


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (9): 2957-2965.DOI: 10.11772/j.issn.1001-9081.2025030268
• 多媒体计算与计算机仿真 • 上一篇
吕景刚, 彭绍睿, 高硕, 周金( )
)
收稿日期:2025-03-19
修回日期:2025-05-31
接受日期:2025-06-06
发布日期:2025-06-25
出版日期:2025-09-10
通讯作者:
周金
作者简介:吕景刚(1977—),男,山东烟台人,副教授,博士,主要研究方向:语音信号处理、语音增强基金资助:
Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU()
Received:2025-03-19
Revised:2025-05-31
Accepted:2025-06-06
Online:2025-06-25
Published:2025-09-10
Contact:
Jin ZHOU
About author:LYU Jinggang, born in 1977, Ph. D., associate professor. His research interests include speech signal processing, speech enhancement.Supported by:摘要:
现有语音增强方法的目标信号为复频谱信号,而训练网络通常采用实值网络,训练时分别并行处理实部和虚部信号降低了特征提取的准确度,并且对复频域的语义特征提取不充分。为解决上述问题,提出一种基于复频域注意力和多尺度频域增强(CFAFE)的复数域网络实现语音增强。该网络以U-Net为基本架构,首先,利用短时傅里叶变换(STFT)将语音时序含噪信号转换到复频域;其次,针对复频域特征,设计复数域多尺度频域增强模块,构建复频域条件下增强的含噪语音局部特征挖掘模块,从而增强频域干扰和识别期望信号特征的能力;再次,在ViT(Vision Transformer)的基础上设计基于复频域的自注意力算法,实现并行复频域特征的增强;最后,在基准数据集VoiceBank+Demand上进行对比实验和消融实验,并在使用Noise92加噪后的Timit数据集上进行迁移泛化实验。实验结果表明,在VoiceBank+Demand数据集上,相较于深度复卷积递归网络(DCCRN),所提网络在语音质量的感知评估(PESQ)、MOS信号失真(CSIG)、MOS噪声失真(CBAK)、MOS整体语音质量(COVL)指标上分别提升了16.6%、10.9%、44.4%和14.1%;在Timit+Noise92数据集上,相较于DCCRN模型,在babble噪声信噪比(SNR)为-5 dB的条件下,所提网络的PESQ和STOI(Short-Time Objective Intelligibility)分别提高了29.8%和5.2%。
中图分类号:
吕景刚, 彭绍睿, 高硕, 周金. 复频域注意力和多尺度频域增强驱动的语音增强网络[J]. 计算机应用, 2025, 45(9): 2957-2965.
Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement[J]. Journal of Computer Applications, 2025, 45(9): 2957-2965.
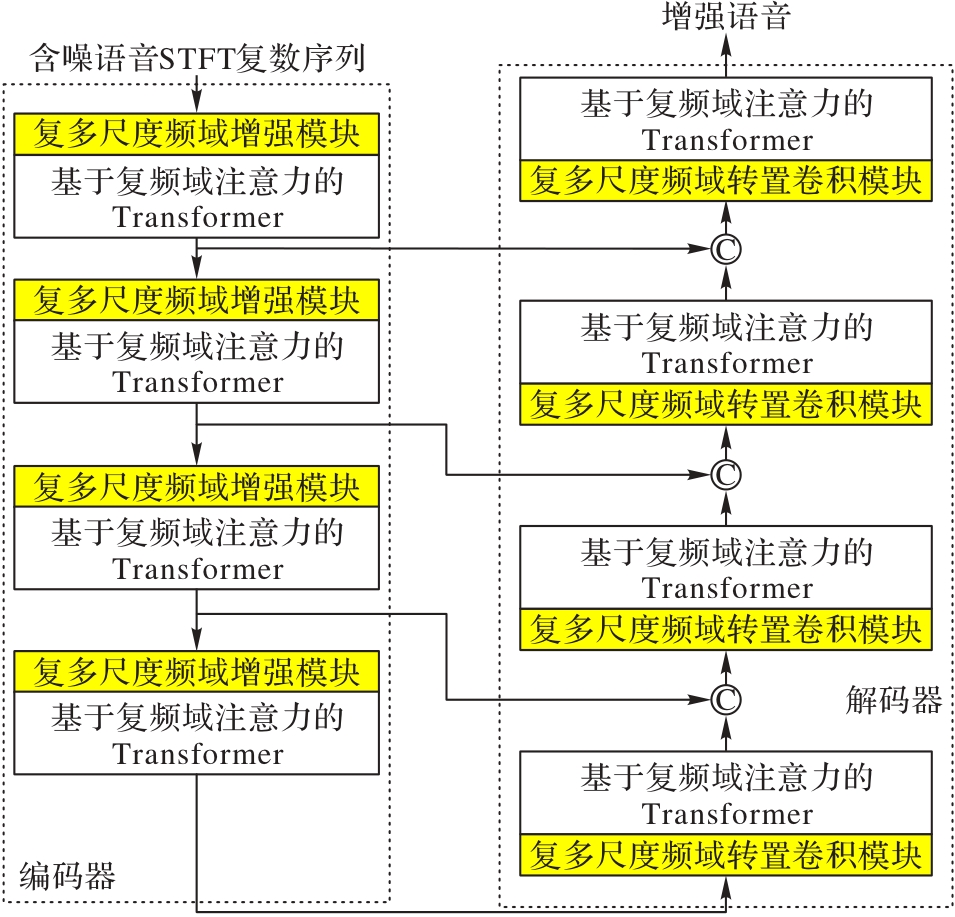
图1 CFAFE的总体结构
Fig. 1 Overall structure of CFAFE
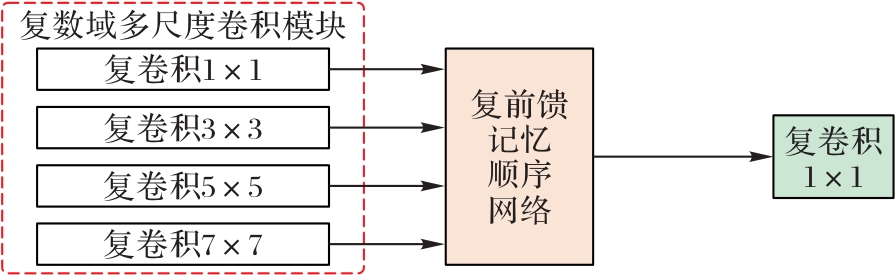
图2 CMSFE模块的结构
Fig. 2 Structure of CMSFE module
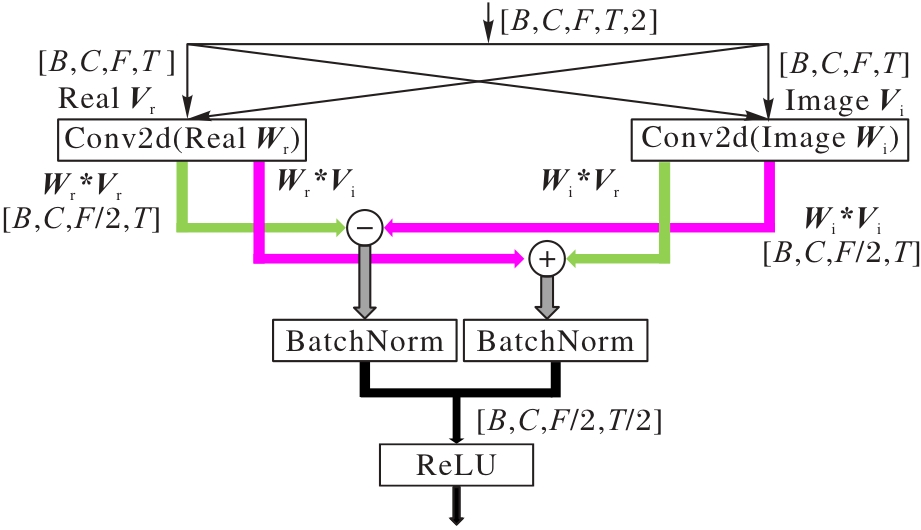
图3 复卷积模块的结构
Fig. 3 Structure of complex convolution module
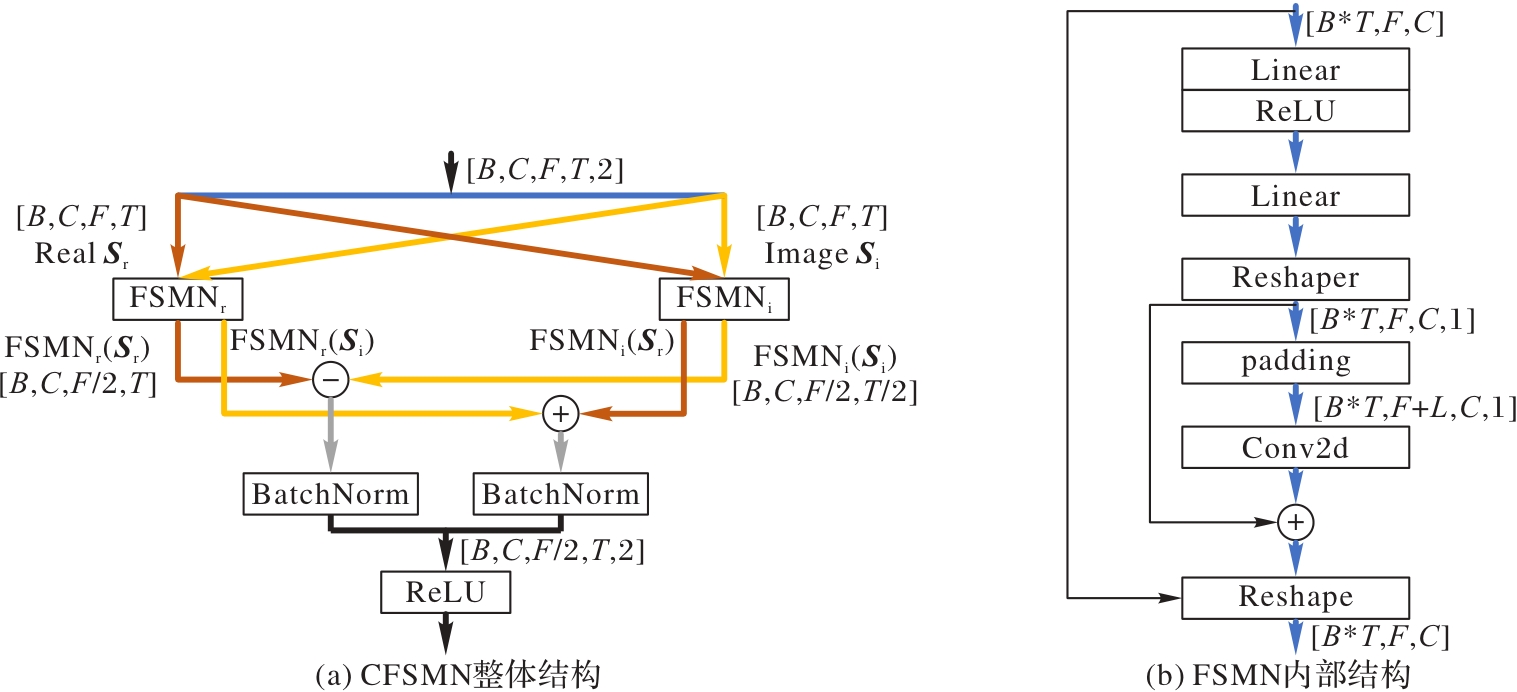
图4 CFSMN整体和内部结构
Fig. 4 Overall and inner structure of CFSMN
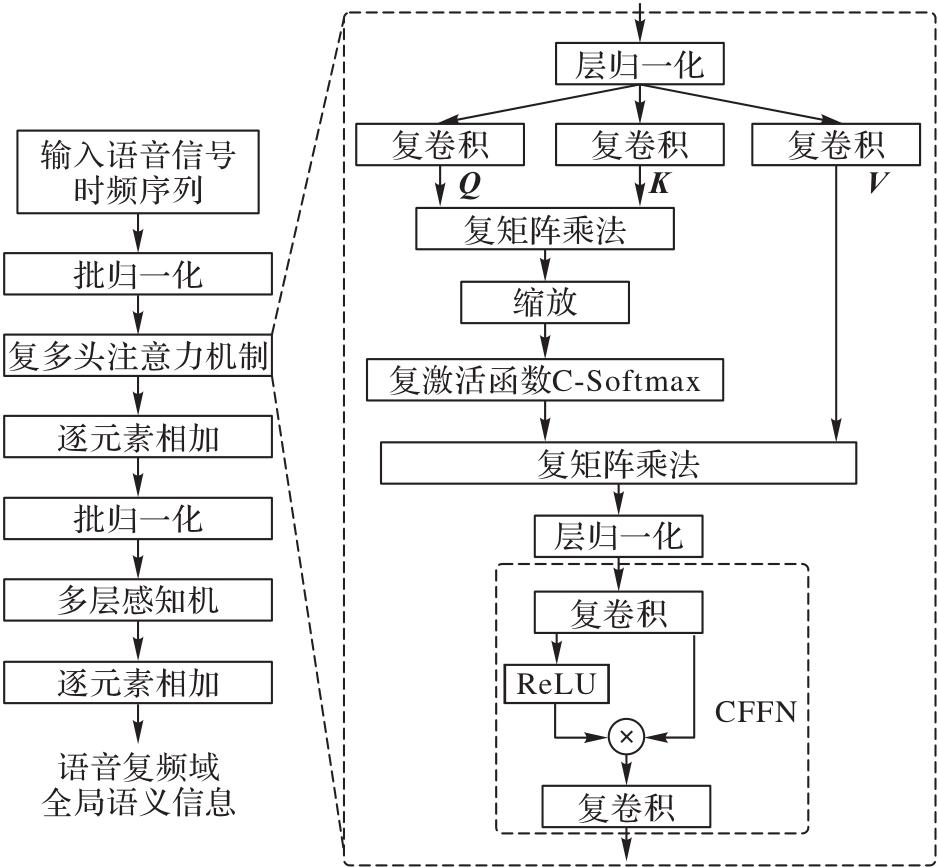
图5 CFDT的结构
Fig. 5 Structure of CFDT
| 方法 | PESQ | CSIG | CBAK | COVL | STOI | 参数量/106 |
|---|---|---|---|---|---|---|
| Noisy | 1.97 | 3.34 | 2.43 | 2.63 | 0.91 | — |
| DCCRN[ | 2.64 | 3.92 | 2.59 | 3.33 | 0.94 | 3.7 |
| DCCRGAN [ | 2.83 | 3.94 | 3.50 | 3.35 | 0.94 | — |
| S-DCCRN [ | 2.84 | 4.03 | 2.97 | 3.43 | 0.94 | 2.3 |
| GCARN [ | 2.99 | 4.27 | 3.46 | 3.63 | 0.95 | 9.7 |
| CycleGAN-DCD[ | 2.90 | 4.24 | 3.57 | 3.49 | 0.94 | — |
| DBCRN[ | 3.14 | 4.07 | 3.68 | 3.62 | 0.95 | 8.3 |
| 去除CFSMN | 2.94 | 4.44 | 3.64 | 3.74 | 0.94 | 3.4 |
| 去除CFDT | 2.91 | 4.35 | 3.58 | 3.65 | 0.94 | 3.0 |
| CFAFE | 3.08 | 4.35 | 3.74 | 3.80 | 0.95 | 3.9 |
表1 不同方法在VoiceBank+Demand数据集上的性能对比
Tab. 1 Performance comparison of different methods on VoiceBank+Demand dataset
| 方法 | PESQ | CSIG | CBAK | COVL | STOI | 参数量/106 |
|---|---|---|---|---|---|---|
| Noisy | 1.97 | 3.34 | 2.43 | 2.63 | 0.91 | — |
| DCCRN[ | 2.64 | 3.92 | 2.59 | 3.33 | 0.94 | 3.7 |
| DCCRGAN [ | 2.83 | 3.94 | 3.50 | 3.35 | 0.94 | — |
| S-DCCRN [ | 2.84 | 4.03 | 2.97 | 3.43 | 0.94 | 2.3 |
| GCARN [ | 2.99 | 4.27 | 3.46 | 3.63 | 0.95 | 9.7 |
| CycleGAN-DCD[ | 2.90 | 4.24 | 3.57 | 3.49 | 0.94 | — |
| DBCRN[ | 3.14 | 4.07 | 3.68 | 3.62 | 0.95 | 8.3 |
| 去除CFSMN | 2.94 | 4.44 | 3.64 | 3.74 | 0.94 | 3.4 |
| 去除CFDT | 2.91 | 4.35 | 3.58 | 3.65 | 0.94 | 3.0 |
| CFAFE | 3.08 | 4.35 | 3.74 | 3.80 | 0.95 | 3.9 |
| 噪声类型 | 信噪比/dB | Noisy | DCCRN | CFAFE | 去除CFDT | ||||
|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | PESQ | STOI | PESQ | STOI | PESQ | STOI | ||
| babble | -5 | 1.15 | 0.69 | 1.24 | 0.76 | 1.61 | 0.80 | 1.52 | 0.76 |
| 0 | 1.31 | 0.78 | 1.56 | 0.85 | 2.14 | 0.89 | 1.92 | 0.86 | |
| 5 | 1.60 | 0.86 | 2.00 | 0.91 | 2.69 | 0.94 | 2.43 | 0.92 | |
| buccaneer | -5 | 1.11 | 0.70 | 1.20 | 0.73 | 1.78 | 0.84 | 1.68 | 0.82 |
| 0 | 1.23 | 0.82 | 1.47 | 0.85 | 2.26 | 0.92 | 2.12 | 0.91 | |
| 5 | 1.46 | 0.90 | 2.03 | 0.94 | 2.77 | 0.96 | 2.54 | 0.95 | |
| destroyerengine | -5 | 1.19 | 0.77 | 1.34 | 0.78 | 2.11 | 0.90 | 1.99 | 0.88 |
| 0 | 1.36 | 0.87 | 1.67 | 0.90 | 2.63 | 0.94 | 2.49 | 0.94 | |
| 5 | 1.67 | 0.93 | 2.23 | 0.95 | 3.02 | 0.96 | 2.85 | 0.94 | |
| factory | -5 | 1.09 | 0.69 | 1.22 | 0.72 | 1.55 | 0.82 | 1.52 | 0.79 |
| 0 | 1.21 | 0.80 | 1.54 | 0.89 | 2.05 | 0.90 | 1.91 | 0.88 | |
| 5 | 1.46 | 0.89 | 2.07 | 0.94 | 2.71 | 0.95 | 2.43 | 0.94 | |
| volvo | -5 | 2.13 | 0.96 | 2.98 | 0.97 | 3.83 | 0.98 | 3.43 | 0.97 |
| 0 | 2.63 | 0.98 | 3.15 | 0.97 | 4.07 | 0.99 | 3.74 | 0.98 | |
| 5 | 2.95 | 0.99 | 3.61 | 0.99 | 4.19 | 0.99 | 4.15 | 0.99 | |
| white | -5 | 1.06 | 0.78 | 1.17 | 0.86 | 1.93 | 0.88 | 1.72 | 0.86 |
| 0 | 1.13 | 0.87 | 1.51 | 0.89 | 2.51 | 0.94 | 2.29 | 0.93 | |
| 5 | 1.30 | 0.94 | 1.91 | 0.95 | 2.96 | 0.96 | 2.84 | 0.96 | |
表2 不同信噪比和不同噪声下的对比实验结果
Tab. 2 Comparison experiment results under different signal-to-noise ratios and different noises
| 噪声类型 | 信噪比/dB | Noisy | DCCRN | CFAFE | 去除CFDT | ||||
|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | PESQ | STOI | PESQ | STOI | PESQ | STOI | ||
| babble | -5 | 1.15 | 0.69 | 1.24 | 0.76 | 1.61 | 0.80 | 1.52 | 0.76 |
| 0 | 1.31 | 0.78 | 1.56 | 0.85 | 2.14 | 0.89 | 1.92 | 0.86 | |
| 5 | 1.60 | 0.86 | 2.00 | 0.91 | 2.69 | 0.94 | 2.43 | 0.92 | |
| buccaneer | -5 | 1.11 | 0.70 | 1.20 | 0.73 | 1.78 | 0.84 | 1.68 | 0.82 |
| 0 | 1.23 | 0.82 | 1.47 | 0.85 | 2.26 | 0.92 | 2.12 | 0.91 | |
| 5 | 1.46 | 0.90 | 2.03 | 0.94 | 2.77 | 0.96 | 2.54 | 0.95 | |
| destroyerengine | -5 | 1.19 | 0.77 | 1.34 | 0.78 | 2.11 | 0.90 | 1.99 | 0.88 |
| 0 | 1.36 | 0.87 | 1.67 | 0.90 | 2.63 | 0.94 | 2.49 | 0.94 | |
| 5 | 1.67 | 0.93 | 2.23 | 0.95 | 3.02 | 0.96 | 2.85 | 0.94 | |
| factory | -5 | 1.09 | 0.69 | 1.22 | 0.72 | 1.55 | 0.82 | 1.52 | 0.79 |
| 0 | 1.21 | 0.80 | 1.54 | 0.89 | 2.05 | 0.90 | 1.91 | 0.88 | |
| 5 | 1.46 | 0.89 | 2.07 | 0.94 | 2.71 | 0.95 | 2.43 | 0.94 | |
| volvo | -5 | 2.13 | 0.96 | 2.98 | 0.97 | 3.83 | 0.98 | 3.43 | 0.97 |
| 0 | 2.63 | 0.98 | 3.15 | 0.97 | 4.07 | 0.99 | 3.74 | 0.98 | |
| 5 | 2.95 | 0.99 | 3.61 | 0.99 | 4.19 | 0.99 | 4.15 | 0.99 | |
| white | -5 | 1.06 | 0.78 | 1.17 | 0.86 | 1.93 | 0.88 | 1.72 | 0.86 |
| 0 | 1.13 | 0.87 | 1.51 | 0.89 | 2.51 | 0.94 | 2.29 | 0.93 | |
| 5 | 1.30 | 0.94 | 1.91 | 0.95 | 2.96 | 0.96 | 2.84 | 0.96 | |

图6 babble噪声下不同模型的语谱图的对比
Fig. 6 Comparison of spectrograms of different models under babble noise
| [1] | 蔡汉添,袁波涛. 一种基于听觉掩蔽模型的语音增强算法[J]. 通信学报, 2002, 23(8): 93-98. |
| CAI H T, YUAN B T. A speech enhancement algorithm based on masking properties of human auditory system [J]. Journal on Communications, 2002, 23(8): 93-98. | |
| [2] | WANG Y, BROOKES M. Model-based speech enhancement in the modulation domain [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(3): 580-594. |
| [3] | ALMAJAI I, MILNER B. Visually derived wiener filters for speech enhancement [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(6):1642-1651. |
| [4] | 蓝天,彭川,李森,等. 单声道语音降噪与去混响研究综述[J]. 计算机研究与发展, 2020, 57(5): 928-953. |
| LAN T, PENG C, LI S, et al. An overview of monaural speech denoising and dereverberation research [J]. Journal of Computer Research and Development, 2020, 57(5):928-953. | |
| [5] | KRAWCZYK-BECKER M, GERKMANN T. Fundamental frequency informed speech enhancement in a flexible statistical framework [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(5): 940-951. |
| [6] | WOHLMAYR M, STARK M, PERNKOPF F. A probabilistic interaction model for multipitch tracking with factorial hidden Markov models [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):799-810. |
| [7] | MING J, SRINIVASAN R, CROOKES D. A corpus-based approach to speech enhancement from nonstationary noise [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):822-836. |
| [8] | PANDEY A, WANG D. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6875-6879. |
| [9] | LI A, LIU W, ZHENG C, et al. Two heads are better than one: a two-stage complex spectral mapping approach for monaural speech enhancement [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 1829-1843. |
| [10] | GAO T, DU J, XU Y, et al. Improving deep neural network based speech enhancement in low SNR environments [C]// Proceedings of the 2015 International Conference on Latent Variable Analysis and Signal Separation, LNCS 9237. Cham: Springer, 2015: 75-82. |
| [11] | YIN D, LUO C, XIONG Z, et al. PHASEN: a phase-and-harmonics-aware speech enhancement network [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9458-9465. |
| [12] | LEE J, KANG H G. Two-stage refinement of magnitude and complex spectra for real-time speech enhancement [J]. IEEE Signal Processing Letters, 2022, 29: 2188-2192. |
| [13] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [14] | WANG K, HE B, ZHU W P. TSTNN: two-stage Transformer based neural network for speech enhancement in the time domain[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 7098-7102. |
| [15] | YU G, LI A, WANG H, et al. DBT-Net: dual-branch federative magnitude and phase estimation with attention-in-attention Transformer for monaural speech enhancement [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2629-2644. |
| [16] | ZHANG Q, SONG Q, NI Z, et al. Time-frequency attention for monaural speech enhancement [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7852-7856. |
| [17] | 张天骐,罗庆予,张慧芝,等. 复谱映射下融合高效Transformer的语音增强方法[J]. 信号处理, 2024, 40(2): 406-416. |
| ZHANG T Q, LUO Q Y, ZHANG H Z, et al. Speech enhancement method based on complex spectrum mapping with efficient Transformer [J]. Journal of Signal Processing, 2024, 40(2): 406-416. | |
| [18] | HU Y, LIU Y, LV S, et al. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2472-2476. |
| [19] | ZHANG S, LEI M, YAN Z, et al. Deep-FSMN for large vocabulary continuous speech recognition [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5869-5873. |
| [20] | ZHAO S, MA B, WATCHARASUPAT K N, et al. FRCRN: boosting feature representation using frequency recurrence for monaural speech enhancement [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 9281-9285. |
| [21] | HAN K, WANG Y, CHEN H, et al. A survey on Vision Transformer [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 87-110. |
| [22] | VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: design, collection and data analysis of a large regional accent speech database [C]// Proceedings of the 2013 International Conference of the Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4. |
| [23] | THIEMANN J, ITO N, VINCENT E. The diverse environments multi-channel acoustic noise database: a database of multichannel environmental noise recordings [J]. The Journal of the Acoustical Society of America, 2013, 133(S5): No.4806631. |
| [24] | GAROFOLO J S, LAMEL L F, FISHER W M, et al. DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM: NISTIR 4930 [R/OL]. [2024-12-14]. . |
| [25] | VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ⅱ. NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems [J]. Speech Communication, 1993, 12(3): 247-251. |
| [26] | HUANG H X, WU R J, HUANG J, et al. DCCRGAN: deep complex convolution recurrent generator adversarial network for speech enhancement [C]// Proceedings of the 2022 International Symposium on Electrical, Electronics and Information Engineering. Piscataway: IEEE, 2022: 30-35. |
| [27] | LV S, FU Y, XING M, et al. S-DCCRN: super wide band DCCRN with learnable complex feature for speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7767-7771. |
| [28] | ZHOU L, GAO Y, WANG Z, et al. Complex spectral mapping with attention based convolution recurrent neural network for speech enhancement [EB/OL]. [2024-12-22]. . |
| [29] | YU G, WANG Y, WANG H, et al. A two-stage complex network using cycle-consistent generative adversarial networks for speech enhancement [J]. Speech Communication, 2021, 134: 42-54. |
| [30] | LI Y, SUN M, ZHANG X. Scale-aware dual-branch complex convolutional recurrent network for monaural speech enhancement[J]. Computer Speech and Language, 2024, 86: No.101618. |
| [1] | 邓伊琳, 余发江. 基于LSTM和可分离自注意力机制的伪随机数生成器[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2893-2901. |
| [2] | 李进, 刘立群. 基于残差Swin Transformer的SAR与可见光图像融合[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2949-2956. |
| [3] | 王翔, 陈志祥, 毛国君. 融合局部和全局相关性的多变量时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2806-2816. |
| [4] | 吴海峰, 陶丽青, 程玉胜. 集成特征注意力和残差连接的偏标签回归算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2530-2536. |
| [5] | 周金, 李玉芝, 张徐, 高硕, 张立, 盛家川. 复杂电磁环境下的调制识别网络[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2672-2682. |
| [6] | 林进浩, 罗川, 李天瑞, 陈红梅. 基于跨尺度注意力网络的胸部疾病分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2712-2719. |
| [7] | 敬超, 全育涛, 陈艳. 基于多层感知机-注意力模型的功耗预测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2646-2655. |
| [8] | 陶永鹏, 柏诗淇, 周正文. 基于卷积和Transformer神经网络架构搜索的脑胶质瘤多组织分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2378-2386. |
| [9] | 梁辰, 王奕森, 魏强, 杜江. 基于Tsransformer-GCN的源代码漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2296-2303. |
| [10] | 刘皓宇, 孔鹏伟, 王耀力, 常青. 基于多视角信息的行人检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2325-2332. |
| [11] | 赵小强, 柳勇勇, 惠永永, 刘凯. 基于改进时域卷积网络与多头自注意力机制的间歇过程质量预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2245-2252. |
| [12] | 王慧斌, 胡展傲, 胡节, 徐袁伟, 文博. 基于分段注意力机制的时间序列预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2262-2268. |
| [13] | 王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2237-2244. |
| [14] | 颜文婧, 王瑞东, 左敏, 张青川. 基于风味嵌入异构图层次学习的食谱推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1869-1878. |
| [15] | 蒋杰, 骆功宁, 董素宇, 李凡丁, 李向宇, 李钦策, 袁永峰, 王宽全. 信息瓶颈引导的颅内出血分割方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1998-2006. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||