


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (8): 2442-2447.DOI: 10.11772/j.issn.1001-9081.2024081083
• The 21th CCF Conference on Web Information Systems and Applications (WISA 2024) • Previous Articles
Received:2024-08-02
Revised:2024-09-02
Accepted:2024-09-05
Online:2024-09-12
Published:2025-08-10
Contact:
Chen LIU
About author:FENG Tao, born in 2000, M. S. candidate. His research interests include distributed system and cloud computing.
Supported by:
冯涛1,2, 刘晨1,2( )
)
通讯作者:
刘晨
作者简介:冯涛(2000—),男,山西大同人,硕士研究生,主要研究方向:分布式系统与云计算
基金资助:CLC Number:
Tao FENG, Chen LIU. Dual-stage prompt tuning method for automated preference alignment[J]. Journal of Computer Applications, 2025, 45(8): 2442-2447.
冯涛, 刘晨. 自动化偏好对齐的双阶段提示调优方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2442-2447.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081083

Fig. 1 Comparison of prompts with different professional depths
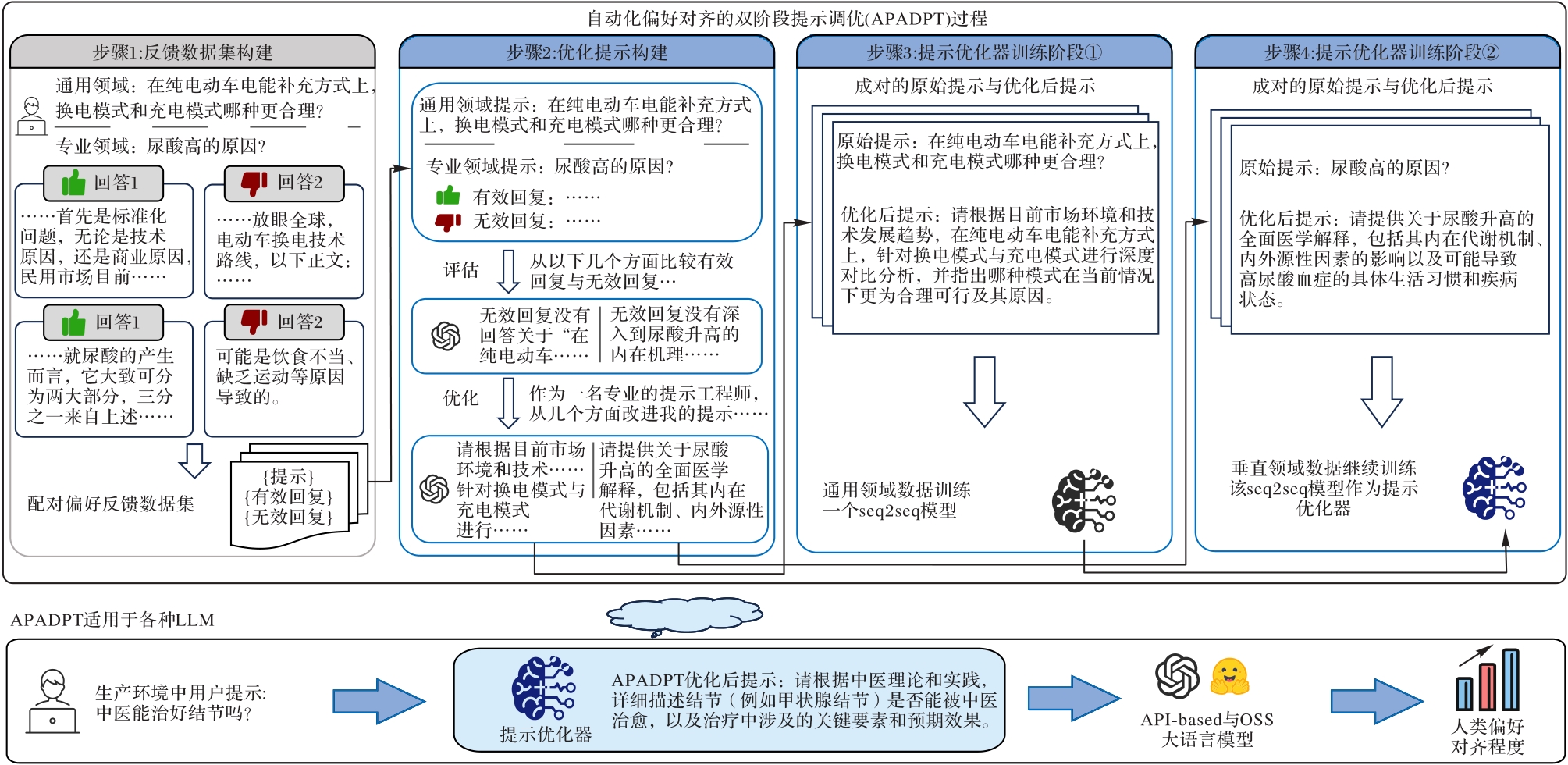
Fig. 2 Structure of APADPT
| 数据集 | 领域 | 原始对话数 | 过滤后对话数 | 语句数 | 平均 字符数 |
|---|---|---|---|---|---|
| zhihu_rlhf_3k | 通用 | 3 460 | 2 915 | 8 745 | 525.73 |
| medical | 医疗 | 3 800 | 3 593 | 10 779 | 80.97 |
Tab. 1 Statistical information of datasets
| 数据集 | 领域 | 原始对话数 | 过滤后对话数 | 语句数 | 平均 字符数 |
|---|---|---|---|---|---|
| zhihu_rlhf_3k | 通用 | 3 460 | 2 915 | 8 745 | 525.73 |
| medical | 医疗 | 3 800 | 3 593 | 10 779 | 80.97 |
| 基础模型 | 方法 | APADPT-test 验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| ChatGPT-3.5-turbo | APADPT | ORI. | 55.0 | 11.0 | 34.0 | 50.0 | 13.0 | 37.0 | +17.0 |
| ChatGPT-4 | APADPT | ORI. | 43.0 | 21.0 | 36.0 | 49.0 | 18.0 | 33.0 | +11.5 |
| ERNIE-Bot 4.0 | APADPT | ORI. | 47.0 | 14.0 | 39.0 | 41.0 | 29.0 | 30.0 | +9.5 |
| ChatGLM4 | APADPT | ORI. | 52.0 | 10.0 | 38.0 | 46.0 | 19.0 | 35.0 | +12.5 |
| Qwen2.1 | APADPT | ORI. | 52.0 | 5.0 | 43.0 | 55.0 | 3.0 | 42.0 | +11.0 |
Tab. 2 Experimental comparison results of API-based LLM
| 基础模型 | 方法 | APADPT-test 验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| ChatGPT-3.5-turbo | APADPT | ORI. | 55.0 | 11.0 | 34.0 | 50.0 | 13.0 | 37.0 | +17.0 |
| ChatGPT-4 | APADPT | ORI. | 43.0 | 21.0 | 36.0 | 49.0 | 18.0 | 33.0 | +11.5 |
| ERNIE-Bot 4.0 | APADPT | ORI. | 47.0 | 14.0 | 39.0 | 41.0 | 29.0 | 30.0 | +9.5 |
| ChatGLM4 | APADPT | ORI. | 52.0 | 10.0 | 38.0 | 46.0 | 19.0 | 35.0 | +12.5 |
| Qwen2.1 | APADPT | ORI. | 52.0 | 5.0 | 43.0 | 55.0 | 3.0 | 42.0 | +11.0 |
| 基础模型 | 方法 | APADPT-test验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| Qwen1.5-chat | 7B+APADPT | 7B | 56.0 | 13.0 | 31.0 | 52.0 | 12.0 | 36.0 | +20.5 |
| 14B+APADPT | 14B | 53.0 | 15.0 | 32.0 | 50.0 | 13.0 | 37.0 | +17.0 | |
| 7B+APADPT | 72B | 46.0 | 6.0 | 48.0 | 40.0 | 5.0 | 55.0 | -8.5 | |
| 14B+APADPT | 72B | 50.0 | 9.0 | 41.0 | 54.0 | 7.0 | 39.0 | +12.0 | |
| 72B+APADPT | 72B | 51.0 | 7.0 | 42.0 | 53.0 | 11.0 | 36.0 | +13.0 | |
| 72B+APADPT | Qwen2.1 | 44.0 | 9.0 | 47.0 | 45.0 | 2.0 | 53.0 | -5.5 | |
Tab. 3 Experimental comparison results of open-source LLM
| 基础模型 | 方法 | APADPT-test验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| Qwen1.5-chat | 7B+APADPT | 7B | 56.0 | 13.0 | 31.0 | 52.0 | 12.0 | 36.0 | +20.5 |
| 14B+APADPT | 14B | 53.0 | 15.0 | 32.0 | 50.0 | 13.0 | 37.0 | +17.0 | |
| 7B+APADPT | 72B | 46.0 | 6.0 | 48.0 | 40.0 | 5.0 | 55.0 | -8.5 | |
| 14B+APADPT | 72B | 50.0 | 9.0 | 41.0 | 54.0 | 7.0 | 39.0 | +12.0 | |
| 72B+APADPT | 72B | 51.0 | 7.0 | 42.0 | 53.0 | 11.0 | 36.0 | +13.0 | |
| 72B+APADPT | Qwen2.1 | 44.0 | 9.0 | 47.0 | 45.0 | 2.0 | 53.0 | -5.5 | |
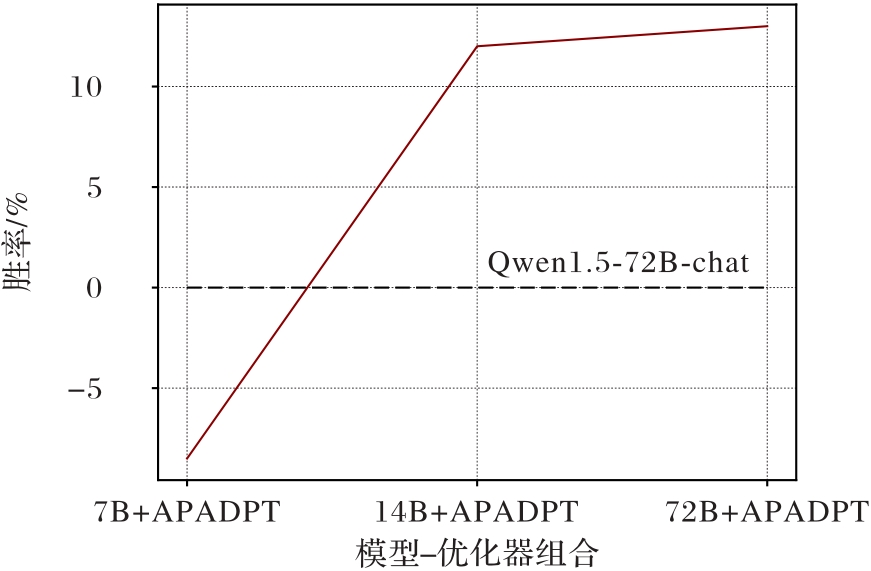
Fig. 3 Comparison of winning rates between APADPT optimized and original output in Qwen1.5-cat models of different sizes
| 基础模型 | 方法 | APADPT-test 验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| ChatGPT-4 | APADPT-1 | ORI. | 46.0 | 14.0 | 40.0 | 49.0 | 11.0 | 40.0 | +7.5 |
| APADPT-2 | ORI. | 50.0 | 8.0 | 42.0 | 47.0 | 10.0 | 43.0 | +6.0 | |
| APADPT | ORI. | 43.0 | 21.0 | 36.0 | 49.0 | 18.0 | 33.0 | +11.5 | |
Tab. 4 Experimental comparison results of API-based LLM in different stages of APADPT
| 基础模型 | 方法 | APADPT-test 验证 | MMTD验证 | ΔWR/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | AWIN | TIE | BWIN | AWIN | TIE | BWIN | ||
| ChatGPT-4 | APADPT-1 | ORI. | 46.0 | 14.0 | 40.0 | 49.0 | 11.0 | 40.0 | +7.5 |
| APADPT-2 | ORI. | 50.0 | 8.0 | 42.0 | 47.0 | 10.0 | 43.0 | +6.0 | |
| APADPT | ORI. | 43.0 | 21.0 | 36.0 | 49.0 | 18.0 | 33.0 | +11.5 | |

Fig. 4 APADPT optimization types and different stage examples
| [1] | 陈浩泷,陈罕之,韩凯峰,等. 垂直领域大模型的定制化:理论基础与关键技术[J]. 数据采集与处理, 2024, 39(3): 524-546. |
| CHEN H L, CHEN H Z, HAN K F, et al. Customization of vertical domain large model: theoretical basis and key technology[J]. Journal of Data Acquisition and Processing, 2024, 39(3): 524-546. | |
| [2] | 郭华源,刘盼,卢若谷,等. 人工智能大模型医学应用研究[J]. 中国科学:生命科学, 2024, 54(3):482-506. |
| GUO H Y, LIU P, LU R G, et al. Research on a massively large artificial intelligence model and its application in medicine[J]. SCIENTIA SINICA Vitae, 2024, 54(3):482-506. | |
| [3] | OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 27730-27744. |
| [4] | BAI Y, KADAVATH S, KUNDU S, et al. Constitutional AI: harmlessness from AI feedback[EB/OL]. [2024-08-15].. |
| [5] | LEE H, PHATALE S, MANSOOR H, et al. RLAIF: scaling reinforcement learning from human feedback with AI feedback[EB/OL]. [2024-08-15].. |
| [6] | RAFAILOV R, SHARMA A, MITCHELL E, et al. Direct preference optimization: your language model is secretly a reward model[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 53728-53741. |
| [7] | CHENG J, LIU X, ZHENG K, et al. Black-box prompt optimization: aligning large language models without model training[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 3201-3219. |
| [8] | WANG Y, KORDI Y, MISHRA S, et al. Self-Instruct: aligning language models with self-generated instructions[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 13484-13508. |
| [9] | SUN Z, SHEN Y, ZHOU Q, et al. Principle-driven self-alignment of language models from scratch with minimal human supervision[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 2511-2565. |
| [10] | SHIN T, RAZEGHI Y, LOGAN R L, Ⅳ, et al. AutoPrompt: eliciting knowledge from language models with automatically generated prompts[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 4222-4235. |
| [11] | ZHOU Y, MURESANU A I, HAN Z, et al. Large language models are human-level prompt engineers[EB/OL]. [2024-07-21].. |
| [12] | YANG C, WANG X, LU Y, et al. Large language models as optimizers[EB/OL]. [2024-07-21].. |
| [13] | SUZGUN M, SCALES N, SCHÄRLI N, et al. Challenging big-bench tasks and whether chain-of-thought can solve them[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 13003-13051. |
| [14] | LIU X, ZHENG Y, DU Z, et al. GPT understands, too[J]. AI Open, 2024, 5: 208-215. |
| [15] | LESTER B, AL-RFOU R, CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 3045-3059. |
| [16] | LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4582-4597. |
| [17] | WANG Y, YU Z, ZENG Z, et al. PandaLM: an automatic evaluation benchmark for LLM instruction tuning optimization[EB/OL]. [2024-07-21].. |
| [18] | ZHENG L, CHIANG W L, SHENG Y, et al. Judging LLM-as-a-judge with MT-bench and Chatbot Arena[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 46595-46623. |
| [19] | CHEN X, LIANG C, HUANG D, et al. Symbolic discovery of optimization algorithms[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2024: 49205-49233. |
| [20] | WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg: ACL, 2020: 38-45. |
| [21] | HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. [2024-07-21].. |
| [22] | REN Q, LI K, YANG D, et al. TCM function multi-classification approach using deep learning models[C]// Proceedings of the 2023 International Conference on Web Information Systems and Applications, LNCS 14094. Singapore: Springer, 2023: 246-258. |
| [1] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [2] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [3] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [4] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [5] | Can MA, Ruizhang HUANG, Lina REN, Ruina BAI, Yaoyao WU. Chinese spelling correction method based on LLM with multiple inputs [J]. Journal of Computer Applications, 2025, 45(3): 849-855. |
| [6] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [7] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [8] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [9] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [10] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [11] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [12] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [13] | Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking [J]. Journal of Computer Applications, 2024, 44(10): 3067-3073. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||