


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (9): 2919-2930.DOI: 10.11772/j.issn.1001-9081.2023091303
• Multimedia computing and computer simulation • Previous Articles Next Articles
Yan RONG1,2, Jiawen LIU1, Xinlei LI1( )
)
Received:2023-09-20
Revised:2023-11-24
Accepted:2023-12-01
Online:2024-01-31
Published:2024-09-10
Contact:
Xinlei LI
About author:RONG Yan, born in 2001, M. S. candidate. Her research interests include computer vision, affective computing.Supported by:
戎妍1,2, 刘嘉雯1, 李馨蕾1()
通讯作者:
李馨蕾
作者简介:戎妍(2001—),女,江苏丹阳人,硕士研究生,CCF会员,主要研究方向:计算机视觉、情感计算基金资助:CLC Number:
Yan RONG, Jiawen LIU, Xinlei LI. Adaptive hybrid network for affective computing in student classroom[J]. Journal of Computer Applications, 2024, 44(9): 2919-2930.
戎妍, 刘嘉雯, 李馨蕾. 面向学生课堂情感计算的自适应混合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2919-2930.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023091303

Fig. 1 Examples of some sample quality differences

Fig. 2 Structure of SC-ACNet
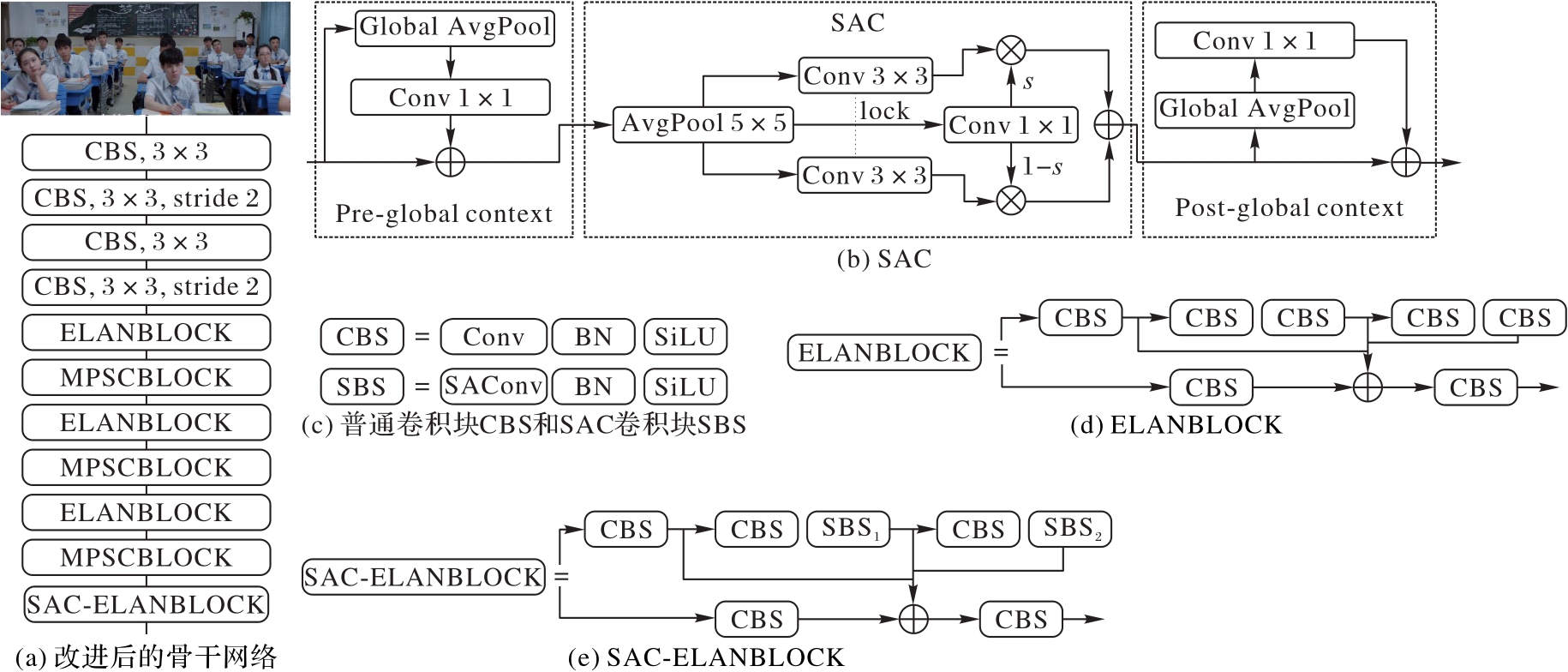
Fig. 3 Structure of improved backbone network and various modules
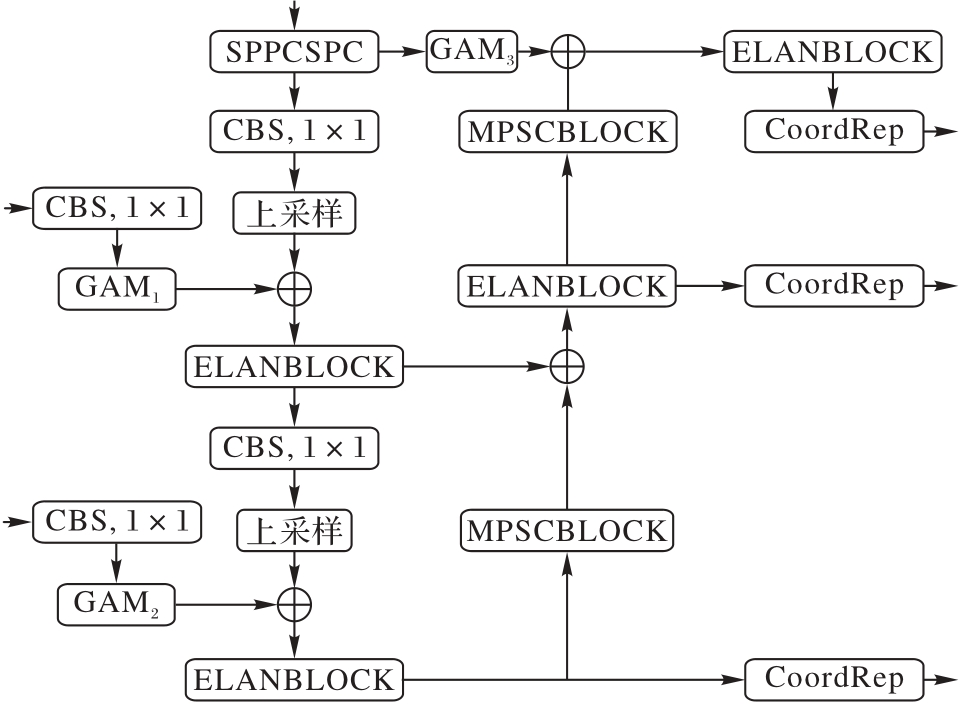
Fig. 4 Neck module of improved detection network
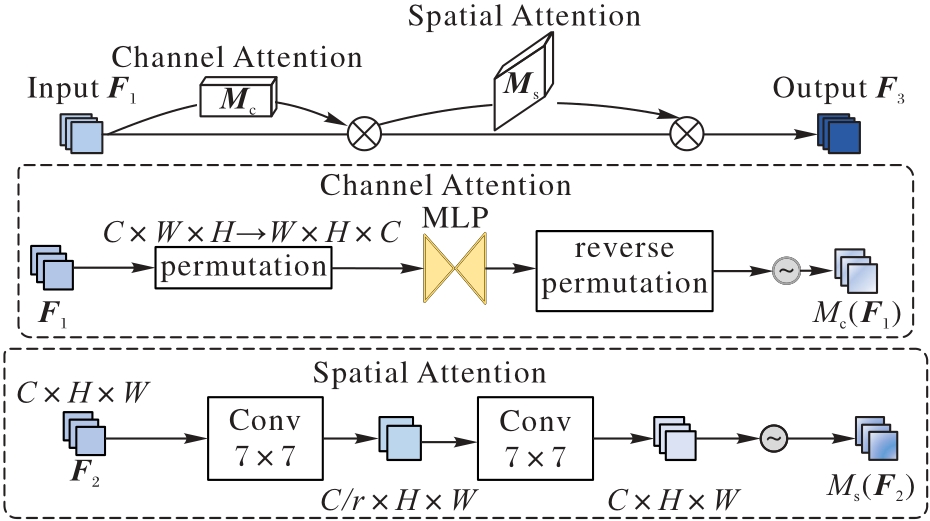
Fig. 5 Structure of GAM attention
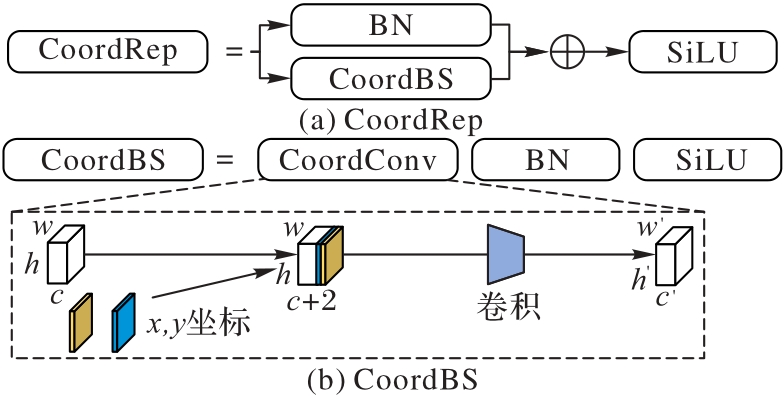
Fig. 6 Structure of CoordRep module

Fig. 7 Examples of face alignment
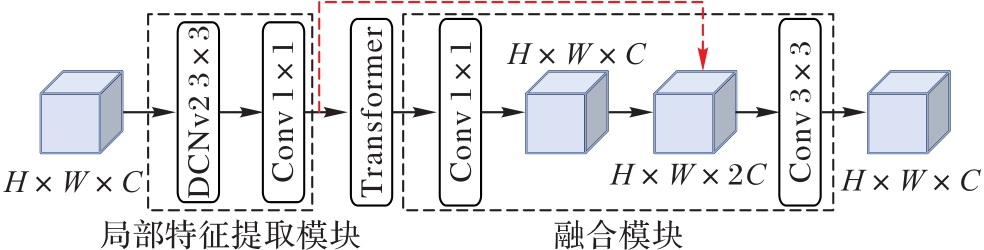
Fig. 8 Structure of DCN-MobileViT module

Fig. 9 Some sample images of students in classroom

Fig. 10 Sample images of student facial emotion labels
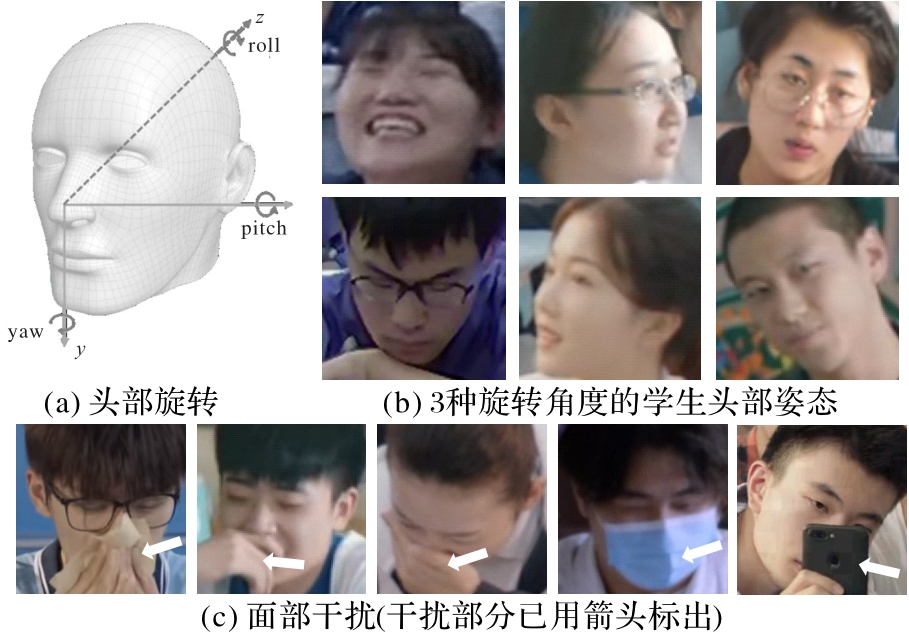
Fig. 11 Sample images of different head postures and non-target components
| P | R | mAP | |||
|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | ||
| | 0.968 | 0.950 | 0.570 | 0.979 | |
| | 0.970 | 0.954 | 0.571 | 0.983 | |
| | | 0.980 | 0.953 | 0.571 | 0.985 |
Tab. 1 Influence of SAC-ELANBLOCK module on model performance
| P | R | mAP | |||
|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | ||
| | 0.968 | 0.950 | 0.570 | 0.979 | |
| | 0.970 | 0.954 | 0.571 | 0.983 | |
| | | 0.980 | 0.953 | 0.571 | 0.985 |
| GAM1 | GAM2 | GAM3 | P | R | mAP | |
|---|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | |||
| | 0.966 | 0.971 | 0.587 | 0.989 | ||
| | 0.970 | 0.968 | 0.605 | 0.987 | ||
| | 0.987 | 0.967 | 0.548 | 0.990 | ||
| | | | 0.984 | 0.978 | 0.576 | 0.991 |
Tab. 2 Influence of GAM structure on model performance
| GAM1 | GAM2 | GAM3 | P | R | mAP | |
|---|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | |||
| | 0.966 | 0.971 | 0.587 | 0.989 | ||
| | 0.970 | 0.968 | 0.605 | 0.987 | ||
| | 0.987 | 0.967 | 0.548 | 0.990 | ||
| | | | 0.984 | 0.978 | 0.576 | 0.991 |
| 注意力机制 | P | R | mAP | |
|---|---|---|---|---|
| SE[ | 0.973 | 0.951 | 0.556 | 0.985 |
| CBAM[ | 0.957 | 0.946 | 0.552 | 0.977 |
| Polarized Self-Attention[ | 0.975 | 0.951 | 0.529 | 0.980 |
| CoordAttention[ | 0.976 | 0.949 | 0.566 | 0.982 |
| Sequential Self-Attention[ | 0.975 | 0.970 | 0.570 | 0.984 |
| SimAM[ | 0.974 | 0.953 | 0.560 | 0.979 |
| TripletAttention[ | 0.979 | 0.938 | 0.542 | 0.979 |
| GAM | 0.984 | 0.978 | 0.576 | 0.991 |
Tab. 3 Comparison results of different attention mechanisms
| 注意力机制 | P | R | mAP | |
|---|---|---|---|---|
| SE[ | 0.973 | 0.951 | 0.556 | 0.985 |
| CBAM[ | 0.957 | 0.946 | 0.552 | 0.977 |
| Polarized Self-Attention[ | 0.975 | 0.951 | 0.529 | 0.980 |
| CoordAttention[ | 0.976 | 0.949 | 0.566 | 0.982 |
| Sequential Self-Attention[ | 0.975 | 0.970 | 0.570 | 0.984 |
| SimAM[ | 0.974 | 0.953 | 0.560 | 0.979 |
| TripletAttention[ | 0.979 | 0.938 | 0.542 | 0.979 |
| GAM | 0.984 | 0.978 | 0.576 | 0.991 |
| 损失函数 | P | R | mAP | |
|---|---|---|---|---|
| CIoU | 0.969 | 0.949 | 0.556 | 0.980 |
| SIoU[ | 0.975 | 0.949 | 0.556 | 0.980 |
| AlphaIoU[ | 0.944 | 0.938 | 0.556 | 0.975 |
| FocalEIoU[ | 0.984 | 0.946 | 0.572 | 0.981 |
| EIoU | 0.979 | 0.956 | 0.567 | 0.983 |
| CIoU+NWD | 0.979 | 0.949 | 0.565 | 0.982 |
| WiseIoU[ | 0.972 | 0.944 | 0.526 | 0.974 |
| NWD-EIoU | 0.985 | 0.949 | 0.581 | 0.984 |
Tab. 4 Comparison results of different loss functions in face detection module
| 损失函数 | P | R | mAP | |
|---|---|---|---|---|
| CIoU | 0.969 | 0.949 | 0.556 | 0.980 |
| SIoU[ | 0.975 | 0.949 | 0.556 | 0.980 |
| AlphaIoU[ | 0.944 | 0.938 | 0.556 | 0.975 |
| FocalEIoU[ | 0.984 | 0.946 | 0.572 | 0.981 |
| EIoU | 0.979 | 0.956 | 0.567 | 0.983 |
| CIoU+NWD | 0.979 | 0.949 | 0.565 | 0.982 |
| WiseIoU[ | 0.972 | 0.944 | 0.526 | 0.974 |
| NWD-EIoU | 0.985 | 0.949 | 0.581 | 0.984 |
| SEB | GAM | CoordRep | NWD-EIoU | P | R | mAP | |
|---|---|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | ||||
| | 0.980 | 0.953 | 0.571 | 0.985 | |||
| | 0.984 | 0.978 | 0.576 | 0.991 | |||
| | 0.970 | 0.968 | 0.605 | 0.987 | |||
| | 0.985 | 0.949 | 0.581 | 0.984 | |||
| | | | | 0.994 | 0.986 | 0.598 | 0.994 |
Tab. 5 Ablation experiment results of improvement modules in face detection module
| SEB | GAM | CoordRep | NWD-EIoU | P | R | mAP | |
|---|---|---|---|---|---|---|---|
| 0.969 | 0.949 | 0.556 | 0.980 | ||||
| | 0.980 | 0.953 | 0.571 | 0.985 | |||
| | 0.984 | 0.978 | 0.576 | 0.991 | |||
| | 0.970 | 0.968 | 0.605 | 0.987 | |||
| | 0.985 | 0.949 | 0.581 | 0.984 | |||
| | | | | 0.994 | 0.986 | 0.598 | 0.994 |
| 损失函数 | Acc | R | F1 |
|---|---|---|---|
| Cross EntropyLoss | 0.828 | 0.824 | 0.814 |
| LabelSmoothLoss | 0.826 | 0.813 | 0.810 |
| SeesawLoss | 0.829 | 0.845 | 0.830 |
| Focal Loss | 0.832 | 0.832 | 0.820 |
| ASL(clip=0.5) | 0.849 | 0.814 | 0.808 |
| ASL | 0.853 | 0.843 | 0.841 |
Tab. 6 Comparison results of different loss functions in affective computing module
| 损失函数 | Acc | R | F1 |
|---|---|---|---|
| Cross EntropyLoss | 0.828 | 0.824 | 0.814 |
| LabelSmoothLoss | 0.826 | 0.813 | 0.810 |
| SeesawLoss | 0.829 | 0.845 | 0.830 |
| Focal Loss | 0.832 | 0.832 | 0.820 |
| ASL(clip=0.5) | 0.849 | 0.814 | 0.808 |
| ASL | 0.853 | 0.843 | 0.841 |
| DCNv2 | 特征融合 | ASL | Acc | R | F1 |
|---|---|---|---|---|---|
| 0.832 | 0.832 | 0.820 | |||
| | 0.853 | 0.843 | 0.841 | ||
| | 0.845 | 0.842 | 0.823 | ||
| | 0.861 | 0.857 | 0.846 | ||
| | | | 0.923 | 0.912 | 0.907 |
Tab. 7 Ablation experiment results of DCNv2, feature fusion, and loss function
| DCNv2 | 特征融合 | ASL | Acc | R | F1 |
|---|---|---|---|---|---|
| 0.832 | 0.832 | 0.820 | |||
| | 0.853 | 0.843 | 0.841 | ||
| | 0.845 | 0.842 | 0.823 | ||
| | 0.861 | 0.857 | 0.846 | ||
| | | | 0.923 | 0.912 | 0.907 |

Fig. 12 Comparison of heat maps for each module
| 算法 | one-stage | Anchor | Backbone | mAP | 浮点运算量/GFLOPs | Params/106 | ||
|---|---|---|---|---|---|---|---|---|
| DETR[ | | R-50 | 0.437 | 0.868 | 0.386 | 5.170 | 41.280 | |
| FSAF[ | | R-50 | 0.725 | 0.988 | 0.866 | 9.950 | 36.010 | |
| YOLOX[ | | YOLOX-S | 0.301 | 0.679 | 0.209 | 1.630 | 8.940 | |
| YOLOv6[ | | | YOLOv6-s | 0.689 | 0.983 | 0.815 | 2.681 | 17.187 |
| RetinaNet[ | | | R-50-FPN | 0.718 | 0.968 | 0.866 | 10.050 | 36.100 |
| Grid RCNN[ | | R-50 | 0.698 | 0.979 | 0.855 | 136.830 | 64.240 | |
| Cascade RCNN[ | | R-50-FPN | 0.743 | 0.979 | 0.907 | 51.150 | 68.930 | |
| Faster RCNN[ | | R-50-FPN | 0.718 | 0.980 | 0.885 | 23.350 | 23.350 | |
| TOOD[ | | R-50 | 0.732 | 0.989 | 0.890 | 8.860 | 31.790 | |
| FCOS[ | | R-50 | 0.705 | 0.979 | 0.847 | 9.660 | 31.840 | |
| Deformable DETR[ | | R-50 | 0.529 | 0.928 | 0.537 | 11.010 | 39.820 | |
| SC-ACNet | | | 本文网络 | 0.748 | 0.995 | 0.902 | 6.338 | 36.503 |
Tab. 8 Comparison results of different object detection algorithms in face detection module
| 算法 | one-stage | Anchor | Backbone | mAP | 浮点运算量/GFLOPs | Params/106 | ||
|---|---|---|---|---|---|---|---|---|
| DETR[ | | R-50 | 0.437 | 0.868 | 0.386 | 5.170 | 41.280 | |
| FSAF[ | | R-50 | 0.725 | 0.988 | 0.866 | 9.950 | 36.010 | |
| YOLOX[ | | YOLOX-S | 0.301 | 0.679 | 0.209 | 1.630 | 8.940 | |
| YOLOv6[ | | | YOLOv6-s | 0.689 | 0.983 | 0.815 | 2.681 | 17.187 |
| RetinaNet[ | | | R-50-FPN | 0.718 | 0.968 | 0.866 | 10.050 | 36.100 |
| Grid RCNN[ | | R-50 | 0.698 | 0.979 | 0.855 | 136.830 | 64.240 | |
| Cascade RCNN[ | | R-50-FPN | 0.743 | 0.979 | 0.907 | 51.150 | 68.930 | |
| Faster RCNN[ | | R-50-FPN | 0.718 | 0.980 | 0.885 | 23.350 | 23.350 | |
| TOOD[ | | R-50 | 0.732 | 0.989 | 0.890 | 8.860 | 31.790 | |
| FCOS[ | | R-50 | 0.705 | 0.979 | 0.847 | 9.660 | 31.840 | |
| Deformable DETR[ | | R-50 | 0.529 | 0.928 | 0.537 | 11.010 | 39.820 | |
| SC-ACNet | | | 本文网络 | 0.748 | 0.995 | 0.902 | 6.338 | 36.503 |
| 模型 | SC-ACD | KDEF | RaFD | 浮点运算量/GFLOPs | Params/106 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | R | F1 | Acc | R | F1 | Acc | R | F1 | |||
| ConvNext[ | 0.525 | 0.429 | 0.409 | 0.652 | 0.653 | 0.652 | 0.155 | 0.278 | 0.187 | 5.84 | 27.83 |
| MobileNet v2[ | 0.863 | 0.814 | 0.818 | 0.848 | 0.848 | 0.847 | 0.741 | 0.714 | 0.683 | 0.41 | 2.23 |
| EfficientNet[ | 0.847 | 0.814 | 0.818 | 0.956 | 0.955 | 0.955 | 0.989 | 0.992 | 0.990 | 0.52 | 4.02 |
| ShuffleNet v2[ | 0.863 | 0.857 | 0.857 | 0.924 | 0.919 | 0.918 | 0.941 | 0.945 | 0.911 | 0.19 | 1.26 |
| DenseNet[ | 0.133 | 0.283 | 0.181 | 0.632 | 0.636 | 0.622 | 0.131 | 0.136 | 0.109 | 3.74 | 6.96 |
| CSPNet[ | 0.825 | 0.845 | 0.819 | 0.666 | 0.666 | 0.666 | 0.975 | 0.975 | 0.974 | 6.57 | 27.64 |
| VAN[ | 0.850 | 0.825 | 0.819 | 0.954 | 0.954 | 0.953 | 0.991 | 0.989 | 0.990 | 1.13 | 3.85 |
| PoolFormer[ | 0.888 | 0.858 | 0.860 | 0.962 | 0.961 | 0.961 | 0.974 | 0.972 | 0.972 | 2.38 | 11.41 |
| MViTv2[ | 0.775 | 0.736 | 0.730 | 0.968 | 0.968 | 0.977 | 0.995 | 0.996 | 0.996 | 6.41 | 23.41 |
| Swin Transformer v2[ | 0.875 | 0.843 | 0.843 | 0.975 | 0.978 | 0.976 | 0.964 | 0.972 | 0.967 | 5.96 | 27.58 |
| ConvMixer[ | 0.825 | 0.775 | 0.773 | 0.728 | 0.701 | 0.689 | 0.954 | 0.961 | 0.956 | 28.83 | 20.35 |
| Twins[ | 0.775 | 0.712 | 0.706 | 0.576 | 0.574 | 0.569 | 0.013 | 0.125 | 0.024 | 5.06 | 23.60 |
| SC-ACNet | 0.923 | 0.913 | 0.908 | 0.972 | 0.972 | 0.971 | 0.994 | 0.997 | 0.996 | 2.03 | 4.94 |
Tab. 9 Comparison results of different algorithms in affective computing module
| 模型 | SC-ACD | KDEF | RaFD | 浮点运算量/GFLOPs | Params/106 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | R | F1 | Acc | R | F1 | Acc | R | F1 | |||
| ConvNext[ | 0.525 | 0.429 | 0.409 | 0.652 | 0.653 | 0.652 | 0.155 | 0.278 | 0.187 | 5.84 | 27.83 |
| MobileNet v2[ | 0.863 | 0.814 | 0.818 | 0.848 | 0.848 | 0.847 | 0.741 | 0.714 | 0.683 | 0.41 | 2.23 |
| EfficientNet[ | 0.847 | 0.814 | 0.818 | 0.956 | 0.955 | 0.955 | 0.989 | 0.992 | 0.990 | 0.52 | 4.02 |
| ShuffleNet v2[ | 0.863 | 0.857 | 0.857 | 0.924 | 0.919 | 0.918 | 0.941 | 0.945 | 0.911 | 0.19 | 1.26 |
| DenseNet[ | 0.133 | 0.283 | 0.181 | 0.632 | 0.636 | 0.622 | 0.131 | 0.136 | 0.109 | 3.74 | 6.96 |
| CSPNet[ | 0.825 | 0.845 | 0.819 | 0.666 | 0.666 | 0.666 | 0.975 | 0.975 | 0.974 | 6.57 | 27.64 |
| VAN[ | 0.850 | 0.825 | 0.819 | 0.954 | 0.954 | 0.953 | 0.991 | 0.989 | 0.990 | 1.13 | 3.85 |
| PoolFormer[ | 0.888 | 0.858 | 0.860 | 0.962 | 0.961 | 0.961 | 0.974 | 0.972 | 0.972 | 2.38 | 11.41 |
| MViTv2[ | 0.775 | 0.736 | 0.730 | 0.968 | 0.968 | 0.977 | 0.995 | 0.996 | 0.996 | 6.41 | 23.41 |
| Swin Transformer v2[ | 0.875 | 0.843 | 0.843 | 0.975 | 0.978 | 0.976 | 0.964 | 0.972 | 0.967 | 5.96 | 27.58 |
| ConvMixer[ | 0.825 | 0.775 | 0.773 | 0.728 | 0.701 | 0.689 | 0.954 | 0.961 | 0.956 | 28.83 | 20.35 |
| Twins[ | 0.775 | 0.712 | 0.706 | 0.576 | 0.574 | 0.569 | 0.013 | 0.125 | 0.024 | 5.06 | 23.60 |
| SC-ACNet | 0.923 | 0.913 | 0.908 | 0.972 | 0.972 | 0.971 | 0.994 | 0.997 | 0.996 | 2.03 | 4.94 |

Fig. 13 Visualization results of face detection module on test set

Fig. 14 Affection classification results of affective computing module on test set

Fig. 15 Affection classification results of SC-ACNet in different head postures

Fig. 16 Prediction results and attention graphs of SC-ACNet on KDEF dataset
| 1 | WANG Y, SONG W, TAO W, et al. A systematic review on affective computing: emotion models, databases, and recent advances [J]. Information Fusion, 2022, 83: 19-52. |
| 2 | MEHRABIAN A. Communication without words [M]// MORTENSEN C D. Communication Theory. 2nd ed. New York: Routledge, 2008: 193-200. |
| 3 | 周进,叶俊民,李超. 多模态学习情感计算:动因、框架与建议[J]. 电化教育研究, 2021, 42(7): 26-32. |
| ZHOU J, YE J M, LI C. Multimodal learning affective computing: motivations, frameworks, and suggestions [J]. e-Education Research, 2021, 42(7): 26-32. | |
| 4 | WEN J, JIANG D, TU G, et al. Dynamic interactive multiview memory network for emotion recognition in conversation [J]. Information Fusion, 2023, 91: 123-133. |
| 5 | SUN B, WU Y, ZHAO K, et al. Student class behavior dataset: a video dataset for recognizing, detecting, and captioning students’ behaviors in classroom scenes [J]. Neural Computing and Applications, 2021, 33(14): 8335-8354. |
| 6 | MASUD U, SAEED T, MALAIKAH H M, et al. Smart assistive system for visually impaired people obstruction avoidance through object detection and classification [J]. IEEE Access, 2022, 10: 13428-13441. |
| 7 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with Transformers [C]// Proceedings of the 16th European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| 8 | ZHU C, HE Y, SAVVIDES M. Feature selective anchor-free module for single-shot object detection [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 840-849. |
| 9 | GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021 [EB/OL]. [2023-11-15]. . |
| 10 | LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications [EB/OL]. (2022-09-07) [2023-11-18]. . |
| 11 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 7464-7475. |
| 12 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. |
| 13 | LU X, LI B, YUE Y, et al. Grid R-CNN [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7355-7364. |
| 14 | CAI Z, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6154-6162. |
| 15 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 91-99. |
| 16 | FENG C, ZHONG Y, GAO Y, et al. TOOD: task-aligned one-stage object detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 3490-3499. |
| 17 | TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9626-9635. |
| 18 | ZHONG P, WANG D, MIAO C. EEG-based emotion recognition using regularized graph neural networks [J]. IEEE Transactions on Affective Computing, 2022, 13(3): 1290-1301. |
| 19 | YE F, PU S, ZHONG Q, et al. Dynamic GCN: context-enriched topology learning for skeleton-based action recognition [C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 55-63. |
| 20 | GUPTA S, KUMAR P, TEKCHANDANI R K. Facial emotion recognition based real-time learner engagement detection system in online learning context using deep learning models [J]. Multimedia Tools and Applications, 2023, 82(8): 11365-11394. |
| 21 | HOU C, AI J, LIN Y, et al. Evaluation of online teaching quality based on facial expression recognition [J]. Future Internet, 2022, 14(6): No.177. |
| 22 | DONG Z, JI X, LAI C S, et al. Memristor-based hierarchical attention network for multimodal affective computing in mental health monitoring [J]. IEEE Consumer Electronics Magazine, 2023, 12(4): 94-106. |
| 23 | CALVO M G, LUNDQVIST D. Facial expressions of emotion (KDEF): identification under different display-duration conditions[J]. Behavior Research Methods, 2008, 40(1): 109-115. |
| 24 | LANGNER O, DOTSCH R, BIJLSTRA G, et al. Presentation and validation of the Radboud faces database [J]. Cognition and Emotion, 2010, 24(8): 1377-1388. |
| 25 | QIAO S, CHEN L C, YUILLE A. DetectoRS: detecting objects with recursive feature pyramid and switchable atrous convolution [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10208-10219. |
| 26 | LIU Y, SHAO Z, HOFFMANN N. Global attention mechanism: retain information to enhance channel-spatial interactions[EB/OL]. [2023-10-13]. . |
| 27 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 3-19. |
| 28 | LIU R, LEHMAN J, MOLINO P, et al. An intriguing failing of convolutional neural networks and the CoordConv solution [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 9628-9639. |
| 29 | YANG Z, WANG X, LI J. EIoU: an improved vehicle detection algorithm based on VehicleNet neural network [J]. Journal of Physics: Conference Series, 2021, 1924: No.012001. |
| 30 | XU C, WANG J, YANG W, et al. Detecting tiny objects in aerial images: a normalized Wasserstein distance and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 79-93. |
| 31 | MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[EB/OL]. (2022-03-04) [2023-08-02]. . |
| 32 | ZHU X, HU H, LIN S, et al. Deformable ConvNets v2: more deformable, better results [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9300-9308. |
| 33 | RIDNIK T, BEN-BARUCH E, ZAMIR N, et al. Asymmetric loss for multi-label classification [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 82-91. |
| 34 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| 35 | LIU H, LIU F, FAN X, et al. Polarized self-attention: towards high-quality pixel-wise mapping [J]. Neurocomputing, 2022, 506: 158-167. |
| 36 | HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13708-13717. |
| 37 | FAN Z, LIU Z, WANG Y, et al. Sequential recommendation via stochastic self-attention [C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2036-2047. |
| 38 | YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 11863-11874. |
| 39 | MISRA D, NALAMADA T, ARASANIPALAI A U, et al. Rotate to attend: convolutional triplet attention module [C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3138-3147. |
| 40 | GEVORGYAN Z. SIoU loss: more powerful learning for bounding box regression[EB/OL]. (2022-05-25) [2023-03-29]. . |
| 41 | HE J, ERFANI S, MA X, et al. Alpha-IoU: a family of power intersection over union losses for bounding box regression [C]// Proceedings of the 35th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 20230-20242. |
| 42 | ZHANG Y F, REN W, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression [J]. Neurocomputing, 2022, 506: 146-157. |
| 43 | TONG Z, CHEN Y, XU Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism [EB/OL]. [2023-10-14]. . |
| 44 | ZHU X, SU W, LU L, et al. Deformable DETR: deformable Transformers for end-to-end object detection [EB/OL]. (2021-03-18) [2023-11-11]. . |
| 45 | LIU Z, MAO H, WU C Y, et al. A ConvNet for the 2020s [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 11966-11976. |
| 46 | SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. |
| 47 | TAN M, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114. |
| 48 | MA N, ZHANG X, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design [C]// Proceedings of the 15th European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 122-138. |
| 49 | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. |
| 50 | WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1571-1580. |
| 51 | GUO M H, LU C Z, LIU Z N, et al. Visual attention network [J]. Computational Visual Media, 2023, 9(4): 733-752. |
| 52 | YU W, LUO M, ZHOU P, et al. MetaFormer is actually what you need for vision [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10809-10819. |
| 53 | LI Y, WU C Y, FAN H, et al. MViTv2: improved multiscale vision Transformers for classification and detection [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4794-4804. |
| 54 | LIU Z, HU H, LIN Y, et al. Swin Transformer V2: scaling up capacity and resolution [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 11999-12009. |
| 55 | NG D, CHEN Y, TIAN B, et al. ConvMixer: feature interactive convolution with curriculum learning for small footprint and noisy far-field keyword spotting [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 3603-3607. |
| 56 | CHU X, TIAN Z, WANG Y, et al. Twins: revisiting the design of spatial attention in vision Transformers [C]// Proceedings of the 35th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 9355-9366. |
| 57 | ZHANG C, ZHANG C, ZHENG S, et al. A complete survey on generative AI (AIGC): is ChatGPT from GPT-4 to GPT-5 all you need? [EB/OL]. [2023-03-21]. . |
| 58 | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[EB/OL]. [2023-06-11]. . |
| 59 | AMIN M M, CAMBRIA E, SCHULLER B W. Will affective computing emerge from foundation models and general artificial intelligence? A first evaluation of ChatGPT [J]. IEEE Intelligent Systems, 2023, 38(2): 15-23. |
| [1] | Tong CHEN, Fengyu YANG, Yu XIONG, Hong YAN, Fuxing QIU. Construction method of voiceprint library based on multi-scale frequency-channel attention fusion [J]. Journal of Computer Applications, 2024, 44(8): 2407-2413. |
| [2] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [3] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [4] | Zhanjun JIANG, Baijing WU, Long MA, Jing LIAN. Faster-RCNN water-floating garbage recognition based on multi-scale feature and polarized self-attention [J]. Journal of Computer Applications, 2024, 44(3): 938-944. |
| [5] | Hao YANG, Yi ZHANG. Feature pyramid network algorithm based on context information and multi-scale fusion importance awareness [J]. Journal of Computer Applications, 2023, 43(9): 2727-2734. |
| [6] | Hong WANG, Qing QIAN, Huan WANG, Yong LONG. Lightweight image tamper localization algorithm based on large kernel attention convolution [J]. Journal of Computer Applications, 2023, 43(9): 2692-2699. |
| [7] | Shuai ZHENG, Xiaolong ZHANG, He DENG, Hongwei REN. 3D liver image segmentation method based on multi-scale feature fusion and grid attention mechanism [J]. Journal of Computer Applications, 2023, 43(7): 2303-2310. |
| [8] | Chunlan ZHAN, Anzhi WANG, Minghui WANG. Camouflage object segmentation method based on channel attention and edge fusion [J]. Journal of Computer Applications, 2023, 43(7): 2166-2172. |
| [9] | Zhouhua ZHU, Qi QI. Automatic detection and recognition of electric vehicle helmet based on improved YOLOv5s [J]. Journal of Computer Applications, 2023, 43(4): 1291-1296. |
| [10] | You YANG, Ruhui ZHANG, Pengcheng XU, Kang KANG, Hao ZHAI. Improved U-Net for seal segmentation of Republican archives [J]. Journal of Computer Applications, 2023, 43(3): 943-948. |
| [11] | Xin ZHAO, Qianqian ZHU, Cong ZHAO, Jialing WU. Segmentation of breast nodules in ultrasound images based on multi-scale and cross-spatial fusion [J]. Journal of Computer Applications, 2023, 43(11): 3599-3606. |
| [12] | LYU Yuchao, JIANG Xi, XU Yinghao, ZHU Xijun. Improved brachial plexus nerve segmentation method based on multi-scale feature fusion [J]. Journal of Computer Applications, 2023, 43(1): 273-279. |
| [13] | Zanxia QIANG, Xianfu BAO. Residual attention deraining network based on convolutional long short-term memory [J]. Journal of Computer Applications, 2022, 42(9): 2858-2864. |
| [14] | Tianhao QIU, Shurong CHEN. EfficientNet based dual-branch multi-scale integrated learning for pedestrian re-identification [J]. Journal of Computer Applications, 2022, 42(7): 2065-2071. |
| [15] | HAN Jiandong, LI Xiaoyu. Pedestrian re-identification method based on multi-scale feature fusion [J]. Journal of Computer Applications, 2021, 41(10): 2991-2996. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||