


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1218-1226.DOI: 10.11772/j.issn.1001-9081.2025050535
• 先进计算 • 上一篇
麦超云, 柯晓鹏, 钟东洲( ), 洪晓纯, 陈潘荣, 苏志远
), 洪晓纯, 陈潘荣, 苏志远
收稿日期:2025-05-14
修回日期:2025-09-16
接受日期:2025-09-29
发布日期:2025-10-16
出版日期:2026-04-10
通讯作者:
钟东洲
作者简介:麦超云(1989—),男,广东江门人,副教授,博士,CCF会员,主要研究方向:智能信息处理、数字信号处理基金资助:
Chaoyun MAI, Xiaopeng KE, Dongzhou ZHONG(), Xiaochun HONG, Panrong CHEN, Zhiyuan SU
Received:2025-05-14
Revised:2025-09-16
Accepted:2025-09-29
Online:2025-10-16
Published:2026-04-10
Contact:
Dongzhou ZHONG
About author:MAI Chaoyun, born in 1989, Ph. D., associate professor. His research interests include intelligent information processing, digital signal processing.Supported by:摘要:
针对对称正定矩阵分解算法在现场可编程门阵列(FPGA)上实现时常面临资源消耗大、计算精度与效率难以兼顾等问题,提出一种基于混合精度策略的LDLT分解加速结构。该结构在存储层面采用半精度数降低资源消耗,在计算层面使用单精度数保障计算精度与数值稳定性。此外,构建多处理单元的并行流水结构,并引入双仲裁机制,以优化数据调度与内存访问过程。加速结构则部署于xczu4ev-sfvc784 FPGA平台上,并在4PE、8PE和16PE这3种并行配置下对4~256阶的对称正定矩阵进行实验。结果显示,所提结构的矩阵分解的计算结果相对误差均在
中图分类号:
麦超云, 柯晓鹏, 钟东洲, 洪晓纯, 陈潘荣, 苏志远. 基于混合精度策略的LDLT矩阵分解FPGA加速器设计[J]. 计算机应用, 2026, 46(4): 1218-1226.
Chaoyun MAI, Xiaopeng KE, Dongzhou ZHONG, Xiaochun HONG, Panrong CHEN, Zhiyuan SU. Design of LDLT matrix decomposition FPGA accelerator based on mixed precision strategy[J]. Journal of Computer Applications, 2026, 46(4): 1218-1226.
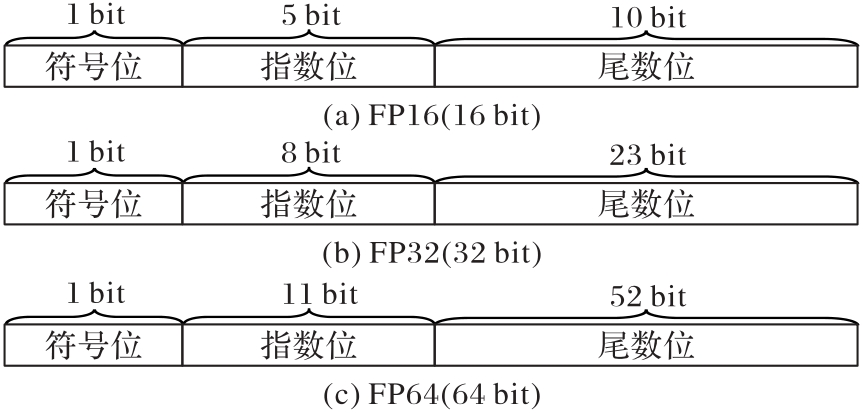
图1 IEEE754标准下的浮点数表示格式
Fig. 1 IEEE754 standard’s floating-point number representation format
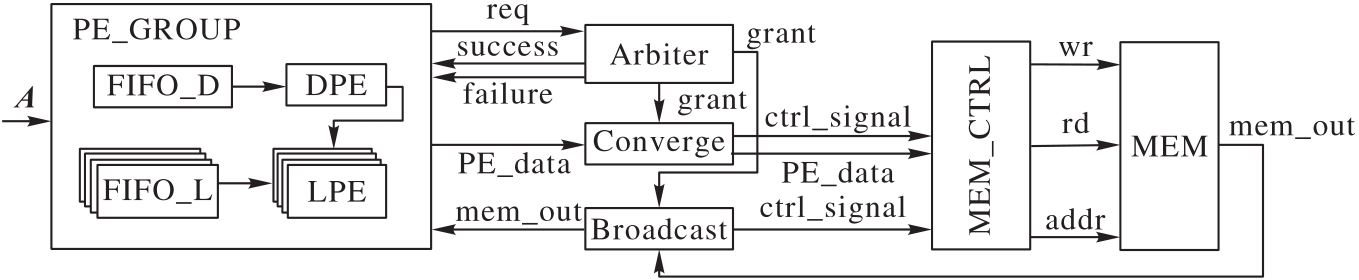
图2 LDLT分解硬件的整体框架
Fig. 2 Overall framework of LDLT decomposition hardware
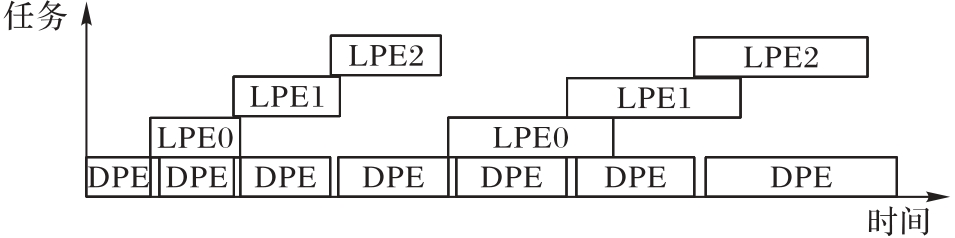
图3 LDLT分解的任务?时间图
Fig. 3 Task-time diagram of LDLT decomposition
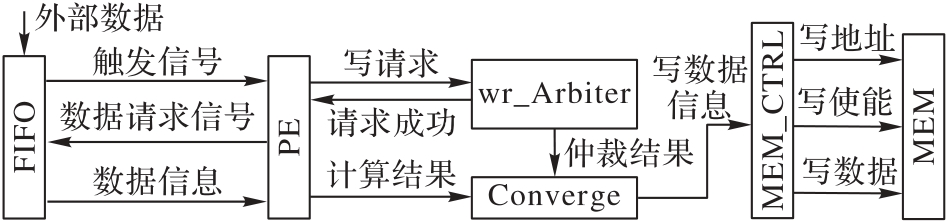
图4 写过程的仲裁机制
Fig. 4 Arbitration mechanism of write process
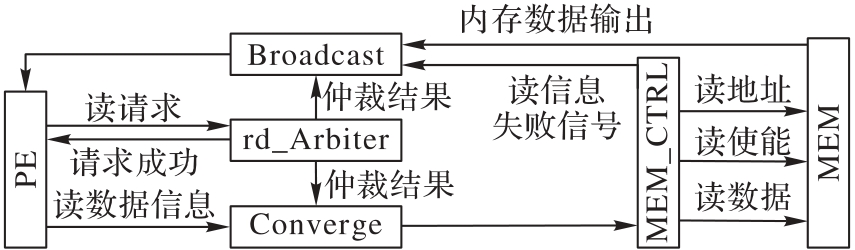
图5 读过程仲裁机制
Fig. 5 Arbitration mechanism of read process
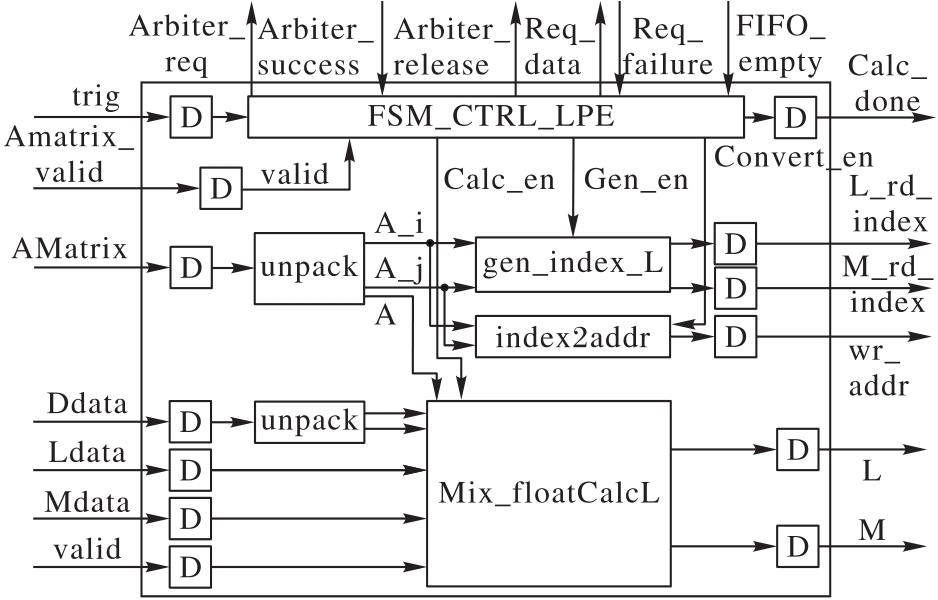
图6 LPE内部结构
Fig. 6 LPE internal structure
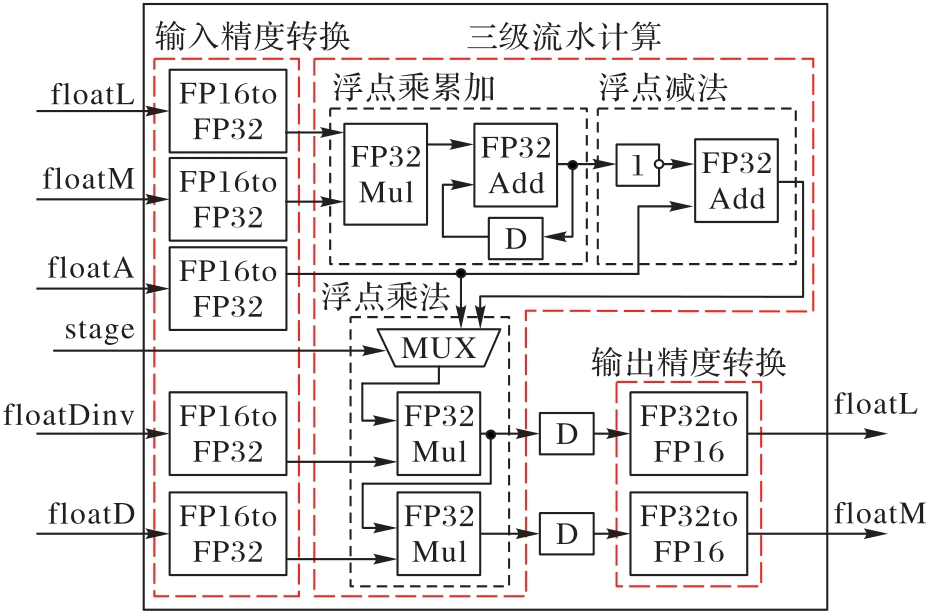
图7 用于LPE的混合精度计算单元
Fig. 7 Mixed precision computing units used for LPE
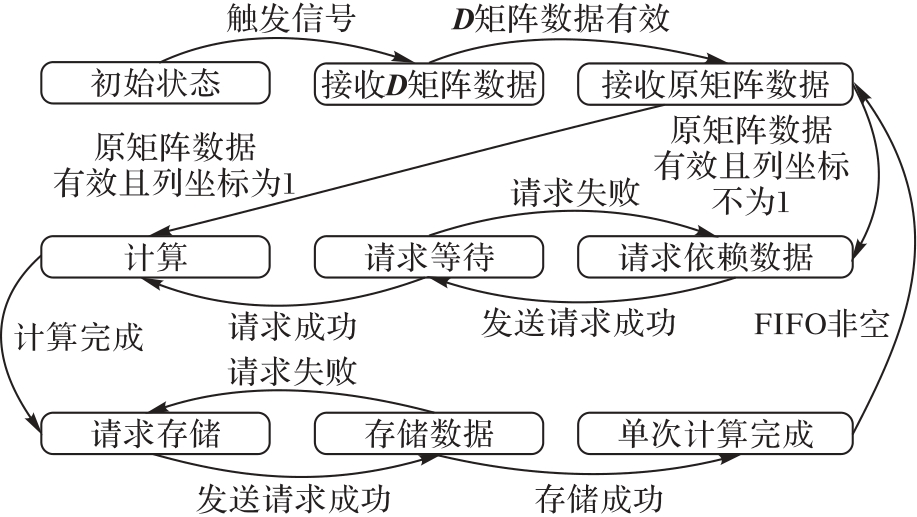
图8 LPE工作流程
Fig. 8 LPE workflow
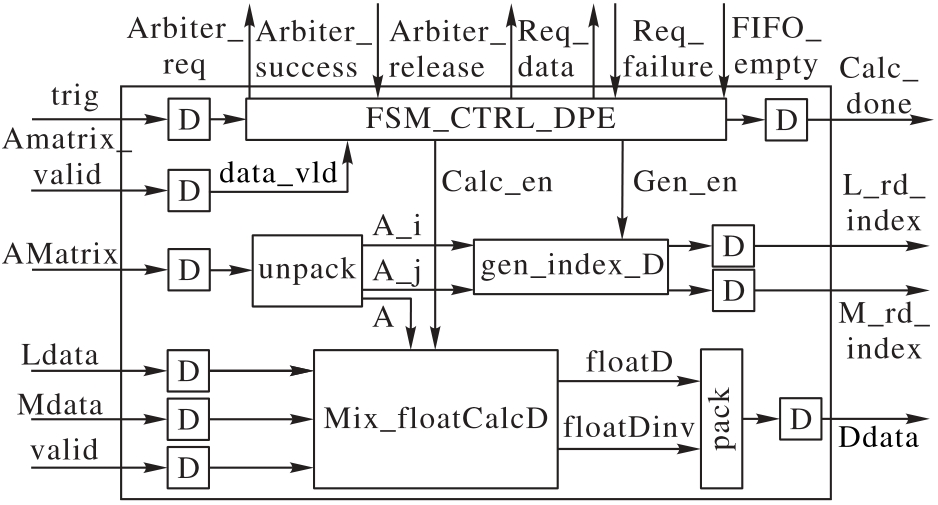
图9 DPE内部结构
Fig. 9 DPE internal structure
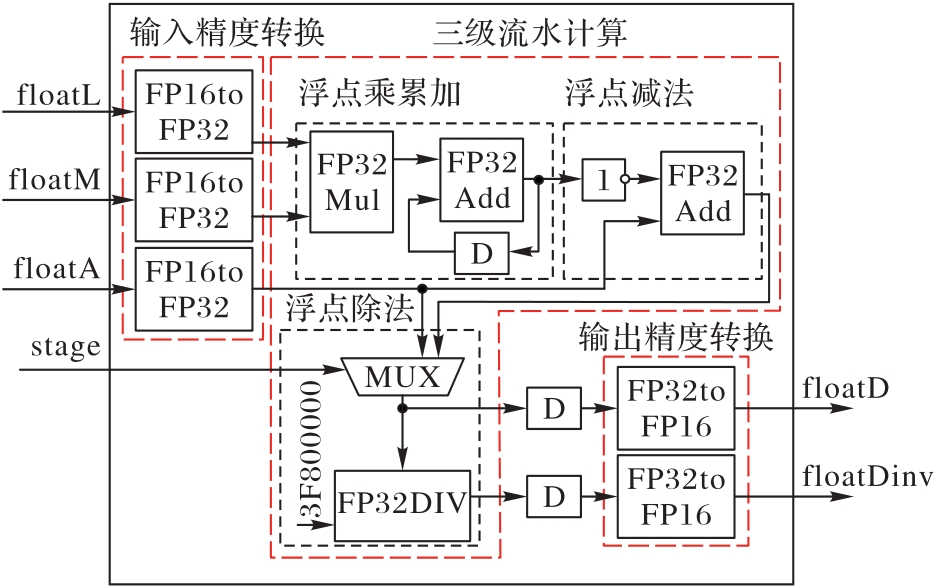
图10 用于DPE的混合精度计算单元
Fig. 10 Mixed precision computing units used for DPE
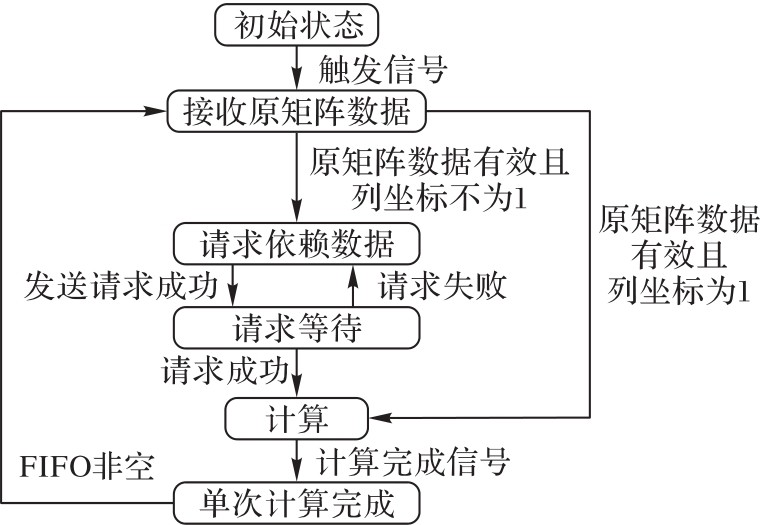
图11 DPE工作流程
Fig. 11 DPE workflow
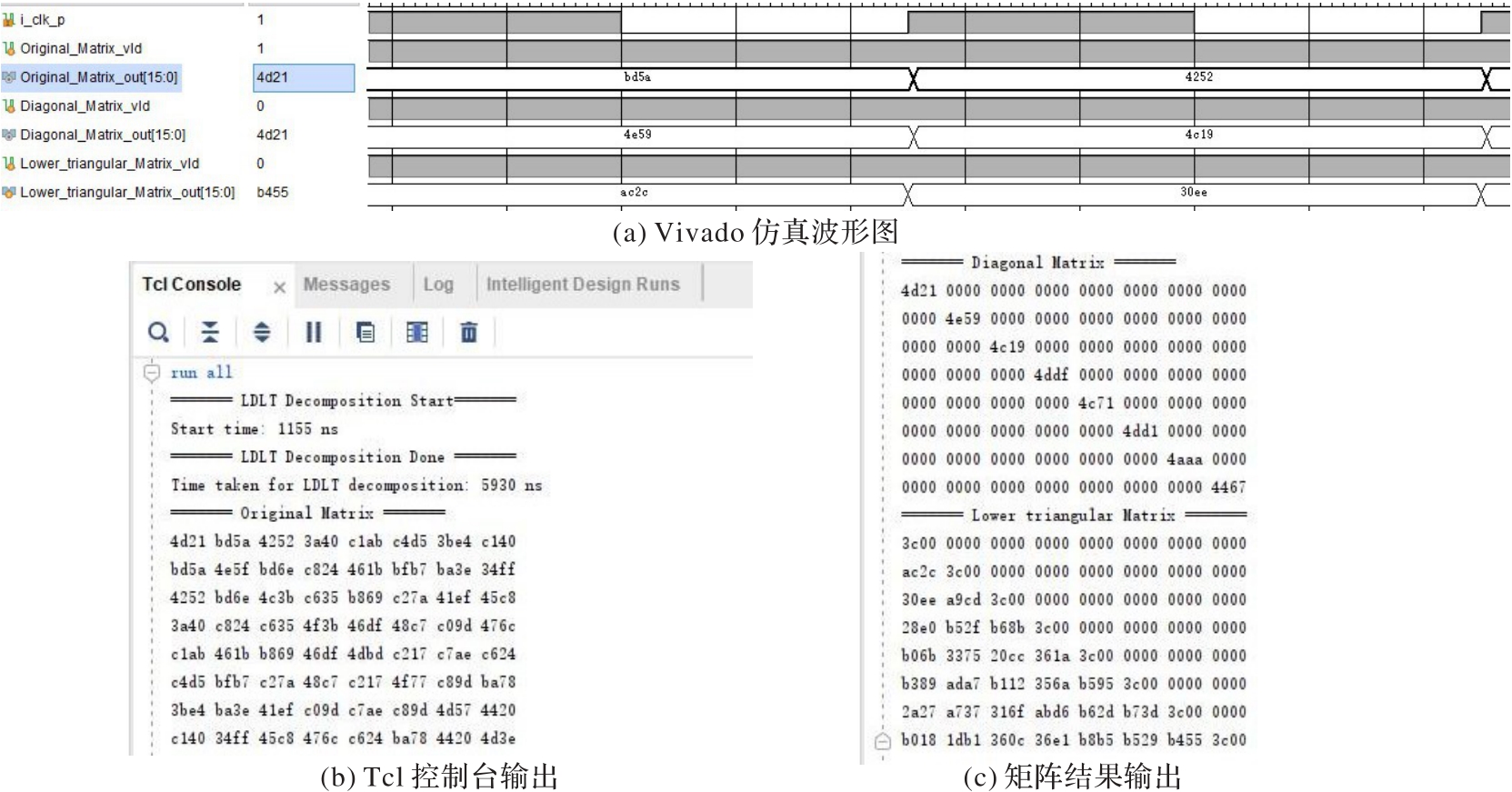
图12 FPGA仿真测试结果
Fig. 12 FPGA simulation test results
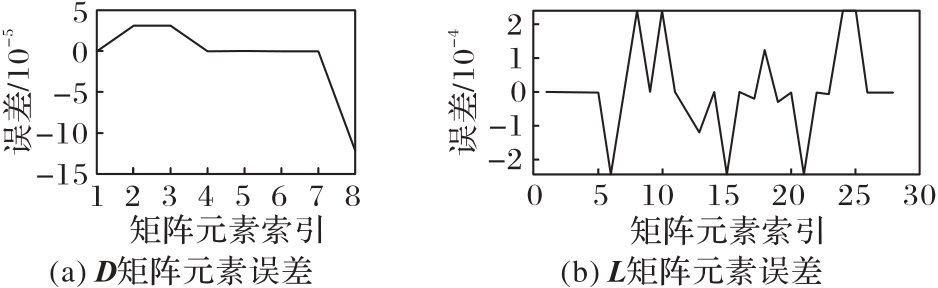
图13 矩阵元素的误差结果对比
Fig. 13 Comparison of error results of matrix elements
| 矩阵阶数 | PE数 | 相对误差/% | 相对误差/% | 计算时间/ms |
|---|---|---|---|---|
| 4 | 4 | 0.010 7 | 0.011 5 | 0.001 65 |
| 8 | 0.001 65 | |||
| 16 | 0.001 65 | |||
| 8 | 4 | 0.043 1 | 0.077 6 | 0.005 93 |
| 8 | 0.006 02 | |||
| 16 | 0.006 02 | |||
| 16 | 4 | 0.032 8 | 0.042 5 | 0.030 84 |
| 8 | 0.030 84 | |||
| 16 | 0.029 11 | |||
| 32 | 4 | 0.061 7 | 0.094 5 | 0.173 64 |
| 8 | 0.171 51 | |||
| 16 | 0.171 51 | |||
| 64 | 4 | 0.037 3 | 0.065 2 | 1.133 69 |
| 8 | 1.125 79 | |||
| 16 | 1.121 28 | |||
| 128 | 4 | 0.032 3 | 0.042 2 | 8.522 45 |
| 8 | 8.147 79 | |||
| 16 | 7.975 71 | |||
| 256 | 4 | 0.031 7 | 0.057 0 | 68.473 25 |
| 8 | 62.784 58 | |||
| 16 | 59.879 47 |
表1 不同PE配置下的测试结果
Tab. 1 Test results under different PE configurations
| 矩阵阶数 | PE数 | 相对误差/% | 相对误差/% | 计算时间/ms |
|---|---|---|---|---|
| 4 | 4 | 0.010 7 | 0.011 5 | 0.001 65 |
| 8 | 0.001 65 | |||
| 16 | 0.001 65 | |||
| 8 | 4 | 0.043 1 | 0.077 6 | 0.005 93 |
| 8 | 0.006 02 | |||
| 16 | 0.006 02 | |||
| 16 | 4 | 0.032 8 | 0.042 5 | 0.030 84 |
| 8 | 0.030 84 | |||
| 16 | 0.029 11 | |||
| 32 | 4 | 0.061 7 | 0.094 5 | 0.173 64 |
| 8 | 0.171 51 | |||
| 16 | 0.171 51 | |||
| 64 | 4 | 0.037 3 | 0.065 2 | 1.133 69 |
| 8 | 1.125 79 | |||
| 16 | 1.121 28 | |||
| 128 | 4 | 0.032 3 | 0.042 2 | 8.522 45 |
| 8 | 8.147 79 | |||
| 16 | 7.975 71 | |||
| 256 | 4 | 0.031 7 | 0.057 0 | 68.473 25 |
| 8 | 62.784 58 | |||
| 16 | 59.879 47 |
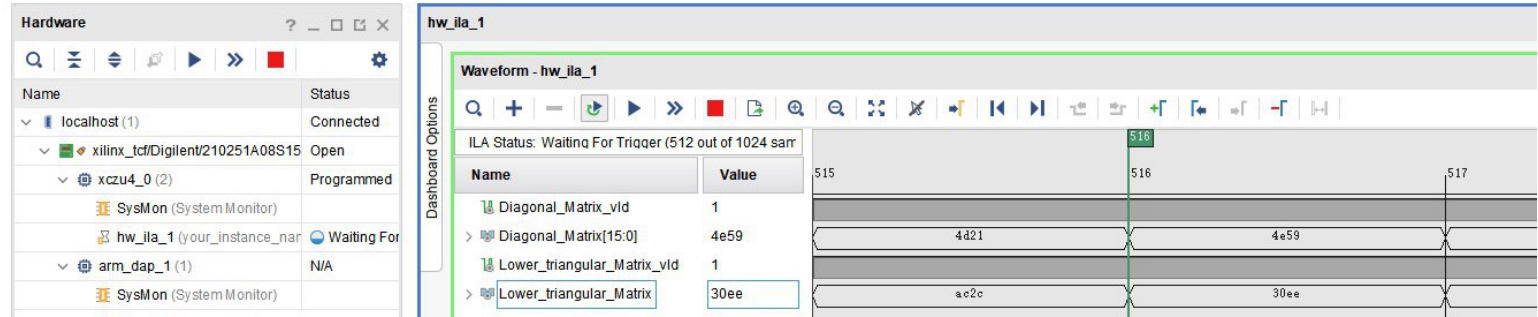
图14 ILA板级调试窗口
Fig. 14 ILA board level debug window
| 方法 | LUTs | FF | BRAM | DSP | Frequency/MHz | WNS/ns | Throughput | |
|---|---|---|---|---|---|---|---|---|
| 文献[ | 59 055 | 134 878 | 189 | 1 530 | 250 | 0.044 | 52.60 | |
| 文献[ | 65 158 | 95 717 | 16 | 411 | 700 | — | — | |
| 文献[ | 36 402 | — | 128 | 116 | 200 | — | 105.20 | |
| 本文方法 | 4PE | 11 654 | 9 261 | 6 | 36 | 100 | 0.853 | 117.34 |
| 8PE | 19 671 | 11 763 | 8 | 64 | 100 | 0.703 | 122.73 | |
| 16PE | 35 509 | 16 782 | 12 | 120 | 100 | 1.031 | 125.38 | |
表2 FPGA硬件资源消耗及效率对比
Tab. 2 Comparison of FPGA hardware resource consumption and efficiency
| 方法 | LUTs | FF | BRAM | DSP | Frequency/MHz | WNS/ns | Throughput | |
|---|---|---|---|---|---|---|---|---|
| 文献[ | 59 055 | 134 878 | 189 | 1 530 | 250 | 0.044 | 52.60 | |
| 文献[ | 65 158 | 95 717 | 16 | 411 | 700 | — | — | |
| 文献[ | 36 402 | — | 128 | 116 | 200 | — | 105.20 | |
| 本文方法 | 4PE | 11 654 | 9 261 | 6 | 36 | 100 | 0.853 | 117.34 |
| 8PE | 19 671 | 11 763 | 8 | 64 | 100 | 0.703 | 122.73 | |
| 16PE | 35 509 | 16 782 | 12 | 120 | 100 | 1.031 | 125.38 | |
| [1] | 冯达,周福才,吴淇毓,等. 基于LU分解的安全外包求解线性代数方程组方法[J]. 东北大学学报(自然科学版), 2024, 45(4): 457-463, 506. |
| FENG D, ZHOU F C, WU Q Y, et al. Secure outsourcing method for solving linear algebraic equations based on LU decomposition[J]. Journal of Northeastern University (Natural Science), 2024, 45(4): 457-463, 506. | |
| [2] | 笪涵,胡圣波. 基于Cholesky矩阵分解的贝叶斯压缩感知信号处理[J]. 贵州师范大学学报(自然科学版), 2021, 39(1): 72-76. |
| DA H, HU S B. Bayesian compressed sensing signal processing based on Cholesky matrix decomposition[J]. Journal of Guizhou Normal University (Natural Sciences), 2021, 39(1): 72-76. | |
| [3] | 鲍长春,白志刚. 基于非负矩阵分解的语音增强方法综述[J]. 信号处理, 2020, 36(6): 791-803. |
| BAO C C, BAI Z G. Speech enhancement based on nonnegative matrix factorization: an overview[J]. Journal of Signal Processing, 2020, 36(6): 791-803. | |
| [4] | 史加荣,李金红. 新型深度矩阵分解及其在推荐系统中的应用[J]. 西安电子科技大学学报, 2022, 49(3): 171-182. |
| SHI J R, LI J H. Novel deep matrix factorization and its application in the recommendation system[J]. Journal of Xidian University, 2022, 49(3): 171-182. | |
| [5] | DU K L, SWAMY M N S, WANG Z Q, et al. Matrix factorization techniques in machine learning, signal processing, and statistics[J]. Mathematics, 2023, 11(12): No.2674. |
| [6] | YANG B. Application of matrix decomposition in machine learning[C]// Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology. Piscataway: IEEE, 2021: 133-137. |
| [7] | 杨羽彤,易琦,孙正宝,等. 矩阵分解方法应用研究进展[J]. 云南大学学报(自然科学版), 2025, 47(4): 635-647. |
| YANG Y T, YI Q, SUN Z B, et al. Review of matrix decomposition methods application[J]. Journal of Yunnan University (Natural Sciences Edition), 2025, 47(4): 635-647. | |
| [8] | 杨露,张得礼,王苑,等. 基于FPGA的阵列雷达矩阵算法研究[J]. 现代雷达, 2023, 45(7): 1-8. |
| YANG L, ZHANG D L, WANG Y, et al. A study on array radar matrix algorithm based on FPGA[J]. Modern Radar, 2023, 45(7): 1-8. | |
| [9] | JAISWAL M K, CHANDRACHOODAN N. FPGA-based high-performance and scalable block LU decomposition architecture[J]. IEEE Transactions on Computers, 2012, 61(1): 60-72. |
| [10] | YEN P T, THANH T M, MINH N H. Novel blind colour image watermarking technique using Cholesky decomposition[C]// Proceedings of the 1st International Conference on Cryptography and Information Security. Piscataway: IEEE, 2024: 1-6. |
| [11] | OSINSKY A, BYCHKOV R, TREFILOV M, et al. Regularization for Cholesky decomposition in massive MIMO detection[J]. IEEE Wireless Communications Letters, 2023, 12(9): 1603-1607. |
| [12] | ALI M, CHOUDHARY J. Investigation of neural network parameters for MNIST using QR decomposition algorithm and principal component analysis[C]// Proceedings of the 2nd International Conference on Computer, Communication and Control. Piscataway: IEEE, 2024: 1-7. |
| [13] | 陈文杰,宋宇鲲,张多利. 基于改进QR算法的矩阵分解器设计[J].电子科技, 2022, 35(11): 21-28. |
| CHEN W J, SONG Y K, ZHANG D L. Design of matrix decomposer based on improved QR algorithm[J]. Electronic Science and Technology, 2022, 35(11): 21-28. | |
| [14] | RAJ M S S, GEORGE S N. A fast and efficient approach for Human action recovery from corrupted 3-D motion capture data using QR decomposition-based approximate SVD[J]. IEEE Transactions on Human-Machine Systems, 2024, 54(4): 395-405. |
| [15] | 陈鑫峰,王武. 稀疏对称矩阵的LDLT分解在GPU上的高效实现[J]. 数据与计算发展前沿, 2021, 3(3): 136-147. |
| CHEN X F, WANG W. An effective implementation of LDLT decomposition of sparse symmetric matrix on GPU[J]. Frontiers of Data and Computing, 2021, 3(3): 136-147. | |
| [16] | 安国臣,刘若凡,赵满,等. 基于现场可编程门阵列的矩阵求逆算法设计[J]. 科学技术与工程, 2024, 24(10): 4140-4147. |
| AN G C, LIU R F, ZHAO M, et al. Design of matrix inversion algorithm based on field programmable gate array[J]. Science Technology and Engineering, 2024, 24(10): 4140-4147. | |
| [17] | 李丽,张巍. 改进Cholesky分解算法的设计与FPGA实现[J]. 电讯技术, 2020, 60(7): 845-849. |
| LI L, ZHANG W. Design and FPGA implementation of an improved Cholesky factorization algorithm[J]. Telecommunication Engineering, 2020, 60(7): 845-849. | |
| [18] | 邱俊豪,宋宇鲲,陈文杰,等. 64位双精度矩阵分解的优化和硬件实现[J]. 合肥工业大学学报(自然科学版), 2021, 44(12): 1640-1645. |
| QIU J H, SONG Y K, CHEN W J, et al. Optimization and hardware implementation of 64-bit double-precision matrix decomposition[J]. Journal of Hefei University of Technology (Natural Science), 2021, 44(12): 1640-1645. | |
| [19] | 朱鹏,叶树霞,杨晓飞. 基于浮点数的Cholesky分解FPGA实现[J].计算机与数字工程, 2023, 51(4):759-762, 831. |
| ZHU P, YE S X, YANG X F. FPGA implementation of Cholesky decomposition based on floating point number[J]. Computer and Digital Engineering, 2023, 51(4): 759-762, 831. | |
| [20] | 余浩然,肖昊. 基于LDL算法的大规模矩阵求逆加速器设计及其FPGA实现[J]. 电子科技, 2023, 36(7): 1-7. |
| YU H R, XIAO H. Design and FPGA implementation of large scale matrix inversion accelerator based on LDL algorithm[J]. Electronic Science and Technology, 2023, 36(7): 1-7. |
| [1] | 肖海林, 杨昱东, 杨紫伊, 刘海龙, 王玉, 张中山, 戴晓明. R22FFT算法的FPGA硬件结构优化设计与实现[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2637-2645. |
| [2] | 申云飞, 申飞, 李芳, 张俊. 基于张量虚拟机的深度神经网络模型加速方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2836-2844. |
| [3] | 马英杰, 肖靖, 赵耿, 曾萍, 杨亚涛. 可控网格多涡卷混沌系统族及其硬件电路实现[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 956-961. |
| [4] | 宋斌威, 王耀. 面向FPGA 知识产权保护的低开销按次付费授权方案[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3142-3148. |
| [5] | 许英鑫, 孙磊, 赵建成, 郭松辉. 基于蚁群优化算法的虚拟现场可编程门阵列部署策略[J]. 计算机应用, 2020, 40(3): 747-752. |
| [6] | 雷小康, 尹志刚, 赵瑞莲. 基于FPGA的卷积神经网络定点加速[J]. 计算机应用, 2020, 40(10): 2811-2816. |
| [7] | 谭海清, 陈正国, 陈微, 肖侬. 基于FPGA的DDR3协议解析逻辑设计[J]. 计算机应用, 2017, 37(5): 1223-1228. |
| [8] | 麦涛涛, 潘晓中, 王亚奇, 苏阳. 基于预定义类的紧凑型正则表达式匹配算法[J]. 计算机应用, 2017, 37(2): 397-401. |
| [9] | 薛俊, 段发阶, 蒋佳佳, 李彦超, 袁建富, 王宪全. 基于Matlab的并行循环冗余校验Verilog代码自动生成方法[J]. 计算机应用, 2016, 36(9): 2503-2507. |
| [10] | 卓艳男, 刘强, 姜磊, 戴琼. 基于FPGA改进电路的高性能正则表达式匹配算法[J]. 计算机应用, 2016, 36(4): 927-930. |
| [11] | 辛小霞, 王奕, 李仁发. 基于现场可编程门阵列的SMS4故障检测实现[J]. 计算机应用, 2015, 35(2): 420-423. |
| [12] | 段小虎 崔爽. 通用嵌入式串行时间码采集系统设计[J]. 计算机应用, 2014, 34(4): 1222-1226. |
| [13] | 李凯 何松华 欧建平. Virtex-5 GTP和Virtex-6 GTX间匹配通信研究及应用[J]. 计算机应用, 2014, 34(2): 325-328. |
| [14] | 张文凯 关桂霞 赵海盟 王明志 吴太夏 晏磊. 小卫星模拟系统中多路串行通信系统设计[J]. 计算机应用, 2013, 33(12): 3477-3481. |
| [15] | 琚小明 张皆浩 张逸中. 基于FPGA实时错误检测技术[J]. 计算机应用, 2013, 33(05): 1459-1462. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||