


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 3995-4003.DOI: 10.11772/j.issn.1001-9081.2024121866
邓旸1,2, 赵涛3, 孙凯3, 童同1,4, 高钦泉1,4( )
)
收稿日期:2025-01-03
修回日期:2025-03-18
接受日期:2025-03-20
发布日期:2025-04-03
出版日期:2025-12-10
通讯作者:
高钦泉
作者简介:邓旸(1998—),女,福建三明人,硕士研究生,主要研究方向:计算机视觉、图像处理基金资助:
Yang DENG1,2, Tao ZHAO3, Kai SUN3, Tong TONG1,4, Qinquan GAO1,4()
Received:2025-01-03
Revised:2025-03-18
Accepted:2025-03-20
Online:2025-04-03
Published:2025-12-10
Contact:
Qinquan GAO
About author:DENG Yang, born in 1998, M. S. candidate. Her research interests include computer vision, image processing.Supported by:摘要:
实际业务场景中的图像数据通常呈现内容丰富和失真表现复杂的特点,对客观图像质量评价(IQA)算法的泛化是一个巨大挑战。针对这一问题,提出一种无参考IQA(NR-IQA)算法。该算法主要由特征提取网络(FEN)、特征融合网络(FFN)和自适应预测网络(APN)这3个子网络组成。首先,将样本的全局视图、局部patch和显著性视图一并输入FEN,并通过Swim Transformer提取全局失真、局部失真和显著性特征;其次,采用级联的Transformer编码器融合全局失真特征和局部失真特征,并挖掘二者的潜在关联模式;受人类视觉关注机制的启发,在FFN中使用显著性特征激发注意力模块,使该模块对视觉显著性区域施加额外关注,从而提升算法的语义解析能力;最后,通过动态构建的多层感知机(MLP)回归网络计算出预测分数。在主流的合成失真和真实失真数据集上的实验结果表明,所提算法与DSMix(Distortion-induced Sensitivity map-guided Mixed augmentation)算法相比,所提算法在TID2013数据集上的斯皮尔曼秩序相关系数(SRCC)提升了4.3%,在KonIQ数据集上的皮尔森线性相关系数(PLCC)提升了1.4%,并展现出了出色的泛化能力和可解释性,能够有效应对业务场景中失真表现复杂的情况,且可以根据样本个体特征做出适应性预测。
中图分类号:
邓旸, 赵涛, 孙凯, 童同, 高钦泉. 基于显著性特征与交叉注意力的无参考图像质量评价算法[J]. 计算机应用, 2025, 45(12): 3995-4003.
Yang DENG, Tao ZHAO, Kai SUN, Tong TONG, Qinquan GAO. No-reference image quality assessment algorithm based on saliency features and cross-attention mechanism[J]. Journal of Computer Applications, 2025, 45(12): 3995-4003.
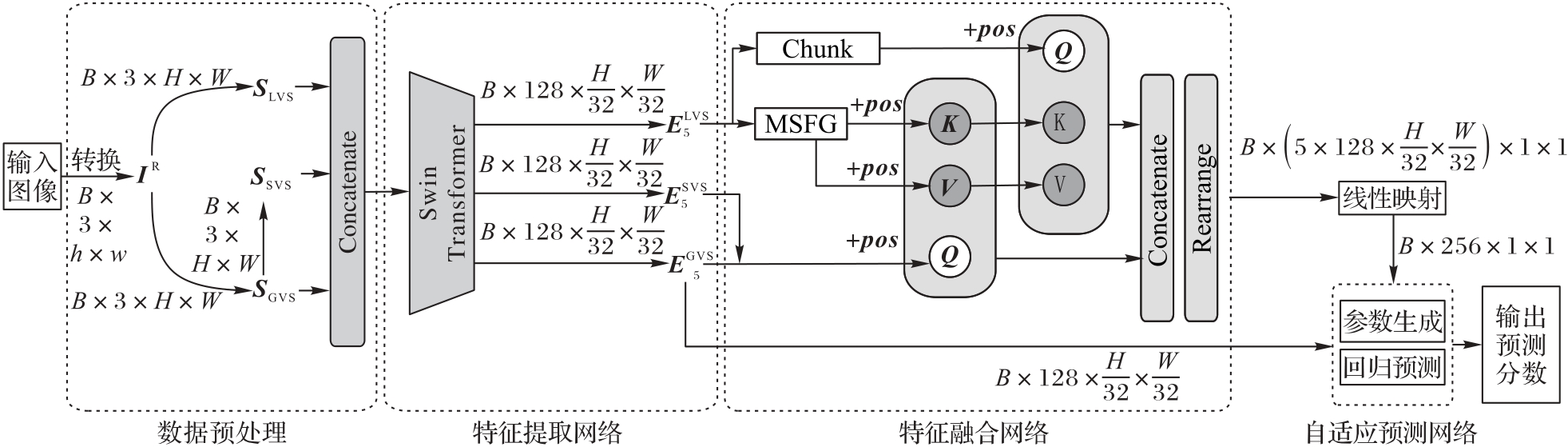
图1 本文算法的总体结构
Fig. 1 Overall architecture of proposed algorithm
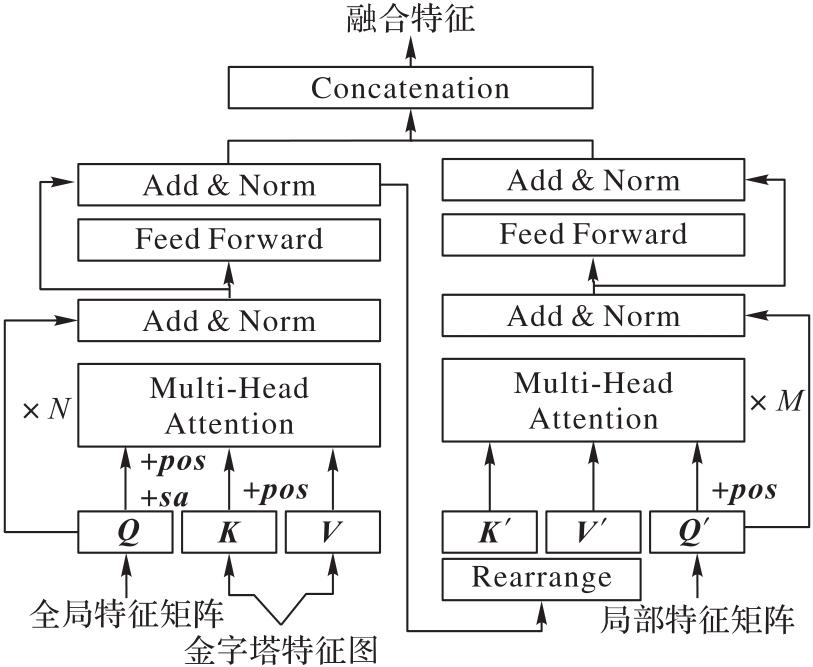
图2 FFN的结构
Fig. 2 Structure of FFN
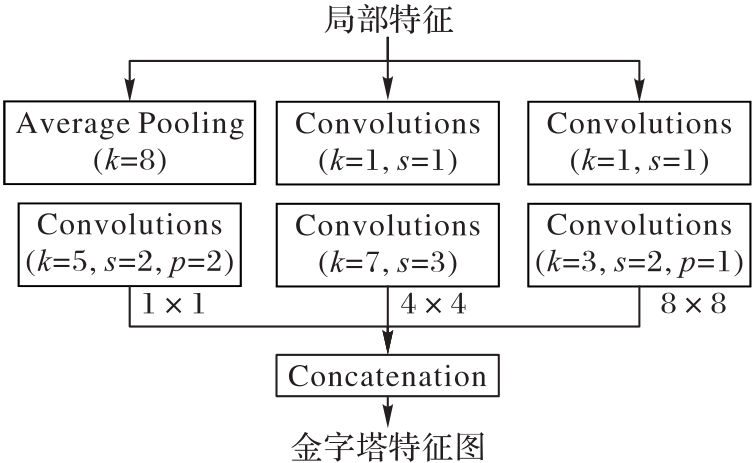
图3 MSFG模块的结构
Fig. 3 Structure of MSFG module
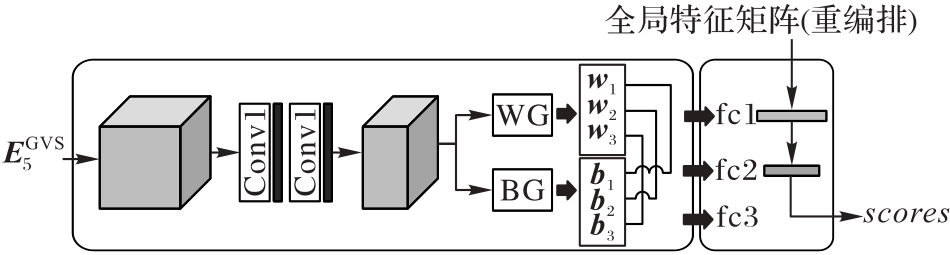
图4 APN的结构
Fig. 4 Structure of APN
| 数据集 | 失真图像数 | 失真类型数 | 失真等级 | 评价方法 | 取值范围 |
|---|---|---|---|---|---|
| LIVE | 799 | 5 | 5~8 | DMOS | [0,100] |
| TID2013 | 3 000 | 24 | 5 | MOS | [0,9] |
| KADID | 10 125 | 25 | 5 | DMOS | [ |
| CLIVE | 1 162 | — | — | MOS | [0,100] |
| KonIQ | 10 073 | — | — | MOS | [ |
| SPAQ | 11 125 | — | — | MOS | [0,100] |
表1 IQA数据集的信息汇总
Tab. 1 Information summary of IQA datasets
| 数据集 | 失真图像数 | 失真类型数 | 失真等级 | 评价方法 | 取值范围 |
|---|---|---|---|---|---|
| LIVE | 799 | 5 | 5~8 | DMOS | [0,100] |
| TID2013 | 3 000 | 24 | 5 | MOS | [0,9] |
| KADID | 10 125 | 25 | 5 | DMOS | [ |
| CLIVE | 1 162 | — | — | MOS | [0,100] |
| KonIQ | 10 073 | — | — | MOS | [ |
| SPAQ | 11 125 | — | — | MOS | [0,100] |
| 算法类型 | 算法 | LIVE | TID2013 | KADID | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.887 | 0.894 | 0.521 | 0.648 | 0.565 | 0.611 |
| BRISQUE | 0.939 | 0.935 | 0.604 | 0.694 | 0.528 | 0.567 | |
| DB-CNN | 0.968 | 0.971 | 0.816 | 0.865 | 0.816 | 0.865 | |
| P2P-BM | 0.959 | 0.958 | 0.862 | 0.856 | 0.840 | 0.849 | |
| MetaIQA | 0.960 | 0.959 | 0.856 | 0.868 | 0.762 | 0.775 | |
| HyperIQA | 0.962 | 0.966 | 0.840 | 0.858 | 0.859 | 0.845 | |
| UNIQUE | 0.969 | 0.968 | — | — | 0.878 | 0.876 | |
| ARNIQA | 0.966 | 0.970 | 0.880 | 0.901 | 0.908 | 0.912 | |
| DSMix | 0.974 | 0.974 | |||||
| 视觉注意驱动 | TRIQ | 0.949 | 0.965 | 0.846 | 0.858 | 0.850 | 0.855 |
| TReS | 0.968 | 0.969 | 0.883 | 0.863 | 0.858 | 0.859 | |
| ADTRS | 0.972 | 0.878 | 0.897 | — | — | ||
| 本文算法 | 0.969 | 0.945 | 0.952 | 0.952 | 0.955 | ||
表2 不同算法在合成失真数据集上的性能比较
Tab. 2 Comparison of performance of different algorithms on synthetic distortion datasets
| 算法类型 | 算法 | LIVE | TID2013 | KADID | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.887 | 0.894 | 0.521 | 0.648 | 0.565 | 0.611 |
| BRISQUE | 0.939 | 0.935 | 0.604 | 0.694 | 0.528 | 0.567 | |
| DB-CNN | 0.968 | 0.971 | 0.816 | 0.865 | 0.816 | 0.865 | |
| P2P-BM | 0.959 | 0.958 | 0.862 | 0.856 | 0.840 | 0.849 | |
| MetaIQA | 0.960 | 0.959 | 0.856 | 0.868 | 0.762 | 0.775 | |
| HyperIQA | 0.962 | 0.966 | 0.840 | 0.858 | 0.859 | 0.845 | |
| UNIQUE | 0.969 | 0.968 | — | — | 0.878 | 0.876 | |
| ARNIQA | 0.966 | 0.970 | 0.880 | 0.901 | 0.908 | 0.912 | |
| DSMix | 0.974 | 0.974 | |||||
| 视觉注意驱动 | TRIQ | 0.949 | 0.965 | 0.846 | 0.858 | 0.850 | 0.855 |
| TReS | 0.968 | 0.969 | 0.883 | 0.863 | 0.858 | 0.859 | |
| ADTRS | 0.972 | 0.878 | 0.897 | — | — | ||
| 本文算法 | 0.969 | 0.945 | 0.952 | 0.952 | 0.955 | ||
| 算法类型 | 算法 | CLIVE | KonIQ | SPAQ | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.469 | 0.518 | 0.507 | 0.523 | 0.713 | 0.721 |
| BRISQUE | 0.608 | 0.629 | 0.665 | 0.681 | 0.809 | 0.817 | |
| DB-CNN | 0.851 | 0.869 | 0.875 | 0.884 | 0.910 | 0.913 | |
| P2P-BM | 0.844 | 0.842 | 0.872 | 0.885 | — | — | |
| MetaIQA | 0.802 | 0.835 | 0.850 | 0.887 | — | — | |
| HyperIQA | 0.859 | 0.882 | 0.906 | 0.917 | 0.911 | 0.915 | |
| UNIQUE | 0.854 | 0.896 | 0.901 | — | — | ||
| ARNIQA | — | — | — | — | 0.905 | 0.910 | |
| DSMix | 0.883 | 0.915 | 0.925 | — | — | ||
| 视觉注意驱动 | TRIQ | 0.845 | 0.861 | 0.892 | 0.903 | — | — |
| TReS | 0.877 | 0.846 | 0.928 | 0.915 | — | — | |
| MUSIQ | — | — | 0.916 | 0.917 | 0.921 | ||
| ADTRS | 0.836 | 0.864 | 0.905 | 0.918 | — | — | |
| 本文算法 | 0.868 | 0.893 | 0.938 | ||||
表3 算法在真实失真数据集上的性能比较
Tab. 3 Comparison of performance of algorithms on real-world distortion datasets
| 算法类型 | 算法 | CLIVE | KonIQ | SPAQ | |||
|---|---|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | SRCC | PLCC | ||
| 数据驱动 | IL-NIQE | 0.469 | 0.518 | 0.507 | 0.523 | 0.713 | 0.721 |
| BRISQUE | 0.608 | 0.629 | 0.665 | 0.681 | 0.809 | 0.817 | |
| DB-CNN | 0.851 | 0.869 | 0.875 | 0.884 | 0.910 | 0.913 | |
| P2P-BM | 0.844 | 0.842 | 0.872 | 0.885 | — | — | |
| MetaIQA | 0.802 | 0.835 | 0.850 | 0.887 | — | — | |
| HyperIQA | 0.859 | 0.882 | 0.906 | 0.917 | 0.911 | 0.915 | |
| UNIQUE | 0.854 | 0.896 | 0.901 | — | — | ||
| ARNIQA | — | — | — | — | 0.905 | 0.910 | |
| DSMix | 0.883 | 0.915 | 0.925 | — | — | ||
| 视觉注意驱动 | TRIQ | 0.845 | 0.861 | 0.892 | 0.903 | — | — |
| TReS | 0.877 | 0.846 | 0.928 | 0.915 | — | — | |
| MUSIQ | — | — | 0.916 | 0.917 | 0.921 | ||
| ADTRS | 0.836 | 0.864 | 0.905 | 0.918 | — | — | |
| 本文算法 | 0.868 | 0.893 | 0.938 | ||||

图5 不同数据集样本的测试结果
Fig. 5 Test results of samples from different datasets
| 数据集 | DBCNN | P2P-BM | HyperIQA | TReS | 本文算法 |
|---|---|---|---|---|---|
| CLIVE | 0.755 | 0.770 | 0.785 | 0.786 | 0.865 |
| SPAQ | 0.783 | 0.730 | 0.807 | 0.848 | 0.890 |
表4 不同数据集上各算法的SRCC对比
Tab.4 Comparison of SRCC for various algorithms on different datasets
| 数据集 | DBCNN | P2P-BM | HyperIQA | TReS | 本文算法 |
|---|---|---|---|---|---|
| CLIVE | 0.755 | 0.770 | 0.785 | 0.786 | 0.865 |
| SPAQ | 0.783 | 0.730 | 0.807 | 0.848 | 0.890 |
| 序号 | 组件 | LIVE | CLIVE | ||
|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | ||
| 1 | Baseline(Swim Transformer) | 0.964 | 0.967 | 0.781 | 0.795 |
| 2 | GVS+Cross Attention | 0.960 | 0.960 | 0.802 | 0.824 |
| 3 | GVS+Cross Attention+ MSFG | 0.968 | 0.966 | 0.841 | 0.865 |
| 4 | GVS+Cross Attention+ MSFG+APN | 0.969 | 0.973 | 0.854 | 0.873 |
| 5 | GVS+Cross Attention(Saliency Embedding)+ MSFG+APN | 0.969 | 0.973 | 0.855 | 0.879 |
表5 消融实验设计与实验结果
Tab. 5 Design and results of ablation experiments
| 序号 | 组件 | LIVE | CLIVE | ||
|---|---|---|---|---|---|
| SRCC | PLCC | SRCC | PLCC | ||
| 1 | Baseline(Swim Transformer) | 0.964 | 0.967 | 0.781 | 0.795 |
| 2 | GVS+Cross Attention | 0.960 | 0.960 | 0.802 | 0.824 |
| 3 | GVS+Cross Attention+ MSFG | 0.968 | 0.966 | 0.841 | 0.865 |
| 4 | GVS+Cross Attention+ MSFG+APN | 0.969 | 0.973 | 0.854 | 0.873 |
| 5 | GVS+Cross Attention(Saliency Embedding)+ MSFG+APN | 0.969 | 0.973 | 0.855 | 0.879 |

图6 注意力矩阵对显著性特征嵌入层的响应情况
Fig. 6 Response of attention matrix to saliency feature embedding layer

图7 注意力在不同JPEG2000压缩失真等级下的分布情况
Fig. 7 Attention distributions under different distortion levels of JPEG2000 compression
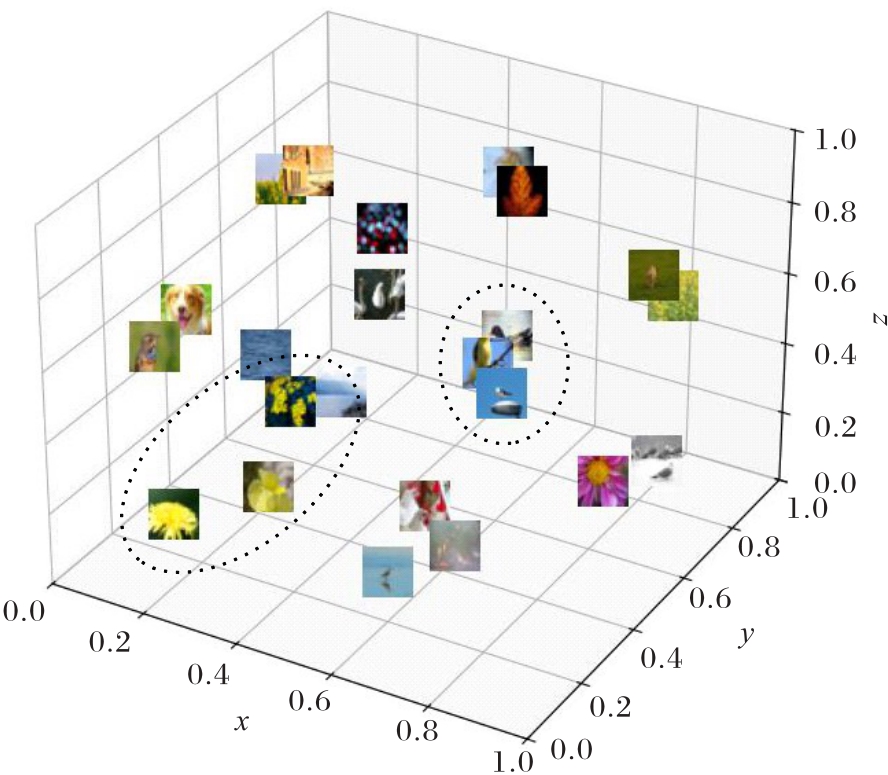
图8 特征向量在3D空间中的分布
Fig. 8 Distribution of feature vectors in 3D space

图9 邻近样本的MOS与预测分数
Fig. 9 MOS and prediction scores of neighboring samples
| [1] | SUN G M, SHI B F, CHEN X D, et al. Learning local quality-aware structures of salient regions for stereoscopic images via deep neural networks[J]. IEEE Transactions on Multimedia, 2020, 22(11): 2938-2949. |
| [2] | CHETOUANI A. Comparative study of saliency- and scanpath-based approaches for patch selection in image quality assessment[C]// Proceedings of the 2023 International Conference on Image Processing. Piscataway: IEEE, 2023: 2670-2674. |
| [3] | ZHANG Y Z, WAN L F, LIU D Y, et al. Saliency-guided no-reference omnidirectional image quality assessment via scene content perceiving[J]. IEEE Transactions on Instrumentation and Measurement, 2024, 73: 1-15. |
| [4] | FENG J, LI S, CHANG Y. Binocular visual mechanism guided no-reference stereoscopic image quality assessment considering spatial saliency[C]// Proceedings of the 2021 International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2021: 1-5. |
| [5] | LI S, ZHAO P, CHANG Y. No-reference stereoscopic image quality assessment based on visual attention mechanism[C]// Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2020: 326-329. |
| [6] | YANG L, XU M, DENG X, et al. Spatial attention-based non-reference perceptual quality prediction network for omnidirectional images[C]// Proceedings of the 2021 International Conference on Multimedia and Expo. Piscataway: IEEE, 2021: 1-6. |
| [7] | YOU J, YAN J. Explore spatial and channel attention in image quality assessment[C]// Proceedings of the 2022 International Conference on Image Processing. Piscataway: IEEE, 2022: 26-30. |
| [8] | KE J, WANG Q, WANG Y, et al. MUSIQ: multi-scale image quality Transformer[C]// Proceedings of the 2021 International Conference on Computer Vision. Piscataway: IEEE, 2021: 5128-5137. |
| [9] | LI H, WANG L, LI Y. Efficient context and saliency aware Transformer network for no-reference image quality assessment[C]// Proceedings of the 2023 International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2023: 1-5. |
| [10] | GOLESTANEH S A, DADSETAN S, KITANI K M. No-reference image quality assessment via Transformers, relative ranking, and self-consistency[C]// Proceedings of the 2022 Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 3989-3999. |
| [11] | ALSAAFIN M, ALSHEIKH M, ANWAR S, et al. Attention down-sampling Transformer, relative ranking and self-consistency for blind image quality assessment[C]// Proceedings of the 2024 International Conference on Image Processing. Piscataway: IEEE, 2024: 1260-1266. |
| [12] | ZHU H, LI L, WU J, et al. MetaIQA: deep meta-learning for no-reference image quality assessment[C]// Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 14131-14140. |
| [13] | SU S, YAN Q, ZHU Y, et al. Blindly assess image quality in the wild guided by a self-adaptive hyper network[C]// Proceedings of the 2020 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3664-3673. |
| [14] | ZHANG W X, MA K, ZHAI G T, et al. Uncertainty-aware blind image quality assessment in the laboratory and wild [J]. IEEE Transactions on Image Processing, 2021, 30: 3474-3486. |
| [15] | SHI J, GAO P, PENG X, et al. DSMix: distortion-induced sensitivity map based pre-training for no-reference image quality assessment [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15128. Cham: Springer, 2025: 1-17. |
| [16] | CHELAZZI L, PERLATO A, SANTANDREA E, et al. Rewards teach visual selective attention[J]. Vision Research, 2013, 85: 58-72. |
| [17] | YOU J, PERKIS A, GABBOUJ M. Improving image quality assessment with modeling visual attention[C]// Proceedings of the 2nd European Workshop on Visual Information Processing. Piscataway: IEEE, 2010: 177-182. |
| [18] | HAREL J, KOCH C, PERONA P. Graph-based visual saliency[C]// Proceedings of the 20th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2006: 545-552. |
| [19] | WASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [20] | 王文冠,沈建冰,贾云得. 视觉注意力检测综述[J]. 软件学报, 2019, 30(2): 416-439. |
| WANG W G, SHEN J B, JIA Y D. Review of visual attention detection[J]. Journal of Software, 2019, 30(2): 416-439. | |
| [21] | CARON M, TOUVRON H, MISRA I, et al. Emerging properties in self-supervised vision Transformers[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9630-9640. |
| [22] | WANG Y, SHEN X, HU S X, et al. Self-supervised Transformers for unsupervised object discovery using normalized cut[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 14523-14533. |
| [23] | SHI J, MALIK J. Normalized cuts and image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888-905. |
| [24] | SHIN G, ALBANIE S, XIE W. Unsupervised salient object detection with spectral cluster voting[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 3970-3979. |
| [25] | SHEIKH H R, SABIR M F, BOVIK A C. A statistical evaluation of recent full reference image quality assessment algorithms[J]. IEEE Transactions on Image Processing, 2006, 15(11): 3440-3451. |
| [26] | PONOMARENKO N, IEREMEIEV O, LUKIN V, et al. Color image database TID2013: peculiarities and preliminary results[C]// Proceedings of the 2013 European Workshop on Visual Information Processing. Piscataway: IEEE, 2013: 106-111. |
| [27] | LIN H, HOSU V, SAUPE D. KADID-10k: a large-scale artificially distorted IQA database[C]// Proceedings of the 11th International Conference on Quality of Multimedia Experience. Piscataway: IEEE, 2019: 1-3. |
| [28] | GHADIYARAM D, BOVIK A C. Massive online crowdsourced study of subjective and objective picture quality[J]. IEEE Transactions on Image Processing, 2016, 25(1): 372-387. |
| [29] | HOSU V, LIN H, SZIRANYI T, et al. KonIQ-10k: an ecologically valid database for deep learning of blind image quality assessment[J]. IEEE Transactions on Image Processing, 2020, 29: 4041-4056. |
| [30] | FANG Y, ZHU H, ZENG Y, et al. Perceptual quality assessment of smartphone photography[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3674-3683. |
| [31] | THOMEE B, SHAMMA D A, FRIEDLAND G, et al. YFCC100M: the new data in multimedia research[J] Communications of the ACM, 2016, 59(2): 64-73. |
| [32] | AGNOLUCCI L, GALTERI L, BERTINI M, et al. ARNIQA: learning distortion manifold for image quality assessment[C]// Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2024: 188-197. |
| [33] | ZHANG L, ZHANG L, BOVIK A C. A feature-enriched completely blind image quality evaluator[J]. IEEE Transactions on Image Processing, 2015, 24(8): 2579-2591. |
| [34] | MITTAL A, MOORTHY A K, BOVIK A C. No-reference image quality assessment in the spatial domain[J]. IEEE Transactions on Image Processing, 2012, 21(12): 4695-4708. |
| [35] | ZHANG W, MA K, YAN J, et al. Blind image quality assessment using a deep bilinear convolutional neural network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(1): 36-47. |
| [36] | YING Z, NIU H, GUPTA P, et al. From patches to pictures (PaQ-2-PiQ): mapping the perceptual space of picture quality[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3572-3582. |
| [37] | YOU J, KORHONEN J. Transformer for image quality assessment[C]// Proceedings of the 2021 IEEE International Conference on Image Processing. Piscataway: IEEE, 2021: 1389-1393. |
| [1] | 王丽芳, 任文婧, 郭晓东, 张荣国, 胡立华. 用于低剂量CT图像降噪的多路特征生成对抗网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 270-279. |
| [2] | 马英杰, 覃晶滢, 赵耿, 肖靖. 面向物联网图像的深度压缩感知网络及其混沌加密保护方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 144-151. |
| [3] | 李亚男, 郭梦阳, 邓国军, 陈允峰, 任建吉, 原永亮. 基于多模态融合特征的并分支发动机寿命预测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 305-313. |
| [4] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [5] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [6] | 王翔, 陈志祥, 毛国君. 融合局部和全局相关性的多变量时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2806-2816. |
| [7] | 吕景刚, 彭绍睿, 高硕, 周金. 复频域注意力和多尺度频域增强驱动的语音增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2957-2965. |
| [8] | 邓伊琳, 余发江. 基于LSTM和可分离自注意力机制的伪随机数生成器[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2893-2901. |
| [9] | 周金, 李玉芝, 张徐, 高硕, 张立, 盛家川. 复杂电磁环境下的调制识别网络[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2672-2682. |
| [10] | 敬超, 全育涛, 陈艳. 基于多层感知机-注意力模型的功耗预测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2646-2655. |
| [11] | 林进浩, 罗川, 李天瑞, 陈红梅. 基于跨尺度注意力网络的胸部疾病分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2712-2719. |
| [12] | 吴海峰, 陶丽青, 程玉胜. 集成特征注意力和残差连接的偏标签回归算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2530-2536. |
| [13] | 梁辰, 王奕森, 魏强, 杜江. 基于Transformer-GCN的源代码漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2296-2303. |
| [14] | 王艺涵, 路翀, 陈忠源. 跨模态文本信息增强的多模态情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2237-2244. |
| [15] | 刘皓宇, 孔鹏伟, 王耀力, 常青. 基于多视角信息的行人检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2325-2332. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||