


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (7): 2237-2244.DOI: 10.11772/j.issn.1001-9081.2024060886
王艺涵, 路翀( ), 陈忠源
), 陈忠源
收稿日期:2024-07-01
修回日期:2024-09-18
接受日期:2024-09-18
发布日期:2025-07-10
出版日期:2025-07-10
通讯作者:
路翀
作者简介:王艺涵(2000—),男,山东淄博人,硕士研究生,CCF学生会员,主要研究方向:数据分析、人工智能基金资助:
Yihan WANG, Chong LU(), Zhongyuan CHEN
Received:2024-07-01
Revised:2024-09-18
Accepted:2024-09-18
Online:2025-07-10
Published:2025-07-10
Contact:
Chong LU
About author:WANG Yihan, born in 2000, M. S. candidate. His research interests include data analysis, artificial intelligence.Supported by:摘要:
近年来,利用文本、视觉和音频数据分析视频中说话者情感的多模态情感分析(MSA)引起了广泛关注。然而,不同模态在情感分析中的贡献大不相同。通常,文本中包含的信息更加直观,因此寻求一种用于增强文本在情感分析中作用的策略显得尤为重要。针对这一问题,提出一种跨模态文本信息增强的多模态情感分析模型(MSAM-CTE)。首先,使用BERT(Bidirectional Encoder Representations from Transformers)预训练模型提取文本特征,并使用双向长短期记忆(Bi-LSTM)网络对预处理后的音频和视频特征进行进一步处理;其次,通过基于文本的交叉注意力机制,将文本信息融入情感相关的非语言表示中,以学习面向文本的成对跨模态映射,从而获得有效的统一多模态表示;最后,使用融合特征进行情感分析。实验结果表明,与最优的基线模型——文本增强Transformer融合网络(TETFN)相比,MSAM-CTE在数据集CMU-MOSI (Carnegie Mellon University Multimodal Opinion Sentiment Intensity)上的平均绝对误差(MAE)和皮尔逊相关系数(Corr)分别降低了2.6%和提高了0.1%;在数据集CMU-MOSEI (Carnegie Mellon University Multimodal Opinion Sentiment and Emotion Intensity)上的两个指标分别降低了3.8%和提高了1.7%,验证了MSAM-CTE在情感分析中的有效性。
中图分类号:
王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 计算机应用, 2025, 45(7): 2237-2244.
Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement[J]. Journal of Computer Applications, 2025, 45(7): 2237-2244.
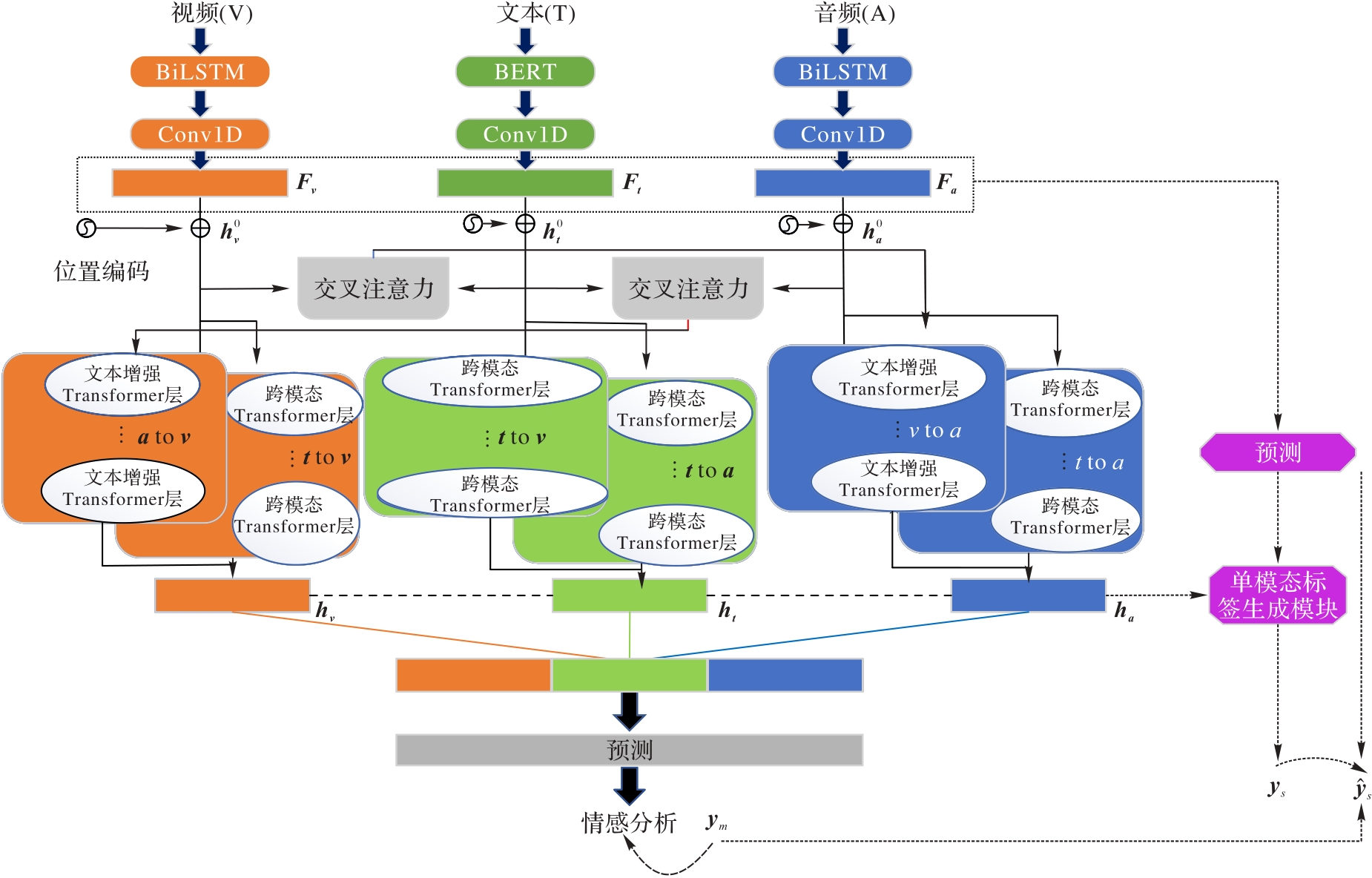
图1 MSAM-CTE结构
Fig. 1 Structure of MSAM-CTE
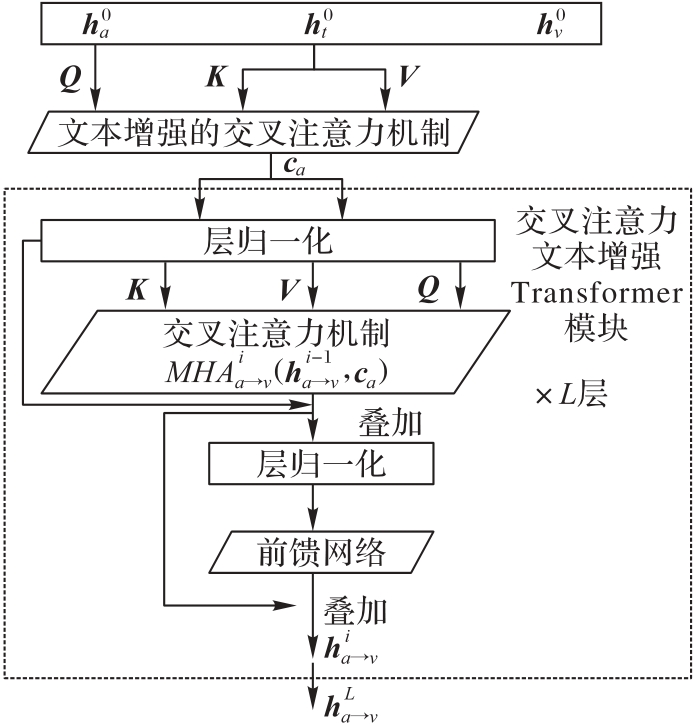
图2 文本增强Transformer模块
Fig. 2 Text enhancement Transformer module
| 数据集 | 样本数 | |||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 合计 | |
| CMU-MOSI | 1 284 | 229 | 686 | 2 199 |
| CMU-MOSEI | 16 326 | 1 871 | 4 659 | 22 856 |
表1 CMU-MOSI和CMU-MOSEI中的数据集划分
Tab. 1 Dataset partition in CMU-MOSI and CMU-MOSEI
| 数据集 | 样本数 | |||
|---|---|---|---|---|
| 训练集 | 验证集 | 测试集 | 合计 | |
| CMU-MOSI | 1 284 | 229 | 686 | 2 199 |
| CMU-MOSEI | 16 326 | 1 871 | 4 659 | 22 856 |
| 超参数 | 含义 | 设置 | |
|---|---|---|---|
| CMU-MOSI | CMU-MOSEI | ||
| batch_size | 训练使用的样本数量 | 32 | 32 |
| learning_rate of BERT | 影响模型参数更新速度 | 3.00×10-5 | 5.00×10-6 |
| a lstm hidden _size | 音频特征提取LSTM隐藏层的维度 | 16 | 32 |
| v lstm hidden _size | 视频特征提取LSTM隐藏层的维度 | 64 | 64 |
| attn_dropout | 防止过拟合 | 0 | 0.1 |
| num_heads | 让模型关注输入的不同 | 5 | 5 |
| kernel_size of Conv1D | 卷积层的核大小 | 1 | 1 |
| early _stop | 在指定epoch内模型性能没有提升,则停止训练 | 8 | 8 |
| dst_feature dims | 投影到统一维度后的特征大小 | 50 | 50 |
表2 超参数设置
Tab. 2 Hyperparameter setting
| 超参数 | 含义 | 设置 | |
|---|---|---|---|
| CMU-MOSI | CMU-MOSEI | ||
| batch_size | 训练使用的样本数量 | 32 | 32 |
| learning_rate of BERT | 影响模型参数更新速度 | 3.00×10-5 | 5.00×10-6 |
| a lstm hidden _size | 音频特征提取LSTM隐藏层的维度 | 16 | 32 |
| v lstm hidden _size | 视频特征提取LSTM隐藏层的维度 | 64 | 64 |
| attn_dropout | 防止过拟合 | 0 | 0.1 |
| num_heads | 让模型关注输入的不同 | 5 | 5 |
| kernel_size of Conv1D | 卷积层的核大小 | 1 | 1 |
| early _stop | 在指定epoch内模型性能没有提升,则停止训练 | 8 | 8 |
| dst_feature dims | 投影到统一维度后的特征大小 | 50 | 50 |
| 模型名称 | CMU-MOSI | CMU-MOSEI | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | Corr | Acc-2/% | F1/% | 数据状态 | MAE | Corr | Acc-2/% | F1/% | 数据状态 | |
| TFN (B) * | 0.901 | 0.698 | —/80.20 | —/80.70 | 非对齐 | 0.593 | 0.700 | —/82.50 | —/82.10 | 非对齐 |
| LMF (B) * | 0.917 | 0.695 | —/82.50 | —/82.40 | 非对齐 | 0.623 | 0.677 | —/82.00 | —/82.10 | 非对齐 |
| RAVEN* | 0.915 | 0.691 | 78.00/— | 76.60/— | 对齐 | 0.614 | 0.662 | 79.10/— | 79.50/— | 对齐 |
| MulT (B) * | 0.861 | 0.711 | 81.50/84.10 | 80.60/83.90 | 对齐 | 0.580 | 0.703 | —/82.50 | —/82.30 | 对齐 |
| ICCN | 0.862 | 0.714 | —/83.00 | —/83.00 | 非对齐 | 0.655 | 0.713 | —/84.20 | —/84.20 | 非对齐 |
| MAG-BERT (B)** | 0.712 | 0.796 | 84.20/86.10 | 84.10/86.00 | 对齐 | — | — | 84.70/— | 84.50/— | 对齐 |
| Self-MM (B) * | 0.713 | 0.798 | 84.00/85.98 | 84.42/85.95 | 非对齐 | 0.530 | 0.765 | 82.82/85.17 | 82.53/85.30 | 非对齐 |
| MISA (B)* | 0.783 | 0.761 | 81.80/83.40 | 81.70/83.60 | 对齐 | 0.555 | 0.756 | 83.60/85.50 | 83.30/85.30 | 对齐 |
| TETFN | 0.717 | 0.800 | 84.05/86.10 | 83.83/86.07 | 非对齐 | 0.551 | 0.748 | 84.25/85.18 | 84.18/85.27 | 非对齐 |
| MSAM-CTE | 0.698 | 0.801 | 84.11/85.52 | 84.12/85.57 | 非对齐 | 0.530 | 0.761 | 84.74/85.50 | 84.63/85.14 | 非对齐 |
表3 不同模型在CMU-MOSI和CMU-MOSEI数据集上的比较结果
Tab. 3 Comparison results of different models on CMU-MOSI and CMU-MOSEI datasets
| 模型名称 | CMU-MOSI | CMU-MOSEI | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | Corr | Acc-2/% | F1/% | 数据状态 | MAE | Corr | Acc-2/% | F1/% | 数据状态 | |
| TFN (B) * | 0.901 | 0.698 | —/80.20 | —/80.70 | 非对齐 | 0.593 | 0.700 | —/82.50 | —/82.10 | 非对齐 |
| LMF (B) * | 0.917 | 0.695 | —/82.50 | —/82.40 | 非对齐 | 0.623 | 0.677 | —/82.00 | —/82.10 | 非对齐 |
| RAVEN* | 0.915 | 0.691 | 78.00/— | 76.60/— | 对齐 | 0.614 | 0.662 | 79.10/— | 79.50/— | 对齐 |
| MulT (B) * | 0.861 | 0.711 | 81.50/84.10 | 80.60/83.90 | 对齐 | 0.580 | 0.703 | —/82.50 | —/82.30 | 对齐 |
| ICCN | 0.862 | 0.714 | —/83.00 | —/83.00 | 非对齐 | 0.655 | 0.713 | —/84.20 | —/84.20 | 非对齐 |
| MAG-BERT (B)** | 0.712 | 0.796 | 84.20/86.10 | 84.10/86.00 | 对齐 | — | — | 84.70/— | 84.50/— | 对齐 |
| Self-MM (B) * | 0.713 | 0.798 | 84.00/85.98 | 84.42/85.95 | 非对齐 | 0.530 | 0.765 | 82.82/85.17 | 82.53/85.30 | 非对齐 |
| MISA (B)* | 0.783 | 0.761 | 81.80/83.40 | 81.70/83.60 | 对齐 | 0.555 | 0.756 | 83.60/85.50 | 83.30/85.30 | 对齐 |
| TETFN | 0.717 | 0.800 | 84.05/86.10 | 83.83/86.07 | 非对齐 | 0.551 | 0.748 | 84.25/85.18 | 84.18/85.27 | 非对齐 |
| MSAM-CTE | 0.698 | 0.801 | 84.11/85.52 | 84.12/85.57 | 非对齐 | 0.530 | 0.761 | 84.74/85.50 | 84.63/85.14 | 非对齐 |
| 模型 | MAE | Corr | Acc-2/% | F1/% |
|---|---|---|---|---|
| MSAM-CTE | 0.698 | 0.801 | 84.11/85.52 | 84.12/85.57 |
| MSAM-CTE w/o Bi-LSTM | 0.736 | 0.791 | 81.34/82.62 | 81.34/82.67 |
| MSAM-CTE w/o TET | 0.735 | 0.788 | 82.22/83.38 | 82.24/83.46 |
| MSAM-CTE w/o CA | 0.730 | 0.789 | 82.65/83.38 | 82.67/83.44 |
表4 在CMU-MOSI数据集上的消融实验结果
Tab. 4 Results of ablation study on CMU-MOSI dataset
| 模型 | MAE | Corr | Acc-2/% | F1/% |
|---|---|---|---|---|
| MSAM-CTE | 0.698 | 0.801 | 84.11/85.52 | 84.12/85.57 |
| MSAM-CTE w/o Bi-LSTM | 0.736 | 0.791 | 81.34/82.62 | 81.34/82.67 |
| MSAM-CTE w/o TET | 0.735 | 0.788 | 82.22/83.38 | 82.24/83.46 |
| MSAM-CTE w/o CA | 0.730 | 0.789 | 82.65/83.38 | 82.67/83.44 |
| 样例 | 文本 | 视频 | 音频 | 真实标签数值 |
|---|---|---|---|---|
| 样例一 | Whole movies very boring | 抬手,闭眼 | 说话者音量时高时低 | -2.0 |
| 样例二 | Because I truly love an action flick action comedy flick even better right | 瞪大眼睛,摇头 | 说话者逐渐提高音量 | 1.6 |
表5 实例信息
Tab. 5 Case information
| 样例 | 文本 | 视频 | 音频 | 真实标签数值 |
|---|---|---|---|---|
| 样例一 | Whole movies very boring | 抬手,闭眼 | 说话者音量时高时低 | -2.0 |
| 样例二 | Because I truly love an action flick action comedy flick even better right | 瞪大眼睛,摇头 | 说话者逐渐提高音量 | 1.6 |
| 模型 | 预测数值 | |
|---|---|---|
| 样例一 | 样例二 | |
| MSAM-CTE | -2.09 | 1.93 |
| TETFN | -2.18 | 2.27 |
| Self-MM | -1.73 | 2.48 |
表6 标签预测数值对比
Tab. 6 Comparison of predicted values of labels
| 模型 | 预测数值 | |
|---|---|---|
| 样例一 | 样例二 | |
| MSAM-CTE | -2.09 | 1.93 |
| TETFN | -2.18 | 2.27 |
| Self-MM | -1.73 | 2.48 |
| [1] | 罗俊豪,朱焱.用于未对齐多模态语言序列情感分析的多交互感知网络[J].计算机应用,2024, 44(1): 79-85. |
| LUO J H, ZHU Y. Multi-dynamic aware network for unaligned multimodal language sequence sentiment analysis [J]. Journal of Computer Applications, 2024, 44(1): 79-85. | |
| [2] | LIU Y, LIU L, GUO Y, et al. Learning visual and textual representations for multimodal matching and classification [J]. Pattern Recognition, 2018, 84: 51-67. |
| [3] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Advances in Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [4] | TANG J, LI K, JIN X, et al. CTFN: hierarchical learning for multimodal sentiment analysis using coupled-translation fusion network [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5301-5311. |
| [5] | TSAI Y H H, BAI S, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 6558-6569. |
| [6] | HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: modality-invariant and-specific representations for multimodal sentiment analysis [C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1122-1131. |
| [7] | YU W, XU H, YUAN Z, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 10790-10797. |
| [8] | WANG D, GUO X, TIAN Y, et al. TETFN: a text enhanced transformer fusion network for multimodal sentiment analysis [J]. Pattern Recognition, 2023, 136: No.109259. |
| [9] | HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL]. [2024-09-04]. . |
| [10] | ZHANG Y, JIN R, ZHOU Z H. Understanding bag-of-words model: a statistical framework [J]. International Journal of Machine Learning and Cybernetics, 2010, 1(1/2/3/4): 43-52. |
| [11] | LI B, LIU T, ZHAO Z, et al. Neural bag-of-ngrams [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 3067-3074. |
| [12] | CHEN P H, LIN C J, SCHÖLKOPF B. A tutorial on ν-support vector machines [J]. Applied Stochastic Models in Business and Industry, 2005, 21(2): 111-136. |
| [13] | RISH I. An empirical study of the naive Bayes classifier [EB/OL]. [2024-09-01]. . |
| [14] | PHILLIPS S J. A brief tutorial on MaxEnt [EB/OL]. [2024-09-01]. . |
| [15] | ALBAWI S, MOHAMMED T A, AL-ZAWI S. Understanding of a convolutional neural network [C]// Proceedings of the 2017 International Conference on Engineering and Technology. Piscataway: IEEE, 2017: 1-6. |
| [16] | HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780. |
| [17] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pretraining of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [18] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2023-08-01]. . |
| [19] | PORIA S, CHATURVEDI I, CAMBRIA E, et al. Convolutional MKL based multimodal emotion recognition and sentiment analysis [C]// Proceedings of the IEEE 16th International Conference on Data Mining. Piscataway: IEEE, 2016: 439-448. |
| [20] | ZADEH A, LIANG P P, MAZUMDER N, et al. Memory fusion network for multi-view sequential learning [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 5634-5641. |
| [21] | KAMPMAN O, BAREZI E J, BERTERO D, et al. Investigating audio, visual, and text fusion methods for end-to-end automatic personality prediction [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2018: 606-611. |
| [22] | RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained Transformers [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 2359-2369. |
| [23] | WANG Y, SHEN Y, LIU Z, et al. Words can shift: dynamically adjusting word representations using nonverbal behaviors [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 7216-7223. |
| [24] | HAN W, CHEN H, GELBUKH A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis [C]// Proceedings of the 2021 International Conference on Multimodal Interaction. New York: ACM, 2021: 6-15. |
| [25] | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| [26] | YANG J, YU Y, NIU D, et al. ConFEDE: contrastive feature decomposition for multimodal sentiment analysis [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 7617-7630. |
| [27] | LIAN H, LU C, LI S, et al. A survey of deep learning-based multimodal emotion recognition: speech, text, and face [J]. Entropy, 2023, 25(10): No.1440. |
| [28] | LAI S, HU X, XU H, et al. Multimodal sentiment analysis: a survey [J]. Displays, 2023, 74: No.102563. |
| [29] | ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos [EB/OL]. [2023-09-04]. . |
| [30] | ZADEH A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2236-2246. |
| [31] | ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 1103-1114. |
| [32] | LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2247-2256. |
| [33] | SUN Z, SARMA P K, SETHARES W A, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8992-8999. |
| [1] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [2] | 吕锡婷, 赵敬华, 荣海迎, 赵嘉乐. 基于Transformer和关系图卷积网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1760-1766. |
| [3] | 罗歆然, 李天瑞, 贾真. 基于自注意力机制与词汇增强的中文医学命名实体识别[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 385-392. |
| [4] | 陈丽安, 过弋. 融合个体偏差信息的文本情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 145-151. |
| [5] | 尹春勇, 张杨春. 基于CNN和Bi-LSTM的无监督日志异常检测模型[J]. 《计算机应用》唯一官方网站, 2023, 43(11): 3510-3516. |
| [6] | 胡婕, 胡燕, 刘梦赤, 张龑. 基于知识库实体增强BERT模型的中文命名实体识别[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2680-2685. |
| [7] | 侯旭东, 滕飞, 张艺. 基于深度自编码的医疗命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2686-2692. |
| [8] | 刘月峰, 张小燕, 郭威, 边浩东, 何滢婕. 基于优化混合模型的航空发动机剩余寿命预测方法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2960-2968. |
| [9] | 罗浩然, 杨青. 基于情感词典和堆叠残差的双向长短期记忆网络的情感分析[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1099-1107. |
| [10] | 张毅, 王爽胜, 何彬, 叶培明, 李克强. 基于BERT的初等数学文本命名实体识别方法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 433-439. |
| [11] | 曾兰兰, 王以松, 陈攀峰. 基于BERT和联合学习的裁判文书命名实体识别[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3011-3017. |
| [12] | 王小鹏, 孙媛媛, 林鸿飞. 基于刑事Electra的编-解码关系抽取模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 87-93. |
| [13] | 武国亮, 徐继宁. 基于命名实体识别任务反馈增强的中文突发事件抽取方法[J]. 计算机应用, 2021, 41(7): 1891-1896. |
| [14] | 武光利, 李雷霆, 郭振洲, 王成祥. 基于改进的双向长短期记忆网络的视频摘要生成模型[J]. 计算机应用, 2021, 41(7): 1908-1914. |
| [15] | 徐萌, 王亚锟. 基于双向长短期记忆网络的DA40飞机碳刹车片剩余寿命预测[J]. 计算机应用, 2021, 41(5): 1527-1532. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||