


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (10): 3284-3293.DOI: 10.11772/j.issn.1001-9081.2024101463
• Multimedia computing and computer simulation • Previous Articles
Gengzangcuomao1,2, Heming HUANG1,2( )
)
Received:2024-10-21
Revised:2025-03-02
Accepted:2025-03-10
Online:2025-10-14
Published:2025-10-10
Contact:
Heming HUANG
About author:Gengzangcuomao, born in 1993, Ph. D. candidate, lecturer. Her research interests include speech enhancement, speech recognition.Supported by:
更藏措毛null1,2, 黄鹤鸣1,2()
通讯作者:
黄鹤鸣
作者简介:更藏措毛(1993—),女(藏族),青海共和县人,讲师,博士研究生,CCF会员,主要研究方向:语音增强、语音识别基金资助:CLC Number:
Gengzangcuomao, Heming HUANG. Monaural speech enhancement with heterogeneous dual-branch decoding based on multi-view attention[J]. Journal of Computer Applications, 2025, 45(10): 3284-3293.
更藏措毛null, 黄鹤鸣. 基于多视角注意力的异构双分支解码单通道语音增强[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3284-3293.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024101463
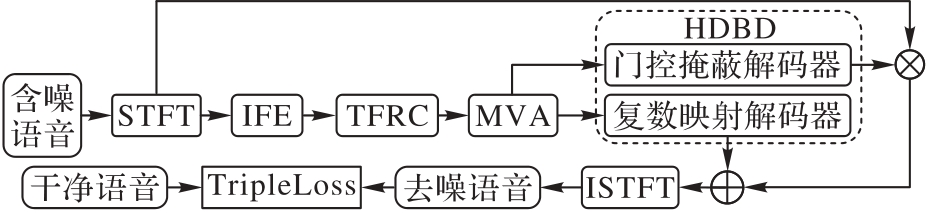
Fig. 1 Overall structure of HDMPV
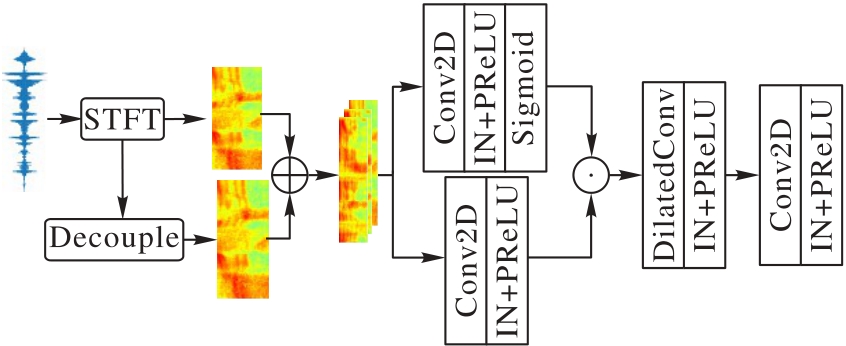
Fig. 2 Structure of information fusion encoder
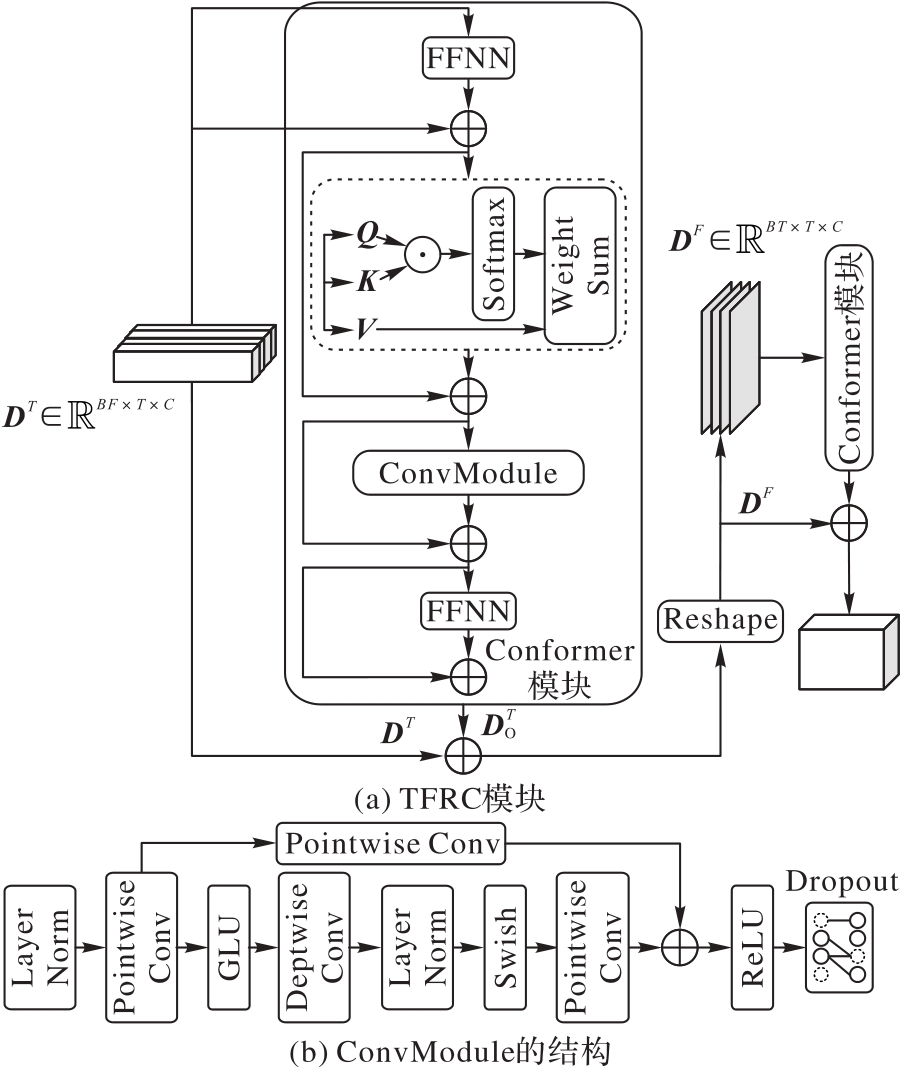
Fig. 3 Structures of TFRC and its submodule ConvModule
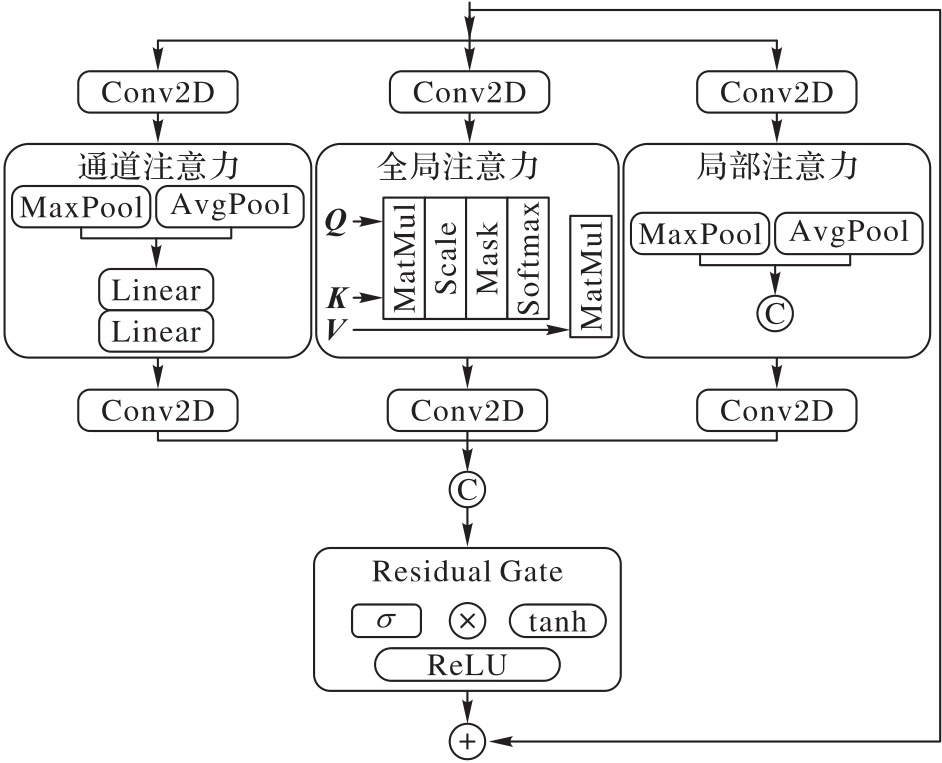
Fig. 4 Structure of multi-view attention module
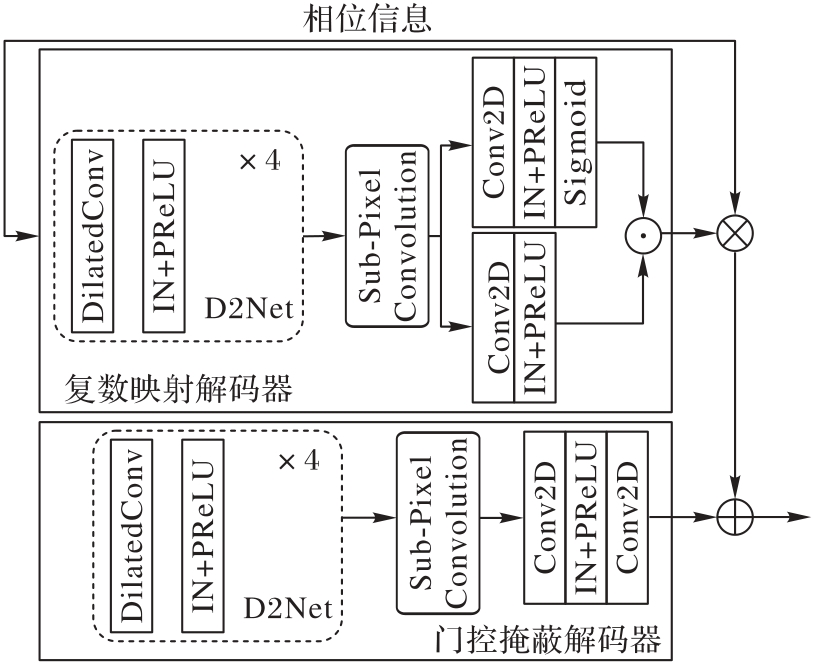
Fig. 5 Structure of HDBD module
| 模块 | 层名 | 输入尺寸 | 超参数 | 输出尺寸 |
|---|---|---|---|---|
| IFE | gatedconvblock | 3×257×257 | (1,1),(1,1),64 | 64×257×257 |
| dilatedconv_1 | 64×257×257 | (2,3),(1,1),128,1 | 128×257×257 | |
| dilatedconv_2 | 128×257×257 | (2,3),(1,1),192,2 | 192×257×257 | |
| dilatedconv_3 | 192×257×257 | (2,3),(1,1),256,4 | 256×257×257 | |
| dilatedconv_4 | 256×257×257 | (2,3),(1,1),320,8 | 320×257×257 | |
| convblock | 320×257×257 | (1,1),(1,1),64 | 64×257×129 | |
| Reshape-size | 64×257×129 | — | 258×257×64 | |
| TFRC | TimeresidualConformer | 258×257×64 | Head=4,Channel=64,Dropout=0.2 | 258×257×64 |
| Reshape-size | 258×257×64 | — | 514×129×64 | |
| FrequencyresidualConformer | 514×129×64 | Head=4,Channel=64,Dropout=0.2 | 514×129×64 | |
| Reshape-size | 514×129×64 | — | 64×257×129 | |
| MVA | MViAtt | 514×129×64 | — | 64×257×129 |
| 门控掩蔽解码器 | dilateconv_1 | 64×257×129 | (2,3),(1,1),128,1 | 128×257×129 |
| dilatedconv_2 | 128×257×129 | (2,3),(1,1),192,2 | 192×257×129 | |
| dilatedconv_3 | 192×257×129 | (2,3),(1,1),256,4 | 256×257×129 | |
| dilatedconv_4 | 256×257×129 | (2,3),(1,1),320,8 | 320×257×129 | |
| Sub-pixelconv | 320×257×129 | (1,3),(1,1),64 | 64×257×258 | |
| gatedconvblock | 64×257×258 | (1,1),(1,1),1 | 1×257×257 | |
| 复数映射解码器 | dilateconv_1 | 64×257×129 | (2,3),(1,1),128,1 | 128×257×129 |
| dilatedconv_2 | 128×257×129 | (2,3),(1,1),192,2 | 192×257×129 | |
| dilatedconv_3 | 192×257×129 | (2,3),(1,1),256,4 | 256×257×129 | |
| dilatedconv_4 | 256×257×129 | (2,3),(1,1),320,8 | 64×257×129 | |
| Sub-pixelconv | 64×257×129 | (1,3),(1,1),64 | 64×257×258 | |
| convblock | 64×257×258 | (1,2),(1,1),2 | 2×257×257 | |
Tab. 1 Parameter setting of HDBMV
| 模块 | 层名 | 输入尺寸 | 超参数 | 输出尺寸 |
|---|---|---|---|---|
| IFE | gatedconvblock | 3×257×257 | (1,1),(1,1),64 | 64×257×257 |
| dilatedconv_1 | 64×257×257 | (2,3),(1,1),128,1 | 128×257×257 | |
| dilatedconv_2 | 128×257×257 | (2,3),(1,1),192,2 | 192×257×257 | |
| dilatedconv_3 | 192×257×257 | (2,3),(1,1),256,4 | 256×257×257 | |
| dilatedconv_4 | 256×257×257 | (2,3),(1,1),320,8 | 320×257×257 | |
| convblock | 320×257×257 | (1,1),(1,1),64 | 64×257×129 | |
| Reshape-size | 64×257×129 | — | 258×257×64 | |
| TFRC | TimeresidualConformer | 258×257×64 | Head=4,Channel=64,Dropout=0.2 | 258×257×64 |
| Reshape-size | 258×257×64 | — | 514×129×64 | |
| FrequencyresidualConformer | 514×129×64 | Head=4,Channel=64,Dropout=0.2 | 514×129×64 | |
| Reshape-size | 514×129×64 | — | 64×257×129 | |
| MVA | MViAtt | 514×129×64 | — | 64×257×129 |
| 门控掩蔽解码器 | dilateconv_1 | 64×257×129 | (2,3),(1,1),128,1 | 128×257×129 |
| dilatedconv_2 | 128×257×129 | (2,3),(1,1),192,2 | 192×257×129 | |
| dilatedconv_3 | 192×257×129 | (2,3),(1,1),256,4 | 256×257×129 | |
| dilatedconv_4 | 256×257×129 | (2,3),(1,1),320,8 | 320×257×129 | |
| Sub-pixelconv | 320×257×129 | (1,3),(1,1),64 | 64×257×258 | |
| gatedconvblock | 64×257×258 | (1,1),(1,1),1 | 1×257×257 | |
| 复数映射解码器 | dilateconv_1 | 64×257×129 | (2,3),(1,1),128,1 | 128×257×129 |
| dilatedconv_2 | 128×257×129 | (2,3),(1,1),192,2 | 192×257×129 | |
| dilatedconv_3 | 192×257×129 | (2,3),(1,1),256,4 | 256×257×129 | |
| dilatedconv_4 | 256×257×129 | (2,3),(1,1),320,8 | 64×257×129 | |
| Sub-pixelconv | 64×257×129 | (1,3),(1,1),64 | 64×257×258 | |
| convblock | 64×257×258 | (1,2),(1,1),2 | 2×257×257 | |
| 时频域 | 模型 | 模型 大小/106 | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|---|---|
| Noisy | 1.97 | 0.79 | 3.35 | 2.44 | 2.63 | ||
| 时域 | DPTNet | 2.69 | 2.78 | — | 3.92 | 3.40 | 3.36 |
| SE-Flow | — | 2.43 | — | 3.77 | 3.12 | 3.09 | |
| CDiffuSE | — | 2.52 | — | 3.72 | 2.91 | 3.10 | |
| DiffWave | 6.91 | 2.52 | — | 3.72 | 3.27 | 3.11 | |
| SEGAN | — | 2.16 | 0.92 | 3.48 | 2.94 | 2.80 | |
| FSPEN | — | 2.97 | 0.94 | — | — | — | |
| MOSE | — | 2.54 | — | 3.72 | 2.93 | 3.06 | |
| ROSE | 36.98 | 3.01 | 0.95 | 3.56 | 3.72 | 4.47 | |
| 频域 | DCTCN | 9.70 | 2.83 | — | 3.91 | 3.37 | 3.37 |
| NAAGN | — | 2.79 | — | 3.99 | 3.38 | 3.32 | |
| TFT-Net | — | 2.71 | 0.95 | 3.86 | 3.39 | 3.25 | |
| MMSE-GAN | — | 2.53 | — | 3.80 | 3.12 | 3.14 | |
| S4D | 10.80 | 2.55 | 0.93 | 3.94 | 3.00 | 3.23 | |
| MetricGAN | — | 2.86 | — | 3.99 | 3.18 | 3.42 | |
| PMOS | — | 2.98 | 0.87 | — | — | — | |
| DeepFilterNet | 1.80 | 2.81 | — | — | — | — | |
| HDBMV | 1.80 | 3.00 | 0.96 | 3.96 | 3.64 | 3.45 | |
Tab. 2 Performance comparison of different models on VoiceBank+DEMAND dataset
| 时频域 | 模型 | 模型 大小/106 | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|---|---|
| Noisy | 1.97 | 0.79 | 3.35 | 2.44 | 2.63 | ||
| 时域 | DPTNet | 2.69 | 2.78 | — | 3.92 | 3.40 | 3.36 |
| SE-Flow | — | 2.43 | — | 3.77 | 3.12 | 3.09 | |
| CDiffuSE | — | 2.52 | — | 3.72 | 2.91 | 3.10 | |
| DiffWave | 6.91 | 2.52 | — | 3.72 | 3.27 | 3.11 | |
| SEGAN | — | 2.16 | 0.92 | 3.48 | 2.94 | 2.80 | |
| FSPEN | — | 2.97 | 0.94 | — | — | — | |
| MOSE | — | 2.54 | — | 3.72 | 2.93 | 3.06 | |
| ROSE | 36.98 | 3.01 | 0.95 | 3.56 | 3.72 | 4.47 | |
| 频域 | DCTCN | 9.70 | 2.83 | — | 3.91 | 3.37 | 3.37 |
| NAAGN | — | 2.79 | — | 3.99 | 3.38 | 3.32 | |
| TFT-Net | — | 2.71 | 0.95 | 3.86 | 3.39 | 3.25 | |
| MMSE-GAN | — | 2.53 | — | 3.80 | 3.12 | 3.14 | |
| S4D | 10.80 | 2.55 | 0.93 | 3.94 | 3.00 | 3.23 | |
| MetricGAN | — | 2.86 | — | 3.99 | 3.18 | 3.42 | |
| PMOS | — | 2.98 | 0.87 | — | — | — | |
| DeepFilterNet | 1.80 | 2.81 | — | — | — | — | |
| HDBMV | 1.80 | 3.00 | 0.96 | 3.96 | 3.64 | 3.45 | |
| 模型 | PESQ | STOI | 模型大小/106 | MAC/109 |
|---|---|---|---|---|
| CA DU-Net | 1.99 | 0.83 | 26.00 | — |
| FasNet TAC | 2.26 | 0.87 | 2.90 | 55.3 |
| DCCRN | 2.57 | 0.90 | 18.00 | 14.4 |
| TPARN | 2.75 | 0.92 | 3.20 | 71.8 |
| ADCN | 2.84 | 0.92 | 9.30 | 72.8 |
| DRC-NET | 2.79 | 0.89 | 2.60 | 13.9 |
| DeFT-AN | 3.01 | 0.92 | 2.70 | 95.6 |
| aTENNuate | 2.98 | — | — | — |
| HDBMV | 3.12 | 0.97 | 1.80 | 65.1 |
Tab. 3 Performance comparison of different models on DNS Challenge 2020 dataset
| 模型 | PESQ | STOI | 模型大小/106 | MAC/109 |
|---|---|---|---|---|
| CA DU-Net | 1.99 | 0.83 | 26.00 | — |
| FasNet TAC | 2.26 | 0.87 | 2.90 | 55.3 |
| DCCRN | 2.57 | 0.90 | 18.00 | 14.4 |
| TPARN | 2.75 | 0.92 | 3.20 | 71.8 |
| ADCN | 2.84 | 0.92 | 9.30 | 72.8 |
| DRC-NET | 2.79 | 0.89 | 2.60 | 13.9 |
| DeFT-AN | 3.01 | 0.92 | 2.70 | 95.6 |
| aTENNuate | 2.98 | — | — | — |
| HDBMV | 3.12 | 0.97 | 1.80 | 65.1 |
| 噪声环境 | SNR/dB | PESQ | STOI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | ||
已知噪声 (pink) | -5 | 1.11 | 1.12 | 1.30 | 1.42 | 1.22 | 1.50 | 0.57 | 0.60 | 0.67 | 0.71 | 0.59 | 0.72 |
| 0 | 1.15 | 1.18 | 1.53 | 1.75 | 1.37 | 1.82 | 0.67 | 0.67 | 0.76 | 0.79 | 0.68 | 0.79 | |
| 5 | 1.23 | 1.30 | 1.84 | 2.14 | 1.63 | 2.16 | 0.76 | 0.76 | 0.81 | 0.84 | 0.75 | 0.84 | |
| 10 | 1.42 | 1.50 | 2.10 | 2.53 | 1.91 | 2.46 | 0.83 | 0.83 | 0.85 | 0.88 | 0.78 | 0.87 | |
| 15 | 1.73 | 1.74 | 2.33 | 2.88 | 2.14 | 2.76 | 0.87 | 0.87 | 0.87 | 0.90 | 0.80 | 0.90 | |
未知噪声 (white) | -6 | 1.13 | 1.12 | 1.20 | 1.19 | 1.15 | 1.39 | 0.61 | 0.61 | 0.63 | 0.68 | 0.63 | 0.72 |
| 0 | 1.15 | 1.16 | 1.40 | 1.32 | 1.31 | 1.76 | 0.70 | 0.70 | 0.75 | 0.78 | 0.71 | 0.80 | |
| 5 | 1.21 | 1.24 | 1.64 | 1.49 | 1.59 | 2.15 | 0.77 | 0.76 | 0.80 | 0.83 | 0.77 | 0.84 | |
| 12 | 1.41 | 1.39 | 2.05 | 1.89 | 2.06 | 2.57 | 0.84 | 0.82 | 0.85 | 0.88 | 0.81 | 0.88 | |
| 15 | 1.57 | 1.51 | 2.20 | 2.13 | 2.19 | 2.73 | 0.87 | 0.84 | 0.87 | 0.90 | 0.81 | 0.89 | |
Tab. 4 PESQ and STOI value comparison of different models on BodSpeDB dataset in stationary noise environment
| 噪声环境 | SNR/dB | PESQ | STOI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | ||
已知噪声 (pink) | -5 | 1.11 | 1.12 | 1.30 | 1.42 | 1.22 | 1.50 | 0.57 | 0.60 | 0.67 | 0.71 | 0.59 | 0.72 |
| 0 | 1.15 | 1.18 | 1.53 | 1.75 | 1.37 | 1.82 | 0.67 | 0.67 | 0.76 | 0.79 | 0.68 | 0.79 | |
| 5 | 1.23 | 1.30 | 1.84 | 2.14 | 1.63 | 2.16 | 0.76 | 0.76 | 0.81 | 0.84 | 0.75 | 0.84 | |
| 10 | 1.42 | 1.50 | 2.10 | 2.53 | 1.91 | 2.46 | 0.83 | 0.83 | 0.85 | 0.88 | 0.78 | 0.87 | |
| 15 | 1.73 | 1.74 | 2.33 | 2.88 | 2.14 | 2.76 | 0.87 | 0.87 | 0.87 | 0.90 | 0.80 | 0.90 | |
未知噪声 (white) | -6 | 1.13 | 1.12 | 1.20 | 1.19 | 1.15 | 1.39 | 0.61 | 0.61 | 0.63 | 0.68 | 0.63 | 0.72 |
| 0 | 1.15 | 1.16 | 1.40 | 1.32 | 1.31 | 1.76 | 0.70 | 0.70 | 0.75 | 0.78 | 0.71 | 0.80 | |
| 5 | 1.21 | 1.24 | 1.64 | 1.49 | 1.59 | 2.15 | 0.77 | 0.76 | 0.80 | 0.83 | 0.77 | 0.84 | |
| 12 | 1.41 | 1.39 | 2.05 | 1.89 | 2.06 | 2.57 | 0.84 | 0.82 | 0.85 | 0.88 | 0.81 | 0.88 | |
| 15 | 1.57 | 1.51 | 2.20 | 2.13 | 2.19 | 2.73 | 0.87 | 0.84 | 0.87 | 0.90 | 0.81 | 0.89 | |
| 噪声环境 | SNR/dB | PESQ | STOI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | ||
已知噪声 (Babble) | -5 | 1.20 | 1.20 | 1.30 | 1.32 | 1.23 | 1.39 | 0.54 | 0.56 | 0.62 | 0.63 | 0.51 | 0.67 |
| 0 | 1.24 | 1.31 | 1.52 | 1.57 | 1.35 | 1.71 | 0.66 | 0.58 | 0.75 | 0.75 | 0.62 | 0.77 | |
| 5 | 1.36 | 1.50 | 1.77 | 1.94 | 1.53 | 2.05 | 0.75 | 0.75 | 0.81 | 0.83 | 0.70 | 0.83 | |
| 10 | 1.62 | 1.78 | 2.06 | 2.40 | 1.80 | 2.39 | 0.82 | 0.82 | 0.85 | 0.87 | 0.76 | 0.87 | |
| 15 | 2.01 | 2.06 | 2.29 | 2.80 | 2.02 | 2.72 | 0.87 | 0.87 | 0.87 | 0.90 | 0.79 | 0.89 | |
未知噪声 (Buccaneer1) | -6 | 1.12 | 1.12 | 1.19 | 1.20 | 1.16 | 1.34 | 0.52 | 0.54 | 0.58 | 0.61 | 0.52 | 0.67 |
| 0 | 1.15 | 1.18 | 1.37 | 1.39 | 1.28 | 1.68 | 0.65 | 0.66 | 0.72 | 0.73 | 0.64 | 0.77 | |
| 5 | 1.22 | 1.29 | 1.65 | 1.69 | 1.48 | 2.03 | 0.73 | 0.74 | 0.79 | 0.80 | 0.71 | 0.82 | |
| 12 | 1.48 | 1.56 | 2.03 | 2.23 | 1.88 | 2.49 | 0.82 | 0.81 | 0.84 | 0.87 | 0.78 | 0.87 | |
| 15 | 1.66 | 1.7 | 2.19 | 2.48 | 2.04 | 2.69 | 0.85 | 0.83 | 0.86 | 0.89 | 0.80 | 0.88 | |
Tab. 5 PESQ and STOI values comparison of different models on BodSpeDB dataset in non-stationary noise environment
| 噪声环境 | SNR/dB | PESQ | STOI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | Noisy | CRN | GCRN | TSTNN | DPTFSNET | HDBMV | ||
已知噪声 (Babble) | -5 | 1.20 | 1.20 | 1.30 | 1.32 | 1.23 | 1.39 | 0.54 | 0.56 | 0.62 | 0.63 | 0.51 | 0.67 |
| 0 | 1.24 | 1.31 | 1.52 | 1.57 | 1.35 | 1.71 | 0.66 | 0.58 | 0.75 | 0.75 | 0.62 | 0.77 | |
| 5 | 1.36 | 1.50 | 1.77 | 1.94 | 1.53 | 2.05 | 0.75 | 0.75 | 0.81 | 0.83 | 0.70 | 0.83 | |
| 10 | 1.62 | 1.78 | 2.06 | 2.40 | 1.80 | 2.39 | 0.82 | 0.82 | 0.85 | 0.87 | 0.76 | 0.87 | |
| 15 | 2.01 | 2.06 | 2.29 | 2.80 | 2.02 | 2.72 | 0.87 | 0.87 | 0.87 | 0.90 | 0.79 | 0.89 | |
未知噪声 (Buccaneer1) | -6 | 1.12 | 1.12 | 1.19 | 1.20 | 1.16 | 1.34 | 0.52 | 0.54 | 0.58 | 0.61 | 0.52 | 0.67 |
| 0 | 1.15 | 1.18 | 1.37 | 1.39 | 1.28 | 1.68 | 0.65 | 0.66 | 0.72 | 0.73 | 0.64 | 0.77 | |
| 5 | 1.22 | 1.29 | 1.65 | 1.69 | 1.48 | 2.03 | 0.73 | 0.74 | 0.79 | 0.80 | 0.71 | 0.82 | |
| 12 | 1.48 | 1.56 | 2.03 | 2.23 | 1.88 | 2.49 | 0.82 | 0.81 | 0.84 | 0.87 | 0.78 | 0.87 | |
| 15 | 1.66 | 1.7 | 2.19 | 2.48 | 2.04 | 2.69 | 0.85 | 0.83 | 0.86 | 0.89 | 0.80 | 0.88 | |
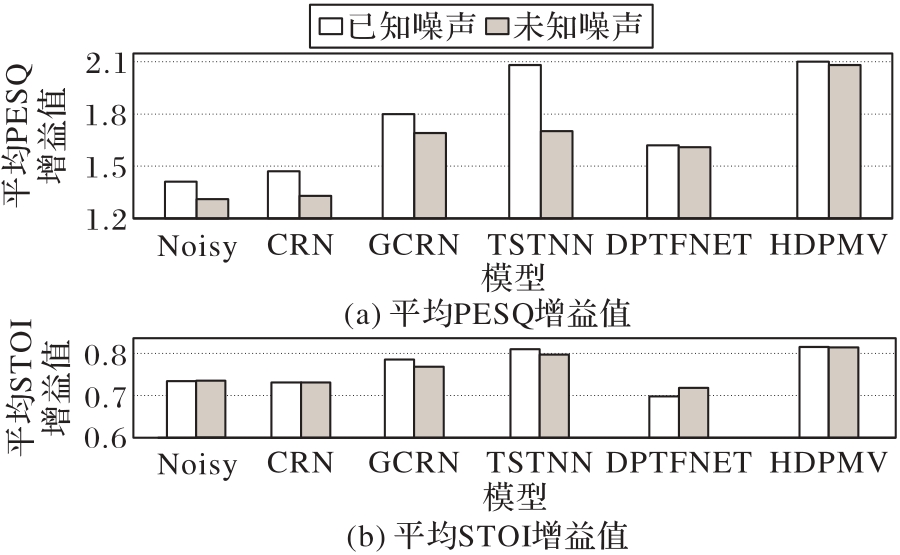
Fig. 6 Average PESQ and average STOI gain values of different models in known and unknown noise environments
| 模型 | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|
| 基线0 | 2.85 | 0.95 | 3.62 | 3.56 | 3.22 |
| 基线1 | 3.00 | 0.96 | 3.86 | 3.56 | 3.41 |
| IFE | 2.97 | 0.96 | 3.93 | 3.64 | 3.43 |
| IFE+HDBD | 2.97 | 0.96 | 3.93 | 3.64 | 3.44 |
| IFE+HDBD+TFRC | 3.00 | 0.96 | 3.95 | 3.63 | 3.44 |
| HDBMV | 3.00 | 0.96 | 3.96 | 3.64 | 3.45 |
Tab. 6 Ablation study results on VoiceBank+DEMAND dataset
| 模型 | PESQ | STOI | CSIG | CBAK | COVL |
|---|---|---|---|---|---|
| 基线0 | 2.85 | 0.95 | 3.62 | 3.56 | 3.22 |
| 基线1 | 3.00 | 0.96 | 3.86 | 3.56 | 3.41 |
| IFE | 2.97 | 0.96 | 3.93 | 3.64 | 3.43 |
| IFE+HDBD | 2.97 | 0.96 | 3.93 | 3.64 | 3.44 |
| IFE+HDBD+TFRC | 3.00 | 0.96 | 3.95 | 3.63 | 3.44 |
| HDBMV | 3.00 | 0.96 | 3.96 | 3.64 | 3.45 |
| [1] | LIANG J, ZENG Q. Improved spectral subtraction based on second-order differential array and phase spectrum compensation[C]// Proceedings of the 3rd International Symposium on Computer Technology and Information Science. Piscataway: IEEE, 2023: 658-661. |
| [2] | NEO V W, EVERS C, NAYLOR P A. Enhancement of noisy reverberant speech using polynomial matrix eigenvalue decomposition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3255-3266. |
| [3] | XIANG Y, HØJVANG J L, RASMUSSEN M H, et al. A two-stage deep representation learning-based speech enhancement method using variational autoencoder and adversarial training[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 164-177. |
| [4] | REN J, MAO Q. DCTCN: deep complex temporal convolutional network for long time speech enhancement[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 5478-5482. |
| [5] | SONI M H, SHAH N, PATIL H A. Time-frequency masking-based speech enhancement using generative adversarial network[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5039-5043. |
| [6] | CHEN J, MAO Q, LIU D. Dual-path Transformer network: direct context-aware modeling for end-to-end monaural speech separation[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2642-2646. |
| [7] | TANG C, LUO C, ZHAO Z, et al. Joint time frequency and time domain learning for speech enhancement[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 3816-3822. |
| [8] | 张天骐,罗庆予,张慧芝,等. 复谱映射下融合高效Transformer的语音增强方法[J]. 信号处理, 2024, 40(2): 406-416. |
| ZHANG T Q, LUO Q Y, ZHANG H Z, et al. Speech enhancement method based on complex spectrum mapping with efficient Transformer[J]. Journal of Signal Processing, 2024, 40(2): 406-416. | |
| [9] | TAN K, WANG D. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 380-390. |
| [10] | WILLIAMSON D S, WANG Y, WANG D. Complex ratio masking for monaural speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3): 483-492. |
| [11] | LIU Y, ZHANG H, ZHANG X, et al. Supervised speech enhancement with real spectrum approximation[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 5746-5750. |
| [12] | DANG F, CHEN H, ZHANG P. DPT-FSNet: dual-path Transformer based full-band and sub-band fusion network for speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6857-6861. |
| [13] | CHAU H N, BUI T D, NGUYEN H B, et al. A novel approach to multi-channel speech enhancement based on graph neural network[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 1133-1144. |
| [14] | SUN L, YUAN S, GONG A, et al. Dual-branch modeling based on state-space model for speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 1457-1467. |
| [15] | ZHAO S, MA B. D2Former: a fully complex dual-path dual-decoder Conformer network using joint complex masking and complex spectral mapping for monaural speech enhancement[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [16] | YU R, ZHAO Z, YE Z. PFRNet: dual-branch progressive fusion rectification network for monaural speech enhancement[J]. IEEE Signal Processing Letters, 2022, 29: 2358-2362. |
| [17] | 莫尚斌,王文君,董凌,等. 基于多路信息聚合协同解码的单通道语音增强[J]. 计算机应用, 2024, 44(8): 2611-2617. |
| MO S B, WANG W J, DONG L, et al. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding[J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. | |
| [18] | XIANG X, ZHANG X, CHEN H. A nest U-Net with self-attention and dense connectivity for monaural speech enhancement[J]. IEEE Signal Processing Letters, 2022, 29: 105-109. |
| [19] | WANG K, HE B, ZHU W P. TSTNN: two-stage Transformer based neural network for speech enhancement in the time domain[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 7098-7102. |
| [20] | WEI W, HU Y, HUANG H, et al. IIFC-Net: a monaural speech enhancement network with high-order information interaction and feature calibration[J]. IEEE Signal Processing Letters, 2024, 31: 196-200. |
| [21] | 琚吴涵,孙成立,陈飞龙,等. 基于Dual-path Skip-Transformer的轻量级语音增强网络[J]. 计算机工程与应用,2025,61(15):209-217. |
| JU W H, SUN C L, CHEN F L, et al. Dual-path Skip-Transformer based light weighting speech enhancement network[J]. Computer Engineering and Applications, 2025, 61(15):209-217. | |
| [22] | 王景润, 郭海燕,王婷婷,等. 基于可学习图比率掩码估计的图频域语音增强方法[J]. 信号处理, 2024, 40(12): 2249-2260. |
| WANG J R, GUO H Y, WANG T T, et al. Learnable graph ratio mask-based speech enhancement in the graph frequency domain[J]. Journal of Signal Processing, 2024, 40(12): 2249-2260. | |
| [23] | 张池,王忠,姜添豪,等. 基于并行多注意力的语音增强网络[J]. 计算机工程, 2024, 50(4):68-77. |
| ZHANG C, WANG Z, JIANG T H, et al. Speech enhancement network based on parallel multi-attention[J]. Computer Engineering, 2024, 50(4): 68-77. | |
| [24] | 高盛祥,莫尚斌,余正涛,等. 基于多维度注意力机制和复数Conformer的单通道语音增强方法[J]. 重庆邮电大学学报(自然科学版), 2024, 36(2): 393-403. |
| GAO S X, MO S B, YU Z T, et al. Monaural speech enhancement method based on multi-dimensional attention mechanism and complex Conformer[J]. Journal of Chongqing university of Posts and Telecommunications (Natural Science Edition), 2024, 36(2): 393-403. | |
| [25] | ZHANG Z, LIANG X, XU R, et al. Hybrid attention time-frequency analysis network for single-channel speech enhancement[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 10426-10430. |
| [26] | LI Y, SUN Y, WANG W, et al. U-shaped Transformer with frequency-band aware attention for speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2023, 31: 1511-1521. |
| [27] | WANG T, ZHU W, GAO Y, et al. Harmonic attention for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2424-2436. |
| [28] | DENG F, JIANG T, WANG X R, et al. NAAGN: noise-aware attention-gated network for speech enhancement[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2457-2461. |
| [29] | NAYEM K M, WILLIAMSON D S. Attention-based speech enhancement using human quality perception modeling[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 250-260. |
| [30] | LU Y J, WANG Z Q, WATANABE S, et al. Conditional diffusion probabilistic model for speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7402-7406. |
| [31] | KONG Z, PING W, HUANG J, et al. DiffWave: a versatile diffusion model for audio synthesis[EB/OL]. [2024-09-21].. |
| [32] | PASCUAL S, BONAFONTE A, SERRÀ J. SEGAN: speech enhancement generative adversarial network[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 3642-3646. |
| [33] | FU S W, LIAO C F, TSAO Y, et al. MetricGAN: generative adversarial networks based black-box metric scores optimization for speech enhancement[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2031-2041. |
| [34] | STRAUSS M, EDLER B. A flow-based neural network for time domain speech enhancement[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 5754-5758. |
| [35] | YU X, GUO D, ZHANG J, et al. ROSE: a recognition-oriented speech enhancement framework in air traffic control using multi-objective learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 3365-3378. |
| [36] | YANG L, LIU W, MENG R, et al. FSPEN: an ultra-lightweight network for real time speech enhancement[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 10671-10675. |
| [37] | SCHRÖTER H, ESCALANTE-B A N, ROSENKRANZ T, et al. DeepFilterNet: a low complexity speech enhancement framework for full-band audio based on deep filtering[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7407-7411. |
| [38] | CHEN C, HU Y, WENG W, et al. Metric-oriented speech enhancement using diffusion probabilistic model[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [39] | TOLOOSHAMS B, GIRI R, SONG A H, et al. Channel-attention dense U-Net for multichannel speech enhancement[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 836-840. |
| [40] | LUO Y, CHEN Z, MESGARANI N, et al. End-to-end microphone permutation and number invariant multi-channel speech separation[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6394-6398. |
| [41] | WANG Z Q, WANG D. Multi-microphone complex spectral mapping for speech dereverberation[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 486-490. |
| [42] | PANDEY A, XU B, KUMAR A, et al. TPARN: triple-path attentive recurrent network for time-domain multichannel speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6497-6501. |
| [43] | PANDEY A, XU B, KUMAR A, et al. Multichannel speech enhancement without beamforming[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6502-6506. |
| [44] | LIU J, ZHANG X. DRC-NET: densely connected recurrent convolutional neural network for speech dereverberation[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 166-170. |
| [45] | LEE D, CHOI J W. DeFT-AN: dense frequency-time attentive network for multichannel speech enhancement[J]. IEEE Signal Processing Letters, 2023, 30: 155-159. |
| [46] | PEI Y R, SHRIVASTAVA R, SIDHARTH. Real-time speech enhancement on raw signals with deep state-space modeling[EB/OL]. [2024-10-21]. . |
| [1] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [2] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| [3] | Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement [J]. Journal of Computer Applications, 2025, 45(9): 2957-2965. |
| [4] | Chao JING, Yutao QUAN, Yan CHEN. Improved multi-layer perceptron and attention model-based power consumption prediction algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2646-2655. |
| [5] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [6] | Haifeng WU, Liqing TAO, Yusheng CHENG. Partial label regression algorithm integrating feature attention and residual connection [J]. Journal of Computer Applications, 2025, 45(8): 2530-2536. |
| [7] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [8] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| [9] | Yihan WANG, Chong LU, Zhongyuan CHEN. Multimodal sentiment analysis model with cross-modal text information enhancement [J]. Journal of Computer Applications, 2025, 45(7): 2237-2244. |
| [10] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [11] | Xiaoqiang ZHAO, Yongyong LIU, Yongyong HUI, Kai LIU. Batch process quality prediction model using improved time-domain convolutional network with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2245-2252. |
| [12] | Huibin WANG, Zhan’ao HU, Jie HU, Yuanwei XU, Bo WEN. Time series forecasting model based on segmented attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2262-2268. |
| [13] | Haijie WANG, Guangxin ZHANG, Hai SHI, Shu CHEN. Document-level relation extraction based on entity representation enhancement [J]. Journal of Computer Applications, 2025, 45(6): 1809-1816. |
| [14] | Weigang LI, Xinyi LI, Yongqiang WANG, Yuntao ZHAO. Point cloud classification and segmentation method based on adaptive dynamic graph convolution and parameter-free attention [J]. Journal of Computer Applications, 2025, 45(6): 1980-1986. |
| [15] | Sheping ZHAI, Yan HUANG, Qing YANG, Rui YANG. Multi-view entity alignment combining triples and text attributes [J]. Journal of Computer Applications, 2025, 45(6): 1793-1800. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||