《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (6): 1775-1780.DOI: 10.11772/j.issn.1001-9081.2023050646
所属专题: 人工智能
赵征宇1, 罗景1( ), 涂新辉2
), 涂新辉2
Zhengyu ZHAO1, Jing LUO1(), Xinhui TU2
摘要:
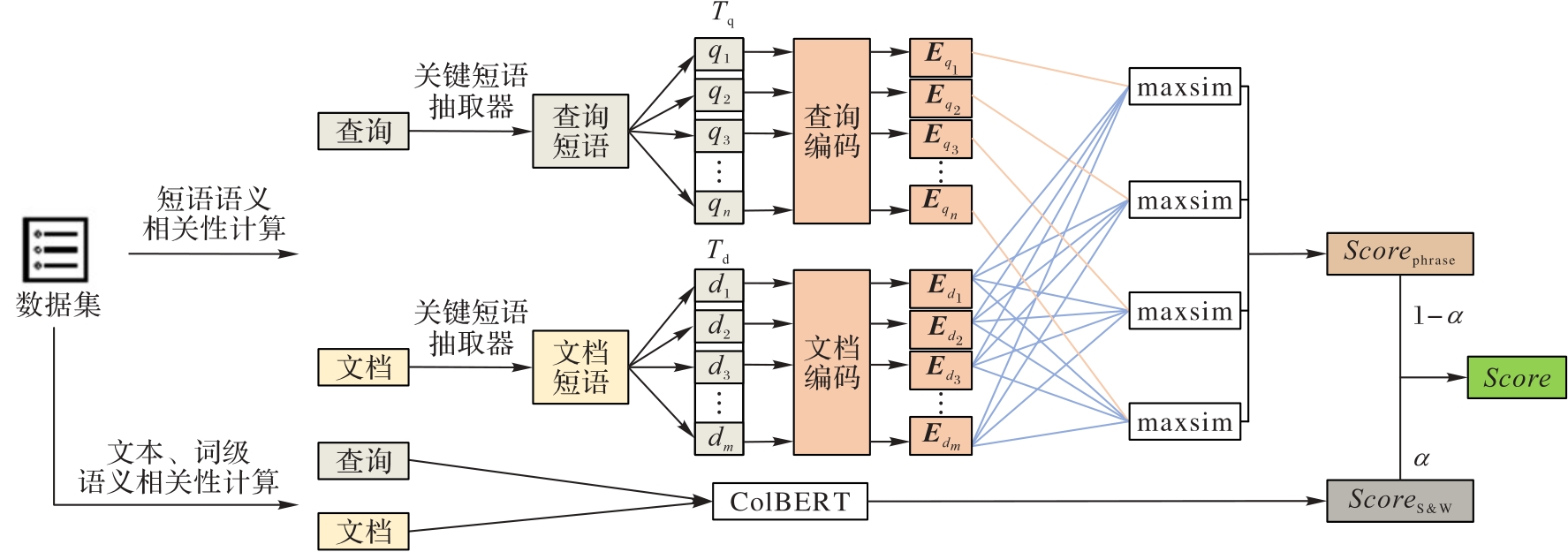
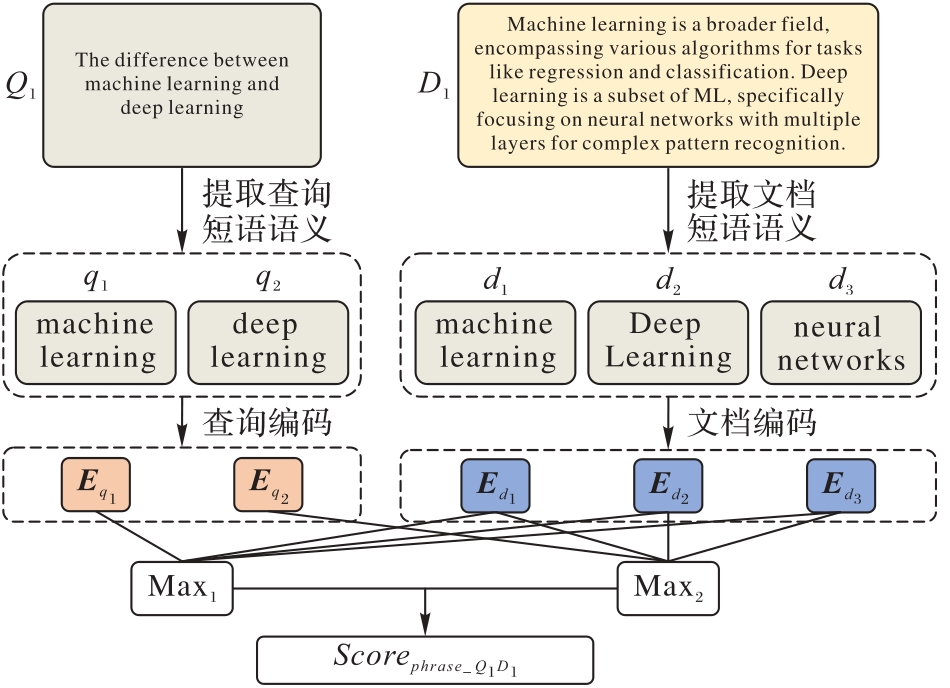
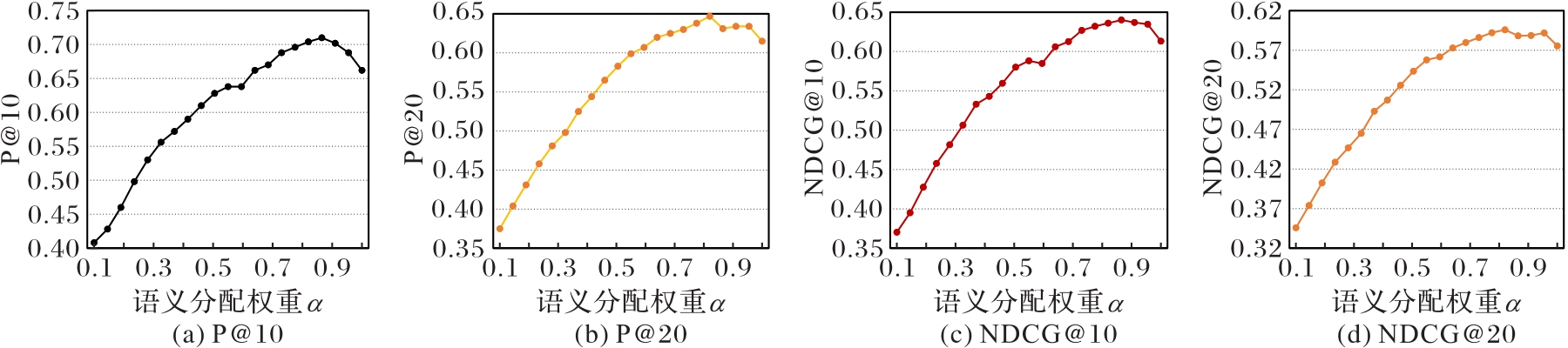
信息检索(IR)是一种通过特定的技术和方法组织、处理信息,以满足用户的信息需求的过程。近年来,基于预训练模型的稠密检索方法取得了巨大的成功;然而,这些方法只利用了文本和词语的向量表征计算查询与文档相关度,忽略了它们短语层面间的语义信息。针对该问题,提出一种名为MSIR(Multi-Scale IR)的IR方法。所提方法通过融合查询与文档中多种不同粒度的语义信息提高IR性能。首先,构建查询和文档中词语、短语和文本这3个粒度的语义单元;其次,利用预训练模型对这3个语义单元分别进行编码获得它们的语义表征;最后,利用语义表征计算查询和文档相关度。在Corvid-19、TREC2019和Robust04这3个不同大小的经典数据集上进行了对比实验。与ColBERT(ranking model based on Contextualized late interaction over BERT (Bidirectional Encoder Representation from Transformers))相比,MSIR在Robust04数据集的P@10、P@20、NDCG@10和NDCG@20指标上均实现了约8%的提升,同时在Corvid-19和TREC2019数据集上也取得了一定的改进。实验结果表明,MSIR能够成功融合多种语义粒度,提升检索精度。
中图分类号: