


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (8): 2626-2633.DOI: 10.11772/j.issn.1001-9081.2023081120
何浩东1, 符浩1,2( ), 王强1, 周帅1, 刘伟1
), 王强1, 周帅1, 刘伟1
收稿日期:2023-08-22
修回日期:2023-11-16
接受日期:2023-11-24
发布日期:2023-12-18
出版日期:2024-08-10
通讯作者:
符浩
作者简介:何浩东(1997—),男,四川巴中人,硕士研究生,主要研究方向:多机器人智能控制、强化学习基金资助:
Haodong HE1, Hao FU1,2(), Qiang WANG1, Shuai ZHOU1, Wei LIU1
Received:2023-08-22
Revised:2023-11-16
Accepted:2023-11-24
Online:2023-12-18
Published:2024-08-10
Contact:
Hao FU
About author:HE Haodong, born in 1997, M. S. candidate. His research interests include multi-robot intelligent control, reinforcement learning.Supported by:摘要:
针对多机器人在人群环境中路径跟随与编队的避障及运动轨迹平滑性问题,提出基于深度强化学习的多机器人路径跟随与编队算法。首先,建立行人危险性优先级机制,结合行人危险性优先级机制与强化学习设计危险意识网络,提高多机器人编队的安全性;然后,引入虚拟机器人作为多机器人的跟随目标,将路径跟随转化为多机器人对虚拟机器人的跟随控制,提高机器人运动轨迹的平滑性;最后,通过仿真实验将所提算法与现有算法进行对比,同时进行定量与定性分析。实验结果表明,与现有点对点的路径跟随算法相比,所提算法在人群环境下具有优异的避障性能,可保证多机器人运动轨迹的平滑性。
中图分类号:
何浩东, 符浩, 王强, 周帅, 刘伟. 基于深度强化学习的多机器人路径跟随与编队[J]. 计算机应用, 2024, 44(8): 2626-2633.
Haodong HE, Hao FU, Qiang WANG, Shuai ZHOU, Wei LIU. Multi-robot path following and formation based on deep reinforcement learning[J]. Journal of Computer Applications, 2024, 44(8): 2626-2633.

图1 路径跟随与编队环境
Fig. 1 Path following and formation environment

图2 虚拟机器人结构的示意图
Fig. 2 Schematic diagram of virtual robot structure
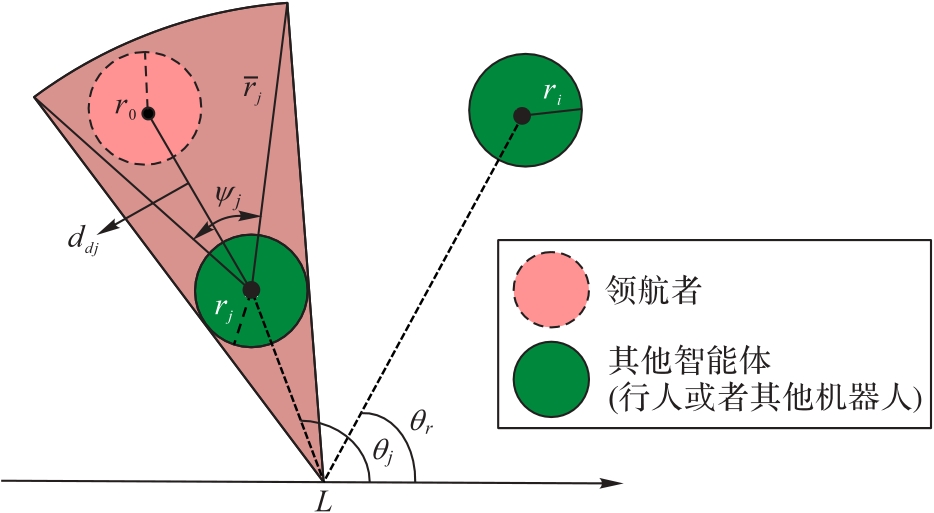
图3 危险区域
Fig. 3 Danger zone

图4 价值网络模型
Fig. 4 Value network model

图5 整体网络的构架
Fig. 5 Framework of overall network
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 输入维度 | 14 | 全连接层 | (150,100,100) |
| 激活函数 | ReLU | 迭代次数 | 104 |
| 优化器 | Adam | 行人数 | 6 |
| 学习率 | 10-4 | 更新回合C | 1 |
| Nb | 128 | 机器人速度 | 0.3 m/s |
| LSTM隐层 | 50 | 行人速度 | 0.3 m/s |
表1 实验参数
Tab. 1 Experimental parameters
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| 输入维度 | 14 | 全连接层 | (150,100,100) |
| 激活函数 | ReLU | 迭代次数 | 104 |
| 优化器 | Adam | 行人数 | 6 |
| 学习率 | 10-4 | 更新回合C | 1 |
| Nb | 128 | 机器人速度 | 0.3 m/s |
| LSTM隐层 | 50 | 行人速度 | 0.3 m/s |
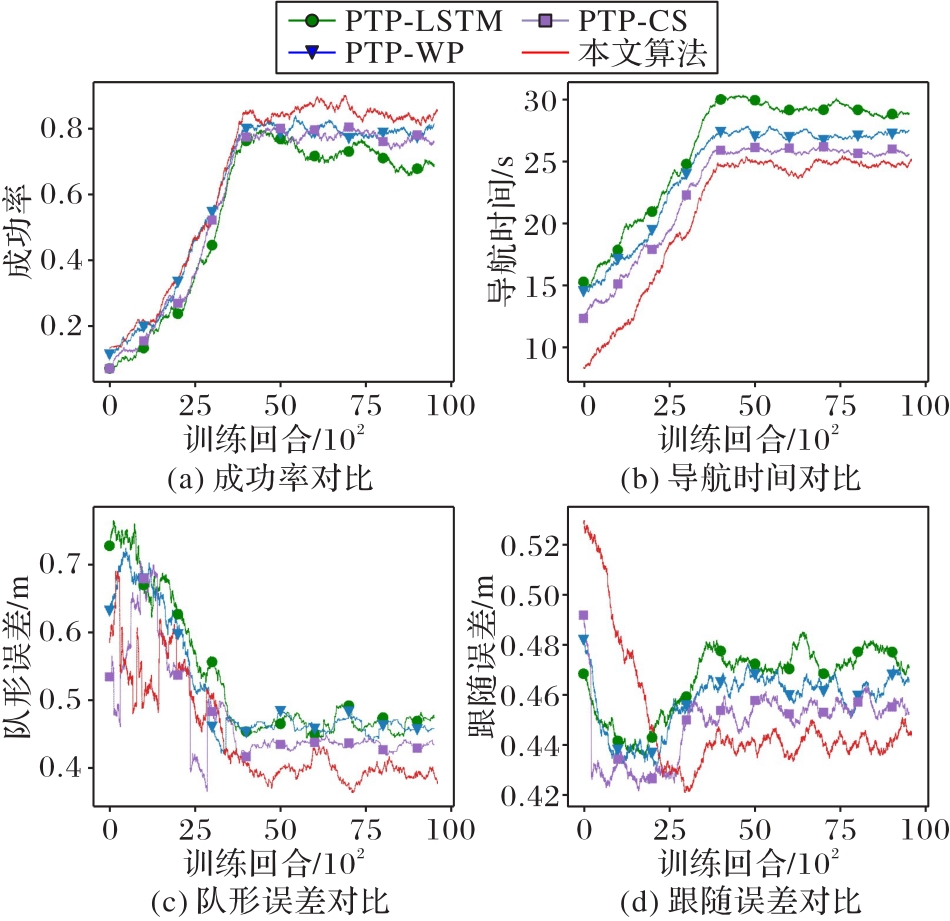
图6 4种算法的不同指标训练曲线
Fig. 6 Different metrics training curves of four algorithms
| 行人数 | 算法 | 成功率/% | 导航 时间/s | 队形 误差/m | 跟随 误差/m |
|---|---|---|---|---|---|
| 6 | PTP-LSTM | 76 | 29.8 | 0.435 | 0.484 |
| PTP-WP | 79 | 25.4 | 0.471 | 0.463 | |
| PTP-CS | 76 | 24.2 | 0.422 | 0.456 | |
| 本文算法 | 86 | 23.8 | 0.371 | 0.443 | |
| 8 | PTP-LSTM | 70 | 26.2 | 0.572 | 0.551 |
| PTP-WP | 73 | 27.8 | 0.532 | 0.612 | |
| PTP-CS | 71 | 27.4 | 0.490 | 0.578 | |
| 本文算法 | 82 | 24.6 | 0.414 | 0.461 | |
| 10 | PTP-LSTM | 63 | 28.4 | 0.681 | 0.614 |
| PTP-WP | 65 | 28.0 | 0.566 | 0.635 | |
| PTP-CS | 64 | 28.1 | 0.584 | 0.687 | |
| 本文算法 | 80 | 25.8 | 0.507 | 0.495 |
表2 定量评估结果
Tab. 2 Quantitative evaluation results
| 行人数 | 算法 | 成功率/% | 导航 时间/s | 队形 误差/m | 跟随 误差/m |
|---|---|---|---|---|---|
| 6 | PTP-LSTM | 76 | 29.8 | 0.435 | 0.484 |
| PTP-WP | 79 | 25.4 | 0.471 | 0.463 | |
| PTP-CS | 76 | 24.2 | 0.422 | 0.456 | |
| 本文算法 | 86 | 23.8 | 0.371 | 0.443 | |
| 8 | PTP-LSTM | 70 | 26.2 | 0.572 | 0.551 |
| PTP-WP | 73 | 27.8 | 0.532 | 0.612 | |
| PTP-CS | 71 | 27.4 | 0.490 | 0.578 | |
| 本文算法 | 82 | 24.6 | 0.414 | 0.461 | |
| 10 | PTP-LSTM | 63 | 28.4 | 0.681 | 0.614 |
| PTP-WP | 65 | 28.0 | 0.566 | 0.635 | |
| PTP-CS | 64 | 28.1 | 0.584 | 0.687 | |
| 本文算法 | 80 | 25.8 | 0.507 | 0.495 |

图7 PTP-LSTM仿真结果
Fig. 7 Simulation results of PTP-LSTM

图8 PTP-WP仿真结果
Fig. 8 Simulation results of PTP-WP
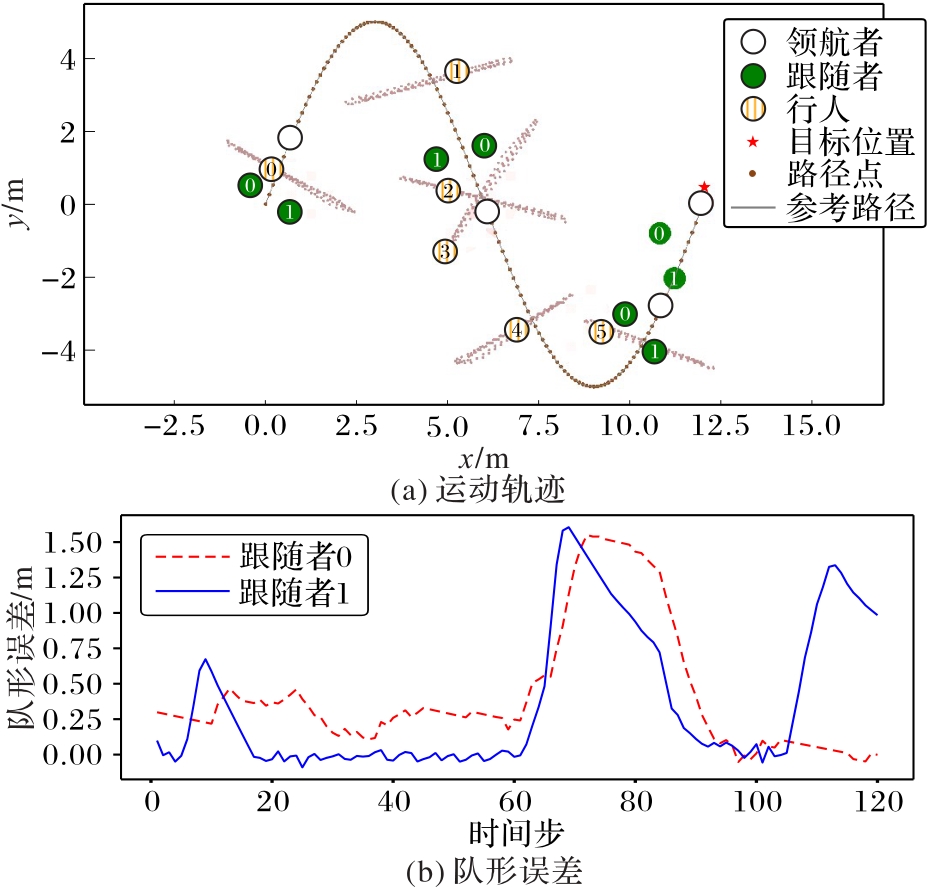
图9 PTP-CS仿真结果
Fig. 9 Simulation results of PTP-CS
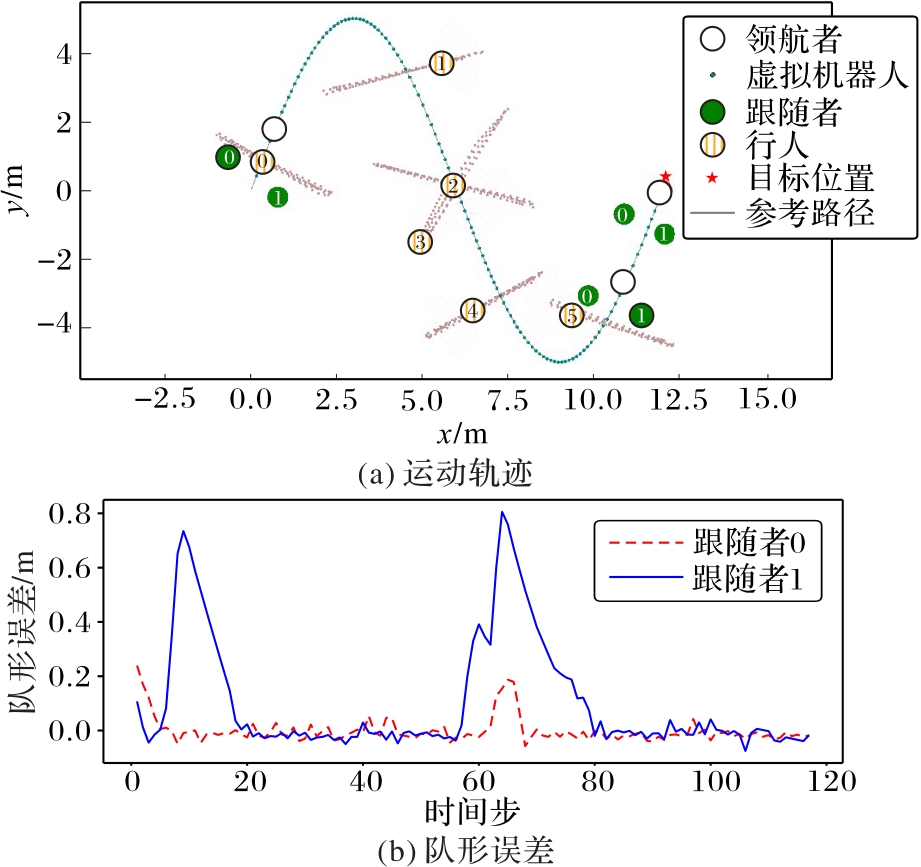
图10 本文算法仿真结果
Fig. 10 Simulation results of proposed algorithm

图11 菱形队形仿真结果
Fig. 11 Diamond formation simulation results
| 1 | 陈佳盼,郑敏华.基于深度强化学习的机器人操作行为研究综述[J].机器人,2022, 44(2): 236-256. |
| CHEN J P, ZHENG M H. A survey of robot manipulation behavior research based on deep reinforcement learning [J]. Robot, 2022, 44(2): 236-256. | |
| 2 | 户晓玲,王健安.一种多机器人分布式编队策略与实现[J].计算机技术与发展,2019, 29(1): 21-25. |
| HU X L, WANG J A. A multi-robot distributed formation strategy and implementation [J]. Computer Technology and Development, 2019, 29(1): 21-25. | |
| 3 | 罗京,刘成林,刘飞.多移动机器人的领航-跟随编队避障控制[J].智能系统学报, 2017, 12(2): 202-212. |
| LUO J, LIU C L, LIU F. Pilot-following formation and obstacle avoidance control of multiple mobile robots [J]. CAAI Transactions on Intelligent Systems, 2017, 12(2): 202-212. | |
| 4 | 秦留界,宋光明,毛巨正,等. 基于手眼双模态人机接口的移动机器人编队共享控制[J].机器人, 2022, 44(3): 343-351. |
| QIN L J, SONG G M, MAO J Z, et al. Shared control of multi-robot formations based on the eye-hand dual-modal human-robot interface [J]. Robot, 2022, 44(3): 343-351. | |
| 5 | HACENE N, MENDIL B. Behavior-based autonomous navigation and formation control of mobile robots in unknown cluttered dynamic environments with dynamic target tracking [J]. International Journal of Automation and Computing, 2021, 18: 766-786. |
| 6 | 安永跃,李淑琴.基于行为规划的多机器鱼编队策略的研究[J].计算机仿真,2013,30(11):369-373. |
| AN Y Y, LI S Q. Study of multiple robotic fishes formation strategy based on behavior planning method [J]. Computer Simulation, 2013, 30(11): 369-373. | |
| 7 | LIU J, YIN T, YUE D, et al. Event-based secure leader-following consensus control for multiagent systems with multiple cyber attacks [J]. IEEE Transactions on Cybernetics, 2021, 51(1): 162-173. |
| 8 | DONG L, CHEN Y, QU X. Formation control strategy for nonholonomic intelligent vehicles based on virtual structure and consensus approach [J]. Procedia Engineering, 2016, 137: 415-424. |
| 9 | LEE G, CHWA D. Decentralized behavior-based formation control of multiple robots considering obstacle avoidance [J]. Intelligent Service Robotics, 2018, 11: 127-138. |
| 10 | LIU X, GE S S, C-H GOH. Vision-based leader-follower formation control of multiagents with visibility constraints [J]. IEEE Transactions on Control Systems Technology, 2019, 27(3): 1326-1333. |
| 11 | 李咏华,张立,刘嘉睿,等.领航-跟随型多移动小车滑模编队控制[J].重庆理工大学学报(自然科学版), 2022, 36(7): 18-27. |
| LI Y H, ZHANG L, LIU J R, et al. Sliding mode formation control of leader-follower multi-mobile cars [J]. Journal of Chongqing University of Technology (Natural Science), 2022, 36(7): 18-27. | |
| 12 | LIANG X, QU X, WANG N, et al. Swarm control with collision avoidance for multiple underactuated surface vehicles [J]. Ocean Engineering, 2019, 191: 106516. |
| 13 | PARK B S, YOO S J. Adaptive-observer-based formation tracking of networked uncertain underactuated surface vessels with connectivity preservation and collision avoidance [J]. Journal of the Franklin Institute, 2019, 356(15): 7947-7966. |
| 14 | 胡阳修,贺亮,赵长春,等.基于路径跟随的改进领航-跟随无人机协同编队方法[J].飞控与探测, 2021, 4(2):26-35. |
| HU Y X, HE L, ZHAO C C, et al. Improved method of leader-follower UAV coordinated formation based on path following[J]. Flight Control & Detection, 2021, 4(2): 26-35. | |
| 15 | PARK B S, YOO S J. An error transformation approach for connectivity-preserving and collision-avoiding formation tracking of networked uncertain underactuated surface vessels [J]. IEEE Transactions on Cybernetics, 2019, 49(8): 2955-2966. |
| 16 | QU X, LIANG X, HOU Y, et al. Fuzzy state observer-based cooperative path-following control of autonomous underwater vehicles with unknown dynamics and ocean disturbances [J]. International Journal of Fuzzy Systems, 2021, 23(6): 1849-1859. |
| 17 | MENDA K, CHEN Y-C, GRANA J, et al. Deep reinforcement learning for event-driven multi-agent decision processes [J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 20(4): 1259-1268. |
| 18 | ZHAO Y, QI X, MA Y, et al. Path following optimization for an underactuated USV using smoothly-convergent deep reinforcement learning [J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(10): 6208-6220. |
| 19 | ZHAO Y, MA Y, HU S. USV formation and path-following control via deep reinforcement learning with random braking [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(12): 5468-5478. |
| 20 | HE Z, SONG C, DONG L. Multi-robot social-aware cooperative planning in pedestrian environments using multi-agent reinforcement learning [EB/OL]. (2022-11-29)[2023-08-01]. . |
| 21 | CUI Y, HUANG X, WANG Y, et al. Socially-aware multi-agent following with 2D laser scans via deep reinforcement learning and potential field [C]// Proceedings of the 2021 IEEE International Conference on Real-time Computing and Robotics. Piscataway: IEEE, 2021: 515-520. |
| 22 | PÉREZ-D’ARPINO C, LIU C, GOEBEL P, et al. Robot navigation in constrained pedestrian environments using reinforcement learning [C]// Proceedings of the 2021 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2021: 1140-1146. |
| 23 | KÄSTNER L, ZHAO X, SHEN Z, et al. Obstacle-aware waypoint generation for long-range guidance of deep-reinforcement-learning-based navigation approaches [EB/OL]. (2021-09-23)[2023-08-01]. . |
| 24 | CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning [C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 285-292. |
| 25 | SAMSANI S S, MUHAMMAD M S. Socially compliant robot navigation in crowded environment by human behavior resemblance using deep reinforcement learning [J]. IEEE Robotics and Automation Letters, 2021, 6(3): 5223-5230. |
| 26 | EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning [C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 3052-3059. |
| 27 | VAN DEN BERG J, GUY S J, LIN M, et al. Reciprocal n-body collision avoidance [C]// Proceedings of the 14th International Symposium on Robotics Research. Berlin: Springer, 2011: 3-19. |
| [1] | 肖海林, 黄天义, 代秋香, 张跃军, 张中山. 基于轨迹预测的安全强化学习自动变道决策方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2958-2963. |
| [2] | 穆凌霞, 周政君, 王斑, 张友民, 薛向宏, 宁凯凯. 多无人机编队避障和编队重构方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2938-2946. |
| [3] | 周毅, 高华, 田永谌. 基于裁剪优化和策略指导的近端策略优化算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2334-2341. |
| [4] | 马天, 席润韬, 吕佳豪, 曾奕杰, 杨嘉怡, 张杰慧. 基于深度强化学习的移动机器人三维路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2055-2064. |
| [5] | 赵晓焱, 韩威, 张俊娜, 袁培燕. 基于异步深度强化学习的车联网协作卸载策略[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1501-1510. |
| [6] | 唐睿, 庞川林, 张睿智, 刘川, 岳士博. D2D通信增强的蜂窝网络中基于DDPG的资源分配[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1562-1569. |
| [7] | 陈发堂, 黄淼, 金宇峰. 面向用户需求的低轨卫星资源分配算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1242-1247. |
| [8] | 秦鑫彤, 宋政育, 侯天为, 王飞越, 孙昕, 黎伟. 基于自适应p持续的移动自组网信道接入和资源分配算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 863-868. |
| [9] | 李源潮, 陶重犇, 王琛. 基于最大熵深度强化学习的双足机器人步态控制方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 445-451. |
| [10] | 邓辅秦, 官桧锋, 谭朝恩, 付兰慧, 王宏民, 林天麟, 张建民. 基于请求与应答通信机制和局部注意力机制的多机器人强化学习路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 432-438. |
| [11] | 宋紫阳, 李军怀, 王怀军, 苏鑫, 于蕾. 基于路径模仿和SAC强化学习的机械臂路径规划算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 439-444. |
| [12] | 余家宸, 杨晔. 基于裁剪近端策略优化算法的软机械臂不规则物体抓取[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3629-3638. |
| [13] | 王昱, 关智慧, 李远鹏. 基于轨迹预测和分布式MADDPG的无人机集群追击决策[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3623-3628. |
| [14] | 龙杰, 谢良, 徐海蛟. 集成的深度强化学习投资组合模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 300-310. |
| [15] | 王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2636-2643. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||