


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (6): 1809-1816.DOI: 10.11772/j.issn.1001-9081.2024050682
• Artificial intelligence • Previous Articles
Haijie WANG( ), Guangxin ZHANG, Hai SHI, Shu CHEN
), Guangxin ZHANG, Hai SHI, Shu CHEN
Received:2024-05-30
Revised:2024-09-01
Accepted:2024-09-13
Online:2024-09-18
Published:2025-06-10
Contact:
Haijie WANG
About author:WANG Haijie, born in 2000, M. S. candidate. His research interests include natural language processing, relation extraction.
王海杰(), 张广鑫, 史海, 陈树
通讯作者:
王海杰
作者简介:王海杰(2000—),男,安徽蚌埠人,硕士研究生,主要研究方向:自然语言处理、关系抽取 6221905044@stu.jiangnan.edu.cnCLC Number:
Haijie WANG, Guangxin ZHANG, Hai SHI, Shu CHEN. Document-level relation extraction based on entity representation enhancement[J]. Journal of Computer Applications, 2025, 45(6): 1809-1816.
王海杰, 张广鑫, 史海, 陈树. 基于实体表示增强的文档级关系抽取[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1809-1816.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050682

Fig. 1 Example in DocRED dataset
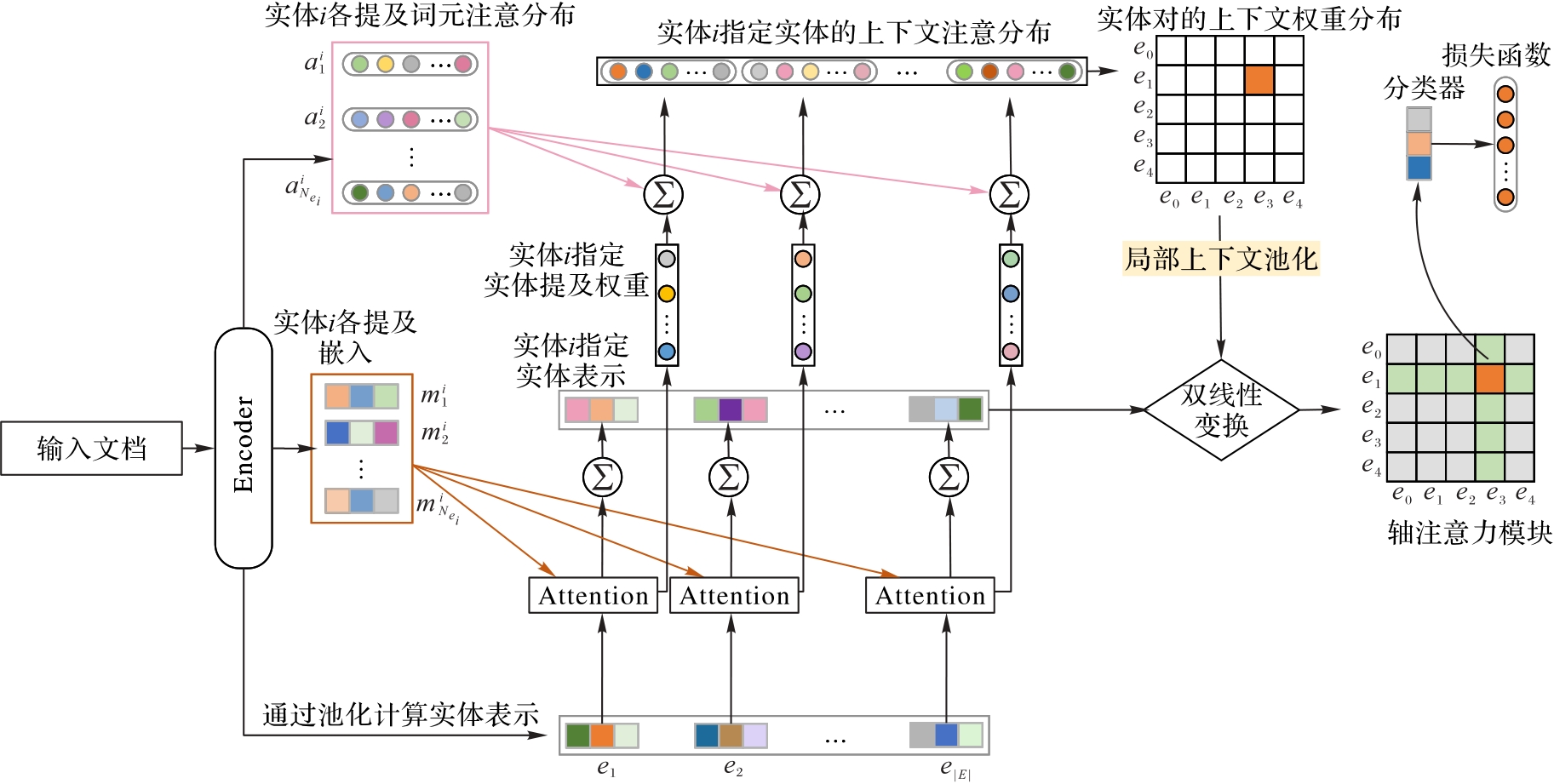
Fig. 2 Architecture of DREERE
| 数据集 | 文档数 | 关系类型数 | ||
|---|---|---|---|---|
| 训练集 | 开发集 | 测试集 | ||
| DocRED | 3 053 | 1 000 | 1 000 | 97 |
| DWIE | 602 | 98 | 99 | 65 |
Tab. 1 Statistics of datasets
| 数据集 | 文档数 | 关系类型数 | ||
|---|---|---|---|---|
| 训练集 | 开发集 | 测试集 | ||
| DocRED | 3 053 | 1 000 | 1 000 | 97 |
| DWIE | 602 | 98 | 99 | 65 |
| 数据集 | 文档平均三元组数 | 三元组总数 | 无证据三元组总数 |
|---|---|---|---|
| DocRED | 12.5 | 38 180 | 1 421(3.7%) |
| Re-DocRED | 28.1 | 85 932 | 38 670(45.0%) |
Tab. 2 Triple statistics of training set
| 数据集 | 文档平均三元组数 | 三元组总数 | 无证据三元组总数 |
|---|---|---|---|
| DocRED | 12.5 | 38 180 | 1 421(3.7%) |
| Re-DocRED | 28.1 | 85 932 | 38 670(45.0%) |
| 模型 | 训练 阶段 | 批次 数 | 批处理 数 | 编码器 学习率 | 分类器 学习率 |
|---|---|---|---|---|---|
| DREERE-BERT | stage1 | 60 | 8 | 0.000 030 | 0.000 10 |
| stage2 | 52 | 8 | 0.000 010 | 0.000 10 | |
| DREERE-RoBERTa | stage1 | 60 | 8 | 0.000 020 | 0.000 10 |
| stage2 | 52 | 8 | 0.000 003 | 0.000 05 |
Tab. 3 Experimental parameters
| 模型 | 训练 阶段 | 批次 数 | 批处理 数 | 编码器 学习率 | 分类器 学习率 |
|---|---|---|---|---|---|
| DREERE-BERT | stage1 | 60 | 8 | 0.000 030 | 0.000 10 |
| stage2 | 52 | 8 | 0.000 010 | 0.000 10 | |
| DREERE-RoBERTa | stage1 | 60 | 8 | 0.000 020 | 0.000 10 |
| stage2 | 52 | 8 | 0.000 003 | 0.000 05 |
| 模型 | PrLM | 开发集 | 测试集 | ||||
|---|---|---|---|---|---|---|---|
| ign-F1 | F1 | evi-F1 | ign-F1 | F1 | evi-F1 | ||
| LSR | BERT-base | 52.41 | 59.00 | ─ | 56.97 | 59.50 | ─ |
| GAIN | 59.14 | 61.22 | ─ | 59.00 | 61.24 | ─ | |
| HeterGSAN | 58.13 | 60.18 | ─ | 57.12 | 59.45 | ─ | |
| SSAN | 56.68 | 58.95 | ─ | 56.06 | 58.41 | ─ | |
| Coref-BERT | 55.32 | 57.51 | ─ | 54.54 | 56.96 | ─ | |
| ATLOP | 59.22 | 61.09 | ─ | 59.31 | 61.30 | ─ | |
| E2GRE | 55.22 | 58.72 | 47.12 | ─ | ─ | ─ | |
| DREEAM | 59.60 | 61.42 | 52.08 | 59.12 | 61.32 | 51.71 | |
| DREERE‑BERT | 59.96 | 61.84 | 52.40 | 59.50 | 61.48 | 52.09 | |
| RoBERTa | RoBERTa-large | 57.19 | 59.40 | ─ | 57.74 | 60.06 | ─ |
| SSAN | 60.25 | 62.08 | ─ | 59.47 | 61.42 | ─ | |
| ATLOP | 61.32 | 63.18 | ─ | 61.39 | 63.40 | ─ | |
| DREEAM | 61.71 | 63.49 | 54.15 | 61.62 | 63.55 | 54.01 | |
| DREERE‑RoBERTa | 61.85 | 63.73 | 54.18 | 61.69 | 63.61 | 54.09 | |
Tab. 4 Experimental results on DocRED dataset
| 模型 | PrLM | 开发集 | 测试集 | ||||
|---|---|---|---|---|---|---|---|
| ign-F1 | F1 | evi-F1 | ign-F1 | F1 | evi-F1 | ||
| LSR | BERT-base | 52.41 | 59.00 | ─ | 56.97 | 59.50 | ─ |
| GAIN | 59.14 | 61.22 | ─ | 59.00 | 61.24 | ─ | |
| HeterGSAN | 58.13 | 60.18 | ─ | 57.12 | 59.45 | ─ | |
| SSAN | 56.68 | 58.95 | ─ | 56.06 | 58.41 | ─ | |
| Coref-BERT | 55.32 | 57.51 | ─ | 54.54 | 56.96 | ─ | |
| ATLOP | 59.22 | 61.09 | ─ | 59.31 | 61.30 | ─ | |
| E2GRE | 55.22 | 58.72 | 47.12 | ─ | ─ | ─ | |
| DREEAM | 59.60 | 61.42 | 52.08 | 59.12 | 61.32 | 51.71 | |
| DREERE‑BERT | 59.96 | 61.84 | 52.40 | 59.50 | 61.48 | 52.09 | |
| RoBERTa | RoBERTa-large | 57.19 | 59.40 | ─ | 57.74 | 60.06 | ─ |
| SSAN | 60.25 | 62.08 | ─ | 59.47 | 61.42 | ─ | |
| ATLOP | 61.32 | 63.18 | ─ | 61.39 | 63.40 | ─ | |
| DREEAM | 61.71 | 63.49 | 54.15 | 61.62 | 63.55 | 54.01 | |
| DREERE‑RoBERTa | 61.85 | 63.73 | 54.18 | 61.69 | 63.61 | 54.09 | |
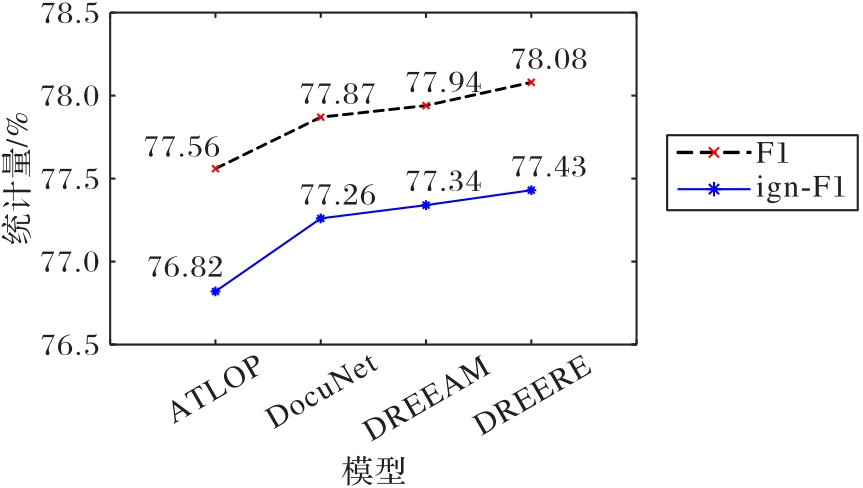
Fig. 3 Experimental results of different models on Re-DocRED test set
| 模型 | ign-F1 | F1 |
|---|---|---|
| ATLOP-BERT | 59.22 | 61.09 |
| DREERE-BERT | 59.96 | 61.84 |
| w/o axial attention | 59.28 | 61.20 |
| only attention network | 59.27 | 61.17 |
| w/o difficulties classification | 59.50 | 61.41 |
Tab. 5 Ablation experimental results on DocRED development set
| 模型 | ign-F1 | F1 |
|---|---|---|
| ATLOP-BERT | 59.22 | 61.09 |
| DREERE-BERT | 59.96 | 61.84 |
| w/o axial attention | 59.28 | 61.20 |
| only attention network | 59.27 | 61.17 |
| w/o difficulties classification | 59.50 | 61.41 |
| 模型 | 开发集 | 测试集 | ||
|---|---|---|---|---|
| ign-F1 | F1 | ign-F1 | F1 | |
| Context-Aware | 42.06 | 53.05 | 45.37 | 56.58 |
| GAIN | 58.63 | 62.55 | 62.37 | 67.57 |
| SSAN | 58.62 | 64.49 | 62.58 | 69.39 |
| ATLOP | 59.03 | 64.82 | 62.09 | 69.94 |
| RSMAN | 60.02 | 65.88 | 63.42 | 70.95 |
| DREERE | 60.25 | 66.21 | 63.54 | 71.18 |
Tab.6 Experimental results on DWIE development and test sets
| 模型 | 开发集 | 测试集 | ||
|---|---|---|---|---|
| ign-F1 | F1 | ign-F1 | F1 | |
| Context-Aware | 42.06 | 53.05 | 45.37 | 56.58 |
| GAIN | 58.63 | 62.55 | 62.37 | 67.57 |
| SSAN | 58.62 | 64.49 | 62.58 | 69.39 |
| ATLOP | 59.03 | 64.82 | 62.09 | 69.94 |
| RSMAN | 60.02 | 65.88 | 63.42 | 70.95 |
| DREERE | 60.25 | 66.21 | 63.54 | 71.18 |

Fig. 4 Case study
| 1 | 谢德鹏,常青. 关系抽取综述[J]. 计算机应用研究, 2020, 37(7):1921-1924, 1930. |
| XIE D P, CHANG Q. Review of relation extraction[J]. Application Research of Computers, 2020, 37(7): 1921-1924, 1930. | |
| 2 | ZHOU W, HUANG K, MA T, et al. Document-level relation extraction with adaptive thresholding and localized context pooling[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 14612-14620. |
| 3 | XU B, WANG Q, LYU Y, et al. Entity structure within and throughout: modeling mention dependencies for document-level relation extraction[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021:14149-14157. |
| 4 | ZHANG N, CHEN X, XIE X, et al. Document-level relation extraction as semantic segmentation[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2021:3999-4006. |
| 5 | TAN Q, HE R, BING L, et al. Document-level relation extraction with adaptive focal loss and knowledge distillation[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022:1672-1681. |
| 6 | ZENG S, WU Y, CHANG B. SIRE: separate intra- and inter-sentential reasoning for document-level relation extraction[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 524-534. |
| 7 | MA Y, WANG A, OKAZAKI N. DREEAM: guiding attention with evidence for improving document-level relation extraction[C]// Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 1971-1983. |
| 8 | ZENG D, LIU K, CHEN Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015:1753-1762. |
| 9 | FENG J, HUANG M, ZHAO L, et al. Reinforcement learning for relation classification from noisy data [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 5779-5786. |
| 10 | YE D, LIN Y, DU J, et al. Coreferential reasoning learning for language representation [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 7170-7186. |
| 11 | WANG Z, WEN R, CHEN X, et al. Finding influential instances for distantly supervised relation extraction [C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 2639-2650. |
| 12 | 袁泉,陈昌平,陈泽,等.基于BERT的两次注意力机制远程监督关系抽取[J]. 计算机应用,2024, 44(4):1080-1085. |
| YUAN Q, CHEN C P, CHEN Z, et al. Twice attention mechanism distantly supervised relation extraction based on BER [J]. Journal of Computer Applications, 2024, 44(4): 1080-1085. | |
| 13 | YU H, ZHANG N, DENG S, et al. Bridging text and knowledge with multi-prototype embedding for few-shot relational triple extraction[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 6399-6410. |
| 14 | WU T, LI X, LI Y F, et al. Curriculum-meta learning for order-robust continual relation extraction[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021:10363-10369. |
| 15 | HUANG Y, LI Z, DENG W, et al. D-BERT: incorporating dependency-based attention into BERT for relation extraction [J]. CAAI Transactions on Intelligence Technology, 2021, 6(4): 417-425. |
| 16 | LI Z, HU F, WANG C, et al. Selective kernel networks for weakly supervised relation extraction[J]. CAAI Transactions on Intelligence Technology, 2021, 6(2): 224-234. |
| 17 | ZHANG G, CHEN S. Siamese representation learning for unsupervised relation extraction[C]// Proceedings of the 26th European Conference on Artificial Intelligence. Amsterdam: IOS Press, 2023: 3002-3009. |
| 18 | CHRISTOPOULOU F, MIWA M, ANANIADOU S. Connecting the dots: document-level neural relation extraction with edge-oriented graphs[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019:4925-4936. |
| 19 | LI B, YE W, SHENG Z, et al. Graph enhanced dual attention network for document-level relation extraction[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 1551-1560. |
| 20 | NAN G, GUO Z, SEKULIC I, et al. Reasoning with latent structure refinement for document-level relation extraction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020:1546-1557. |
| 21 | WANG D, HU W, CAO E, et al. Global-to-local neural networks for document-level relation extraction[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020:3711-3721. |
| 22 | SOROKIN D, GUREVYCH I. Context-aware representations for knowledge base relation extraction[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017:1784-1789. |
| 23 | ZENG S, XU R, CHANG B, et al. Double graph based reasoning for document-level relation extraction[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020:1630-1640. |
| 24 | XU W, CHEN K, ZHAO T.Document-level relation extraction with reconstruction [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 14167-14175. |
| 25 | ZHANG Z, YU B, SHU X, et al. Document-level relation extraction with dual-tier heterogeneous graph[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 1630-1641. |
| 26 | ZHOU H, XU Y, YAO W, et al. Global context-enhanced graph convolutional networks for document-level relation extraction[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020:5259-5270. |
| 27 | TANG H, CAO Y, ZHANG Z, et al. HIN: hierarchical inference network for document-level relation extraction[C]// Proceedings of the 2020 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 12084. Cham: Springer, 2020: 197-209. |
| 28 | HUANG K, QI P, WANG G, et al. Entity and evidence guided document-level relation extraction[C]// Proceedings of the 6th Workshop on Representation Learning for NLP. Stroudsburg: ACL, 2021: 307-315. |
| 29 | XIE Y, SHEN J, LI S, et al. Eider: evidence-enhanced document-level relation extraction [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 257-268. |
| 30 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 31 | YAO Y, YE D M, LI P, et al. DocRED: a large-scale document-level relation extraction dataset[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019:764-777. |
| 32 | TAN Q, XU L, BING L, et al. Revisiting DocRED-addressing the false negative problem in relation extraction[C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2022: 8472-8487. |
| 33 | ZAPOROJETS K, DELEU J, DEVELDER C, et al. DWIE: an entity-centric dataset for multi-task document-level information extraction[J]. Information Processing and Management, 2021, 58(4): No.102563. |
| 34 | WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg: ACL, 2020: 38-45. |
| 35 | DEVLIN J, CHANG M W, LEE K T, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019:4171-4186. |
| 36 | YU J, YANG D, TIAN S. Relation-specific attentions over entity mentions for enhanced document-level relation extraction[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2022:1523-1529. |
| [1] | Sheping ZHAI, Yan HUANG, Qing YANG, Rui YANG. Multi-view entity alignment combining triples and text attributes [J]. Journal of Computer Applications, 2025, 45(6): 1793-1800. |
| [2] | Man CHEN, Xiaojun YANG, Huimin YANG. Pedestrian trajectory prediction based on graph convolutional network and endpoint induction [J]. Journal of Computer Applications, 2025, 45(5): 1480-1487. |
| [3] | Jie HU, Cui WU, Jun SUN, Yan ZHANG. Document-level relation extraction model based on anaphora and logical reasoning [J]. Journal of Computer Applications, 2025, 45(5): 1496-1503. |
| [4] | Lu CHEN, Huaiyao WANG, Jingyang LIU, Tao YAN, Bin CHEN. Robotic grasp detection with feature fusion of spatial-Fourier domain information under low-light environments [J]. Journal of Computer Applications, 2025, 45(5): 1686-1693. |
| [5] | Hui LI, Bingzhi JIA, Chenxi WANG, Ziyu DONG, Jilong LI, Zhaoman ZHONG, Yanyan CHEN. Generative adversarial network underwater image enhancement model based on Swin Transformer [J]. Journal of Computer Applications, 2025, 45(5): 1439-1446. |
| [6] | Yufei LONG, Yuchen MOU, Ye LIU. Multi-source data representation learning model based on tensorized graph convolutional network and contrastive learning [J]. Journal of Computer Applications, 2025, 45(5): 1372-1378. |
| [7] | Dan WANG, Wenhao ZHANG, Lijuan PENG. Channel estimation of reconfigurable intelligent surface assisted communication system based on deep learning [J]. Journal of Computer Applications, 2025, 45(5): 1613-1618. |
| [8] | Jie HU, Qiyang ZHENG, Jun SUN, Yan ZHANG. Multi-label classification model based on multi-label relational graph and local dynamic reconstruction learning [J]. Journal of Computer Applications, 2025, 45(4): 1104-1112. |
| [9] | Guangju YANG, Tianjian LUO, Kaijun WANG, Siqi YANG. Multi-branch multi-view based contextual contrastive representation learning method for time series [J]. Journal of Computer Applications, 2025, 45(4): 1042-1052. |
| [10] | Liwei ZHANG, Quan LIANG, Yutao HU, Qiaole ZHU. Channel shuffle attention mechanism based on group convolution [J]. Journal of Computer Applications, 2025, 45(4): 1069-1076. |
| [11] | Kunyuan JIANG, Xiaoxia LI, Li WANG, Yaodan CAO, Xiaoqiang ZHANG, Nan DING, Yingyue ZHOU. Boundary-cross supervised semantic segmentation network with decoupled residual self-attention [J]. Journal of Computer Applications, 2025, 45(4): 1120-1129. |
| [12] | Chun XU, Shuangyan JI, Huan MA, Enwei SUN, Mengmeng WANG, Mingyu SU. Consultation recommendation method based on knowledge graph and dialogue structure [J]. Journal of Computer Applications, 2025, 45(4): 1157-1168. |
| [13] | Shiyue GUO, Jianwu DANG, Yangping WANG, Jiu YONG. 3D hand pose estimation combining attention mechanism and multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(4): 1293-1299. |
| [14] | Liqin WANG, Zhilei GENG, Yingshuang LI, Yongfeng DONG, Meng BIAN. Open-world knowledge reasoning model based on path and enhanced triplet text [J]. Journal of Computer Applications, 2025, 45(4): 1177-1183. |
| [15] | Haijun GENG, Yun DONG, Zhiguo HU, Haotian CHI, Jing YANG, Xia YIN. Encrypted traffic classification method based on Attention-1DCNN-CE [J]. Journal of Computer Applications, 2025, 45(3): 872-882. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||