


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (11): 3574-3580.DOI: 10.11772/j.issn.1001-9081.2023111570
• Multimedia computing and computer simulation • Previous Articles Next Articles
Received:2023-11-15
Revised:2024-03-01
Accepted:2024-03-05
Online:2024-03-12
Published:2024-11-10
Contact:
Xuezhong XIAO
About author:LIU Yusheng, born in 2001, M. S. candidate. His research interests include computer vision, image composition.
刘雨生, 肖学中( )
)
通讯作者:
肖学中
作者简介:刘雨生(2001—),男,江苏徐州人,硕士研究生,主要研究方向:计算机视觉、图像合成
CLC Number:
Yusheng LIU, Xuezhong XIAO. High-fidelity image editing based on fine-tuning of diffusion model[J]. Journal of Computer Applications, 2024, 44(11): 3574-3580.
刘雨生, 肖学中. 基于扩散模型微调的高保真图像编辑[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3574-3580.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023111570

Fig. 1 Image editing results of proposed method
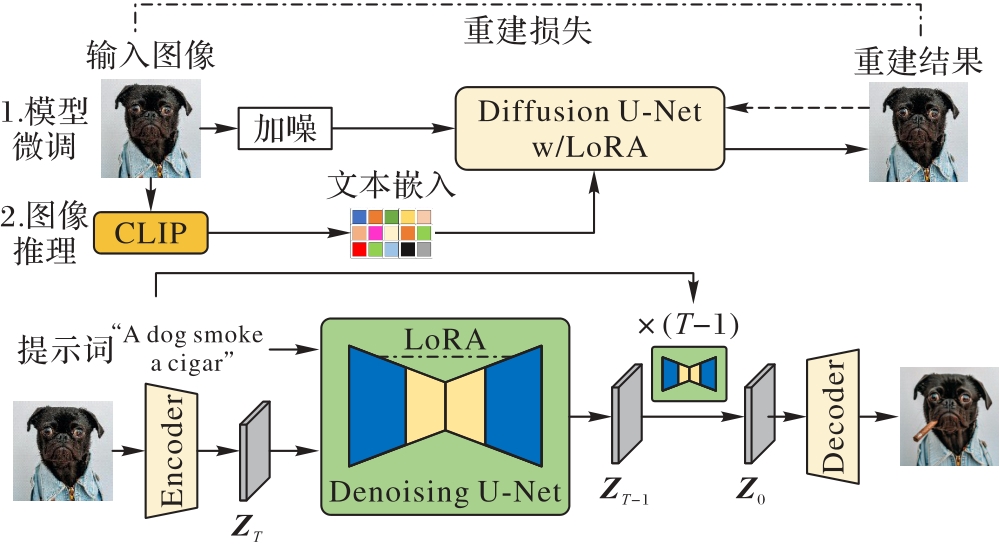
Fig. 2 Framework of proposed algorithm

Fig. 3 Attention Maps weighting
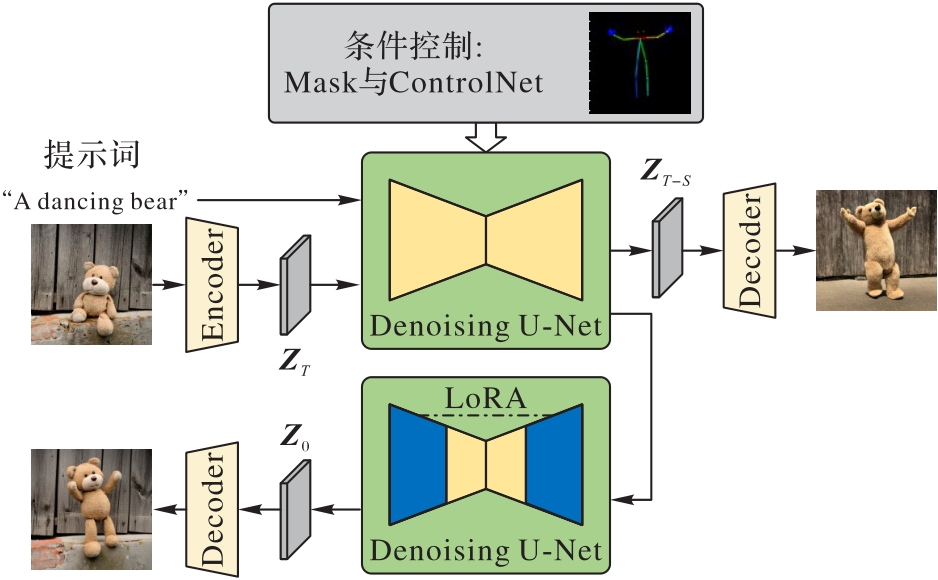
Fig. 4 Structure of dual-layer U-Net

Fig. 5 Editing results on TedBench dataset

Fig. 6 Comparison of editing results of five methods
| 方法 | 非刚性编辑(60个) | 物体增加(21个) | 主体替换(11个) | 背景替换(8个) | 总任务(100个) |
|---|---|---|---|---|---|
| 本文方法 | 58 | 21 | 11 | 8 | 98 |
| Imagic | 56 | 20 | 11 | 8 | 95 |
| Img2Img | 46 | 13 | 3 | 5 | 67 |
| DiffEdit | 11 | 4 | 10 | 1 | 26 |
| InstructPix2Pix | 12 | 12 | 10 | 6 | 40 |
Tab. 1 Comparison of significant figures of editing results
| 方法 | 非刚性编辑(60个) | 物体增加(21个) | 主体替换(11个) | 背景替换(8个) | 总任务(100个) |
|---|---|---|---|---|---|
| 本文方法 | 58 | 21 | 11 | 8 | 98 |
| Imagic | 56 | 20 | 11 | 8 | 95 |
| Img2Img | 46 | 13 | 3 | 5 | 67 |
| DiffEdit | 11 | 4 | 10 | 1 | 26 |
| InstructPix2Pix | 12 | 12 | 10 | 6 | 40 |
| 方法 | CLIP Score | LPIPS |
|---|---|---|
| Imagic | 25.186 2 | 0.550 7 |
| Img2Img | 23.885 5 | 0.634 5 |
| 本文方法 | 25.318 1 | 0.383 4 |
Tab. 2 Comparison of fidelity
| 方法 | CLIP Score | LPIPS |
|---|---|---|
| Imagic | 25.186 2 | 0.550 7 |
| Img2Img | 23.885 5 | 0.634 5 |
| 本文方法 | 25.318 1 | 0.383 4 |
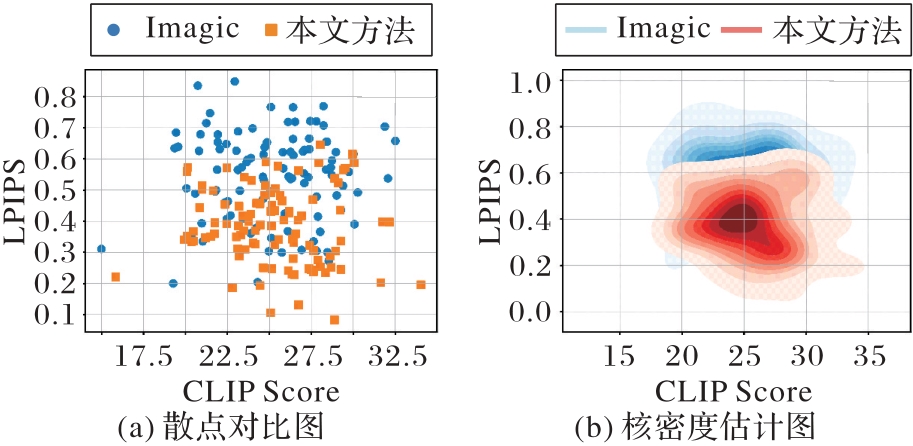
Fig. 7 Data comparison of proposed method with Imagic

Fig. 8 Dual-layer U-Net editing results with postural guidance
| 1 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 2 | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 586-595. |
| 3 | BROOKS T, HOLYNSKI A, EFROS A A. InstructPix2Pix: learning to follow image editing instructions[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 18392-18402. |
| 4 | HERTZ A, MOKADY R, TENENBAUM J, et al. Prompt-to-Prompt image editing with cross-attention control[EB/OL]. [2023-09-12].. |
| 5 | COUAIRON G, VERBEEK J, SCHWENK H, et al. DiffEdit: diffusion-based semantic image editing with mask guidance[EB/OL]. [2023-08-22].. |
| 6 | KAWAR B, ZADA S, LANG O, et al. Imagic: text-based real image editing with diffusion models[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 6007-6017. |
| 7 | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2672-2680. |
| 8 | NICHOL A, DHARIWAL P. Improved denoising diffusion probabilistic models[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8162-8171. |
| 9 | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 6840-6851. |
| 10 | LIU H, WAN Z, HUANG W, et al. PD-GAN: probabilistic diverse GAN for image inpainting[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9367-9376. |
| 11 | JING Y, YANG Y, FENG Z, et al. Neural style transfer: a review[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(11): 3365-3385. |
| 12 | ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2223-2232. |
| 13 | PAN X, TEWARI A, LEIMKÜHLER T, et al. Drag your GAN: interactive point-based manipulation on the generative image manifold[C]// Proceedings of the 2023 ACM SIGGRAPH Conference. New York: ACM, 2023: No.78. |
| 14 | ABDAL R, ZHU P, MITRA N J, et al. StyleFlow: attribute-conditioned exploration of StyleGAN-generated images using conditional continuous normalizing flows[J]. ACM Transactions on Graphics, 2021, 40(3): No.21. |
| 15 | PATASHNIK O, WU Z, SHECHTMAN E, et al. StyleCLIP: text-driven manipulation of StyleGAN imagery[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2065-2074. |
| 16 | GAL R, PATASHNIK O, MARON H, et al. StyleGAN-nada: clip-guided domain adaptation of image generators[J]. ACM Transactions on Graphics, 2022, 41(4): 1-13. |
| 17 | XIA W, YANG Y, XUE J H, et al. TediGAN: text-guided diverse face image generation and manipulation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2256-2265. |
| 18 | ABDAL R, ZHU P, FEMIANI J, et al. CLIP2StyleGAN: unsupervised extraction of StyleGAN edit directions[C]// Proceedings of the 2022 ACM SIGGRAPH Conference. New York: ACM, 2022: No.48. |
| 19 | CROWSON K, BIDERMAN S, KORNIS D, et al. VQGAN-CLIP: open domain image generation and editing with natural language guidance[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13697. Cham: Springer, 2022: 88-105. |
| 20 | ESSER P, ROMBACH R, OMMER B. Taming Transformers for high-resolution image synthesis[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12868-12878. |
| 21 | MOKADY R, TOV O, YAROM M, et al. Self-distilled styleGAN: towards generation from internet photos[C]// Proceedings of the 2022 ACM SIGGRAPH Conference. New York: ACM, 2022: No.50. |
| 22 | GONG S, LI M, FENG J, et al. DiffuSeq: sequence to sequence text generation with diffusion models[EB/OL]. [2023-10-12].. |
| 23 | RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8821-8831. |
| 24 | ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10674-10685. |
| 25 | ZHANG L, RAO A, AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3813-3824. |
| 26 | LUGMAYR A, DANELLJAN M, ROMERO A, et al. RePaint: inpainting using denoising diffusion probabilistic models[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 11451-11461. |
| 27 | SAHARIA C, CHAN W, CHANG H, et al. Palette: image-to-image diffusion models[C]// Proceedings of the 2022 ACM SIGGRAPH Conference. New York: ACM, 2022: No.15. |
| 28 | RUIZ N, LI Y, JAMPANI V, et al. DreamBooth: fine tuning text-to-image diffusion models for subject-driven generation[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 22500-22510. |
| 29 | SUN Z, ZHOU Y, HE H, et al. SGDiff: a style guided diffusion model for fashion synthesis[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 8433-8442. |
| 30 | MENG C, HE Y, SONG Y, et al. SDEdit: guided image synthesis and editing with stochastic differential equations[EB/OL]. [2023-08-05].. |
| 31 | KIM G, KWON T, YE J C. DiffusionCLIP: text-guided diffusion models for robust image manipulation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 2416-2425. |
| 32 | HOU C, WEI G, CHEN Z. High-fidelity diffusion-based image editing[C]// Proceedings of the 38th AAAI Conference of Artificial Intelligence. Palo Alto, CA: AAAI Press, 2024: 2184-2192. |
| 33 | VALEVSKI D, KALMAN M, MOLAD E, et al. UniTune: text-driven image editing by fine tuning a diffusion model on a single image[J]. ACM Transactions on Graphics, 2023, 42(4): No.128. |
| 34 | AVRAHAMI O, LISCHINSKI D, FRIED O. Blended diffusion for text-driven editing of natural images[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18187-18197. |
| 35 | HU E, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. [2023-06-22].. |
| 36 | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 37 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. |
| 38 | SONG J, MENG C, ERMON S. Denoising diffusion implicit models[EB/OL]. [2023-11-25].. |
| 39 | CHAKRAVARTHI A, GURURAJA H S. Classifier-free guidance for Generative Adversarial Networks (GANs)[C]// Proceedings of the 2022 International Conference on Intelligent Computing and Communication, AISC 1447. Singapore: Springer, 2023: 217-232. |
| 40 | CAO M, WANG X, QI Z, et al. MasaCtrl: tuning-free mutual self-attention control for consistent image synthesis and editing[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 22503-22513. |
| [1] | Chenyang LI, Long ZHANG, Qiusheng ZHENG, Shaohua QIAN. Multivariate controllable text generation based on diffusion sequences [J]. Journal of Computer Applications, 2024, 44(8): 2414-2420. |
| [2] | Minghao SUN, Han YU, Yuqing CHEN, Kai LU. First-arrival picking and inversion of seismic waveforms based on U-shaped multilayer perceptron network [J]. Journal of Computer Applications, 2024, 44(7): 2301-2309. |
| [3] | Lijun XU, Hui LI, Zuyang LIU, Kansong CHEN, Weixuan MA. 3D-GA-Unet: MRI image segmentation algorithm for glioma based on 3D-Ghost CNN [J]. Journal of Computer Applications, 2024, 44(4): 1294-1302. |
| [4] | Jinsong XU, Ming ZHU, Zhiqiang LI, Shijie GUO. Location control method for generated objects by diffusion model with exciting and pooling attention [J]. Journal of Computer Applications, 2024, 44(4): 1093-1098. |
| [5] | Di ZHOU, Zili ZHANG, Jia CHEN, Xinrong HU, Ruhan HE, Jun ZHANG. Stomach cancer image segmentation method based on EfficientNetV2 and object-contextual representation [J]. Journal of Computer Applications, 2023, 43(9): 2955-2962. |
| [6] | Liyao FU, Mengxiao YIN, Feng YANG. Transformer based U-shaped medical image segmentation network: a survey [J]. Journal of Computer Applications, 2023, 43(5): 1584-1595. |
| [7] | Jingchao CHEN, Shugong XU, Youdong DING. Text image editing method based on font and character attribute guidance [J]. Journal of Computer Applications, 2023, 43(5): 1416-1421. |
| [8] | You YANG, Ruhui ZHANG, Pengcheng XU, Kang KANG, Hao ZHAI. Improved U-Net for seal segmentation of Republican archives [J]. Journal of Computer Applications, 2023, 43(3): 943-948. |
| [9] | Li’an ZHU, Hong ZHANG. Nonhomogeneous image dehazing based on dual-branch conditional generative adversarial network [J]. Journal of Computer Applications, 2023, 43(2): 567-574. |
| [10] | Zhiang ZHANG, Guangzhong LIAO. Multi-scale feature enhanced retinal vessel segmentation algorithm based on U-Net [J]. Journal of Computer Applications, 2023, 43(10): 3275-3281. |
| [11] | LIN Jianzhuang, YANG Wenzhong, TAN Sixiang, ZHOU Lexin, CHEN Danni. Fusing filter enhancement and reverse attention network for polyp segmentation [J]. Journal of Computer Applications, 2023, 43(1): 265-272. |
| [12] | Huazhong JIN, Xiuyang ZHANG, Zhiwei YE, Wenqi ZHANG, Xiaoyu XIA. Image denoising model based on approximate U-shaped network structure [J]. Journal of Computer Applications, 2022, 42(8): 2571-2577. |
| [13] | Guangzhu XU, Wenjie LIN, Sha CHEN, Wan KUANG, Bangjun LEI, Jun ZHOU. Fundus vessel segmentation method based on U-Net and pulse coupled neural network with adaptive threshold [J]. Journal of Computer Applications, 2022, 42(3): 825-832. |
| [14] | Qiwen WU, Jianhua WANG, Xiang ZHENG, Ju FENG, Hongyan JIANG, Yubo WANG. Waterweed image segmentation method based on improved U-Net [J]. Journal of Computer Applications, 2022, 42(10): 3177-3183. |
| [15] | HUANG Li, LU Long. Segmentation of ischemic stroke lesion based on long-distance dependency encoding and deep residual U-Net [J]. Journal of Computer Applications, 2021, 41(6): 1820-1827. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||