


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (9): 2903-2910.DOI: 10.11772/j.issn.1001-9081.2023091242
李云1, 王富铕2( ), 井佩光3, 王粟4, 肖澳5
), 井佩光3, 王粟4, 肖澳5
收稿日期:2023-09-18
修回日期:2023-12-11
接受日期:2023-12-12
发布日期:2024-03-15
出版日期:2024-09-10
通讯作者:
王富铕
作者简介:李云(1978—),女(壮族),广西南宁人,教授,博士,CCF会员,主要研究方向:大数据、人工智能基金资助:
Yun LI1, Fuyou WANG2(), Peiguang JING3, Su WANG4, Ao XIAO5
Received:2023-09-18
Revised:2023-12-11
Accepted:2023-12-12
Online:2024-03-15
Published:2024-09-10
Contact:
Fuyou WANG
About author:LI Yun, born in 1978, Ph. D., professor. Her research interests include big data, artificial intelligence.Supported by:摘要:
针对如何联合短视频的帧不确定度和时序关联性,以增强事件检测能力的问题,提出一种基于不确定度感知的帧关联短视频事件检测方法。首先,利用2D卷积神经网络(CNN)提取短视频每一帧的特征,再将该特征多次前向传播并通过贝叶斯变分层获得特征均值和与特征对应的不确定度信息;其次,利用模型构建的不确定度感知模块将特征均值和不确定度信息进行融合,再将融合后所得的各帧特征通过时序关联模块加强时域上的联系;最后,用时域关联后的特征通过分类网络实现短视频事件检测。在从Flickr平台上爬取到的短视频事件检测数据集上开展实验对比,实验结果表明,支持向量机(SVM)等子空间学习方法的分类性能较差,对高级语义表示的探索不充分;而深度学习方法对于事件检测的准确率明显更优。相较于SViTT(Sparse Video-Text Transformer)方法,所提方法的准确率、平均召回率和平均精度分别提高了3.37%、2.55%和2.09%,验证了所提方法在短视频事件检测任务上的有效性。
中图分类号:
李云, 王富铕, 井佩光, 王粟, 肖澳. 基于不确定度感知的帧关联短视频事件检测方法[J]. 计算机应用, 2024, 44(9): 2903-2910.
Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method[J]. Journal of Computer Applications, 2024, 44(9): 2903-2910.
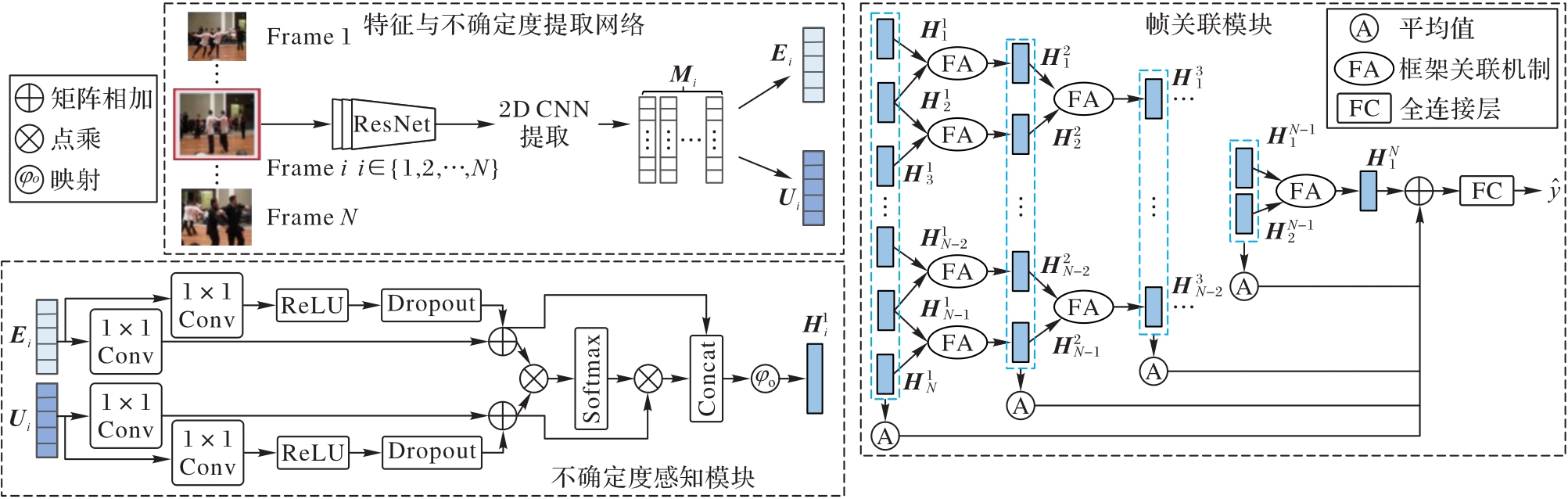
图1 本文方法的框架
Fig. 1 Framework of proposed method
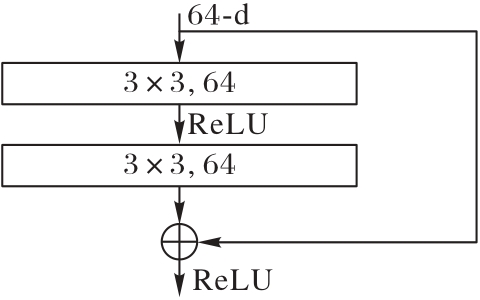
图2 2D CNN的结构
Fig. 2 Structure of 2D CNN
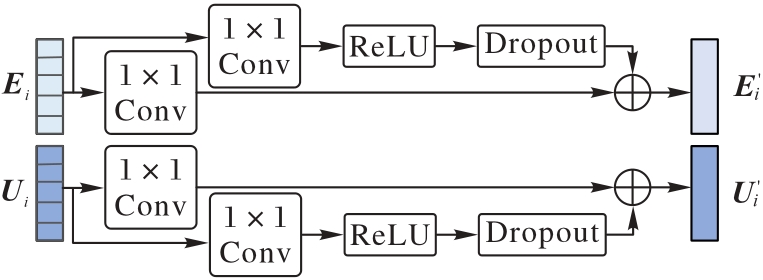
图3 特征映射模块的结构
Fig. 3 Structure of feature mapping module

图4 UIAM的结构
Fig. 4 Structure of UIAM
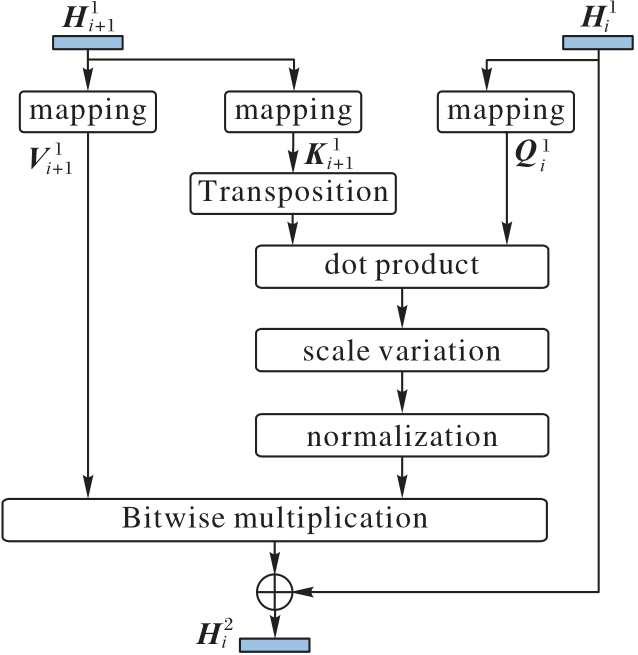
图5 帧关联机制
Fig. 5 Frame association mechanism
| 帧数 | 模型 | AR | AP | ACC |
|---|---|---|---|---|
| 4 | 模型A | 0.533 | 0.540 | 0.554 |
| 模型B | 0.654 | 0.662 | 0.674 | |
| 8 | 模型A | 0.573 | 0.588 | 0.602 |
| 模型B | 0.701 | 0.712 | 0.720 | |
| 12 | 模型A | 0.598 | 0.602 | 0.610 |
| 模型B | 0.738 | 0.752 | 0.760 | |
| 16 | 模型A | 0.608 | 0.622 | 0.615 |
| 模型B | 0.763 | 0.782 | 0.798 | |
| 20 | 模型A | 0.610 | 0.633 | 0.622 |
| 模型B | 0.763 | 0.782 | 0.798 |
表1 视频帧数对本文模型效果的影响
Tab. 1 Influence of number of video frames on proposed model performance
| 帧数 | 模型 | AR | AP | ACC |
|---|---|---|---|---|
| 4 | 模型A | 0.533 | 0.540 | 0.554 |
| 模型B | 0.654 | 0.662 | 0.674 | |
| 8 | 模型A | 0.573 | 0.588 | 0.602 |
| 模型B | 0.701 | 0.712 | 0.720 | |
| 12 | 模型A | 0.598 | 0.602 | 0.610 |
| 模型B | 0.738 | 0.752 | 0.760 | |
| 16 | 模型A | 0.608 | 0.622 | 0.615 |
| 模型B | 0.763 | 0.782 | 0.798 | |
| 20 | 模型A | 0.610 | 0.633 | 0.622 |
| 模型B | 0.763 | 0.782 | 0.798 |
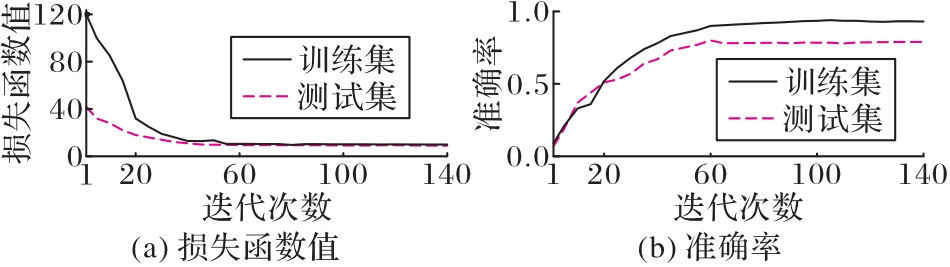
图6 本文模型的收敛曲线
Fig. 6 Convergence curves of proposed model
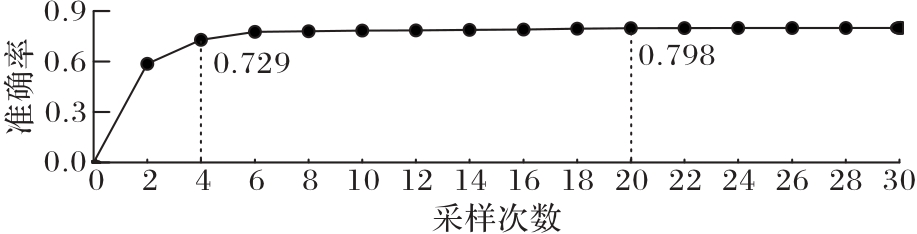
图7 采样次数对模型性能影响
Fig. 7 Influence of sampling times on model performance
| 层数 | AR | AP | ACC |
|---|---|---|---|
| 1 | 0.714 | 0.721 | 0.732 |
| 2 | 0.742 | 0.756 | 0.755 |
| 3 | 0.763 | 0.782 | 0.798 |
| 4 | 0.732 | 0.747 | 0.750 |
| 5 | 0.716 | 0.712 | 0.707 |
| 6 | 0.691 | 0.685 | 0.686 |
表2 不同层数的变分层对本文模型性能影响
Tab. 2 Influence of variable layering with different layers on proposed model performance
| 层数 | AR | AP | ACC |
|---|---|---|---|
| 1 | 0.714 | 0.721 | 0.732 |
| 2 | 0.742 | 0.756 | 0.755 |
| 3 | 0.763 | 0.782 | 0.798 |
| 4 | 0.732 | 0.747 | 0.750 |
| 5 | 0.716 | 0.712 | 0.707 |
| 6 | 0.691 | 0.685 | 0.686 |
| 步长 | AR | AP | ACC |
|---|---|---|---|
| 1 | 0.763 | 0.782 | 0.798 |
| 2 | 0.742 | 0.756 | 0.755 |
| 3 | 0.736 | 0.728 | 0.744 |
| 4 | 0.722 | 0.713 | 0.726 |
表3 不同步长的帧关联对本文模型性能影响
Tab. 3 Influence of frame association with different step sizes on proposed model performance
| 步长 | AR | AP | ACC |
|---|---|---|---|
| 1 | 0.763 | 0.782 | 0.798 |
| 2 | 0.742 | 0.756 | 0.755 |
| 3 | 0.736 | 0.728 | 0.744 |
| 4 | 0.722 | 0.713 | 0.726 |
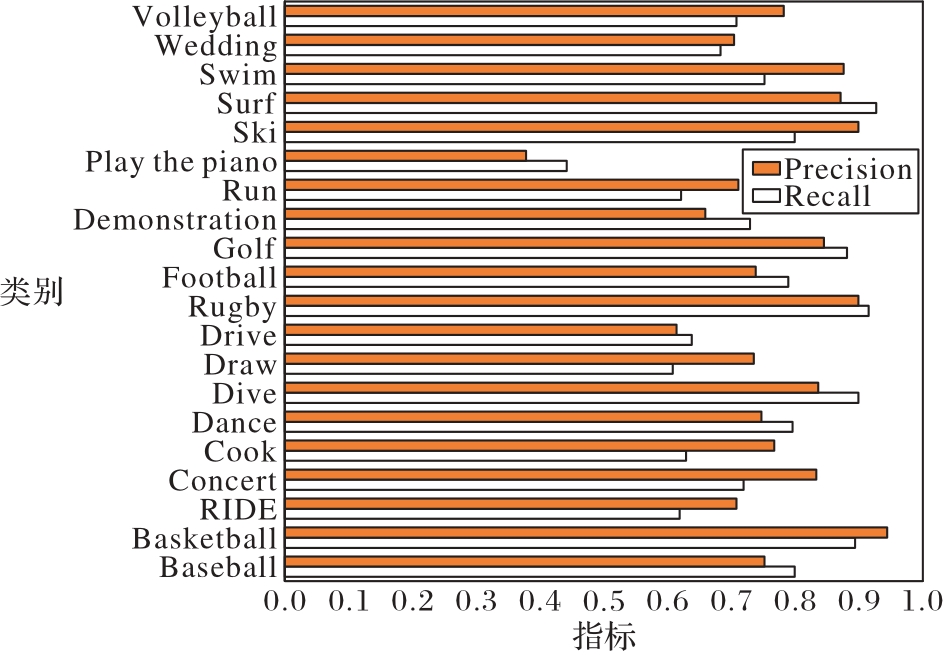
图8 每一类别短视频的精确率与召回率
Fig. 8 Precision and recall for each category of short videos
| 方法 | AR | AP | ACC |
|---|---|---|---|
| I3D+残差模块 | 0.692 | 0.713 | 0.722 |
| EASTERN+残差模块 | 0.744 | 0.770 | 0.778 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
表4 残差模块的实验结果
Tab. 4 Experimental results of residual module
| 方法 | AR | AP | ACC |
|---|---|---|---|
| I3D+残差模块 | 0.692 | 0.713 | 0.722 |
| EASTERN+残差模块 | 0.744 | 0.770 | 0.778 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
| 方法 | AR | AP | ACC |
|---|---|---|---|
| Self-Attention | 0.682 | 0.708 | 0.712 |
| Multi-Scale Attention | 0.726 | 0.733 | 0.745 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
表5 不同注意力机制的实验结果
Tab. 5 Experimental results of different attention mechanisms
| 方法 | AR | AP | ACC |
|---|---|---|---|
| Self-Attention | 0.682 | 0.708 | 0.712 |
| Multi-Scale Attention | 0.726 | 0.733 | 0.745 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
| 方法 | AR | AP | ACC |
|---|---|---|---|
| noB+U | 0.658 | 0.671 | 0.688 |
| noB+T | 0.624 | 0.645 | 0.650 |
| noU+T | 0.573 | 0.588 | 0.576 |
| noBNN | 0.738 | 0.747 | 0.752 |
| noUPM | 0.710 | 0.728 | 0.733 |
| noTCM | 0.680 | 0.695 | 0.704 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
表6 消融实验结果
Tab. 6 Results of ablation experiments
| 方法 | AR | AP | ACC |
|---|---|---|---|
| noB+U | 0.658 | 0.671 | 0.688 |
| noB+T | 0.624 | 0.645 | 0.650 |
| noU+T | 0.573 | 0.588 | 0.576 |
| noBNN | 0.738 | 0.747 | 0.752 |
| noUPM | 0.710 | 0.728 | 0.733 |
| noTCM | 0.680 | 0.695 | 0.704 |
| 本文方法 | 0.763 | 0.782 | 0.798 |
| 类型 | 方法 | AR | AP | ACC |
|---|---|---|---|---|
| 子空间学习 | SVM | 0.442 | 0.461 | 0.482 |
| SRRS | 0.487 | 0.491 | 0.501 | |
| DTSL | 0.513 | 0.524 | 0.533 | |
| 深度学习 | C3D | 0.552 | 0.571 | 0.582 |
| GoogleNet | 0.617 | 0.651 | 0.661 | |
| ResNet3D | 0.632 | 0.671 | 0.672 | |
| I3D | 0.671 | 0.692 | 0.712 | |
| EASTERN | 0.738 | 0.760 | 0.765 | |
| SViTT | 0.744 | 0.766 | 0.772 | |
| PSN | 0.722 | 0.733 | 0.728 | |
| 本文方法 | 0.763 | 0.782 | 0.798 |
表7 Flickr数据集上的不同方法的短视频事件分类性能对比
Tab. 7 Comparison of short video event classification performance of different methods on Flickr dataset
| 类型 | 方法 | AR | AP | ACC |
|---|---|---|---|---|
| 子空间学习 | SVM | 0.442 | 0.461 | 0.482 |
| SRRS | 0.487 | 0.491 | 0.501 | |
| DTSL | 0.513 | 0.524 | 0.533 | |
| 深度学习 | C3D | 0.552 | 0.571 | 0.582 |
| GoogleNet | 0.617 | 0.651 | 0.661 | |
| ResNet3D | 0.632 | 0.671 | 0.672 | |
| I3D | 0.671 | 0.692 | 0.712 | |
| EASTERN | 0.738 | 0.760 | 0.765 | |
| SViTT | 0.744 | 0.766 | 0.772 | |
| PSN | 0.722 | 0.733 | 0.728 | |
| 本文方法 | 0.763 | 0.782 | 0.798 |
| 方法 | 测试时间/s | 浮点运算量/GFLOPs |
|---|---|---|
| I3D | 264 | 112.4 |
| SViTT | 292 | 296.2 |
| PSN | 206 | 82.3 |
| 本文方法 | 372 | 442.6 |
表8 不同方法的复杂度实验结果
Tab. 8 Complexity experimental results of different methods
| 方法 | 测试时间/s | 浮点运算量/GFLOPs |
|---|---|---|
| I3D | 264 | 112.4 |
| SViTT | 292 | 296.2 |
| PSN | 206 | 82.3 |
| 本文方法 | 372 | 442.6 |
| 1 | JING P, SU Y, NIE L, et al. Low-rank multi-view embedding learning for micro-video popularity prediction [J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(8): 1519-1532. |
| 2 | WEI Y, WANG X, GUAN W, et al. Neural multimodal cooperative learning toward micro-video understanding [J]. IEEE Transactions on Image Processing, 2020, 29: 1-14. |
| 3 | LIU S, CHEN Z, LIU H, et al. User-video co-attention network for personalized micro-video recommendation [C]// Proceedings of the 2019 World Wide Web Conference. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2019: 3020-3026. |
| 4 | WANG Y, HE D, LI F, et al. Multi-label classification with label graph superimposing [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12265-12272. |
| 5 | YE O, DENG J, YU Z, et al. Abnormal event detection via feature expectation subgraph calibrating classification in video surveillance scenes [J]. IEEE Access, 2020, 8: 97564-97575. |
| 6 | XU P, BAI L, PEI X, et al. Uncertainty matters: Bayesian modeling of bicycle crashes with incomplete exposure data [J]. Accident Analysis and Prevention, 2022, 165: No.106518. |
| 7 | ABDAR M, SAMAMI M, DEHGHANI MAHMOODABAD S, et al. Uncertainty quantification in skin cancer classification using three-way decision-based Bayesian deep learning [J]. Computers in Biology and Medicine, 2021, 135: No.104418. |
| 8 | KENDALL A, GAL Y. What uncertainties do we need in Bayesian deep learning for computer vision? [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5580-5590. |
| 9 | GENG J, MIAO Z, ZHANG X P. Efficient heuristic methods for multimodal fusion and concept fusion in video concept detection[J]. IEEE Transactions on Multimedia, 2015, 17(4): 498-511. |
| 10 | YANG Y, MA Z, XU Z, et al. How related exemplars help complex event detection in web videos? [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 2104-2111. |
| 11 | XING T, VILAMALA M R, GARCIA L, et al. DeepCEP: deep complex event processing using distributed multimodal information[C]// Proceedings of the 2019 IEEE International Conference on Smart Computing. Piscataway: IEEE, 2019: 87-92. |
| 12 | 井佩光,宋晓艺,苏育挺. 基于深度动态语义关联的短视频事件检测[J]. 激光与光电子学进展, 2024, 61(4): 0437002. |
| JING P G, SONG X Y, SU Y T. Micro-video event detection based on deep dynamic semantic correlation [J]. Laser and Optoelectronics Progress, 2024, 61(4): 0437002. | |
| 13 | 天津大学.一种用于短视频的事件检测方法: CN201910303095.7 [P]. 2019-08-09. |
| Tianjin University. An event detection method for short videos: CN201910303095.7 [P]. 2019-08-09. | |
| 14 | GAL Y, GHAHRAMANI Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1050-1059. |
| 15 | ZHANG J, ZHAO X, JIN S, et al. Phase-resolved real-time ocean wave prediction with quantified uncertainty based on variational Bayesian machine learning [J]. Applied Energy, 2022, 324: No.119711. |
| 16 | DEODATO G. Uncertainty modeling in deep learning: variational inference for Bayesian neural networks [D]. Torino: Politecnico di Torino, 2019: 122-125. |
| 17 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 18 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 19 | CHEN T, FOX E B, GUESTRIN C. Stochastic gradient Hamiltonian Monte Carlo [C]// Proceedings of the 31st International Conference on Machine Learning. New York: JMLR.org, 2014: 1683-1691. |
| 20 | WELLING M, TEH Y W. Bayesian learning via stochastic gradient Langevin dynamics [C]// Proceedings of the 28th International Conference on Machine Learning. New York: JMLR.org, 2011: 681-688. |
| 21 | MacKAY D J C. A practical Bayesian framework for backpropagation networks [J]. Neural Computation, 1992, 4(3): 448-472. |
| 22 | FROME A, CORRADO G S, SHLENS J, et al. DeViSE: a deep visual-semantic embedding model [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 2121-2129. |
| 23 | CHEN H, DING G, LIU X, et al. IMRAM: iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12652-12660. |
| 24 | LI Y, MIN K, TRIPATHI S, et al. SViTT: temporal learning of sparse video-text Transformers [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 18919-18929. |
| 25 | WANG X, ZHU L, WU F, et al. A differentiable parallel sampler for efficient video classification [J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(3): No.112. |
| [1] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [2] | 陈虹, 齐兵, 金海波, 武聪, 张立昂. 融合1D-CNN与BiGRU的类不平衡流量异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2493-2499. |
| [3] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [4] | 张春雪, 仇丽青, 孙承爱, 荆彩霞. 基于两阶段动态兴趣识别的购买行为预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2365-2371. |
| [5] | 高阳峄, 雷涛, 杜晓刚, 李岁永, 王营博, 闵重丹. 基于像素距离图和四维动态卷积网络的密集人群计数与定位方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2233-2242. |
| [6] | 王东炜, 刘柏辰, 韩志, 王艳美, 唐延东. 基于低秩分解和向量量化的深度网络压缩方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1987-1994. |
| [7] | 黄梦源, 常侃, 凌铭阳, 韦新杰, 覃团发. 基于层间引导的低光照图像渐进增强算法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1911-1919. |
| [8] | 李健京, 李贯峰, 秦飞舟, 李卫军. 基于不确定知识图谱嵌入的多关系近似推理模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1751-1759. |
| [9] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [10] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [11] | 高文烁, 陈晓云. 基于节点结构的点云分类网络[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1471-1478. |
| [12] | 席治远, 唐超, 童安炀, 王文剑. 基于双路时空网络的驾驶员行为识别[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1511-1519. |
| [13] | 孙敏, 成倩, 丁希宁. 基于CBAM-CGRU-SVM的Android恶意软件检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1539-1545. |
| [14] | 王杰, 孟华. 基于点云整体拓扑结构的图像分类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1107-1113. |
| [15] | 陈天华, 朱家煊, 印杰. 基于注意力机制的鸟类识别算法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1114-1120. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||