


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (9): 2958-2963.DOI: 10.11772/j.issn.1001-9081.2023091266
• Frontier and comprehensive applications • Previous Articles Next Articles
Hailin XIAO1( ), Tianyi HUANG1, Qiuxiang DAI1, Yuejun ZHANG2, Zhongshan ZHANG3
), Tianyi HUANG1, Qiuxiang DAI1, Yuejun ZHANG2, Zhongshan ZHANG3
Received:2023-09-18
Revised:2023-11-30
Accepted:2023-12-04
Online:2023-12-21
Published:2024-09-10
Contact:
Hailin XIAO
About author:HUANG Tianyi, born in 1998, M. S. candidate. His research interests include in-vehicle communications, intelligent vehicle control.Supported by:
肖海林1(), 黄天义1, 代秋香1, 张跃军2, 张中山3
通讯作者:
肖海林
作者简介:黄天义(1998—),男,陕西西安人,硕士研究生,主要研究方向:车载通信、智能车辆控制;基金资助:CLC Number:
Hailin XIAO, Tianyi HUANG, Qiuxiang DAI, Yuejun ZHANG, Zhongshan ZHANG. Safe reinforcement learning method for decision making of autonomous lane changing based on trajectory prediction[J]. Journal of Computer Applications, 2024, 44(9): 2958-2963.
肖海林, 黄天义, 代秋香, 张跃军, 张中山. 基于轨迹预测的安全强化学习自动变道决策方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2958-2963.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023091266
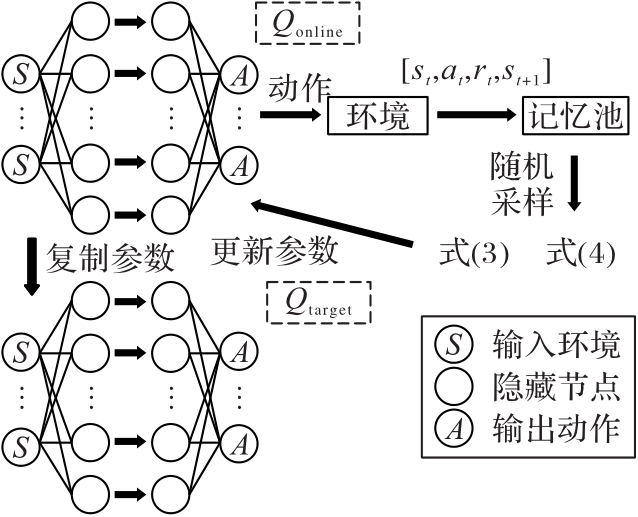
Fig. 1 Framework of DQN
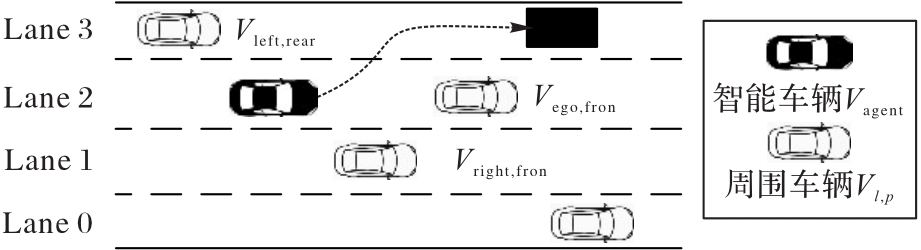
Fig. 2 Decision-making scene of lane changing
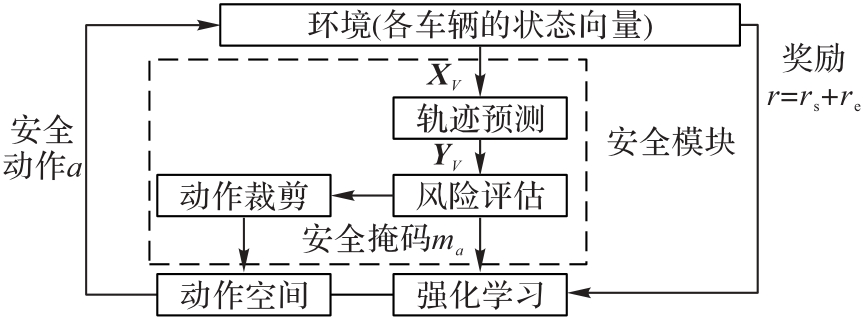
Fig. 3 Whole framework of proposed method
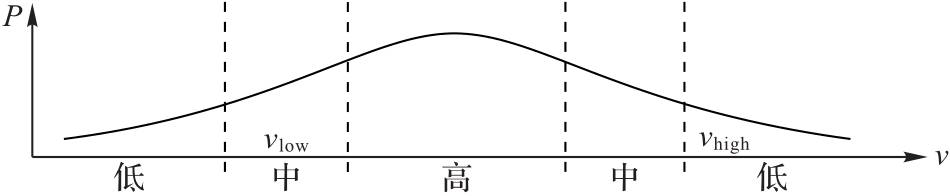
Fig. 4 Qualitative presentation for probability distribution in Eq. (20)
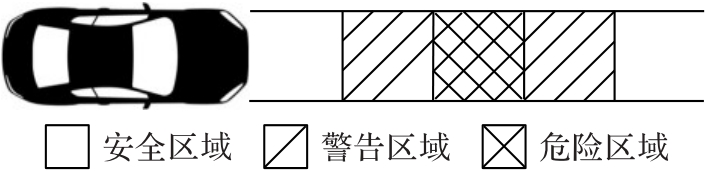
Fig. 5 Risk area division
| 符号 | 参数 | 数值 |
|---|---|---|
| Llength | 道路的长度 | 8 000 m |
| Lwidth | 道路的宽度 | 3.2 m |
| vallowed | 道路速度限制 | 33.3 m/s |
| vmax,agent | 智能车辆最大行驶速度 | 33.3 m/s |
| amax | 智能车辆的最大加速度 | 2.0 m/s2 |
| amin | 智能车辆的最小减速度 | -3.5 m/s2 |
| tTTC | 碰撞时间 | 1.5 s |
| w1 | 安全距离奖励权重系数 | 0.06 |
| w2 | 行驶速度奖励权重系数 | 0.4 |
| th | 历史信息长度 | 10 |
| tp | 预测信息长度 | 10 |
Tab. 1 Parameters of integrated simulation
| 符号 | 参数 | 数值 |
|---|---|---|
| Llength | 道路的长度 | 8 000 m |
| Lwidth | 道路的宽度 | 3.2 m |
| vallowed | 道路速度限制 | 33.3 m/s |
| vmax,agent | 智能车辆最大行驶速度 | 33.3 m/s |
| amax | 智能车辆的最大加速度 | 2.0 m/s2 |
| amin | 智能车辆的最小减速度 | -3.5 m/s2 |
| tTTC | 碰撞时间 | 1.5 s |
| w1 | 安全距离奖励权重系数 | 0.06 |
| w2 | 行驶速度奖励权重系数 | 0.4 |
| th | 历史信息长度 | 10 |
| tp | 预测信息长度 | 10 |
| 符号 | 参数 | 数值 |
|---|---|---|
| γ | 奖励值折扣因子 | 0.9 |
| α | 学习率 | 0.000 1 |
| ε | 贪婪值 | 0.9 |
| εincrement | 贪婪值回合增长 | 0.000 5 |
| Msize | 记忆池大小 | 5 000 |
| batchsize | 批量抽样大小 | 256 |
| targetreplace | Qtarget更新步长 | 200 |
Tab. 2 Training parameters of reinforcement learning
| 符号 | 参数 | 数值 |
|---|---|---|
| γ | 奖励值折扣因子 | 0.9 |
| α | 学习率 | 0.000 1 |
| ε | 贪婪值 | 0.9 |
| εincrement | 贪婪值回合增长 | 0.000 5 |
| Msize | 记忆池大小 | 5 000 |
| batchsize | 批量抽样大小 | 256 |
| targetreplace | Qtarget更新步长 | 200 |
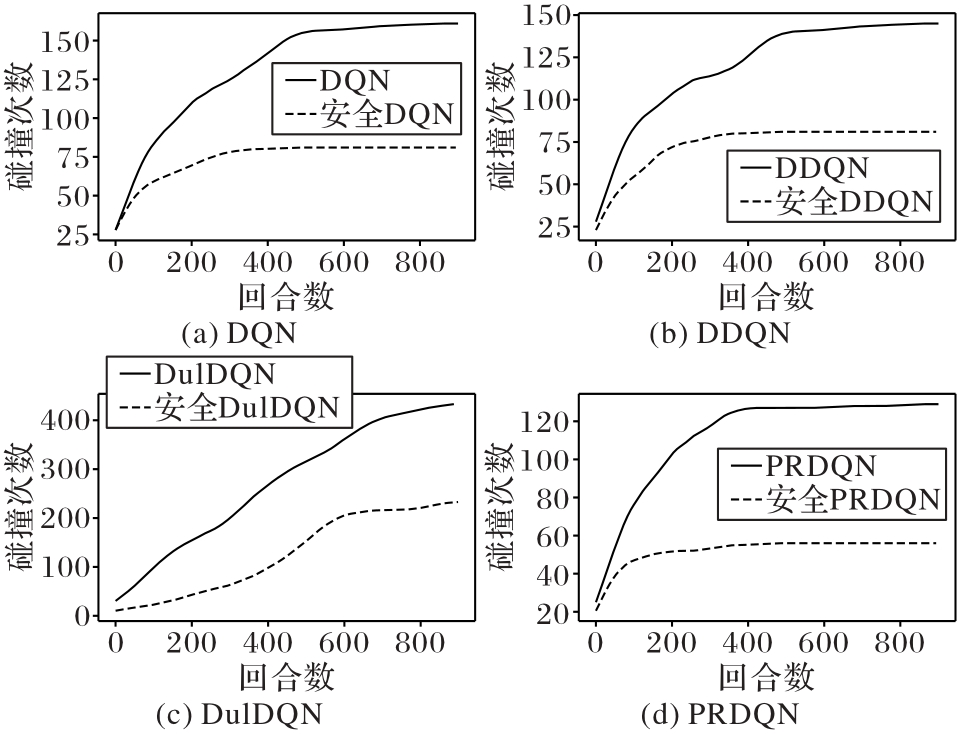
Fig. 6 Numbers of collisions of different algorithms during training
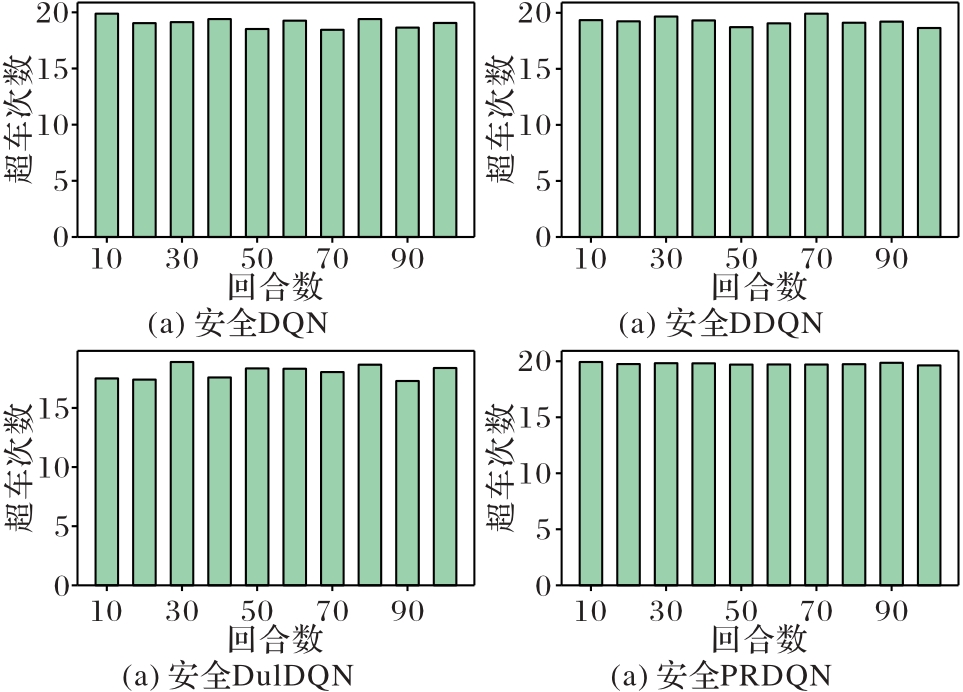
Fig. 7 Numbers of overtaking in 100 rounds of different safety algorithms
| 算法 | 平均超车次数 | 效率/% | 平均速度/(m·s-1) |
|---|---|---|---|
| DQN | 18.0 | 90.0 | 29.2 |
| 安全DQN | 18.9 | 94.5 | 29.6 |
| DDQN | 18.4 | 92.0 | 29.2 |
| 安全DDQN | 19.3 | 96.5 | 29.6 |
| DulDQN | 17.4 | 87.0 | 32.4 |
| 安全DulDQN | 18.0 | 90.0 | 26.3 |
| PRDQN | 18.8 | 94.0 | 29.6 |
| 安全PRDQN | 19.8 | 99.0 | 31.3 |
Tab. 3 Efficiency comparison of different trained algorithms tested for 100 rounds
| 算法 | 平均超车次数 | 效率/% | 平均速度/(m·s-1) |
|---|---|---|---|
| DQN | 18.0 | 90.0 | 29.2 |
| 安全DQN | 18.9 | 94.5 | 29.6 |
| DDQN | 18.4 | 92.0 | 29.2 |
| 安全DDQN | 19.3 | 96.5 | 29.6 |
| DulDQN | 17.4 | 87.0 | 32.4 |
| 安全DulDQN | 18.0 | 90.0 | 26.3 |
| PRDQN | 18.8 | 94.0 | 29.6 |
| 安全PRDQN | 19.8 | 99.0 | 31.3 |
| 1 | FAGNANT D J, KOCKELMAN K. Preparing a nation for autonomous vehicles: opportunities, barriers and policy recommendations [J]. Transportation Research Part A: Policy and Practice, 2015, 77: 167-181. |
| 2 | SALVUCCI D D, GRAY R. A two-point visual control model of steering [J]. Perception, 2004, 33(10): 1233-1248. |
| 3 | URMSON C, ANHALT J, BAGNELL D, et al. Autonomous driving in urban environments: boss and the urban challenge [J]. Journal of Field Robotics, 2008, 25(8): 425-466. |
| 4 | LEONARD J, HOW J, TELLER S, et al. A perception-driven autonomous urban vehicle [J]. Journal of Field Robotics, 2008, 25(10): 727-774. |
| 5 | XU X, ZUO L, LI X, et al. A reinforcement learning approach to autonomous decision making of intelligent vehicles on highways [J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(10): 3884-3897. |
| 6 | MIRCHEVSKA B, PEK C, WERLING M, et al. High-level decision making for safe and reasonable autonomous lane changing using reinforcement learning [C]// Proceedings of the 21st International Conference on Intelligent Transportation Systems. Piscataway: IEEE, 2018: 2156-2162. |
| 7 | ZHANG S, PENG H, NAGESHRAO S, et al. Discretionary lane change decision making using reinforcement learning with model-based exploration [C]// Proceedings of the 18th IEEE International Conference on Machine Learning and Applications. Piscataway: IEEE, 2019: 844-850. |
| 8 | AN H, JUNG J I. Decision-making system for lane change using deep reinforcement learning in connected and automated driving[J]. Electronics, 2019, 8(5): No.543. |
| 9 | 王雪松,王荣荣,程玉虎.安全强化学习综述[J].自动化学报, 2023, 49(9): 1813-1835. |
| WANG X S, WANG R R, CHENG Y H. Safe reinforcement learning: a survey [J]. Acta Automatica Sinica, 2023, 49(9): 1813-1835. | |
| 10 | 代珊珊,刘全.基于动作约束深度强化学习的安全自动驾驶方法[J].计算机科学,2021,48(9): 235-243. |
| DAI S S, LIU Q. Action constrained deep reinforcement learning based safe automatic driving method [J]. Computer Science, 2021, 48(9): 235-243. | |
| 11 | GARCÍA J, FERNÁNDEZ F. A comprehensive survey on safe reinforcement learning [J]. Journal of Machine Learning Research, 2015, 16: 1437-1480. |
| 12 | YU M, YANG Z, KOLAR M, et al. Convergent policy optimization for safe reinforcement learning [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 3127-3139. |
| 13 | GEIBEL P, WYSOTZKI F. Risk-sensitive reinforcement learning applied to control under constraints [J]. Journal of Artificial Intelligence Research, 2005, 24: 81-108. |
| 14 | MO S, PEI X, WU C. Safe reinforcement learning for autonomous vehicle using Monte Carlo tree search [J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(7): 6766-6773. |
| 15 | BAHERI A, NAGESHRAO S, TSENG H E, et al. Deep reinforcement learning with enhanced safety for autonomous highway driving [C]// Proceedings of the 2020 IEEE Intelligent Vehicles Symposium. Piscataway: IEEE, 2020: 1550-1555. |
| 16 | LI G, YANG Y, LI S, et al. Decision making of autonomous vehicles in lane change scenarios: deep reinforcement learning approaches with risk awareness [J]. Transportation Research Part C: Emerging Technologies, 2022, 134: No.103452. |
| 17 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning [J]. Nature, 2015, 518(7540): 529-533. |
| 18 | VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning [C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 2094-2100. |
| 19 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning [C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1995-2003. |
| 20 | DUAN J, LI S E, GUAN Y, et al. Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data [J]. IET Intelligent Transport Systems, 2020, 14(5): 297-305. |
| 21 | HUANG Y, DU J, YANG Z, et al. A survey on trajectory-prediction methods for autonomous driving [J]. IEEE Transactions on Intelligent Vehicles, 2022, 7(3): 652-674. |
| 22 | JOSEPH J, DOSHI-VELEZ F, HUANG A S, et al. A Bayesian nonparametric approach to modeling motion patterns [J]. Autonomous Robots, 2011, 31(4): 383-400. |
| 23 | BRÄNNSTRÖM M, COELINGH E, SJÖBERG J. Model-based threat assessment for avoiding arbitrary vehicle collisions [J]. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 658-669. |
| 24 | KRASOWSKI H, WANG X, ALTHOFF M. Safe reinforcement learning for autonomous lane changing using set-based prediction[C]// Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems. Piscataway: IEEE, 2020: 1-7. |
| 25 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay [EB/OL]. (2016-02-25) [2023-04-04]. . |
| [1] | Runze TIAN, Yulong ZHOU, Hong ZHU, Gang XUE. Local information based path selection algorithm for service migration [J]. Journal of Computer Applications, 2024, 44(7): 2168-2174. |
| [2] | Honglei YAO, Jiqiang LIU, Endong TONG, Wenjia NIU. Network security risk assessment method for CTCS based on α-cut triangular fuzzy number and attack tree [J]. Journal of Computer Applications, 2024, 44(4): 1018-1026. |
| [3] | Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG [J]. Journal of Computer Applications, 2024, 44(11): 3623-3628. |
| [4] | Xiaoyu HUA, Dongfen LI, You FU, Kejun BI, Shi YING, Ruijin WANG. Industrial chain risk assessment and early warning model combining hierarchical graph neural network and long short-term memory [J]. Journal of Computer Applications, 2024, 44(10): 3223-3231. |
| [5] | Jiagao WU, Shiwen ZHANG, Yudong JIANG, Linfeng LIU. Social-interaction GAN for pedestrian trajectory prediction based on state-refinement long short-term memory and attention mechanism [J]. Journal of Computer Applications, 2023, 43(5): 1565-1570. |
| [6] | Tao PENG, Yalong KANG, Feng YU, Zili ZHANG, Junping LIU, Xinrong HU, Ruhan HE, Li LI. Pedestrian trajectory prediction based on multi-head soft attention graph convolutional network [J]. Journal of Computer Applications, 2023, 43(3): 736-743. |
| [7] | Yijian ZHAO, Li LIN, Qianqian WANG, Peng WEN, Dong YANG. Trajectory prediction of sea targets based on geodetic distance similarity calculation [J]. Journal of Computer Applications, 2023, 43(11): 3594-3598. |
| [8] | Yuli CHEN, Qiang TONG, Tongtong CHEN, Shoulu HOU, Xiulei LIU. Short-term trajectory prediction model of aircraft based on attention mechanism and generative adversarial network [J]. Journal of Computer Applications, 2022, 42(10): 3292-3299. |
| [9] | DAI Yurou, YANG Qing, ZHANG Fengli, ZHOU Fan. Trajectory prediction model of social network users based on self-supervised learning [J]. Journal of Computer Applications, 2021, 41(9): 2545-2551. |
| [10] | LI Xujuan, PI Jianyong, HUANG Feixiang, JIA Haipeng. Self-generated deep neural network based 4D trajectory prediction [J]. Journal of Computer Applications, 2021, 41(5): 1492-1499. |
| [11] | GAO Jian, MAO Yingchi, LI Zhitao. Trajectory prediction based on Gauss mixture time series model [J]. Journal of Computer Applications, 2019, 39(8): 2261-2270. |
| [12] | SUN Yasheng, JIANG Qi, HU Jie, QI Jin, PENG Yinghong. Attention mechanism based pedestrian trajectory prediction generation model [J]. Journal of Computer Applications, 2019, 39(3): 668-674. |
| [13] | BU Tongtong, CAO Tianjie. Risk assessment method of Android application based on permission [J]. Journal of Computer Applications, 2019, 39(1): 131-135. |
| [14] | WU Wenbo, KANG Rui, LI Zi. Attack graph based risk assessment method for cyber security of cyber-physical system [J]. Journal of Computer Applications, 2016, 36(1): 203-206. |
| [15] | LI Yan, HUANG Guangqiu, ZHANG Bin. New network vulnerability diffusion analysis method based on cumulative effect [J]. Journal of Computer Applications, 2015, 35(8): 2169-2173. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||