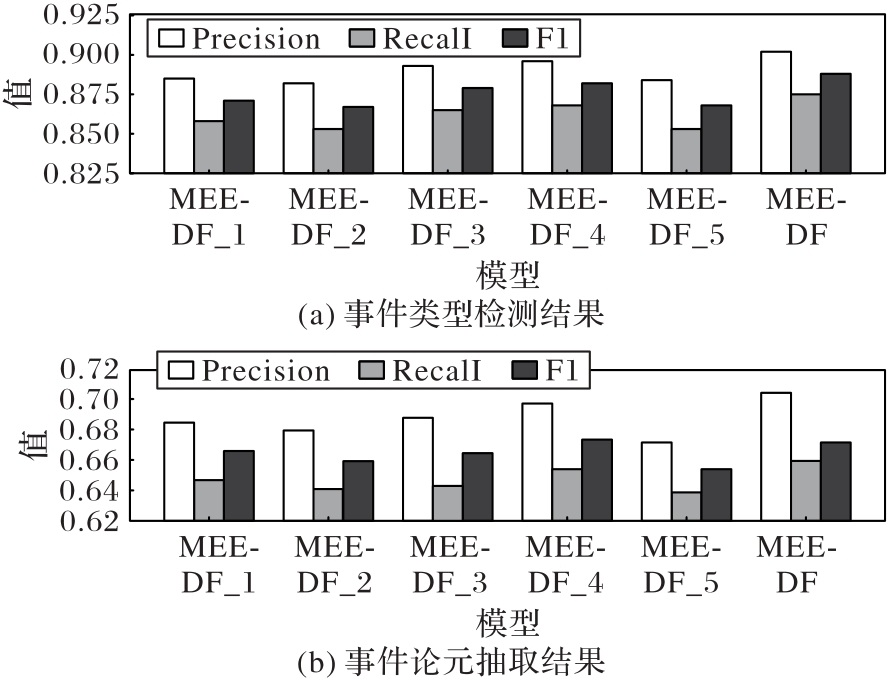
图9 M2E2数据集上的消融实验中不同模型的性能可视化
Fig. 9 Performance visualization of different models in ablation experiments on M2E2 dataset
| [1] | COORAY T, CHEUNG N M, LU W. Attention-based context aware reasoning for situation recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4735-4744. |
| [2] | 薛颂东,李永豪,赵红燕. 基于多粒度阅读器和图注意力网络的文档级事件抽取[J]. 计算机应用研究, 2024, 41(8): 2329-2335. |
| XUE S D, LI Y H, ZHAO H Y. Document level event extraction based on multi granularity readers and graph attention networks[J]. Application Research of Computers, 2024, 41(8): 2329-2335. | |
| [3] | YATSKAR M, ZETTLEMOYER L, FARHADI A. Situation recognition: visual semantic role labeling for image understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 5534-5542. |
| [4] | 左敏,王菲,宋绍义,等. “智慧+食品监管”:发展历程、应用现状与未来方向[J]. 食品科学技术学报, 2024, 42(3): 1-10. |
| ZUO M, WANG F, SONG S Y, et al. “Intelligence+food regulation”: development process, current application status, and future direction[J]. Journal of Food Science and Technology, 2024, 42(3): 1-10. | |
| [5] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [6] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [7] | LIU J, CHEN Y, XU J. Multimedia event extraction from news with a unified contrastive learning framework[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 1945-1953. |
| [8] | PAN Y, YAO T, LI Y, et al. X-Linear attention networks for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10968-10977. |
| [9] | LI M, XU R, WANG S, et al. CLIP-Event: connecting text and images with event structures[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16399-16408. |
| [10] | 葛唯益,程思伟,王羽,等. 基于双向门控循环神经网络的事件论元抽取方法[J]. 电子科技大学学报, 2022, 51(1): 100-107. |
| GE W Y, CHENG S W, WANG Y, et al. Bi-GRU-based event argument extraction approach[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(1): 100-107. | |
| [11] | 肖立中,殷晨旭. 融合预训练模型与注意力的事件抽取方法[J]. 计算机工程与应用, 2025, 61(4): 130-140. |
| XIAO L Z, YIN C X. Incorporating pre-trained model and attention mechanism for event extraction[J]. Computer Engineering and Applications, 2025, 61(4): 130-140. | |
| [12] | 周晓磊,梁宇龙,郭锐锋. 预训练多池注意力模型的事件论元抽取[J]. 小型微型计算机系统, 2025, 46(5): 1064-1071. |
| ZHOU X L, LIANG Y L, GUO R F. Event argument extraction using pre-trained multi-pooling attention models[J]. Journal of Chinese Computer Systems, 2025, 46(5): 1064-1071. | |
| [13] | WANG A, SUN Y, KORTYLEWSKI A, et al. Robust object detection under occlusion with context-aware CompositionalNets[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12642-12651. |
| [14] | DENG Y, LI Y, XIAN S, et al. MuAL: enhancing multimodal sentiment analysis with cross-modal attention and difference loss[J]. International Journal of Multimedia Information Retrieval, 2024, 13(3): No.31. |
| [15] | 苏杭,胡亚豪,潘志松. 利用提示调优融合多种信息的低资源事件抽取方法[J]. 计算机应用研究, 2024, 41(2): 381-387, 400. |
| SU H, HU Y H, PAN Z S. Low-resource event extraction method using multi-information fusion with prompt tuning[J]. Application Research of Computers, 2024, 41(2): 381-387, 400. | |
| [16] | NGUYEN T H, GRISHMAN R. Event detection and domain adaptation with convolutional neural networks[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2015: 365-371. |
| [17] | CHO J, YOON Y, KWAK S. Collaborative Transformers for grounded situation recognition[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19627-19636. |
| [18] | PRATT S, YATSKAR M, WEIHS L, et al. Grounded situation recognition[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12349. Cham: Springer, 2020: 314-332. |
| [19] | YATSKAR M, ORDONEZ V, ZETTLEMOYER L, et al. Commonly uncommon: semantic sparsity in situation recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6335-6344. |
| [20] | LI M, ZAREIAN A, ZENG Q, et al. Cross-media structured common space for multimedia event extraction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 2557-2568. |
| [21] | TONG M, WANG S, CAO Y, et al. Image enhanced event detection in news articles[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9040-9047. |
| [22] | ZHANG T, WHITEHEAD S, ZHANG H, et al. Improving event extraction via multimodal integration[C]// Proceedings of the 25th ACM International Conference on Multimedia. New York: ACM, 2017: 270-278. |
| [23] | DU Z, LI Y, GUO X, et al. Training multimedia event extraction with generated images and captions[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 5504-5513. |
| [24] | LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 12888-12900. |
| [25] | WANG S, ZHENG Q, SU Z, et al. MEED: a multimodal event extraction dataset[C]// Proceedings of the 2021 China Conference on Knowledge Graph and Semantic Computing, CCIS 1466. Singapore: Springer, 2021: 288-294. |
| [26] | MA Y, WANG Z, CAO Y, et al. Prompt for extraction? PAIE: prompting argument interaction for event argument extraction[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 6759-6774. |
| [27] | HE Y, HU J, TANG B. Revisiting event argument extraction: can EAE models learn better when being aware of event co-occurrences?[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 12542-12556. |
| [28] | MOGHIMIFAR F, SHIRI F, NGUYEN V, et al. Theia: weakly supervised multimodal event extraction from incomplete data[C]// Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2023: 139-145. |
| [29] | WU Z, KONG L, BI W, et al. Good for misconceived reasons: an empirical revisiting on the need for visual context in multimodal machine translation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 6153-6166. |
| [30] | LI Y, PANDA R, KIM Y, et al. VALHALLA: visual hallucination for machine translation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5206-5216. |
| [31] | LIU M, HU Z, ZHOU B, et al. Cross-modal event extraction based on adaptive feature selection and semantic-aware graph[J]. Knowledge-Based Systems, 2025, 326: No.114038. |
| [1] | 彭一峰, 朱焱. 结合预处理方法和对抗学习的公平链接预测[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2566-2571. |
| [2] | 丁美荣, 卓金鑫, 陆玉武, 刘庆龙, 郎济聪. 融合环境标签平滑与核范数差异的领域自适应[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1130-1138. |
| [3] | 安俊秀, 杨林旺, 柳源. 基于邻近性语义感知的无监督文本风格迁移[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1139-1147. |
| [4] | 曹铉, 罗天健. 运动想象脑电信号的跨被试动态多域对抗学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 645-653. |
| [5] | 姬张建, 张明, 王子龙. 基于改进VarifocalNet的高精度目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2147-2154. |
| [6] | 刘拥民, 杨钰津, 罗皓懿, 黄浩, 谢铁强. 基于双向循环生成对抗网络的无线传感网入侵检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 160-168. |
| [7] | 蒋宁, 方景龙, 杨庆. 基于单点多盒检测器的全局-局部层级的域适应目标检测[J]. 计算机应用, 2021, 41(2): 517-522. |
| [8] | 尹春勇, 章荪. 面向短文本情感分类的端到端对抗变分贝叶斯方法[J]. 计算机应用, 2020, 40(9): 2536-2542. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||