


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (5): 1520-1527.DOI: 10.11772/j.issn.1001-9081.2024050616
• 人工智能 • 上一篇
张军燕1, 赵一鸣1, 林兵2, 吴允平1( )
)
收稿日期:2024-05-17
修回日期:2024-08-11
接受日期:2024-09-13
发布日期:2024-09-18
出版日期:2025-05-10
通讯作者:
吴允平
作者简介:张军燕(2001—),女,安徽六安人,硕士研究生,主要研究方向:自然语言处理、图像文字描述基金资助:
Junyan ZHANG1, Yiming ZHAO1, Bing LIN2, Yunping WU1()
Received:2024-05-17
Revised:2024-08-11
Accepted:2024-09-13
Online:2024-09-18
Published:2025-05-10
Contact:
Yunping WU
About author:ZHANG Junyan, born in 2001, M. S. candidate. Her research interests include natural language processing, image captioning.Supported by:摘要:
图像文字描述技术可以帮助计算机更好地理解图像内容,实现跨模态交互。针对图像中文描述任务中存在的图像多粒度特征提取不全面以及图文关联性理解不充分等问题,提出一种基于多级视觉与图文动态交互的图像中文描述方法。首先,在编码器端提取多级视觉特征,通过图像局部特征提取器的辅助引导模块获取多粒度特征。其次,设计图文交互模块对图文信息的语义关联进行动态关注;同时,设计特征动态融合解码器将带有图文信息动态权重的特征经过闭环动态融合并关注与解码,以保证信息增强且无缺失,从而获得语义关联性的输出。最后,生成语义通顺的图像中文描述语句。使用BLEU-n、Rouge、Meteor、CIDEr指标评估方法的有效性并与8种不同方法进行对比。实验结果显示,所提方法的语义相关性评价指标均有提升。具体而言,与基线模型NIC(Neural Image Caption)相比,所提方法在BLEU-1、BLEU-2、BLEU-3、BLEU-4、Rouge_L、Meteor、CIDEr分别提升了5.62%、7.25%、8.78%、10.85%、14.06%、5.14%、15.16%,表明该方法具有较好的准确性。
中图分类号:
张军燕, 赵一鸣, 林兵, 吴允平. 基于多级视觉与图文动态交互的图像中文描述方法[J]. 计算机应用, 2025, 45(5): 1520-1527.
Junyan ZHANG, Yiming ZHAO, Bing LIN, Yunping WU. Chinese image captioning method based on multi-level visual and dynamic text-image interaction[J]. Journal of Computer Applications, 2025, 45(5): 1520-1527.

图1 图像文字描述示意图
Fig. 1 Schematic diagram of image captioning
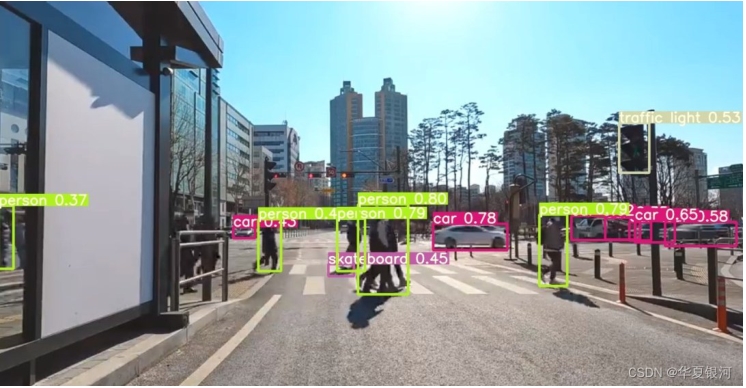
图2 自动驾驶场景下的YOLO目标检测示例图
Fig. 2 Example image of YOLO object detection results in autonomous driving scenarios
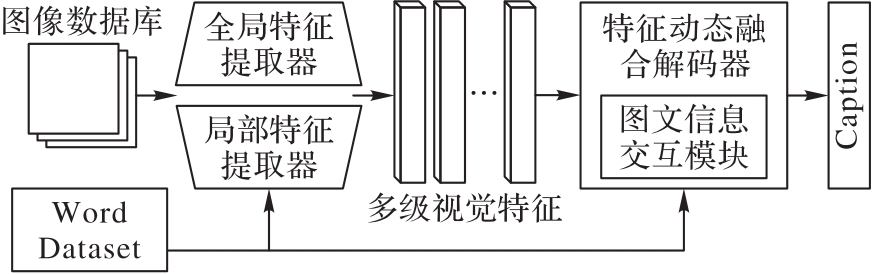
图3 本文方法的总体结构
Fig. 3 Overall structure of proposed method
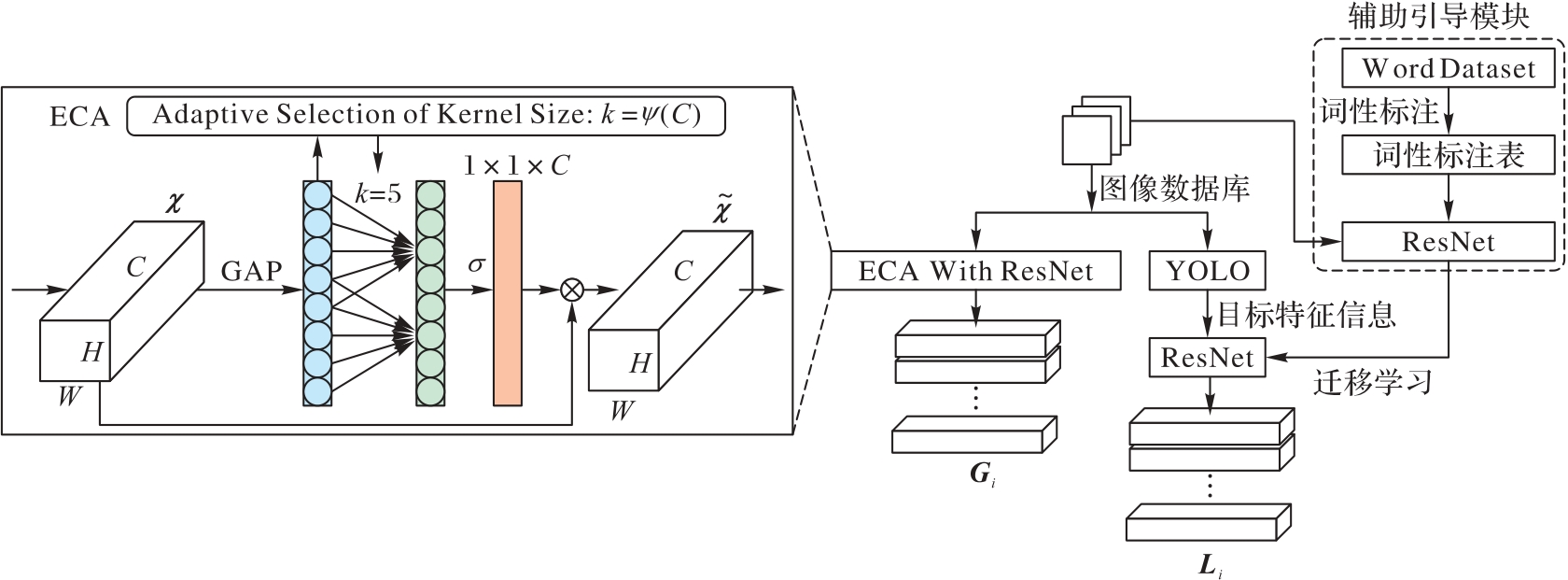
图4 编码器框架
Fig. 4 Framework of encoder
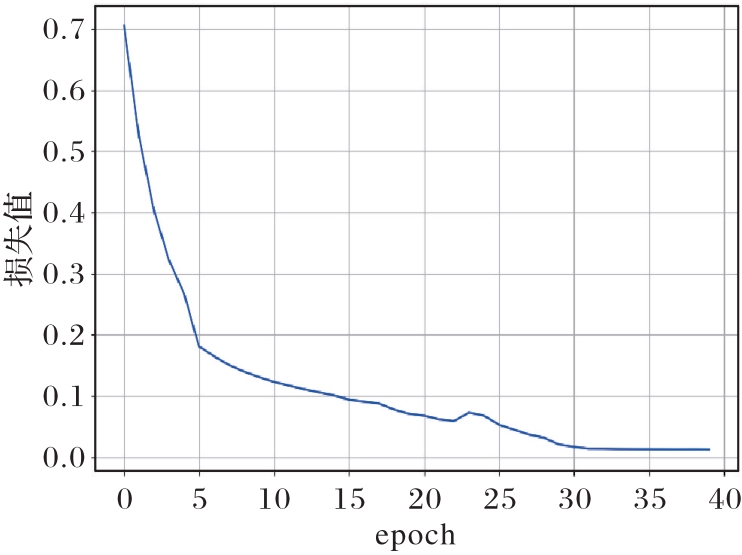
图5 M1损失变化趋势
Fig. 5 M1 loss change trend
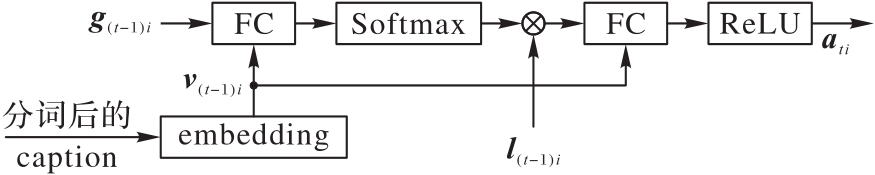
图6 图文信息交互模块
Fig. 6 Image-text information interaction module
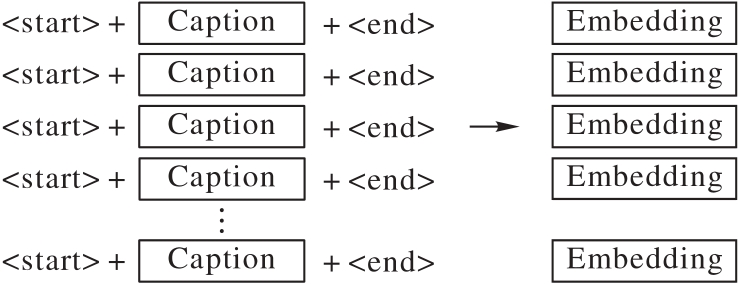
图7 文字的embedding处理
Fig. 7 Embedding of text
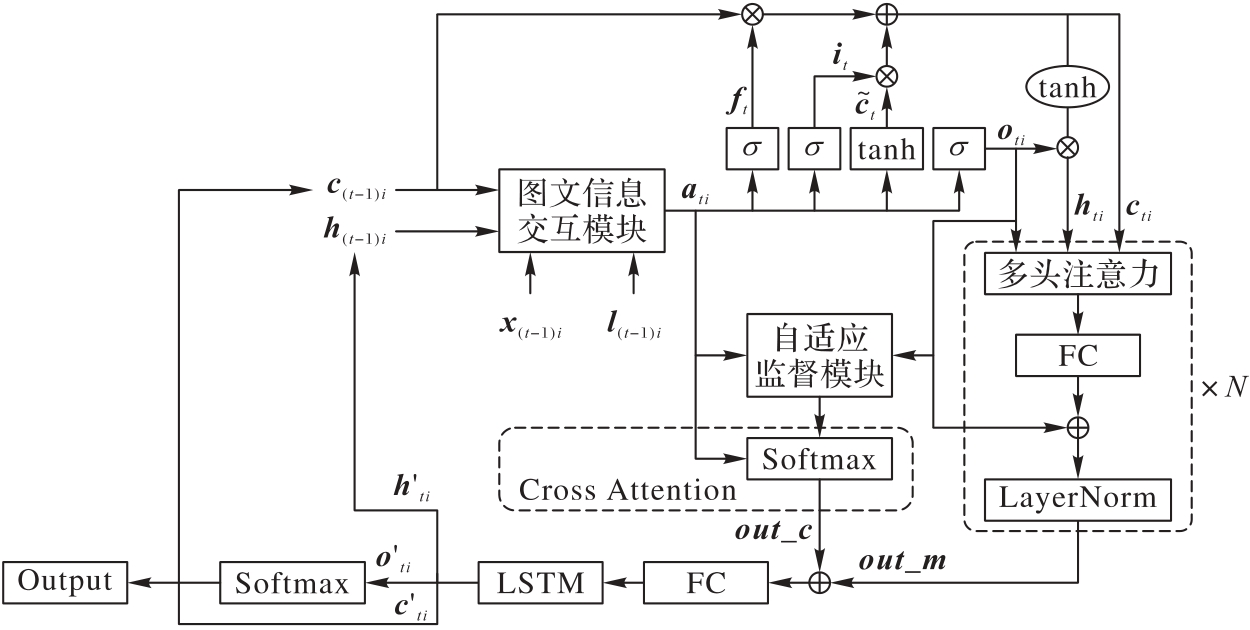
图8 特征动态融合解码器
Fig. 8 Dynamic fusion decoder for features

图9 数据集示例图
Fig. 9 Sample image of dataset
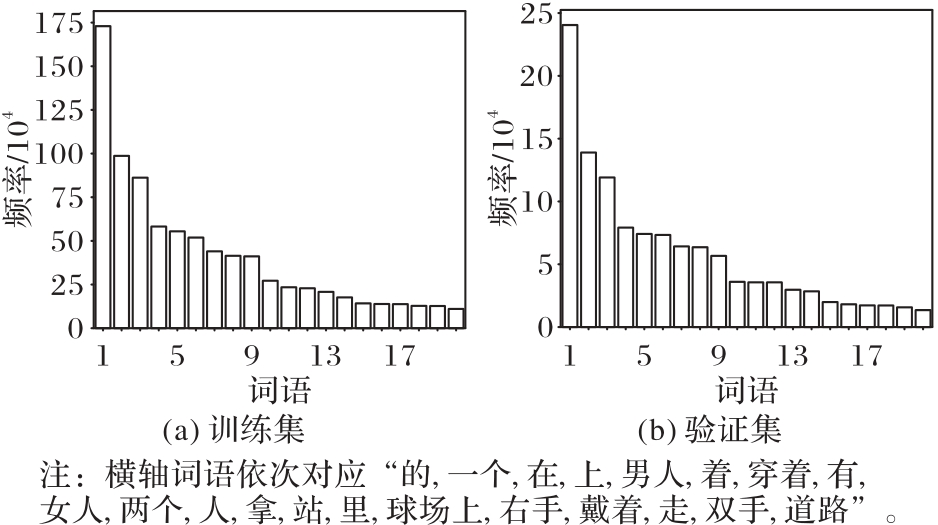
图10 训练集和验证集中的分词词频分布情况
Fig. 10 Word frequency distribution of word segmentation in training and validation datasets
图11 训练集和验证集中的词性频率分布情况
Fig. 11 Part-of-speech frequency distribution in training and validation datasets
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline-NIC | 0.765 | 0.648 | 0.547 | 0.461 | 0.633 | 0.370 | 1.425 |
| NICVATP2L | 0.671 | 0.468 | 0.344 | 0.235 | 0.521 | 0.303 | 0.669 |
| GLF-IFATT | 0.798 | 0.687 | 0.591 | 0.507 | 0.665 | 0.397 | 1.624 |
| 文献[ | 0.737 | 0.616 | 0.515 | 0.432 | 0.619 | 0.365 | 1.318 |
| 文献[ | 0.793 | 0.683 | 0.586 | 0.503 | 0.658 | 0.393 | 1.580 |
| 文献[ | 0.785 | — | — | 0.478 | 0.712 | 0.415 | 1.913 |
| DeCap | 0.618 | 0.448 | 0.326 | 0.240 | 0.494 | 0.309 | 0.701 |
| Knight | 0.443 | 0.298 | 0.203 | 0.140 | 0.402 | 0.247 | 0.202 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
表1 不同方法的评价指标得分
Tab.1 Evaluation index scores of different methods
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline-NIC | 0.765 | 0.648 | 0.547 | 0.461 | 0.633 | 0.370 | 1.425 |
| NICVATP2L | 0.671 | 0.468 | 0.344 | 0.235 | 0.521 | 0.303 | 0.669 |
| GLF-IFATT | 0.798 | 0.687 | 0.591 | 0.507 | 0.665 | 0.397 | 1.624 |
| 文献[ | 0.737 | 0.616 | 0.515 | 0.432 | 0.619 | 0.365 | 1.318 |
| 文献[ | 0.793 | 0.683 | 0.586 | 0.503 | 0.658 | 0.393 | 1.580 |
| 文献[ | 0.785 | — | — | 0.478 | 0.712 | 0.415 | 1.913 |
| DeCap | 0.618 | 0.448 | 0.326 | 0.240 | 0.494 | 0.309 | 0.701 |
| Knight | 0.443 | 0.298 | 0.203 | 0.140 | 0.402 | 0.247 | 0.202 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| dff_cross | 0.802 | 0.690 | 0.582 | 0.480 | 0.704 | 0.363 | 1.445 |
| no_cross | 0.767 | 0.610 | 0.482 | 0.359 | 0.614 | 0.311 | 1.114 |
| no_multi | 0.804 | 0.691 | 0.579 | 0.481 | 0.708 | 0.366 | 1.437 |
| only_lstm | 0.789 | 0.650 | 0.528 | 0.426 | 0.671 | 0.341 | 1.262 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
表2 本文方法的消融实验评价指标得分
Tab.2 Evaluation index scores of proposed method in ablation experiments
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| dff_cross | 0.802 | 0.690 | 0.582 | 0.480 | 0.704 | 0.363 | 1.445 |
| no_cross | 0.767 | 0.610 | 0.482 | 0.359 | 0.614 | 0.311 | 1.114 |
| no_multi | 0.804 | 0.691 | 0.579 | 0.481 | 0.708 | 0.366 | 1.437 |
| only_lstm | 0.789 | 0.650 | 0.528 | 0.426 | 0.671 | 0.341 | 1.262 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |

图12 本文方法生成的结果
Fig. 12 Result generated by proposed method
| 1 | PRUDVIRAJ J, VISHNU C, MOHAN C K. M-FFN: multi-scale feature fusion network for image captioning[J]. Applied Intelligence, 2022, 52: 14711-14723. |
| 2 | WU W, SUN D. Attention based double layer LSTM for Chinese image captioning[C]// Proceedings of the 2021 International Joint Conference on Neural Networks. Piscataway: IEEE, 2021: 1-7. |
| 3 | 徐通锵.“字”和汉语语义句法的生成机制[J]. 语言文字应用, 1999(1):24-34. |
| XU T Q. Chinese zi and the generative mechanism of semantic syntax in Chinese[J]. Applied Linguistics, 1999(1):24-34. | |
| 4 | XU M. Research on computerized automatic word segmentation of Chinese stylistic words[C]// Proceedings of the 2nd International Conference on Big Data, Information and Computer Network. Piscataway: IEEE, 2023: 230-235. |
| 5 | 白雪冰,车进,吴金蔓. 多尺度特征融合的图像描述算法[J/OL]. 计算机工程与应用 [2025-02-08].. |
| BAI X B, CHE J, WU J M. Image captioning algorithm for multi-scale features fusion[J/OL]. Computer Engineering and Applications [2025-02-08].. | |
| 6 | 陈耀传,奚雪峰,崔志明,等.图像描述技术方法研究[J]. 计算机技术与发展,2023,33(4):9-17. |
| CHEN Y C, XI X F, CUI Z M, et al. Research of image caption methods[J]. Computer Technology and Development, 2023, 33(4):9-17. | |
| 7 | 李永杰,钱艺,文益民.基于外部先验和自先验注意力的图像描述生成方法[J].计算机科学,2024,51(7):214-220. |
| LI Y J, QIAN Y, WEN Y M. Image captioning based on external prior and self-prior attention[J]. Computer Science, 2024, 51(7): 214-220. | |
| 8 | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3156-3164. |
| 9 | LALA M P, KUMAR D. Improving the quality of image captioning using CNN and LSTM method[C]// Proceedings of the 2022 International Conference on Intelligent Innovations in Engineering and Technology. Piscataway: IEEE, 2022: 64-70. |
| 10 | GUO L, LIU J, ZHU X, et al. Normalized and geometry-aware self-attention network for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10324-10333. |
| 11 | SUN T, WANG S, ZHONG S. Multi-granularity feature attention fusion network for image-text sentiment analysis[C]// Proceedings of the 2022 Computer Graphics International Conference, LNCS 13443. Cham: Springer, 2022: 3-14. |
| 12 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 13 | YAN J, XIE Y, LUAN X, et al. Caption TLSTMs: combining transformer with LSTMs for image captioning[J]. International Journal of Multimedia Information Retrieval, 2022, 11: 111-121. |
| 14 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 15 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. |
| 16 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. |
| 17 | REDMON J, FARHADI A.YOLOv3: an incremental improvement[EB/OL]. [2024-06-03].. |
| 18 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 7464-7475. |
| 19 | FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images[C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 15-29. |
| 20 | KULKARNI G, PREMRAJ V, ORDONEZ V, et al. BabyTalk: understanding and generating simple image descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903. |
| 21 | WU J, ZHENG H, ZHAO B, et al. Large-scale dataset for going deeper in image understanding[C]// Proceedings of the 2019 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2019: 1480-1485. |
| 22 | 肖雨寒,江爱文,王明文,等. 基于视觉-语义中间综合属性特征的图像中文描述生成算法[J]. 中文信息学报, 2021, 35(4):129-138. |
| XIAO Y H, JIANG A W, WANG M W, et al. Chinese image captioning based on middle-level visual-semantic composite attributes[J]. Journal of Chinese Information Processing, 2021, 35(4):129-138. | |
| 23 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 24 | KONG D, ZHAO H, ZENG X. Research on image content description in Chinese based on fusion of image global and local features[J]. PLoS ONE, 2022, 17(8): No.e0271322. |
| 25 | WANG Y, WANG Y, ZHU J, et al. Image caption generation method based on target detection[C]// Proceedings of the 8th International Conference on Intelligent Informatics and Biomedical Sciences. Piscataway: IEEE, 2023: 151-155. |
| 26 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250. |
| 27 | ZHANG W, NIE W, LI X, et al. Image caption generation with adaptive Transformer[C]// Proceedings of the 34rd Youth Academic Annual Conference of Chinese Association of Automation. Piscataway: IEEE, 2019: 521-526. |
| 28 | LIU M, HU H, LI L, et al. Chinese image caption generation via visual attention and topic modeling[J]. IEEE Transactions on Cybernetics, 2022, 52(2): 1247-1257. |
| 29 | 赵宏,孔东一.图像特征注意力与自适应注意力融合的图像内容中文描述[J].计算机应用,2021,41(9):2496-2503. |
| ZHAO H, KONG D Y. Chinese description of image content based on fusion of image feature attention and adaptive attention[J]. Journal of Computer Applications, 2021, 41(9): 2496-2503. | |
| 30 | LU H, YANG R, DENG Z, et al. Chinese image captioning via fuzzy attention-based DenseNet-BiLSTM[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(1s): No.14. |
| 31 | 刘茂福,施琦,聂礼强. 基于视觉关联与上下文双注意力的图像描述生成方法[J]. 软件学报, 2022, 33(9):3210-3222. |
| LIU M F, SHI Q, NIE L Q. Image captioning based on visual relevance and context dual attention[J]. Journal of Software, 2022, 33(9):3210-3222. | |
| 32 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| 33 | DENKOWSKI M, LAVIE A. Meteor Universal: language specific translation evaluation for any target language[C]// Proceedings of the 9th Workshop on Statistical Machine Translation. Stroudsburg: ACL, 2014: 376-380. |
| 34 | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| 35 | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus based image description evaluation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4566-4575. |
| 36 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2024-08-03].. |
| 37 | LI W, ZHU L, WEN L, et al. DeCap: decoding CLIP latents for zero-shot captioning via text-only training[EB/OL]. [2024-05-11].. |
| 38 | WANG J, YAN M, ZHANG Y. From association to generation: text-only captioning by unsupervised cross-modal mapping[C]// Proceedings of the 32nd International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 2023: 4326-4334. |
| [1] | 石乾宏, 杨燕, 江永全, 欧阳小草, 范武波, 陈强, 姜涛, 李媛. 面向空气质量预测的多粒度突变拟合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2643-2650. |
| [2] | 孟凡, 杨群力, 霍静, 王新宽. 基于边缘异常候选集的迭代式主动多元时序异常检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1458-1463. |
| [3] | 唐宇皓, 彭德中, 袁钟. 面向不完备混合数据的模糊多粒度异常检测[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3097-3104. |
| [4] | 张晓燕, 王佳一. 属性聚类下三支概念的对比[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1336-1341. |
| [5] | 姚华勇, 叶东毅, 陈昭炯. 考虑多粒度反馈的多轮对话强化学习推荐算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 15-21. |
| [6] | 胡军, 许正康, 刘立, 钟福金. 融合多粒度社区信息的网络嵌入方法[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 663-670. |
| [7] | 耿艳兵, 廉永健. 基于多粒度特征生成对抗网络的跨分辨率行人重识别[J]. 《计算机应用》唯一官方网站, 2022, 42(11): 3573-3579. |
| [8] | 卞凌志, 王直杰. 基于增强多维多粒度级联森林的信用评分模型[J]. 计算机应用, 2021, 41(9): 2539-2544. |
| [9] | 孟凡, 陈广, 王勇, 高阳, 高德群, 贾文龙. 基于多粒度时序结构表示的异常检测算法在储层含油性检测中应用[J]. 计算机应用, 2021, 41(8): 2453-2459. |
| [10] | 王鹏, 李艳雯, 杨迪, 杨华民. 基于层级控制的宏观基本图交通信号控制模型[J]. 计算机应用, 2021, 41(2): 571-576. |
| [11] | 任俊伟, 曾诚, 肖丝雨, 乔金霞, 何鹏. 基于会话的多粒度图神经网络推荐模型[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3164-3170. |
| [12] | 徐怡, 肖鹏. 基于容差关系的多粒度粗糙集中近似集动态更新方法[J]. 计算机应用, 2019, 39(5): 1247-1251. |
| [13] | 郑文彬, 李进金, 于佩秋, 林艺东. 变精度多粒度粗糙集近似集更新的矩阵算法[J]. 计算机应用, 2019, 39(11): 3140-3145. |
| [14] | 翁理国, 刘万安, 施必成, 夏旻. 基于多维多粒度级联森林的高原地区云雪分类[J]. 计算机应用, 2018, 38(8): 2218-2223. |
| [15] | 万志超, 宋杰, 沈永良. 可变直觉模糊多粒度粗糙集模型及其近似分布约简算法[J]. 计算机应用, 2018, 38(2): 390-398. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||