


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (6): 1796-1806.DOI: 10.11772/j.issn.1001-9081.2023060733
所属专题: 人工智能
沈君凤( ), 周星辰, 汤灿
), 周星辰, 汤灿
收稿日期:2023-06-09
修回日期:2023-08-13
接受日期:2023-08-15
发布日期:2023-09-14
出版日期:2024-06-10
通讯作者:
沈君凤
作者简介:周星辰(1998—),男,湖北襄阳人,硕士研究生,主要研究方向:文本分类、文本情感分析基金资助:
Junfeng SHEN(), Xingchen ZHOU, Can TANG
Received:2023-06-09
Revised:2023-08-13
Accepted:2023-08-15
Online:2023-09-14
Published:2024-06-10
Contact:
Junfeng SHEN
About author:ZHOU Xingchen, born in 1998, M. S. candidate. His research interests include text classification, text sentiment analysis.Supported by:摘要:
针对先前提示学习方法中存在的模板迭代更新周期长、泛化能力差等问题,基于改进的提示学习方法提出一种双通道的情感分析模型。首先,将序列化后的提示模板与输入词向量一起引入注意力机制结构,在输入词向量在多层注意力机制中更新的同时迭代更新提示模板;其次,在另一通道采用ALBERT(A Lite BERT (Bidirectional Encoder Representations from Transformers))模型提取语义信息;最后,输出用集成方式提取的语义特征,提升整体模型的泛化能力。所提模型在SemEval2014的Laptop和Restaurants数据集、ACL(Association for Computational Linguistics)的Twitter数据集和斯坦福大学创建的SST-2数据集上进行实验,分类准确率达到80.88%、91.78%、76.78%和95.53%,与基线模型BERT_Large相比,分别提升0.99%、1.13%、3.39%和2.84%;与P-tuning v2相比,所提模型的分类准确率在Restaurants数据集、Twitter数据集以及SST-2数据集上分别有2.88%、3.60%和2.06%的提升,且比原方法更早达到收敛状态。
中图分类号:
沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 计算机应用, 2024, 44(6): 1796-1806.
Junfeng SHEN, Xingchen ZHOU, Can TANG. Dual-channel sentiment analysis model based on improved prompt learning method[J]. Journal of Computer Applications, 2024, 44(6): 1796-1806.

图1 本文模型的结构
Fig. 1 Architecture of proposed model
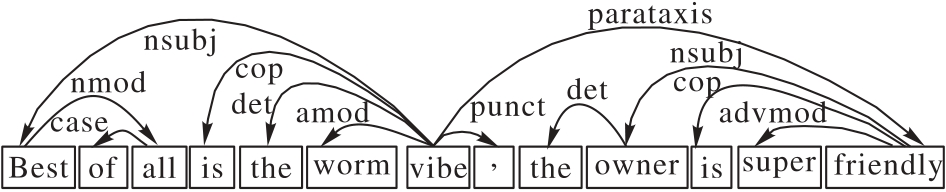
图2 语法依赖图
Fig.2 Syntactic dependency graph
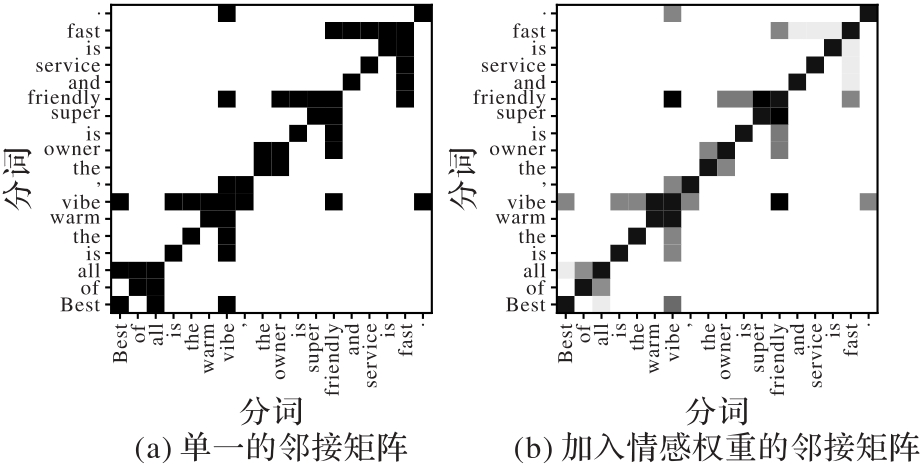
图3 加入情感权重前后邻接矩阵权值对比
Fig.3 Comparison of adjacency matrices weight values before and after adding emotion weights
| 输入 | 输出 |
|---|---|
| You are likely to find a overflow in a ___. | drain |
| Ravens can ___. | fly |
| Joke would make you want to ___. | laugh |
| Sometimes virus causes ___. | infection |
| Birds have ___. | feathers |
表1 手动构建模板示例
Tab. 1 Handcrafted template examples
| 输入 | 输出 |
|---|---|
| You are likely to find a overflow in a ___. | drain |
| Ravens can ___. | fly |
| Joke would make you want to ___. | laugh |
| Sometimes virus causes ___. | infection |
| Birds have ___. | feathers |
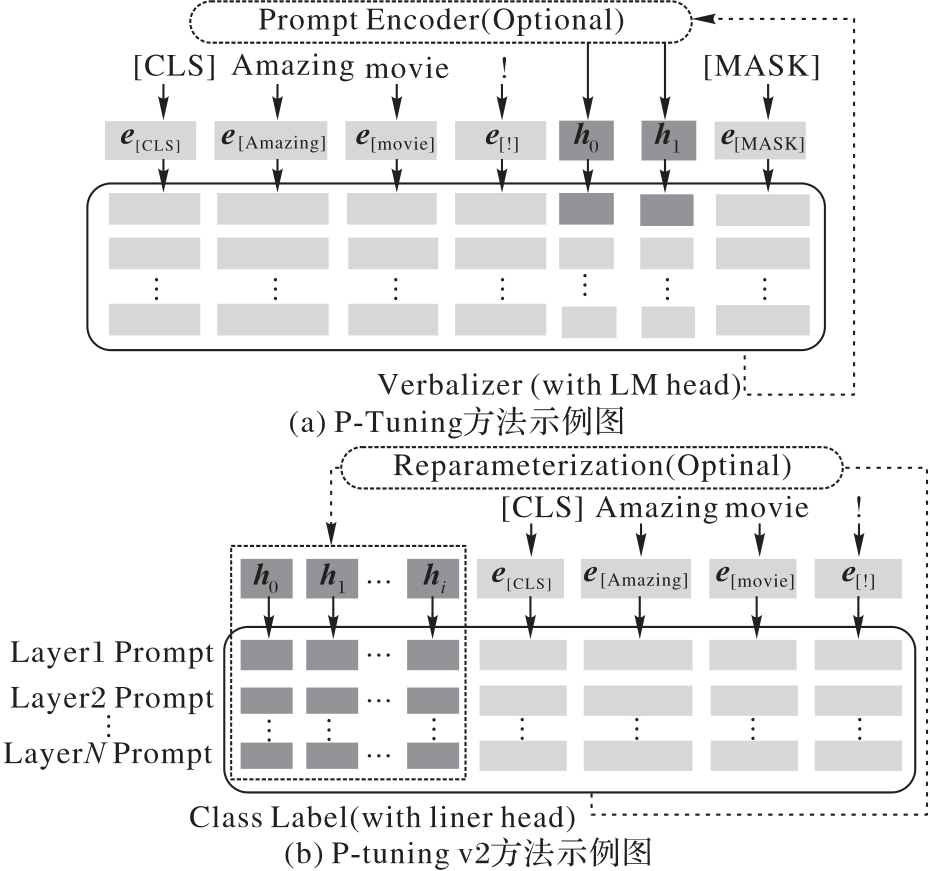
图4 P-Tuning方法与P-tuning v2方法对比
Fig.4 Comparison between P-Tuning method and P-tuning v2 method
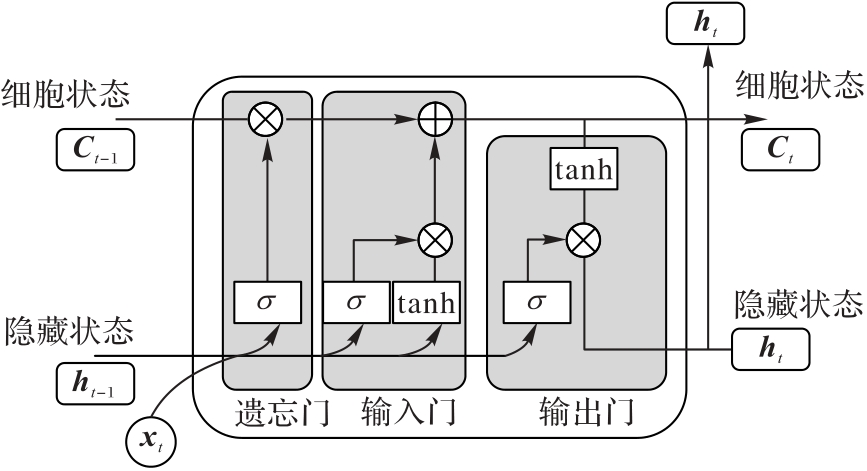
图5 LSTM结构
Fig. 5 Structure of LSTM
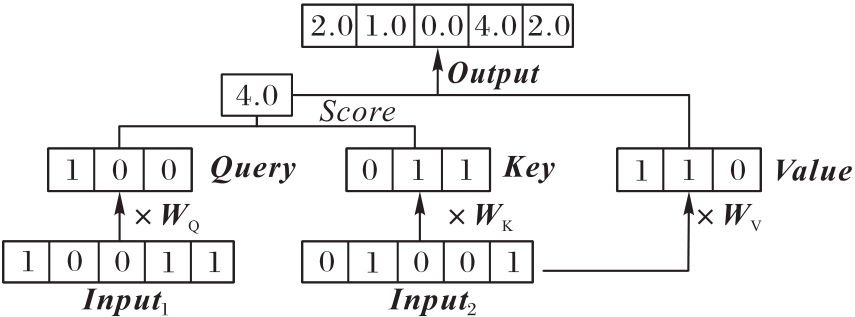
图6 交叉注意力结构
Fig. 6 Structure of cross-attention
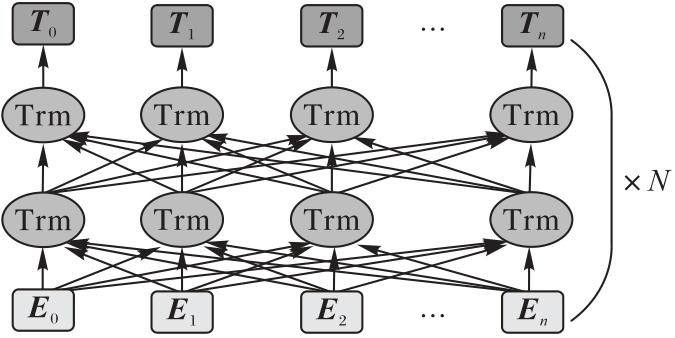
图7 BERT结构
Fig.7 Structure of BERT
样本 极性 | SST-2 | Lap14 | Rest14 | |||||
|---|---|---|---|---|---|---|---|---|
| train | test | train | test | train | test | train | test | |
| 共计 | 67 349 | 872 | 2 313 | 638 | 3 518 | 973 | 6 050 | 676 |
| 积极 | 29 780 | 428 | 987 | 341 | 2 179 | 657 | 1 507 | 172 |
| 消极 | 37 569 | 444 | 866 | 128 | 839 | 222 | 1 527 | 168 |
| 中性 | 0 | 0 | 460 | 169 | 500 | 94 | 3 016 | 336 |
表2 数据集样本极性分布统计
Tab. 2 Statistics of polarity distribution of dataset samples
样本 极性 | SST-2 | Lap14 | Rest14 | |||||
|---|---|---|---|---|---|---|---|---|
| train | test | train | test | train | test | train | test | |
| 共计 | 67 349 | 872 | 2 313 | 638 | 3 518 | 973 | 6 050 | 676 |
| 积极 | 29 780 | 428 | 987 | 341 | 2 179 | 657 | 1 507 | 172 |
| 消极 | 37 569 | 444 | 866 | 128 | 839 | 222 | 1 527 | 168 |
| 中性 | 0 | 0 | 460 | 169 | 500 | 94 | 3 016 | 336 |
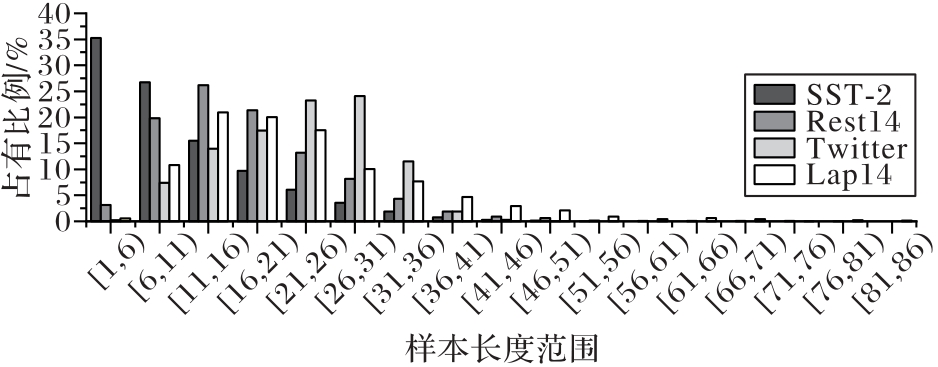
图8 数据样本长度分布
Fig.8 Data sample length distribution
| 超参数 | 左通道 | 右通道 |
|---|---|---|
| Batch size | 32 | 32 |
| Learning rate | ||
| Weight decay | 0.01 | |
| Prefix_length | — | 20 |
| Prefix_att_rate | — | 0.1 |
| GCN layers | — | 2 |
| Hidden size | 2 048 | 1 024 |
| Padding_length | 55 | 55 |
| Dropout | 0.5 | 0.5 |
表3 模型超参数
Tab. 3 Model hyperparameters
| 超参数 | 左通道 | 右通道 |
|---|---|---|
| Batch size | 32 | 32 |
| Learning rate | ||
| Weight decay | 0.01 | |
| Prefix_length | — | 20 |
| Prefix_att_rate | — | 0.1 |
| GCN layers | — | 2 |
| Hidden size | 2 048 | 1 024 |
| Padding_length | 55 | 55 |
| Dropout | 0.5 | 0.5 |
| 模型 | STT-2 | Lap14 | Rest14 | |||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | |||||
| GloVe_LSTM | 85.58 | 85.58 | 68.17 | 68.12 | 77.50 | 76.35 | 68.64 | 68.45 |
| GloVe_BiLSTM_TextCNN | 88.18 | 88.18 | 71.16 | 70.15 | 84.28 | 84.00 | 71.45 | 71.32 |
| ATAE_LSTM | — | — | 68.20 | — | 77.20 | — | — | — |
| AEN_BERT | — | — | 79.93 | 76.31 | 83.12 | 73.76 | 74.71 | 73.13 |
| BERT_base | 91.20 | 91.20 | 78.53 | 78.52 | 89.11 | 88.66 | 73.82 | 73.76 |
| BERT_Large | 92.89 | 92.89 | 80.09 | 79.93 | 90.75 | 90.75 | 74.26 | 74.10 |
| BERT_TextCNN | 93.23 | 93.23 | 80.56 | 80.65 | 89.93 | 89.47 | 74.70 | 74.58 |
| P-tuning v2(BERT_Large) | 93.60 | 93.60 | 81.97 | 82.05 | 89.21 | 88.91 | 74.11 | 73.99 |
| P-Tuning(our) | 94.61 | 94.61 | 81.03 | 81.26 | 90.03 | 89.90 | 75.15 | 74.97 |
| ALBERT_xlarge | 95.30 | 95.30 | 79.00 | 78.57 | 91.16 | 90.91 | 74.85 | 74.85 |
| 本文模型 | 95.53 | 95.53 | 80.88 | 80.81 | 91.78 | 91.54 | 76.78 | 76.48 |
表4 对比实验结果 (%)
Tab. 4 Comparison experiment results
| 模型 | STT-2 | Lap14 | Rest14 | |||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Accuracy | Accuracy | Accuracy | |||||
| GloVe_LSTM | 85.58 | 85.58 | 68.17 | 68.12 | 77.50 | 76.35 | 68.64 | 68.45 |
| GloVe_BiLSTM_TextCNN | 88.18 | 88.18 | 71.16 | 70.15 | 84.28 | 84.00 | 71.45 | 71.32 |
| ATAE_LSTM | — | — | 68.20 | — | 77.20 | — | — | — |
| AEN_BERT | — | — | 79.93 | 76.31 | 83.12 | 73.76 | 74.71 | 73.13 |
| BERT_base | 91.20 | 91.20 | 78.53 | 78.52 | 89.11 | 88.66 | 73.82 | 73.76 |
| BERT_Large | 92.89 | 92.89 | 80.09 | 79.93 | 90.75 | 90.75 | 74.26 | 74.10 |
| BERT_TextCNN | 93.23 | 93.23 | 80.56 | 80.65 | 89.93 | 89.47 | 74.70 | 74.58 |
| P-tuning v2(BERT_Large) | 93.60 | 93.60 | 81.97 | 82.05 | 89.21 | 88.91 | 74.11 | 73.99 |
| P-Tuning(our) | 94.61 | 94.61 | 81.03 | 81.26 | 90.03 | 89.90 | 75.15 | 74.97 |
| ALBERT_xlarge | 95.30 | 95.30 | 79.00 | 78.57 | 91.16 | 90.91 | 74.85 | 74.85 |
| 本文模型 | 95.53 | 95.53 | 80.88 | 80.81 | 91.78 | 91.54 | 76.78 | 76.48 |
| 消融模块 | 模型 | SST-2 | Lap14 | Rest14 | |
|---|---|---|---|---|---|
| 序列化模块 | P-tuning v2 | 93.60 | 81.97 | 89.21 | 74.11 |
| Prefix_BiLSTM | 93.68 | 80.09 | 89.62 | 75.00 | |
| Prefix_Att_BiLSTM | 94.61 | 81.03 | 90.03 | 75.15 | |
| 情感权重模块 | Prefix_adj_Gcn | 94.69 | 80.88 | 90.34 | 76.04 |
| Prefix_senti_Gcn | 94.72 | 81.19 | 90.44 | 76.92 | |
| 对抗训练实验 | GloVe_BiLSTM_TextCNN | 88.18 | 71.16 | 84.28 | 71.45 |
| GloVe_BiLSTM_TextCNN(adv) | 88.30 | 72.57 | 84.89 | 72.63 | |
| BERT_base | 91.20 | 78.53 | 89.11 | 72.82 | |
| BERT_adv | 94.15 | 79.47 | 90.34 | 76.63 | |
| ALBERT_xlarge | 95.30 | 79.00 | 91.78 | 74.58 | |
| ALBERT_adv | 95.30 | 80.88 | 91.16 | 76.78 |
表5 消融实验准确率结果 (%)
Tab. 5 Ablation experiment accuracy results
| 消融模块 | 模型 | SST-2 | Lap14 | Rest14 | |
|---|---|---|---|---|---|
| 序列化模块 | P-tuning v2 | 93.60 | 81.97 | 89.21 | 74.11 |
| Prefix_BiLSTM | 93.68 | 80.09 | 89.62 | 75.00 | |
| Prefix_Att_BiLSTM | 94.61 | 81.03 | 90.03 | 75.15 | |
| 情感权重模块 | Prefix_adj_Gcn | 94.69 | 80.88 | 90.34 | 76.04 |
| Prefix_senti_Gcn | 94.72 | 81.19 | 90.44 | 76.92 | |
| 对抗训练实验 | GloVe_BiLSTM_TextCNN | 88.18 | 71.16 | 84.28 | 71.45 |
| GloVe_BiLSTM_TextCNN(adv) | 88.30 | 72.57 | 84.89 | 72.63 | |
| BERT_base | 91.20 | 78.53 | 89.11 | 72.82 | |
| BERT_adv | 94.15 | 79.47 | 90.34 | 76.63 | |
| ALBERT_xlarge | 95.30 | 79.00 | 91.78 | 74.58 | |
| ALBERT_adv | 95.30 | 80.88 | 91.16 | 76.78 |
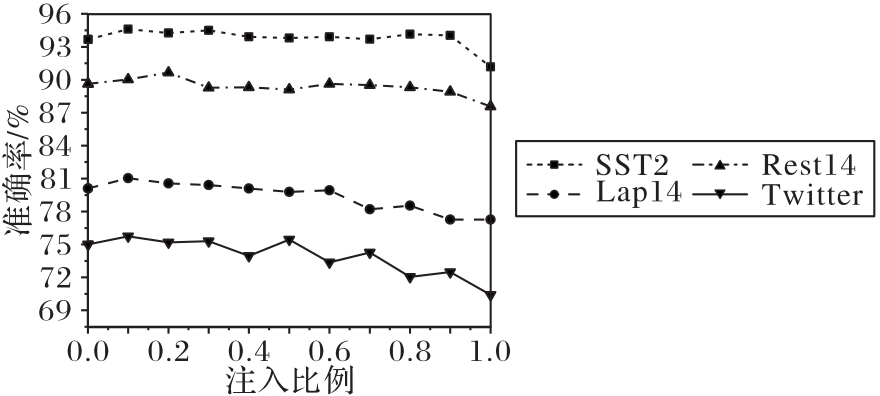
图9 输入不同比例的样本信息方案消融实验结果
Fig.9 Ablation experiment results of schemes with different proportions of sample information
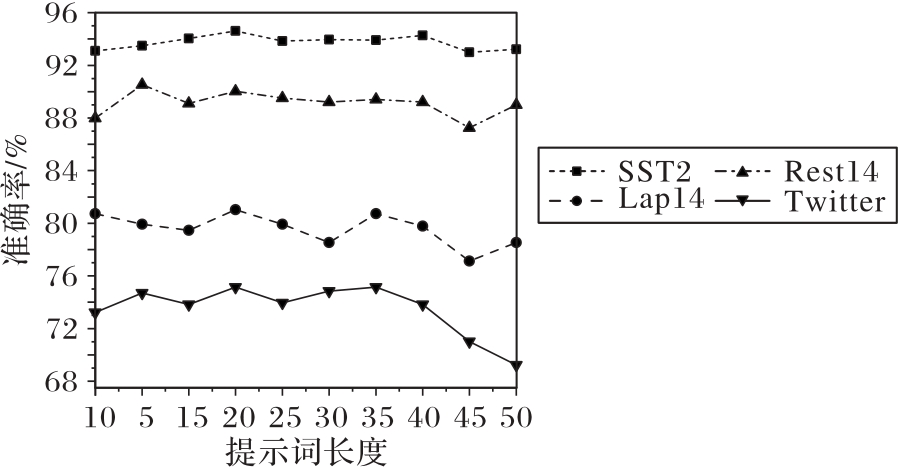
图10 不同长度的提示模板实验结果
Fig.10 Experiment results of prompt templates with different lengths
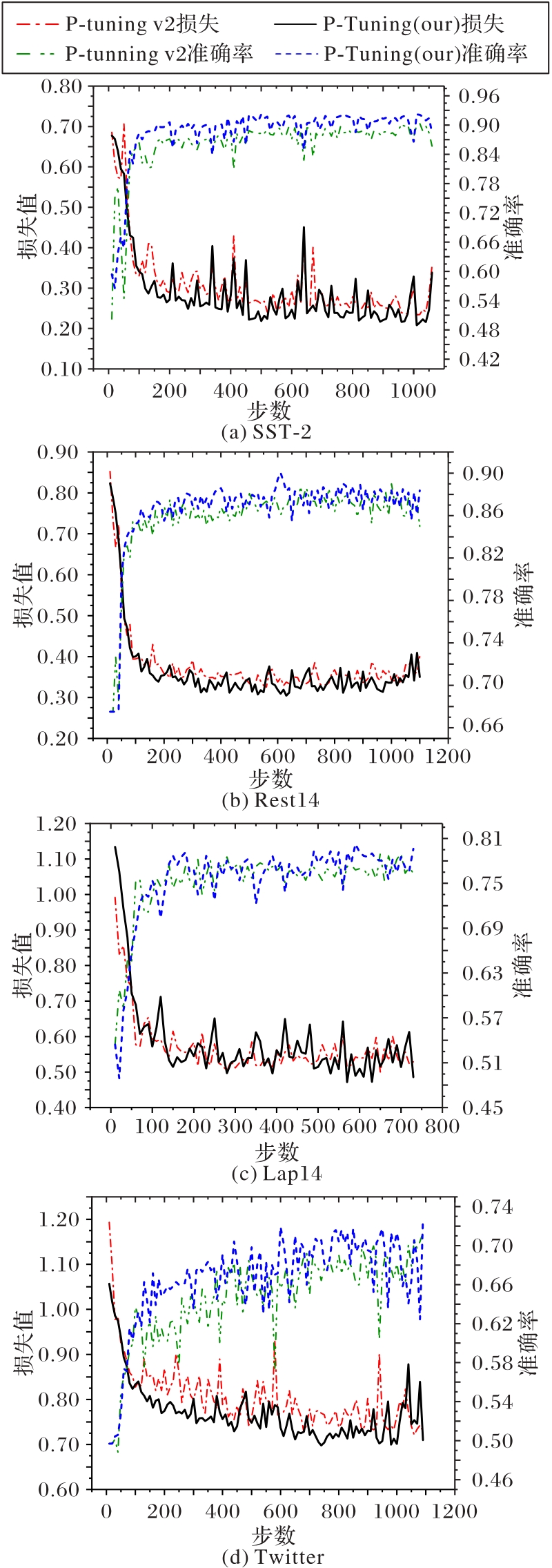
图11 不同模型在各数据集上的损失和准确率
Fig. 11 Losses and accuracies of different models on each dataset
| 1 | 江洋洋,金伯,张宝昌. 深度学习在自然语言处理领域的研究进展[J]. 计算机工程与应用, 2021, 57(22): 1-14. |
| JIANG Y Y, JIN B, ZHANG B C. Research progress of natural language processing based on deep learning [J]. Computer Engineering and Applications, 2021, 57(22): 1-14. | |
| 2 | SMITH S, PATWARY M, NORICK B, et al. Using DeepSpeed and Megatron to train Megatron-Turing NLG 530B, a large-scale generative language model [EB/OL]. (2022-02-04)[2023-05-30]. . |
| 3 | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation [EB/OL]. (2021-07-05)[2023-05-30]. . |
| 4 | WU S, ZHAO X, YU T, et al. Yuan 1.0: large-scale pre-trained language model in zero-shot and few-shot learning [EB/OL]. (2021-10-12)[2023-05-30]. . |
| 5 | HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP [EB/OL]. (2019-06-09)[2023-05-30]. . |
| 6 | WANG A, SINGH A, MICHAEL J, et al. GLUE: a multi-task benchmark and analysis platform for natural language understanding [EB/OL]. (2018-04-20)[2023-05-30]. . |
| 7 | LIU X, ZHENG Y, DU Z, et al. GPT understands, too [EB/OL]. (2021-03-18)[2023-05-30]. . |
| 8 | LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [EB/OL]. (2021-01-01)[2023-05-30]. . |
| 9 | LIU X, JI K, FU Y, et al. P-tuning v2: prompt tuning can be comparable to fine-tuning universally across scales and tasks [EB/OL]. (2021-10-14)[2023-05-30]. . |
| 10 | LESTER B, AL-RFOU R, CONSTANT N. The power of scale for parameter-efficient prompt tuning [EB/OL]. (2021-04-18) [2023-05-30]. . |
| 11 | KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences [EB/OL]. (2014-04-08)[2023-05-30]. . |
| 12 | KIM Y. Convolutional neural networks for sentence classification [EB/OL]. (2014-08-25)[2023-05-30]. . |
| 13 | SOCHER R, LIN C C-Y, NG A Y, et al. Parsing natural scenes and natural language with recursive neural networks[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 129-136. |
| 14 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 15 | CHUNG J, GULCEHRE C, CHO K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [EB/OL]. (2014-12-11)[2023-05-30]. . |
| 16 | PAN S J, YANG Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359. |
| 17 | PAN S J, TSANG I W, KWOK J T, et al. Domain adaptation via transfer component analysis [J]. IEEE Transactions on Neural Networks, 2010, 22(2): 199-210. |
| 18 | LONG M, WANG J, DING G, et al. Transfer feature learning with joint distribution adaptation [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 2200-2207. |
| 19 | WEISS K, KHOSHGOFTAAR T M, WANG D D. A survey of transfer learning [J]. Journal of Big Data, 2016, 3: No. 9. |
| 20 | DAY O, KHOSHGOFTAAR T M. A survey on heterogeneous transfer learning [J]. Journal of Big Data, 2017, 4: No. 29. |
| 21 | PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2018:2227-2237. |
| 22 | RADFORD A, NARASIMHAN K, SALIMANS T,et al. Improving language understanding by generative pre-training [EB/OL]. [2023-05-30]. . |
| 23 | VASWANI A, SHAZEER N, PARMAR N,et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc, 2017:6000-6010. |
| 24 | DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2018-10-11)[2023-05-30]. . |
| 25 | YU J, JIANG J. Adapting BERT for target-oriented multimodal sentiment classification [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2019:5408-5414. |
| 26 | 方澄,李贝,韩萍,等.基于语法依存图的中文微博细粒度情感分类[J]. 计算机应用, 2023, 43(4): 1056-1061. |
| FANG C, LI B, HAN P, et al. Fine-grained emotion classification of Chinese microblog based on syntactic dependency graph[J]. Journal of Computer Applications, 2023, 43(4): 1056-1061. | |
| 27 | YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding [EB/OL]. [2020-05-26]. . |
| 28 | PFEIFFER J, KAMATH A, RÜCKLÉ A,et al. AdapterFusion:non-destructive task composition for transfer learning [EB/OL]. (2020-05-01)[2023-05-30]. . |
| 29 | RÜCKLÉ A, GEIGLE G, GLOCKNER M, et al. AdapterDrop: on the efficiency of adapters in transformers [EB/OL]. (2020-10-22)[2023-05-30]. . |
| 30 | GAO T, FISCH A, CHEN D. Making pre-trained language models better few-shot learners [EB/OL]. (2020-12-31)[2023-05-30]. . |
| 31 | SHIN T, RAZEGHI Y, LOGAN IV R L, et al. AutoPrompt:eliciting knowledge from language models with automatically generated prompts [EB/OL]. (2020-10-29)[2023-05-30]. . |
| 32 | 张心月,刘蓉,魏驰宇,等.融合提示知识的方面级情感分析[J].计算机应用, 2023, 43(9): 2753-2759. |
| ZHANG X Y, LIU R, WEI C Y, et al. Aspect-based sentiment analysis method with integrating prompt knowledge [J]. Journal of Computer Applications, 2023, 43(9): 2753-2759. | |
| 33 | MARGATINA K, BAZIOTIS C, POTAMIANOS A. Attention-based conditioning methods for external knowledge integration [EB/OL]. (2019-06-09)[2023-05-30]. . |
| 34 | BAO L, LAMBERT P, BADIA T. Attention and lexicon regularized LSTM for aspect-based sentiment analysis[C]/ /Proceedings of the 57th Annual Meeting of the Association For Computational Linguistics: Student Research Workshop. Stroudsburg: ACL, 2019: 253-259. |
| 35 | CAMBRIA E, LI Y, XING F Z, et al. SenticNet 6: ensemble application of symbolic and subsymbolic AI for sentiment analysis[C]// Proceedings of the 29th ACM International Conference on Information & Knowledge Management. New York: ACM, 2020: 105-114. |
| 36 | PETRONI F, ROCKTÄSCHEL T, LEWIS P, et al. Language models as knowledge bases? [EB/OL].(2019-09-03)[2023-05-30]. . |
| 37 | MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks [EB/OL]. (2017-06-09)[2023-05-30]. . |
| 38 | WANG Y, HUANG M, ZHU X, et al. Attention-based LSTM for aspect-level sentiment classification[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2016: 606-615. |
| 39 | SONG Y, WANG J, JIANG T, et al. Targeted sentiment classification with attentional encoder network [C]// Proceedings of the 28th International Conference on Artificial Neural Networks. Cham: Springer, 2019: 93-103. |
| [1] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [2] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| [3] | 游新冬, 问英姿, 佘鑫鹏, 吕学强. 面向煤矿机电设备领域的三元组抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2026-2033. |
| [4] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [5] | 吴锦富, 柳毅. 基于随机噪声和自适应步长的快速对抗训练方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1807-1815. |
| [6] | 余新言, 曾诚, 王乾, 何鹏, 丁晓玉. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1767-1774. |
| [7] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [8] | 余杭, 周艳玲, 翟梦鑫, 刘涵. 基于预训练模型与标签融合的文本分类[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 709-714. |
| [9] | 赖华, 孙童, 王文君, 余正涛, 高盛祥, 董凌. 多模态特征的越南语语音识别文本标点恢复[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 418-423. |
| [10] | 王星, 刘贵娟, 陈志豪. 高斯混合模型与文本图卷积网络结合的虚假评论识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 360-368. |
| [11] | 高颖杰, 林民, 斯日古楞null, 李斌, 张树钧. 基于片段抽取原型网络的古籍文本断句标点提示学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3815-3822. |
| [12] | 郭晓, 陈艳平, 唐瑞雪, 黄瑞章, 秦永彬. 融合行为词的罪名预测多任务学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 159-166. |
| [13] | 陈彤, 位纪伟, 何仕远, 宋井宽, 杨阳. 基于自适应攻击强度的对抗训练方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 94-100. |
| [14] | 于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740. |
| [15] | 张小艳, 段正宇. 基于句级别GAN的跨语言零资源命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2406-2411. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||