


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (1): 216-223.DOI: 10.11772/j.issn.1001-9081.2025010051
梁瑾裕1, 高宏娟1,2( ), 杜晓飞1
), 杜晓飞1
收稿日期:2025-01-15
修回日期:2025-03-26
接受日期:2025-03-26
发布日期:2026-01-10
出版日期:2026-01-10
通讯作者:
高宏娟
作者简介:梁瑾裕(2000—),男,宁夏中卫人,硕士研究生,主要研究方向:计算机视觉、图形图像处理基金资助:
Jinyu LIANG1, Hongjuan GAO1,2(), Xiaofei DU1
Received:2025-01-15
Revised:2025-03-26
Accepted:2025-03-26
Online:2026-01-10
Published:2026-01-10
Contact:
Hongjuan GAO
About author:LIANG Jinyu, born in 2000, M. S. candidate. His research interests include computer vision, graphics and image processing.Supported by:摘要:
针对现有的三维人脸生成方法中潜在特征解释性不足、解耦能力有限以及身份一致性不佳等问题,提出一种基于潜在特征增强进行解耦的三维人脸生成方法(LFED)。首先,采用层次聚类技术构建向量离散化模块,以促进潜在特征对先验知识的吸收,提升解耦性能;其次,设计位置注意力模块,通过逐元素求和操作,选择性整合潜在特征的位置信息,确保生成人脸的身份一致性;最后,结合先验知识与位置信息,采用最大归一化技术,增强潜在特征在人脸生成过程中的可解释性。实验结果表明,所提方法在潜在特征解耦指标变异可预测性(VP)上的精度达到95.67%,与小批次特征交换解纠缠方法SD-VAE (Swap Disentangled Variational Auto-Encoder)、局部特征投影解纠缠方法LED-VAE (Local Eigenprojection Disentangled Variational Auto-Encoder)和球谐函数局部特征投影方法SHLED-VAE (Latent Feature Enhanced for Disentanglement Variational Auto-Encoder )相比,分别提升了14.96、14.33和12.46个百分点。可见,所提方法在保持良好的表示与重建能力的同时,解耦性能有大幅提升。
中图分类号:
梁瑾裕, 高宏娟, 杜晓飞. 基于潜在特征增强进行解耦的三维人脸生成方法[J]. 计算机应用, 2026, 46(1): 216-223.
Jinyu LIANG, Hongjuan GAO, Xiaofei DU. 3D face generation method based on latent feature enhancement for disentanglement[J]. Journal of Computer Applications, 2026, 46(1): 216-223.
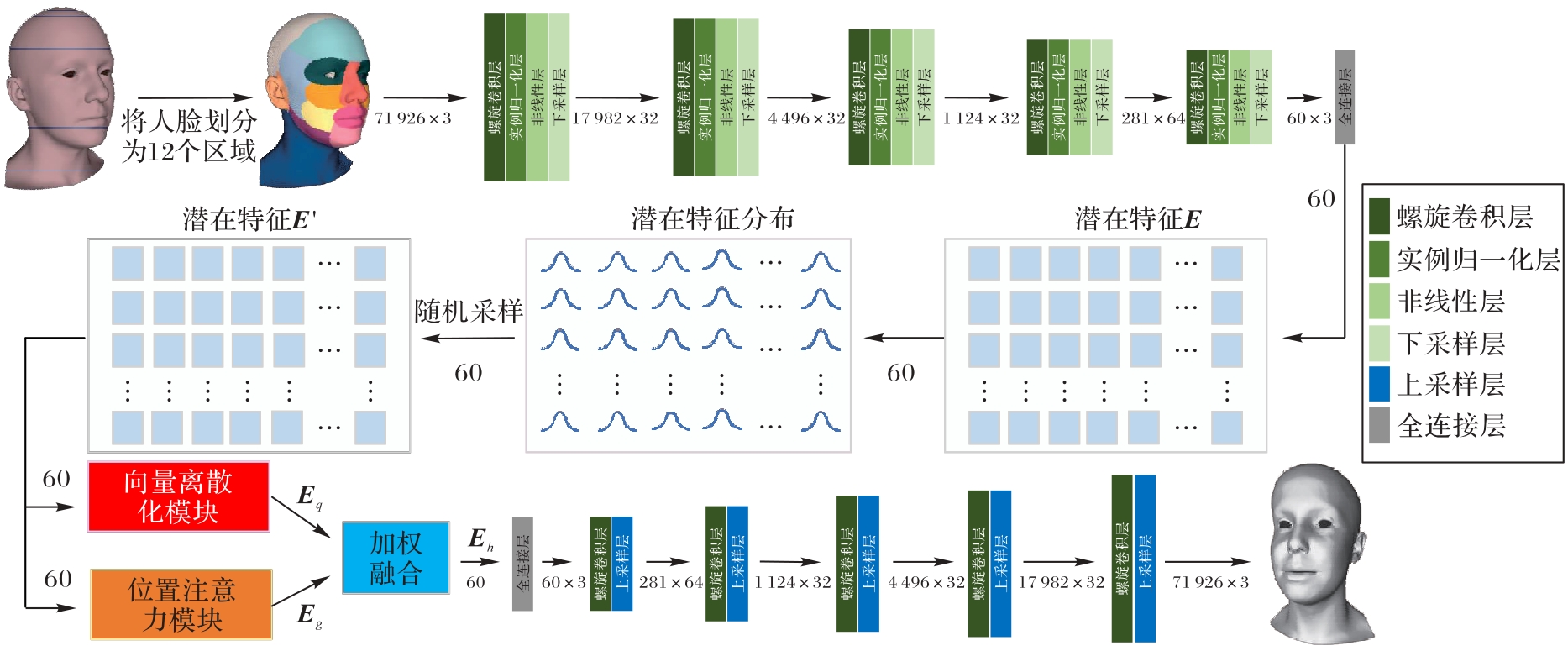
图1 本文方法的架构
Fig. 1 Framework of proposed method
| 层序号 | 层名称 | 输入大小 | 输出大小 |
|---|---|---|---|
| 1 | 螺旋卷积层[ | 71 926 | 71 926 |
| 实例归一化层 | 71 926 | 71 926 | |
| 非线性层 | 71 926 | 71 926 | |
| 下采样层 | 71 926 | 17 982 | |
| 2 | 螺旋卷积层[ | 17 982 | 17 982 |
| 实例归一化层 | 17 982 | 17 982 | |
| 非线性层 | 17 982 | 17 982 | |
| 下采样层 | 17 982 | 4 496 | |
| 3 | 螺旋卷积层[ | 4 496 | 4 496 |
| 实例归一化层 | 4 496 | 4 496 | |
| 非线性层 | 4 496 | 4 496 | |
| 下采样层 | 4 496 | 1 124 | |
| 4 | 螺旋卷积层[ | 1 124 | 1 124 |
| 实例归一化层 | 1 124 | 1 124 | |
| 非线性层 | 1 124 | 1 124 | |
| 下采样层 | 1 124 | 281 | |
| 5 | 螺旋卷积层[ | 281 | 281 |
| 实例归一化层 | 281 | 281 | |
| 非线性层 | 281 | 281 | |
| 下采样层 | 281 | 60 | |
| 6 | 全连接 | 60 | 60 |
表1 编码器各层输入输出
Tab. 1 Encoder layer input and output
| 层序号 | 层名称 | 输入大小 | 输出大小 |
|---|---|---|---|
| 1 | 螺旋卷积层[ | 71 926 | 71 926 |
| 实例归一化层 | 71 926 | 71 926 | |
| 非线性层 | 71 926 | 71 926 | |
| 下采样层 | 71 926 | 17 982 | |
| 2 | 螺旋卷积层[ | 17 982 | 17 982 |
| 实例归一化层 | 17 982 | 17 982 | |
| 非线性层 | 17 982 | 17 982 | |
| 下采样层 | 17 982 | 4 496 | |
| 3 | 螺旋卷积层[ | 4 496 | 4 496 |
| 实例归一化层 | 4 496 | 4 496 | |
| 非线性层 | 4 496 | 4 496 | |
| 下采样层 | 4 496 | 1 124 | |
| 4 | 螺旋卷积层[ | 1 124 | 1 124 |
| 实例归一化层 | 1 124 | 1 124 | |
| 非线性层 | 1 124 | 1 124 | |
| 下采样层 | 1 124 | 281 | |
| 5 | 螺旋卷积层[ | 281 | 281 |
| 实例归一化层 | 281 | 281 | |
| 非线性层 | 281 | 281 | |
| 下采样层 | 281 | 60 | |
| 6 | 全连接 | 60 | 60 |
| 层序号 | 层名称 | 输入大小 | 输出大小 |
|---|---|---|---|
| 1 | 全连接层 | 60 | 60 |
| 2 | 螺旋卷积层[ | 60 | 281 |
| 上采样层 | 281 | 281 | |
| 3 | 螺旋卷积层[ | 281 | 1 124 |
| 上采样层 | 1 124 | 1 124 | |
| 4 | 螺旋卷积层[ | 1 124 | 4 496 |
| 上采样层 | 4 496 | 4 496 | |
| 5 | 螺旋卷积层[ | 4 496 | 17 982 |
| 上采样层 | 17 982 | 17 982 | |
| 6 | 螺旋卷积层[ | 17 982 | 71 926 |
| 上采样层 | 71 926 | 71 926 |
表2 解码器各层输入输出
Tab. 2 Decoder layer input and output
| 层序号 | 层名称 | 输入大小 | 输出大小 |
|---|---|---|---|
| 1 | 全连接层 | 60 | 60 |
| 2 | 螺旋卷积层[ | 60 | 281 |
| 上采样层 | 281 | 281 | |
| 3 | 螺旋卷积层[ | 281 | 1 124 |
| 上采样层 | 1 124 | 1 124 | |
| 4 | 螺旋卷积层[ | 1 124 | 4 496 |
| 上采样层 | 4 496 | 4 496 | |
| 5 | 螺旋卷积层[ | 4 496 | 17 982 |
| 上采样层 | 17 982 | 17 982 | |
| 6 | 螺旋卷积层[ | 17 982 | 71 926 |
| 上采样层 | 71 926 | 71 926 |
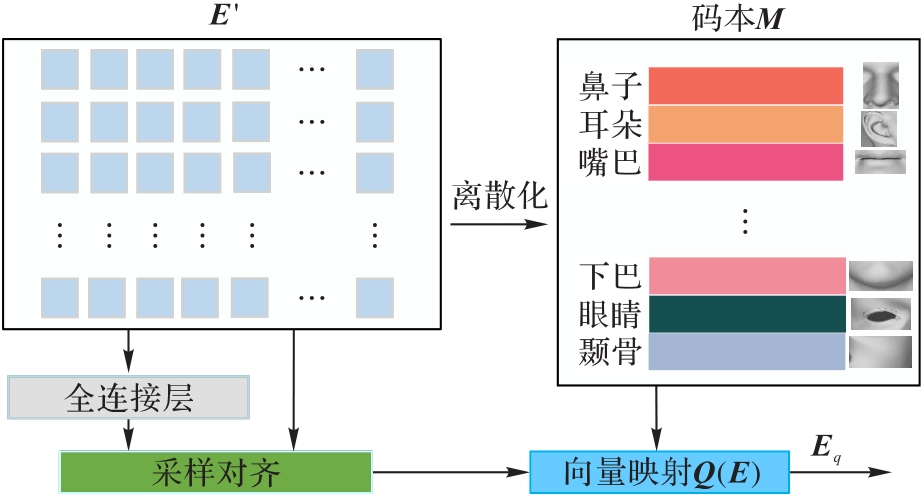
图2 向量离散化模块的架构
Fig. 2 Architecture of vector discretization module
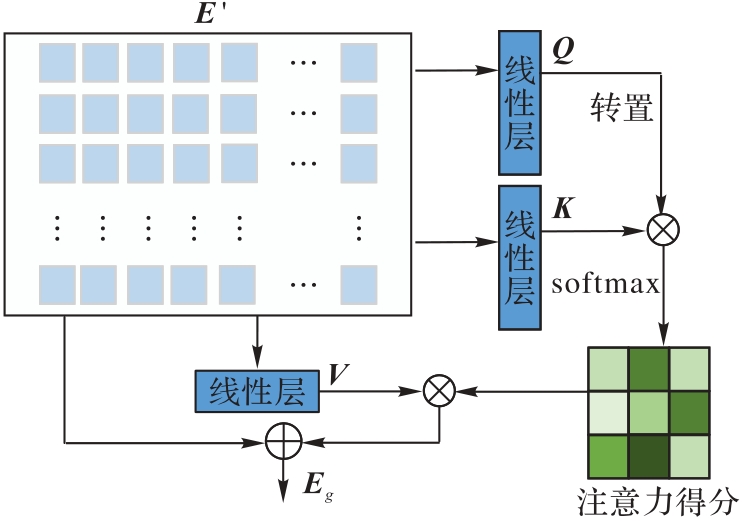
图3 位置注意力模块的架构
Fig. 3 Architecture of positional attention module
| 方法 | Diversity ( | JSD ( | MMD ( | COV/%( | VP/%( | 训练时间/min( |
|---|---|---|---|---|---|---|
| β-VAE[ | 3.93 | 6.31 | 1.06 | 59.07 | 65.92 | 106 |
| DIP-VAE-I[ | 3.12 | 11.15 | 0.93 | 52.82 | 50.60 | 108 |
| LSGAN[ | 5.92 | 2.52 | 1.54 | 43.95 | 71.39 | 374 |
| WGAN[ | 4.46 | 5.41 | 1.26 | 56.65 | 77.15 | 313 |
| SD-VAE[ | 4.13 | 4.59 | 1.50 | 64.60 | 80.71 | 441 |
| LED-VAE[ | 5.22 | 2.31 | 2.24 | 49.79 | 81.34 | 342 |
| SHLED-VAE[ | 5.13 | 3.32 | 1.70 | 46.69 | 83.21 | 288 |
| LFED | 5.26 | 2.34 | 1.84 | 47.58 | 95.67 | 388 |
表3 不同方法的实验结果对比
Tab. 3 Comparison of experimental results from different methods
| 方法 | Diversity ( | JSD ( | MMD ( | COV/%( | VP/%( | 训练时间/min( |
|---|---|---|---|---|---|---|
| β-VAE[ | 3.93 | 6.31 | 1.06 | 59.07 | 65.92 | 106 |
| DIP-VAE-I[ | 3.12 | 11.15 | 0.93 | 52.82 | 50.60 | 108 |
| LSGAN[ | 5.92 | 2.52 | 1.54 | 43.95 | 71.39 | 374 |
| WGAN[ | 4.46 | 5.41 | 1.26 | 56.65 | 77.15 | 313 |
| SD-VAE[ | 4.13 | 4.59 | 1.50 | 64.60 | 80.71 | 441 |
| LED-VAE[ | 5.22 | 2.31 | 2.24 | 49.79 | 81.34 | 342 |
| SHLED-VAE[ | 5.13 | 3.32 | 1.70 | 46.69 | 83.21 | 288 |
| LFED | 5.26 | 2.34 | 1.84 | 47.58 | 95.67 | 388 |
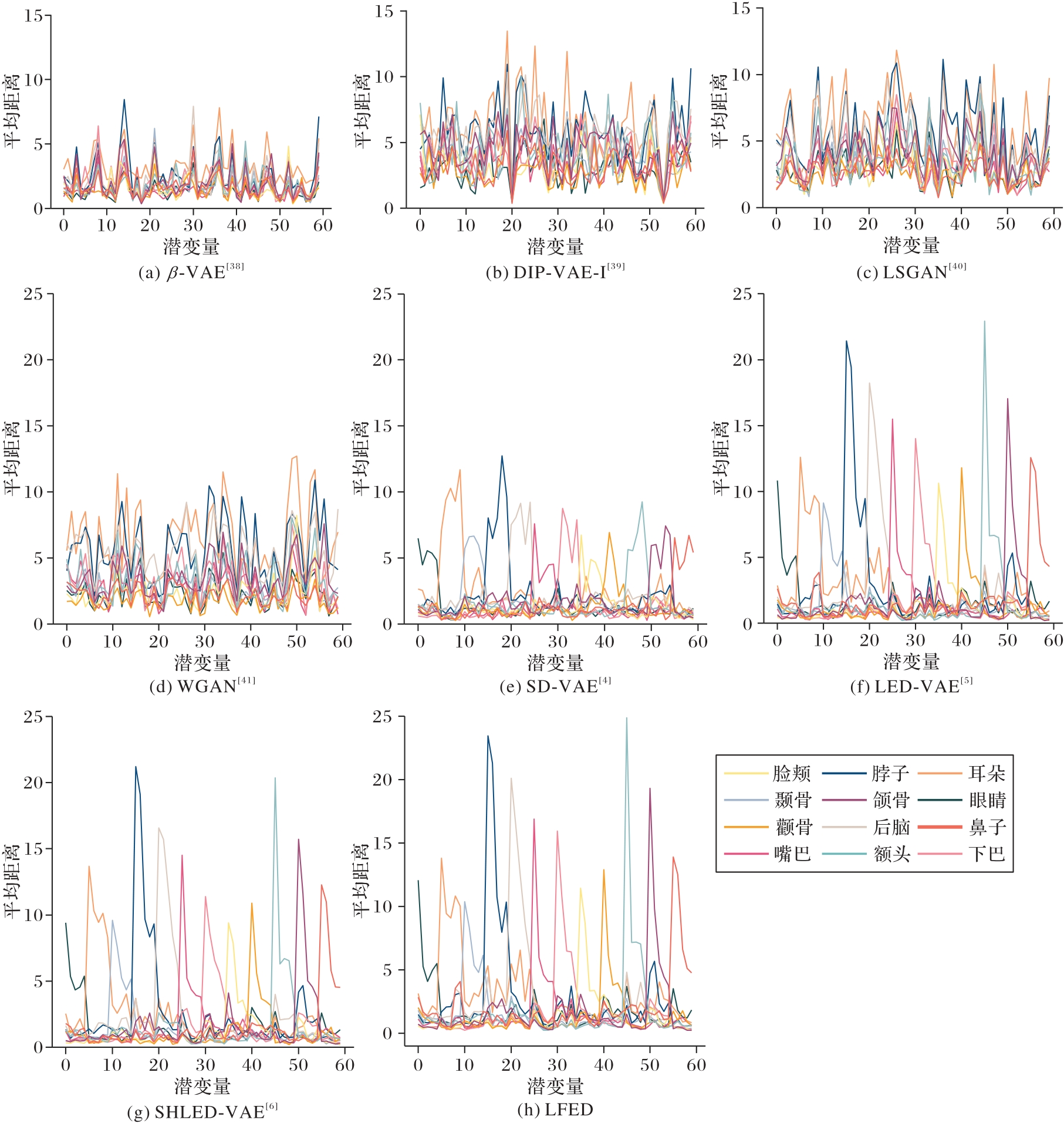
图4 在不同人脸属性上遍历每个潜在特征的效果
Fig. 4 Effects of traversing each latents feature in different facial attributes
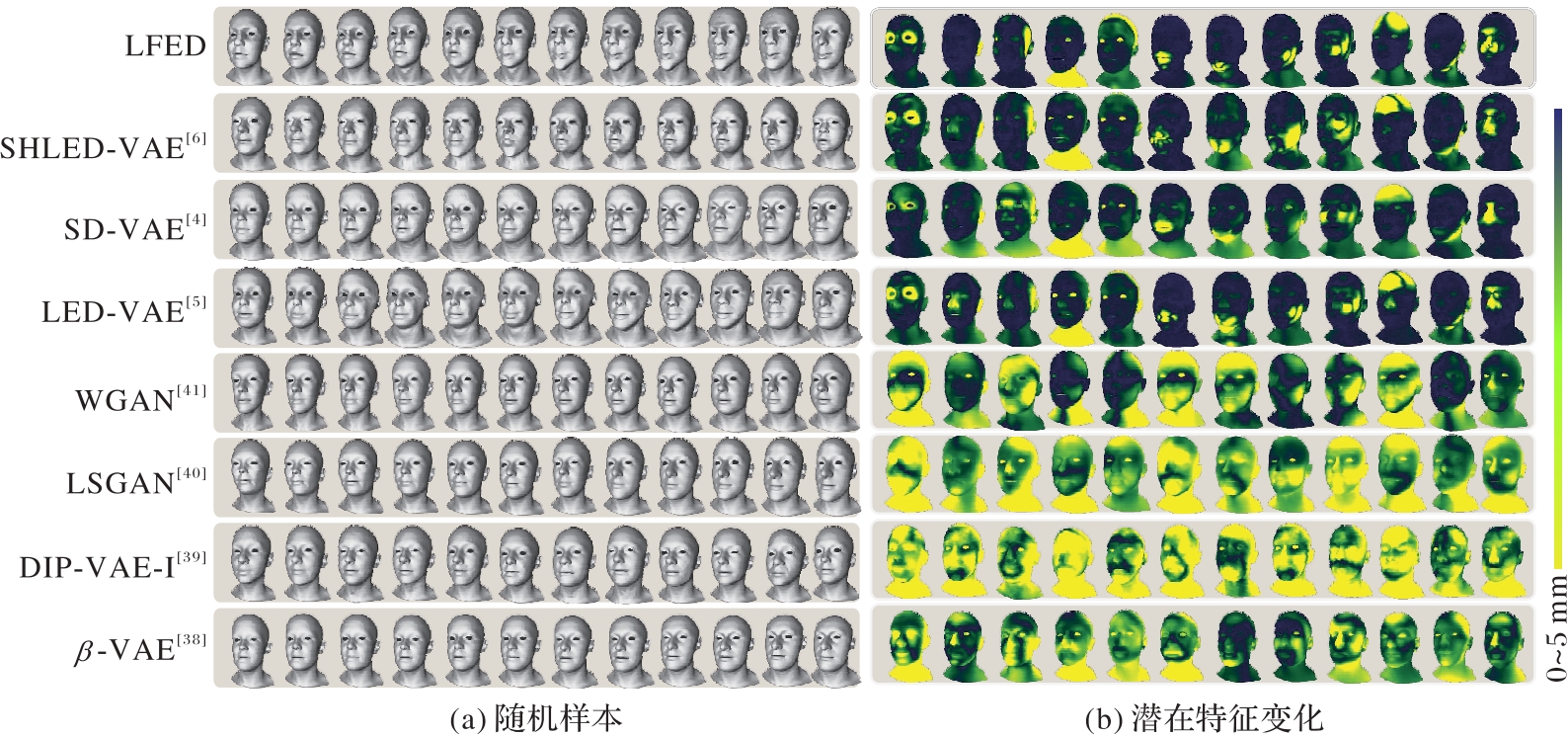
图5 不同方法的潜在特征遍历效果图
Fig. 5 Latent feature traversal effect diagrams of different methods
| 模块 | VP/%( |
|---|---|
| None | 81.34 |
| PA | 84.50 |
| VQ | 83.84 |
| VQ+PA | 90.27 |
| EC | 87.77 |
| VQ+PA+EC | 95.67 |
表4 各个模块在VP指标上的实验结果
Tab. 4 Experimental results of each module in VP metric
| 模块 | VP/%( |
|---|---|
| None | 81.34 |
| PA | 84.50 |
| VQ | 83.84 |
| VQ+PA | 90.27 |
| EC | 87.77 |
| VQ+PA+EC | 95.67 |

图6 各模块对潜在遍历的影响
Fig. 6 Impact of each module on latent traversal
| [1] | SILVA A G DA, MENDES GOMES M V, WINKLER I. Virtual reality and digital human modeling for ergonomic assessment in industrial product development: a patent and literature review [J]. Applied Sciences, 2022, 12(3): No.1084. |
| [2] | HE Q, LI L, LI D, et al. From digital human modeling to human digital twin: framework and perspectives in human factors [J]. Chinese Journal of Mechanical Engineering, 2024, 37(1): No.9. |
| [3] | YANG Y, ZHANG H, FERNÁNDEZ A B, et al. Digitalization of 3-D human bodies: a survey [J]. IEEE Transactions on Consumer Electronics, 2024, 70(1): 3152-3166. |
| [4] | FOTI S, KOO B, STOYANOV D, et al. 3D shape variational autoencoder latent disentanglement via mini-batch feature swapping for bodies and faces [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18709-18718. |
| [5] | FOTI S, KOO B, STOYANOV D, et al. 3D generative model latent disentanglement via local eigenprojection [J]. Computer Graphics Forum, 2023, 42(6): No.e14793. |
| [6] | 赵世杰,梁瑾裕,杜晓飞,等.球谐函数局部特征投影的三维人脸生成方法[J].计算机辅助设计与图形学学报, 2025, 37(3): 385-395. |
| ZHAO S J, LIANG J Y, DU X F, et al. 3D face generation method based on local feature projection of spherical harmonic [J]. Journal of Computer-Aided Design and Computer Graphics, 2025, 37(3): 385-395. | |
| [7] | HUANG Z. New face recognition technologies based on 3DMM [C]// Proceedings of the SPIE 12153, International Conference on Artificial Intelligence, Virtual Reality, and Visualization. Bellingham, WA: SPIE, 2021: No.1215315. |
| [8] | ZHAO Y, CAO X, LIU S, et al. A facial expression transfer method based on 3DMM and diffusion models [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 3145-3149. |
| [9] | ZHANG H, REN Y, CHEN Y, et al. Exploiting multiple guidance from 3DMM for face reenactment [EB/OL]. [2024-04-28]. . |
| [10] | TRAN L, LIU X. Nonlinear 3D face morphable model [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7346-7355. |
| [11] | BOURITSAS G, BOKHNYAK S, PLOUMPIS S, et al. Neural 3D morphable models: spiral convolutional networks for 3D shape representation learning and generation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7212-7221. |
| [12] | BLANZ V, VETTER T. A morphable model for the synthesis of 3D faces [J]. Seminal Graphics Papers: Pushing the Boundaries, 2023, 2: No.18. |
| [13] | WANG X, LU H, LIU X, et al. Dynamic coordination of miscible polymer blends towards highly designable shape memory effect [J]. Polymer, 2020, 208: No.122946. |
| [14] | ALEXA M, COHEN-OR D, LEVIN D. As-rigid-as-possible shape interpolation [C]// Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM, 2000: 157-164. |
| [15] | ONIZUKA H, THOMAS D, UCHIYAMA H, et al. Landmark-guided deformation transfer of template facial expressions for automatic generation of avatar blend-shapes [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop. Piscataway: IEEE, 2019: 2100-2108. |
| [16] | RACKOVIĆ S, SOARES C, JAKOVETIĆ D, et al. Clustering of the blendshape facial model [C]// Proceedings of the 29th European Signal Processing Conference. Piscataway: IEEE, 2021: 1556-1560. |
| [17] | MING X, LI J, LING J, et al. High-quality mesh blendshape generation from face videos via neural inverse rendering [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15128. Cham: Springer, 2025: 106-125. |
| [18] | GECER B, PLOUMPIS S, KOTSIA I, et al. GANFIT: generative adversarial network fitting for high fidelity 3D face reconstruction [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1155-1164. |
| [19] | MOSCHOGLOU S, PLOUMPIS S, NICOLAOU M A, et al. 3DFaceGAN: adversarial nets for 3D face representation, generation, and translation [J]. International Journal of Computer Vision, 2020, 128(10/11): 2534-2551. |
| [20] | LAN Y, MENG X, YANG S, et al. Self-supervised geometry-aware encoder for style-based 3D GAN inversion [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 20940-20949. |
| [21] | LIU Z, LI M, ZHANG Y, et al. Fine-grained face swapping via regional GAN inversion [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 8578-8587. |
| [22] | RAI A, GUPTA H, PANDEY A, et al. Towards realistic generative 3D face models [C]// Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2024: 3726-3736. |
| [23] | SONG X, FENG X, ZHU L, et al. SNP site-drug association prediction algorithm based on denoising variational auto-encoder [J]. Journal of Measurement Science and Instrumentation, 2022, 13(3): 300-308. |
| [24] | KIM S U, ROH J, IM H, et al. Anisotropic SpiralNet for 3D shape completion and denoising [J]. Sensors, 2022, 22(17): No.6457. |
| [25] | DEY R, BODDETI V N. Generating diverse 3D reconstructions from a single occluded face image [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 1537-1547. |
| [26] | ZHANG W, CUNX, WANG X, et al. SadTalker: learning realistic 3D motion coefficients for stylized audio-driven single image talking face animation [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 8652-8661. |
| [27] | TAN Q, ZHANG L X, YANG J, et al. Variational autoencoders for localized mesh deformation component analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10): 6297-6310. |
| [28] | YANG J, MO K, LAI Y K, et al. DSG-Net: learning disentangled structure and geometry for 3D shape generation [J]. ACM Transactions on Graphics, 2023, 42(1): No.1. |
| [29] | LI G, YANG H, HUANG D, et al. 3D face modeling via weakly-supervised disentanglement network joint identity-consistency prior [C]// Proceedings of the IEEE 18th International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE, 2024: 1-10. |
| [30] | GONG S, CHEN L, BRONSTEIN M, et al. Spiralnet++: a fast and highly efficient mesh convolution operator [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2019: 4141-4148. |
| [31] | REDEKOP E, PLEASURE M, WANG Z, et al. Codebook VQ-VAE approach for prostate cancer diagnosis using multiparametric MRI [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2024: 2365-2372. |
| [32] | NAIK, PARVAIZ AHMAD, ZOHREH ESKANDARI. Nonlinear dynamics of a three-dimensional discrete time delay neural network [J]. International Journal of Biomathematics, 2024, 17(6): No.2350057. |
| [33] | FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149. |
| [34] | YU X, TANG L, RAO Y, et al. Point-BERT: pre-training 3D point cloud transformers with masked point modeling [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19291-19300. |
| [35] | PLOUMPIS S, WANG H, PEARS N, et al. Combining 3D morphable models: a large scale face-and-head model [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10926-10935. |
| [36] | ACHLIOPTAS P, DIAMANTI O, MITLIAGKAS I, et al. Learning representations and generative models for 3D point clouds [C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 40-49. |
| [37] | ZHU X, XU C, TAO D. Learning disentangled representations with latent variation predictability [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12355. Cham: Springer, 2020: 684-700. |
| [38] | HIGGINS I, MATTHEY L, PAL A, et al. β-VAE: learning basic visual concepts with a constrained variational framework [EB/OL]. [2024-04-28]. . |
| [39] | KUMAR A, SATTIGERI P, BALAKRISHNAN A. Variational inference of disentangled latent concepts from unlabeled observations [EB/OL]. [2024-04-28]. . |
| [40] | MAO X, LI Q, XIE H, et al. Least squares generative adversarial networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2813-2821. |
| [41] | ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 214-223. |
| [1] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [2] | 曹柠, 温昕, 郝雁嵘, 曹锐. 多域特征融合的轻量化运动想象脑电信号解码神经网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 289-296. |
| [3] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [4] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| [5] | 王芳, 胡静, 张睿, 范文婷. 内容引导下多角度特征融合医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3017-3025. |
| [6] | 梁一鸣, 范菁, 柴汶泽. 基于双向交叉注意力的多尺度特征融合情感分类[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2773-2782. |
| [7] | 林进浩, 罗川, 李天瑞, 陈红梅. 基于跨尺度注意力网络的胸部疾病分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2712-2719. |
| [8] | 颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2537-2545. |
| [9] | 习怡萌, 邓箴, 刘倩, 刘立波. 跨模态信息融合的视频-文本检索[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2448-2456. |
| [10] | 陈亮, 王璇, 雷坤. 复杂场景下跨层多尺度特征融合的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2333-2341. |
| [11] | 王向, 崔倩倩, 张晓明, 王建超, 王震洲, 宋佳霖. 改进ConvNeXt的无线胶囊内镜图像分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2016-2024. |
| [12] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [13] | 孙林嘉, 秦磊, 康美金, 王莹琳. 基于音节类型识别的自动语音分割算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2034-2042. |
| [14] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [15] | 杨雅莉, 黎英, 章育涛, 宋佩华. 面向人脸识别的多模态研究方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1645-1657. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||