


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (9): 2783-2789.DOI: 10.11772/j.issn.1001-9081.2024091393
• Artificial intelligence • Previous Articles
Binbin ZHANG1,2,3, Yongbin QIN1,2,3( ), Ruizhang HUANG1,2,3, Yanping CHEN1,2,3
), Ruizhang HUANG1,2,3, Yanping CHEN1,2,3
Received:2024-10-07
Revised:2025-01-08
Accepted:2025-01-16
Online:2025-03-21
Published:2025-09-10
Contact:
Yongbin QIN
About author:ZHANG Binbin, born in 1999, M. S. candidate. His research interests include natural language processing, judicial summarization.Supported by:
张滨滨1,2,3, 秦永彬1,2,3(), 黄瑞章1,2,3, 陈艳平1,2,3
通讯作者:
秦永彬
作者简介:张滨滨(1999—),男,贵州仁怀人,硕士研究生,CCF会员,主要研究方向:自然语言处理、司法摘要基金资助:CLC Number:
Binbin ZHANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN. Judgment document summarization method combining large language model and dynamic prompts[J]. Journal of Computer Applications, 2025, 45(9): 2783-2789.
张滨滨, 秦永彬, 黄瑞章, 陈艳平. 结合大语言模型与动态提示的裁判文书摘要方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2783-2789.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024091393
| 原始文本(节选) | 摘要 | 文书结构 |
|---|---|---|
| 梁启照与梁叶光租赁合同纠纷……原告梁启照与被告梁叶光租赁合同纠纷一案,本院于2017年7月18日立案后,依法适用简易程序,公开开庭进行了审理。 | 原被告系租赁合同纠纷。 | 案件类型 |
| 原告梁启照、被告梁叶光到庭参加诉讼。本案现已审理终结。原告梁启照向本院提出诉讼请求:要求被告赔偿损失的80%即80 000元。事实理由……。 | 原告提出诉讼请求:要求被告赔偿损失的80%即80 000元。 | 原告诉求 |
| 事实理由……被告梁叶光辩称,梁叶光不同意向梁启照赔偿。梁启照的主张没有法律依据,没有证据证明大暴雨造成水浸的责任在于梁叶光。 | 被告辩称,被告不同意向原告赔偿。原告的主张没有法律依据,没有证据证明大暴雨造成水浸的责任在于被告。 | 被告辩称 |
| 本院经审理认定事实如下:2016年11月1日,被告梁叶光作为甲方,原告梁启照及案外人梁x甲、梁x乙作为乙方,双方签订《土地租赁合同》……经查,原、被告均确认本案租赁物为土地,并不包括地上构筑物,梁叶光已按约履行了出租人交付土地并保持土地可使用的义务。涉案地点的土地属于集体经济组织所有,当出现自然灾害导致水浸时,出租人并不负有法定的排水防洪义务,梁启照在租赁土地上的经营风险属于承租人的自身风险,其据此主张梁叶光承担责任的诉讼请求无法律依据,本院依法予以驳回。 | 经查,双方签订《土地租赁合同》,原、被告均确认本案租赁物为土地,并不包括地上构筑物,被告已按约履行了出租人交付土地并保持土地可使用的义务。涉案地点的土地属于集体经济组织所有,当出现自然灾害导致水浸时,出租人并不负有法定的,l排水防洪义务,原告在租赁土地上的经营风险属于承租人的自身风险,其据此主张被告承担责任的诉讼请求,本院依法予以驳回。 | 事实描述 |
| 综上所述,依照《中华人民共和国民法典》第七百四十二条的规定。 | 依《中华人民共和国民法典》。 | 判决依据 |
| 判决如下:驳回原告梁启照的全部诉讼请求…… | 判决:驳回原告的全部诉求。 | 判决结果 |
Tab. 1 Judgment document structure
| 原始文本(节选) | 摘要 | 文书结构 |
|---|---|---|
| 梁启照与梁叶光租赁合同纠纷……原告梁启照与被告梁叶光租赁合同纠纷一案,本院于2017年7月18日立案后,依法适用简易程序,公开开庭进行了审理。 | 原被告系租赁合同纠纷。 | 案件类型 |
| 原告梁启照、被告梁叶光到庭参加诉讼。本案现已审理终结。原告梁启照向本院提出诉讼请求:要求被告赔偿损失的80%即80 000元。事实理由……。 | 原告提出诉讼请求:要求被告赔偿损失的80%即80 000元。 | 原告诉求 |
| 事实理由……被告梁叶光辩称,梁叶光不同意向梁启照赔偿。梁启照的主张没有法律依据,没有证据证明大暴雨造成水浸的责任在于梁叶光。 | 被告辩称,被告不同意向原告赔偿。原告的主张没有法律依据,没有证据证明大暴雨造成水浸的责任在于被告。 | 被告辩称 |
| 本院经审理认定事实如下:2016年11月1日,被告梁叶光作为甲方,原告梁启照及案外人梁x甲、梁x乙作为乙方,双方签订《土地租赁合同》……经查,原、被告均确认本案租赁物为土地,并不包括地上构筑物,梁叶光已按约履行了出租人交付土地并保持土地可使用的义务。涉案地点的土地属于集体经济组织所有,当出现自然灾害导致水浸时,出租人并不负有法定的排水防洪义务,梁启照在租赁土地上的经营风险属于承租人的自身风险,其据此主张梁叶光承担责任的诉讼请求无法律依据,本院依法予以驳回。 | 经查,双方签订《土地租赁合同》,原、被告均确认本案租赁物为土地,并不包括地上构筑物,被告已按约履行了出租人交付土地并保持土地可使用的义务。涉案地点的土地属于集体经济组织所有,当出现自然灾害导致水浸时,出租人并不负有法定的,l排水防洪义务,原告在租赁土地上的经营风险属于承租人的自身风险,其据此主张被告承担责任的诉讼请求,本院依法予以驳回。 | 事实描述 |
| 综上所述,依照《中华人民共和国民法典》第七百四十二条的规定。 | 依《中华人民共和国民法典》。 | 判决依据 |
| 判决如下:驳回原告梁启照的全部诉讼请求…… | 判决:驳回原告的全部诉求。 | 判决结果 |

Fig. 1 Flow of proposed method
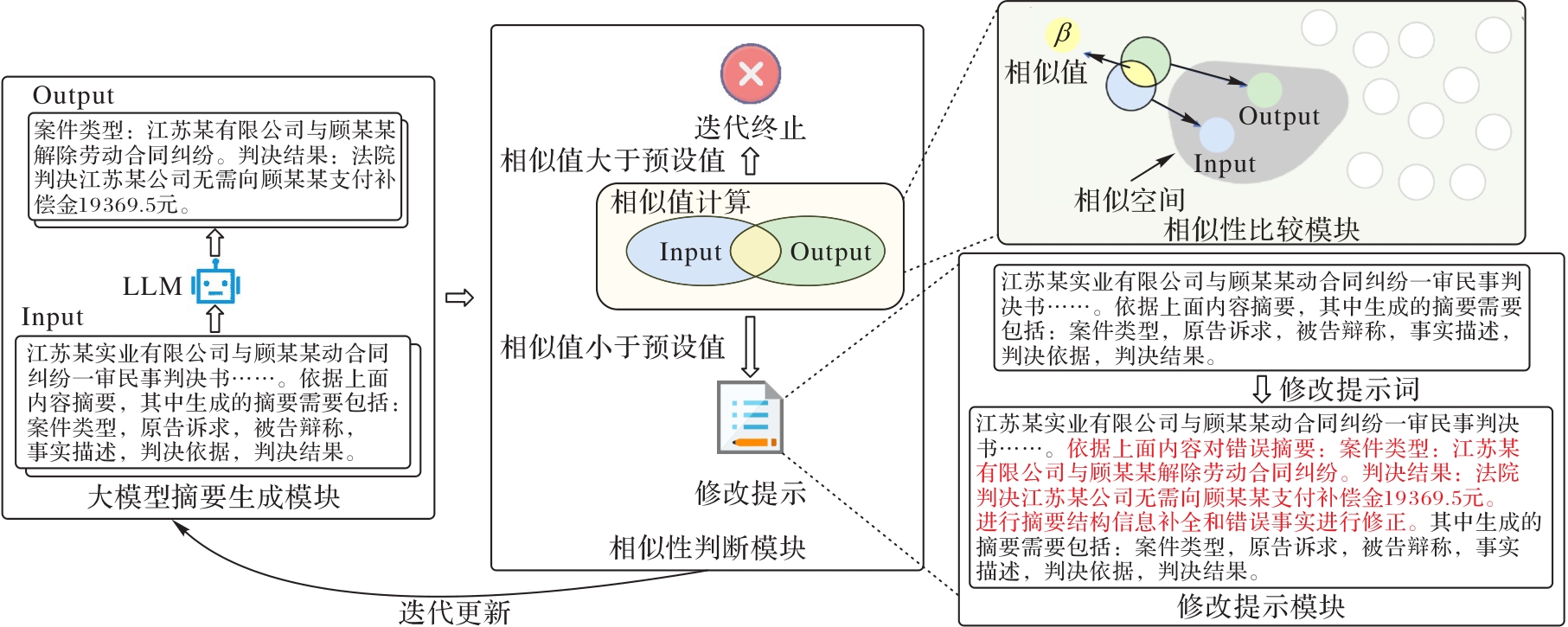
Fig. 2 Framework of DPCM
| 标准提示词样例 | 动态提示词样例 |
|---|---|
| ##裁判文书##。依据上面裁判文书生成裁判文书摘要,其中生成的摘要需要包括:案件类型,原告诉求,被告辩称,事实描述,判决依据,判决结果。 | ##裁判文书##。依据上面裁判文书原文对错误摘要:##错误摘要##。进行修正和结构信息补全。其中生成的摘要需要包括:案件类型,原告诉求,被告辩称,事实描述,判决依据,判决结果。 |
Tab. 2 Prompt word samples
| 标准提示词样例 | 动态提示词样例 |
|---|---|
| ##裁判文书##。依据上面裁判文书生成裁判文书摘要,其中生成的摘要需要包括:案件类型,原告诉求,被告辩称,事实描述,判决依据,判决结果。 | ##裁判文书##。依据上面裁判文书原文对错误摘要:##错误摘要##。进行修正和结构信息补全。其中生成的摘要需要包括:案件类型,原告诉求,被告辩称,事实描述,判决依据,判决结果。 |
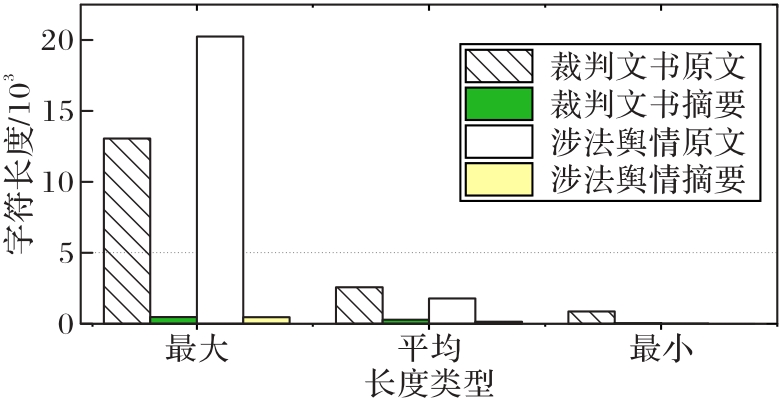
Fig. 3 Character lengths of original text of judgement documents and expert summaries
| 模型 | 隐藏层数 | 注意力头数 | 隐藏层神经元数 | 词表数 |
|---|---|---|---|---|
| ChatGLM3-6B | 4 096 | 32 | 28 | 65 024 |
| Qwen-7B | 4 096 | 32 | 32 | 151 936 |
| Baichuan2-7B | 4 096 | 32 | 32 | 125 696 |
| Qwen-14B | 5 120 | 40 | 40 | 152 064 |
| DISC-LawLLM | 5 120 | 40 | 40 | 64 000 |
Tab. 3 Information of large language models
| 模型 | 隐藏层数 | 注意力头数 | 隐藏层神经元数 | 词表数 |
|---|---|---|---|---|
| ChatGLM3-6B | 4 096 | 32 | 28 | 65 024 |
| Qwen-7B | 4 096 | 32 | 32 | 151 936 |
| Baichuan2-7B | 4 096 | 32 | 32 | 125 696 |
| Qwen-14B | 5 120 | 40 | 40 | 152 064 |
| DISC-LawLLM | 5 120 | 40 | 40 | 64 000 |
| 数据集 | 模型 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | ||||||
| CAIL2022 | Qwen-7B | 45.15 | 23.84 | 33.57 | 70.20 | 79.39 | 79.95 |
| Qwen-7B+DPCM | 48.23 | 27.28 | 36.88 | 71.88 | 82.70 | 84.22 | |
| ChatGLM3-6B | 50.79 | 30.56 | 41.19 | 73.09 | 80.07 | 82.26 | |
| ChatGLM3-6B+DPCM | 52.63 | 32.67 | 42.84 | 74.02 | 81.03 | 82.72 | |
| Baichuan2-7B | 49.87 | 29.56 | 39.65 | 73.00 | 83.25 | 84.61 | |
| Baichuan2-7B+DPCM | 51.30 | 31.16 | 41.77 | 73.42 | 83.82 | 85.07 | |
| Qwen-14B | 45.22 | 24.01 | 34.15 | 70.46 | 79.59 | 80.76 | |
| Qwen-14B+DPCM | 45.59 | 24.90 | 35.07 | 71.03 | 81.26 | 82.30 | |
| DISC-LawLLM | 58.04 | 43.10 | 52.25 | 77.78 | 87.01 | 89.79 | |
| DISC-LawLLM+DPCM | 58.70 | 43.74 | 52.67 | 78.01 | 87.63 | 90.20 | |
| CAIL2020 | Qwen-7B | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| Qwen-7B+DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 | |
| ChatGLM3-6B | 53.96 | 28.46 | 40.33 | 72.03 | 83.00 | 85.22 | |
| ChatGLM3-6B+DPCM | 58.02 | 33.21 | 47.34 | 73.96 | 87.84 | 90.79 | |
| Baichuan2-7B | 56.04 | 30.94 | 44.80 | 73.45 | 85.24 | 86.32 | |
| Baichuan2-7B+DPCM | 59.50 | 33.69 | 48.95 | 75.04 | 87.60 | 90.17 | |
| Qwen-14B | 55.74 | 29.54 | 42.06 | 73.27 | 82.61 | 84.82 | |
| Qwen-14B+DPCM | 57.65 | 31.40 | 44.80 | 73.84 | 83.17 | 86.32 | |
| DISC-LawLLM | 46.42 | 20.92 | 33.46 | 68.22 | 78.62 | 80.38 | |
| DISC-LawLLM+DPCM | 50.16 | 24.59 | 38.43 | 70.79 | 79.77 | 82.30 | |
Tab. 4 Comparison experimental results of different models on CAIL2022 and CAIL2020 datasets
| 数据集 | 模型 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | ||||||
| CAIL2022 | Qwen-7B | 45.15 | 23.84 | 33.57 | 70.20 | 79.39 | 79.95 |
| Qwen-7B+DPCM | 48.23 | 27.28 | 36.88 | 71.88 | 82.70 | 84.22 | |
| ChatGLM3-6B | 50.79 | 30.56 | 41.19 | 73.09 | 80.07 | 82.26 | |
| ChatGLM3-6B+DPCM | 52.63 | 32.67 | 42.84 | 74.02 | 81.03 | 82.72 | |
| Baichuan2-7B | 49.87 | 29.56 | 39.65 | 73.00 | 83.25 | 84.61 | |
| Baichuan2-7B+DPCM | 51.30 | 31.16 | 41.77 | 73.42 | 83.82 | 85.07 | |
| Qwen-14B | 45.22 | 24.01 | 34.15 | 70.46 | 79.59 | 80.76 | |
| Qwen-14B+DPCM | 45.59 | 24.90 | 35.07 | 71.03 | 81.26 | 82.30 | |
| DISC-LawLLM | 58.04 | 43.10 | 52.25 | 77.78 | 87.01 | 89.79 | |
| DISC-LawLLM+DPCM | 58.70 | 43.74 | 52.67 | 78.01 | 87.63 | 90.20 | |
| CAIL2020 | Qwen-7B | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| Qwen-7B+DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 | |
| ChatGLM3-6B | 53.96 | 28.46 | 40.33 | 72.03 | 83.00 | 85.22 | |
| ChatGLM3-6B+DPCM | 58.02 | 33.21 | 47.34 | 73.96 | 87.84 | 90.79 | |
| Baichuan2-7B | 56.04 | 30.94 | 44.80 | 73.45 | 85.24 | 86.32 | |
| Baichuan2-7B+DPCM | 59.50 | 33.69 | 48.95 | 75.04 | 87.60 | 90.17 | |
| Qwen-14B | 55.74 | 29.54 | 42.06 | 73.27 | 82.61 | 84.82 | |
| Qwen-14B+DPCM | 57.65 | 31.40 | 44.80 | 73.84 | 83.17 | 86.32 | |
| DISC-LawLLM | 46.42 | 20.92 | 33.46 | 68.22 | 78.62 | 80.38 | |
| DISC-LawLLM+DPCM | 50.16 | 24.59 | 38.43 | 70.79 | 79.77 | 82.30 | |
| 方法 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| Least-To-Most-Prompting[ | 45.48 | 20.01 | 32.55 | 68.93 | 71.71 | 73.29 |
| Zero-Shot-Reasoners[ | 44.81 | 21.68 | 34.19 | 68.95 | 76.39 | 77.35 |
| Qwen-7B+标准提示(Baseline) | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| CoT[ | 48.79 | 23.17 | 36.58 | 67.78 | 81.07 | 82.69 |
| Self_Consistency_Cot[ | 50.45 | 24.04 | 37.30 | 70.37 | 84.69 | 86.17 |
| Qwen-7B+DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
Tab. 5 Comparison results of different methods
| 方法 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| Least-To-Most-Prompting[ | 45.48 | 20.01 | 32.55 | 68.93 | 71.71 | 73.29 |
| Zero-Shot-Reasoners[ | 44.81 | 21.68 | 34.19 | 68.95 | 76.39 | 77.35 |
| Qwen-7B+标准提示(Baseline) | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| CoT[ | 48.79 | 23.17 | 36.58 | 67.78 | 81.07 | 82.69 |
| Self_Consistency_Cot[ | 50.45 | 24.04 | 37.30 | 70.37 | 84.69 | 86.17 |
| Qwen-7B+DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
| 模型 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| Qwen-7B+标准提示 | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| Qwen-7B+相似性比较 | 50.28 | 24.51 | 38.17 | 70.89 | 81.61 | 83.41 |
| DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
Tab. 6 Ablation experimental results
| 模型 | Rouge-1 | Rouge-2 | Rouge-L | BERTscore | FactCC | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| Qwen-7B+标准提示 | 46.87 | 21.50 | 34.16 | 68.41 | 78.00 | 79.87 |
| Qwen-7B+相似性比较 | 50.28 | 24.51 | 38.17 | 70.89 | 81.61 | 83.41 |
| DPCM | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
| 迭代次数 | Rouge-1/% | Rouge-2/% | Rouge-L/% | BERTscore/% | FactCC/% | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| 1 | 53.60 | 28.21 | 40.13 | 72.19 | 82.91 | 85.13 |
| 2 | 55.66 | 29.68 | 43.98 | 73.93 | 84.94 | 87.93 |
| 3 | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
Tab. 7 Statistical analysis results
| 迭代次数 | Rouge-1/% | Rouge-2/% | Rouge-L/% | BERTscore/% | FactCC/% | |
|---|---|---|---|---|---|---|
| F1分数 | 加权Acc | |||||
| 1 | 53.60 | 28.21 | 40.13 | 72.19 | 82.91 | 85.13 |
| 2 | 55.66 | 29.68 | 43.98 | 73.93 | 84.94 | 87.93 |
| 3 | 56.04 | 30.04 | 44.31 | 73.95 | 85.10 | 88.28 |
| [1] | WIDYASSARI A P, RUSTAD S, SHIDIK G F, et al. Review of automatic text summarization techniques & methods [J]. Journal of King Saud University — Computer and Information Sciences, 2022, 34(4): 1029-1046. |
| [2] | KANAPALA A, PAL S, PAMULA R. Text summarization from legal documents: a survey [J]. Artificial Intelligence Review, 2019, 51(3): 371-402. |
| [3] | CELIKYILMAZ A, BOSSELUT A, HE X, et al. Deep communicating agents for abstractive summarization [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018: 1662-1675. |
| [4] | BHATTACHARYA P, PODDAR S, RUDRA K, et al. Incorporating domain knowledge for extractive summarization of legal case documents [C]// Proceedings of the 18th International Conference on Artificial Intelligence and Law. New York: ACM, 2021: 22-31. |
| [5] | LI D, YANG K, ZHANG L, et al. CLASS: a novel method for Chinese legal judgments summarization [C]// Proceedings of the 5th International Conference on Computer Science and Application Engineering. New York: ACM, 2021: No.86. |
| [6] | 周蔚,王兆毓,魏斌. 面向法律裁判文书的生成式自动摘要模型[J]. 计算机科学, 2021, 48(12): 331-336. |
| ZHOU W, WANG Z Y, WEI B. Abstractive automatic summarizing model for legal judgment documents [J]. Computer Science, 2021, 48(12): 331-336. | |
| [7] | 魏鑫炀,秦永彬,唐向红,等. 融合法条的司法裁判文书摘要生成方法[J]. 计算机工程与设计, 2023, 44(9): 2844-2850. |
| WEI X Y, QIN Y B, TANG X H, et al. Method of abstracting judgement document combined with law [J]. Computer Engineering and Design, 2023, 44(9): 2844-2850. | |
| [8] | 余帅,宋玉梅,秦永彬,等. 基于审判逻辑步骤的裁判文书摘要生成方法[J]. 计算机工程与应用, 2024, 60(4): 113-121. |
| YU S, SONG Y M, QIN Y B, et al. Method for generating summary of judgment documents based on trial logic steps [J]. Computer Engineering and Applications, 2024, 60(4): 113-121. | |
| [9] | 陈炫言,安娜,孙宇,等. 面向司法文书的抽取-生成式自动摘要模型[J]. 计算机工程与设计, 2024, 45(4): 1117-1125. |
| CHEN X Y, AN N, SUN Y, et al. Automatic extraction-generative automatic summarization model for judicial documents [J]. Computer Engineering and Design, 2024, 45(4): 1117-1125. | |
| [10] | 裴炳森,李欣,胡凯茜,等. 基于知识增强预训练模型的司法文本摘要生成[J]. 科学技术与工程, 2024, 24(20): 8587-8597. |
| PEI B S, LI X, HU K X, et al. Judicial text summarization based on knowledge-enhanced pretrained language models [J]. Science Technology and Engineering, 2024, 24(20): 8587-8597. | |
| [11] | 李佳沂,黄瑞章,陈艳平,等. 结合提示学习和Qwen大语言模型的裁判文书摘要方法[J]. 清华大学学报(自然科学版), 2024, 64(12): 2007-2018. |
| LI J Y, HUANG R Z, CHEN Y P, et al. Method for judicial document summarization by combining prompt learning and Qwen large language models [J]. Journal of Tsinghua University (Science and Technology), 2024, 64(12): 2007-2018. | |
| [12] | WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 24824-24837. |
| [13] | ZHOU D, SCHÄRLI N, HOU L, et al. Least-to-most prompting enables complex reasoning in large language models [EB/OL]. [2024-08-21]. . |
| [14] | WANG X, WEI J, SCHUURMANS D, et al. Self-consistency improves chain of thought reasoning in language models [EB/OL]. [2024-08-19]. . |
| [15] | ZHANG Z, ZHANG A, LI M, et al. Automatic chain of thought prompting in large language models[EB/OL]. [2024-08-23].. |
| [16] | Team Qwen. Qwen technical report [R/OL]. [2024-03-20].. |
| [17] | SHABAN A, BANSAL S, LIU Z, et al. One-shot learning for semantic segmentation [C]// Proceedings of the 2017 British Machine Vision Conference. Durham: BMVA Press, 2017: No.167. |
| [18] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [19] | LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| [20] | ZHANG T, KISHORE V, WU F, et al. BERTscore: evaluating text generation with BERT [EB/OL]. [2024-06-02]. . |
| [21] | KRYŚCIŃSKI W, McCANN B, XIONG C, et al. Evaluating the factual consistency of abstractive text summarization [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 9332-9346. |
| [22] | YANG J, WANG M, ZHOU H, et al. Towards making the most of BERT in neural machine translation [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9378-9385. |
| [23] | Team GLM. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools [EB/OL]. [2024-08-10]. . |
| [24] | Inc Baichuan. Baichuan 2: open large-scale language models [EB/OL]. [2024-05-08].. |
| [25] | YUE S, CHEN W, WANG S, et al. DISC-LawLLM: fine-tuning large language models for intelligent legal services [EB/OL]. [2024-08-07].. |
| [26] | KOJIMA T, GU S S, REID M, et al. Large language models are zero-shot reasoners [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 22199-22213. |
| [1] | Tao FENG, Chen LIU. Dual-stage prompt tuning method for automated preference alignment [J]. Journal of Computer Applications, 2025, 45(8): 2442-2447. |
| [2] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [3] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [4] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [5] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [6] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [7] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [8] | Can MA, Ruizhang HUANG, Lina REN, Ruina BAI, Yaoyao WU. Chinese spelling correction method based on LLM with multiple inputs [J]. Journal of Computer Applications, 2025, 45(3): 849-855. |
| [9] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [10] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [11] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [12] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [13] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [14] | Yushan JIANG, Yangsen ZHANG. Large language model-driven stance-aware fact-checking [J]. Journal of Computer Applications, 2024, 44(10): 3067-3073. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||