


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1596-1603.DOI: 10.11772/j.issn.1001-9081.2025050674
• Multimedia computing and computer simulation • Previous Articles
Zhengtao YU1,2( ), Yixue LUAN1,2, Wenjun WANG1,2, Ling DONG1,2, Yan XIANG1,2, Shengxiang GAO1,2
), Yixue LUAN1,2, Wenjun WANG1,2, Ling DONG1,2, Yan XIANG1,2, Shengxiang GAO1,2
Received:2025-06-19
Revised:2025-07-18
Accepted:2025-07-23
Online:2025-08-01
Published:2026-05-10
Contact:
Zhengtao YU
About author:LUAN Yixue, born in 2000, M. S. candidate. Her research interests include speech enhancement, speech recognition.Supported by:
余正涛1,2(), 栾逸雪1,2, 王文君1,2, 董凌1,2, 相艳1,2, 高盛祥1,2
通讯作者:
余正涛
作者简介:栾逸雪(2000—),女,云南个旧人,硕士研究生,主要研究方向:语音增强、语音识别;基金资助:CLC Number:
Zhengtao YU, Yixue LUAN, Wenjun WANG, Ling DONG, Yan XIANG, Shengxiang GAO. Bispectrum-based nonlinear feature coupling method for speech enhancement[J]. Journal of Computer Applications, 2026, 46(5): 1596-1603.
余正涛, 栾逸雪, 王文君, 董凌, 相艳, 高盛祥. 基于双谱非线性特征耦合的语音增强方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1596-1603.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050674

Fig.1 Overall structure of BNFC

Fig.2 Encoder structure

Fig.3 BE structure
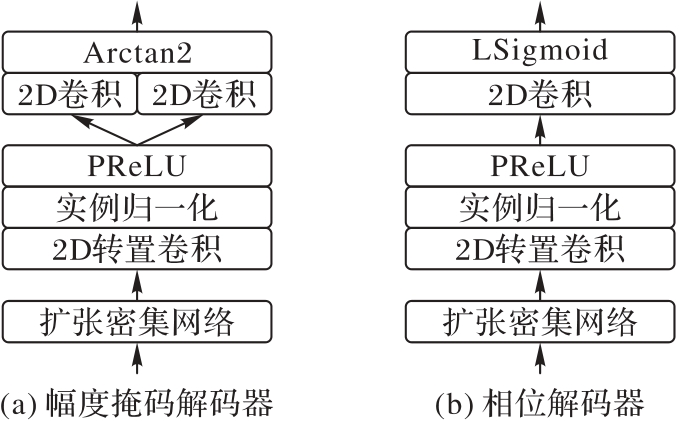
Fig.4 Decoder structure
| 模型 | 年份 | 模型处理信号的方法 | 模型参数量/106 | PESQ | CSIG | CBAK | COVL | SSNR/dB | STOI |
|---|---|---|---|---|---|---|---|---|---|
| Noisy | — | — | — | 1.97 | 3.35 | 2.44 | 2.63 | 1.68 | 0.91 |
| SEGAN | 2017 | T | 43.18 | 2.16 | 3.48 | 2.94 | 2.80 | 7.73 | 0.92 |
| Demucs | 2021 | T | 33.53 | 3.07 | 4.31 | 3.40 | 3.63 | — | 0.95 |
| SE-Conformer | 2021 | T | — | 3.13 | 4.45 | 3.55 | 3.82 | — | 0.95 |
| MetricGAN | 2019 | T | — | 2.86 | 3.99 | 3.18 | 3.42 | — | — |
| MetricGAN+ | 2021 | T-F | — | 3.15 | 4.14 | 3.16 | 3.64 | — | — |
| TridentSE | 2023 | T-F | 3.03 | 3.47 | 4.70 | 3.81 | 4.10 | — | 0.96 |
| CMGAN | 2022 | T-F | 1.83 | 3.41 | 4.63 | 3.94 | 4.12 | 11.10 | 0.96 |
| PHASEN | 2020 | T-F | — | 2.99 | 4.21 | 3.55 | 3.62 | 10.18 | — |
| BREM | 2025 | T-F | 5.16 | 3.09 | 4.54 | 3.90 | 3.88 | — | 0.97 |
| MP-SENet | 2023 | T-F | 2.05 | 3.50 | 4.73 | 3.95 | 4.22 | 10.64 | 0.96 |
| SEMamba | 2024 | T-F | 2.25 | 3.55 | 4.77 | 3.95 | 4.26 | — | 0.96 |
| BNFC | 2025 | T-F | 2.26 | 3.57 | 4.79 | 4.02 | 4.28 | 10.71 | 0.96 |
Tab. 1 Evaluation scores of BNFC and baseline models on VoiceBank+DEMAND dataset
| 模型 | 年份 | 模型处理信号的方法 | 模型参数量/106 | PESQ | CSIG | CBAK | COVL | SSNR/dB | STOI |
|---|---|---|---|---|---|---|---|---|---|
| Noisy | — | — | — | 1.97 | 3.35 | 2.44 | 2.63 | 1.68 | 0.91 |
| SEGAN | 2017 | T | 43.18 | 2.16 | 3.48 | 2.94 | 2.80 | 7.73 | 0.92 |
| Demucs | 2021 | T | 33.53 | 3.07 | 4.31 | 3.40 | 3.63 | — | 0.95 |
| SE-Conformer | 2021 | T | — | 3.13 | 4.45 | 3.55 | 3.82 | — | 0.95 |
| MetricGAN | 2019 | T | — | 2.86 | 3.99 | 3.18 | 3.42 | — | — |
| MetricGAN+ | 2021 | T-F | — | 3.15 | 4.14 | 3.16 | 3.64 | — | — |
| TridentSE | 2023 | T-F | 3.03 | 3.47 | 4.70 | 3.81 | 4.10 | — | 0.96 |
| CMGAN | 2022 | T-F | 1.83 | 3.41 | 4.63 | 3.94 | 4.12 | 11.10 | 0.96 |
| PHASEN | 2020 | T-F | — | 2.99 | 4.21 | 3.55 | 3.62 | 10.18 | — |
| BREM | 2025 | T-F | 5.16 | 3.09 | 4.54 | 3.90 | 3.88 | — | 0.97 |
| MP-SENet | 2023 | T-F | 2.05 | 3.50 | 4.73 | 3.95 | 4.22 | 10.64 | 0.96 |
| SEMamba | 2024 | T-F | 2.25 | 3.55 | 4.77 | 3.95 | 4.26 | — | 0.96 |
| BNFC | 2025 | T-F | 2.26 | 3.57 | 4.79 | 4.02 | 4.28 | 10.71 | 0.96 |
| 模型 | PESQ | CSIG | CBAK | COVL | SSNR/dB |
|---|---|---|---|---|---|
| MP-SENet | 3.50 | 4.73 | 3.95 | 4.22 | 10.64 |
| BNFC | 3.57 | 4.79 | 4.02 | 4.28 | 10.71 |
| +Encoder | 3.55 | 4.78 | 4.00 | 4.27 | 10.68 |
| +Decoder | 3.49 | 4.75 | 3.97 | 4.22 | 10.64 |
| +Branch | 3.52 | 4.76 | 3.99 | 4.25 | 10.66 |
Tab. 2 Effect evaluation of bispectrum module in different fusion positions of BNFC on VoiceBank+DEMAND dataset
| 模型 | PESQ | CSIG | CBAK | COVL | SSNR/dB |
|---|---|---|---|---|---|
| MP-SENet | 3.50 | 4.73 | 3.95 | 4.22 | 10.64 |
| BNFC | 3.57 | 4.79 | 4.02 | 4.28 | 10.71 |
| +Encoder | 3.55 | 4.78 | 4.00 | 4.27 | 10.68 |
| +Decoder | 3.49 | 4.75 | 3.97 | 4.22 | 10.64 |
| +Branch | 3.52 | 4.76 | 3.99 | 4.25 | 10.66 |
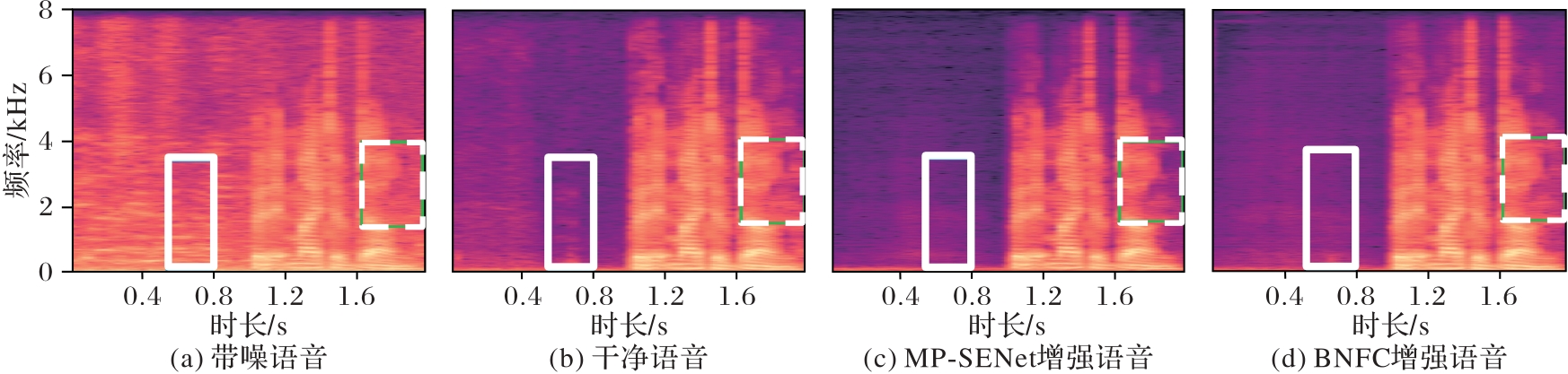
Fig.5 Spectrograms of clean speech, noisy speech, as well as speech enhanced by MP-SENet and BNFC for p232_048
| [1] | EPHRAIM Y, MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1109-1121. |
| [2] | BOLL S. Suppression of acoustic noise in speech using spectral subtraction[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2): 113-120. |
| [3] | WILSON K W, RAJ B, SMARAGDIS P, et al. Speech denoising using nonnegative matrix factorization with priors[C]// Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2008: 4029-4032. |
| [4] | WANG D, CHEN J. Supervised speech separation based on deep learning: an overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702-1726. |
| [5] | VAN DEN OORD A, DIELEMAN S, ZEN H, et al. WaveNet: a generative model for raw audio[C]// Proceedings of the 9th ISCA Speech Synthesis Workshop. [S.l.]: International Speech Communication Association, 2016: 125. |
| [6] | DÉFOSSEZ A, USUNIER N, BOTTOU L, et al. Demucs: deep extractor for music sources with extra unlabeled data remixed[EB/OL]. [2025-07-18]. . |
| [7] | HU Y, LIU Y, LV S, et al. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2472-2476. |
| [8] | YIN D, LUO C, XIONG Z, et al. PHASEN: a phase-and-harmonics-aware speech enhancement network[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9458-9465. |
| [9] | ABDALLA R. Complex-valued neural networks — theory and analysis[EB/OL]. [2025-07-18].. |
| [10] | LU Y X, YANG A, LING Z H. MP-SENet: a speech enhancement model with parallel denoising of magnitude and phase spectra[C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 3834-3838. |
| [11] | ALHUSSEIN G, ALKHODARI M, KHANDOKER A H, et al. Deep bispectral analysis of conversational speech towards emotional climate recognition[C]// Proceedings of the 2023 IEEE International Conference on Artificial Intelligence in Engineering and Technology. Piscataway: IEEE, 2023: 170-175. |
| [12] | WANG W, DONG L, YU Z, et al. Robust speech recognition method based on dense time-frequency convolution and bispectral refinement enhancement[J]. International Journal of Machine Learning and Cybernetics, 2025, 16(9): 5707-5725. |
| [13] | TAN K, WANG D. Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6865-6869. |
| [14] | 莫尚斌,王文君,董凌,等.基于多路信息聚合协同解码的单通道语音增强[J].计算机应用,2024,44(8):2611-2617. |
| MO S B, WANG W J, DONG L, et al. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding[J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. | |
| [15] | CAO R, ABDULATIF S, YANG B. CMGAN: conformer-based metric GAN for speech enhancement[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 936-940. |
| [16] | ZHANG Z, XU S, ZHUANG X, et al. Dual branch deep interactive UNet for monaural noisy-reverberant speech enhancement[J]. Applied Acoustics, 2023, 212: No.109574. |
| [17] | SU Y, LIU Y, YANG C, et al. MN-Net: multi-scale feature fusion and neighborhood attention self-supervised network for industrial spool surface anomaly detection[C]// Proceedings of the IEEE 36th International Conference on Tools with Artificial Intelligence. Piscataway: IEEE, 2024: 282-289. |
| [18] | NIKIAS C L, MENDEL J M. Signal processing with higher-order spectra[J]. IEEE Signal Processing Magazine, 1993, 10(3): 10-37. |
| [19] | RANGOUSSI M, CARAYANNIS G. Adaptive detection of noisy speech using third-order statistics[J]. International Journal of Adaptive Control and Signal Processing, 1996, 10(2/3): 113-136. |
| [20] | HIRLEKAR S G, HOLAMBE R S, BASU T K. Phase recovery from bispectrum[J]. IETE Journal of Research, 2000, 46(3): 139-145. |
| [21] | LAVANYA T, VIJAYALAKSHMI P, MRINALINI K, et al. Higher order statistics-driven magnitude and phase spectrum estimation for speech enhancement[J]. Computer Speech and Language, 2024, 87: No.101639. |
| [22] | PANDEY A, WANG D. Densely connected neural network with dilated convolutions for real-time speech enhancement in the time domain[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6629-6633. |
| [23] | ULYANOV D, VEDALDI A, LEMPITSKY V. Instance normalization: the missing ingredient for fast stylization[EB/OL]. [2025-02-18].. |
| [24] | HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1026-1034. |
| [25] | FU S W, YU C, HSIEH T A, et al. MetricGAN+: an improved version of MetricGAN for speech enhancement[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 201-205. |
| [26] | YANG A, LING Z H. Neural speech phase prediction based on parallel estimation architecture and anti-wrapping losses[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [27] | VALENTINI-BOTINHAO C, WANG X, TAKAKI S, et al. Investigating RNN-based speech enhancement methods for noise-robust text-to-speech[C]// Proceedings of the 9th ISCA Speech Synthesis Workshop. [S.l.]: International Speech Communication Association, 2016: 146-152. |
| [28] | VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: design, collection and data analysis of a large regional accent speech database[C]// Proceedings of the 2013 International Conference on Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4. |
| [29] | THIEMANN J, ITO N, VINCENT E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): a database of multichannel environmental noise recordings[J]. Proceedings of Meetings on Acoustics, 2013, 19(1): No.035081. |
| [30] | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]. [2025-01-09].. |
| [31] | PASCUAL S, BONAFONTE A, SERRÀ J. SEGAN: speech enhancement generative adversarial network[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 3642-3646. |
| [32] | KIM E, SEO H. SE-Conformer: time-domain speech enhancement using conformer[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 2736-2740. |
| [33] | FU S W, LIAO C F, TSAO Y, et al. MetricGAN: generative adversarial networks based black-box metric scores optimization for speech enhancement[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2031-2041. |
| [34] | YIN D, ZHAO Z, TANG C, et al. TridentSE: guiding speech enhancement with 32 global tokens[C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 3839-3843. |
| [35] | CHAO R, CHENG W H, LA QUATRA M, et al. An investigation of incorporating mamba for speech enhancement[C]// Proceedings of the 2024 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2024: 302-308. |
| [1] | Ming DENG, Jinfan XU, Hongxiang XIAO, Xiaolan XIE. Medical image segmentation network based on improved TransUNet with efficient channel attention [J]. Journal of Computer Applications, 2025, 45(12): 4037-4044. |
| [2] | Guoyu XU, Xiaolong YAN, Yidan ZHANG. DU-FastGAN: lightweight generative adversarial network based on dynamic-upsample [J]. Journal of Computer Applications, 2025, 45(10): 3067-3073. |
| [3] | Juntao CHEN, Ziqi ZHU. Image copy-move forgery detection based on multi-scale feature extraction and fusion [J]. Journal of Computer Applications, 2023, 43(9): 2919-2924. |
| [4] | Jiangfeng ZHANG, Tao YAN, Bin CHEN, Yuhua QIAN, Yantao SONG. Multi-depth-of-field 3D shape reconstruction with global spatio-temporal feature coupling [J]. Journal of Computer Applications, 2023, 43(3): 894-902. |
| [5] | Qiuyu ZHANG, Yukun WANG. Speech classification model based on improved Inception network [J]. Journal of Computer Applications, 2023, 43(3): 909-915. |
| [6] | Xiaoyan LU, Yang XU, Wenhao YUAN. Multiscale dense fusion network for lung lesion image segmentation [J]. Journal of Computer Applications, 2023, 43(10): 3282-3289. |
| [7] | Minghui WU, Guangjie ZHANG, Canghong JIN. Time series prediction model based on multimodal information fusion [J]. Journal of Computer Applications, 2022, 42(8): 2326-2332. |
| [8] | XIAO Yong, ZHENG Kaihong, ZHENG Zhenjing, QIAN Bin, LI Sen, MA Qianli. Multi-scale skip deep long short-term memory network for short-term multivariate load forecasting [J]. Journal of Computer Applications, 2021, 41(1): 231-236. |
| [9] | DAI Qiang, CHENG Xi, WANG Yongmei, NIU Ziwei, LIU Fei. Light-weight automatic residual scaling network for image super-resolution reconstruction [J]. Journal of Computer Applications, 2020, 40(5): 1446-1452. |
| [10] | JIA Ruiming, QIU Zhenzhi, CUI Jiali, WANG Yiding. Deep multi-scale encoder-decoder convolutional network for blind deblurring [J]. Journal of Computer Applications, 2019, 39(9): 2552-2557. |
| [11] | GAO Yuan, LIU Zhi, QIN Pinle, WANG Lifang. Medical image super-resolution algorithm based on deep residual generative adversarial network [J]. Journal of Computer Applications, 2018, 38(9): 2689-2695. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||