


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 4030-4036.DOI: 10.11772/j.issn.1001-9081.2024121745
平金如1, 孙子文1,2( )
)
收稿日期:2024-12-12
修回日期:2025-03-14
接受日期:2025-03-17
发布日期:2025-03-27
出版日期:2025-12-10
通讯作者:
孙子文
作者简介:平金如(2000—),男,江苏南通人,硕士研究生,CCF会员,主要研究方向:医学图像处理、肺炎图像分类基金资助:
Jinru PING1, Ziwen SUN1,2()
Received:2024-12-12
Revised:2025-03-14
Accepted:2025-03-17
Online:2025-03-27
Published:2025-12-10
Contact:
Ziwen SUN
About author:PING Jinru, born in 2000, M. S. candidate. His research interests include medical image processing, pneumonia image classification.
Supported by:摘要:
针对肺炎X光图像病灶区域特征难以被提取和现有模型轻量化程度不高的问题,提出一种特征融合的MV2-Transformer(FFMV2-Transformer)肺炎X光图像分类模型。首先,采用轻量型网络MobileNetV2(Mobile Network Version 2)作为主干网络,并在反向残差瓶颈块中嵌入坐标注意力(CA)机制,从而通过将位置信息嵌入通道信息提高模型对病灶区域特征的提取能力;其次,设计局部和全局特征融合模块(LGFFM)将卷积层提取的局部特征与Transformer捕获的全局特征相结合,从而使模型能同时捕捉病灶区域的细节信息和整体信息,并进一步提高模型的语义特征提取能力;最后,设计跨层特征融合模块(CFFM)将空间注意力机制增强的浅层特征的空间信息与通道注意力机制增强的深层特征的语义信息相结合,从而获得丰富的上下文信息。为了验证模型的有效性,在肺炎X光数据集上进行消融实验和对比实验,结果表明,FFMV2-Transformer模型与MobileViT(Mobile Vision Transformer)模型相比,准确率、精确率、召回率、F1值和AUC(Area Under ROC(Receiver Operating Characteristic) Curve)值分别提高了1.09、0.31、1.91、1.08和0.40个百分点。可见,FFMV2-Transformer模型能在实现模型轻量化的同时,有效提取肺炎X光图像病灶区域的特征。
中图分类号:
平金如, 孙子文. 特征融合的MV2-Transformer肺炎X光图像分类模型[J]. 计算机应用, 2025, 45(12): 4030-4036.
Jinru PING, Ziwen SUN. Pneumonia X-ray image classification model by MV2-Transformer with feature fusion[J]. Journal of Computer Applications, 2025, 45(12): 4030-4036.

图1 FFMV2-Transformer模型的结构
Fig.1 Structure of FFMV2-Transformer model

图2 MobileNetV2的2种基本模块
Fig.2 Two basic modules of MobileNetV2

图3 CA机制的结构
Fig.3 Structure of CA mechanism

图4 嵌入CA后的IRB
Fig.4 IRB after embedding CA
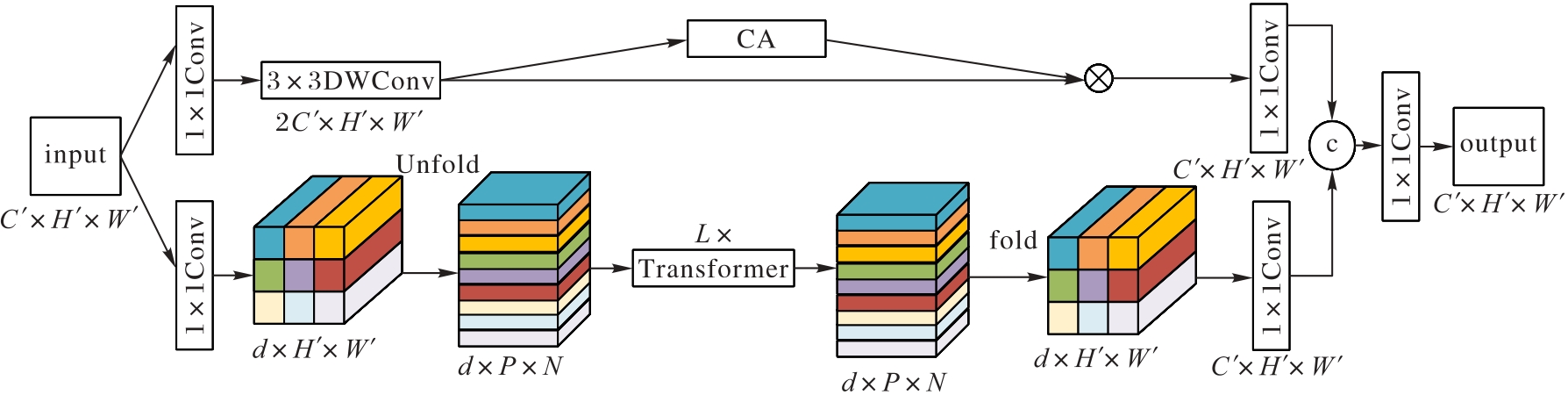
图5 LGFFM的结构
Fig.5 Structure of LGFFM
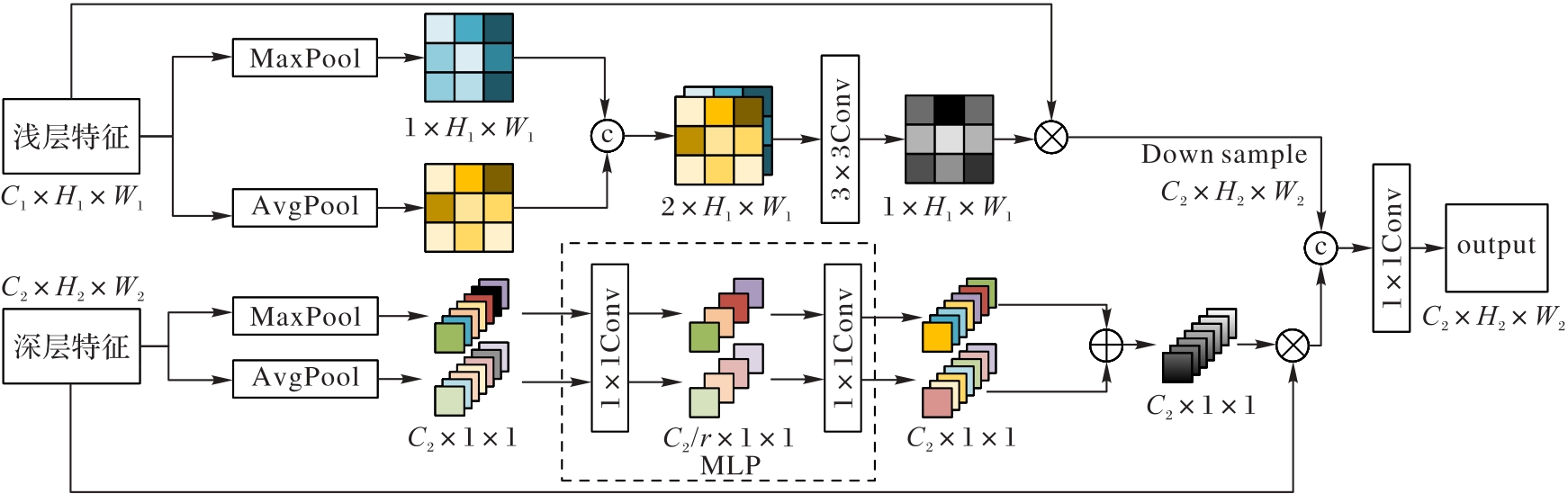
图6 CFFM的结构
Fig.6 Structure of CFFM
| 模型 | CA | LGFFM | CFFM | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|---|---|---|
| MobileNetV2 | 94.05 | 90.94 | 98.09 | 94.38 | 97.46 | |||
| 模型1 | √ | 94.92 | 93.09 | 97.24 | 95.12 | 98.11 | ||
| 模型2 | √ | 94.59 | 91.68 | 98.30 | 94.88 | 97.98 | ||
| 模型3 | √ | 94.49 | 93.39 | 95.97 | 94.66 | 98.09 | ||
| 模型4 | √ | √ | 95.35 | 92.13 | 99.36 | 98.15 | ||
| 模型5 | √ | √ | 95.14 | 96.39 | 95.28 | 98.21 | ||
| 模型6 | √ | √ | 94.41 | 96.82 | 95.60 | |||
| 模型7 | √ | √ | √ | 95.68 | 93.36 | 95.87 | 98.61 |
表1 消融实验结果 (%)
Tab.1 Results of ablation experiments
| 模型 | CA | LGFFM | CFFM | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|---|---|---|
| MobileNetV2 | 94.05 | 90.94 | 98.09 | 94.38 | 97.46 | |||
| 模型1 | √ | 94.92 | 93.09 | 97.24 | 95.12 | 98.11 | ||
| 模型2 | √ | 94.59 | 91.68 | 98.30 | 94.88 | 97.98 | ||
| 模型3 | √ | 94.49 | 93.39 | 95.97 | 94.66 | 98.09 | ||
| 模型4 | √ | √ | 95.35 | 92.13 | 99.36 | 98.15 | ||
| 模型5 | √ | √ | 95.14 | 96.39 | 95.28 | 98.21 | ||
| 模型6 | √ | √ | 94.41 | 96.82 | 95.60 | |||
| 模型7 | √ | √ | √ | 95.68 | 93.36 | 95.87 | 98.61 |
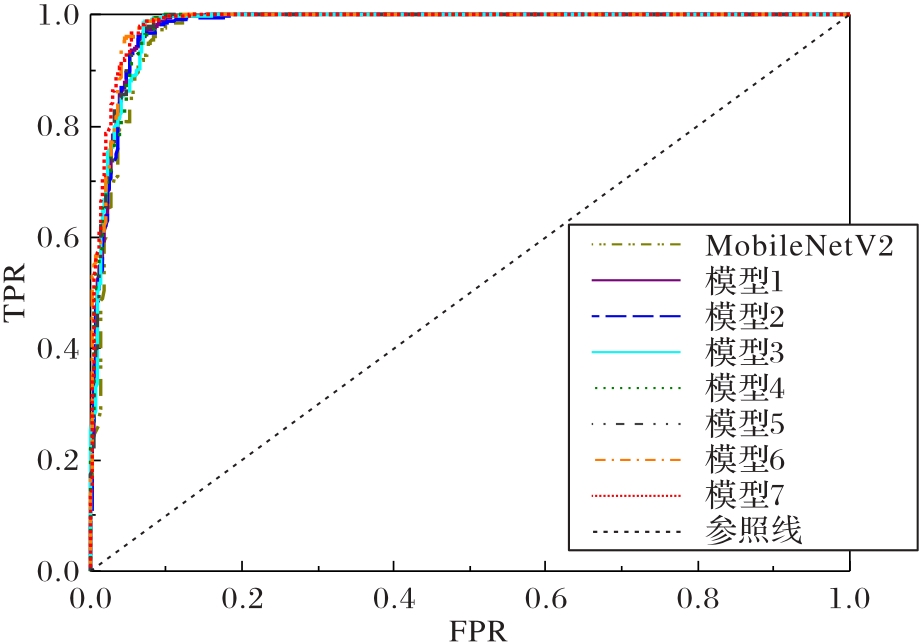
图7 消融实验中各模型的ROC曲线
Fig.7 ROC curves of different models in ablation experiments
| 模型 | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|
| GhostNet | 94.38 | 92.49 | 96.82 | 94.61 | 97.49 |
| MobileNetV3 | 94.27 | 91.14 | 94.59 | ||
| MobileViT | 96.60 | 98.21 | |||
| ShuffleNet | 93.73 | 91.38 | 96.82 | 94.02 | 97.18 |
| EfficientNet | 94.49 | 92.17 | 97.45 | 94.74 | 97.30 |
| 本文模型 | 95.68 | 93.36 | 98.51 | 95.87 | 98.61 |
表2 对比实验结果 (%)
Tab.2 Results of comparison experiments
| 模型 | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|
| GhostNet | 94.38 | 92.49 | 96.82 | 94.61 | 97.49 |
| MobileNetV3 | 94.27 | 91.14 | 94.59 | ||
| MobileViT | 96.60 | 98.21 | |||
| ShuffleNet | 93.73 | 91.38 | 96.82 | 94.02 | 97.18 |
| EfficientNet | 94.49 | 92.17 | 97.45 | 94.74 | 97.30 |
| 本文模型 | 95.68 | 93.36 | 98.51 | 95.87 | 98.61 |

图8 对比实验中各模型的ROC曲线
Fig.8 ROC curves of different models in comparison experiments
| 模型 | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|
| GhostNet | 76.50 | 97.19 | |||
| MobileNetV3 | 91.55 | 87.16 | 83.75 | 95.39 | |
| MobileViT | 92.06 | 96.43 | 73.34 | 83.32 | |
| ShuffleNet | 91.46 | 94.72 | 72.46 | 82.10 | 97.36 |
| EfficientNet | 91.79 | 93.73 | 74.61 | 83.08 | 96.60 |
| 本文模型 | 93.80 | 92.84 | 83.51 | 87.93 | 97.84 |
表3 各个模型在ChestXRay2017数据集上的分类结果 (%)
Tab.3 Classification results of different models on ChestXRay2017 dataset
| 模型 | Acc | Pre | Rec | F1 | AUC |
|---|---|---|---|---|---|
| GhostNet | 76.50 | 97.19 | |||
| MobileNetV3 | 91.55 | 87.16 | 83.75 | 95.39 | |
| MobileViT | 92.06 | 96.43 | 73.34 | 83.32 | |
| ShuffleNet | 91.46 | 94.72 | 72.46 | 82.10 | 97.36 |
| EfficientNet | 91.79 | 93.73 | 74.61 | 83.08 | 96.60 |
| 本文模型 | 93.80 | 92.84 | 83.51 | 87.93 | 97.84 |
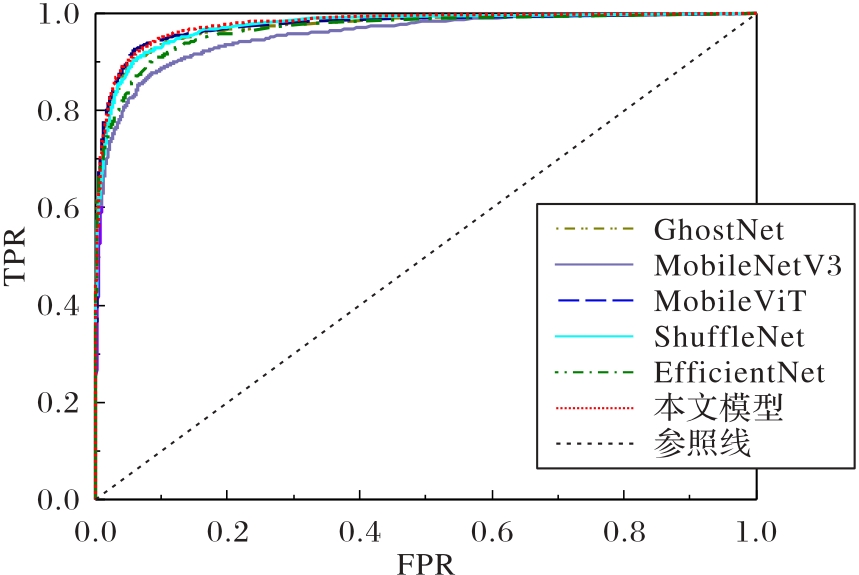
图9 泛化实验中各模型的ROC曲线
Fig.9 ROC curves of different models in generalization experiments
| 模型 | 计算量/GFLOPs | 参数量/ |
|---|---|---|
| MobileNetV2 | 0.07 | 0.45 |
| GhostNet | 3.90 | |
| MobileNetV3 | 0.16 | 1.52 |
| MobileViT | 0.27 | 1.27 |
| ShuffleNet | 0.44 | 3.30 |
| EfficientNet | 0.41 | 5.29 |
| 本文模型 | 0.26 |
表4 时间和空间复杂度分析
Tab.4 Time and space complexity analysis
| 模型 | 计算量/GFLOPs | 参数量/ |
|---|---|---|
| MobileNetV2 | 0.07 | 0.45 |
| GhostNet | 3.90 | |
| MobileNetV3 | 0.16 | 1.52 |
| MobileViT | 0.27 | 1.27 |
| ShuffleNet | 0.44 | 3.30 |
| EfficientNet | 0.41 | 5.29 |
| 本文模型 | 0.26 |
| [1] | NARALASETTI V, SHAIK R K, KATEPALLI G, et al. Deep learning models for pneumonia identification and classification based on X-ray images [J]. Traitement du Signal, 2021, 38(3): 903-909. |
| [2] | RONG G, MENDEZ A, ASSI E BOU, et al. Artificial intelligence in healthcare: review and prediction case studies[J]. Engineering, 2020, 6(3): 291-301. |
| [3] | 陈丽芳,罗世勇. 融合卷积和Transformer的多尺度肝肿瘤分割方法[J]. 计算机工程与应用, 2024, 60(4): 270-279. |
| CHEN L F, LUO S Y, Multi-scale liver tumor segmentation algorithm by fusing convolution and Transformer[J]. Computer Engineering and Applications, 2024, 60(4): 270-279. | |
| [4] | MAMALAKIS M, SWIFT A J, VORSELAARS B, et al. DenResCov-19: a deep transfer learning network for robust automatic classification of COVID-19, pneumonia, and tuberculosis from X-rays[J]. Computerized Medical Imaging and Graphics, 2021, 94: No.102008. |
| [5] | 周涛,刘赟璨,陆惠玲,等. ResNet及其在医学图像处理领域的应用:研究进展与挑战[J]. 电子与信息学报, 2022, 44(1): 149-167. |
| ZHOU T, LIU Y C, LU H L, et al. ResNet and its application to medical image processing: research progress and challenges[J]. Journal of Electronics and Information Technology, 2022, 44(1): 149-167. | |
| [6] | CHEN Y, LIN Y, XU X, et al. Classification of lungs infected COVID-19 images based on Inception-ResNet[J]. Computer Methods and Programs in Biomedicine, 2022, 225: No.107053. |
| [7] | JAIN R, NAGRATH P, KATARIA G, et al. Pneumonia detection in chest X-ray images using convolutional neural networks and transfer learning[J]. Measurement, 2020, 165: No.108046. |
| [8] | LIANG S, NIE R, CAO J, et al. FCF: feature complement fusion network for detecting COVID-19 through CT scan images[J]. Applied Soft Computing, 2022, 125: No.109111. |
| [9] | LI B, KANG G, CHENG K, et al. Attention-guided convolutional neural network for detecting pneumonia on chest X-rays[C]// Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Piscataway: IEEE, 2019: 4851-4854. |
| [10] | 宋子岩,罗川,李天瑞,等. 基于注意力机制和双分支网络的胸部疾病分类[J]. 计算机科学, 2024, 51(11A): No.230900116. |
| SONG Z Y, LUO C, LI T R, et al. Classification of thoracic diseases based on attention mechanisms and two-branch networks[J]. Computer Science, 2024, 51(11A): No.230900116. | |
| [11] | NASEER M, RANASINGHE K, KHAN S, et al. Intriguing properties of Vision Transformers[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 23296-23308. |
| [12] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [13] | PARK S, KIM G, OH Y, et al. Multi-task Vision Transformer using low-level chest X-ray feature corpus for COVID-19 diagnosis and severity quantification[J]. Medical Image Analysis, 2022, 75: No.102299. |
| [14] | 胡锦波,聂为之,宋丹,等. 可形变Transformer辅助的胸部X光影像疾病诊断模型[J]. 浙江大学学报(工学版), 2023, 57(10): 1923-1932. |
| HU J B, NIE W Z, SONG D, et al. Chest X-ray imaging disease diagnosis model assisted by deformable Transformer[J]. Journal of Zhejiang University (Engineering Science), 2023, 57(10): 1923-1932. | |
| [15] | SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. |
| [16] | HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2024-11-01].. |
| [17] | HU J, LI S, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| [18] | HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13708-13717. |
| [19] | 孙俊,朱伟栋,罗元秋,等. 基于改进MobileNet-V2的田间农作物叶片病害识别[J]. 农业工程学报, 2021, 37(22): 161-169. |
| SUN J, ZHU W D, LUO Y Q, et al. Recognizing the diseases of crop leaves in fields using improved MobileNet-V2[J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(22): 161-169. | |
| [20] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [21] | 王威,黄文迪,王新,等. 面向肺炎CT图像识别的DL-CTNet模型[J]. 计算机辅助设计与图形学学报, 2024, 36(1): 122-132. |
| WANG W, HUANG W D, WANG X, et al. DL-CTNet model for CT images recognition of pneumonia[J]. Journal of Computer-Aided Design and Computer Graphics, 2024, 36(1): 122-132. | |
| [22] | HOU S, XIAO S, DONG W, et al. Multi-level features fusion via cross-layer guided attention for hyperspectral pansharpening[J]. Neurocomputing, 2022, 506: 380-392. |
| [23] | GIEŁCZYK A, MARCINIAK A, TARCZEWSKA M, et al. Pre-processing methods in chest X-ray image classification[J]. PLoS ONE, 2022, 17(4): No.0265949. |
| [24] | HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586. |
| [25] | HOWARD A, SANDLER M, CHU G, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324. |
| [26] | MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly Vision Transformer[EB/OL]. [2024-11-01].. |
| [27] | ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6848-6856. |
| [28] | TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114. |
| [29] | KERMANY D, ZHANG K, GOLDBAUM M. Labeled Optical Coherence Tomography (OCT) and chest X-ray images for classification[DS/OL]. [2024-11-01].. |
| [1] | 李亚男, 郭梦阳, 邓国军, 陈允峰, 任建吉, 原永亮. 基于多模态融合特征的并分支发动机寿命预测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 305-313. |
| [2] | 姚理进, 张迪, 周丕宇, 曲志坚, 王海鹏. 基于Transformer和门控循环单元的磷酸化肽从头测序算法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 297-304. |
| [3] | 桑雨, 贡同, 赵琛, 于博文, 李思漫. 具有光度对齐的域适应夜间目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 242-251. |
| [4] | 梁瑾裕, 高宏娟, 杜晓飞. 基于潜在特征增强进行解耦的三维人脸生成方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 216-223. |
| [5] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [6] | 曹柠, 温昕, 郝雁嵘, 曹锐. 多域特征融合的轻量化运动想象脑电信号解码神经网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 289-296. |
| [7] | 王丽芳, 任文婧, 郭晓东, 张荣国, 胡立华. 用于低剂量CT图像降噪的多路特征生成对抗网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 270-279. |
| [8] | 吴俊衡, 王晓东, 何启学. 基于统计分布感知与频域双通道融合的时序预测模型[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 113-123. |
| [9] | 马英杰, 覃晶滢, 赵耿, 肖靖. 面向物联网图像的深度压缩感知网络及其混沌加密保护方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 144-151. |
| [10] | 吕景刚, 彭绍睿, 高硕, 周金. 复频域注意力和多尺度频域增强驱动的语音增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2957-2965. |
| [11] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [12] | 王翔, 陈志祥, 毛国君. 融合局部和全局相关性的多变量时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2806-2816. |
| [13] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [14] | 王芳, 胡静, 张睿, 范文婷. 内容引导下多角度特征融合医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3017-3025. |
| [15] | 梁一鸣, 范菁, 柴汶泽. 基于双向交叉注意力的多尺度特征融合情感分类[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2773-2782. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||