


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (3): 821-829.DOI: 10.11772/j.issn.1001-9081.2025030384
胡岩1, 李鹏1,2( ), 成姝燕1
), 成姝燕1
收稿日期:2025-04-15
修回日期:2025-06-04
接受日期:2025-06-05
发布日期:2025-07-01
出版日期:2026-03-10
通讯作者:
李鹏
作者简介:胡岩(2001—),男,江苏泰州人,硕士研究生,主要研究方向:深度学习、对抗攻击与防御基金资助:
Yan HU1, Peng LI1,2(), Shuyan CHENG1
Received:2025-04-15
Revised:2025-06-04
Accepted:2025-06-05
Online:2025-07-01
Published:2026-03-10
Contact:
Peng LI
About author:HU Yan, born in 2001, M. S. candidate. His research interests include deep learning, adversarial attack and defense.Supported by:摘要:
深度神经网络(DNN)容易受到对抗扰动的影响,因此攻击者会通过向图像中添加难以察觉的对抗扰动以欺骗DNN。虽然基于扩散模型的对抗净化方法可以使用扩散模型生成干净样本以防御此类攻击,但扩散模型本身也会受到对抗扰动的影响。因此,提出对抗净化方法StraightDiffusion,使用对抗样本直接引导扩散模型的净化过程。首先,探讨现有方法在使用扩散模型进行对抗净化时存在的关键问题与局限性;其次,提出一种新的采样方式在去噪过程中使用两阶段引导方式——头引导和尾引导,即在去噪过程的初期和末期进行引导,其他阶段不使用引导。在CIFAR-10和ImageNet数据集使用3个分类器WideResNet-70-16、WideResNet-28-10和ResNet-50的实验结果表明,StraightDiffusion具有超过基线方法的防御性能,在CIFAR-10和ImageNet数据集上相较于去噪模型用于对抗净化(DiffPure方法)和净化引导扩散模型(GDMP)等方法取得了最好的标准准确率和鲁棒准确率。以上验证了所提方法能够提升净化效果,从而提高分类模型面对对抗样本的鲁棒准确率,实现了多攻击场景下的有效防御。
中图分类号:
胡岩, 李鹏, 成姝燕. 基于直接引导扩散模型的对抗净化方法[J]. 计算机应用, 2026, 46(3): 821-829.
Yan HU, Peng LI, Shuyan CHENG. Adversarial purification method based on directly guided diffusion model[J]. Journal of Computer Applications, 2026, 46(3): 821-829.
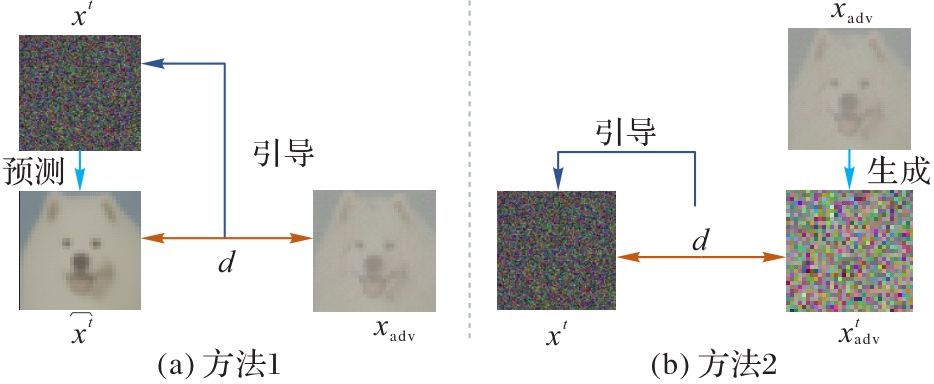
图1 间接引导扩散模型方法的流程
Fig. 1 Flows of methods of indirectly guided diffusion models
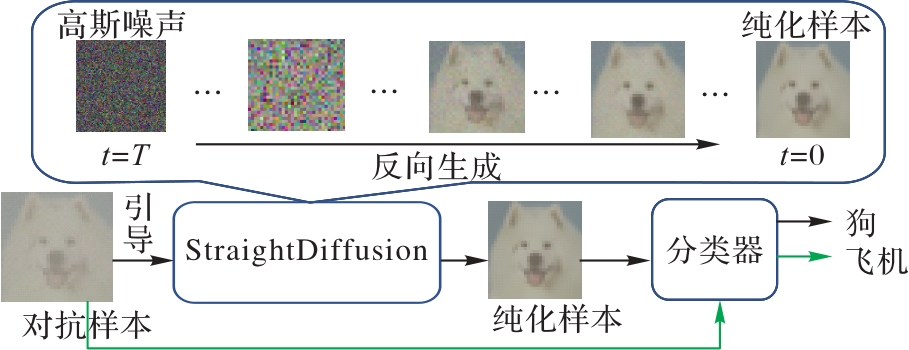
图2 StraightDiffusion的框架
Fig. 2 Framework of StraightDiffusion

图3 直接引导扩散模型方法的流程
Fig. 3 Flow of method of directly guided diffusion model
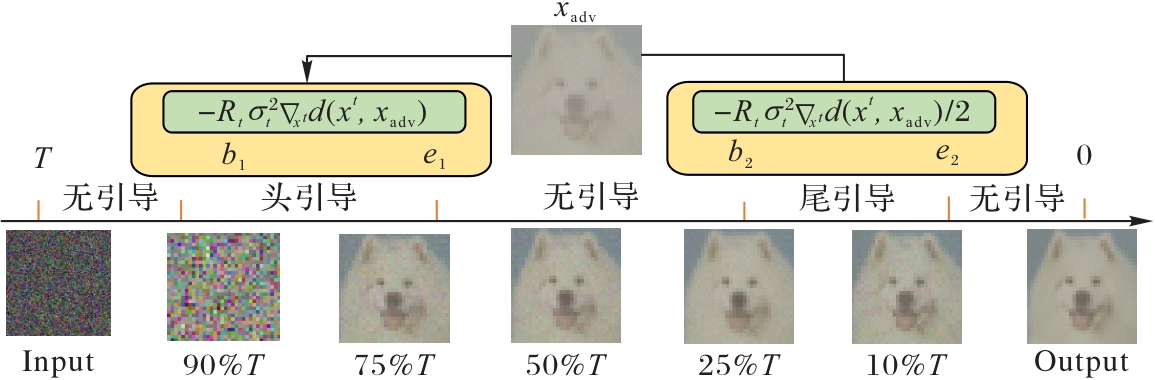
图4 引导区间的设计
Fig. 4 Design of guidance interval
| 分类器 | 防御方法 | 标准准确率 | 鲁棒准确率 | |
|---|---|---|---|---|
| WRN-28-10 | 文献[ | 89.48* | 62.82* | 66.12 |
| 文献[ | 87.33 | 60.77 | 78.69 | |
| DiffPure[ | 90.22 | 62.92 | 81.47 | |
| 文献[ | 92.23 | 90.71 | 91.28 | |
| 文献[ | 90.51 | 71.10 | 85.52 | |
| MimicDiffusion[ | 86.52 | 84.76 | 84.96 | |
| StraightDiffusion | 94.18±0.15 | 93.79±0.40 | 93.87±0.36 | |
| WRN-70-16 | 文献[ | 91.10* | 65.89* | 74.12 |
| 文献[ | 88.54 | 64.54 | 80.00 | |
| DiffPure[ | 90.38 | 66.57 | 82.73 | |
| 文献[ | 86.67 | 60.77 | 80.44 | |
| 文献[ | 91.08 | 71.19 | 85.93 | |
| MimicDiffusion[ | 88.23 | 85.93 | 87.25 | |
| StraightDiffusion | 94.22±0.10 | 93.88±0.20 | 93.94±0.29 | |
表1 在CIFAR-10数据集上针对AutoAttack的标准准确率和鲁棒准确率 (%)
Tab. 1 Standard accuracy and robust accuracy against AutoAttack on CIFAR-10 dataset
| 分类器 | 防御方法 | 标准准确率 | 鲁棒准确率 | |
|---|---|---|---|---|
| WRN-28-10 | 文献[ | 89.48* | 62.82* | 66.12 |
| 文献[ | 87.33 | 60.77 | 78.69 | |
| DiffPure[ | 90.22 | 62.92 | 81.47 | |
| 文献[ | 92.23 | 90.71 | 91.28 | |
| 文献[ | 90.51 | 71.10 | 85.52 | |
| MimicDiffusion[ | 86.52 | 84.76 | 84.96 | |
| StraightDiffusion | 94.18±0.15 | 93.79±0.40 | 93.87±0.36 | |
| WRN-70-16 | 文献[ | 91.10* | 65.89* | 74.12 |
| 文献[ | 88.54 | 64.54 | 80.00 | |
| DiffPure[ | 90.38 | 66.57 | 82.73 | |
| 文献[ | 86.67 | 60.77 | 80.44 | |
| 文献[ | 91.08 | 71.19 | 85.93 | |
| MimicDiffusion[ | 88.23 | 85.93 | 87.25 | |
| StraightDiffusion | 94.22±0.10 | 93.88±0.20 | 93.94±0.29 | |
| 分类器 | 防御方法 | 标准准确率 | 鲁棒准确率 | |
|---|---|---|---|---|
| WRN-28-10 | DiffPure[ | 90.22 | 46.56 | 78.55 |
| 文献[ | 86.67 | 33.49 | 72.60 | |
| 文献[ | 90.51 | 55.83 | 83.65 | |
| AGDM[ | 90.42 | 64.06 | 85.55 | |
| MimicDiffusion[ | 84.37 | 71.68 | 83.20 | |
| StraightDiffusion | 94.18±0.15 | 82.86±0.90 | 91.16±0.16 | |
| WRN-70-16 | DiffPure[ | 90.38 | 51.99 | 84.10 |
| 文献[ | 86.67 | 38.32 | 76.51 | |
| 文献[ | 91.08 | 51.40 | 83.61 | |
| AGDM[ | 90.43 | 66.41 | 85.94 | |
| MimicDiffusion[ | 89.45 | 74.41 | 83.59 | |
| StraightDiffusion | 94.22±0.10 | 85.73±0.47 | 92.24±0.47 | |
表2 在CIFAR-10数据集上针对PGD+EOT的标准准确率和鲁棒准确率 (%)
Tab. 2 Standard accuracy and robust accuracy against PGD+EOT on CIFAR-10 dataset
| 分类器 | 防御方法 | 标准准确率 | 鲁棒准确率 | |
|---|---|---|---|---|
| WRN-28-10 | DiffPure[ | 90.22 | 46.56 | 78.55 |
| 文献[ | 86.67 | 33.49 | 72.60 | |
| 文献[ | 90.51 | 55.83 | 83.65 | |
| AGDM[ | 90.42 | 64.06 | 85.55 | |
| MimicDiffusion[ | 84.37 | 71.68 | 83.20 | |
| StraightDiffusion | 94.18±0.15 | 82.86±0.90 | 91.16±0.16 | |
| WRN-70-16 | DiffPure[ | 90.38 | 51.99 | 84.10 |
| 文献[ | 86.67 | 38.32 | 76.51 | |
| 文献[ | 91.08 | 51.40 | 83.61 | |
| AGDM[ | 90.43 | 66.41 | 85.94 | |
| MimicDiffusion[ | 89.45 | 74.41 | 83.59 | |
| StraightDiffusion | 94.22±0.10 | 85.73±0.47 | 92.24±0.47 | |
| 防御方法 | 标准准确率 | 鲁棒准确率 |
|---|---|---|
| DiffPure[ | 66.23 | 37.71 |
| 文献[ | 63.41 | 35.12 |
| 文献[ | 67.10 | 43.87 |
| MimicDiffusion[ | 66.75 | 63.02 |
| StraightDiffusion | 67.54±1.27 | 66.57±0.81 |
表3 在ImageNet数据集上针对PGD+EOT的标准准确率和鲁棒准确率 (%)
Tab. 3 Standard accuracy and robust accuracy against PGD+EOT on ImageNet dataset
| 防御方法 | 标准准确率 | 鲁棒准确率 |
|---|---|---|
| DiffPure[ | 66.23 | 37.71 |
| 文献[ | 63.41 | 35.12 |
| 文献[ | 67.10 | 43.87 |
| MimicDiffusion[ | 66.75 | 63.02 |
| StraightDiffusion | 67.54±1.27 | 66.57±0.81 |
| 防御方法 | 标准准确率 | 鲁棒准确率 |
|---|---|---|
| DiffPure[ | 90.22 | 81.44 |
| 文献[ | 85.71 | 68.32 |
| 文献[ | 90.87 | 78.09 |
| 文献[ | 90.51 | 89.96 |
| MimicDiffusion[ | 91.36 | 83.69 |
| StraightDiffusion | 94.18±0.15 | 94.62±0.63 |
表4 在CIFAR-10数据集上针对BPDA+EOT的标准准确率和鲁棒准确率 (%)
Tab. 4 Standard accuracy and robust accuracy against BPDA + EOT on CIFAR-10 dataset
| 防御方法 | 标准准确率 | 鲁棒准确率 |
|---|---|---|
| DiffPure[ | 90.22 | 81.44 |
| 文献[ | 85.71 | 68.32 |
| 文献[ | 90.87 | 78.09 |
| 文献[ | 90.51 | 89.96 |
| MimicDiffusion[ | 91.36 | 83.69 |
| StraightDiffusion | 94.18±0.15 | 94.62±0.63 |
| 头引导 | 尾引导 | 尾引导强/弱 | 标准准确率 | 鲁棒准确率 |
|---|---|---|---|---|
| √ | 80.20 | 79.16 | ||
| √ | 弱 | 88.75 | 88.75 | |
| √ | √ | 弱 | 94.72 | 94.72 |
| √ | √ | 强 | 88.67 | 89.45 |
表5 头尾引导的消融实验结果 (%)
Tab. 5 Ablation study results on head and tail guidance
| 头引导 | 尾引导 | 尾引导强/弱 | 标准准确率 | 鲁棒准确率 |
|---|---|---|---|---|
| √ | 80.20 | 79.16 | ||
| √ | 弱 | 88.75 | 88.75 | |
| √ | √ | 弱 | 94.72 | 94.72 |
| √ | √ | 强 | 88.67 | 89.45 |

图5 净化结果的对比
Fig. 5 Comparison of purification results
| 防御方法 | 分类器 | 时间消耗/s |
|---|---|---|
| StraightDiffusion | WRN-70-16 | 764 |
| MimicDiffusion[ | 814 | |
| StraightDiffusion | WRN-28-10 | 716 |
| MimicDiffusion[ | 734 |
表6 净化时间消耗的对比
Tab. 6 Comparison of purification time consumption
| 防御方法 | 分类器 | 时间消耗/s |
|---|---|---|
| StraightDiffusion | WRN-70-16 | 764 |
| MimicDiffusion[ | 814 | |
| StraightDiffusion | WRN-28-10 | 716 |
| MimicDiffusion[ | 734 |
| [1] | HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1026-1034. |
| [2] | ZHANG J, LI C. Adversarial examples: opportunities and challenges [J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(7): 2578-2593. |
| [3] | MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks [EB/OL]. [2025-02-17].. |
| [4] | WONG E, RICE L, KOLTER J Z. Fast is better than free: revisiting adversarial training [EB/OL]. [2025-02-03].. |
| [5] | XIAO C, CHEN Z, JIN K, et al. DensePure: understanding diffusion models towards adversarial robustness [EB/OL]. [2024-11-01].. |
| [6] | YOON J, HWANG S J, LEE J. Adversarial purification with score-based generative models [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 12062-12072. |
| [7] | WU Q, YE H, GU Y. Guided diffusion model for adversarial purification from random noise [EB/OL]. [2024-06-22].. |
| [8] | WANG J, LYU Z, LIN D, et al. Guided diffusion model for adversarial purification [EB/OL]. [2024-05-30].. |
| [9] | BRUNA J, SZEGEDY C, SUTSKEVER I, et al. Intriguing properties of neural networks [EB/OL]. [2025-02-12].. |
| [10] | CARLINI N, WAGNER D. Towards evaluating the robustness of neural networks [C]// Proceedings of the 2017 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2017: 39-57. |
| [11] | GOODFELLOW I J, SHLENS J, SZEGEDY C. Explaining and harnessing adversarial examples [EB/OL]. [2025-02-13].. |
| [12] | HALETA P, LIKHOMANOV D, SOKOL O. Multitask adversarial attack with dispersion amplification [J]. EURASIP Journal on Information Security, 2021, 2021(1): No.10. |
| [13] | WANG X, HE X, WANG J, et al. Admix: enhancing the transferability of adversarial attacks [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 16138-16147. |
| [14] | REBUFFI S, GOWAL S, CALIAN D A, et al. Fixing data augmentation to improve adversarial robustness [EB/OL]. [2024-10-18].. |
| [15] | QIN C, MARTENS J, GOWAL S, et al. Adversarial robustness through local linearization [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13842-13853. |
| [16] | CAI Q, LIU C, SONG D. Curriculum adversarial training [EB/OL]. [2024-05-13].. |
| [17] | ZHANG J, XU X, HAN B, et al. Attacks which do not kill training make adversarial learning stronger [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 11278-11287. |
| [18] | LIN G, LI C, ZHANG J, et al. Adversarial Training on Purification (AToP): advancing both robustness and generalization[EB/OL]. [2025-02-09].. |
| [19] | NIE W, GUO B, HUANG Y, et al. Diffusion models for adversarial purification [C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 16805-16827. |
| [20] | SINGH H, SUBRAMANYAM A V. Language guided adversarial purification [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 7685-7689. |
| [21] | YANG Z, XU Z, ZHANG J, et al. Adversarial purification with the manifold hypothesis [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 16379-16387. |
| [22] | SONG K, LAI H, PAN Y, et al. MimicDiffusion: purifying adversarial perturbation via mimicking clean diffusion model [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 24665-24674. |
| [23] | LEE M, KIM D. Robust evaluation of diffusion-based adversarial purification [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 134-144. |
| [24] | SONG Y, SOHL-DICKSTEIN J, KINGMA D P, et al. Score-based generative modeling through stochastic differential equations[EB/OL]. [2025-02-15].. |
| [25] | KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2025-02-05].. |
| [26] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks [J]. Communications of the ACM, 2020, 63(11): 139-144. |
| [27] | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 6840-6851. |
| [28] | SONG J, MENG C, ERMON S. Denoising diffusion implicit model[EB/OL]. [2025-03-17].. |
| [29] | YU J, WANG Y, ZHAO C, et al. FreeDoM: training-free energy-guided conditional diffusion model [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 23117-23127. |
| [30] | CHUNG H, KIM J, MCCANN M T, et al. Diffusion posterior sampling for general noisy inverse problems [EB/OL]. [2025-01-17].. |
| [31] | ENGSTROM L, ILYAS A, SANTURKAR S, et al. Adversarial Robustness as a prior for learned representations [EB/OL]. [2024-09-27].. |
| [32] | GOWAL S, QIN C, UESATO J, et al. Uncovering the limits of adversarial training against norm-bounded adversarial examples[EB/OL]. [2025-03-30].. |
| [33] | LIN G, TAO Z, ZHANG J, et al. Robust diffusion models for adversarial purification [EB/OL]. [2024-03-24].. |
| [34] | CROCE F, HEIN M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 2206-2216. |
| [1] | 马凯光, 陈学斌, 菅银龙, 王柳, 高远. 基于混合序列模型与联邦类平衡算法的网络入侵检测[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 857-866. |
| [2] | 王日龙, 李振平, 李晓松, 高强, 何亚, 钟勇, 赵英潇. 多Agent协作的知识推理框架[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 708-714. |
| [3] | 陈敏, 秦小林, 李绍涵, 杨昊, 李韬弘. 深度学习应用于强对流天气预测的综述[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 980-992. |
| [4] | 姜勇维, 陈晓清, 付麟杰. 基于频谱分解的高频保持医学图像弹性配准模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 924-932. |
| [5] | 邵培荣, 蔺素珍, 王彦博. 以人为中心的细节增强虚拟试衣方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 915-923. |
| [6] | 陈荟慧, 孙洪韬, 关柏良, 衡中青. 基于NetVLAD特征编码的古籍汉字图像检索算法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 750-757. |
| [7] | 张四中, 刘建阳, 李林峰. 基于X3D的轨迹引导感知学习的动作质量评估模型[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 555-563. |
| [8] | 吴俊锐, 杨江川, 喻海生, 邹赛, 汪文勇. 基于复增强注意力机制图神经网络的确定性网络性能评估方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 505-517. |
| [9] | 熊前龙, 秦进. 混合启发信息指导神经网络架构搜索算法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 395-405. |
| [10] | 姜皓骞, 张东, 李冠宇, 陈恒. 基于结构增强的层次化任务导向提示策略的对话推荐系统SetaCRS[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 368-377. |
| [11] | 付锦程, 杨仕友. 基于贝叶斯优化和特征融合混合模型的短期风电功率预测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 652-658. |
| [12] | 林金娇, 张灿舜, 陈淑娅, 王天鑫, 连剑, 徐庸辉. 基于改进图注意力网络的车险欺诈检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 437-444. |
| [13] | 文洪建, 胡瑞娇, 吴保文, 孙家兴, 李环, 张晴, 刘杰. 基于图神经网络实现多尺度特征联合学习的中文作文自动评分[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 378-385. |
| [14] | 徐千惠, 钮可, 朱顺哲, 石林, 李军. 增强型可逆神经网络视频隐写网络GAB3D-SEVSN[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 467-474. |
| [15] | 边小勇, 袁培洋, 胡其仁. 双编码空频混合的红外小目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 252-259. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||