


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (3): 915-923.DOI: 10.11772/j.issn.1001-9081.2025040475
• Multimedia computing and computer simulation • Previous Articles Next Articles
Peirong SHAO, Suzhen LIN( ), Yanbo WANG
), Yanbo WANG
Received:2025-04-30
Revised:2025-06-14
Accepted:2025-06-23
Online:2025-06-26
Published:2026-03-10
Contact:
Suzhen LIN
About author:SHAO Peirong, born in 2001, M. S. candidate. Her research interests include virtual try-on, image processing.Supported by:
邵培荣, 蔺素珍(), 王彦博
通讯作者:
蔺素珍
作者简介:邵培荣(2001—),女,山西运城人,硕士研究生,CCF会员,主要研究方向:虚拟试衣、图像处理基金资助:CLC Number:
Peirong SHAO, Suzhen LIN, Yanbo WANG. Human-centric detail-enhanced virtual try-on method[J]. Journal of Computer Applications, 2026, 46(3): 915-923.
邵培荣, 蔺素珍, 王彦博. 以人为中心的细节增强虚拟试衣方法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 915-923.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025040475
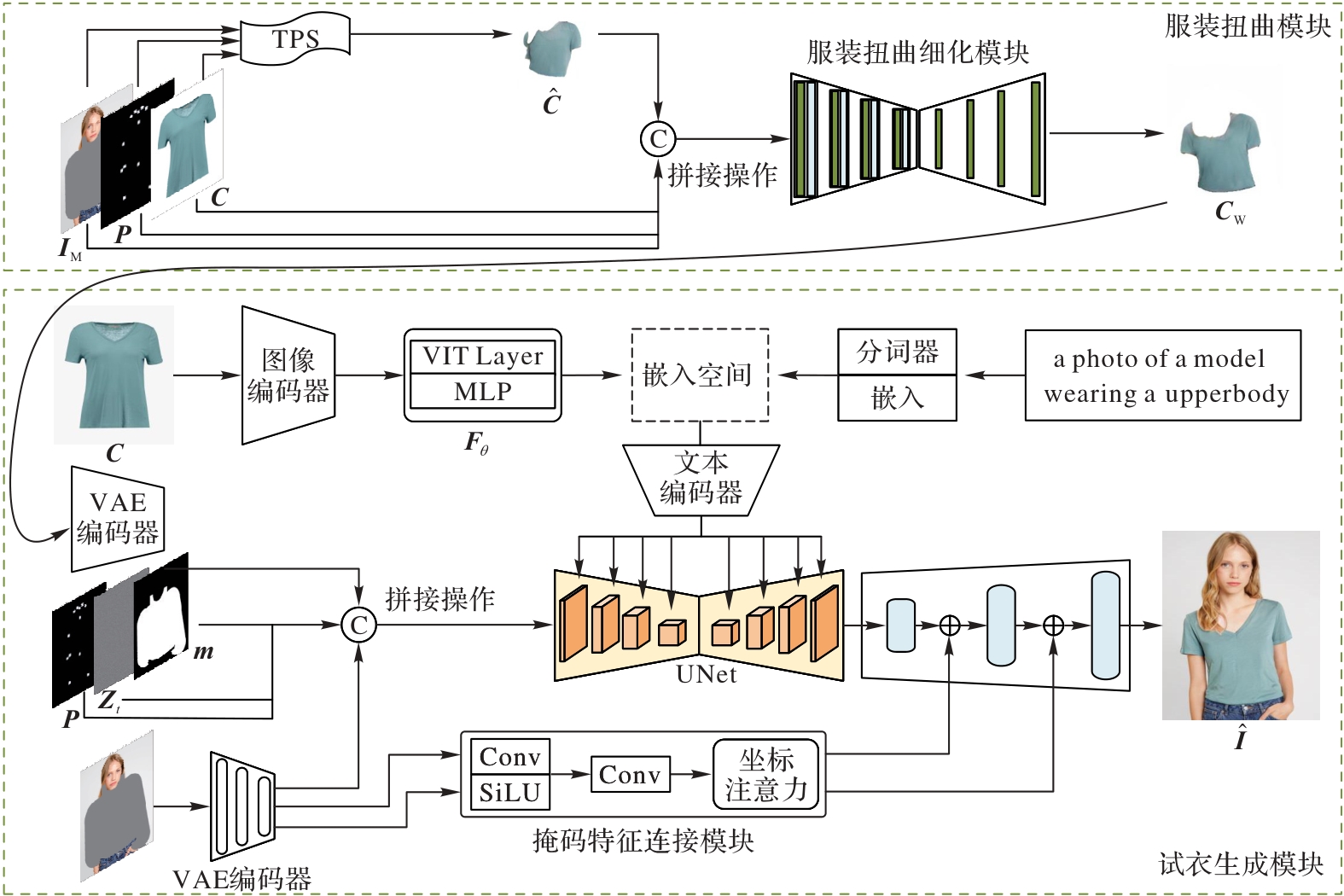
Fig. 1 Overall network structure of proposed method
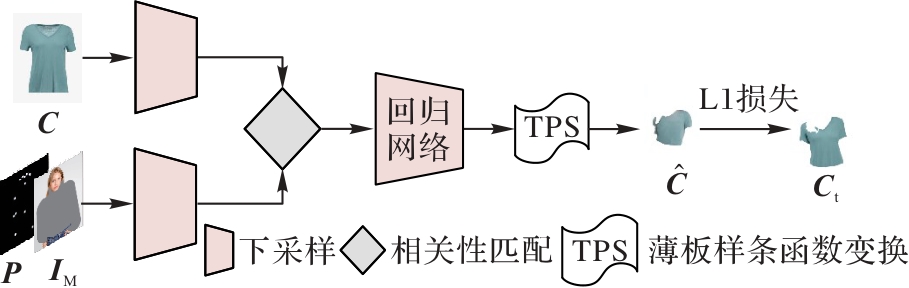
Fig. 2 Coarse warp module

Fig. 3 Comparison of garment warping results
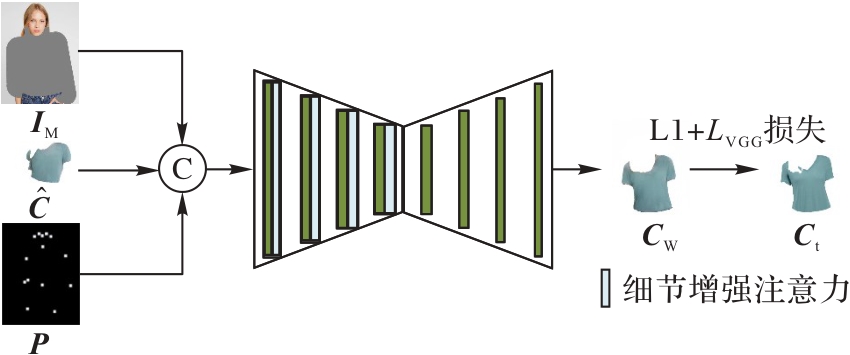
Fig. 4 Structure of GWR module
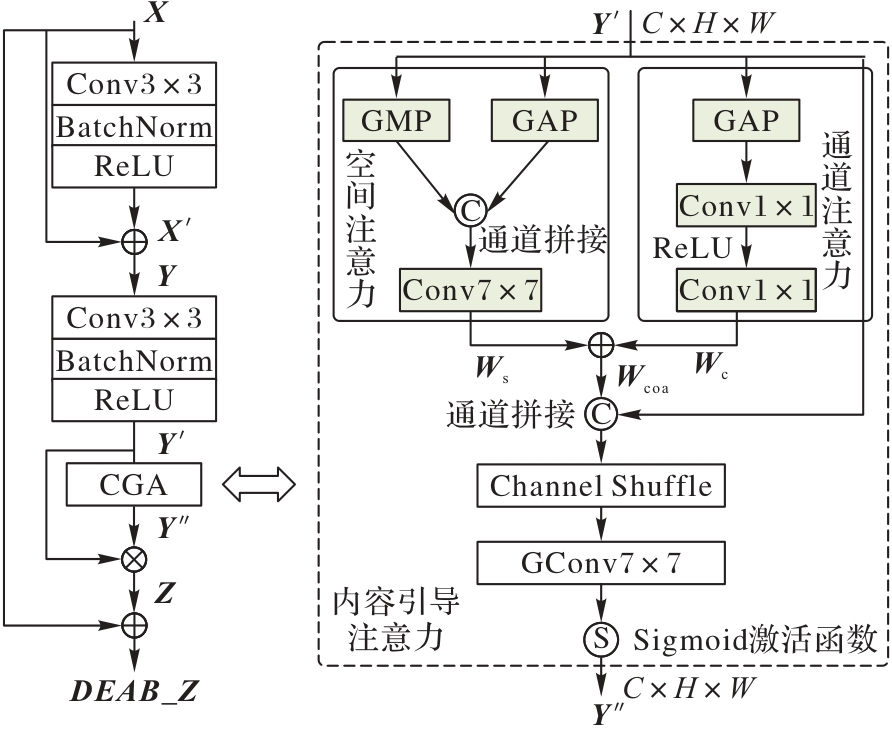
Fig. 5 Structure of DEAB
| 层名 | 网络结构 | 输出尺寸 |
|---|---|---|
| input | — | (24,512,384) |
| inputConv | DoubleConv | (64,512,384) |
| down1 | MaxPool2d,DoubleConv,DEABlock | (128,256,192) |
| down2 | MaxPool2d,DoubleConv,DEABlock | (256,128,96) |
| down3 | MaxPool2d,DoubleConv,DEABlock | (512,64,48) |
| down4 | MaxPool2d,DoubleConv,DEABlock | (512,32,24) |
| up1 | Unsample,DoubleConv | (256,64,48) |
| up2 | Unsample,DoubleConv | (128,128,96) |
| up3 | Unsample,DoubleConv | (64,256,192) |
| up4 | Unsample,DoubleConv | (64,512,384) |
Tab. 1 Network parameters of garment warp refinement module
| 层名 | 网络结构 | 输出尺寸 |
|---|---|---|
| input | — | (24,512,384) |
| inputConv | DoubleConv | (64,512,384) |
| down1 | MaxPool2d,DoubleConv,DEABlock | (128,256,192) |
| down2 | MaxPool2d,DoubleConv,DEABlock | (256,128,96) |
| down3 | MaxPool2d,DoubleConv,DEABlock | (512,64,48) |
| down4 | MaxPool2d,DoubleConv,DEABlock | (512,32,24) |
| up1 | Unsample,DoubleConv | (256,64,48) |
| up2 | Unsample,DoubleConv | (128,128,96) |
| up3 | Unsample,DoubleConv | (64,256,192) |
| up4 | Unsample,DoubleConv | (64,512,384) |
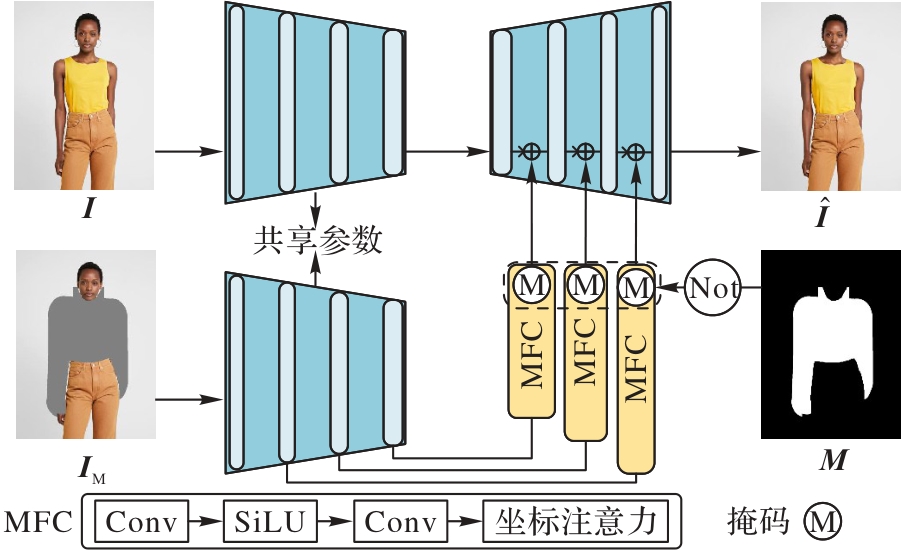
Fig. 6 Structure of MFC module
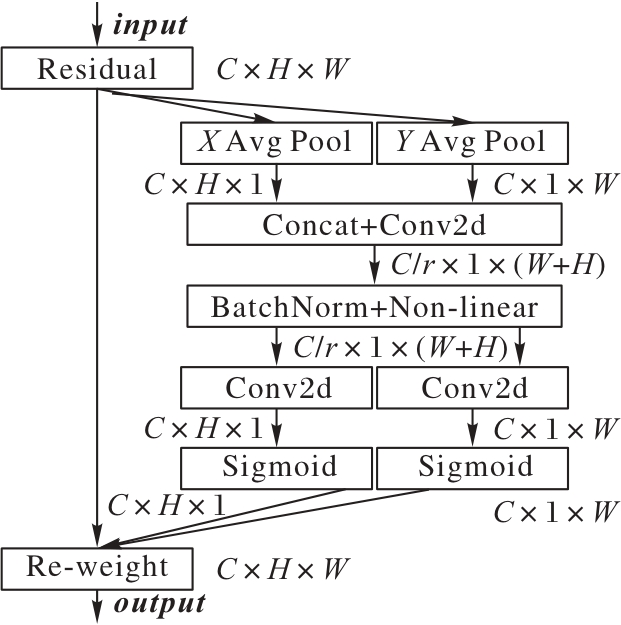
Fig. 7 Structure of coordinate attention

Fig. 8 Results comparison of different virtual try-on methods on VITON-HD dataset

Fig. 9 Results comparison of different virtual try-on methods on Dress Code dataset
| 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|
| HR-VTON | 12.20 | 3.79 | 0.813 9 | 0.202 8 |
| GP-VTON | 9.66 | 1.58 | 0.216 1 | |
| LADI-VTON | 9.41 | 1.60 | 0.814 9 | |
| IDM-VTON | 1.40 | 0.808 1 | 0.210 1 | |
| OOTDiffusion | 9.59 | 1.53 | 0.798 6 | 0.215 2 |
| 本文方法 | 9.05 | 0.823 7 | 0.197 2 |
Tab. 2 Quantitative comparison results on VITON-HD dataset
| 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|
| HR-VTON | 12.20 | 3.79 | 0.813 9 | 0.202 8 |
| GP-VTON | 9.66 | 1.58 | 0.216 1 | |
| LADI-VTON | 9.41 | 1.60 | 0.814 9 | |
| IDM-VTON | 1.40 | 0.808 1 | 0.210 1 | |
| OOTDiffusion | 9.59 | 1.53 | 0.798 6 | 0.215 2 |
| 本文方法 | 9.05 | 0.823 7 | 0.197 2 |
| 方法 | 上半身服装 | 下半身服装 | 裙子 | 所有类别 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FID | KID | FID | KID | FID | KID | FID | KID | SSIM | LPIPS | |
| GP-VTON | 12.46 | 1.52 | 16.92 | 3.29 | 0.753 9 | 0.300 2 | ||||
| LADI-VTON | 13.96 | 3.02 | 14.61 | 3.32 | 6.96 | 2.37 | ||||
| IDM-VTON | 17.76 | 6.06 | 14.04 | 3.38 | 6.95 | 2.74 | 0.862 3 | 0.152 1 | ||
| OOTDiffusion | 12.28 | 1.56 | 16.48 | 4.62 | 14.68 | 3.42 | 6.23 | 2.97 | 0.849 9 | 0.138 2 |
| 本文方法 | 10.81 | 0.77 | 12.40 | 1.82 | 11.70 | 1.40 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
Tab. 3 Quantitative comparison results on Dress Code dataset
| 方法 | 上半身服装 | 下半身服装 | 裙子 | 所有类别 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FID | KID | FID | KID | FID | KID | FID | KID | SSIM | LPIPS | |
| GP-VTON | 12.46 | 1.52 | 16.92 | 3.29 | 0.753 9 | 0.300 2 | ||||
| LADI-VTON | 13.96 | 3.02 | 14.61 | 3.32 | 6.96 | 2.37 | ||||
| IDM-VTON | 17.76 | 6.06 | 14.04 | 3.38 | 6.95 | 2.74 | 0.862 3 | 0.152 1 | ||
| OOTDiffusion | 12.28 | 1.56 | 16.48 | 4.62 | 14.68 | 3.42 | 6.23 | 2.97 | 0.849 9 | 0.138 2 |
| 本文方法 | 10.81 | 0.77 | 12.40 | 1.82 | 11.70 | 1.40 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
| 数据集 | 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|---|
| VITON-HD | LADI-VTON | 9.41 | 1.60 | 0.814 9 | 0.202 6 |
| LADI-VTON(+MFC) | 1.46 | ||||
| LADI-VTON(+GWR) | 9.09 | 0.815 2 | 0.201 7 | ||
| 本文方法 | 9.05 | 1.41 | 0.823 7 | 0.197 2 | |
| Dress Code | LADI-VTON | 6.96 | 2.37 | 0.871 1 | 0.133 9 |
| LADI-VTON(+MFC) | 5.49 | 1.19 | |||
| LADI-VTON(+GWR) | 0.875 1 | 0.130 6 | |||
| 本文方法 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
Tab. 4 Quantitative comparison results of ablation experiments
| 数据集 | 方法 | FID | KID | SSIM | LPIPS |
|---|---|---|---|---|---|
| VITON-HD | LADI-VTON | 9.41 | 1.60 | 0.814 9 | 0.202 6 |
| LADI-VTON(+MFC) | 1.46 | ||||
| LADI-VTON(+GWR) | 9.09 | 0.815 2 | 0.201 7 | ||
| 本文方法 | 9.05 | 1.41 | 0.823 7 | 0.197 2 | |
| Dress Code | LADI-VTON | 6.96 | 2.37 | 0.871 1 | 0.133 9 |
| LADI-VTON(+MFC) | 5.49 | 1.19 | |||
| LADI-VTON(+GWR) | 0.875 1 | 0.130 6 | |||
| 本文方法 | 4.80 | 0.84 | 0.883 4 | 0.124 1 |
| [1] | PONS-MOLL G, PUJADES S, HU S, et al. ClothCap: seamless 4D clothing capture and retargeting [J]. ACM Transactions on Graphics, 2017, 36(4): No.73. |
| [2] | PATEL C, LIAO Z, PONS-MOLL G. TailorNet: predicting clothing in 3D as a function of human pose, shape and garment style[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 7363-7373. |
| [3] | 胡新荣,张君宇,彭涛,等. 级联跨域特征融合的虚拟试衣[J]. 计算机应用, 2022, 42(4): 1269-1274. |
| HU X R, ZHANG J Y, PENG T, et al. Cascaded cross-domain feature fusion for virtual try-on [J]. Journal of Computer Applications, 2022, 42(4): 1269-1274. | |
| [4] | CHOI S, PARK S, LEE M, et al. VITON-HD: high-resolution virtual try-on via misalignment-aware normalization [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 14126-14135. |
| [5] | LEWIS K M, VARADHARAJAN S, KEMELMACHER-SHLIZERMAN I. TryOnGAN: body-aware try-on via layered interpolation [J]. ACM Transactions on Graphics, 2021, 40(4): No.115. |
| [6] | LEE S, GU G, PARK S, et al. High-resolution virtual try-on with misalignment and occlusion-handled conditions [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13677. Cham: Springer, 2022: 204-219. |
| [7] | XIE Z, HUANG Z, DONG X, et al. GP-VTON: towards general purpose virtual try-on via collaborative local-flow global-parsing learning [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 23550-23559. |
| [8] | YANG Z, CHEN J, SHI Y, et al. OccluMix: towards de-occlusion virtual try-on by semantically-guided mixup [J]. IEEE Transactions on Multimedia, 2023, 25: 1477-1488. |
| [9] | CHOI Y, KWAK S, LEE K, et al. Improving diffusion models for authentic virtual try-on in the wild [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15144. Cham: Springer, 2025: 206-235. |
| [10] | KIM J, GU G, PARK M, et al. Stable VITON: learning semantic correspondence with latent diffusion model for virtual try-on [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 8176-8185. |
| [11] | XU Y, GU T, CHEN W, et al. OOTDiffusion: outfitting fusion based latent diffusion for controllable virtual try-on [C]// Proceedings of the 39th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2025: 8996-9004. |
| [12] | MORELLI D, BALDRATI A, CARTELLA G, et al. LaDI-VTON: latent diffusion textual-inversion enhanced virtual try-on[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 8580-8589. |
| [13] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks [J]. Communications of the ACM, 2020, 63(11): 139-144. |
| [14] | ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10674-10685. |
| [15] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 2021 International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [16] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| [17] | WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 607-623. |
| [18] | DUCHON J. Splines minimizing rotation-invariant semi-norms in Sobolev spaces [C]// Constructive Theory of Functions of Several Variables: Proceedings of a Conference Held at Oberwolfach, April 25 — May 1, 1976, LNM 571. Berlin: Springer, 1977: 85-100. |
| [19] | ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976. |
| [20] | MORELLI D, FINCATO M, CORNIA M, et al. Dress Code: high-resolution multi-category virtual try-on [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 2230-2234. |
| [21] | CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1302-1310. |
| [22] | CHEN Z, HE Z, LU Z M. DEA-Net: single image dehazing based on detail-enhanced convolution and content-guided attention [J]. IEEE Transactions on Image Processing, 2024, 33: 1002-1015. |
| [23] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| [24] | ZHANG S, HAN X, ZHANG W, et al. Limb-aware virtual try-on network with progressive clothing warping [J]. IEEE Transactions on Multimedia, 2024, 26: 1731-1746. |
| [25] | ZHANG X, CHEN J, MA L, et al. A virtual try-on network with arm region preservation [J]. Applied Soft Computing, 2025, 175: No.112960. |
| [1] | Min CHEN, Xiaolin QIN, Shaohan LI, Hao YANG, Taohong LI. Review of deep learning applications in severe convective weather prediction [J]. Journal of Computer Applications, 2026, 46(3): 980-992. |
| [2] | Yan HU, Peng LI, Shuyan CHENG. Adversarial purification method based on directly guided diffusion model [J]. Journal of Computer Applications, 2026, 46(3): 821-829. |
| [3] | Haifeng LI, Wenqiang LIU, Nansha LI, Zhongcheng GUI. Ground penetrating radar clutter suppression algorithm for airport runways [J]. Journal of Computer Applications, 2026, 46(2): 659-665. |
| [4] | Yuan JIA, Deyu YUAN, Yuquan PAN, Anran WANG. Watermarking method for diffusion model output [J]. Journal of Computer Applications, 2026, 46(1): 161-168. |
| [5] | Xingjie FENG, Xingpeng BIAN, Xiaorong FENG, Xinglong WANG. Incremental missing value imputation algorithm for time series based on diffusion model [J]. Journal of Computer Applications, 2025, 45(8): 2582-2591. |
| [6] | Qiang LI, Shaoxiong BAI, Yuan XIONG, Wei YUAN. Privacy preserving localization of surveillance images based on large vision models [J]. Journal of Computer Applications, 2025, 45(3): 832-839. |
| [7] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [8] | Chenyang LI, Long ZHANG, Qiusheng ZHENG, Shaohua QIAN. Multivariate controllable text generation based on diffusion sequences [J]. Journal of Computer Applications, 2024, 44(8): 2414-2420. |
| [9] | Jinsong XU, Ming ZHU, Zhiqiang LI, Shijie GUO. Location control method for generated objects by diffusion model with exciting and pooling attention [J]. Journal of Computer Applications, 2024, 44(4): 1093-1098. |
| [10] | Yusheng LIU, Xuezhong XIAO. High-fidelity image editing based on fine-tuning of diffusion model [J]. Journal of Computer Applications, 2024, 44(11): 3574-3580. |
| [11] | Qiumei ZHENG, Weiwei NIU, Fenghua WANG, Dan ZHAO. Dual-branch real-time semantic segmentation network based on detail enhancement [J]. Journal of Computer Applications, 2024, 44(10): 3058-3066. |
| [12] | Shengwei DUAN, Xinyu CHENG, Haozhou WANG, Fei WANG. Dam surface disease detection algorithm based on improved YOLOv5 [J]. Journal of Computer Applications, 2023, 43(8): 2619-2629. |
| [13] | Xinrong HU, Junyu ZHANG, Tao PENG, Junping LIU, Ruhan HE, Kai HE. Cascaded cross-domain feature fusion for virtual try-on [J]. Journal of Computer Applications, 2022, 42(4): 1269-1274. |
| [14] | YANG Shuxin, LIANG Wen, ZHU Kaili. Reverse influence maximization algorithm in social networks [J]. Journal of Computer Applications, 2020, 40(7): 1944-1949. |
| [15] | ZHANG Yan-fang XIONG Hai-ling. Product diffusion study of fast moving consumer goods based on hybrid model of Bass and cellular automata models [J]. Journal of Computer Applications, 2011, 31(12): 3305-3308. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||