


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 3804-3812.DOI: 10.11772/j.issn.1001-9081.2024111704
樊永红1,2,3, 黄鹤鸣1,2,3( )
)
收稿日期:2024-12-06
修回日期:2025-03-08
接受日期:2025-03-18
发布日期:2025-03-21
出版日期:2025-12-10
通讯作者:
黄鹤鸣
作者简介:樊永红(1997—),女,宁夏吴忠人,博士研究生,CCF会员,主要研究方向:模式识别、智能系统、语音情感识别基金资助:
Yonghong FAN1,2,3, Heming HUANG1,2,3()
Received:2024-12-06
Revised:2025-03-08
Accepted:2025-03-18
Online:2025-03-21
Published:2025-12-10
Contact:
Heming HUANG
About author:FAN Yonghong, born in 1997, Ph. D. candidate. Her research interests include pattern recognition, intelligent systems, speech emotion recognition.
Supported by:摘要:
语音情感识别(SER)旨在赋予计算机准确识别语音信号中的情感状态的能力,而如何高效地表征语音中的情感特征一直是SER的研究热点。目前,大多数研究都致力于利用深度学习方法直接从原始语音或语谱图中学习最优特征,这种学习模式可以提取到更完整的特征信息,但忽略了对特定特征更深层细化信息的学习,同时不能保证特征的可解释性。为了解决上述问题,提出一种基于卷积神经网络的渐进式表征学习SER方法(CnnPRL),在语音声学特征的基础上利用卷积神经网络(CNN)渐进式地提取具有可解释性的精细化情感特征。首先,手工提取可解释的浅层特征并选择出最优的特征集;其次,提出级联CNN和动态融合结构,以细化浅层特征,并学习深层情感表征;最后,构建并行异构CNN提取不同尺度的互补特征,以利用融合模块实现多特征融合,捕获多粒度特征,并整合来自不同特征尺度的深层情感信息。实验结果表明,在保证时间复杂度的前提下,在数据集IEMOCAP (Interactive EMOtional dyadic motion CAPture database)、CASIA(Institute of Automation, Chinese Academy of Sciences)和EMODB(Berlin EMOtional DataBase)上,相较于SpeechFormer++、TLFMRF(Two-Layer Fuzzy Multiple Random Forest)和TIM-Net(Temporal-aware bI-direction Multi-scale Network)等对比方法,CnnPRL在指标加权平均召回率(WAR)上分别至少取得了0.86、2.92和1.46个百分点的提升,验证了CnnPRL的有效性;消融实验结果验证了CnnPRL的每个模块都有利于提升模型的整体性能。
中图分类号:
樊永红, 黄鹤鸣. 渐进式表征学习语音情感识别方法CnnPRL[J]. 计算机应用, 2025, 45(12): 3804-3812.
Yonghong FAN, Heming HUANG. CnnPRL: progressive representation learning method for speech emotion recognition[J]. Journal of Computer Applications, 2025, 45(12): 3804-3812.
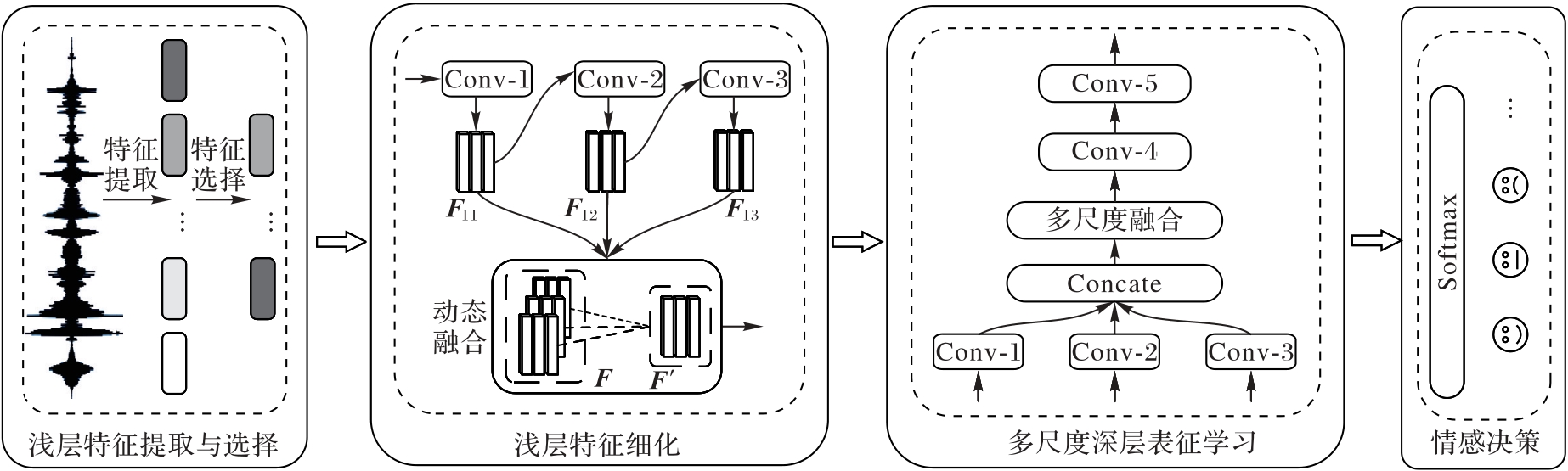
图1 CnnPRL总体架构
Fig. 1 Overall architecture of CnnPRL
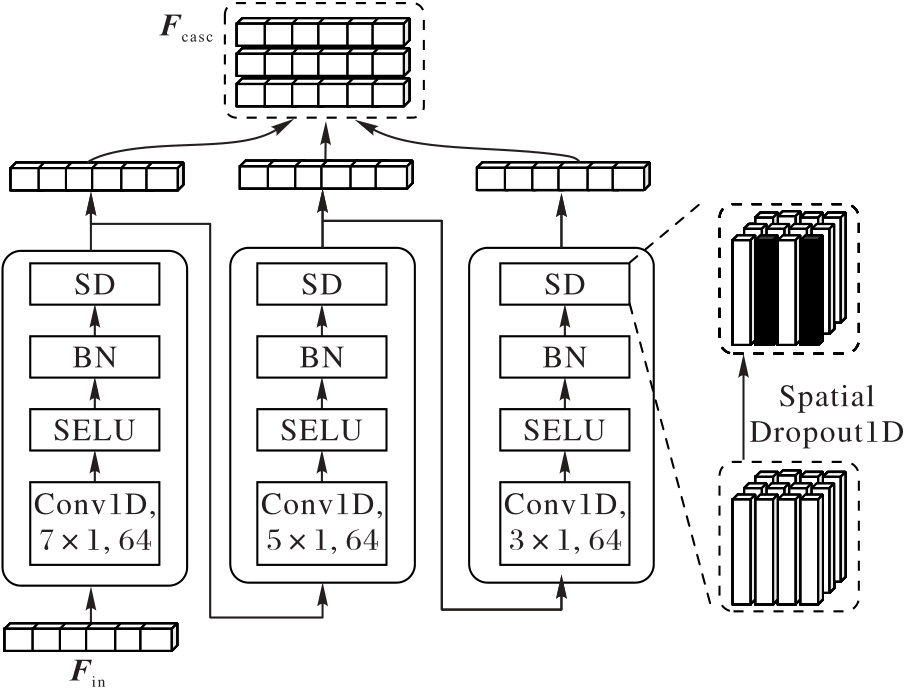
图2 CasCNN模块结构
Fig.2 Structure of CasCNN module
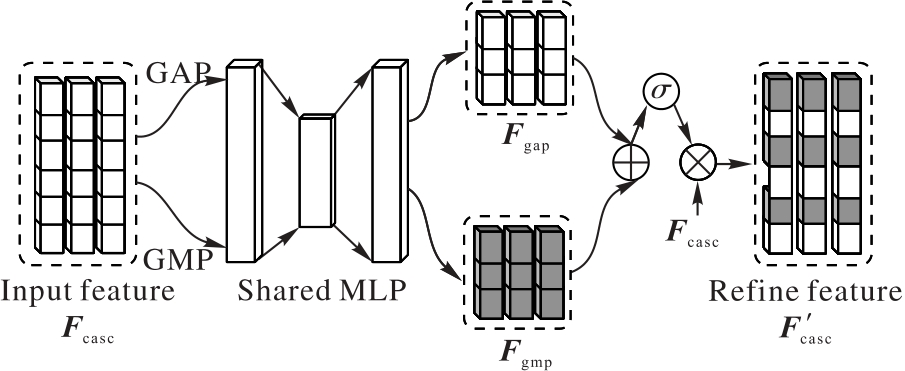
图3 动态融合模块结构
Fig. 3 Structure of dynamic fusion module
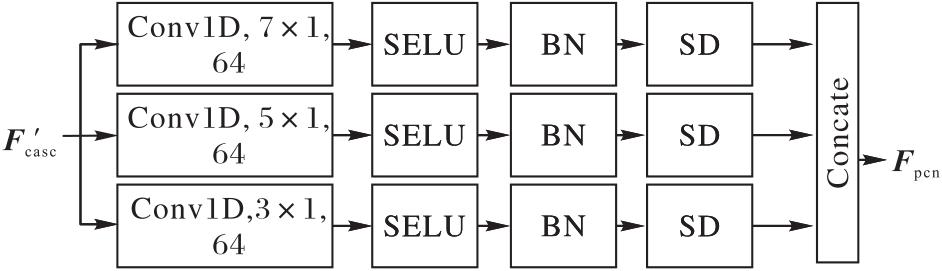
图4 PCN模块结构
Fig. 4 Structure of PCN module
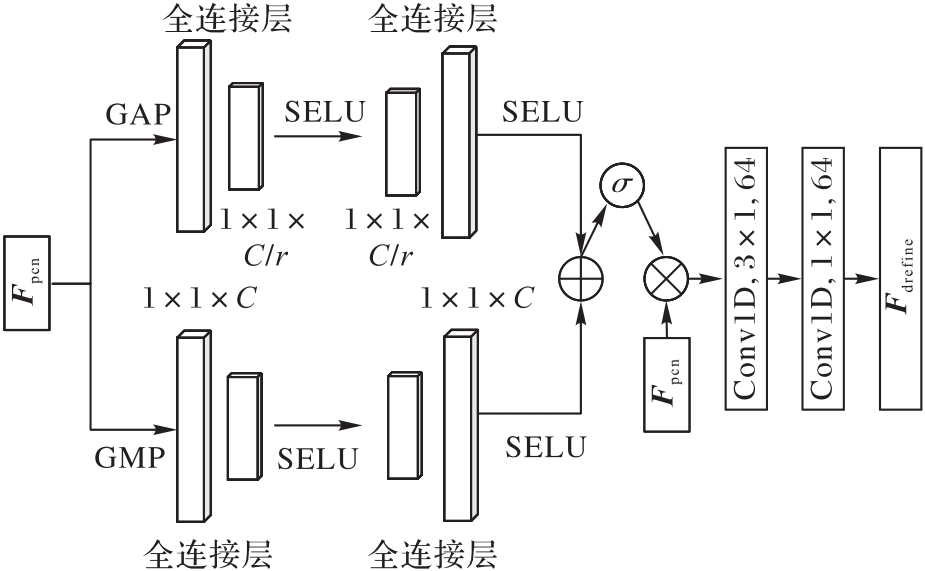
图5 多尺度融合模块结构
Fig. 5 Structure of multi-scale fusion module
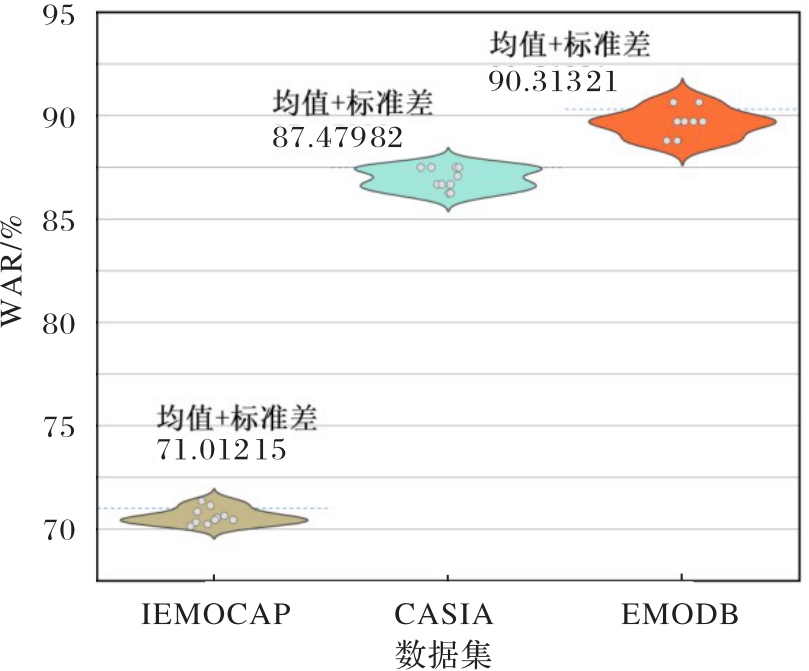
图6 CnnPRL在不同数据集上进行10次实验的结果分布
Fig. 6 Distribution of 10 experimental results of CnnPRL on different datasets
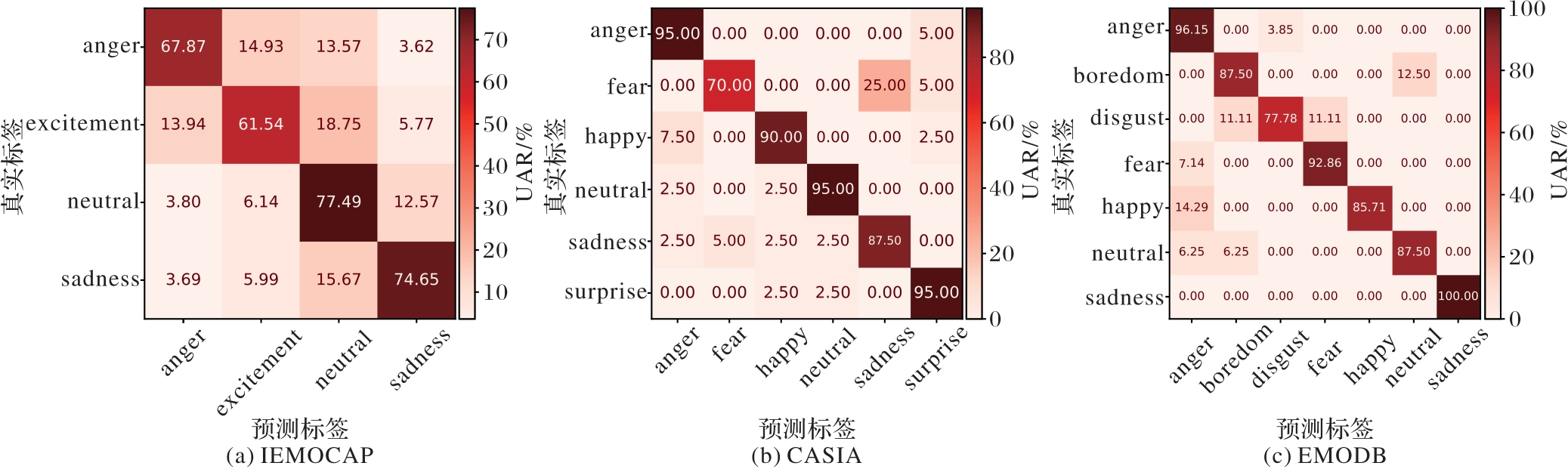
图7 CnnPRL在不同数据集上的最优结果的混淆矩阵
Fig. 7 Confusion matrices of optimal results of CnnPRL on different datasets

图8 3个数据集上数据的原始分布与经CnnPRL分类的数据分布效果的T-SNE可视化
Fig. 8 T-SNE visualization of original distribution and classification effects by CnnPRL of data on three datasets
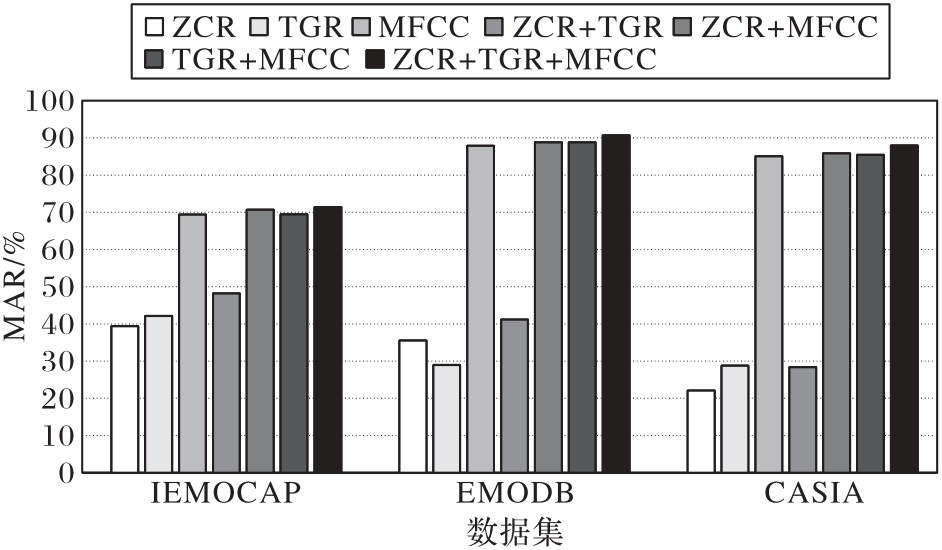
图9 3个数据集上不同特征集的WAR
Fig. 9 WAR for different feature sets on multiple datasets
| SFR | MsDRL | SD | IEMOCAP | CASIA | EMODB | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CasCNN | DF | PCN | MsF | WAR | UAR | WAR | UAR | WAR | UAR | |
| √ | √ | √ | 69.03 | 67.70 | 84.17 | 84.17 | 85.98 | 84.17 | ||
| √ | √ | √ | 68.83 | 67.95 | 85.00 | 85.00 | 86.92 | 85.94 | ||
| √ | √ | √ | 69.13 | 67.83 | 84.58 | 84.58 | 87.85 | 87.88 | ||
| √ | √ | √ | √ | 70.04 | 69.06 | 85.83 | 85.83 | 89.72 | 88.33 | |
| √ | √ | √ | √ | 70.14 | 69.62 | 86.67 | 86.67 | 88.79 | 87.73 | |
| √ | √ | √ | √ | 70.65 | 70.39 | 87.50 | 87.50 | 87.85 | 86.37 | |
| √ | √ | √ | √ | √ | 71.36 | 70.59 | 88.75 | 88.75 | 90.65 | 89.64 |
表1 CnnPRL各子模块的消融实验结果 (%)
Tab. 1 Ablation experimental results of each submodule in CnnPRL
| SFR | MsDRL | SD | IEMOCAP | CASIA | EMODB | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CasCNN | DF | PCN | MsF | WAR | UAR | WAR | UAR | WAR | UAR | |
| √ | √ | √ | 69.03 | 67.70 | 84.17 | 84.17 | 85.98 | 84.17 | ||
| √ | √ | √ | 68.83 | 67.95 | 85.00 | 85.00 | 86.92 | 85.94 | ||
| √ | √ | √ | 69.13 | 67.83 | 84.58 | 84.58 | 87.85 | 87.88 | ||
| √ | √ | √ | √ | 70.04 | 69.06 | 85.83 | 85.83 | 89.72 | 88.33 | |
| √ | √ | √ | √ | 70.14 | 69.62 | 86.67 | 86.67 | 88.79 | 87.73 | |
| √ | √ | √ | √ | 70.65 | 70.39 | 87.50 | 87.50 | 87.85 | 86.37 | |
| √ | √ | √ | √ | √ | 71.36 | 70.59 | 88.75 | 88.75 | 90.65 | 89.64 |
| 数据集 | 方法 | 模型结构 | WAR | UAR |
|---|---|---|---|---|
| IEMOCAP | MCMA[ | CNN | 57.58 | 58.07 |
| Dual-TBNet[ | Transformer+BiLSTM | 64.80 | 64.00 | |
| SFF-NEC[ | SVM | 65.78 | 64.27 | |
| SERC-GCN[ | Graph Convolution | 66.85 | — | |
| Foundation model[ | Transformer-based | 67.45 | — | |
| PTM-based SER[ | Speech Pre-trained Model | 68.85 | — | |
| TIM-Net[ | TCN | 69.00 | 68.29 | |
| BiGRU-Focal[ | CNN+BiGRU | 69.73 | 68.75 | |
| SpeechFormer++[ | Transformer-based | 70.50 | — | |
| DST[ | Transformer-based | 71.80 | — | |
| CnnPRL | CNN | 71.36 | 70.59 | |
| CASIA | MSCRNN-A[ | CNN+BiLSTM | 60.75 | 60.75 |
| AS-CANet[ | CNN | 67.08 | 67.08 | |
| CNN-LSTM[ | CNN+LSTM | 74.17 | 74.17 | |
| MA-CapsNet-DA[ | Capsule Network | 76.28 | — | |
| DT-SVM[ | SVM | 85.08 | 85.08 | |
| TLFMRF[ | Random Forest | 85.83 | 85.83 | |
| CnnPRL | CNN | 88.75 | 88.75 | |
| EMODB | MA-CapsNet-DA[ | Capsule Network | 77.89 | — |
| SFF-NEC[ | SVM | 82.84 | 81.45 | |
| ST-FCANet[ | CNN | 83.30 | 82.10 | |
| Dual-TBNet[ | Transformer+BiLSTM | 84.10 | — | |
| DT-SVM[ | SVM | 87.55 | — | |
| AMSNet[ | CNN+BiLSTM | 88.34 | 88.56 | |
| MSCRNN-A[ | CNN+BiLSTM | 88.41 | 87.95 | |
| TIM-Net[ | TCN | 89.19 | — | |
| CnnPRL | CNN | 90.65 | 89.64 | |
| MCDNet[ | CNN | 96.25 | — | |
| CnnPRL* | CNN | 99.07 | 99.27 |
表2 CnnPRL与其他方法的比较结果 (%)
Tab. 2 Comparison results of CnnPRL and other methods
| 数据集 | 方法 | 模型结构 | WAR | UAR |
|---|---|---|---|---|
| IEMOCAP | MCMA[ | CNN | 57.58 | 58.07 |
| Dual-TBNet[ | Transformer+BiLSTM | 64.80 | 64.00 | |
| SFF-NEC[ | SVM | 65.78 | 64.27 | |
| SERC-GCN[ | Graph Convolution | 66.85 | — | |
| Foundation model[ | Transformer-based | 67.45 | — | |
| PTM-based SER[ | Speech Pre-trained Model | 68.85 | — | |
| TIM-Net[ | TCN | 69.00 | 68.29 | |
| BiGRU-Focal[ | CNN+BiGRU | 69.73 | 68.75 | |
| SpeechFormer++[ | Transformer-based | 70.50 | — | |
| DST[ | Transformer-based | 71.80 | — | |
| CnnPRL | CNN | 71.36 | 70.59 | |
| CASIA | MSCRNN-A[ | CNN+BiLSTM | 60.75 | 60.75 |
| AS-CANet[ | CNN | 67.08 | 67.08 | |
| CNN-LSTM[ | CNN+LSTM | 74.17 | 74.17 | |
| MA-CapsNet-DA[ | Capsule Network | 76.28 | — | |
| DT-SVM[ | SVM | 85.08 | 85.08 | |
| TLFMRF[ | Random Forest | 85.83 | 85.83 | |
| CnnPRL | CNN | 88.75 | 88.75 | |
| EMODB | MA-CapsNet-DA[ | Capsule Network | 77.89 | — |
| SFF-NEC[ | SVM | 82.84 | 81.45 | |
| ST-FCANet[ | CNN | 83.30 | 82.10 | |
| Dual-TBNet[ | Transformer+BiLSTM | 84.10 | — | |
| DT-SVM[ | SVM | 87.55 | — | |
| AMSNet[ | CNN+BiLSTM | 88.34 | 88.56 | |
| MSCRNN-A[ | CNN+BiLSTM | 88.41 | 87.95 | |
| TIM-Net[ | TCN | 89.19 | — | |
| CnnPRL | CNN | 90.65 | 89.64 | |
| MCDNet[ | CNN | 96.25 | — | |
| CnnPRL* | CNN | 99.07 | 99.27 |
| 子模块 | CasCNN | DF | PCN | MsF | FLOPs/106 |
|---|---|---|---|---|---|
| 模块消融 | √ | 0.29 | |||
| √ | √ | 0.34 | |||
| √ | √ | √ | 1.08 | ||
| CnnPRL | √ | √ | √ | √ | 1.31 |
表3 CnnPRL的计算复杂度分析
Tab. 3 Computational complexity analysis of CnnPRL
| 子模块 | CasCNN | DF | PCN | MsF | FLOPs/106 |
|---|---|---|---|---|---|
| 模块消融 | √ | 0.29 | |||
| √ | √ | 0.34 | |||
| √ | √ | √ | 1.08 | ||
| CnnPRL | √ | √ | √ | √ | 1.31 |
| 数据集 | 方法 | 愤怒 | 快乐 | 兴奋 | 中性 | 悲伤 | 无聊 | 厌恶 | 恐惧 | 惊讶 |
|---|---|---|---|---|---|---|---|---|---|---|
| IEMOCAP | MCMA[ | 65.10 | — | 53.18 | 57.85 | 56.18 | — | — | — | — |
| Dual-TBNet[ | 62.00 | — | 59.00 | 71.00 | 64.00 | — | — | — | — | |
| BiGRU-Focal[ | 66.54 | — | 55.31 | 71.85 | 60.23 | — | — | — | — | |
| CnnPRL | 67.87 | — | 61.54 | 77.49 | 74.65 | — | — | — | — | |
| CASIA | MSCRNN-A[ | 74.00 | 59.00 | — | 71.00 | 76.50 | — | — | 38.50 | 45.50 |
| DT-SVM[ | 90.00 | 88.50 | — | 92.50 | 78.00 | — | — | 74.50 | 87.00 | |
| TLFMRF[ | 93.00 | 77.00 | — | 94.00 | 88.00 | — | — | 67.00 | 98.00 | |
| CnnPRL | 95.00 | 90.00 | — | 95.00 | 87.50 | — | — | 70.00 | 95.00 | |
| EMODB | Dual-TBNet[ | 75.00 | 82.00 | — | 75.00 | 100.00 | 88.00 | 100.00 | 90.00 | — |
| DT-SVM[ | 91.80 | 85.00 | — | 94.50 | 83.00 | 89.85 | 80.45 | 88.30 | — | |
| AMSNet[ | 92.00 | 91.00 | — | 85.00 | 92.00 | 85.00 | — | 90.00 | — | |
| MSCRNN-A[ | 97.00 | 72.87 | — | 87.55 | 91.35 | 92.57 | 86.87 | 81.29 | — | |
| CnnPRL | 96.15 | 85.71 | — | 87.50 | 100.00 | 87.50 | 77.78 | 92.86 | — | |
| MCDNet[ | 97.37 | 94.74 | — | 100.00 | 100.00 | 100.00 | 92.86 | 95.24 | — | |
| CnnPRL* | 98.04 | 100.00 | — | 96.88 | 100.00 | 100.00 | 100.00 | 100.00 | — |
表4 CnnPRL与其他方法在每类情感上的UAR比较结果 (%)
Tab. 4 UAR results comparison of proposed CnnPRL and other methods on each emotion category
| 数据集 | 方法 | 愤怒 | 快乐 | 兴奋 | 中性 | 悲伤 | 无聊 | 厌恶 | 恐惧 | 惊讶 |
|---|---|---|---|---|---|---|---|---|---|---|
| IEMOCAP | MCMA[ | 65.10 | — | 53.18 | 57.85 | 56.18 | — | — | — | — |
| Dual-TBNet[ | 62.00 | — | 59.00 | 71.00 | 64.00 | — | — | — | — | |
| BiGRU-Focal[ | 66.54 | — | 55.31 | 71.85 | 60.23 | — | — | — | — | |
| CnnPRL | 67.87 | — | 61.54 | 77.49 | 74.65 | — | — | — | — | |
| CASIA | MSCRNN-A[ | 74.00 | 59.00 | — | 71.00 | 76.50 | — | — | 38.50 | 45.50 |
| DT-SVM[ | 90.00 | 88.50 | — | 92.50 | 78.00 | — | — | 74.50 | 87.00 | |
| TLFMRF[ | 93.00 | 77.00 | — | 94.00 | 88.00 | — | — | 67.00 | 98.00 | |
| CnnPRL | 95.00 | 90.00 | — | 95.00 | 87.50 | — | — | 70.00 | 95.00 | |
| EMODB | Dual-TBNet[ | 75.00 | 82.00 | — | 75.00 | 100.00 | 88.00 | 100.00 | 90.00 | — |
| DT-SVM[ | 91.80 | 85.00 | — | 94.50 | 83.00 | 89.85 | 80.45 | 88.30 | — | |
| AMSNet[ | 92.00 | 91.00 | — | 85.00 | 92.00 | 85.00 | — | 90.00 | — | |
| MSCRNN-A[ | 97.00 | 72.87 | — | 87.55 | 91.35 | 92.57 | 86.87 | 81.29 | — | |
| CnnPRL | 96.15 | 85.71 | — | 87.50 | 100.00 | 87.50 | 77.78 | 92.86 | — | |
| MCDNet[ | 97.37 | 94.74 | — | 100.00 | 100.00 | 100.00 | 92.86 | 95.24 | — | |
| CnnPRL* | 98.04 | 100.00 | — | 96.88 | 100.00 | 100.00 | 100.00 | 100.00 | — |
| [1] | 陶建华,陈俊杰,李永伟. 语音情感识别综述[J]. 信号处理, 2023, 39(4): 571-587. |
| TAO J H, CHEN J J, LI Y W. Review on speech emotion recognition[J]. Journal of Signal Processing, 2023, 39(4): 571-587. | |
| [2] | BLASZKE M, KOSZEWSKI D. Determination of low-level audio descriptors of a musical instrument sound using neural network[C]// Proceedings of the 2020 Conference on Signal Processing: Algorithms, Architectures, Arrangements and Applications. Piscataway: IEEE, 2020: 138-141. |
| [3] | WANG X, DU P, CHEN D, et al. Change detection based on low-level to high-level features integration with limited samples[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 6260-6276. |
| [4] | HAN K, YU D, TASHEV I. Speech emotion recognition using deep neural network and extreme learning machine[C]// Proceedings of the INTERSPEECH 2014. [S.l.]: International Speech Communication Association, 2014: 223-227. |
| [5] | ZHOU B, RICHARDSON K, NING Q, et al. Temporal reasoning on implicit events from distant supervision[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 1361-1371. |
| [6] | ZHU Z, DAI W, HU Y, et al. Speech emotion recognition model based on Bi-GRU and focal loss [J]. Pattern Recognition Letters, 2020, 140: 358-365. |
| [7] | RAJAMANI S T, RAJAMANI K T, MALLOL-RAGOLTA A, et al. A novel attention-based gated recurrent unit and its efficacy in speech emotion recognition[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6294-6298. |
| [8] | LIU M, JOSEPH RAJ A N, RAJANGAM V, et al. Multiscale-multichannel feature extraction and classification through one-dimensional convolutional neural network for speech emotion recognition [J]. Speech Communication, 2024, 156: No.103010. |
| [9] | MIAO X, LI Y, WEN M, et al. Fusing features of speech for depression classification based on higher-order spectral analysis[J]. Speech Communication, 2022, 143: 46-56. |
| [10] | GUO L, WANG L, DANG J, et al. Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition[J]. Speech Communication, 2022, 136: 118-127. |
| [11] | ZHAO Z P, LI Q F, ZHANG Z X, et al. Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition [J]. Neural Networks, 2021, 141: 52-60. |
| [12] | LIU A T, LI S W, LEE H Y. TERA: self-supervised learning of Transformer encoder representation for speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 2351-2366. |
| [13] | LIU Z, KANG X, REN F. Dual-TBNet: improving the robustness of speech features via dual-Transformer-BiLSTM for speech emotion recognition [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2193-2203. |
| [14] | 张钹,朱军,苏航.迈向第三代人工智能[J].中国科学:信息科学,2020, 50(9): 1281-1302. |
| ZHANG B, ZHU J, SU H. Toward the third generation of artificial intelligence[J]. SCIENTIA SINICA Informationis, 2020, 50(9): 1281-1302. | |
| [15] | YE J X, WEN X C, WANG X Z, et al. GM-TCNet: gated multi-scale temporal convolutional network using emotion causality for speech emotion recognition[J]. Speech Communication, 2022, 145: 21-35. |
| [16] | ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning[C]// Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2016: 265-283. |
| [17] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2024-11-03].. |
| [18] | CHEN W, XING X, XU X, et al. SpeechFormer++: a hierarchical efficient framework for paralinguistic speech processing[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 775-788. |
| [19] | LIU Y, SUN H, GUAN W, et al. A discriminative feature representation method based on cascaded attention network with adversarial strategy for speech emotion recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1063-1074. |
| [20] | THIRUMURU R, GURUGUBELLI K, VUPPALA A K. Novel feature representation using single frequency filtering and nonlinear energy operator for speech emotion recognition[J]. Digital Signal Processing, 2023, 120: No.103293. |
| [21] | CHANDOLA D, ALTARAWNEH E, JENKIN M, et al. SERC-GCN: speech emotion recognition in conversation using graph convolutional networks[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 76-80. |
| [22] | YE J, WEN X C, WEI Y, et al. Temporal modeling matters: a novel temporal emotional modeling approach for speech emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [23] | TAO H, GENG L, SHAN S, et al. Multi-stream convolution recurrent neural networks based on attention mechanism fusion for speech emotion recognition[J]. Entropy, 2022, 24(8): No.1025. |
| [24] | HE J, REN L. Speech emotion recognition using XGBoost and CNN BLSTM with attention[C]// Proceedings of the 2021 IEEE SmartWorld, Ubiquitous Intelligence and Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Internet of People and Smart City Innovation. Piscataway: IEEE, 2021: 154-159. |
| [25] | SUN L, FU S, WANG F. Decision tree SVM model with Fisher feature selection for speech emotion recognition[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2019, 2019: No.2. |
| [26] | CHEN L, SU W, FENG Y, et al. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction [J]. Information Sciences, 2020, 509: 150-163. |
| [27] | LI S, XING X, FAN W, et al. Spatiotemporal and frequential cascaded attention networks for speech emotion recognition[J]. Neurocomputing, 2021, 448: 238-248. |
| [28] | CHEN Z, LI J, LIU H, et al. Learning multi-scale features for speech emotion recognition with connection attention mechanism[J]. Expert Systems with Applications, 2023, 214: No.118943. |
| [29] | FENG T, NARAYANAN S. Foundation model assisted automatic speech emotion recognition: transcribing, annotating, and augmenting[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 12116-12120. |
| [30] | MA Z, WU W, ZHENG Z, et al. Leveraging speech PTM, text LLM, and emotional TTS for speech emotion recognition[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11146-11150. |
| [31] | ZHANG H, HUANG H, HAN H. MA-CapsNet-DA: speech emotion recognition based on MA-CapsNet using data augmentation[J]. Expert Systems with Applications, 2024, 244: No.122939. |
| [32] | CHEN W, XING X, XU X, et al. DST: deformable speech Transformer for emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 1-5. |
| [1] | 李亚男, 郭梦阳, 邓国军, 陈允峰, 任建吉, 原永亮. 基于多模态融合特征的并分支发动机寿命预测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 305-313. |
| [2] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [3] | 张宏俊, 潘高军, 叶昊, 陆玉彬, 缪宜恒. 结合深度学习和张量分解的多源异构数据分析方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2838-2847. |
| [4] | 石超, 周昱昕, 扶倩, 唐万宇, 何凌, 李元媛. 基于骨架和3D热图的注意缺陷多动障碍患者动作识别算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3036-3044. |
| [5] | 彭鹏, 蔡子婷, 刘雯玲, 陈才华, 曾维, 黄宝来. 基于CNN和双向GRU混合孪生网络的语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2515-2521. |
| [6] | 林进浩, 罗川, 李天瑞, 陈红梅. 基于跨尺度注意力网络的胸部疾病分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2712-2719. |
| [7] | 陶永鹏, 柏诗淇, 周正文. 基于卷积和Transformer神经网络架构搜索的脑胶质瘤多组织分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2378-2386. |
| [8] | 张英俊, 闫薇薇, 谢斌红, 张睿, 陆望东. 梯度区分与特征范数驱动的开放世界目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2203-2210. |
| [9] | 陈盈涛, 方康康, 张金敖, 梁浩然, 郭焕斌, 邱兆文. 基于多尺度空间特征的冠状动脉CT血管造影图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2007-2015. |
| [10] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [11] | 张军燕, 赵一鸣, 林兵, 吴允平. 基于多级视觉与图文动态交互的图像中文描述方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1520-1527. |
| [12] | 龙雨菲, 牟宇辰, 刘晔. 基于张量化图卷积网络和对比学习的多源数据表示学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1372-1378. |
| [13] | 王丹, 张文豪, 彭丽娟. 基于深度学习的智能反射面辅助通信系统信道估计[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1613-1618. |
| [14] | 耿海军, 董赟, 胡治国, 池浩田, 杨静, 尹霞. 基于Attention-1DCNN-CE的加密流量分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 872-882. |
| [15] | 袁宝华, 陈佳璐, 王欢. 融合多尺度语义和双分支并行的医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 988-995. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||