


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (9): 2727-2734.DOI: 10.11772/j.issn.1001-9081.2022081249
杨昊, 张轶( )
)
收稿日期:2022-08-23
修回日期:2022-10-22
接受日期:2022-11-03
发布日期:2023-01-11
出版日期:2023-09-10
通讯作者:
张轶
作者简介:杨昊(1999—),男,四川雅安人,硕士研究生,主要研究方向:计算机视觉、目标检测;
基金资助:Received:2022-08-23
Revised:2022-10-22
Accepted:2022-11-03
Online:2023-01-11
Published:2023-09-10
Contact:
Yi ZHANG
About author:YANG Hao, born in 1999, M. S. candidate. His research interests include computer vision, object detection.
Supported by:摘要:
针对目标检测中分类和定位子任务分别需要大感受野和高分辨率,难以在这两个相互矛盾的需求间取得平衡的问题,提出一种用于目标检测的基于注意力机制的特征金字塔网络算法。该算法能整合多个不同感受野来获取更丰富的语义信息,以一种更关注不同特征图重要性的方式融合多尺度特征图,并在注意力机制引导下进一步精练复杂融合后的特征图。首先,通过多尺度的空洞卷积获取多尺度感受野,在保留分辨率的同时增强语义信息;其次,通过多级特征融合(MLF)方式将多个不同尺度的特征图通过上采样或池化操作变为相同分辨率后融合;最后,利用注意力引导的特征精练模块(AFRM)对融合后的特征图作精练处理,丰富语义信息并消除融合带来的混叠效应。将所提特征金字塔替换Faster R-CNN中的特征金字塔网络(FPN)后在MS COCO 2017数据集上进行实验,结果表明当骨干网络为深度50和101的残差网络(ResNet)时,平均精度(AP)分别达到了39.2%和41.0%,与使用原FPN的Faster R-CNN相比,分别提高了1.4和1.0个百分点。可见,所提特征金字塔网络算法能替代原FPN,更好地应用在目标检测场景中。
中图分类号:
杨昊, 张轶. 基于上下文信息和多尺度融合重要性感知的特征金字塔网络算法[J]. 计算机应用, 2023, 43(9): 2727-2734.
Hao YANG, Yi ZHANG. Feature pyramid network algorithm based on context information and multi-scale fusion importance awareness[J]. Journal of Computer Applications, 2023, 43(9): 2727-2734.
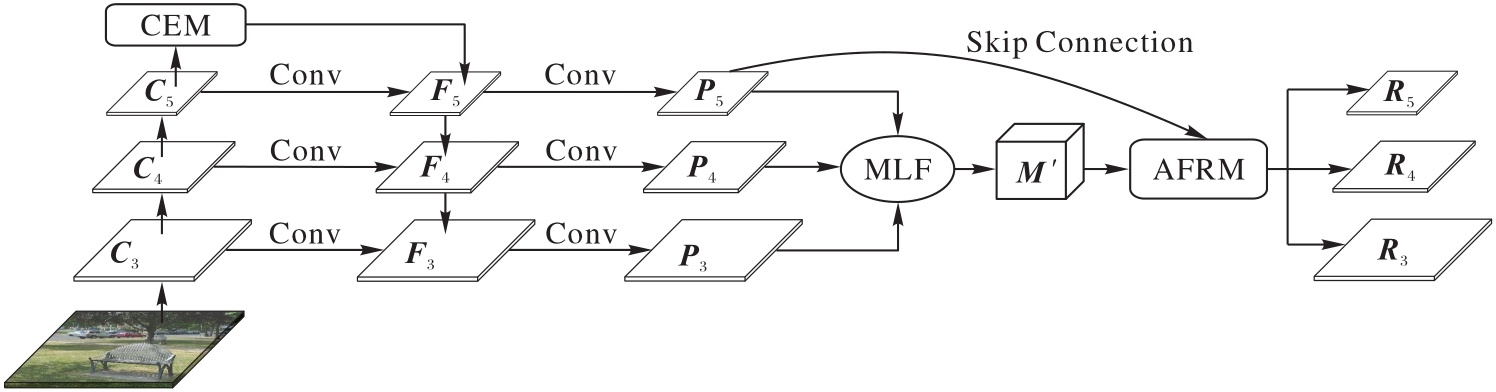
图1 本文算法的架构
Fig. 1 Architecture of the proposed algorithm
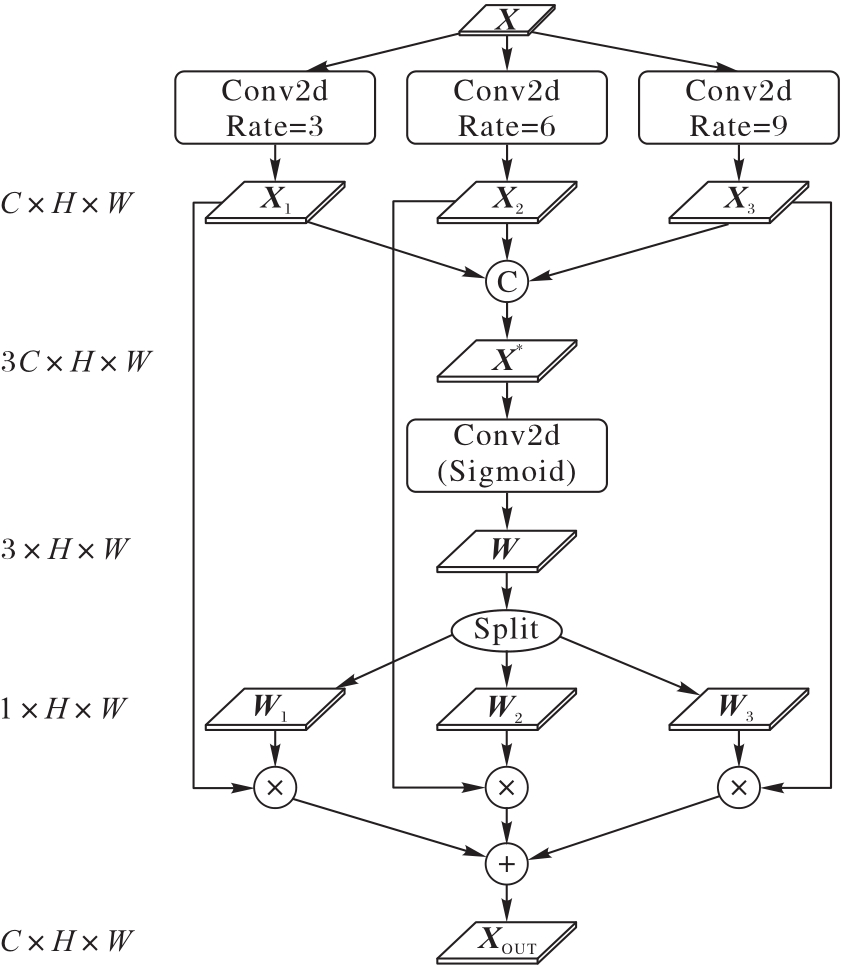
图2 CEM的结构
Fig. 2 Structure of CEM
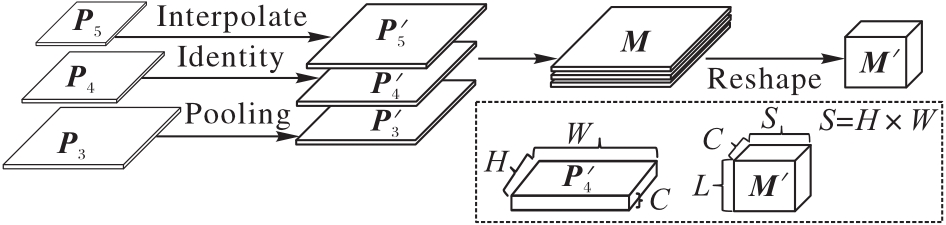
图3 MLF的结构
Fig. 3 Structure of MLF

图4 AFRM的结构
Fig. 4 Structure of AFRM

图5 层级子模块的结构
Fig. 5 Structure of level sub-module
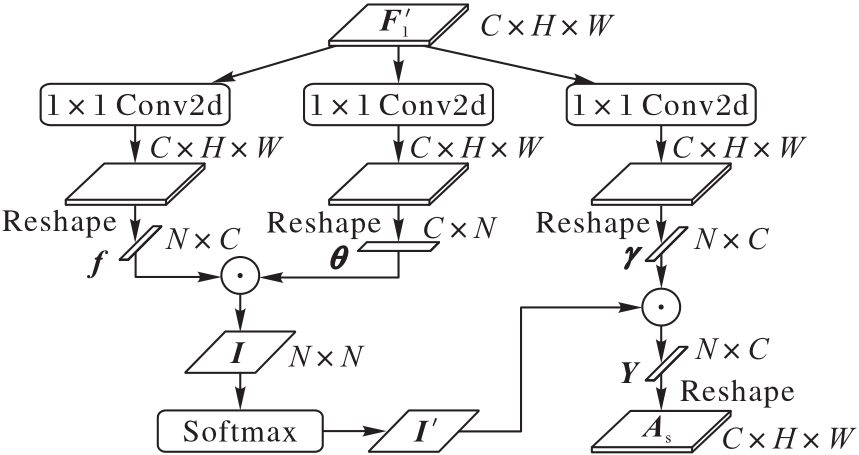
图6 空间子模块的结构
Fig. 6 Structure of spatial sub-module
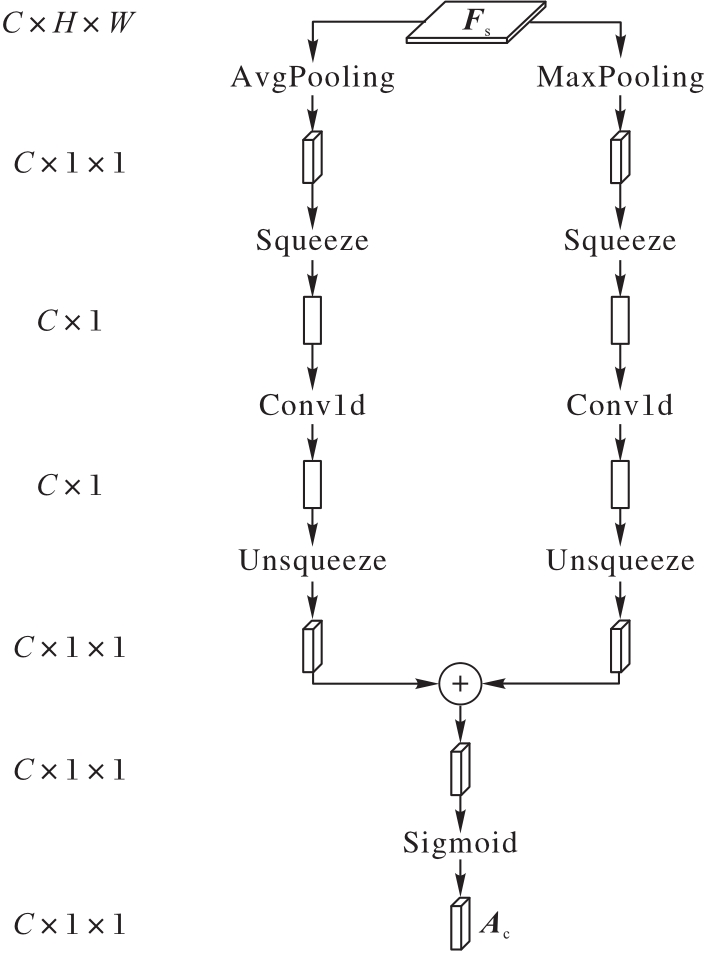
图7 通道子模块的结构
Fig. 7 Structure of channel sub-module
| 算法 | 骨干网络 | 训练计划 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| YOLOv2[ | DarkNet-19 | — | 21.6 | 44.0 | 19.2 | 5.0 | 22.4 | 35.5 |
| SSD | ResNet-101 | — | 31.2 | 50.4 | 33.3 | 10.2 | 34.5 | 49.8 |
| RetinaNet | ResNet-101 | — | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| FCOS | ResNet-101 | — | 41.5 | 60.7 | 45.0 | 24.4 | 44.8 | 51.6 |
| CornerNet | Hourglass-104 | — | 40.5 | 56.5 | 43.1 | 19.4 | 42.7 | 53.9 |
| Mask R-CNN | ResNet-101 | — | 38.2 | 60.3 | 41.7 | 20.1 | 41.1 | 50.2 |
| Faster R-CNN | ResNet-101 | — | 36.2 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| ResNet-50* | 1x | 37.8 | 59.0 | 40.9 | 21.9 | 40.7 | 46.6 | |
| ResNet-101* | 1x | 40.0 | 61.0 | 43.4 | 22.8 | 43.3 | 50.2 | |
| Libra R-CNN | ResNet-50 | 1x | 38.7 | 59.9 | 42.0 | 22.5 | 41.1 | 48.7 |
| ResNet-101 | 1x | 40.3 | 61.3 | 43.9 | 22.9 | 43.1 | 51.0 | |
| ResNet-101 | 2x | 41.1 | 62.1 | 44.7 | 23.4 | 43.7 | 52.5 | |
| ResNext101-64x4d | 1x | 43.0 | 64.0 | 47.0 | 25.3 | 45.6 | 54.6 | |
| AugFPN | ResNet-50 | 1x | 38.8 | 61.5 | 42.0 | 23.3 | 42.1 | 47.7 |
| ResNet-101 | 1x | 40.6 | 63.2 | 44.0 | 24.0 | 44.1 | 51.0 | |
| ResNet-101 | 2x | 41.5 | 63.9 | 45.1 | 23.8 | 44.7 | 52.8 | |
| ResNext101-64x4d | 1x | 43.0 | 65.6 | 46.9 | 26.2 | 46.5 | 53.9 | |
| 本文算法 | ResNet-50 | 1x | 39.2 | 61.3 | 42.3 | 22.8 | 42.0 | 49.1 |
| ResNet-101 | 1x | 41.0 | 62.9 | 44.5 | 23.4 | 44.0 | 52.0 | |
| ResNet-101 | 2x | 41.2 | 62.6 | 44.6 | 22.9 | 44.3 | 52.8 | |
| ResNext101-64x4d | 1x | 43.3 | 65.3 | 47.1 | 25.7 | 46.6 | 53.8 |
表1 不同算法在COCO测试数据集上的平均精度对比 (%)
Tab. 1 Comparisons of average precisoin of different algorithms on COCO test set
| 算法 | 骨干网络 | 训练计划 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| YOLOv2[ | DarkNet-19 | — | 21.6 | 44.0 | 19.2 | 5.0 | 22.4 | 35.5 |
| SSD | ResNet-101 | — | 31.2 | 50.4 | 33.3 | 10.2 | 34.5 | 49.8 |
| RetinaNet | ResNet-101 | — | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| FCOS | ResNet-101 | — | 41.5 | 60.7 | 45.0 | 24.4 | 44.8 | 51.6 |
| CornerNet | Hourglass-104 | — | 40.5 | 56.5 | 43.1 | 19.4 | 42.7 | 53.9 |
| Mask R-CNN | ResNet-101 | — | 38.2 | 60.3 | 41.7 | 20.1 | 41.1 | 50.2 |
| Faster R-CNN | ResNet-101 | — | 36.2 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| ResNet-50* | 1x | 37.8 | 59.0 | 40.9 | 21.9 | 40.7 | 46.6 | |
| ResNet-101* | 1x | 40.0 | 61.0 | 43.4 | 22.8 | 43.3 | 50.2 | |
| Libra R-CNN | ResNet-50 | 1x | 38.7 | 59.9 | 42.0 | 22.5 | 41.1 | 48.7 |
| ResNet-101 | 1x | 40.3 | 61.3 | 43.9 | 22.9 | 43.1 | 51.0 | |
| ResNet-101 | 2x | 41.1 | 62.1 | 44.7 | 23.4 | 43.7 | 52.5 | |
| ResNext101-64x4d | 1x | 43.0 | 64.0 | 47.0 | 25.3 | 45.6 | 54.6 | |
| AugFPN | ResNet-50 | 1x | 38.8 | 61.5 | 42.0 | 23.3 | 42.1 | 47.7 |
| ResNet-101 | 1x | 40.6 | 63.2 | 44.0 | 24.0 | 44.1 | 51.0 | |
| ResNet-101 | 2x | 41.5 | 63.9 | 45.1 | 23.8 | 44.7 | 52.8 | |
| ResNext101-64x4d | 1x | 43.0 | 65.6 | 46.9 | 26.2 | 46.5 | 53.9 | |
| 本文算法 | ResNet-50 | 1x | 39.2 | 61.3 | 42.3 | 22.8 | 42.0 | 49.1 |
| ResNet-101 | 1x | 41.0 | 62.9 | 44.5 | 23.4 | 44.0 | 52.0 | |
| ResNet-101 | 2x | 41.2 | 62.6 | 44.6 | 22.9 | 44.3 | 52.8 | |
| ResNext101-64x4d | 1x | 43.3 | 65.3 | 47.1 | 25.7 | 46.6 | 53.8 |
| 算法 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| 基线 | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| 基线+CEM | 38.6 | 60.2 | 41.5 | 22.9 | 42.1 | 49.9 |
| 基线+MLF+AFRM | 38.4 | 60.3 | 41.4 | 22.8 | 42.5 | 48.9 |
| 基线+CEM+MLF+AFRM | 38.9 | 60.7 | 42.1 | 23.2 | 42.5 | 50.1 |
表2 三个核心模块的平均精度对比 (%)
Tab. 2 Comparison of average precision of three core modules
| 算法 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| 基线 | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| 基线+CEM | 38.6 | 60.2 | 41.5 | 22.9 | 42.1 | 49.9 |
| 基线+MLF+AFRM | 38.4 | 60.3 | 41.4 | 22.8 | 42.5 | 48.9 |
| 基线+CEM+MLF+AFRM | 38.9 | 60.7 | 42.1 | 23.2 | 42.5 | 50.1 |
| 空洞率 | AP | AP50 | AP75 | APS | APM | APL | |
|---|---|---|---|---|---|---|---|
| 0 | — | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| 3 | (3,6,9) | 38.4 | 59.8 | 41.7 | 22.6 | 42.0 | 49.4 |
| 5 | (3,6,9,12,15) | 38.6 | 60.2 | 41.5 | 22.9 | 42.1 | 49.9 |
| 7 | (3,6,9,12,15, 18,21) | 38.4 | 60.2 | 41.6 | 22.3 | 42.2 | 49.9 |
表3 CEM的卷积数和空洞率对AP的影响 (%)
Tab. 3 Effects of convolution number and dilation rates in CEM on AP
| 空洞率 | AP | AP50 | AP75 | APS | APM | APL | |
|---|---|---|---|---|---|---|---|
| 0 | — | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| 3 | (3,6,9) | 38.4 | 59.8 | 41.7 | 22.6 | 42.0 | 49.4 |
| 5 | (3,6,9,12,15) | 38.6 | 60.2 | 41.5 | 22.9 | 42.1 | 49.9 |
| 7 | (3,6,9,12,15, 18,21) | 38.4 | 60.2 | 41.6 | 22.3 | 42.2 | 49.9 |
| 算法 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| 基线 | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| AFRM-L | 37.8 | 59.0 | 40.7 | 22.2 | 41.6 | 48.5 |
| AFRM-S | 37.8 | 58.9 | 41.0 | 22.0 | 41.4 | 49.0 |
| AFRM-C | 38.1 | 59.8 | 41.4 | 22.7 | 41.8 | 48.6 |
| AFRM-L+S | 38.3 | 60.1 | 41.2 | 22.6 | 42.2 | 48.5 |
| AFRM-L+S+C | 38.4 | 60.3 | 41.4 | 22.8 | 42.5 | 48.9 |
表4 AFRM逐渐增加各个子模块的结果 (%)
Tab. 4 Results of gradually adding sub-modules on AFRM
| 算法 | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| 基线 | 37.6 | 58.5 | 40.5 | 22.2 | 40.8 | 48.6 |
| AFRM-L | 37.8 | 59.0 | 40.7 | 22.2 | 41.6 | 48.5 |
| AFRM-S | 37.8 | 58.9 | 41.0 | 22.0 | 41.4 | 49.0 |
| AFRM-C | 38.1 | 59.8 | 41.4 | 22.7 | 41.8 | 48.6 |
| AFRM-L+S | 38.3 | 60.1 | 41.2 | 22.6 | 42.2 | 48.5 |
| AFRM-L+S+C | 38.4 | 60.3 | 41.4 | 22.8 | 42.5 | 48.9 |

图8 本文算法与基线算法的检测结果对比
Fig. 8 Comparison of detection results of the proposed algorithm and baseline
| 算法 | 骨干网络 | 参数规模/MB | 浮点运算量/GFLOPs | AP/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|
| FPN | ResNet-50 | 41.53 | 207.07 | 37.6 | 18.0 |
| ResNet-101 | 60.52 | 283.14 | 39.4 | 12.3 | |
本文 算法 | ResNet-50 | 55.97 | 222.30 | 38.9 | 14.7 |
| ResNet-101 | 74.96 | 298.37 | 40.5 | 10.0 |
表5 检测结果、模型复杂度和帧率对比
Tab. 5 Comparison of detection results, model complexity and frame rate
| 算法 | 骨干网络 | 参数规模/MB | 浮点运算量/GFLOPs | AP/% | 帧率/(frame·s-1) |
|---|---|---|---|---|---|
| FPN | ResNet-50 | 41.53 | 207.07 | 37.6 | 18.0 |
| ResNet-101 | 60.52 | 283.14 | 39.4 | 12.3 | |
本文 算法 | ResNet-50 | 55.97 | 222.30 | 38.9 | 14.7 |
| ResNet-101 | 74.96 | 298.37 | 40.5 | 10.0 |
| 1 | ZHAO Z Q, ZHENG P, XU S T, et al. Object detection with deep learning: a review[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(11): 3212-3232. 10.1109/tnnls.2018.2876865 |
| 2 | PAL S K, PRAMANIK A, MAITI J, et al. Deep learning in multi-object detection and tracking: state of the art[J]. Applied Intelligence, 2021, 51(9): 6400-6429. 10.1007/s10489-021-02293-7 |
| 3 | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. 10.1109/cvpr.2015.7298965 |
| 4 | 胡嵽,冯子亮. 基于深度学习的轻量级道路图像语义分割算法[J]. 计算机应用, 2021, 41(5):1326-1331. 10.11772/j.issn.1001-9081.2020081181 |
| HU D, FENG Z L. Light-weight road image semantic segmentation algorithm based on deep learning[J]. Journal of Computer Applications, 2021, 41(5): 1326-1331. 10.11772/j.issn.1001-9081.2020081181 | |
| 5 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 6 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 7 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. 10.1109/iccv.2017.324 |
| 8 | TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9626-9635. 10.1109/iccv.2019.00972 |
| 9 | LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768. 10.1109/cvpr.2018.00913 |
| 10 | PANG J M, CHEN K, SHI J P, et al. Libra R-CNN: towards balanced learning for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 821-830. 10.1109/cvpr.2019.00091 |
| 11 | GUO C X, FAN B, ZHANG Q, et al. AugFPN: improving multi-scale feature learning for object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12592-12601. 10.1109/cvpr42600.2020.01261 |
| 12 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 580-587. 10.1109/cvpr.2014.81 |
| 13 | UIJLINGS J R R, K E A van de SANDE, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171. 10.1007/s11263-013-0620-5 |
| 14 | GIRSHICK R. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448. 10.1109/iccv.2015.169 |
| 15 | CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6154-6162. 10.1109/cvpr.2018.00644 |
| 16 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multiBox detector[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 21-37. |
| 17 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. 10.1109/cvpr.2016.91 |
| 18 | KONG T, SUN F C, LIU H P, et al. FoveaBox: beyond anchor-based object detection[J]. IEEE Transactions on Image Processing, 2020, 29: 7389-7398. 10.1109/tip.2020.3002345 |
| 19 | LAW H, DENG J. CornerNet: detecting objects as paired keypoints[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 765-781. |
| 20 | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(4): 834-848. 10.1109/tpami.2017.2699184 |
| 21 | CHEN Q, WANG Y M, YANG T, et al. You only look one-level feature[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13034-13043. 10.1109/cvpr46437.2021.01284 |
| 22 | CHEN Z, HUANG S L, TAO D C. Context refinement for object detection[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Cham: Springer, 2018: 74-89. |
| 23 | 钟磊,何一,张建伟. 基于环境上下文和语义特征融合的小目标检测算法[J]. 计算机应用, 2022, 42(S1):281-286. |
| ZHONG L, HE Y, ZHANG J W. Small object detection algorithm based on context and semantic feature fusion[J]. Journal of Computer Applications, 2022, 42(S1):281-286. | |
| 24 | WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7794-7803. 10.1109/cvpr.2018.00813 |
| 25 | LI J N, WEI Y C, LIANG X D, et al. Attentive contexts for object detection[J]. IEEE Transactions on Multimedia, 2017, 19(5): 944-954. 10.1109/tmm.2016.2642789 |
| 26 | GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7029-7038. 10.1109/cvpr.2019.00720 |
| 27 | TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10778-10787. 10.1109/cvpr42600.2020.01079 |
| 28 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing System. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 29 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. 10.1109/cvpr.2018.00745 |
| 30 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19. |
| 31 | DAI X Y, CHEN Y P, XIAO B, et al. Dynamic head: unifying object detection heads with attentions[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7369-7378. 10.1109/cvpr46437.2021.00729 |
| 32 | SUNG F, YANG Y X, ZHANG L, et al. Learning to compare: relation network for few-shot learning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1199-1208. 10.1109/cvpr.2018.00131 |
| 33 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| 34 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 35 | CHEN K, WANG J Q, PANG J M, et al. MMDetection: open MMLab detection toolbox and benchmark[EB/OL]. (2019-06-17) [2022-06-20].. |
| 36 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 37 | XIE S N, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5987-5995. 10.1109/cvpr.2017.634 |
| 38 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525. 10.1109/cvpr.2017.690 |
| 39 | HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. 10.1109/iccv.2017.322 |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [3] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| [4] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [5] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [6] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [7] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [8] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [9] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [10] | 李烨恒, 罗光圣, 苏前敏. 基于改进YOLOv5的Logo检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2580-2587. |
| [11] | 张英俊, 李牛牛, 谢斌红, 张睿, 陆望东. 课程学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2326-2333. |
| [12] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [13] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [14] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [15] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||