


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (4): 991-1004.DOI: 10.11772/j.issn.1001-9081.2022020296
• 人工智能 • 下一篇
王惠茹1, 李秀红1( ), 李哲2, 马春明1, 任泽裕1, 杨丹1
), 李哲2, 马春明1, 任泽裕1, 杨丹1
收稿日期:2022-03-16
修回日期:2022-06-06
接受日期:2022-06-07
发布日期:2022-08-16
出版日期:2023-04-10
通讯作者:
李秀红
作者简介:王惠茹(1996—),女,硕士研究生,新疆伊犁人,硕士研究生,主要研究方向:自然语言处理、图像处理;基金资助:
Huiru WANG1, Xiuhong LI1(), Zhe LI2, Chunming MA1, Zeyu REN1, Dan YANG1
Received:2022-03-16
Revised:2022-06-06
Accepted:2022-06-07
Online:2022-08-16
Published:2023-04-10
Contact:
Xiuhong LI
About author:WANG Huiru, born in 1996, M. S. candidate. Her research interests include natural language processing, image processing.Supported by:摘要:
预训练模型(PTM)通过利用复杂的预训练目标和大量的模型参数,可以有效地获得无标记数据中的丰富知识。而在多模态中,PTM的发展还处于初期。根据具体模态的不同,将目前大多数的多模态PTM分为图像?文本PTM和视频?文本PTM;根据数据融合方式的不同,还可将多模态PTM分为单流模型和双流模型两类。首先,总结了常见的预训练任务和验证实验所使用的下游任务;接着,梳理了目前多模态预训练领域的常见模型,并用表格列出各个模型的下游任务以及模型的性能和实验数据比较;然后,介绍了M6(Multi-Modality to Multi-Modality Multitask Mega-transformer)模型、跨模态提示调优(CPT)模型、VideoBERT(Video Bidirectional Encoder Representations from Transformers)模型和AliceMind(Alibaba’s collection of encoder-decoders from Mind)模型在具体下游任务中的应用场景;最后,总结了多模态PTM相关工作面临的挑战以及未来可能的研究方向。
中图分类号:
王惠茹, 李秀红, 李哲, 马春明, 任泽裕, 杨丹. 多模态预训练模型综述[J]. 计算机应用, 2023, 43(4): 991-1004.
Huiru WANG, Xiuhong LI, Zhe LI, Chunming MA, Zeyu REN, Dan YANG. Survey of multimodal pre-training models[J]. Journal of Computer Applications, 2023, 43(4): 991-1004.
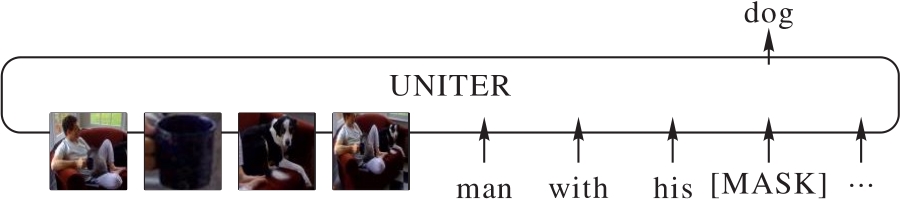
图1 MLM任务图
Fig. 1 MLM task diagram
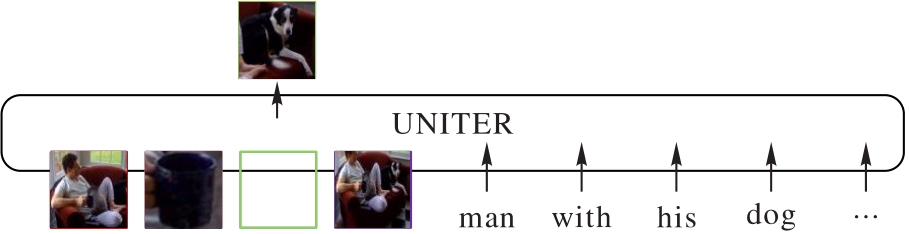
图2 MRM任务图
Fig. 2 MRM task diagram
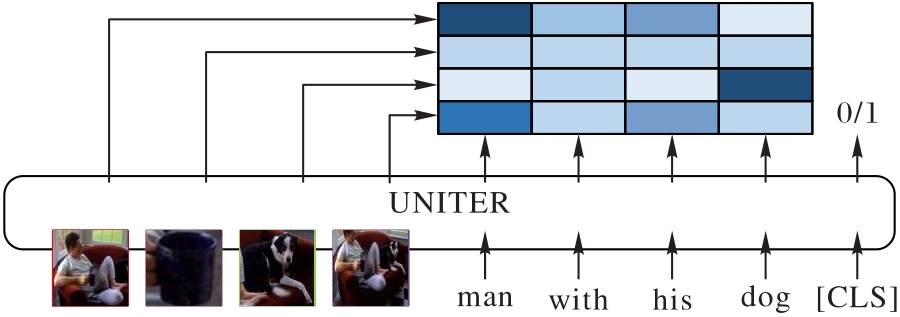
图3 ITM任务图
Fig. 3 ITM task diagram

图4 3种融合方式流程
Fig. 4 Flows of three fusion methods
| 融合方式 | 信息损失 | 融合难度 | 容错性 | 输出 | 时序模型 |
|---|---|---|---|---|---|
| 早期融合 | 中 | 难 | 差 | 分类 | 否 |
| 晚期融合 | 大 | 中 | 中 | 回归 | 是 |
| 混合融合 | 小 | 易 | 好 | 分类 | 否 |
表1 三种融合方式比较
Tab. 1 Comparison of three fusion methods
| 融合方式 | 信息损失 | 融合难度 | 容错性 | 输出 | 时序模型 |
|---|---|---|---|---|---|
| 早期融合 | 中 | 难 | 差 | 分类 | 否 |
| 晚期融合 | 大 | 中 | 中 | 回归 | 是 |
| 混合融合 | 小 | 易 | 好 | 分类 | 否 |
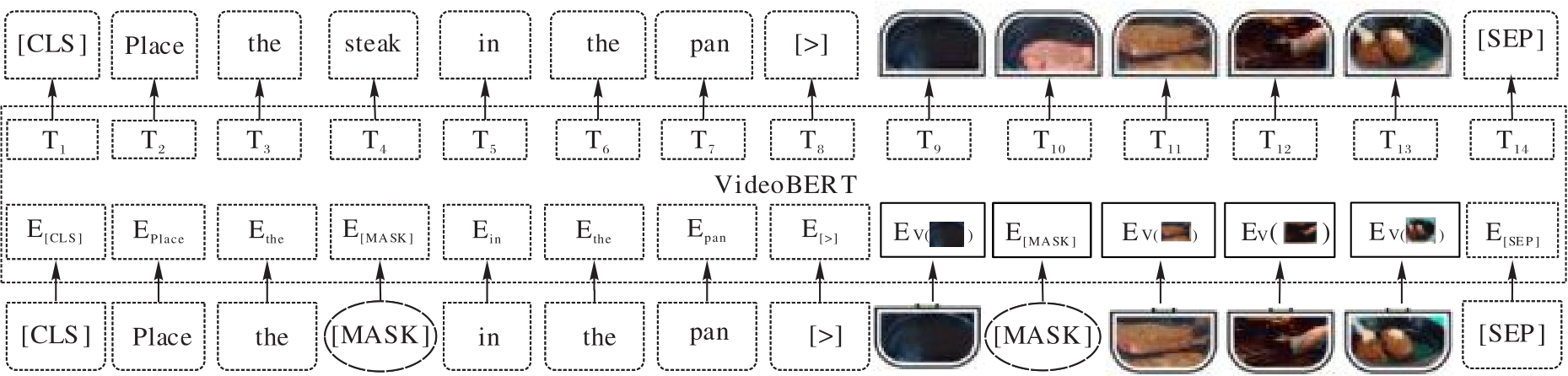
图5 VideoBERT模型结构
Fig. 5 Structure of VideoBERT model
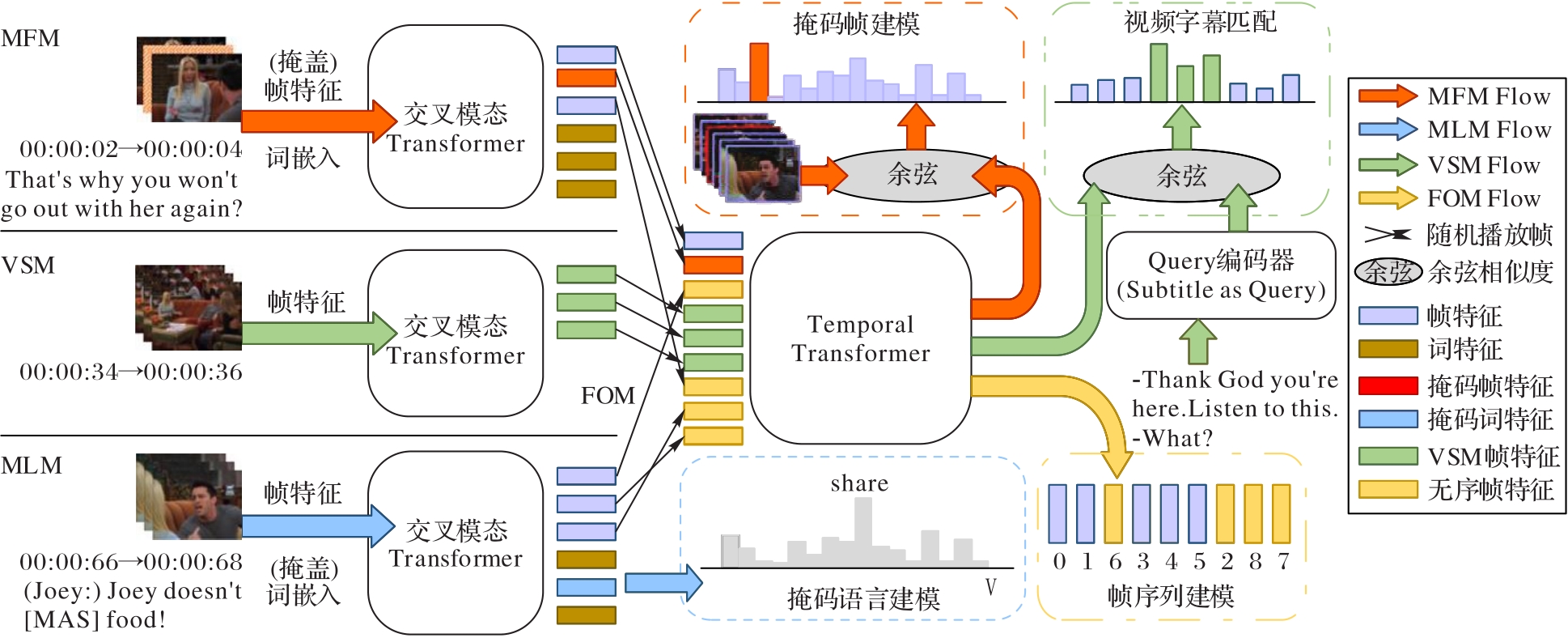
图6 HERO模型
Fig. 6 HERO model

图7 VL-BERT模型
Fig. 7 VL-BERT model

图8 ImageBERT模型
Fig. 8 ImageBERT model

图9 UniVL模型
Fig. 9 UniVL model

图10 ERNIE-ViL模型
Fig. 10 ERNIE-ViL model
| 模型 | 初始模型 | 预训练任务 | 视觉构成 | 下游任务 | 特征提取器 | 预训练数据集 | |
|---|---|---|---|---|---|---|---|
| 单流 | VideoBERT[ | BERT | 1)根据文本预测视频,根据文本 自动插图;2)根据视频预测文本, 对视频自动生成摘要 | 视频帧 | 1)视频字幕; 2)零样本动态分类 | S3D[ | Cooking312k[ |
| HERO[ | — | 1)掩码语言建模;2)掩码帧建模; 3)视频字幕匹配;4)帧顺序建模 | 视频帧 | 1)视频语言推断; 2)视频字幕匹配 | — | TV数据集[ Howto100M[ | |
| VL-BERT[ | BERT | 1)掩码文本预测; 2)掩码图像类别预测 | 图像RoI | 1)视觉常识推理;2)视觉 问答;3)引用表达式理解 | Fast R-CNN[ | Conceptual captions[ | |
| ImageBERT[ | BERT | 1)掩码文本预测;2)掩码图像 类别分类;3)掩码图像特征回归; 4)图像文本对齐 | 图像RoI | 1)图像检索;2)文本检索 | Fast R-CNN[ | LAIT数据集 | |
| 双流 | UniVL[ | Transformer | 1)条件屏蔽语言模型; 2)条件屏蔽帧模型; 3)视频文本对齐; 4)语言重建 | 视频帧 | 1)多模态视频字幕; 2)动作分割;3)动作步骤 定位;4)多模态情感分析; 5)基于文本的视频检索 | S3D[ Resnet-101[ Resnet-152 | HowTo100M[ |
| ERNIE-ViL[ | Transformer | 1)视觉问答[ 2)视觉常识推理[ 3)图像&文本检索 | 图像RoI | 场景图预测(目标预测、 属性预测、关系预测) | — | Conceptual Captions(CC)[ SBU Captions[ | |
| ViLBERT[ | BERT | 1)掩码文本预测; 2)掩码图像类别预测; 3)图像文本对齐 | — | 1)图像检索;2)视觉常识 推理;3)视觉问答; 4)引用表达式理解 | Fast R-CNN[ Resnet-101[ | Visual Genome[ | |
| ActBERT[ | BERT | 1)掩码文本预测;2)掩码 动作预测;3)掩码物体预测; 4)视频文本对齐 | 视频帧 | 1)视频检索;2)视频问答; 3)视频描述生成; 4)行为分割;5)动作定位 | Faster R-CNN[ | HowTo100M[ | |
表2 不同模型的比较
Tab. 2 Comparison of different models
| 模型 | 初始模型 | 预训练任务 | 视觉构成 | 下游任务 | 特征提取器 | 预训练数据集 | |
|---|---|---|---|---|---|---|---|
| 单流 | VideoBERT[ | BERT | 1)根据文本预测视频,根据文本 自动插图;2)根据视频预测文本, 对视频自动生成摘要 | 视频帧 | 1)视频字幕; 2)零样本动态分类 | S3D[ | Cooking312k[ |
| HERO[ | — | 1)掩码语言建模;2)掩码帧建模; 3)视频字幕匹配;4)帧顺序建模 | 视频帧 | 1)视频语言推断; 2)视频字幕匹配 | — | TV数据集[ Howto100M[ | |
| VL-BERT[ | BERT | 1)掩码文本预测; 2)掩码图像类别预测 | 图像RoI | 1)视觉常识推理;2)视觉 问答;3)引用表达式理解 | Fast R-CNN[ | Conceptual captions[ | |
| ImageBERT[ | BERT | 1)掩码文本预测;2)掩码图像 类别分类;3)掩码图像特征回归; 4)图像文本对齐 | 图像RoI | 1)图像检索;2)文本检索 | Fast R-CNN[ | LAIT数据集 | |
| 双流 | UniVL[ | Transformer | 1)条件屏蔽语言模型; 2)条件屏蔽帧模型; 3)视频文本对齐; 4)语言重建 | 视频帧 | 1)多模态视频字幕; 2)动作分割;3)动作步骤 定位;4)多模态情感分析; 5)基于文本的视频检索 | S3D[ Resnet-101[ Resnet-152 | HowTo100M[ |
| ERNIE-ViL[ | Transformer | 1)视觉问答[ 2)视觉常识推理[ 3)图像&文本检索 | 图像RoI | 场景图预测(目标预测、 属性预测、关系预测) | — | Conceptual Captions(CC)[ SBU Captions[ | |
| ViLBERT[ | BERT | 1)掩码文本预测; 2)掩码图像类别预测; 3)图像文本对齐 | — | 1)图像检索;2)视觉常识 推理;3)视觉问答; 4)引用表达式理解 | Fast R-CNN[ Resnet-101[ | Visual Genome[ | |
| ActBERT[ | BERT | 1)掩码文本预测;2)掩码 动作预测;3)掩码物体预测; 4)视频文本对齐 | 视频帧 | 1)视频检索;2)视频问答; 3)视频描述生成; 4)行为分割;5)动作定位 | Faster R-CNN[ | HowTo100M[ | |
| 模型 | VQA(数据集为VQA2.0) | VCR(数据集为VCR) | GRE(数据集为RefCOCO+[ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| test-dev | test-std | Q->A | QA->R | Q->AR | val | testA | testB | ||||
| val | test | val | test | val | test | ||||||
| VL-BERT | 71.79 | 72.22 | 75.50 | 75.80 | 77.90 | 78.40 | 58.90 | 59.70 | 72.59 | 78.57 | 62.30 |
| ViLBERT | 70.55 | 70.92 | 72.42 | 73.30 | 74.47 | 74.60 | 54.04 | 54.80 | 72.34 | 78.52 | 62.61 |
| ERNIE-ViL | 73.78 | 73.96 | 78.52 | 79.20 | 83.37 | 83.50 | 65.81 | 66.30 | 74.24 | 80.97 | 64.70 |
表3 各模型在VQA、VCR、GRE任务上的实验结果对比 (%)
Tab. 3 Experimental result comparison of different models on VQA,VCR and GRE tasks
| 模型 | VQA(数据集为VQA2.0) | VCR(数据集为VCR) | GRE(数据集为RefCOCO+[ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| test-dev | test-std | Q->A | QA->R | Q->AR | val | testA | testB | ||||
| val | test | val | test | val | test | ||||||
| VL-BERT | 71.79 | 72.22 | 75.50 | 75.80 | 77.90 | 78.40 | 58.90 | 59.70 | 72.59 | 78.57 | 62.30 |
| ViLBERT | 70.55 | 70.92 | 72.42 | 73.30 | 74.47 | 74.60 | 54.04 | 54.80 | 72.34 | 78.52 | 62.61 |
| ERNIE-ViL | 73.78 | 73.96 | 78.52 | 79.20 | 83.37 | 83.50 | 65.81 | 66.30 | 74.24 | 80.97 | 64.70 |
| 模型 | IR(数据集Flickr30k[ | VR/TVR(数据集YouCook2[ | VC/TVC(数据集为YouCook2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | R@1/% | R@5/% | R@10/% | MR | B-3/% | B-4/% | METEOR/% | ROUNG-L/% | CIDEr | |
| ViLBERT | 58.2 | 84.9 | 91.52 | — | — | — | — | — | — | — | — | — |
| ImageBERT | 73.1 | 92.6 | 96.00 | — | — | — | — | — | — | — | — | — |
| ActBERT | — | — | — | 9.6 | 26.7 | 38.0 | 19 | 8.66 | 5.41 | 13.30 | 30.56 | 0.65 |
| UniVL[ | — | — | — | 28.9 | 57.6 | 70.0 | 4 | 16.46 | 11.17 | 17.57 | 40.09 | 1.27 |
| VideoBERT | — | — | — | — | — | — | — | 6.80 | 4.04 | 11.01 | 27.50 | 0.49 |
| ERNIE-ViL | 75.1 | 93.42 | 96.26 | — | — | — | — | — | — | — | — | — |
| HERO | — | — | — | 6.21 (3.25) | — | 19.34 (13.41) | — | 12.35 (10.87) | — | 17.64 (16.91) | 34.16 (32.81) | 49.98 (45.38) |
表4 各模型在IR、VR、VC任务上的实验结果对比
Tab. 4 Experimental result comparison of different models on IR, VR and VC tasks
| 模型 | IR(数据集Flickr30k[ | VR/TVR(数据集YouCook2[ | VC/TVC(数据集为YouCook2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | R@1/% | R@5/% | R@10/% | MR | B-3/% | B-4/% | METEOR/% | ROUNG-L/% | CIDEr | |
| ViLBERT | 58.2 | 84.9 | 91.52 | — | — | — | — | — | — | — | — | — |
| ImageBERT | 73.1 | 92.6 | 96.00 | — | — | — | — | — | — | — | — | — |
| ActBERT | — | — | — | 9.6 | 26.7 | 38.0 | 19 | 8.66 | 5.41 | 13.30 | 30.56 | 0.65 |
| UniVL[ | — | — | — | 28.9 | 57.6 | 70.0 | 4 | 16.46 | 11.17 | 17.57 | 40.09 | 1.27 |
| VideoBERT | — | — | — | — | — | — | — | 6.80 | 4.04 | 11.01 | 27.50 | 0.49 |
| ERNIE-ViL | 75.1 | 93.42 | 96.26 | — | — | — | — | — | — | — | — | — |
| HERO | — | — | — | 6.21 (3.25) | — | 19.34 (13.41) | — | 12.35 (10.87) | — | 17.64 (16.91) | 34.16 (32.81) | 49.98 (45.38) |

图11 减震透气跑鞋和军旅风迷彩高跟鞋生成图像
Fig. 11 Generation images of shock-absorbing and breathable running shoes and military style camouflage high-heeled shoes

图12 使用VideoBERT预测视频剪辑中的名词和动词
Fig. 12 Predicting nouns and verbs in video clips by VideoBERT
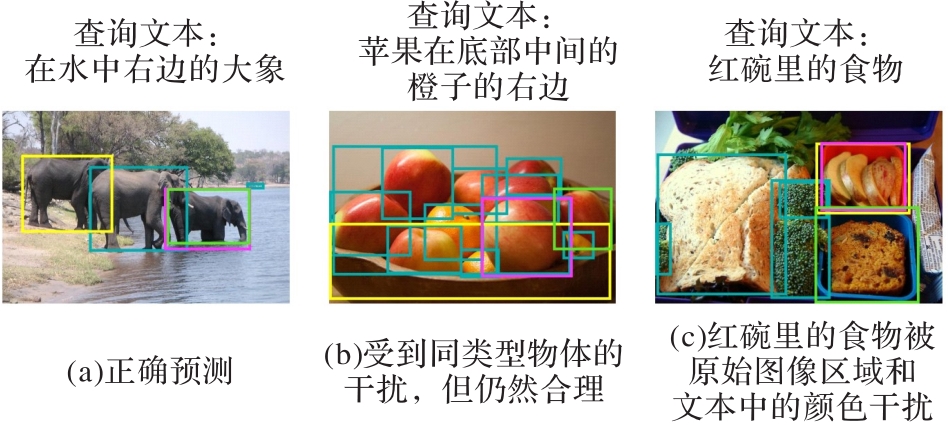
图13 边界框给出的图像区域建议
Fig. 13 Suggestions for image areas given by border frame

图14 视觉问答的各个类别示例
Fig. 14 Each category examples of visual Q&A

图15 文本生成视频
Fig. 15 Text generating video

图16 视频字幕生成
Fig. 16 Video subtitle generation
| 1 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 2 | LUO H S, JI L, SHI B T, et al. UniVL: a unified video and language pre-training model for multimodal understanding and generation[EB/OL]. (2020-09-15) [2021-12-20].. |
| 3 | 赵亮. 多模态数据融合算法研究[D]. 大连:大连理工大学, 2018:1-2. |
| ZHAO L. Research on multimodal data fusion methods[D]. Dalian: Dalian University of Technology, 2018:1-2. | |
| 4 | LU J S, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[EB/OL]. (2019-08-06) [2021-12-20].. |
| 5 | SUN C, MYERS A, VONDRICK C, et al. VideoBERT: a joint model for video and language representation learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7463-7472. 10.1109/iccv.2019.00756 |
| 6 | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from transformers[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 5100-5111. 10.18653/v1/d19-1514 |
| 7 | LI L H, YATSKAR M, YIN D, et al. VisualBERT: a simple and performant baseline for vision and language[EB/OL]. (2019-08-09) [2021-12-21].. |
| 8 | LI G, DUAN N, FANG Y J, et al. Unicoder-VL: a universal encoder for vision and language by cross-modal pre-training[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 11336-11344. 10.1609/aaai.v34i07.6795 |
| 9 | SU W J, ZHU X Z, CAO Y, et al. VL-BERT: pre-training of generic visual-linguistic representations[EB/OL]. (2020-02-18) [2021-12-21].. |
| 10 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 11 | LI J N, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with[C/OL]// Proceedings of the 35th Conference on Neural Information Processing Systems. [2021-12-21].. |
| 12 | 赵广立. 跨模态通用AI平台“紫东太初”发布[N]. 中国科学报, 2021-07-12(4). |
| ZHAO G L. Cross-modal universal AI platform "Zidong Taichu" was released[N]. China Science Daily, 2021-07-12(4). | |
| 13 | SHARMA P, DING N, GOODMAN S, et al. Conceptual captions: a cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2018: 2556-2565. 10.18653/v1/p18-1238 |
| 14 | ORDONEZ V, KULKARNI G, BERG T L. Im2Text: describing images using 1 million captioned photographs[C]// Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2011: 1143-1151. |
| 15 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 16 | PLUMMER B A, WANG L W, CERVANTES C M, et al. Flickr30k Entities: collecting region-to-phrase correspondences for richer image-to-sentence models[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2641-2649. 10.1109/iccv.2015.303 |
| 17 | HUDSON D A, MANNING C D. GQA: a new dataset for real-world visual reasoning and compositional question answering[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6693-6702. 10.1109/cvpr.2019.00686 |
| 18 | ANTOL S, AGRAWAL A, LU J S, et al. VQA: visual question answering[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2425-2433. 10.1109/iccv.2015.279 |
| 19 | KRISHNA R, ZHU Y K, GROTH O, et al. Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. 10.1007/s11263-016-0981-7 |
| 20 | CHEN Y C, LI L J, YU L C, et al. UNITER: UNiversal Image-TExt Representation learning[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 104-120. |
| 21 | QI D, SU L, SONG J, et al. ImageBERT: cross-modal pre-training with large-scale weak-supervised image-text data[EB/OL]. (2020-01-23) [2021-12-21].. |
| 22 | ZHU Y K, KIROS R, ZEMEL R, et al. Aligning books and movies: towards story-like visual explanations by watching movies and reading books[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 19-27. 10.1109/iccv.2015.11 |
| 23 | LU J S, GOSWAMI V, ROHRBACH M, et al. 12-in-1: multi-task vision and language representation learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10434-10443. 10.1109/cvpr42600.2020.01045 |
| 24 | SINHA K, JIA R, HUPKES D, et al. Masked language modeling and the distributional hypothesis: order word matters pre-training for little[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 2888-2913. 10.18653/v1/2021.emnlp-main.230 |
| 25 | ZHOU L W, PALANGI H, ZHANG L, et al. Unified vision-language pre-training for image captioning and VQA[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 13041-13049. 10.1609/aaai.v34i07.7005 |
| 26 | MENG R H, RICE S G, WANG J, et al. A fusion steganographic algorithm based on Faster R-CNN[J]. Computers, Materials and Continua, 2018, 55(1): 1-16. |
| 27 | HUANG Z C, ZENG Z Y, LIU B, et al. Pixel-BERT: aligning image pixels with text by deep multi-modal transformers[EB/OL]. (2020-06-22) [2021-12-21].. |
| 28 | FRANK S, BUGLIARELLO E, ELLIOTT D. Vision-and-language or vision-for-language? on cross-modal influence in multimodal transformers[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 9847-9857. 10.18653/v1/2021.emnlp-main.775 |
| 29 | LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 212-228. |
| 30 | LAHAT D, ADALI T, JUTTEN C. Multimodal data fusion: an overview of methods, challenges, and prospects[J]. Proceedings of the IEEE, 2015, 103(9): 1449-1477. 10.1109/jproc.2015.2460697 |
| 31 | GAO J, LI P, CHEN Z K, et al. A survey on deep learning for multimodal data fusion[J]. Neural Computation, 2020, 32(5): 829-864. 10.1162/neco_a_01273 |
| 32 | BALAKRISHNAMA S, GANAPATHIRAJU A. Linear discriminant analysis - a brief tutorial[EB/OL]. [2021-12-21].. 10.1109/secon.1999.766096 |
| 33 | NEFIAN A V, LIANG L H, PI X B, et al. Dynamic Bayesian networks for audio-visual speech recognition[J]. EURASIP Journal on Advances in Signal Processing, 2002, 2002: No.783042. 10.1155/s1110865702206083 |
| 34 | MARTÍNEZ H P, YANNAKAKIS G N. Deep multimodal fusion: combining discrete events and continuous signals[C]// Proceedings of the 16th International Conference on Multimodal Interaction. New York: ACM, 2014: 34-41. 10.1145/2663204.2663236 |
| 35 | EDDY S R. What is a hidden Markov model?[J]. Nature Biotechnology, 2004, 22(10): 1315-1316. 10.1038/nbt1004-1315 |
| 36 | HEARST M A, DUMAIS S T, OSUNA E, et al. Support vector machines[J]. IEEE Intelligent Systems and their Applications, 1998, 13(4): 18-28. 10.1109/5254.708428 |
| 37 | TURK M. Multimodal interaction: a review[J]. Pattern Recognition Letters, 2014, 36: 189-195. 10.1016/j.patrec.2013.07.003 |
| 38 | LI X P, SONG J K, GAO L L, et al. Beyond RNNs: positional self-attention with co-attention for video question answering[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 8658-8665. 10.1609/aaai.v33i01.33018658 |
| 39 | OWENS A, ISOLA P, McDERMOTT J, et al. Visually indicated sounds[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2405-2413. 10.1109/cvpr.2016.264 |
| 40 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 41 | LI L J, CHEN Y C, CHENG Y, et al. HERO: hierarchical encoder for video+ language omni-representation pre-training[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 2046-2065. 10.18653/v1/2020.emnlp-main.161 |
| 42 | YAMADA K, SASANO R, TAKEDA K. Semantic frame induction using masked word embeddings and two-step clustering[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg, PA: ACL, 2021: 811-816. 10.18653/v1/2021.acl-short.102 |
| 43 | KAMIGAITO H, HAYASHI K. Unified interpretation of softmax cross-entropy and negative sampling: with case study for knowledge graph embedding[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 5517-5531. 10.18653/v1/2021.acl-long.429 |
| 44 | JANG E, GU S X, POOLE B. Categorical reparameterization with Gumbel-Softmax[EB/OL]. (2017-08-05) [2021-12-24].. |
| 45 | WU Y H, SCHUSTER M, CHEN Z F, et al. Google’s neural machine translation system: bridging the gap between human and machine translation[EB/OL]. (2016-10-08) [2021-12-24].. |
| 46 | LI Z J, FAN Z H, TOU H X, et al. MVPTR: multi-level semantic alignment for vision-language pre-training via multi-stage learning[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 4395-4405. 10.1145/3503161.3548341 |
| 47 | XIE S N, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11219. Cham: Springer, 2018: 318-355. |
| 48 | SUN Y, WANG S H, LI Y K, et al. ERNIE: enhanced representation through knowledge integration[EB/OL]. (2019-04-19) [2021-12-24].. |
| 49 | SUN Y, WANG S H, LI Y K, et al. ERNIE 2.0: a continual pre-training framework for language understanding[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8968-8975. 10.1609/aaai.v34i05.6428 |
| 50 | YU F, TANG J J, YIN W C, et al. ERNIE-ViL: knowledge enhanced vision-language representations through scene graphs[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 3208-3216. 10.1609/aaai.v35i4.16431 |
| 51 | ZELLERS R, BISK Y, FARHADI A, et al. From recognition to cognition: visual commonsense reasoning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6713-6724. 10.1109/cvpr.2019.00688 |
| 52 | YANG S B, LI G B, YU Y Z. Cross-modal relationship inference for grounding referring expressions[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4140-4149. 10.1109/cvpr.2019.00427 |
| 53 | ZHANG Q, LEI Z, ZHANG Z X, et al. Context-aware attention network for image-text retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3533-3542. 10.1109/cvpr42600.2020.00359 |
| 54 | ZHU L C, YANG Y. ActBERT: learning global-local video-text representations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8743-8752. 10.1109/cvpr42600.2020.00877 |
| 55 | LEI J, YU L C, BANSAL M, et al. TVQA: localized, compositional video question answering[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 1369-1379. 10.18653/v1/d18-1167 |
| 56 | MIECH A, ZHUKOV D, ALAYRAC J B, et al. HowTo100m: learning a text-video embedding by watching hundred million narrated video clips[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2630-2640. 10.1109/iccv.2019.00272 |
| 57 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 58 | YU Z, YU J, CUI Y H, et al. Deep modular co-attention networks for visual question answering[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6274-6283. 10.1109/cvpr.2019.00644 |
| 59 | XIONG Z G, TANG Z W, CHEN X W, et al. Research on image retrieval algorithm based on combination of color and shape features[J]. Journal of Signal Processing Systems, 2021, 93(2/3): 139-146. 10.1007/s11265-019-01508-y |
| 60 | GABEUR V, SUN C, ALAHARI K, et al. Multi-modal transformer for video retrieval[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12349. Cham: Springer, 2020: 214-229. |
| 61 | WANG B R, MA L, ZHANG W, et al. Reconstruction network for video captioning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7622-7631. 10.1109/cvpr.2018.00795 |
| 62 | LEI J, YU L C, BERG T L, et al. TVR: a large-scale dataset for video-subtitle moment retrieval[C]// Proceedings of the 2020 European Conference on Computer Vision LNCS 12366 . Cham: Springer, 2020: 447-463. 10.1007/978-3-030-58589-1_27 |
| 63 | KAZEMZADEH S, ORDONEZ V, MATTEN M, et al. ReferItGame: referring to objects in photographs of natural scenes[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 787-798. 10.3115/v1/d14-1086 |
| 64 | YOUNG P, LAI A, HODOSH M, et al. From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2: 67-78. 10.1162/tacl_a_00166 |
| 65 | ZHOU L W, XU C L, CORSO J J. Towards automatic learning of procedures from web instructional videos[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 7590-7598. 10.1609/aaai.v32i1.12342 |
| 66 | YAO Y, ZHANG A, ZHANG Z Y, et al. CPT: colorful prompt tuning for pre-trained vision-language models[EB/OL]. (2022-05-20) [2021-12-24].. 10.18653/v1/2022.findings-acl.273 |
| 67 | ZHAO Z Q, ZHENG P, XU S T, et al. Object detection with deep learning: a review[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(11): 3212-3232. 10.1109/tnnls.2018.2876865 |
| 68 | HONG G, KIM Y, CHOI Y, et al. BioPREP: deep learning-based predicate classification with SemMedDB[J]. Journal of Biomedical Informatics, 2021, 122: No.103888. 10.1016/j.jbi.2021.103888 |
| 69 | LI J, LIN D Y, WANG Y, et al. Deep discriminative representation learning with attention map for scene classification[J]. Remote Sensing, 2020, 12(9): No.1366. 10.3390/rs12091366 |
| 70 | LIN J U, MEN R, YANG A, et al. M6 : a Chinese multimodal pretrainer[EB/OL]. (2021-05-29) [2021-12-24].. |
| 71 | A van den OORD, VINYALS O, KAVUKCUOGLU K. Neural discrete representation learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6309-6318. |
| 72 | KASBAN H, HASHIMA S. Adaptive radiographic image compression technique using hierarchical vector quantization and Huffman encoding[J]. Journal of Ambient Intelligence and Humanized Computing, 2019, 10(7): 2855-2867. 10.1007/s12652-018-1016-8 |
| 73 | YAN M, XU H Y, LI C L, et al. Achieving human parity on visual question answering[EB/OL]. (2021-11-19) [2021-12-24].. 10.1145/3572833 |
| 74 | CAI W W, SONG Y P, WEI Z G. Multimodal data guided spatial feature fusion and grouping strategy for e-commerce commodity demand forecasting[J]. Mobile Information Systems, 2021, 2021: No.5568208. 10.1155/2021/5568208 |
| 75 | DESHPANDE A M, KALBHOR S R. Video-based marathi sign language recognition and text conversion using convolutional neural network[M]// HITENDRA SARMA T, SANKAR V, SHAIK R A. Emerging Trends in Electrical, Communications, and Information Technologies: Proceedings of ICECIT-2018, LNEE 569. Singapore: Springer, 2020: 761-773. 10.1007/978-981-13-8942-9_65 |
| 76 | HAN X, ZHANG Z Y, DING N, et al. Pre-trained models: past, present and future[J]. AI Open, 2021, 2: 225-250. 10.1016/j.aiopen.2021.08.002 |
| [1] | 杨兴耀, 陈羽, 于炯, 张祖莲, 陈嘉颖, 王东晓. 结合自我特征和对比学习的推荐模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2704-2710. |
| [2] | 王娜, 蒋林, 李远成, 朱筠. 基于图形重写和融合探索的张量虚拟机算符融合优化[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2802-2809. |
| [3] | 李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2903-2910. |
| [4] | 唐廷杰, 黄佳进, 秦进. 基于图辅助学习的会话推荐[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2711-2718. |
| [5] | 张睿, 张鹏云, 高美蓉. 自优化双模态多通路非深度前庭神经鞘瘤识别模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2975-2982. |
| [6] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [7] | 方介泼, 陶重犇. 应对零日攻击的混合车联网入侵检测系统[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2763-2769. |
| [8] | 杨航, 李汪根, 张根生, 王志格, 开新. 基于图神经网络的多层信息交互融合算法用于会话推荐[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2719-2725. |
| [9] | 杜郁, 朱焱. 构建预训练动态图神经网络预测学术合作行为消失[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2726-2731. |
| [10] | 姚光磊, 熊菊霞, 杨国武. 基于神经网络优化的花朵授粉算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2829-2837. |
| [11] | 黄颖, 杨佳宇, 金家昊, 万邦睿. 用于RGBT跟踪的孪生混合信息融合算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2878-2885. |
| [12] | 沈哲远, 杨珂珂, 李京. 基于双流神经网络的个性化联邦学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2319-2325. |
| [13] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [14] | 杨莹, 郝晓燕, 于丹, 马垚, 陈永乐. 面向图神经网络模型提取攻击的图数据生成方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2483-2492. |
| [15] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||