


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 732-738.DOI: 10.11772/j.issn.1001-9081.2024081139
• Frontier research and typical applications of large models • Previous Articles Next Articles
Yuanlong WANG( ), Tinghua LIU, Hu ZHANG
), Tinghua LIU, Hu ZHANG
Received:2024-08-12
Revised:2024-09-09
Accepted:2024-09-13
Online:2024-09-25
Published:2025-03-10
Contact:
Yuanlong WANG
About author:LIU Tinghua, born in 1998, M. S. candidate. Her research interests include natural language processing.Supported by:
王元龙(), 刘亭华, 张虎
通讯作者:
王元龙
作者简介:刘亭华(1998—),女,山西临汾人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Yuanlong WANG, Tinghua LIU, Hu ZHANG. Commonsense question answering model based on cross-modal contrastive learning[J]. Journal of Computer Applications, 2025, 45(3): 732-738.
王元龙, 刘亭华, 张虎. 基于跨模态对比学习的常识问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 732-738.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081139
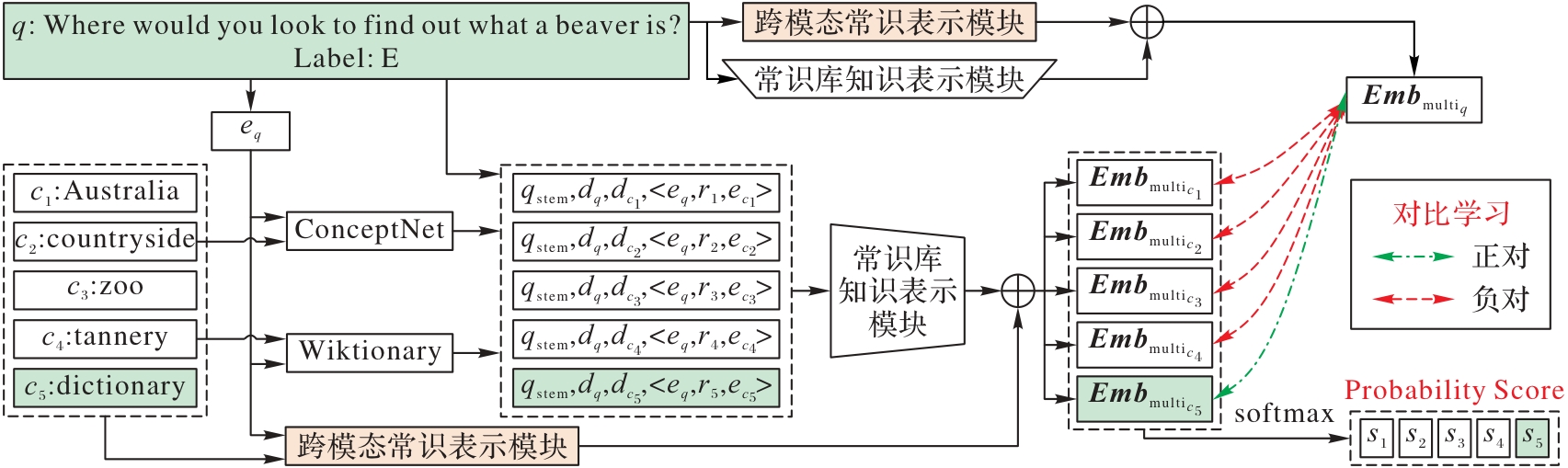
Fig. 1 Framework of proposed model
| 方法 | 划分验证集准确率 | 划分测试集准确率 |
|---|---|---|
| RGCN[ | 72.69(±0.19) | 68.41(±0.66) |
| KagNet[ | 73.47(±0.22) | 69.01(±0.76) |
| QA-GNN[ | 76.54(±0.21) | 73.41(±0.92) |
| GREASELM[ | 78.50(±0.50) | 74.20(±0.40) |
| MHGRN[ | 73.88(±0.25) | 70.31(±0.83) |
| DEKCOR[ | 83.31(±0.23) | 81.78(±0.39) |
| ChatGPT*[ | — | 74.00 |
| DHLK[ | 79.39 (±0.24) | 74.68(±0.26) |
| CPACE[ | 88.40 | — |
| 本文方法 | 86.24(±0.26) | 83.24(±0.17) |
Tab. 1 Performance comparison of different methods on CSQA training and test sets
| 方法 | 划分验证集准确率 | 划分测试集准确率 |
|---|---|---|
| RGCN[ | 72.69(±0.19) | 68.41(±0.66) |
| KagNet[ | 73.47(±0.22) | 69.01(±0.76) |
| QA-GNN[ | 76.54(±0.21) | 73.41(±0.92) |
| GREASELM[ | 78.50(±0.50) | 74.20(±0.40) |
| MHGRN[ | 73.88(±0.25) | 70.31(±0.83) |
| DEKCOR[ | 83.31(±0.23) | 81.78(±0.39) |
| ChatGPT*[ | — | 74.00 |
| DHLK[ | 79.39 (±0.24) | 74.68(±0.26) |
| CPACE[ | 88.40 | — |
| 本文方法 | 86.24(±0.26) | 83.24(±0.17) |
| 方法 | 测试集准确率 |
|---|---|
| RGCN[ | 62.45(±1.57) |
| QA-GNN[ | 70.58(±1.42) |
| GREASELM[ | — |
| MHGRN[ | 66.85(±1.19) |
| DEKCOR[ | 82.40 |
| ChatGPT*[ | 73.00 |
| DHLK[ | 72.20(±0.40) |
| 本文方法 | 83.11(±0.36) |
Tab. 2 Performance comparison on OBQA test set
| 方法 | 测试集准确率 |
|---|---|
| RGCN[ | 62.45(±1.57) |
| QA-GNN[ | 70.58(±1.42) |
| GREASELM[ | — |
| MHGRN[ | 66.85(±1.19) |
| DEKCOR[ | 82.40 |
| ChatGPT*[ | 73.00 |
| DHLK[ | 72.20(±0.40) |
| 本文方法 | 83.11(±0.36) |
| 方法 | 划分测试集准确率 |
|---|---|
| 本文方法 | 83.24 |
| 本文方法-multi | 81.39 |
| 本文方法-con | 82.11 |
| 本文方法-K_text | 78.08 |
| 本文方法-K_text-multi | 78.16 |
| 本文方法-K_text-con | 79.85 |
| 本文方法-multi-con | 80.90 |
Tab. 3 Ablation experiment results on CSQA test set
| 方法 | 划分测试集准确率 |
|---|---|
| 本文方法 | 83.24 |
| 本文方法-multi | 81.39 |
| 本文方法-con | 82.11 |
| 本文方法-K_text | 78.08 |
| 本文方法-K_text-multi | 78.16 |
| 本文方法-K_text-con | 79.85 |
| 本文方法-multi-con | 80.90 |
| 序号 | 示例 | DEKCOR的预测结果 | 本文模型的预测结果 |
|---|---|---|---|
| 1 | Question: What green area is a marmot likely to be found in? Choices: A. countryside B. great plains C. encyclopedia D. jungle E. north America | D. jungle | A. countryside |
| 2 | Question: Where would you keep an ottoman near your front door? Choices: A. living room B. parlor C. furniture store D. basement E. kitchen | B. parlor | A. living room |
| 3 | Question: Where is a monkey likely to enjoy being? Choices: A. banana tree B. sailor suit C. theatre D. mulberry bush E. research laboratory | D. mulberry bush | A. banana tree |
Tab. 4 Example studies on CSQA dataset
| 序号 | 示例 | DEKCOR的预测结果 | 本文模型的预测结果 |
|---|---|---|---|
| 1 | Question: What green area is a marmot likely to be found in? Choices: A. countryside B. great plains C. encyclopedia D. jungle E. north America | D. jungle | A. countryside |
| 2 | Question: Where would you keep an ottoman near your front door? Choices: A. living room B. parlor C. furniture store D. basement E. kitchen | B. parlor | A. living room |
| 3 | Question: Where is a monkey likely to enjoy being? Choices: A. banana tree B. sailor suit C. theatre D. mulberry bush E. research laboratory | D. mulberry bush | A. banana tree |
| CLIP的输入序列 | 准确率/% | 准确率变化百分点 |
|---|---|---|
| 80.90 | -0.88 | |
| 82.84 | +1.06 | |
| 82.03 | +0.25 | |
| 83.16 | +1.38 | |
| 83.24 | +1.46 | |
| 80.18 | -1.60 | |
| 79.94 | -1.84 |
Tab. 5 Experimental analysis of cross-modal commonsense representation
| CLIP的输入序列 | 准确率/% | 准确率变化百分点 |
|---|---|---|
| 80.90 | -0.88 | |
| 82.84 | +1.06 | |
| 82.03 | +0.25 | |
| 83.16 | +1.38 | |
| 83.24 | +1.46 | |
| 80.18 | -1.60 | |
| 79.94 | -1.84 |
| 多模态大模型 | 准确率 |
|---|---|
| CLIP | 83.24 |
| BLIP | 79.05 |
| Gemini | 81.73 |
Tab. 6 Comparison results of multi-modal large models
| 多模态大模型 | 准确率 |
|---|---|
| CLIP | 83.24 |
| BLIP | 79.05 |
| Gemini | 81.73 |
| 1 | 范怡帆,邹博伟,徐庆婷,等. 常识问答研究综述[J]. 软件学报, 2024, 35(1): 236-265. |
| FAN Y F, ZOU B W, XU Q T, et al. Survey on commonsense question answering [J]. Journal of Software, 2024, 35(1): 236-265. | |
| 2 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2023-11-20]. . |
| 3 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2023-11-22]. . |
| 4 | LIN B Y, CHEN X, CHEN J, et al. KagNet: knowledge-aware graph networks for commonsense reasoning [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 2829-2839. |
| 5 | FENG Y, CHEN X, LIN B Y, et al. Scalable multi-hop relational reasoning for knowledge-aware question answering [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 1295-1309. |
| 6 | FELLBAUM C. WordNet: an electronic lexical database [M]. Cambridge: MIT Press, 1998. |
| 7 | BAKER C F, FILLMORE C J, LOWE J B. The Berkeley FrameNet project [C]// Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Volume 1. New Brunswick, NJ: ACL, 1998: 86-90. |
| 8 | VRANDEČIĆ D, KRÖTZSCH M. Wikidata: a free collaborative knowledgebase [J]. Communications of the ACM, 2014, 57(10): 78-85. |
| 9 | PELLISSIER TANON T, WEIKUM G, SUCHANEK F. YAGO 4: a reason-able knowledge base [C]// Proceedings of the 2020 European Semantic Web Conference, LNCS 12123. Cham: Springer, 2020: 583-596. |
| 10 | SAP M, LE BRAS R, ALLAWAY E, et al. ATOMIC: an atlas of machine commonsense for if-then reasoning [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 3027-3035. |
| 11 | KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations [J]. International Journal of Computer Vision, 2017, 123(1): 32-73. |
| 12 | ILIEVSKI F, SZEKELY P, ZHANG B. CSKG: the commonsense knowledge graph [C]// Proceedings of the 2021 European Semantic Web Conference, LNCS 12731. Cham: Springer, 2021: 680-696. |
| 13 | SPEER R, CHIN J, HAVASI C. ConceptNet 5.5: an open multilingual graph of general knowledge [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 4444-4451. |
| 14 | TAN H, BANSAL M. LXMERT: learning cross-modality encoder representations from Transformers [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 5100-5111. |
| 15 | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 13-23. |
| 16 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 17 | LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 12888-12900. |
| 18 | YASUNAGA M, REN H, BOSSELUT A, et al. QA-GNN: reasoning with language models and knowledge graphs for question answering [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 535-546. |
| 19 | ZHANG X, BOSSELUT A, YASUNAGA M, et al. GreaseLM: graph reasoning enhanced language models for question answering[EB/OL]. [2023-10-08]. . |
| 20 | WANG Y, ZHANG H, LIANG J, et al. Dynamic heterogeneous-graph reasoning with language models and knowledge representation learning for commonsense question answering [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 14048-14063. |
| 21 | XU Y, ZHU C, XU R, et al. Fusing context into knowledge graph for commonsense question answering [C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 1201-1207. |
| 22 | XU Y, ZHU C, WANG S, et al. Human parity on CommonSenseQA: augmenting self-attention with external attention [C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2022: 2762-2768. |
| 23 | CHEN Q, XU G, YAN M, et al. Distinguish before answer: generating contrastive explanation as knowledge for commonsense question answering [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 13207-13224. |
| 24 | LIN J. ALBERT + KCR(knowledge chosen by relations) [EB/OL]. [2023-07-20]. . |
| 25 | LI G, GAN Y, WU H, et al. Cross-modal attentional context learning for RGB-D object detection [J]. IEEE Transactions on Image Processing, 2019, 28(4): 1591-1601. |
| 26 | MIHAYLOV T, CLARK P, KHOT T, et al. Can a suit of armor conduct electricity? a new dataset for open book question answering[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2381-2391. |
| 27 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. [2023-11-14]. . |
| 28 | SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// Proceedings of the 2018 European Semantic Web Conference, LNCS 10843. Cham: Springer, 2018: 593-607. |
| 29 | BIAN N, HAN X, SUN L, et al. ChatGPT is a knowledgeable but inexperienced solver: an investigation of commonsense problem in large language models [C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA Language Resources Association, 2024: 3098-3110. |
| [1] | Sheng YANG, Yan LI. Contrastive knowledge distillation method for object detection [J]. Journal of Computer Applications, 2025, 45(2): 354-361. |
| [2] | Xiaosheng YU, Zhixin WANG. Sequential recommendation model based on multi-level graph contrastive learning [J]. Journal of Computer Applications, 2025, 45(1): 106-114. |
| [3] | Xingyao YANG, Yu CHEN, Jiong YU, Zulian ZHANG, Jiaying CHEN, Dongxiao WANG. Recommendation model combining self-features and contrastive learning [J]. Journal of Computer Applications, 2024, 44(9): 2704-2710. |
| [4] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [5] | Xiaoxia JIANG, Ruizhang HUANG, Ruina BAI, Lina REN, Yanping CHEN. Deep event clustering method based on event representation and contrastive learning [J]. Journal of Computer Applications, 2024, 44(6): 1734-1742. |
| [6] | Jiong WANG, Taotao TANG, Caiyan JIA. PAGCL: positive augmentation graph contrastive learning recommendation method without negative sampling [J]. Journal of Computer Applications, 2024, 44(5): 1485-1492. |
| [7] | Jie GUO, Jiayu LIN, Zuhong LIANG, Xiaobo LUO, Haitao SUN. Recommendation method based on knowledge‑awareness and cross-level contrastive learning [J]. Journal of Computer Applications, 2024, 44(4): 1121-1127. |
| [8] | Weichao DANG, Lei ZHANG, Gaimei GAO, Chunxia LIU. Weakly supervised action localization method with snippet contrastive learning [J]. Journal of Computer Applications, 2024, 44(2): 548-555. |
| [9] | Xingyao YANG, Hongtao SHEN, Zulian ZHANG, Jiong YU, Jiaying CHEN, Dongxiao WANG. Sequential recommendation based on hierarchical filter and temporal convolution enhanced self-attention network [J]. Journal of Computer Applications, 2024, 44(10): 3090-3096. |
| [10] | Yunhua ZHU, Bing KONG, Lihua ZHOU, Hongmei CHEN, Chongming BAO. Multi-view clustering network guided by graph contrastive learning [J]. Journal of Computer Applications, 2024, 44(10): 3267-3274. |
| [11] | Wei TONG, Liyang HE, Rui LI, Wei HUANG, Zhenya HUANG, Qi LIU. Efficient similar exercise retrieval model based on unsupervised semantic hashing [J]. Journal of Computer Applications, 2024, 44(1): 206-216. |
| [12] | Yirui HUANG, Junwei LUO, Jingqiang CHEN. Multi-modal dialog reply retrieval based on contrast learning and GIF tag [J]. Journal of Computer Applications, 2024, 44(1): 32-38. |
| [13] | Jingsheng LEI, Kaijun LA, Shengying YANG, Yi WU. Joint entity and relation extraction based on contextual semantic enhancement [J]. Journal of Computer Applications, 2023, 43(5): 1438-1444. |
| [14] | Rong GAO, Jiawei SHEN, Xiongkai SHAO, Xinyun WU. Instance segmentation algorithm based on Fastformer and self-supervised contrastive learning [J]. Journal of Computer Applications, 2023, 43(4): 1062-1070. |
| [15] | Weichao DANG, Bingyang CHENG, Gaimei GAO, Chunxia LIU. Contrastive hypergraph transformer for session-based recommendation [J]. Journal of Computer Applications, 2023, 43(12): 3683-3688. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||