


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 808-814.DOI: 10.11772/j.issn.1001-9081.2024101434
• Frontier research and typical applications of large models • Previous Articles Next Articles
Bin KANG1,2, Bin CHEN2,3( ), Junjie WANG3,4, Yulin LI3,4, Junzhi ZHAO5, Weizhi XIAN6
), Junjie WANG3,4, Yulin LI3,4, Junzhi ZHAO5, Weizhi XIAN6
Received:2024-10-11
Revised:2024-11-26
Accepted:2024-12-04
Online:2025-01-06
Published:2025-03-10
Contact:
Bin CHEN
About author:KANG Bin, born in 1998, Ph. D. candidate. His research interests include multi-modal retrieval, object detection.Supported by:
康斌1,2, 陈斌2,3(), 王俊杰3,4, 李昱林3,4, 赵军智5, 咸伟志6
通讯作者:
陈斌
作者简介:康斌(1998—),男,甘肃临洮人,博士研究生,主要研究方向:多模态检索、目标检测基金资助:CLC Number:
Bin KANG, Bin CHEN, Junjie WANG, Yulin LI, Junzhi ZHAO, Weizhi XIAN. Text-based person retrieval method based on multi-granularity shared semantic center association[J]. Journal of Computer Applications, 2025, 45(3): 808-814.
康斌, 陈斌, 王俊杰, 李昱林, 赵军智, 咸伟志. 基于多粒度共享语义中心关联的文本到人物检索方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 808-814.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024101434
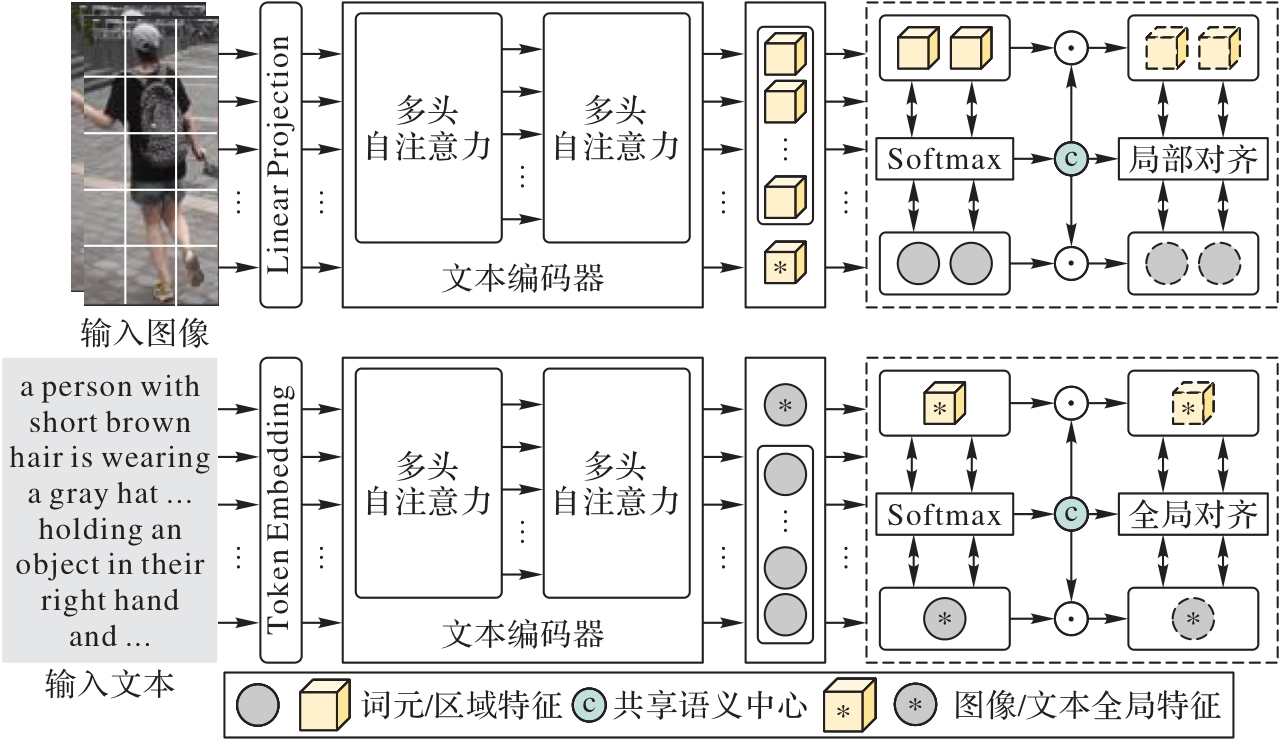
Fig. 1 Overall structure of proposed method
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| DSSL | 59.98 | 80.41 | 87.56 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
Tab. 1 Performance comparison of different methods on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| DSSL | 59.98 | 80.41 | 87.56 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| IVT | 56.04 | 73.60 | 80.22 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.26 | 80.99 | 86.12 | 39.81 |
Tab. 2 Performance comparison of different methods on ICFG-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| IVT | 56.04 | 73.60 | 80.22 | — |
| CTLG | 57.69 | 75.79 | 82.67 | — |
| CFine | 60.83 | 76.55 | 82.42 | — |
| IRRA | 63.46 | 80.25 | 85.82 | 38.06 |
| BiLMa | 63.83 | 80.15 | 85.74 | 38.26 |
| TBPS-CLIP | 65.05 | 80.34 | 85.47 | 39.83 |
| 本文方法 | 66.26 | 80.99 | 86.12 | 39.81 |
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 56.67 | 78.09 | 86.62 | 44.25 |
| DSSL | 32.43 | 55.08 | 63.19 | — |
| SSAN | 43.50 | 67.80 | 77.15 | — |
| IVT | 46.70 | 70.00 | 78.80 | — |
| CFine | 50.55 | 72.50 | 81.60 | — |
| IRRA | 60.20 | 81.30 | 88.20 | 47.17 |
| BiLMa | 61.20 | 81.50 | 88.80 | 48.51 |
| TBPS-CLIP | 61.95 | 83.55 | 88.75 | 48.26 |
| 本文方法 | 62.85 | 84.63 | 89.92 | 48.79 |
Tab. 3 Performance comparison of different methods on RSTPReid dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 56.67 | 78.09 | 86.62 | 44.25 |
| DSSL | 32.43 | 55.08 | 63.19 | — |
| SSAN | 43.50 | 67.80 | 77.15 | — |
| IVT | 46.70 | 70.00 | 78.80 | — |
| CFine | 50.55 | 72.50 | 81.60 | — |
| IRRA | 60.20 | 81.30 | 88.20 | 47.17 |
| BiLMa | 61.20 | 81.50 | 88.80 | 48.51 |
| TBPS-CLIP | 61.95 | 83.55 | 88.75 | 48.26 |
| 本文方法 | 62.85 | 84.63 | 89.92 | 48.79 |

Fig. 2 Visualization results on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| GA | 60.08 | 77.50 | 83.50 | 34.50 |
| LA | 60.32 | 77.94 | 83.78 | 35.01 |
| MGCA(GA+LA) | 63.20 | 79.80 | 85.10 | 36.80 |
| MGCA+SSC | 65.10 | 80.30 | 85.80 | 38.50 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
Tab. 4 Ablations experimental results on CUHK-PEDES dataset
| 方法 | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| baseline | 57.44 | 75.79 | 82.22 | 33.03 |
| GA | 60.08 | 77.50 | 83.50 | 34.50 |
| LA | 60.32 | 77.94 | 83.78 | 35.01 |
| MGCA(GA+LA) | 63.20 | 79.80 | 85.10 | 36.80 |
| MGCA+SSC | 65.10 | 80.30 | 85.80 | 38.50 |
| 本文方法 | 66.13 | 80.95 | 86.32 | 39.88 |
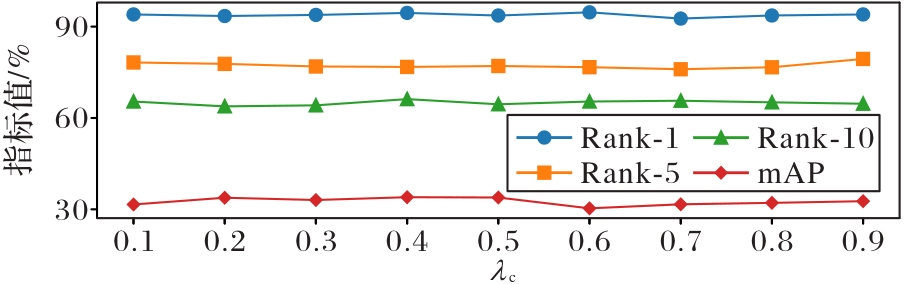
Fig. 3 Parameter analysis
| 1 | YU C, LIU X, WANG Y, et al. TF-CLIP: learning text-free CLIP for video-based person re-identification [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6764-6772. |
| 2 | GAO L, NIU K, JIAO B, et al. Addressing information inequality for text-based person search via pedestrian-centric visual denoising and bias-aware alignments [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(12): 7884-7899. |
| 3 | ZHUANG W, GAN X, WEN Y, et al. Optimizing performance of federated person re-identification: benchmarking and analysis [J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(1s): No.38. |
| 4 | 姜定,叶茫. 面向跨模态文本到图像行人重识别的Transformer网络[J]. 中国图象图形学报, 2023, 28(5): 1384-1395. |
| JIANG D, YE M. Transformer network for cross-modal text-to-image person re-identification [J]. Journal of Image and Graphics, 2023, 28(5): 1384-1395. | |
| 5 | LI J, JIANG M, KONG J, et al. Learning semantic polymorphic mapping for text-based person retrieval [J]. IEEE Transactions on Multimedia, 2024, 26: 10678-10691. |
| 6 | WANG D, YAN F, WANG Y, et al. Fine-grained semantics-aware representation learning for text-based person retrieval [C]// Proceedings of the 14th Annual ACM International Conference on Multimedia Retrieval. New York: ACM, 2024: 92-100. |
| 7 | YAN S, TANG H, ZHANG L, et al. Image-specific information suppression and implicit local alignment for text-based person search[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 17973-17986. |
| 8 | GAO C, CAI G, JIANG X, et al. Conditional feature learning based Transformer for text-based person search [J]. IEEE Transactions on Image Processing, 2022, 31: 6097-6108. |
| 9 | AGGARWAL S, BABU R V, CHAKRABORTY A. Text-based person search via attribute-aided matching [C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 2606-2614. |
| 10 | BAO L, WEI L, ZHOU W, et al. Multi-granularity matching Transformer for text-based person search [J]. IEEE Transactions on Multimedia, 2024, 26: 4281-4293. |
| 11 | ZUO J, ZHOU H, NIE Y, et al. UFineBench: towards text-based person retrieval with ultra-fine granularity [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 22010-22019. |
| 12 | WU X, MA W, GUO D, et al. Text-based occluded person re-identification via multi-granularity contrastive consistency learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6162-6170. |
| 13 | KANG B, CHEN B, WANG J, et al. Multi-path exploration and feedback adjustment for text-to-image person retrieval [EB/OL]. [2024-12-13]. . |
| 14 | KANG B, CHEN B, WANG J, et al. Multi-attribute consistency driven visual language framework for surface defect detection [C]// Proceedings of the 2024 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2024: 1-5. |
| 15 | MINDERER M, GRITSENKO A, HOULSBY N. Scaling open-vocabulary object detection [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 72983-73007. |
| 16 | HONG W, WANG W, DING M, et al. CogVLM2: visual language models for image and video understanding [EB/OL]. [2024-07-13].. |
| 17 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 18 | JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4904-4916. |
| 19 | WANG A, YU J, YU A W, et al. SimVLM: simple visual language model pretraining with weak supervision [EB/OL]. [2024-07-13]. . |
| 20 | LI J, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 9694-9705. |
| 21 | JING Y, WANG W, WANG L, et al. Cross-modal cross-domain moment alignment network for person search [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10675-10683. |
| 22 | LIN D, PENG Y X, MENG J, et al. Cross-modal adaptive dual association for text-to-image person retrieval [J]. IEEE Transactions on Multimedia, 2024, 26: 6609-6620. |
| 23 | ZUO J, HONG J, ZHANG F, et al. PLIP: language-image pre-training for person representation learning [EB/OL]. [2024-07-13]. . |
| 24 | DENG Y, HU Z, HAN J, et al. DualFocus: integrating plausible descriptions in text-based person re-identification [EB/OL]. [2024-07-08]. . |
| 25 | DING Z, DING C, SHAO Z, et al. Semantically self-aligned network for text-to-image part-aware person re-identification [EB/OL]. [2024-02-15]. . |
| 26 | ZHU A, WANG Z, LI Y, et al. DSSL: deep surroundings-person separation learning for text-based person retrieval [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 209-217. |
| 27 | WU H, CHEN W, LIU Z, et al. Contrastive Transformer learning with proximity data generation for text-based person search [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(8): 7005-7016. |
| 28 | YAN S, DONG N, ZHANG L, et al. CLIP-driven fine-grained text-image person re-identification [J]. IEEE Transactions on Image Processing, 2023, 32: 6032-6046. |
| 29 | JIANG D, YE M. Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2787-2797. |
| 30 | FUJII T, TARASHIMA S. BiLMa: bidirectional local-matching for text-based person re-identification [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 2778-2782. |
| 31 | CAO M, BAI Y, ZENG Z, et al. An empirical study of CLIP for text-based person search [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 465-473. |
| 32 | SHU X, WEN W, WU H, et al. See finer, see more: implicit modality alignment for text-based person retrieval [C]// Proceedings of the 2022 European Conference on Computer Vision Workshops, LNCS 13805. Cham: Springer, 2023: 624-641. |
| [1] | . Concrete pavement crack detection network with progressive context interaction and attention mechanism [J]. Journal of Computer Applications, 0, (): 0-0. |
| [2] | . Adaptive face recognition in low light scenes based on feature fusion [J]. Journal of Computer Applications, 0, (): 0-0. |
| [3] | Hong SHANGGUAN, Huiying REN, Xiong ZHANG, Xinglong HAN, Zhiguo GUI, Yanling WANG. Low-dose CT denoising model based on dual encoder-decoder generative adversarial network [J]. Journal of Computer Applications, 2025, 45(2): 624-632. |
| [4] | Qiurun HE, Jie HU, Bo PENG, Tianyuan LI. Fabric defect detection algorithm based on context information and multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(2): 640-646. |
| [5] | Songsen YU, Zhifan LIN, Guopeng XUE, Jianyu XU. Lightweight large-format tile defect detection algorithm based on improved YOLOv8 [J]. Journal of Computer Applications, 2025, 45(2): 647-654. |
| [6] | . 7T ultra-high field magnetic resonance parallel imaging algorithm based on residual complex convolution network [J]. Journal of Computer Applications, 0, (): 0-0. |
| [7] | . Human parsing method with aggregation of generalized contextual features [J]. Journal of Computer Applications, 0, (): 0-0. |
| [8] | . Pavement defect detection algorithm with enhanced morphological perception [J]. Journal of Computer Applications, 0, (): 0-0. |
| [9] | Jietao LIANG, Bing LUO, Lanhui FU, Qingling CHANG, Nannan LI, Ningbo YI, Qi FENG, Xin HE, Fuqin DENG. Point cloud registration method based on coordinate geometric sampling [J]. Journal of Computer Applications, 2025, 45(1): 214-222. |
| [10] | Ying HUANG, Changsheng LI, Hui PENG, Su LIU. Dual-branch network guided by local entropy for dynamic scene high dynamic range imaging [J]. Journal of Computer Applications, 2025, 45(1): 204-213. |
| [11] | . Data augmentation method for abnormal passenger behavior in elevators based on dynamic graph convolutional network [J]. Journal of Computer Applications, 0, (): 0-0. |
| [12] | Chuanjiang ZHENG, Xuefu JIA, Xinyu YANG, Xiaoxue LI. Intelligent completion method for weak texture scene in 3D reconstruction [J]. Journal of Computer Applications, 0, (): 206-211. |
| [13] | Yuwan LIU, Zhiyi GUO, Guanyu XING, Yanli LIU. Variation-aware online dynamic illumination estimation method for indoor scenes [J]. Journal of Computer Applications, 0, (): 184-191. |
| [14] | Zhanyang LIU, Jinfeng LIU. Data-free class incremental learning based on knowledge distillation [J]. Journal of Computer Applications, 0, (): 12-17. |
| [15] | . Image Caption Method Based on Swin-Transformer and Multi-Scale Feature Fusion [J]. Journal of Computer Applications, 0, (): 0-0. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||