


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (8): 2484-2490.DOI: 10.11772/j.issn.1001-9081.2024071015
• Artificial intelligence • Previous Articles
Wei ZHANG1, Jiaxiang NIU2( ), Jichao MA2, Qiongxia SHEN3
), Jichao MA2, Qiongxia SHEN3
Received:2024-07-18
Revised:2024-10-31
Accepted:2024-11-01
Online:2024-11-19
Published:2025-08-10
Contact:
Jiaxiang NIU
About author:ZHANG Wei, born in 1979, Ph. D., associate professor. His research interests include artificial intelligence.Supported by:
张伟1, 牛家祥2(), 马继超2, 沈琼霞3
通讯作者:
牛家祥
作者简介:张伟(1979—),男,湖北武汉人,副教授,博士,主要研究方向:人工智能基金资助:CLC Number:
Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features[J]. Journal of Computer Applications, 2025, 45(8): 2484-2490.
张伟, 牛家祥, 马继超, 沈琼霞. 深层语义特征增强的ReLM中文拼写纠错模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2484-2490.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024071015
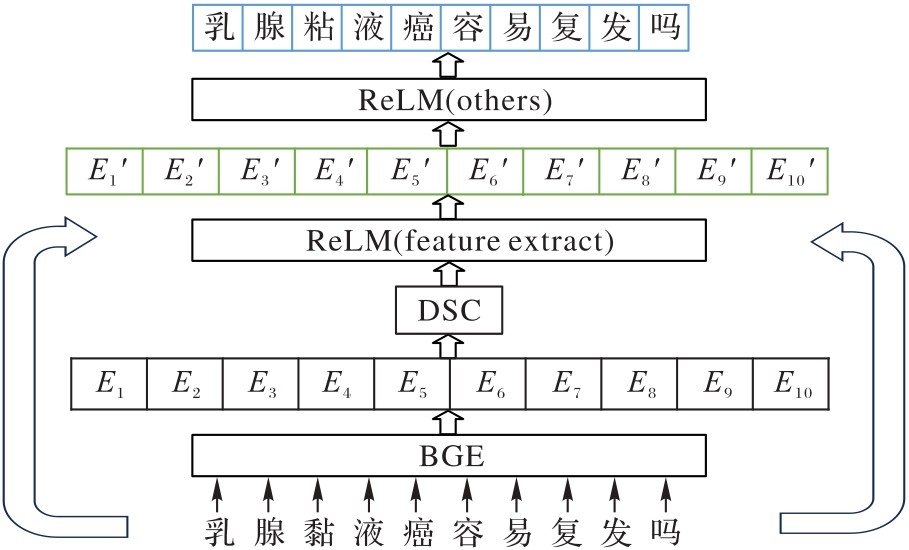
Fig. 1 Main framework of FeReLM

Fig. 2 Deep semantic features extracted by BGE model
| 数据集 | 句子数 | 平均长度 | 错字数 |
|---|---|---|---|
| EC-LAW | 2 460 | 30.5 | 2 071 |
| EC-MED | 3 500 | 50.1 | 2 616 |
| EC-ODW | 2 228 | 41.1 | 1 985 |
Tab. 1 Size of ECSpell dataset
| 数据集 | 句子数 | 平均长度 | 错字数 |
|---|---|---|---|
| EC-LAW | 2 460 | 30.5 | 2 071 |
| EC-MED | 3 500 | 50.1 | 2 616 |
| EC-ODW | 2 228 | 41.1 | 1 985 |
| 数据集 | 句子数 | 平均长度 | 错字数 |
|---|---|---|---|
| MCSC-Train | 1 571 934 | 10.9 | 146 503 |
| MCSC-Dev | 19 652 | 10.9 | 18 357 |
| MCSC-Test | 19 650 | 10.9 | 18 286 |
Tab. 2 Size of MCSC dataset
| 数据集 | 句子数 | 平均长度 | 错字数 |
|---|---|---|---|
| MCSC-Train | 1 571 934 | 10.9 | 146 503 |
| MCSC-Dev | 19 652 | 10.9 | 18 357 |
| MCSC-Test | 19 650 | 10.9 | 18 286 |
| 数据集 | 模型 | Precision | Recall | F1 |
|---|---|---|---|---|
| EC-LAW | BERT-tagging[ | 73.2 | 79.2 | 76.1 |
| MDCSpell[ | 77.5 | 83.9 | 80.6 | |
| ECSpell[ | 78.3 | 74.9 | 76.6 | |
| RSpell[ | 85.3 | 81.6 | 83.4 | |
| Baichuan2[ | 85.1 | 83.9 | 80.6 | |
| ReLM[ | 89.9 | 94.5 | 91.2 | |
| FeReLM | 90.5 | 97.5 | 93.9 | |
| EC-MED | BERT-tagging | 57.9 | 58.1 | 58.0 |
| MDCSpell | 69.9 | 69.3 | 69.6 | |
| ECSpell | 75.9 | 71.2 | 73.5 | |
| RSpell | 86.1 | 77.0 | 81.3 | |
| Baichuan2 | 72.6 | 73.9 | 73.2 | |
| ReLM | 79.2 | 85.9 | 82.4 | |
| FeReLM | 83.6 | 86.5 | 85.1 | |
| EC-ODW | BERT-tagging | 59.7 | 58.8 | 59.2 |
| MDCSpell | 65.7 | 68.2 | 66.9 | |
| ECSpell | 82.3 | 74.5 | 78.2 | |
| RSpell | 89.0 | 79.9 | 84.2 | |
| Baichuan2 | 86.1 | 79.3 | 82.6 | |
| ReLM | 82.4 | 84.8 | 83.6 | |
| FeReLM | 87.8 | 88.0 | 87.9 |
Tab. 3 Performance comparison of different models on ECSpell dataset
| 数据集 | 模型 | Precision | Recall | F1 |
|---|---|---|---|---|
| EC-LAW | BERT-tagging[ | 73.2 | 79.2 | 76.1 |
| MDCSpell[ | 77.5 | 83.9 | 80.6 | |
| ECSpell[ | 78.3 | 74.9 | 76.6 | |
| RSpell[ | 85.3 | 81.6 | 83.4 | |
| Baichuan2[ | 85.1 | 83.9 | 80.6 | |
| ReLM[ | 89.9 | 94.5 | 91.2 | |
| FeReLM | 90.5 | 97.5 | 93.9 | |
| EC-MED | BERT-tagging | 57.9 | 58.1 | 58.0 |
| MDCSpell | 69.9 | 69.3 | 69.6 | |
| ECSpell | 75.9 | 71.2 | 73.5 | |
| RSpell | 86.1 | 77.0 | 81.3 | |
| Baichuan2 | 72.6 | 73.9 | 73.2 | |
| ReLM | 79.2 | 85.9 | 82.4 | |
| FeReLM | 83.6 | 86.5 | 85.1 | |
| EC-ODW | BERT-tagging | 59.7 | 58.8 | 59.2 |
| MDCSpell | 65.7 | 68.2 | 66.9 | |
| ECSpell | 82.3 | 74.5 | 78.2 | |
| RSpell | 89.0 | 79.9 | 84.2 | |
| Baichuan2 | 86.1 | 79.3 | 82.6 | |
| ReLM | 82.4 | 84.8 | 83.6 | |
| FeReLM | 87.8 | 88.0 | 87.9 |
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| BERT-Corrector[ | 81.0 | 80.0 | 80.5 |
| MedBERT[ | 81.0 | 80.2 | 80.6 |
| Soft-Masked BERT[ | 81.2 | 80.5 | 80.9 |
| MCRSpell[ | 85.2 | 83.2 | 84.2 |
| ReLM[ | 84.7 | 84.9 | 84.8 |
| FeReLM | 85.7 | 86.2 | 86.0 |
Tab. 4 Performance comparison of different models on MCSC dataset
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| BERT-Corrector[ | 81.0 | 80.0 | 80.5 |
| MedBERT[ | 81.0 | 80.2 | 80.6 |
| Soft-Masked BERT[ | 81.2 | 80.5 | 80.9 |
| MCRSpell[ | 85.2 | 83.2 | 84.2 |
| ReLM[ | 84.7 | 84.9 | 84.8 |
| FeReLM | 85.7 | 86.2 | 86.0 |
| 数据集 | 模型 | Precision | Recall | F1 |
|---|---|---|---|---|
| EC-LAW | FeReLM(no fe) | 89.9 | 94.5 | 91.2 |
| FeReLM(no dsc) | 90.1 | 96.0 | 92.9 | |
| FeReLM | 90.8 | 97.1 | 93.8 | |
| EC-MED | FeReLM(no fe) | 79.2 | 85.9 | 82.4 |
| FeReLM(no dsc) | 82.4 | 86.4 | 84.4 | |
| FeReLM | 83.6 | 86.5 | 85.0 | |
| EC-ODW | FeReLM(no fe) | 82.4 | 84.8 | 83.6 |
| FeReLM(no dsc) | 87.0 | 87.9 | 87.5 | |
| FeReLM | 87.8 | 88.0 | 88.0 |
Tab. 5 Results of ablation experiments on ECSpell dataset
| 数据集 | 模型 | Precision | Recall | F1 |
|---|---|---|---|---|
| EC-LAW | FeReLM(no fe) | 89.9 | 94.5 | 91.2 |
| FeReLM(no dsc) | 90.1 | 96.0 | 92.9 | |
| FeReLM | 90.8 | 97.1 | 93.8 | |
| EC-MED | FeReLM(no fe) | 79.2 | 85.9 | 82.4 |
| FeReLM(no dsc) | 82.4 | 86.4 | 84.4 | |
| FeReLM | 83.6 | 86.5 | 85.0 | |
| EC-ODW | FeReLM(no fe) | 82.4 | 84.8 | 83.6 |
| FeReLM(no dsc) | 87.0 | 87.9 | 87.5 | |
| FeReLM | 87.8 | 88.0 | 88.0 |
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| FeReLM(no fe) | 84.7 | 84.9 | 84.8 |
| FeReLM(no dsc) | 85.3 | 86.1 | 85.8 |
| FeReLM | 85.7 | 86.2 | 86.0 |
Tab. 6 Results of ablation experiments on MCSC dataset
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| FeReLM(no fe) | 84.7 | 84.9 | 84.8 |
| FeReLM(no dsc) | 85.3 | 86.1 | 85.8 |
| FeReLM | 85.7 | 86.2 | 86.0 |

Fig. 3 Case study on ECSpell test set

Fig. 4 Case study on MCSC test set
| [1] | MARTINS B, SILVA M J. Spelling correction for search engine queries[C]// Proceedings of the 2004 International Conference on Natural Language Processing (in Spain), LNCS 3230. Berlin: Springer, 2004: 372-383. |
| [2] | LI Z, PARNOW K, ZHAO H. Incorporating rich syntax information in Grammatical Error Correction[J]. Information Processing and Management, 2022, 59(3): No.102891. |
| [3] | WANG P, ZHANG S, LI Z, et al. Enhancing ancient Chinese understanding with derived noisy syntax trees[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). Stroudsburg: ACL, 2023: 83-92. |
| [4] | WANG H, LI J, WU H, et al. Pre-trained language models and their applications[J]. Engineering, 2023, 25: 51-65. |
| [5] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [6] | HUANG L, LI J, JIANG W, et al. PHMOSpell: phonological and morphological knowledge guided Chinese spelling check[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 5958-5967. |
| [7] | 丁建平,李卫军,刘雪洋,等. 命名实体识别研究综述[J]. 计算机工程与科学, 2024, 46(7):1296-1310. |
| DING J P, LI W J, LIU X Y, et al. A review of named entity recognition research[J]. Computer Engineering and Science, 2024, 46(7):1296-1310. | |
| [8] | JI B, LI S, XU H, et al. Span-based joint entity and relation extraction augmented with sequence tagging mechanism[J]. SCIENCE CHINA Information Sciences, 2024, 67(5): No.152105. |
| [9] | LV Q, CAO Z, GENG L, et al. General and domain-adaptive Chinese spelling check with error-consistent pretraining[J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2023, 22(5): No.124. |
| [10] | TSENG Y H, LEE L H, CHANG L P, et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check[C]// Proceedings of the 8th SIGHAN Workshop on Chinese Language Processing. Stroudsburg: ACL, 2015: 32-37. |
| [11] | LIU L, WU H, ZHAO H. Chinese spelling correction as rephrasing language model[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 18662-18670. |
| [12] | XIAO S, LIU Z, ZHANG P, et al. C-pack: packaged resources to advance general Chinese embedding[C]// Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2024: 641-649. |
| [13] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807. |
| [14] | GAO Y, XIONG Y, GAO X, et al. Retrieval-augmented generation for large language models: a survey[EB/OL]. [2024-05-11].. |
| [15] | 赵国红. 中文语法纠错方法的研究综述[J]. 现代计算机, 2021, 27(28):65-69. |
| ZHAO G H. A survey of researches on Chinese grammar error correction methods[J]. Modern Computer, 2021, 27(28):65-69. | |
| [16] | WANG Y R, LIAO Y F. Word vector/conditional random field-based Chinese spelling error detection for SIGHAN-2015 evaluation[C]// Proceedings of the 8th SIGHAN Workshop on Chinese Language Processing. Stroudsburg: ACL, 2015: 46-49. |
| [17] | WANG D, SONG Y, LI J, et al. A hybrid approach to automatic corpus generation for Chinese spelling check[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2517-2527. |
| [18] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [19] | YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5753-5763. |
| [20] | JOSHI M, CHEN D, LIU Y, et al. SpanBERT: improving pre-training by representing and predicting spans[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 64-77. |
| [21] | CHENG X, XU W, CHEN K, et al. SpellGCN: incorporating phonological and visual similarities into language models for Chinese spelling check[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 871-881. |
| [22] | ZHANG S, HUANG H, LIU J, et al. Spelling error correction with soft-masked BERT[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 882-890. |
| [23] | ZHANG R, PANG C, ZHANG C, et al. Correcting Chinese spelling errors with phonetic pre-training[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 2250-2261. |
| [24] | ZHU C, YING Z, ZHANG B, et al. MDCSpell: a multi-task detector-corrector framework for Chinese spelling correction[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 1244-1253. |
| [25] | LI Y, ZHOU Q, LI Y, et al. The past mistake is the future wisdom: error-driven contrastive probability optimization for Chinese spell checking[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3202-3213. |
| [26] | FANG Z, ZHANG R, HE Z, et al. Non-autoregressive Chinese ASR error correction with phonological training[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2022: 5907-5917. |
| [27] | LIU S, SONG S, YUE T, et al. CRASpell: a contextual typo robust approach to improve Chinese spelling correction[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3008-3018. |
| [28] | WU H, ZHANG S, ZHANG Y, et al. Rethinking masked language modeling for Chinese spelling correction[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 10743-10756. |
| [29] | WEI X, HUANG J, YU H, et al. PTCSpell: pre-trained corrector based on character shape and pinyin for Chinese spelling correction[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 6330-6343. |
| [30] | LIANG H, SUN X, SUN Y, et al. Text feature extraction based on deep learning: a review[J]. EURASIP Journal on Wireless Communications and Networking, 2017, 2017: No.211. |
| [31] | CHEN J, XIAO S, ZHANG P, et al. M3-embedding: multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 2318-2335. |
| [32] | HOSSEINI S S, YAMAGHANI M R, POORZAKER ARABANI S. Multimodal modelling of human emotion using sound, image and text fusion[J]. Signal, Image and Video Processing, 2024, 18: 71-79. |
| [33] | JIANG W, YE Z, OU Z, et al. MCSCSet: a specialist-annotated dataset for medical-domain Chinese spelling correction[C]// Proceedings of the 31st ACM International Conference on Information and Knowledge Management. New York: ACM, 2022: 4084-4088. |
| [34] | SONG S, LV Q, GENG L, et al. RSpell: retrieval-augmented framework for domain adaptive Chinese spelling check[C]// Proceedings of the 2023 CCF International Conference on Natural Language Processing and Chinese Computing, LNCS 14302. Cham: Springer, 2023: 551-562. |
| [35] | Inc Baichuan. Baichuan 2: open large-scale language models[EB/OL]. [2024-05-11].. |
| [36] | LI C, ZHANG M, ZHANG X, et al. MCRSpell: a metric learning of correct representation for Chinese spelling correction[J]. Expert Systems with Applications, 2024, 237(Pt B): No.121513. |
| [37] | WU S H, LIU C L, LEE L H. Chinese spelling check evaluation at SIGHAN bake-off 2013[C]// Proceedings of the 7th SIGHAN Workshop on Chinese Language Processing. [S.l.]: Asian Federation of Natural Language Processing, 2013: 35-42. |
| [38] | YU L C, LEE L H, TSENG Y H, et al. Overview of SIGHAN 2014 bake-off for Chinese spelling check[C]// Proceedings of the 3rd CIPS-SIGHAN Joint Conference on Chinese Language Processing. Stroudsburg: ACL, 2014: 126-132. |
| [1] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [2] | Ziliang LI, Guangli ZHU, Yulei ZHANG, Jiajia LIU, Yixuan JIAO, Shunxiang ZHANG. Aspect-based sentiment analysis model integrating syntax and sentiment knowledge [J]. Journal of Computer Applications, 2025, 45(6): 1724-1731. |
| [3] | Qing ZHANG, Fan YANG, Yuhan FANG. Chinese spelling correction algorithm based on multi-modal information fusion [J]. Journal of Computer Applications, 2025, 45(5): 1528-1534. |
| [4] | Malei SHEN, Zhicai SHI, Yongbin GAO, Jianyang HU. Fact verification of semantic fusion collaborative reasoning based on graph embedding [J]. Journal of Computer Applications, 2025, 45(4): 1184-1189. |
| [5] | Can MA, Ruizhang HUANG, Lina REN, Ruina BAI, Yaoyao WU. Chinese spelling correction method based on LLM with multiple inputs [J]. Journal of Computer Applications, 2025, 45(3): 849-855. |
| [6] | Weichao DANG, Yinghao FAN, Gaimei GAO, Chunxia LIU. Weakly supervised action localization based on temporal and global contextual feature enhancement [J]. Journal of Computer Applications, 2025, 45(3): 963-971. |
| [7] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [8] | Benchen YANG, Haoran LI, Haibo JIN. Multi-focus image fusion network with cascade fusion and enhanced reconstruction [J]. Journal of Computer Applications, 2025, 45(2): 594-600. |
| [9] | Binhong XIE, Wanyin GAO, Wangdong LU, Yingjun ZHANG, Rui ZHANG. Dense object counting network with few-shot similarity matching feature enhancement [J]. Journal of Computer Applications, 2025, 45(2): 403-410. |
| [10] | Bin LI, Min LIN, Siriguleng, Yingjie GAO, Yurong WANG, Shujun ZHANG. Joint entity-relation extraction method for ancient Chinese books based on prompt learning and global pointer network [J]. Journal of Computer Applications, 2025, 45(1): 75-81. |
| [11] | Xueqiang LYU, Tao WANG, Xindong YOU, Ge XU. HTLR: named entity recognition framework with hierarchical fusion of multi-knowledge [J]. Journal of Computer Applications, 2025, 45(1): 40-47. |
| [12] | Qi SHUAI, Hairui WANG, Guifu ZHU. Chinese story ending generation model based on bidirectional contrastive training [J]. Journal of Computer Applications, 2024, 44(9): 2683-2688. |
| [13] | Quanmei ZHANG, Runping HUANG, Fei TENG, Haibo ZHANG, Nan ZHOU. Automatic international classification of disease coding method incorporating heterogeneous information [J]. Journal of Computer Applications, 2024, 44(8): 2476-2482. |
| [14] | Youren YU, Yangsen ZHANG, Yuru JIANG, Gaijuan HUANG. Chinese named entity recognition model incorporating multi-granularity linguistic knowledge and hierarchical information [J]. Journal of Computer Applications, 2024, 44(6): 1706-1712. |
| [15] | Chao WEI, Yanping CHEN, Kai WANG, Yongbin QIN, Ruizhang HUANG. Relation extraction method based on mask prompt and gated memory network calibration [J]. Journal of Computer Applications, 2024, 44(6): 1713-1719. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||