


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (8): 2497-2506.DOI: 10.11772/j.issn.1001-9081.2024081141
• Artificial intelligence • Previous Articles
Zhiyuan WANG1, Tao PENG1,2( ), Jie YANG3
), Jie YANG3
Received:2024-08-14
Revised:2024-10-18
Accepted:2024-10-21
Online:2024-11-07
Published:2025-08-10
Contact:
Tao PENG
About author:WANG Zhiyuan, born in 2000, M. S. candidate. Her research interests include natural language processing.Supported by:
王祉苑1, 彭涛1,2(), 杨捷3
通讯作者:
彭涛
作者简介:王祉苑(2000—),女,湖北十堰人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Zhiyuan WANG, Tao PENG, Jie YANG. Integrating internal and external data for out-of-distribution detection training and testing[J]. Journal of Computer Applications, 2025, 45(8): 2497-2506.
王祉苑, 彭涛, 杨捷. 分布外检测中训练与测试的内外数据整合[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2497-2506.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081141
| 实例 | 语义标签 | 样本偏移类型 |
|---|---|---|
| ①这家餐厅的环境很好。 | 正面 | ID样本 |
| ②食物不新鲜,我不会再来这用餐。 | 负面 | ID样本 |
| ③喜马拉雅山的高度为8 848.86米。 | 未知 | 语义偏移类型 |
| ④明天天气如何? | 未知 | 语义偏移类型 |
| ⑤这是一部优秀的电影。 | 正面 | 背景偏移类型 |
| ⑥这部动画剧情混乱,令人失望。 | 负面 | 背景偏移类型 |
Tab. 1 Specific examples of OOD samples of semantic/background offset types
| 实例 | 语义标签 | 样本偏移类型 |
|---|---|---|
| ①这家餐厅的环境很好。 | 正面 | ID样本 |
| ②食物不新鲜,我不会再来这用餐。 | 负面 | ID样本 |
| ③喜马拉雅山的高度为8 848.86米。 | 未知 | 语义偏移类型 |
| ④明天天气如何? | 未知 | 语义偏移类型 |
| ⑤这是一部优秀的电影。 | 正面 | 背景偏移类型 |
| ⑥这部动画剧情混乱,令人失望。 | 负面 | 背景偏移类型 |
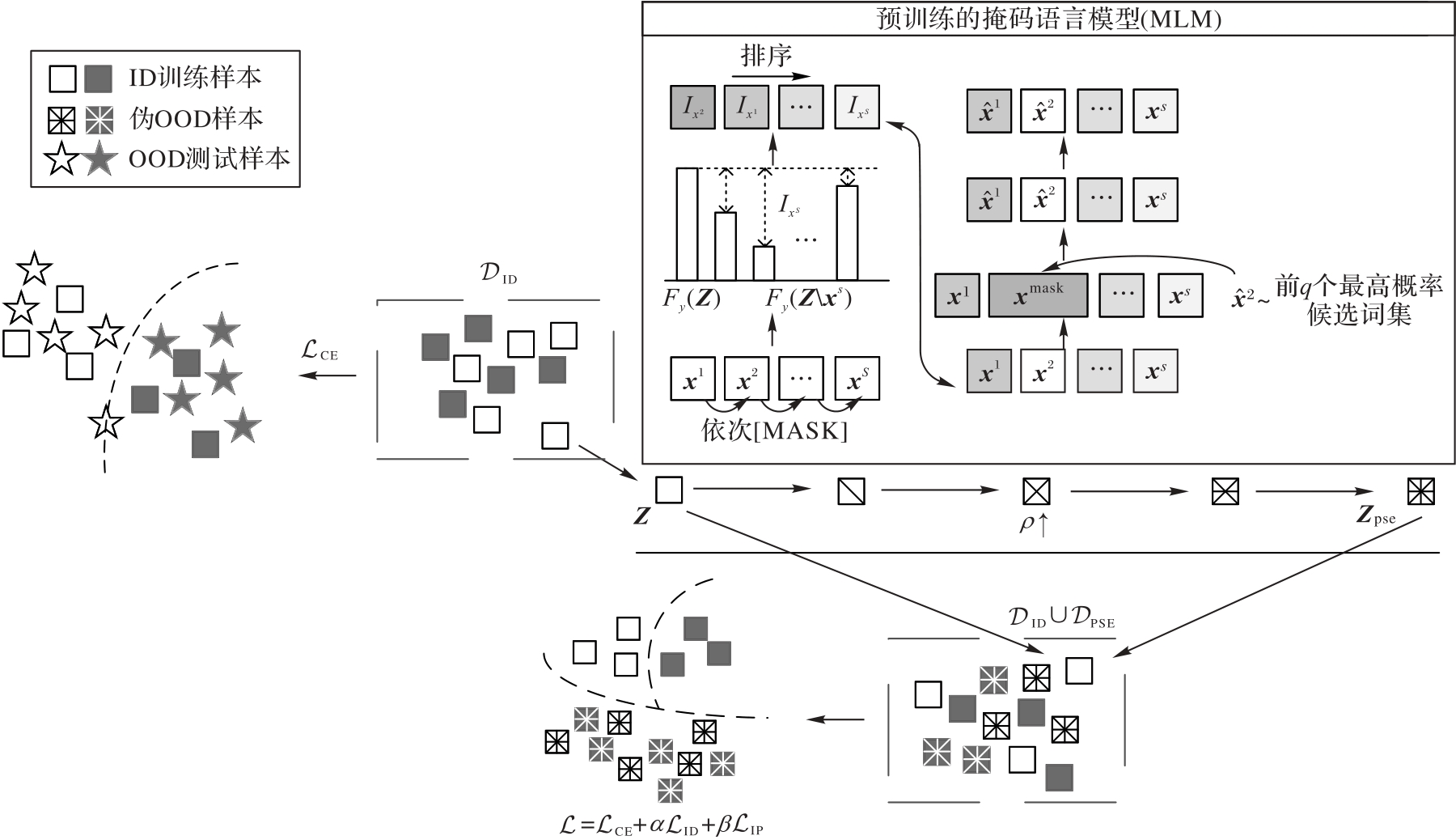
Fig. 1 Training-stage IEDOD-TT framework
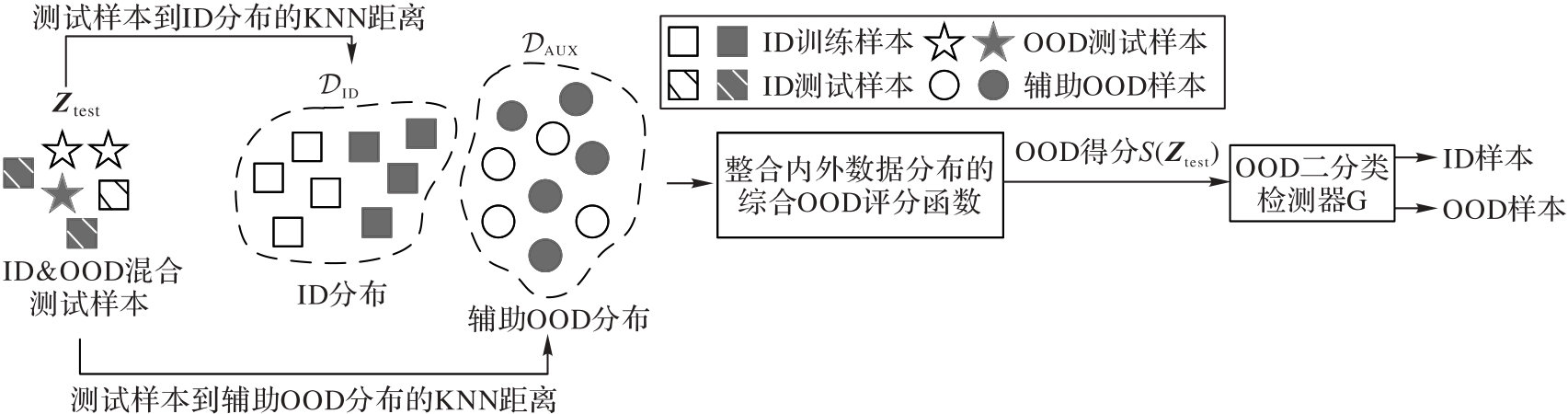
Fig. 2 Testing-stage IEDOD-TT framework
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| MSP | 95.71 | 74.14 | 67.06 | 80.81 | 79.43 |
| Energy | 96.33 | 75.91 | 61.53 | 75.52 | 77.32 |
| Maha | 97.55 | 79.77 | 64.63 | 91.04 | 83.25 |
| KNN | 96.39 | 75.10 | 74.48 | 79.76 | 81.43 |
| MSP+MCL | 95.73 | 72.87 | 62.23 | 89.30 | 80.03 |
| Energy+MCL | 96.41 | 73.12 | 61.66 | 89.17 | 80.09 |
| KNN-CL | 97.84 | 79.35 | 90.82 | 96.93 | 91.24 |
| doSCL-cMaha | 97.42 | 80.64 | 90.16 | 97.10 | 91.33 |
| IEDOD-TT | 97.56 | 83.77 | 92.74 | 97.48 | 92.89 |
Tab. 2 Detection AUROC of all methods in two different ID/OOD scenarios
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| MSP | 95.71 | 74.14 | 67.06 | 80.81 | 79.43 |
| Energy | 96.33 | 75.91 | 61.53 | 75.52 | 77.32 |
| Maha | 97.55 | 79.77 | 64.63 | 91.04 | 83.25 |
| KNN | 96.39 | 75.10 | 74.48 | 79.76 | 81.43 |
| MSP+MCL | 95.73 | 72.87 | 62.23 | 89.30 | 80.03 |
| Energy+MCL | 96.41 | 73.12 | 61.66 | 89.17 | 80.09 |
| KNN-CL | 97.84 | 79.35 | 90.82 | 96.93 | 91.24 |
| doSCL-cMaha | 97.42 | 80.64 | 90.16 | 97.10 | 91.33 |
| IEDOD-TT | 97.56 | 83.77 | 92.74 | 97.48 | 92.89 |
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| MSP | 20.04 | 79.96 | 88.50 | 65.29 | 63.45 |
| Energy | 15.99 | 75.54 | 92.99 | 65.17 | 62.42 |
| Maha | 12.66 | 68.73 | 90.41 | 51.74 | 55.89 |
| KNN | 19.33 | 78.35 | 87.63 | 65.03 | 62.58 |
| MSP+MCL | 17.93 | 77.56 | 89.95 | 58.93 | 61.09 |
| Energy+MCL | 13.74 | 76.13 | 89.76 | 59.00 | 59.66 |
| KNN-CL | 12.18 | 67.46 | 57.54 | 26.39 | 40.89 |
| doSCL-cMaha | 11.24 | 66.21 | 60.16 | 17.13 | 38.69 |
| IEDOD-TT | 11.91 | 58.75 | 58.22 | 14.57 | 35.86 |
Tab. 3 Detection FPR95 of all methods in two different ID/OOD scenarios
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| MSP | 20.04 | 79.96 | 88.50 | 65.29 | 63.45 |
| Energy | 15.99 | 75.54 | 92.99 | 65.17 | 62.42 |
| Maha | 12.66 | 68.73 | 90.41 | 51.74 | 55.89 |
| KNN | 19.33 | 78.35 | 87.63 | 65.03 | 62.58 |
| MSP+MCL | 17.93 | 77.56 | 89.95 | 58.93 | 61.09 |
| Energy+MCL | 13.74 | 76.13 | 89.76 | 59.00 | 59.66 |
| KNN-CL | 12.18 | 67.46 | 57.54 | 26.39 | 40.89 |
| doSCL-cMaha | 11.24 | 66.21 | 60.16 | 17.13 | 38.69 |
| IEDOD-TT | 11.91 | 58.75 | 58.22 | 14.57 | 35.86 |
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| CE/IEDOD-TT | 96.50 | 76.21 | 76.58 | 82.66 | 83.49 |
| EXT/IEDOD-TT | 97.38 | 80.18 | 86.07 | 91.42 | 88.76 |
| IS/IEDOD-TT | 96.97 | 82.71 | 90.15 | 95.29 | 91.28 |
| IEDOD-TT | 97.56 | 83.77 | 92.74 | 97.48 | 92.89 |
Tab. 4 Detection AUROC of IEDOD-TT and its three variants in different ID/OOD scenarios
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| CE/IEDOD-TT | 96.50 | 76.21 | 76.58 | 82.66 | 83.49 |
| EXT/IEDOD-TT | 97.38 | 80.18 | 86.07 | 91.42 | 88.76 |
| IS/IEDOD-TT | 96.97 | 82.71 | 90.15 | 95.29 | 91.28 |
| IEDOD-TT | 97.56 | 83.77 | 92.74 | 97.48 | 92.89 |
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| CE/IEDOD-TT | 17.53 | 75.65 | 80.54 | 58.20 | 57.98 |
| EXT/IEDOD-TT | 14.72 | 61.02 | 69.81 | 36.57 | 45.53 |
| IS/IEDOD-TT | 12.36 | 60.28 | 62.88 | 18.74 | 38.57 |
| IEDOD-TT | 11.91 | 58.75 | 58.22 | 14.57 | 35.86 |
Tab. 5 Detection FPR95 of IEDOD-TT and its three variants in different ID/OOD scenarios
| 方法 | ID数据集 | Average | |||
|---|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | ||
| CE/IEDOD-TT | 17.53 | 75.65 | 80.54 | 58.20 | 57.98 |
| EXT/IEDOD-TT | 14.72 | 61.02 | 69.81 | 36.57 | 45.53 |
| IS/IEDOD-TT | 12.36 | 60.28 | 62.88 | 18.74 | 38.57 |
| IEDOD-TT | 11.91 | 58.75 | 58.22 | 14.57 | 35.86 |
| 目标数据集 | ID训练集 | |||
|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | |
| CLINC150 | ||||
| NEWS-TOP5 | ||||
| CLINC-OOD | -35.96 | |||
| NEWS-REST | -40.27 | |||
| SST2 | -5.22 | |||
| YELP | -5.22 | |||
| 伪OOD数据集 | -19.87 | -28.31 | -3.79 | -6.58 |
Tab. 6 Average Maha distance score between ID test set and target dataset
| 目标数据集 | ID训练集 | |||
|---|---|---|---|---|
| CLINC150 | NEWS-TOP5 | SST2 | YELP | |
| CLINC150 | ||||
| NEWS-TOP5 | ||||
| CLINC-OOD | -35.96 | |||
| NEWS-REST | -40.27 | |||
| SST2 | -5.22 | |||
| YELP | -5.22 | |||
| 伪OOD数据集 | -19.87 | -28.31 | -3.79 | -6.58 |
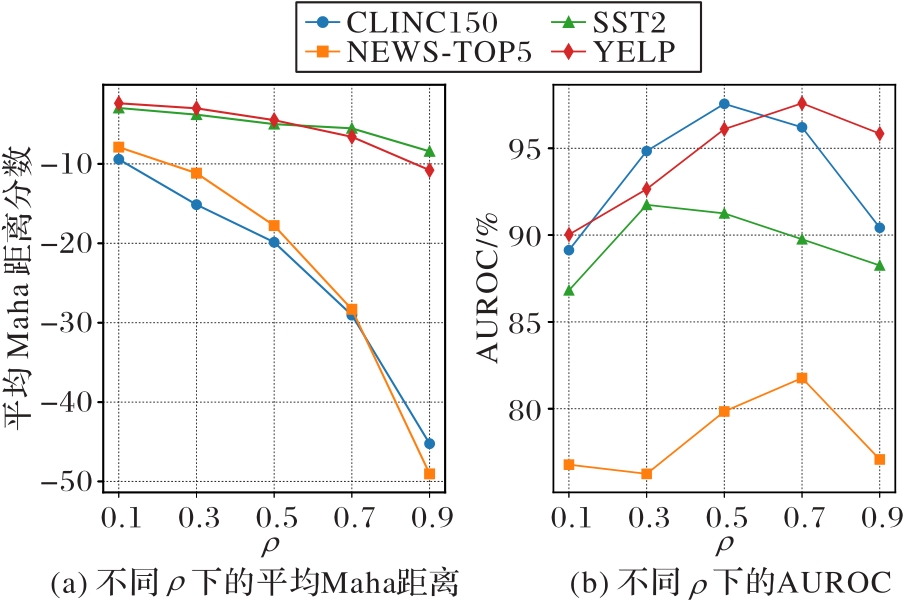
Fig. 3 Feature differences of pseudo OOD datasets generated under different ρ and their influence on detection performance of IEDOD-TT
| 场景 | ID数据集 | 性能指标 | ||
|---|---|---|---|---|
| AUROC/% | FPR95/% | |||
| 语义偏移 | CLINC150 | -/- | 90.10 | 24.54 |
| +/- | 92.42 | 21.09 | ||
| -/+ | 96.04 | 16.90 | ||
| +/+ | 97.56 | 11.91 | ||
| NEWS-TOP5 | -/- | 72.75 | 68.21 | |
| +/- | 73.81 | 64.70 | ||
| -/+ | 79.93 | 59.73 | ||
| +/+ | 81.77 | 58.75 | ||
| 背景偏移 | SST2 | -/- | 83.22 | 74.68 |
| +/- | 85.29 | 69.14 | ||
| -/+ | 89.96 | 61.62 | ||
| +/+ | 91.74 | 58.22 | ||
| YELP | -/- | 89.56 | 22.05 | |
| +/- | 90.79 | 19.97 | ||
| -/+ | 95.88 | 13.36 | ||
| +/+ | 97.59 | 14.57 | ||
Tab. 7 Ablation experiment results of loss functions
| 场景 | ID数据集 | 性能指标 | ||
|---|---|---|---|---|
| AUROC/% | FPR95/% | |||
| 语义偏移 | CLINC150 | -/- | 90.10 | 24.54 |
| +/- | 92.42 | 21.09 | ||
| -/+ | 96.04 | 16.90 | ||
| +/+ | 97.56 | 11.91 | ||
| NEWS-TOP5 | -/- | 72.75 | 68.21 | |
| +/- | 73.81 | 64.70 | ||
| -/+ | 79.93 | 59.73 | ||
| +/+ | 81.77 | 58.75 | ||
| 背景偏移 | SST2 | -/- | 83.22 | 74.68 |
| +/- | 85.29 | 69.14 | ||
| -/+ | 89.96 | 61.62 | ||
| +/+ | 91.74 | 58.22 | ||
| YELP | -/- | 89.56 | 22.05 | |
| +/- | 90.79 | 19.97 | ||
| -/+ | 95.88 | 13.36 | ||
| +/+ | 97.59 | 14.57 | ||
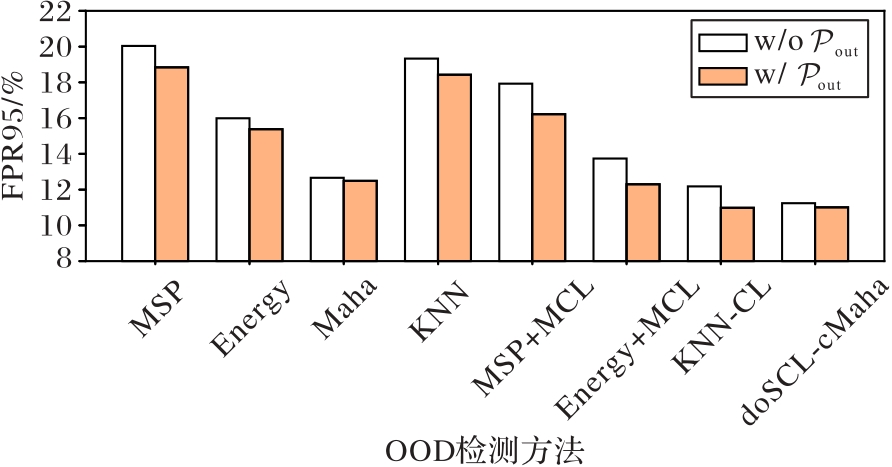
Fig. 4 Influence of combining OOD distribution on detection performance of baseline methods
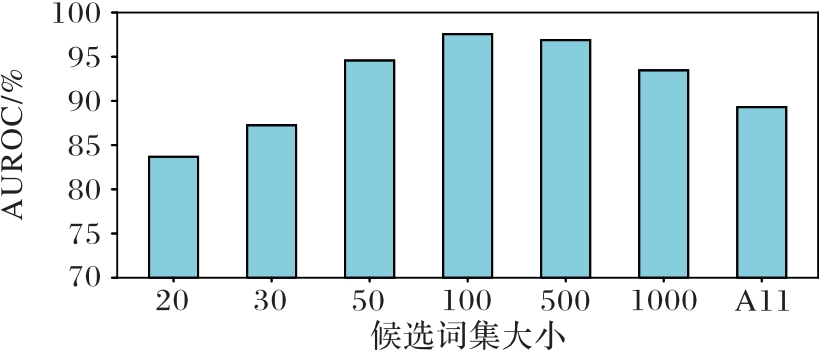
Fig. 5 Detection performance of IEDOD-TT for candidate word sets of different sizes
| [1] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [2] | YANG Z, DAI Z, YANG Y, et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5753-5763. |
| [3] | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| [4] | CLARK K, LUONG M T, LE Q, et al. Pre-training transformers as energy-based cloze models[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 285-294. |
| [5] | BARAN M, BARAN J, WÓJCIK M, et al. Classical out-of-distribution detection methods benchmark in text classification tasks[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics(Volume 4: Student Research Workshop). Stroudsburg: ACL, 2023: 119-129. |
| [6] | JIANG Z, XU F F, ARAKI J, et al. How can we know what language models know?[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 423-438. |
| [7] | KONG L, JIANG H, ZHUANG Y, et al. Calibrated language model fine-tuning for in-and out-of-distribution data[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 1326-1340. |
| [8] | HENDRYCKS D, GIMPEL K. A baseline for detecting misclassified and out-of-distribution examples in neural networks[EB/OL]. [2024-04-08].. |
| [9] | LAKSHMINARAYANAN B, PRITZEL A, BLUNDELL C. Simple and scalable predictive uncertainty estimation using deep ensembles[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6405-6416. |
| [10] | ANDERSEN J S, SCHÖNER T, MAALEJ W. Word-level uncertainty estimation for black-box text classifiers using RNNs[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 5541-5546. |
| [11] | LEE K, LEE K, LEE H, et al. A simple unified framework for detecting out-of-distribution samples and adversarial attacks[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 7167-7177. |
| [12] | SUN Y, LI Y. DICE: leveraging sparsification for out-of-distribution detection[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13684. Cham: Springer, 2022: 691-708. |
| [13] | HENDRYCKS D, MAZEIKA M, DIETTERICH T. Deep anomaly detection with outlier exposure[EB/OL]. [2024-04-08].. |
| [14] | LIN H, GU Y. FlatS: principled out-of-distribution detection with feature-based likelihood ratio score[C]// Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2023: 8956-8963. |
| [15] | ARORA U, HUANG W, HE H. Types of out-of-distribution texts and how to detect them[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 10687-10701. |
| [16] | 欧阳亚文,高源,宗石,等. Pobe:一种基于生成式模型的分布外文本检测方法[J]. 软件学报, 2024, 35(9): 4365-4376. |
| OUYANG Y W, GAO Y, ZONG S, et al. Pobe: a generative-based out-of-distribution text detection method[J]. Journal of Software, 2024, 35(9): 4365-4376. | |
| [17] | ZHANG Y, DENG W, ZHENG L. Unsupervised evaluation of out-of-distribution detection: a data-centric perspective[EB/OL]. [2024-03-27].. |
| [18] | LIU W, WANG X, OWENS J D, et al. Energy-based out-of-distribution detection[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 21464-21475. |
| [19] | PODOLSKIY A, LIPIN D, BOUT A, et al. Revisiting Mahalanobis distance for transformer-based out-of-domain detection[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 13675-13682. |
| [20] | CHEN S, YANG W, BI X, et al. Fine-tuning deteriorates general textual out-of-distribution detection by distorting task-agnostic features[C]// Findings of the Association for Computational Linguistics: EACL 2023. Stroudsburg: ACL, 2023: 564-579. |
| [21] | SUN Y, MING Y, ZHU X, et al. Out-of-distribution detection with deep nearest neighbors[C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 20827-20840. |
| [22] | WANG M, SHAO Y, LIN H, et al. CMG: a class-mixed generation approach to out-of-distribution detection[C]// Proceedings of the 2023 European Conference on Machine Learning and Knowledge Discovery in Databases, LNCS 13716. Cham: Springer, 2023: 502-518. |
| [23] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| [24] | HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9726-9735. |
| [25] | ZHOU W, LIU F, CHEN M. Contrastive out-of-distribution detection for pretrained transformers[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 1100-1111. |
| [26] | WANG B, MINE T. Optimizing upstream representations for out-of-domain detection with supervised contrastive learning[C]// Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. New York: ACM, 2023: 2585-2595. |
| [27] | ZENG Z, HE K, YAN Y, et al. Modeling discriminative representations for out-of-domain detection with supervised contrastive learning[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2021: 870-878. |
| [28] | ZHOU Y, LIU P, QIU X. KNN-contrastive learning for out-of-domain intent classification[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 5129-5141. |
| [29] | ZHAO P, LAI L. Analysis of kNN density estimation[J]. IEEE Transactions on Information Theory, 2022, 68(12): 7971-7995. |
| [30] | LARSON S, MAHENDRAN A, PEPER J J, et al. An evaluation dataset for intent classification and out-of-scope prediction[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 1311-1316. |
| [31] | MISRA R. News category dataset[EB/OL]. [2024-09-20].. |
| [32] | SOCHER R, PERELYGIN A, WU J, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2013: 1631-1642. |
| [33] | ZHANG X, ZHAO J, LeCUN Y. Character-level convolutional networks for text classification[C]// Proceedings of the 29th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015: 649-657. |
| [34] | CHO H, PARK C, KIM J, et al. Probing out-of-distribution robustness of language models with parameter-efficient transfer learning[C]// Proceedings of the 12th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2023: 225-235. |
| [35] | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]. [2024-04-08].. |
| [36] | Foundation Wikimedia. Wikipedia database dumps[EB/OL]. [2024-04-08].. |
| [37] | BOJAR O, GRAHAM Y, KAMRAN A, et al. Results of the WMT16 metrics shared task[C]// Proceedings of the 1st Conference on Machine Translation: Volume 2, Shared Task Papers. Stroudsburg: ACL, 2016: 199-231. |
| [1] | Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features [J]. Journal of Computer Applications, 2025, 45(8): 2484-2490. |
| [2] | Jin XIE, Surong CHU, Yan QIANG, Juanjuan ZHAO, Hua ZHANG, Yong GAO. Dual-branch distribution consistency contrastive learning model for hard negative sample identification in chest X-rays [J]. Journal of Computer Applications, 2025, 45(7): 2369-2377. |
| [3] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [4] | Chaoying JIANG, Qian LI, Ning LIU, Lei LIU, Lizhen CUI. Readmission prediction model based on graph contrastive learning [J]. Journal of Computer Applications, 2025, 45(6): 1784-1792. |
| [5] | Mingfeng YU, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Chuan LIN. Multi-label text classification method based on contrastive learning enhanced dual-attention mechanism [J]. Journal of Computer Applications, 2025, 45(6): 1732-1740. |
| [6] | Xiangyu LI, Jingqiang CHEN. Comparability assessment and comparative citation generation method for scientific papers [J]. Journal of Computer Applications, 2025, 45(6): 1888-1894. |
| [7] | Wenjing YAN, Ruidong WANG, Min ZUO, Qingchuan ZHANG. Recipe recommendation model based on hierarchical learning of flavor embedding heterogeneous graph [J]. Journal of Computer Applications, 2025, 45(6): 1869-1878. |
| [8] | Yufei LONG, Yuchen MOU, Ye LIU. Multi-source data representation learning model based on tensorized graph convolutional network and contrastive learning [J]. Journal of Computer Applications, 2025, 45(5): 1372-1378. |
| [9] | Wenbin HU, Tianxiang CAI, Tianle HAN, Zhaoman ZHONG, Changxia MA. Multimodal sarcasm detection model integrating contrastive learning with sentiment analysis [J]. Journal of Computer Applications, 2025, 45(5): 1432-1438. |
| [10] | Weichao DANG, Xinyu WEN, Gaimei GAO, Chunxia LIU. Multi-view and multi-scale contrastive learning for graph collaborative filtering [J]. Journal of Computer Applications, 2025, 45(4): 1061-1068. |
| [11] | Jiaxin LI, Site MO. Power work order classification in substation area based on MiniRBT-LSTM-GAT and label smoothing [J]. Journal of Computer Applications, 2025, 45(4): 1356-1362. |
| [12] | Renjie TIAN, Mingli JING, Long JIAO, Fei WANG. Recommendation algorithm of graph contrastive learning based on hybrid negative sampling [J]. Journal of Computer Applications, 2025, 45(4): 1053-1060. |
| [13] | Haitao SUN, Jiayu LIN, Zuhong LIANG, Jie GUO. Data augmentation technique incorporating label confusion for Chinese text classification [J]. Journal of Computer Applications, 2025, 45(4): 1113-1119. |
| [14] | Wei CHEN, Changyong SHI, Chuanxiang MA. Crop disease recognition method based on multi-modal data fusion [J]. Journal of Computer Applications, 2025, 45(3): 840-848. |
| [15] | Yuanlong WANG, Tinghua LIU, Hu ZHANG. Commonsense question answering model based on cross-modal contrastive learning [J]. Journal of Computer Applications, 2025, 45(3): 732-738. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||