


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (8): 2448-2456.DOI: 10.11772/j.issn.1001-9081.2024081082
• The 21th CCF Conference on Web Information Systems and Applications (WISA 2024) • Previous Articles
Yimeng XI1, Zhen DENG1, Qian LIU1, Libo LIU1,2( )
)
Received:2024-08-02
Revised:2024-08-19
Accepted:2024-08-21
Online:2024-09-12
Published:2025-08-10
Contact:
Libo LIU
About author:XI Yimeng, born in 2000, M. S. candidate. Her research interests include cross-modal retrieval of video and text.Supported by:
习怡萌1, 邓箴1, 刘倩1, 刘立波1,2()
通讯作者:
刘立波
作者简介:习怡萌(2000—),女,陕西渭南人,硕士研究生,CCF会员,主要研究方向:视频文本跨模态检索基金资助:CLC Number:
Yimeng XI, Zhen DENG, Qian LIU, Libo LIU. Cross-modal information fusion for video-text retrieval[J]. Journal of Computer Applications, 2025, 45(8): 2448-2456.
习怡萌, 邓箴, 刘倩, 刘立波. 跨模态信息融合的视频-文本检索[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2448-2456.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081082
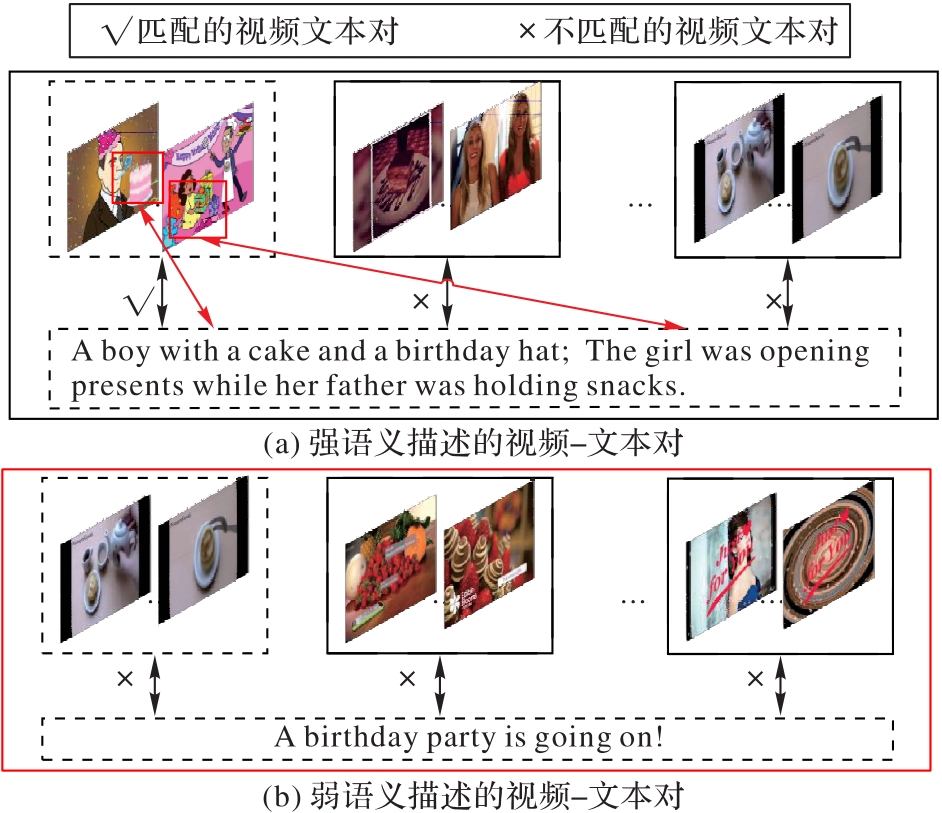
Fig. 1 Examples of strong and weak semantic descriptions

Fig. 2 Architecture of proposed model
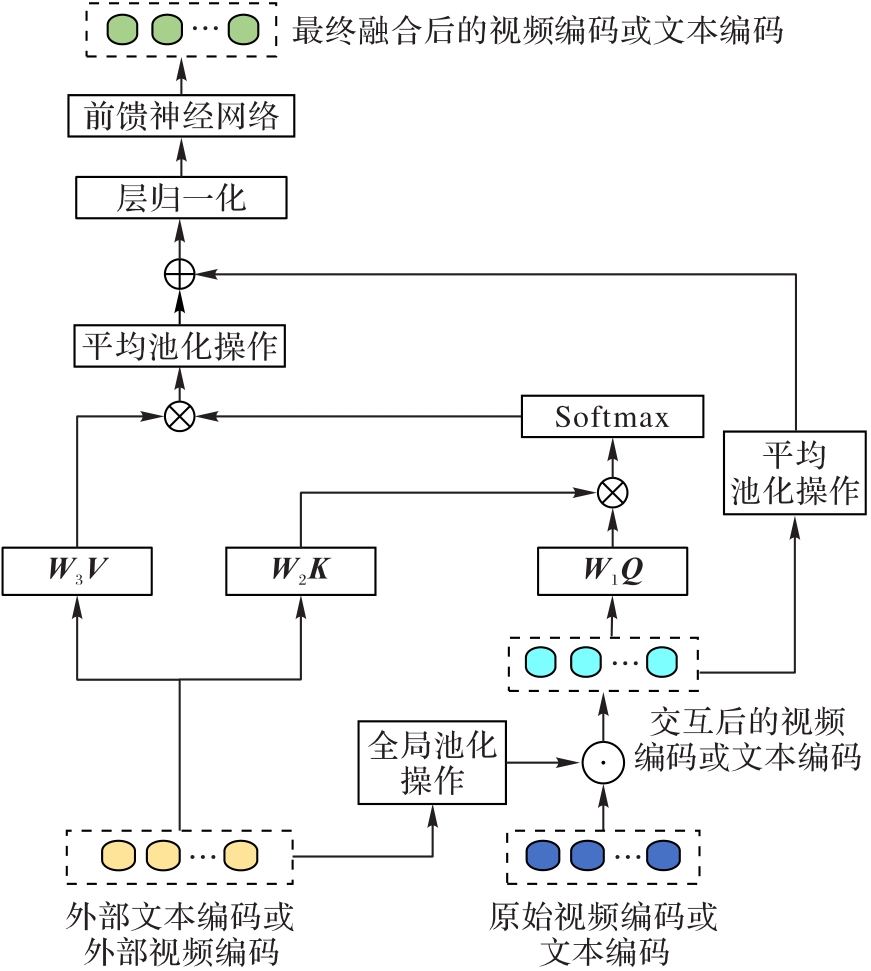
Fig. 3 Cross-modal information fusion module
| 数据集 | 训练数据对 | 验证数据对 | 测试数据对 |
|---|---|---|---|
| MSR-VTT[ | 180 000 | 0 | 1 000 |
| DiDeMo[ | 8 395 | 1 065 | 1 004 |
| LSMDC[ | 109 673 | 7 408 | 1 000 |
Tab. 1 Dataset partitioning
| 数据集 | 训练数据对 | 验证数据对 | 测试数据对 |
|---|---|---|---|
| MSR-VTT[ | 180 000 | 0 | 1 000 |
| DiDeMo[ | 8 395 | 1 065 | 1 004 |
| LSMDC[ | 109 673 | 7 408 | 1 000 |
| MSR-VTT上的R@1值/% | DiDeMo上的R@1值/% | LSMDC上的R@1值/% | |||||
|---|---|---|---|---|---|---|---|
| 文本检索视频 | 视频检索文本 | 文本检索视频 | 视频检索文本 | 文本检索视频 | 视频检索文本 | ||
| 0.25 | 0.25 | 49.4 | 49.2 | 50.3 | 49.6 | 33.6 | 32.1 |
| 0.50 | 52.5 | 51.4 | 49.4 | 54.3 | 30.4 | 29.3 | |
| 0.75 | 48.9 | 48.2 | 47.6 | 47.3 | 29.7 | 28.5 | |
| 0.50 | 0.25 | 54.6 | 52.3 | 54.6 | 52.8 | 29.5 | 32.1 |
| 0.50 | 56.7 | 54.9 | 58.4 | 56.0 | 28.8 | 31.0 | |
| 0.75 | 51.5 | 48.8 | 52.7 | 53.5 | 27.5 | 30.6 | |
| 0.75 | 0.25 | 52.1 | 50.9 | 53.2 | 49.7 | 28.6 | 30.5 |
| 0.50 | 53.2 | 53.6 | 55.9 | 53.8 | 27.9 | 29.9 | |
| 0.75 | 51.2 | 48.4 | 52.0 | 52.6 | 27.3 | 29.4 | |
Tab. 2 R@1 values on MSR-VTT, DiDeMo, and LSMDC datasets with different α and β values
| MSR-VTT上的R@1值/% | DiDeMo上的R@1值/% | LSMDC上的R@1值/% | |||||
|---|---|---|---|---|---|---|---|
| 文本检索视频 | 视频检索文本 | 文本检索视频 | 视频检索文本 | 文本检索视频 | 视频检索文本 | ||
| 0.25 | 0.25 | 49.4 | 49.2 | 50.3 | 49.6 | 33.6 | 32.1 |
| 0.50 | 52.5 | 51.4 | 49.4 | 54.3 | 30.4 | 29.3 | |
| 0.75 | 48.9 | 48.2 | 47.6 | 47.3 | 29.7 | 28.5 | |
| 0.50 | 0.25 | 54.6 | 52.3 | 54.6 | 52.8 | 29.5 | 32.1 |
| 0.50 | 56.7 | 54.9 | 58.4 | 56.0 | 28.8 | 31.0 | |
| 0.75 | 51.5 | 48.8 | 52.7 | 53.5 | 27.5 | 30.6 | |
| 0.75 | 0.25 | 52.1 | 50.9 | 53.2 | 49.7 | 28.6 | 30.5 |
| 0.50 | 53.2 | 53.6 | 55.9 | 53.8 | 27.9 | 29.9 | |
| 0.75 | 51.2 | 48.4 | 52.0 | 52.6 | 27.3 | 29.4 | |
| 方法 | 参数量/106 | 文本检索视频 | 视频检索文本 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | R@1/% | R@5/% | R@10/% | MedR | ||
| ClipBERT[ | — | 22.0 | 46.8 | 59.9 | 6.0 | — | — | — | — |
| MMT[ | 133.3 | 26.6 | 57.1 | 69.6 | 4.0 | 27.0 | 57.5 | 69.7 | 3.7 |
| Frozen[ | 142.4 | 32.5 | 61.5 | 71.2 | 3.0 | — | — | — | — |
| TMVM[ | — | 36.2 | 64.2 | 75.7 | 3.0 | 34.8 | 63.8 | 73.7 | 3.0 |
| CenterCLIP[ | — | 48.4 | 73.8 | 82.0 | 2.0 | 47.7 | 75.0 | 83.3 | 2.0 |
| TS2-Net[ | — | 47.0 | 74.5 | 83.8 | 2.0 | 46.6 | 75.9 | 84.9 | 2.0 |
| DRL[ | — | 50.2 | 76.5 | 84.7 | 1.0 | 50.2 | 76.5 | 84.7 | 1.0 |
| MSIA[ | — | 49.3 | 75.1 | 85.5 | 2.0 | — | — | — | — |
| Cap4Video[ | — | 51.4 | 75.7 | 83.9 | 1.0 | 51.4 | 75.7 | 83.9 | 1.0 |
| MuLTI[ | 247.0 | 54.7 | 77.7 | 86.0 | 1.0 | — | — | — | — |
| 本文方法 | 160.6 | 56.7 | 79.6 | 87.4 | 1.0 | 54.9 | 79.9 | 86.6 | 1.0 |
Tab. 3 Performance comparison of proposed method and benchmark methods on MSR-VTT dataset
| 方法 | 参数量/106 | 文本检索视频 | 视频检索文本 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | R@1/% | R@5/% | R@10/% | MedR | ||
| ClipBERT[ | — | 22.0 | 46.8 | 59.9 | 6.0 | — | — | — | — |
| MMT[ | 133.3 | 26.6 | 57.1 | 69.6 | 4.0 | 27.0 | 57.5 | 69.7 | 3.7 |
| Frozen[ | 142.4 | 32.5 | 61.5 | 71.2 | 3.0 | — | — | — | — |
| TMVM[ | — | 36.2 | 64.2 | 75.7 | 3.0 | 34.8 | 63.8 | 73.7 | 3.0 |
| CenterCLIP[ | — | 48.4 | 73.8 | 82.0 | 2.0 | 47.7 | 75.0 | 83.3 | 2.0 |
| TS2-Net[ | — | 47.0 | 74.5 | 83.8 | 2.0 | 46.6 | 75.9 | 84.9 | 2.0 |
| DRL[ | — | 50.2 | 76.5 | 84.7 | 1.0 | 50.2 | 76.5 | 84.7 | 1.0 |
| MSIA[ | — | 49.3 | 75.1 | 85.5 | 2.0 | — | — | — | — |
| Cap4Video[ | — | 51.4 | 75.7 | 83.9 | 1.0 | 51.4 | 75.7 | 83.9 | 1.0 |
| MuLTI[ | 247.0 | 54.7 | 77.7 | 86.0 | 1.0 | — | — | — | — |
| 本文方法 | 160.6 | 56.7 | 79.6 | 87.4 | 1.0 | 54.9 | 79.9 | 86.6 | 1.0 |
| 方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | ||
| CE[ | 119.5 | 16.1 | 41.1 | — | 8.3 |
| CLIP4Clip[ | 151.2 | 43.4 | 70.2 | 80.6 | 2.0 |
| Frozen[ | 142.4 | 31.0 | 59.8 | 72.4 | 3.0 |
| MSIA[ | — | 43.6 | 70.2 | 79.6 | 2.0 |
| Cap4Video[ | — | 52.0 | 79.4 | 87.5 | 1.0 |
| MuLTI[ | 247.0 | 56.5 | 80.2 | 87.0 | 1.0 |
| 本文方法 | 160.6 | 58.4 | 82.3 | 88.4 | 1.0 |
Tab. 4 Performance comparison of proposed method and benchmark methods on DiDeMo dataset
| 方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | ||
| CE[ | 119.5 | 16.1 | 41.1 | — | 8.3 |
| CLIP4Clip[ | 151.2 | 43.4 | 70.2 | 80.6 | 2.0 |
| Frozen[ | 142.4 | 31.0 | 59.8 | 72.4 | 3.0 |
| MSIA[ | — | 43.6 | 70.2 | 79.6 | 2.0 |
| Cap4Video[ | — | 52.0 | 79.4 | 87.5 | 1.0 |
| MuLTI[ | 247.0 | 56.5 | 80.2 | 87.0 | 1.0 |
| 本文方法 | 160.6 | 58.4 | 82.3 | 88.4 | 1.0 |
| 方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | ||
| CE[ | 119.5 | 11.2 | 26.9 | 34.8 | 25.3 |
| MMT[ | 133.3 | 12.9 | 29.9 | 40.1 | 19.3 |
| Frozen[ | 142.4 | 15.0 | 30.8 | 39.8 | 20.0 |
| MSIA[ | — | 19.7 | 38.1 | 47.5 | 12.0 |
| CLIP4Clip[ | 151.2 | 21.6 | 41.8 | 49.8 | 11.0 |
| CLIP-ViP[ | — | 30.7 | 51.4 | 60.6 | 5.0 |
| 本文方法 | 160.6 | 33.6 | 54.1 | 62.8 | 5.0 |
Tab. 5 Performance comparison of proposed method and benchmark methods on LSMDC dataset
| 方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | ||
| CE[ | 119.5 | 11.2 | 26.9 | 34.8 | 25.3 |
| MMT[ | 133.3 | 12.9 | 29.9 | 40.1 | 19.3 |
| Frozen[ | 142.4 | 15.0 | 30.8 | 39.8 | 20.0 |
| MSIA[ | — | 19.7 | 38.1 | 47.5 | 12.0 |
| CLIP4Clip[ | 151.2 | 21.6 | 41.8 | 49.8 | 11.0 |
| CLIP-ViP[ | — | 30.7 | 51.4 | 60.6 | 5.0 |
| 本文方法 | 160.6 | 33.6 | 54.1 | 62.8 | 5.0 |
| 方法 | 检索策略 | 融合策略 | 融合方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | |||||
| 本文方法 | 单模态 | 跨模态 | 自适应交叉注意力 | 160.6 | 56.7 | 79.6 | 87.4 | 1.0 |
| 基线模型 | — | — | — | 151.2 | 44.5 | 71.4 | 81.6 | 2.0 |
| 调整检索策略 | 跨模态 | 跨模态 | 自适应交叉注意力 | 160.6 | 48.6 | 67.4 | 78.2 | 2.0 |
| 调整融合策略 | 单模态 | 单模态 | 自适应交叉注意力 | 160.6 | 49.1 | 67.6 | 79.4 | 2.0 |
| 调整融合方法 | 单模态 | 跨模态 | Sum信息融合 | 155.8 | 50.9 | 73.2 | 83.3 | 1.0 |
| 单模态 | 跨模态 | MLP信息融合 | 163.2 | 53.1 | 74.5 | 85.1 | 1.0 | |
| 单模态 | 跨模态 | Cross Transformer信息融合 | 158.1 | 54.4 | 76.7 | 85.9 | 1.0 | |
Tab. 6 Ablation experimental results of proposed method on MSR-VTT dataset
| 方法 | 检索策略 | 融合策略 | 融合方法 | 参数量/106 | 文本检索视频 | |||
|---|---|---|---|---|---|---|---|---|
| R@1/% | R@5/% | R@10/% | MedR | |||||
| 本文方法 | 单模态 | 跨模态 | 自适应交叉注意力 | 160.6 | 56.7 | 79.6 | 87.4 | 1.0 |
| 基线模型 | — | — | — | 151.2 | 44.5 | 71.4 | 81.6 | 2.0 |
| 调整检索策略 | 跨模态 | 跨模态 | 自适应交叉注意力 | 160.6 | 48.6 | 67.4 | 78.2 | 2.0 |
| 调整融合策略 | 单模态 | 单模态 | 自适应交叉注意力 | 160.6 | 49.1 | 67.6 | 79.4 | 2.0 |
| 调整融合方法 | 单模态 | 跨模态 | Sum信息融合 | 155.8 | 50.9 | 73.2 | 83.3 | 1.0 |
| 单模态 | 跨模态 | MLP信息融合 | 163.2 | 53.1 | 74.5 | 85.1 | 1.0 | |
| 单模态 | 跨模态 | Cross Transformer信息融合 | 158.1 | 54.4 | 76.7 | 85.9 | 1.0 | |

Fig. 4 Examples of text-to-video retrieval
| [1] | MITHUN N C, LI J, METZE F, et al. Learning joint embedding with multimodal cues for cross-modal video-text retrieval[C]// Proceedings of the 2018 ACM International Conference on Multimedia Retrieval. New York: ACM, 2018: 19-27. |
| [2] | 彭宇新,綦金玮,黄鑫. 多媒体内容理解的研究现状与展望[J]. 计算机研究与发展, 2019, 56(1):183-208. |
| PENG Y X, QI J W, HUANG X. Current research status and prospects on multimedia content understanding[J]. Journal of Computer Research and Development, 2019, 56(1):183-208. | |
| [3] | JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4904-4916. |
| [4] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [5] | LUO H, JI L, ZHONG M, et al. CLIP4Clip: an empirical study of CLIP for end to end video clip retrieval[J]. Neurocomputing, 2021, 508: 293-304. |
| [6] | GORTI S K, VOUITSIS N, MA J, et al. X-Pool: cross-modal language-video attention for text-video retrieval[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4996-5005. |
| [7] | CHEN L, DENG Z, LIU L, et al. Multilevel semantic interaction alignment for video-text cross-modal retrieval[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(7): 6559-6575. |
| [8] | KO K C, CHEON Y M, KIM G Y, et al. Video shot boundary detection algorithm[C]// Proceedings of the 2006 Indian Conference on Computer Vision, Graphics and Image Processing, LNCS 4338. Berlin : Springer, 2006: 388-396. |
| [9] | CHEN C Y, WANG J C, WANG J F. Efficient news video querying and browsing based on distributed news video servers[J]. IEEE Transactions on Multimedia, 2006, 8(2): 257-269. |
| [10] | RASIWASIA N, COSTA PEREIRA J, COVIELLO E, et al. A new approach to cross-modal multimedia retrieval[C]// Proceedings of the 18th ACM International Conference on Multimedia. New York: ACM, 2010: 251-260. |
| [11] | SUN X, LONG X, HE D, et al. VSRNet: end-to-end video segment retrieval with text query[J]. Pattern Recognition, 2021, 119: No.108027. |
| [12] | MIN S, KONG W, TU R C, et al. HunYuan_tvr for text-video retrieval[EB/OL]. [2024-08-20].. |
| [13] | CHOI S, KIM J T, CHOO J. Cars can’t fly up in the sky: improving urban-scene segmentation via height-driven attention networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020:9370-9380. |
| [14] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [15] | ZHAI A, WU H Y. Classification is a strong baseline for deep metric learning[C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: 1-12. |
| [16] | 李天煜,刘立波. 基于模态内相似性与语义保留的深度跨模态哈希 [J]. 数据分析与知识发现, 2023, 7(5): 105-115. |
| LI T Y, LIU L B. Deep cross-modal hashing based on intra-modal similarity and semantic preservation[J]. Data Analysis and Knowledge Discovery, 2023, 7(5): 105-115. | |
| [17] | XU J, MEI T, YAO T, et al. MSR-VTT: a large video description dataset for bridging video and language[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 5288-5296. |
| [18] | WU Z, YAO T, FU Y, et al. Deep learning for video classification and captioning[M]// CHANG S F. Frontiers of multimedia research. New York: ACM, 2017: 3-29. |
| [19] | HENDRICKS L A, WANG O, SHECHTMAN E, et al. Localizing moments in video with natural language[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 5804-5813. |
| [20] | LEI J, LI L, ZHOU L, et al. Less is more: ClipBERT for video-and-language learning via sparse sampling[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7327-7337. |
| [21] | GABEUR V, SUN C, ALAHARI K, et al. Multi-modal transformer for video retrieval[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12349. Cham: Springer, 2020: 214-229. |
| [22] | BAIN M, NAGRANI A, VAROL G, et al. Frozen in time: a joint video and image encoder for end-to-end retrieval[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1708-1718. |
| [23] | LIN C, WU A, LIANG J, et al. Text-adaptive multiple visual prototype matching for video-text retrieval[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 38655-38666. |
| [24] | ZHAO S, ZHU L, WANG X, et al. CenterCLIP: token clustering for efficient text-video retrieval[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 970-981. |
| [25] | LIU Y, XIONG P, XU L, et al. TS2-Net: token shift and selection Transformer for text-video retrieval[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13674. Cham: Springer, 2022: 319-335. |
| [26] | WANG Q, ZHANG Y, ZHENG Y, et al. Disentangled representation learning for text-video retrieval[EB/OL]. [2024-06-20].. |
| [27] | WU W, LUO H, FANG B, et al. Cap4Video: what can auxiliary captions do for text-video retrieval?[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 10704-10713. |
| [28] | XU J, LIU B, CHEN Y, et al. MuLTI: efficient video-and-language understanding with text-guided multi way-sampler and multiple choice modeling[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6297-6305. |
| [29] | LIU Y, ALBANIE S, NAGRANI A, et al. Use what you have: video retrieval using representations from collaborative experts[C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: 1-19. |
| [30] | XUE H, SUN Y, LIU B, et al. CLIP-ViP: adapting pre-trained image-text model to video-language representation alignment[EB/OL]. [2024-08-20].. |
| [1] | Jianhua WANG, Chuanyu WU, Liping XU. Enhanced evolutionary algorithm for multi-factor flexible job shop green scheduling [J]. Journal of Computer Applications, 2025, 45(6): 1954-1962. |
| [2] | Weigang LI, Xinyi LI, Yongqiang WANG, Yuntao ZHAO. Point cloud classification and segmentation method based on adaptive dynamic graph convolution and parameter-free attention [J]. Journal of Computer Applications, 2025, 45(6): 1980-1986. |
| [3] | Shuangshuang CUI, Hongzhi WANG, Jiahao ZHU, Hao WU. Two-stage data selection method for classifier with low energy consumption and high performance [J]. Journal of Computer Applications, 2025, 45(6): 1703-1711. |
| [4] | Jie JIANG, Gongning LUO, Suyu DONG, Fanding LI, Xiangyu LI, Qince LI, Yongfeng YUAN, Kuanquan WANG. Information bottleneck-guided intracranial hemorrhage segmentation method [J]. Journal of Computer Applications, 2025, 45(6): 1998-2006. |
| [5] | Daoquan LI, Zheng XU, Sihui CHEN, Jiayu LIU. Network traffic classification model integrating variational autoencoder and AdaBoost-CNN [J]. Journal of Computer Applications, 2025, 45(6): 1841-1848. |
| [6] | Quan WANG, Qixiang LU, Pei SHI. Multi-graph diffusion attention network for traffic flow prediction [J]. Journal of Computer Applications, 2025, 45(5): 1472-1479. |
| [7] | Jie HU, Shuaixing WU, Zhilan CAO, Yan ZHANG. Named entity recognition model based on global information fusion and multi-dimensional relation perception [J]. Journal of Computer Applications, 2025, 45(5): 1511-1519. |
| [8] | Caiqi WANG, Xining CUI, Yi XIONG, Shiqian WU. Adaptive extended RRT* path planning algorithm based on node-to-obstacle distance [J]. Journal of Computer Applications, 2025, 45(3): 920-927. |
| [9] | Chuanhao ZHANG, Xiaohan TU, Xuehui GU, Bo XUAN. LiDAR-camera 3D object detection based on multi-modal information mutual guidance and supplementation [J]. Journal of Computer Applications, 2025, 45(3): 946-952. |
| [10] | Xingwang WANG, Qingyang ZHANG, Shouyong JIANG, Yongquan DONG. Dynamic UAV path planning based on modified whale optimization algorithm [J]. Journal of Computer Applications, 2025, 45(3): 928-936. |
| [11] | Linhao LI, Yize WANG, Yingshuang LI, Yongfeng DONG, Zhen WANG. Panoptic scene graph generation method based on relation feature enhancement [J]. Journal of Computer Applications, 2025, 45(2): 584-593. |
| [12] | Chao XU, Shufen ZHANG, Haitian CHEN, Lulu PENG, Shuaihua ZHANG. Federated learning method based on adaptive differential privacy and client selection optimization [J]. Journal of Computer Applications, 2025, 45(2): 482-489. |
| [13] | Yalun WANG, Yangsen ZHANG, Siwen ZHU. Headline generation model with position embedding for knowledge reasoning [J]. Journal of Computer Applications, 2025, 45(2): 345-353. |
| [14] | Wenbo ZHAO, Zitong MA, Zhe YANG. Link prediction model based on directed hypergraph adaptive convolution [J]. Journal of Computer Applications, 2025, 45(1): 15-23. |
| [15] | Qinzhuang ZHAO, Hongye TAN. Time series causal inference method based on adaptive threshold learning [J]. Journal of Computer Applications, 2024, 44(9): 2660-2666. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||