


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (6): 1816-1823.DOI: 10.11772/j.issn.1001-9081.2023060811
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Shibin LI1, Jun GONG1( ), Shengjun TANG2
), Shengjun TANG2
Received:2023-06-25
Revised:2023-09-11
Accepted:2023-09-12
Online:2023-10-07
Published:2024-06-10
Contact:
Jun GONG
About author:LI Shibin, born in 1999, M. S. candidate. His research interests include graph deep learning, complex network.Supported by:
黎施彬1, 龚俊1(), 汤圣君2
通讯作者:
龚俊
作者简介:黎施彬(1999—),男,重庆人,硕士研究生,主要研究方向:图深度学习、复杂网络基金资助:CLC Number:
Shibin LI, Jun GONG, Shengjun TANG. Semi-supervised heterophilic graph representation learning model based on Graph Transformer[J]. Journal of Computer Applications, 2024, 44(6): 1816-1823.
黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023060811

Fig.1 Overall framework of HPGT
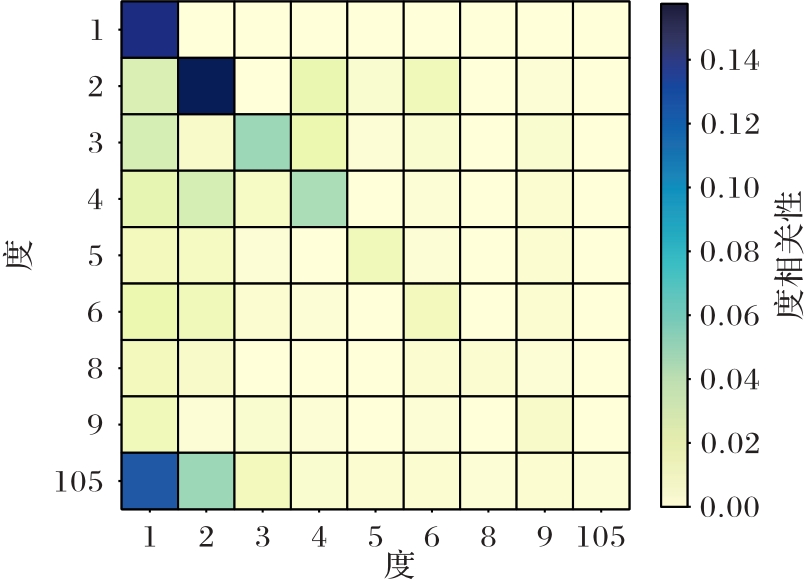
Fig.2 Degree correlation matrix of Texas
| 类型 | 数据集 | 节点数 | 边数 | 特征维度 | 类别数 | 同配比 |
|---|---|---|---|---|---|---|
同配 数据集 | Cora | 2 708 | 5 429 | 1 433 | 7 | 0.81 |
| CiteSeer | 3 327 | 4 732 | 3 703 | 6 | 0.74 | |
| PubMed | 19 717 | 44 338 | 500 | 3 | 0.80 | |
异配 数据集 | Texas | 183 | 309 | 1 703 | 5 | 0.06 |
| Wisconsin | 251 | 499 | 1 703 | 5 | 0.18 | |
| Actor | 7 600 | 33 544 | 931 | 5 | 0.22 | |
| Cornell | 183 | 295 | 1 703 | 5 | 0.30 |
Tab.1 Statistics for seven baseline graph datasets
| 类型 | 数据集 | 节点数 | 边数 | 特征维度 | 类别数 | 同配比 |
|---|---|---|---|---|---|---|
同配 数据集 | Cora | 2 708 | 5 429 | 1 433 | 7 | 0.81 |
| CiteSeer | 3 327 | 4 732 | 3 703 | 6 | 0.74 | |
| PubMed | 19 717 | 44 338 | 500 | 3 | 0.80 | |
异配 数据集 | Texas | 183 | 309 | 1 703 | 5 | 0.06 |
| Wisconsin | 251 | 499 | 1 703 | 5 | 0.18 | |
| Actor | 7 600 | 33 544 | 931 | 5 | 0.22 | |
| Cornell | 183 | 295 | 1 703 | 5 | 0.30 |
| 模型类型 | 模型 | 异配数据集 | 同配数据集 | |||||
|---|---|---|---|---|---|---|---|---|
| Texas | Wisconsin | Actor | Cornell | Cora | CiteSeer | PubMed | ||
| 传统GNN | MLP | 0.750 0 | 0.824 7 | 0.354 9 | 0.773 2 | 0.729 8 | 0.661 0 | 0.843 7 |
| GCN | 0.540 5 | 0.503 9 | 0.287 8 | 0.537 8 | 0.835 6 | 0.735 8 | 0.873 4 | |
| GAT | 0.573 0 | 0.543 1 | 0.289 9 | 0.545 9 | 0.861 6 | 0.756 0 | 0.852 5 | |
| GIN | 0.814 8 | 0.760 0 | 0.344 0 | 0.759 2 | 0.865 5 | 0.750 5 | ||
| GraphSAGE | 0.834 1 | 0.773 3 | 0.359 9 | 0.783 8 | 0.864 2 | 0.742 9 | 0.865 3 | |
| 异配GNN | H2GCN | 0.821 6 | 0.825 7 | 0.789 2 | 0.754 5 | 0.884 8 | ||
| CPGNN | 0.743 2 | 0.817 6 | 0.355 1 | 0.635 1 | 0.871 8 | 0.880 8 | ||
| GRP-GNN | 0.845 9 | 0.364 7 | 0.867 0 | 0.741 2 | 0.873 8 | |||
| BM-GCN | 0.808 2 | 0.363 2 | 0.761 4 | 0.8771 | 0.7564 | 0.9025 | ||
| HPGT | 0.8657 | 0.8410 | 0.3673 | 0.8044 | 0.837 9 | 0.746 7 | 0.886 2 | |
Tab.2 Node classification accuracy of HPGT on 7 datasets
| 模型类型 | 模型 | 异配数据集 | 同配数据集 | |||||
|---|---|---|---|---|---|---|---|---|
| Texas | Wisconsin | Actor | Cornell | Cora | CiteSeer | PubMed | ||
| 传统GNN | MLP | 0.750 0 | 0.824 7 | 0.354 9 | 0.773 2 | 0.729 8 | 0.661 0 | 0.843 7 |
| GCN | 0.540 5 | 0.503 9 | 0.287 8 | 0.537 8 | 0.835 6 | 0.735 8 | 0.873 4 | |
| GAT | 0.573 0 | 0.543 1 | 0.289 9 | 0.545 9 | 0.861 6 | 0.756 0 | 0.852 5 | |
| GIN | 0.814 8 | 0.760 0 | 0.344 0 | 0.759 2 | 0.865 5 | 0.750 5 | ||
| GraphSAGE | 0.834 1 | 0.773 3 | 0.359 9 | 0.783 8 | 0.864 2 | 0.742 9 | 0.865 3 | |
| 异配GNN | H2GCN | 0.821 6 | 0.825 7 | 0.789 2 | 0.754 5 | 0.884 8 | ||
| CPGNN | 0.743 2 | 0.817 6 | 0.355 1 | 0.635 1 | 0.871 8 | 0.880 8 | ||
| GRP-GNN | 0.845 9 | 0.364 7 | 0.867 0 | 0.741 2 | 0.873 8 | |||
| BM-GCN | 0.808 2 | 0.363 2 | 0.761 4 | 0.8771 | 0.7564 | 0.9025 | ||
| HPGT | 0.8657 | 0.8410 | 0.3673 | 0.8044 | 0.837 9 | 0.746 7 | 0.886 2 | |
| 模型 | Texas | Wisconsin | Actor | Cornell | Cora | CiteSeer | PubMed |
|---|---|---|---|---|---|---|---|
HPGT (no SE) | 0.850 1 | 0.831 4 | 0.328 0 | 0.744 5 | 0.766 5 | 0.722 9 | 0.877 5 |
| HPGT | 0.865 7 | 0.841 0 | 0.367 3 | 0.804 4 | 0.837 9 | 0.746 7 | 0.886 2 |
Tab.3 Influence of SE on HPGT (node classification accuracy)
| 模型 | Texas | Wisconsin | Actor | Cornell | Cora | CiteSeer | PubMed |
|---|---|---|---|---|---|---|---|
HPGT (no SE) | 0.850 1 | 0.831 4 | 0.328 0 | 0.744 5 | 0.766 5 | 0.722 9 | 0.877 5 |
| HPGT | 0.865 7 | 0.841 0 | 0.367 3 | 0.804 4 | 0.837 9 | 0.746 7 | 0.886 2 |
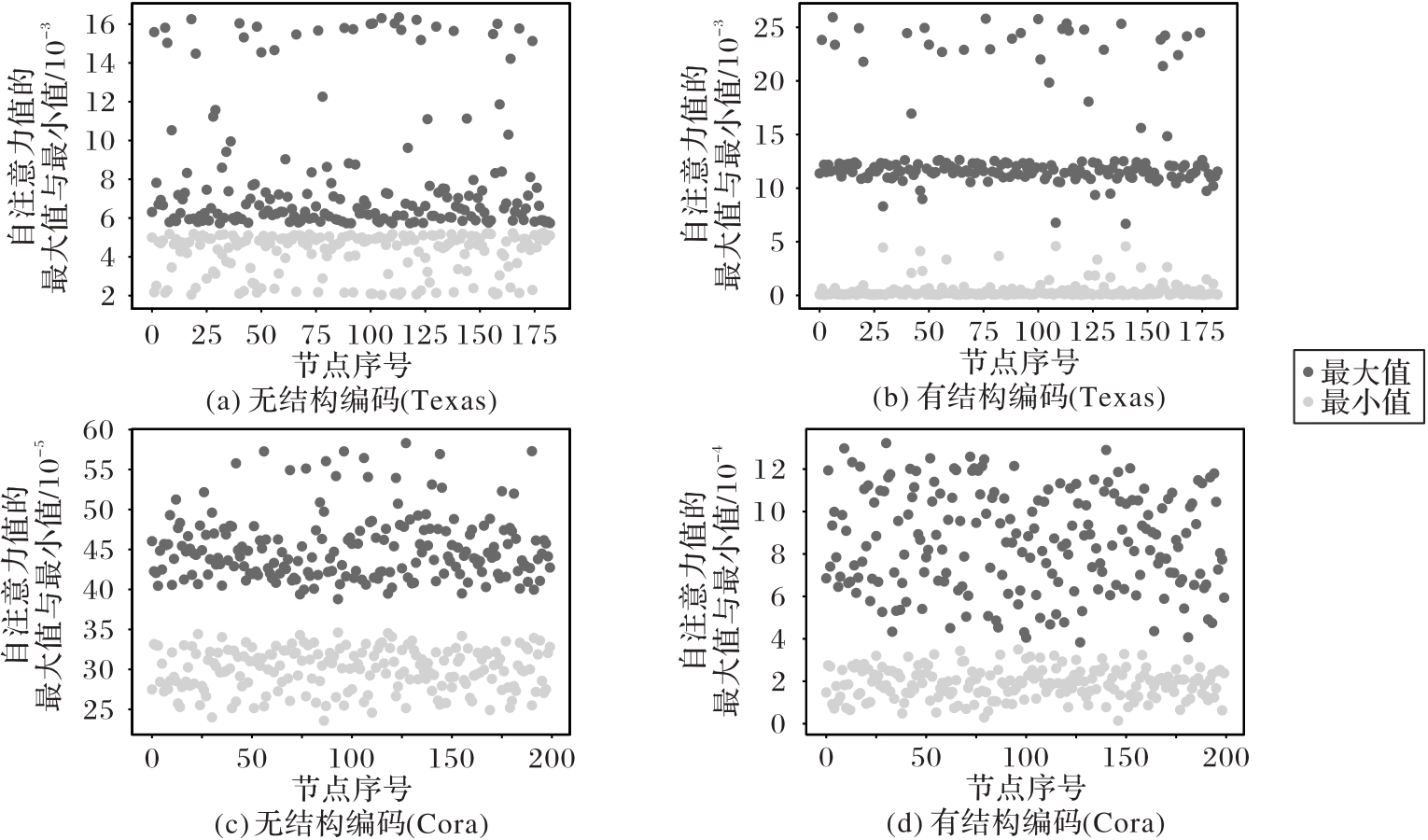
Fig.3 Influence of SE on learning bias of self-attention module

Fig.4 Node classification results of different sampling strategies
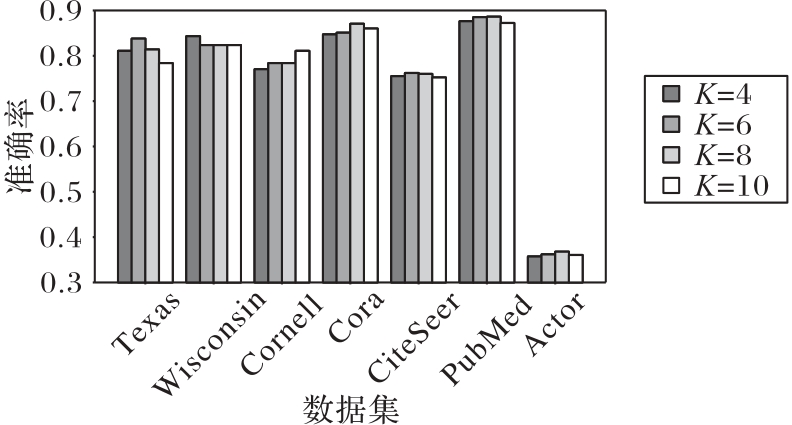
Fig. 5 Sensitivity of model to path neighborhood length
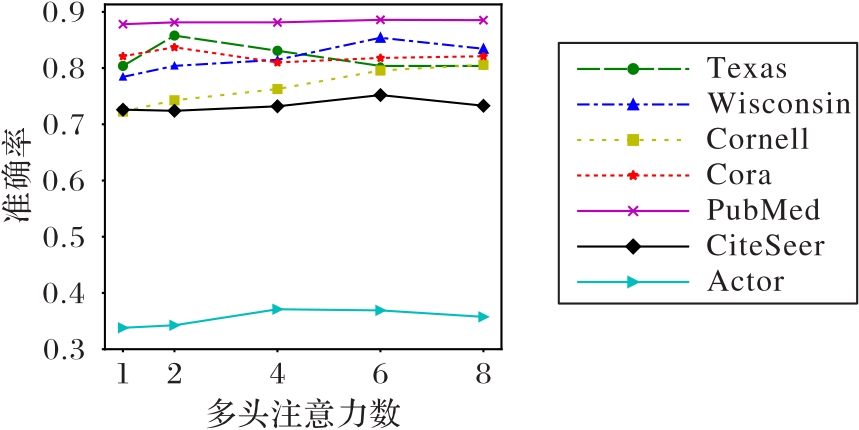
Fig.6 Sensitivity of model to amount of multi-head attention
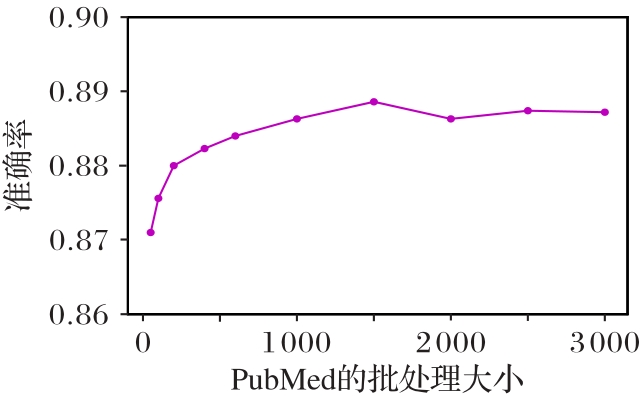
Fig.7 Sensitivity of model to batch-size
| 1 | ZHENG W, WANG C, PEI J, et al. Causality based propagation history ranking in social networks[C]// Proceedings of the 25th International Joint Conference on Aritificial Intelligence. Palo Alto: AAAI Press, 2016: 3917-3923. |
| 2 | GILMER J, SCHOENHOLZ S S, RILEY P F, et al. Neural message passing for quantum chemistry[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1263-1272. |
| 3 | DUVENAUD D K, MACLAURIN D, AGUILERA-IPARRAGUIRRE J, et al. Convolutional networks on graphs for learning molecular fingerprints[C]// Proceedings of the 28th Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 2224-2232. |
| 4 | JIN D, HUO C, LIANG C, et al. Heterophilic graph neural network via attribute completion[C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 391-400. |
| 5 | SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// Proceedings of the 2018 European Semantic Web Conference. Cham: Springer, 2018: 593-607. |
| 6 | ZHANG M, CHEN Y. Link prediction based on graph neural networks [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 5171-5181. |
| 7 | WANG Z, LIU M, LUO Y, et al. Advanced graph and sequence neural networks for molecular property prediction and drug discovery[J]. Bioinformatics, 2022, 38(9): 2579-2586. |
| 8 | 严骏驰. 图匹配问题的研究和算法设计[D]. 上海:上海交通大学,2015:170. |
| YAN J C. Algorithmic studies and design on graph matching[D]. Shanghai: Shanghai Jiao Tong University, 2015: 170. | |
| 9 | 宁懿昕,谢辉,姜火文.图神经网络社区发现研究综述[J]. 计算机科学,2021,48(11A):11-16. |
| NING Y X, XIE H, JIANG H W. Survey of graph neural network in community detection[J]. Computer Science, 2021, 48(11A): 11-16. | |
| 10 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2016-11-21)[2023-06-24]. . |
| 11 | VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks [EB/OL]. (2018-02-04)[2023-06-24]. . |
| 12 | ZHU J, ROSSI R A, RAO A, et al. Graph neural networks with heterophily[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2021: 11168-11176. |
| 13 | ZHU M, WANG X, SHI C, et al. Interpreting and unifying graph neural networks with an optimization framework[C]// Proceedings of the Web Conference 2021. New York: ACM, 2021:1215-1226. |
| 14 | HE D, LIANG C, LIU H, et al. Block modeling-guided graph convolutional neural networks [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2022: 4022-4029. |
| 15 | PEI H, WEI B, CHANG K C-C, et al. Geom-GCN: geometric graph convolutional networks [EB/OL]. (2020-04-13)[2023-06-24]. . |
| 16 | ZHU J, YAN Y, ZHAO L, et al. Beyond homophily in graph neural networks: current limitations and effective designs[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 7793-7804. |
| 17 | CHIEN E, PENG J, LI P, et al. Adaptive universal generalized pagerank graph neural network [EB/OL]. (2021-10-26) [2023-06-24]. . |
| 18 | SUN Y, DENG H, YANG Y, et al. Beyond homophily: structure-aware path aggregation graph neural network[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 2233-2240. |
| 19 | JIN D, WANG R, GE M, et al. RAW-GNN: random walk aggregation based graph neural network [C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 2108-2114. |
| 20 | GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 855-864. |
| 21 | DWIVEDI V P, BRESSON X. A generalization of transformer networks to graphs[EB/OL]. (2020-12-17)[2023-06-24]. . |
| 22 | FU X, ZHANG J, MENG Z, et al. MAGNN: metapath aggregated graph neural network for heterophilic graph embedding[C]// Proceedings of the Web Conference 2020. New York: ACM, 2020: 2331-2341. |
| 23 | DU Z, ZHOU C, YAO J, et al. CogKR: cognitive graph for multi-hop knowledge reasoning [J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(2): 1283-1295. |
| 24 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 25 | MIALON G, CHEN D, SELOSSE M, et al. GraphiT: encoding graph structure in Transformers [EB/OL]. (2021-06-10)[2023-06-24]. . |
| 26 | SEN P, NAMATA G, BILGIC M, et al. Collective classification in network data articles [J]. AI Magazine, 2008, 29(3): 93-106. |
| 27 | NAMATA G, LONDON B, GETOOR L, et al. Query-driven active surveying for collective classification [EB/OL]. [2023-06-20]. htttps://people.cs.vt.edu/~bhuang/papers/namata-mlg12.pdf. |
| 28 | TANG J, SUN J, WANG C, et al. Social influence analysis in large-scale networks [C]// Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 807-816. |
| 29 | PARK Y S, LEK S. Artificial neural networks: multilayer perceptron for ecological modeling[J]. Developments in Environmental Modelling, 2016, 28: 123-140. |
| [1] | Guixiang XUE, Hui WANG, Weifeng ZHOU, Yu LIU, Yan LI. Port traffic flow prediction based on knowledge graph and spatio-temporal diffusion graph convolutional network [J]. Journal of Computer Applications, 2024, 44(9): 2952-2957. |
| [2] | Yu DU, Yan ZHU. Constructing pre-trained dynamic graph neural network to predict disappearance of academic cooperation behavior [J]. Journal of Computer Applications, 2024, 44(9): 2726-2731. |
| [3] | Chuanlin PANG, Rui TANG, Ruizhi ZHANG, Chuan LIU, Jia LIU, Shibo YUE. Distributed power allocation algorithm based on graph convolutional network for D2D communication systems [J]. Journal of Computer Applications, 2024, 44(9): 2855-2862. |
| [4] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [5] | Wenping ZHENG, Huilin GE, Meilin LIU, Gui YANG. Node classification algorithm fusing 2-connected motif-structure information [J]. Journal of Computer Applications, 2024, 44(5): 1464-1470. |
| [6] | Longtao GAO, Nana LI. Aspect sentiment triplet extraction based on aspect-aware attention enhancement [J]. Journal of Computer Applications, 2024, 44(4): 1049-1057. |
| [7] | Xianfeng YANG, Yilei TANG, Ziqiang LI. Aspect-level sentiment analysis model based on alternating‑attention mechanism and graph convolutional network [J]. Journal of Computer Applications, 2024, 44(4): 1058-1064. |
| [8] | Dapeng XU, Xinmin HOU. Feature selection method for graph neural network based on network architecture design [J]. Journal of Computer Applications, 2024, 44(3): 663-670. |
| [9] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [10] | Zucheng WU, Xiaojun WU, Tianyang XU. Image-text retrieval model based on intra-modal fine-grained feature relationship extraction [J]. Journal of Computer Applications, 2024, 44(12): 3776-3783. |
| [11] | Xinrong HU, Jingxue CHEN, Zijian HUANG, Bangchao WANG, Xun YAO, Junping LIU, Qiang ZHU, Jie YANG. Graph convolution network-based masked data augmentation [J]. Journal of Computer Applications, 2024, 44(11): 3335-3344. |
| [12] | Nengqiang XIANG, Xiaofei ZHU, Zhaoze GAO. Information diffusion prediction model of prototype-aware dual-channel graph convolutional neural network [J]. Journal of Computer Applications, 2024, 44(10): 3260-3266. |
| [13] | Yanbo LI, Qing HE, Shunyi LU. Aspect sentiment triplet extraction integrating semantic and syntactic information [J]. Journal of Computer Applications, 2024, 44(10): 3275-3280. |
| [14] | Wanting JI, Wenyi LU, Yuhang MA, Linlin DING, Baoyan SONG, Haolin ZHANG. Machine reading comprehension event detection based on relation-enhanced graph convolutional network [J]. Journal of Computer Applications, 2024, 44(10): 3288-3293. |
| [15] | Hanxiao SHI, Leichun WANG. Short-term power load forecasting by graph convolutional network combining LSTM and self-attention mechanism [J]. Journal of Computer Applications, 2024, 44(1): 311-317. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||