


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (7): 2288-2296.DOI: 10.11772/j.issn.1001-9081.2025060699
• Multimedia computing and computer simulation • Previous Articles
Xiuli DU1,2, Xing GAO1,2, Xiaoyu ZHANG1,2, Chengsheng PAN3( ), Qijie ZOU2
), Qijie ZOU2
Received:2025-06-24
Revised:2025-09-28
Accepted:2025-09-30
Online:2025-10-23
Published:2026-07-10
Contact:
Chengsheng PAN
About author:DU Xiuli, born in 1977, Ph. D., professor. Her research interests include compressed sensing, perception and recognition of electroencephalogram signals.Supported by:
杜秀丽1,2, 高星1,2, 张校毓1,2, 潘成胜3(), 邹启杰2
通讯作者:
潘成胜
作者简介:杜秀丽(1977—),女,辽宁锦州人,教授,博士,CCF会员,主要研究方向:压缩感知、脑电信号感知与识别基金资助:CLC Number:
Xiuli DU, Xing GAO, Xiaoyu ZHANG, Chengsheng PAN, Qijie ZOU. Video snapshot compressive imaging reconstruction method based on dense spatio-temporal deformable attention[J]. Journal of Computer Applications, 2026, 46(7): 2288-2296.
杜秀丽, 高星, 张校毓, 潘成胜, 邹启杰. 基于密集时空可变形注意力的视频快照压缩成像重建方法[J]. 《计算机应用》唯一官方网站, 2026, 46(7): 2288-2296.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025060699
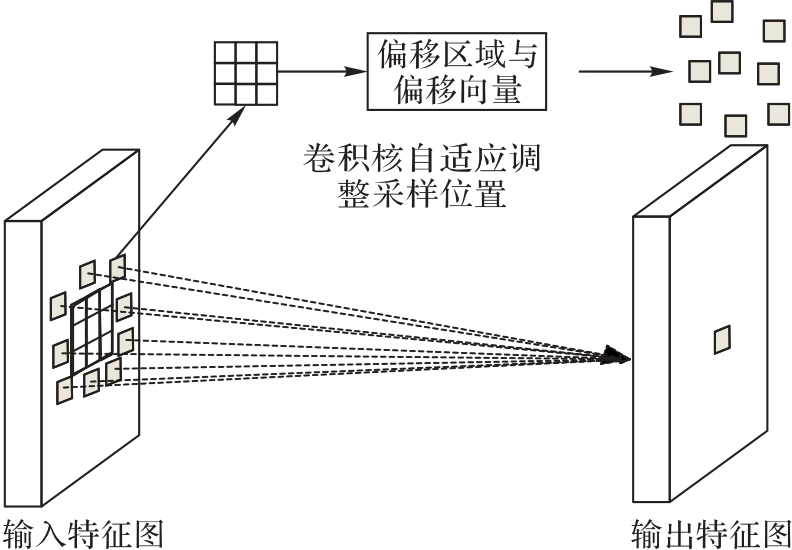
Fig. 1 Process of deformable convolutional feature extraction
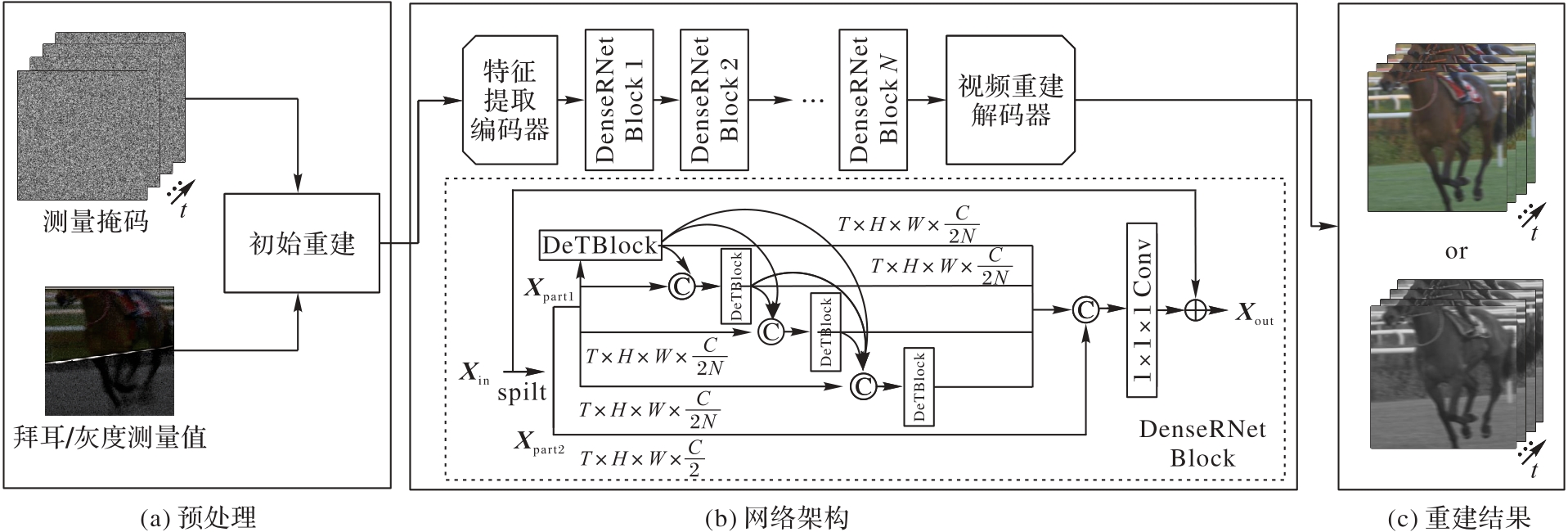
Fig. 2 DeT-SCI network architecture
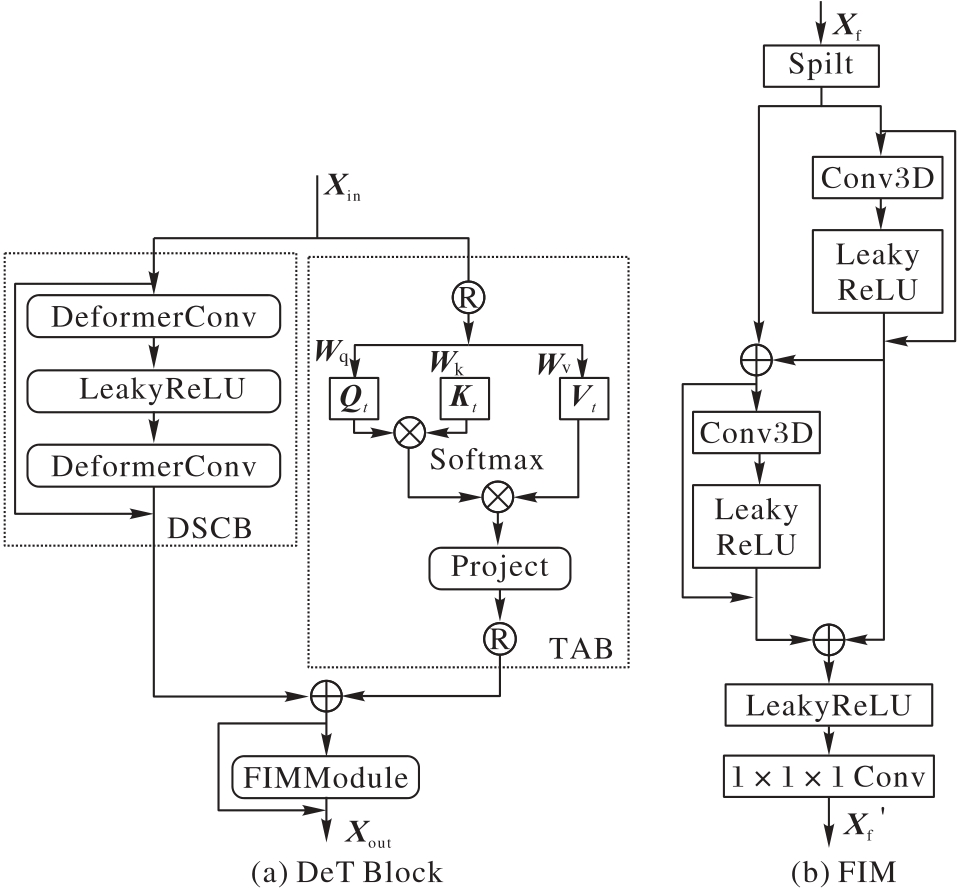
Fig. 3 DeT Block architecture
| 方法 | 模拟灰度数据集的PSNR/dB | ||||||
|---|---|---|---|---|---|---|---|
| Kobe | Traffic | Runner | Drop | Crash | Aerial | Average | |
| PnP-FFDNet | 30.50 | 24.18 | 32.15 | 40.70 | 25.42 | 25.27 | 29.70 |
| DeSCI | 33.25 | 28.71 | 38.48 | 43.10 | 27.04 | 25.33 | 32.65 |
| BIRNAT | 32.71 | 29.33 | 38.70 | 42.28 | 27.84 | 28.99 | 33.31 |
| RevSCI | 33.72 | 30.02 | 39.40 | 42.93 | 28.12 | 29.35 | 33.92 |
| STFormer | 33.19 | 29.19 | 39.00 | 42.84 | 29.26 | 30.13 | 33.94 |
| EfficientSCI++ | 30.21 | 40.18 | 42.42 | 30.17 | 34.63 | ||
| M2BA-SCI | 33.90 | 30.74 | |||||
| DeT-SCI | 34.57 | 30.71 | 41.04 | 43.93 | 30.40 | 31.14 | 35.30 |
Tab. 1 Comparison of reconstruction results on simulated grayscale datasets
| 方法 | 模拟灰度数据集的PSNR/dB | ||||||
|---|---|---|---|---|---|---|---|
| Kobe | Traffic | Runner | Drop | Crash | Aerial | Average | |
| PnP-FFDNet | 30.50 | 24.18 | 32.15 | 40.70 | 25.42 | 25.27 | 29.70 |
| DeSCI | 33.25 | 28.71 | 38.48 | 43.10 | 27.04 | 25.33 | 32.65 |
| BIRNAT | 32.71 | 29.33 | 38.70 | 42.28 | 27.84 | 28.99 | 33.31 |
| RevSCI | 33.72 | 30.02 | 39.40 | 42.93 | 28.12 | 29.35 | 33.92 |
| STFormer | 33.19 | 29.19 | 39.00 | 42.84 | 29.26 | 30.13 | 33.94 |
| EfficientSCI++ | 30.21 | 40.18 | 42.42 | 30.17 | 34.63 | ||
| M2BA-SCI | 33.90 | 30.74 | |||||
| DeT-SCI | 34.57 | 30.71 | 41.04 | 43.93 | 30.40 | 31.14 | 35.30 |

Fig. 4 Comparison of selected reconstruction frames in simulated grayscale video datasets
| 方法 | 模拟彩色数据集的PSNR/dB | ||||||
|---|---|---|---|---|---|---|---|
| Beauty | Bosphorus | Jockey | Runner | ShakeNDry | Traffic | Average | |
| GAP-TV | 33.08 | 29.70 | 29.48 | 29.10 | 29.59 | 19.84 | 28.47 |
| DeSCI | 34.66 | 32.88 | 34.14 | 36.16 | 30.94 | 24.62 | 32.23 |
| PnP-FastDVDNet | 35.27 | 37.24 | 35.63 | 38.22 | 33.71 | 27.49 | 34.60 |
| BIRNAT | 36.08 | 38.30 | 36.51 | 39.65 | 34.26 | 28.03 | 35.47 |
| STFormer | 36.83 | 38.36 | 37.09 | 40.56 | 34.67 | 36.09 | |
| SCT-SCI | 28.64 | ||||||
| DeT-SCI | 37.08 | 40.71 | 38.32 | 42.22 | 35.02 | 30.06 | 37.23 |
Tab. 2 Comparison of reconstruction results on simulated color datasets
| 方法 | 模拟彩色数据集的PSNR/dB | ||||||
|---|---|---|---|---|---|---|---|
| Beauty | Bosphorus | Jockey | Runner | ShakeNDry | Traffic | Average | |
| GAP-TV | 33.08 | 29.70 | 29.48 | 29.10 | 29.59 | 19.84 | 28.47 |
| DeSCI | 34.66 | 32.88 | 34.14 | 36.16 | 30.94 | 24.62 | 32.23 |
| PnP-FastDVDNet | 35.27 | 37.24 | 35.63 | 38.22 | 33.71 | 27.49 | 34.60 |
| BIRNAT | 36.08 | 38.30 | 36.51 | 39.65 | 34.26 | 28.03 | 35.47 |
| STFormer | 36.83 | 38.36 | 37.09 | 40.56 | 34.67 | 36.09 | |
| SCT-SCI | 28.64 | ||||||
| DeT-SCI | 37.08 | 40.71 | 38.32 | 42.22 | 35.02 | 30.06 | 37.23 |

Fig. 5 Comparison of selected reconstructed frames in simulated color video datasets

Fig. 6 Comparison of reconstruction results on Duomino real data

Fig. 7 Comparison of reconstruction results on Water Balloon real data
| 方法 | 参数量/106 | 浮点运算量/GFLOPs | PSNR/dB | SSIM |
|---|---|---|---|---|
| RevSCI[ | 5.66 | 766.95 | 33.92 | 0.956 |
| DDUN [ | 61.91 | 3 975.83 | 35.26 | 0.968 |
| STFormer[ | 1.22 | 193.47 | 33.94 | 0.958 |
| EfficientSCI++[ | 3.78 | 563.87 | 34.63 | 0.966 |
| M2BA-SCI[ | 5.70 | 882.89 | 34.85 | 0.966 |
| DeT-SCI | 3.60 | 424.74 | 35.30 | 0.970 |
Tab. 3 Comparison of network model performance
| 方法 | 参数量/106 | 浮点运算量/GFLOPs | PSNR/dB | SSIM |
|---|---|---|---|---|
| RevSCI[ | 5.66 | 766.95 | 33.92 | 0.956 |
| DDUN [ | 61.91 | 3 975.83 | 35.26 | 0.968 |
| STFormer[ | 1.22 | 193.47 | 33.94 | 0.958 |
| EfficientSCI++[ | 3.78 | 563.87 | 34.63 | 0.966 |
| M2BA-SCI[ | 5.70 | 882.89 | 34.85 | 0.966 |
| DeT-SCI | 3.60 | 424.74 | 35.30 | 0.970 |
| TAB | DSCB | 3D-SCB | FIM | SimpleFIM | 参数量/106 | 浮点运算量/GFLOPs | PSNR/dB | SSIM |
|---|---|---|---|---|---|---|---|---|
| √ | √ | 2.91 | 383.97 | 33.63 | 0.956 | |||
| √ | √ | 3.17 | 394.52 | 34.63 | 0.964 | |||
| √ | √ | 2.40 | 269.05 | 34.14 | 0.960 | |||
| √ | √ | √ | 2.98 | 344.21 | 34.97 | 0.966 | ||
| √ | √ | √ | 3.28 | 432.29 | 34.57 | 0.965 | ||
| √ | √ | √ | 3.60 | 424.74 | 35.30 | 0.970 |
Tab. 4 Ablation experimental results of DeT Block
| TAB | DSCB | 3D-SCB | FIM | SimpleFIM | 参数量/106 | 浮点运算量/GFLOPs | PSNR/dB | SSIM |
|---|---|---|---|---|---|---|---|---|
| √ | √ | 2.91 | 383.97 | 33.63 | 0.956 | |||
| √ | √ | 3.17 | 394.52 | 34.63 | 0.964 | |||
| √ | √ | 2.40 | 269.05 | 34.14 | 0.960 | |||
| √ | √ | √ | 2.98 | 344.21 | 34.97 | 0.966 | ||
| √ | √ | √ | 3.28 | 432.29 | 34.57 | 0.965 | ||
| √ | √ | √ | 3.60 | 424.74 | 35.30 | 0.970 |
| [1] | Yuan X, Brady D J, Katsaggelos A K. Snapshot compressive imaging: Theory, algorithms, and applications [J]. IEEE Signal Processing Magazine, 2021, 38(2): 65-88. |
| [2] | Pan F, Wen J, Han Y. Snapshot compressed imaging based single-measurement computer vision for videos [PP/OL]. arXiv (2025-01-25) [2025-05-25]. . |
| [3] | Yuan X, Pu Y. Parallel lensless compressive imaging via deep convolutional neural networks [J]. Optics Express, 2018, 26(2): 1962-1977. |
| [4] | Zhang Z, Zheng S, Qiu M, et al. A decade review of video compressive sensing: a roadmap to practical applications [J]. Engineering, 2025, 46: 172-185. |
| [5] | Hitomi Y, Gu J, Gupta M, et al. Video from a single coded exposure photograph using a learned over-complete dictionary [C]// ICCV 2011. Piscataway: IEEE, 2011: 287-294. |
| [6] | Reddy D, Veeraraghavan A, Chellappa R. P2C2: programmable pixel compressive camera for high speed imaging [C]// CVPR 2011. Piscataway: IEEE, 2011: 329-336. |
| [7] | Llull P, Liao X, Yuan X, et al. Coded aperture compressive temporal imaging [J]. Optics Express, 2013, 21(9): 10526-10545. |
| [8] | Liao X, Li H, Carin L. Generalized alternating projection for weighted-l2, 1 minimization with applications to model-based compressive sensing [J]. SIAM Journal on Imaging Sciences, 2014, 7(2): 797-823. |
| [9] | Yang J, Yuan X, Liao X, et al. Video compressive sensing using Gaussian mixture models [J]. IEEE Transactions on Image Processing, 2014, 23(11): 4863-4878. |
| [10] | Sun Y, Chen X, Kankanhalli M S, et al. Video snapshot compressive imaging using residual ensemble network [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(9): 5931-5943. |
| [11] | Wang L, Cao M, Zhong Y, et al. Spatial-temporal Transformer for video snapshot compressive imaging [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(7): 9072-9089. |
| [12] | 周宇,谢威,邝得互,等.基于三元自注意力的视频快照压缩成像重建[J].计算机工程, 2025, 51(1): 20-30. |
| Zhou Yu, Xie Wei, Takwu Kwong, et al. Reconstruction of video snapshot compressive imaging based on triple self-attention [J]. Computer Engineering, 2025, 51(1): 20-30. | |
| [13] | Cheng Z, Lu R, Wang Z, et al. BIRNAT: bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging [C]// ECCV 2020. Cham: Springer, 2020: 258-275. |
| [14] | Wu Z, Zhang J, Mou C. Dense deep unfolding network with 3D-CNN prior for snapshot compressive imaging [C]// ICCV 2021. Piscataway: IEEE, 2021: 4872-4881. |
| [15] | 郑巳明,朱明宇,袁鑫,等.基于弹性权重巩固的视频单曝光压缩成像算法研究[J].数据与计算发展前沿, 2024, 6(5): 111-125. |
| Zheng Siming, Zhu Mingyu, Yuan Xin, et al. Video snapshot compressive imaging based on elastic weight consolidation [J]. Frontiers of Data and Computing, 2024, 6(5): 111-125. | |
| [16] | Yuan X, Liu Y, Suo J, et al. Plug-and-play algorithms for large-scale snapshot compressive imaging [C]// CVPR 2020. Piscataway: IEEE, 2020: 1444-1454. |
| [17] | Yuan X, Liu Y, Suo J, et al. Plug-and-play algorithms for video snapshot compressive imaging [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10): 7093-7111. |
| [18] | Wu Z, Yang C, Su X, et al. Adaptive deep PnP algorithm for video snapshot compressive imaging [J]. International Journal of Computer Vision, 2023, 131(7): 1662-1679. |
| [19] | 唐麒,赵耀,刘美琴,等.基于深度学习的视频超分辨率重建算法进展[J].自动化学报, 2025, 51(7): 1480-1524. |
| Tang Qi, Zhao Yao, Liu Meiqin, et al. A review of video super-resolution algorithms based on deep learning [J]. Acta Automatica Sinica, 2025, 51(7): 1480-1524. | |
| [20] | Liu Y, Yuan X, Suo J, et al. Rank minimization for snapshot compressive imaging [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(12): 2990-3006. |
| [21] | Dai J, Qi H, Xiong Y, et al. Deformable convolutional networks [C]// ICCV 2017. Piscataway: IEEE, 2017: 764-773. |
| [22] | Ying X, Wang L, Wang Y, et al. Deformable 3D convolution for video super-resolution [J]. IEEE Signal Processing Letters, 2020, 27: 1500-1504. |
| [23] | Hu Z, Lu G, Xu D. FVC: a new framework towards deep video compression in feature space [C]// CVPR 2021. Piscataway: IEEE, 2021: 1502-1511. |
| [24] | Wang R, Shivanna R, Cheng D, et al. DCN V2: improved deep & cross network and practical lessons for web-scale learning to rank systems [C]// Web Conference 2021. New York: ACM, 2021: 1785-1797. |
| [25] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]// NeurIPS 2017. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [26] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [PP/OL]. V2. arXiv (2021-06-03) [2025-05-25]. . |
| [27] | Arnab A, Dehghani M, Heigold G, et al. ViViT: a video Vision Transformer [C]// ICCV 2021. Piscataway: IEEE, 2021: 6816-6826. |
| [28] | Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding? [C]// ICML 2021. New York: JMLR.org, 2021: 813-824. |
| [29] | Liu Z, Lin Y, Cao Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows [C]// ICCV 2021. Piscataway: IEEE, 2021: 9992-10002. |
| [30] | Huang G, Liu Z, van der Maaten L, et al. Densely connected convolutional networks [C]// CVPR 2017. Piscataway: IEEE, 2017: 2261-2269. |
| [31] | Pont-Tuset J, Perazzi F, Caelles S, et al. The 2017 DAVIS challenge on video object segmentation [PP/OL]. V3. arXiv (2018-03-01) [2025-05-26]. . |
| [32] | Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity [J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. |
| [33] | Cheng Z, Chen B, Liu G, et al. Memory-efficient network for large-scale video compressive sensing [C]// CVPR 2021. Piscataway: IEEE, 2021: 16241-16250. |
| [34] | Cao M, Wang L, Zhu M, et al. Hybrid CNN-Transformer architecture for efficient large-scale video snapshot compressive imaging [J]. International Journal of Computer Vision, 2024, 132(10): 4521-4540. |
| [35] | 石敦攀,徐伟,朴永杰,等.基于Mamba-2的视频快照压缩成像重构方法[J].液晶与显示, 2025, 40(6): 881-894. |
| Shi Dunpan, Xu Wei, Yongjie Piao, et al. Reconstruction method of video snapshot compressive imaging based on Mamba-2 [J]. Chinese Journal of Liquid Crystals and Displays, 2025, 40(6): 881-894. |
| [1] | Xiangyi WU, Hailiang YE, Feilong CAO. Point cloud completion method based on smooth-sharpen graph convolution [J]. Journal of Computer Applications, 2026, 46(7): 2267-2276. |
| [2] | Yi DU, Mingjin XU, Jiayi KONG, Liyao WANG, Chen ZHAO. Low-rank adaptive parameter-efficient fine-tuning algorithm based on YOLOv11 [J]. Journal of Computer Applications, 2026, 46(6): 1738-1745. |
| [3] | Zhenkai XIONG, Mengjun XU, Yinyin SUN, Xin WANG. Maritime ship detection algorithm under complex weather environments based on enhanced YOLOv8 [J]. Journal of Computer Applications, 2026, 46(6): 1998-2006. |
| [4] | Yunping HE, Leichun WANG, Ruirui SONG, Xiangfeng LU, Jinxiang WEI, Xiaomeng LIU. Dual-channel multimodal sentiment analysis model based on contrast invariance and reinforcement specificity [J]. Journal of Computer Applications, 2026, 46(6): 1767-1775. |
| [5] | Lili HE, Meng CAO, Lei ZHANG, Hongjun PAN, Yi LIU, Chengxin SUN. Sign language generation model based on Kolmogorov-Arnold network and diffusion Transformer [J]. Journal of Computer Applications, 2026, 46(6): 1801-1810. |
| [6] | Qianfei WANG, Yang LI, Deyu LI, Suge WANG. Dual-channel feature fusion representation method for short-text clustering based on large language model [J]. Journal of Computer Applications, 2026, 46(5): 1441-1449. |
| [7] | Xing SHENG, Sunxian WENG, Kuosong CHEN, Zhongping WANG, Ruifeng REN, Yong LIU. Deep learning-based patent value evaluation for power grid enterprises [J]. Journal of Computer Applications, 2026, 46(5): 1468-1474. |
| [8] | Ruirui SONG, Leichun WANG, Yunping HE, Jinxiang WEI, Xiangfeng LU, Xiaomeng LIU. Long time series prediction based on hybrid self-attention and differentiated normalization [J]. Journal of Computer Applications, 2026, 46(5): 1499-1506. |
| [9] | Huijie GUO, Tianfeng DOU, Zhenlin ZHANG, Kaiyuan QI, Dong WU, Zhijian QU, Zhao LI, Chongguang REN. Time-interdependency-aware dynamic Bayesian network for traffic prediction [J]. Journal of Computer Applications, 2026, 46(5): 1507-1517. |
| [10] | Xinyao LIU, Jun LIANG, Jiahao LONG, Renliang YAN. Fine-grained Chinese herbal medicine image classification based on feature fusion and channel information compensation [J]. Journal of Computer Applications, 2026, 46(5): 1677-1683. |
| [11] | Haoxuan CHEN, Peichang YE, Lei LIU, Chengming LIU, Wenhua HU. Survey of automated code edit suggestion [J]. Journal of Computer Applications, 2026, 46(4): 1227-1237. |
| [12] | Yongwei JIANG, Xiaoqing CHEN, Linjie FU. Elastic medical image registration model with high-frequency preservation based on spectrum decomposition [J]. Journal of Computer Applications, 2026, 46(3): 924-932. |
| [13] | Songsen YU, Huang HE, Guopeng XUE, Hengtuo CUI. Quantitation and grading method for ceramic tile chromatic aberration based on improved fractal encoding network [J]. Journal of Computer Applications, 2026, 46(3): 959-968. |
| [14] | Jian ZHANG, Jianbo YU, Jian TANG. Municipal solid waste incineration state recognition method based on multilayer preprocessing [J]. Journal of Computer Applications, 2026, 46(3): 940-949. |
| [15] | Min CHEN, Xiaolin QIN, Shaohan LI, Hao YANG, Taohong LI. Review of deep learning applications in severe convective weather prediction [J]. Journal of Computer Applications, 2026, 46(3): 980-992. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||