


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (7): 2307-2317.DOI: 10.11772/j.issn.1001-9081.2025060749
• Multimedia computing and computer simulation • Previous Articles
Yanyang LIANG1, Wenxuan XIE2( ), Wei CUI2, Hongfei LYU2, Da LI2, Dongzhou ZHONG1
), Wei CUI2, Hongfei LYU2, Da LI2, Dongzhou ZHONG1
Received:2025-07-09
Revised:2025-09-12
Accepted:2025-09-24
Online:2025-10-27
Published:2026-07-10
Contact:
Wenxuan XIE
About author:LIANG Yanyang, born in 1980, Ph. D., associate professor. His research interests include machine vision, robotic motion control.Supported by:
梁艳阳1, 谢文轩2(), 崔伟2, 吕洪妃2, 李达2, 钟东洲1
通讯作者:
谢文轩
作者简介:梁艳阳(1980—),男,广东阳江人,副教授,博士,主要研究方向:机器视觉、机器人运动控制基金资助:CLC Number:
Yanyang LIANG, Wenxuan XIE, Wei CUI, Hongfei LYU, Da LI, Dongzhou ZHONG. Robotic end-to-end dynamic grasping method based on curriculum reinforcement learning[J]. Journal of Computer Applications, 2026, 46(7): 2307-2317.
梁艳阳, 谢文轩, 崔伟, 吕洪妃, 李达, 钟东洲. 基于课程强化学习的机器人端到端动态抓取方法[J]. 《计算机应用》唯一官方网站, 2026, 46(7): 2307-2317.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025060749
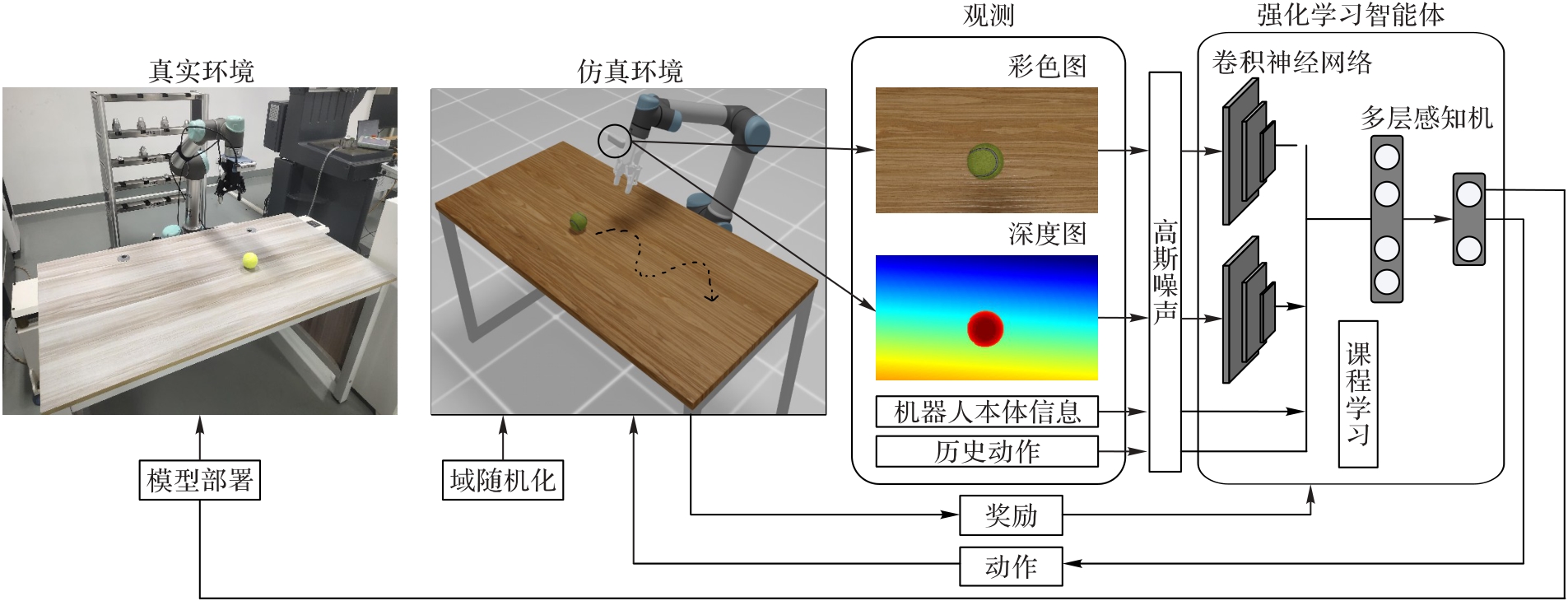
Fig. 1 Basic framework of CRL
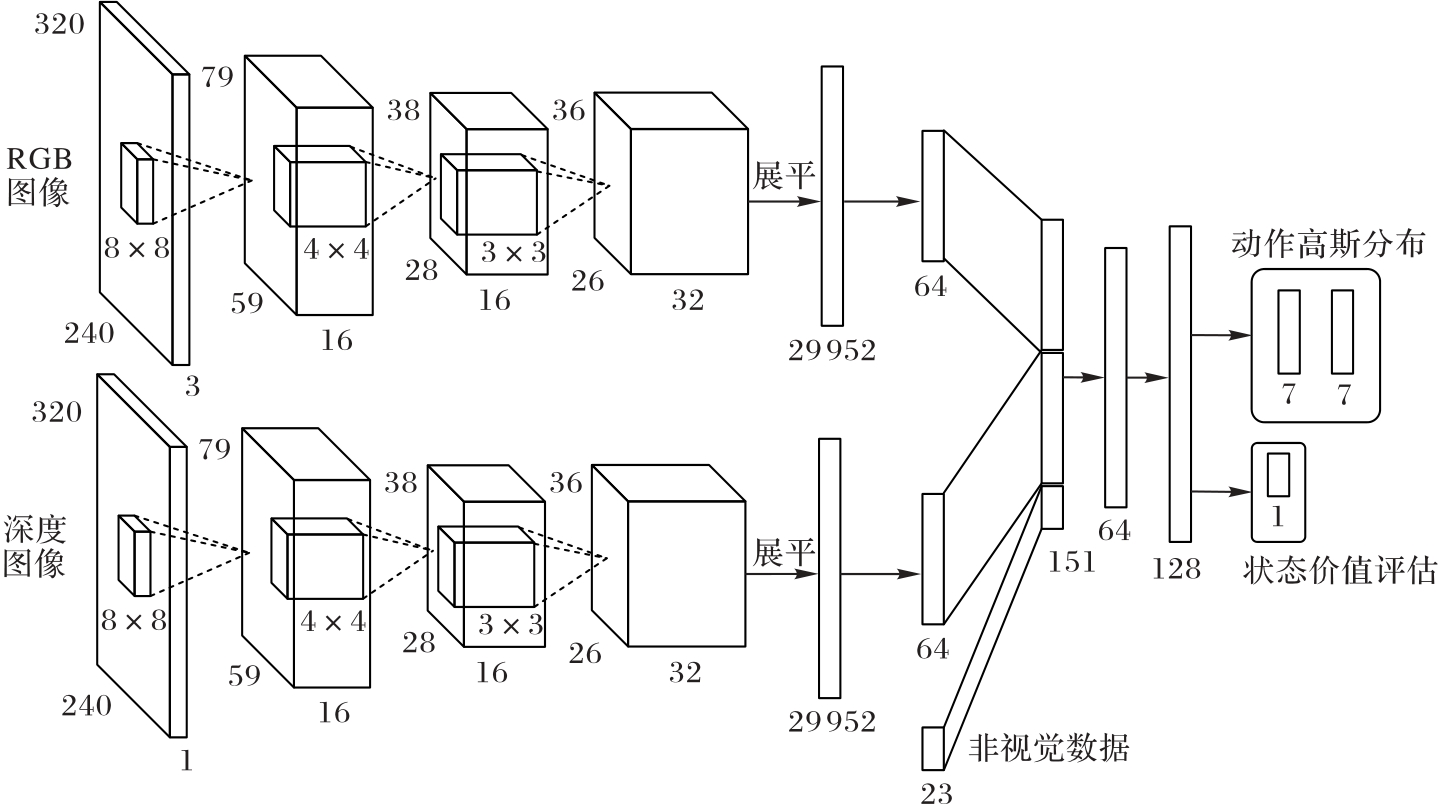
Fig. 2 Framework of multi-modal fusion network
| 层类型 | 输入通道 | 输出通道 | 卷积核 | 步长 | 激活函数 |
|---|---|---|---|---|---|
| 卷积层 | 3或1 | 16 | 8×8 | 4 | ReLU |
| 卷积层 | 16 | 16 | 4×4 | 2 | ReLU |
| 卷积层 | 16 | 32 | 3×3 | 1 | ReLU |
Tab. 1 Parameter configuration of CNN
| 层类型 | 输入通道 | 输出通道 | 卷积核 | 步长 | 激活函数 |
|---|---|---|---|---|---|
| 卷积层 | 3或1 | 16 | 8×8 | 4 | ReLU |
| 卷积层 | 16 | 16 | 4×4 | 2 | ReLU |
| 卷积层 | 16 | 32 | 3×3 | 1 | ReLU |
| 阶段 | 物体生成位置 | 物体运动模式 | 直线运动概率 | 水平速度范围/(m·s-1) | 加速度惩罚 | 动作变化惩罚 |
|---|---|---|---|---|---|---|
| 静态阶段 | 视野内 | 静止 | 0.0 | 0.00 | -0.01 | -0.001 |
| 低速阶段 | 视野外 | 直线 | 1.0 | 0.15~0.20 | -0.03 | -0.003 |
| 中速阶段 | 视野外 | 直线、正弦 | 0.8 | 0.15~0.30 | -0.10 | -0.010 |
| 高速随机 | 视野外 | 直线、正弦 | 0.5 | 0.15~0.40 | -0.30 | -0.030 |
Tab. 2 Parameter configuration of curriculum learning
| 阶段 | 物体生成位置 | 物体运动模式 | 直线运动概率 | 水平速度范围/(m·s-1) | 加速度惩罚 | 动作变化惩罚 |
|---|---|---|---|---|---|---|
| 静态阶段 | 视野内 | 静止 | 0.0 | 0.00 | -0.01 | -0.001 |
| 低速阶段 | 视野外 | 直线 | 1.0 | 0.15~0.20 | -0.03 | -0.003 |
| 中速阶段 | 视野外 | 直线、正弦 | 0.8 | 0.15~0.30 | -0.10 | -0.010 |
| 高速随机 | 视野外 | 直线、正弦 | 0.5 | 0.15~0.40 | -0.30 | -0.030 |
| 参数名称 | 随机化方法与范围 | 对物理实验性能的影响 |
|---|---|---|
| 初始关节位置 | 在默认姿态上叠加标准差为0.005的零均值高斯噪声 | 模拟物理机器人任务重置时存在的微小姿态偏差,避免策略依赖固定的初始位置 |
| 夹爪初始张合程度 | 在整个行程范围内均匀采样 | 模拟物理夹爪在连续操作中可能存在的非完全复位状态,增强策略对执行器状态不确定性的适应能力 |
| 夹爪张合速度 | 在0.1~0.5 rad/s范围内均匀采样 | 模拟物理夹爪电机性能的波动,使策略不依赖于某个特定的执行器速度 |
| 光照强度 | 在5 000~15 000 lm范围内均匀采样 | 模拟从阴影到明亮的真实光照条件,使策略学习对光照不敏感的几何与形状特征 |
| 桌面纹理 | 在包含7种不同木质纹理的预设库中随机选择1种 | 避免策略过拟合仿真环境中单一的桌面外观,提升策略在真实桌面上的泛化能力 |
| 物体颜色 | 在指定RGB空间中随机采样(R:0.7~1.0, G:0.7~1.0, B:0.0~0.2) | 针对物理实验中的网球进行颜色随机化,确保策略学习到的是物体的形状和动态特征,而非某一特定的颜色 |
Tab. 3 Parameter configuration of domain randomization
| 参数名称 | 随机化方法与范围 | 对物理实验性能的影响 |
|---|---|---|
| 初始关节位置 | 在默认姿态上叠加标准差为0.005的零均值高斯噪声 | 模拟物理机器人任务重置时存在的微小姿态偏差,避免策略依赖固定的初始位置 |
| 夹爪初始张合程度 | 在整个行程范围内均匀采样 | 模拟物理夹爪在连续操作中可能存在的非完全复位状态,增强策略对执行器状态不确定性的适应能力 |
| 夹爪张合速度 | 在0.1~0.5 rad/s范围内均匀采样 | 模拟物理夹爪电机性能的波动,使策略不依赖于某个特定的执行器速度 |
| 光照强度 | 在5 000~15 000 lm范围内均匀采样 | 模拟从阴影到明亮的真实光照条件,使策略学习对光照不敏感的几何与形状特征 |
| 桌面纹理 | 在包含7种不同木质纹理的预设库中随机选择1种 | 避免策略过拟合仿真环境中单一的桌面外观,提升策略在真实桌面上的泛化能力 |
| 物体颜色 | 在指定RGB空间中随机采样(R:0.7~1.0, G:0.7~1.0, B:0.0~0.2) | 针对物理实验中的网球进行颜色随机化,确保策略学习到的是物体的形状和动态特征,而非某一特定的颜色 |
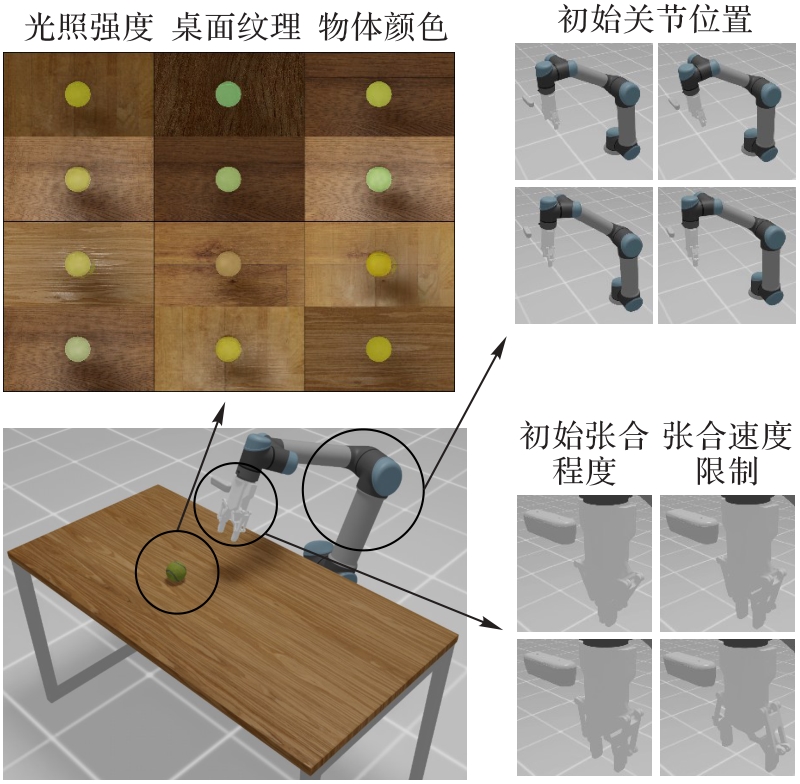
Fig. 3 Domain randomization of scenes
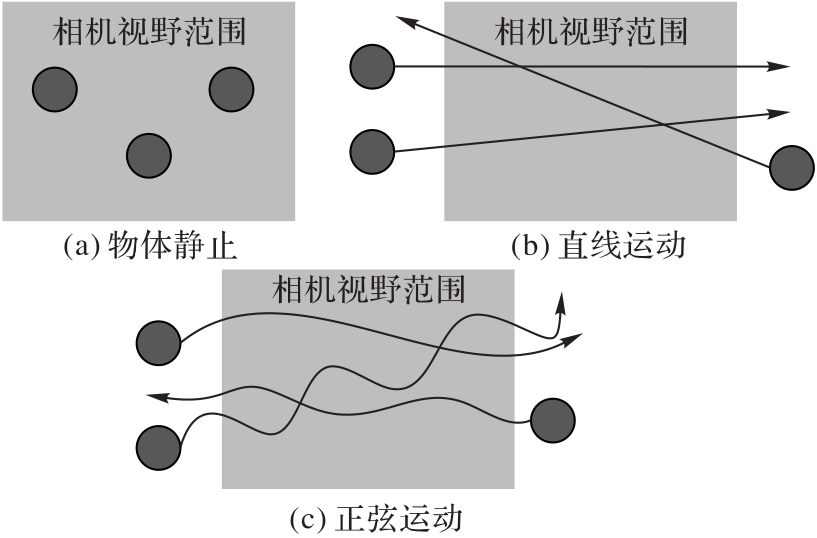
Fig. 4 Diversified object motion trajectories
| 超参数 | 值 | 超参数 | 值 |
|---|---|---|---|
| Rollouts | 16 | Ratio clip | 0.2 |
| Learning epochs | 6 | Value clip | 0.2 |
| Mini batches | 4 | Entropy loss scale | 0.01 |
| Discount factor | 0.95 | Value loss scale | 2.0 |
| Lambda | 0.95 | Kl threshold | 0.0 |
| Learning rate | 0.000 3 | Timesteps | 120 000 |
Tab. 4 Hyperparameter configuration of PPO algorithm
| 超参数 | 值 | 超参数 | 值 |
|---|---|---|---|
| Rollouts | 16 | Ratio clip | 0.2 |
| Learning epochs | 6 | Value clip | 0.2 |
| Mini batches | 4 | Entropy loss scale | 0.01 |
| Discount factor | 0.95 | Value loss scale | 2.0 |
| Lambda | 0.95 | Kl threshold | 0.0 |
| Learning rate | 0.000 3 | Timesteps | 120 000 |

Fig. 5 Grasping process keyframes in simulation environment
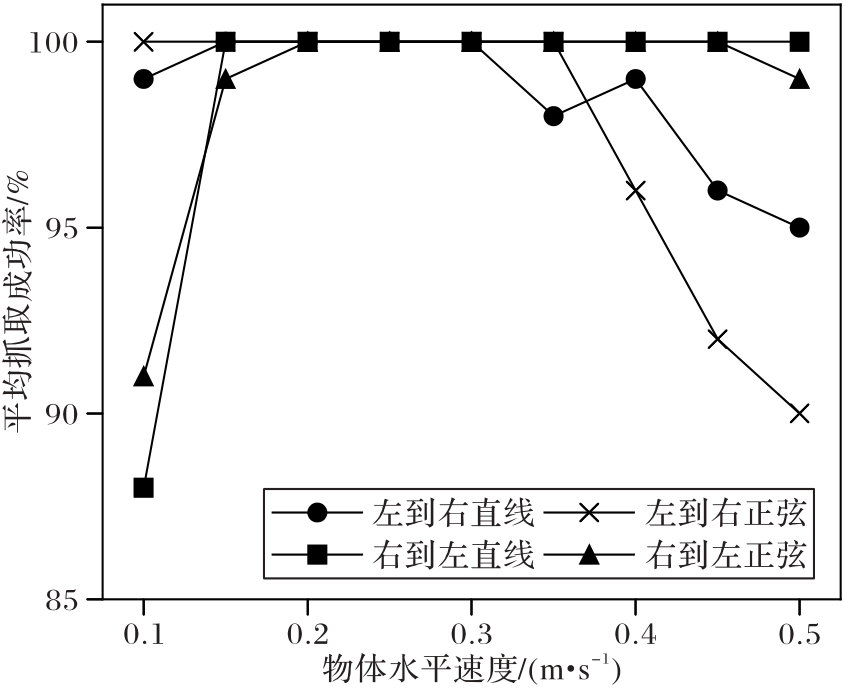
Fig. 6 Average grasping success rates at different object horizontal velocities
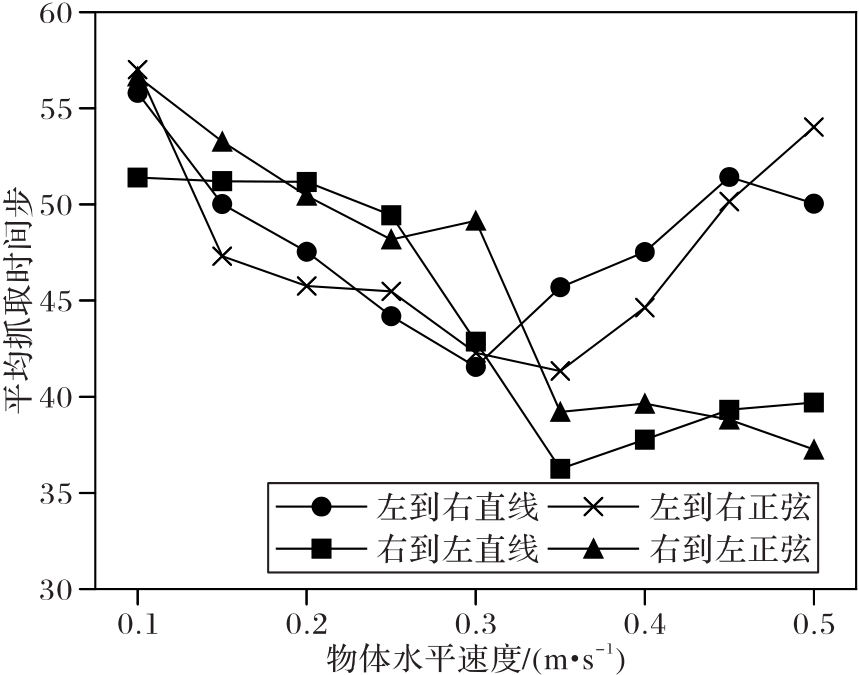
Fig. 7 Average grasping time steps at different object horizontal velocities
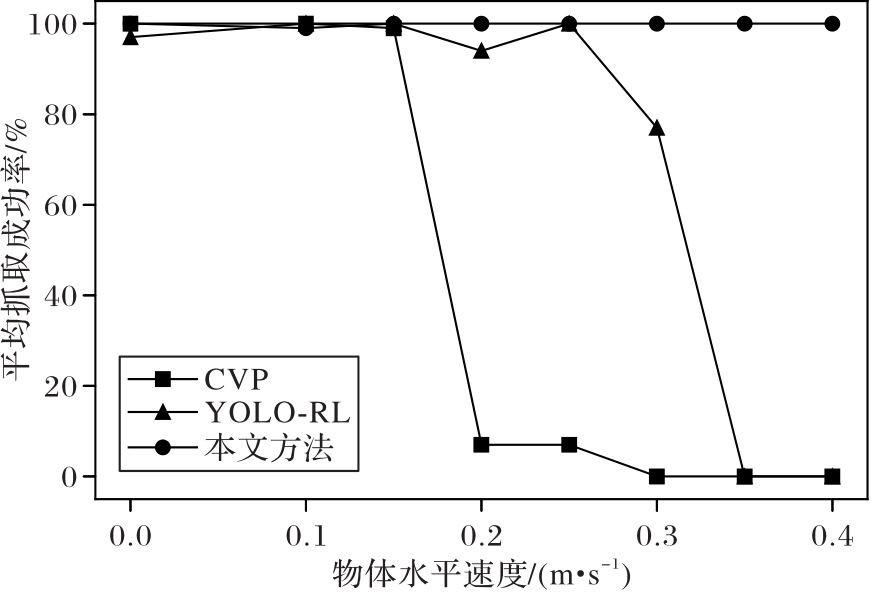
Fig. 8 Average grasping success rates of three methods at different horizontal velocities
| 方法 | 本文方法 | YOLO-RL | GAP-RL |
|---|---|---|---|
| 技术路线 | 端到端 | 模块化 | 模块化 |
| 核心思想 | 从原始像素直接学习 | 目标检测+强化学习 | 抓取位姿检测+强化学习 |
| 信息流 | RGB图像和深度图像→动作 | RGB图像→目标框→动作 | 点云→抓取位姿→动作 |
| 优点 | 响应快;无误差累积;能学习隐式特征 | 概念简单;可利用成熟的目标检测器 | 泛化性好;可利用成熟的抓取检测器 |
| 局限 | 训练初期探索难度大(本文通过课程学习缓解);模型可解释性较差 | 性能受限于检测器;信息延迟与误差累积;目标框信息不足以指导复杂抓取 | 性能受限于检测器;信息延迟与误差累积;系统复杂度高 |
Tab. 5 Comparison of proposed method and mainstream dynamic grasping methods
| 方法 | 本文方法 | YOLO-RL | GAP-RL |
|---|---|---|---|
| 技术路线 | 端到端 | 模块化 | 模块化 |
| 核心思想 | 从原始像素直接学习 | 目标检测+强化学习 | 抓取位姿检测+强化学习 |
| 信息流 | RGB图像和深度图像→动作 | RGB图像→目标框→动作 | 点云→抓取位姿→动作 |
| 优点 | 响应快;无误差累积;能学习隐式特征 | 概念简单;可利用成熟的目标检测器 | 泛化性好;可利用成熟的抓取检测器 |
| 局限 | 训练初期探索难度大(本文通过课程学习缓解);模型可解释性较差 | 性能受限于检测器;信息延迟与误差累积;目标框信息不足以指导复杂抓取 | 性能受限于检测器;信息延迟与误差累积;系统复杂度高 |
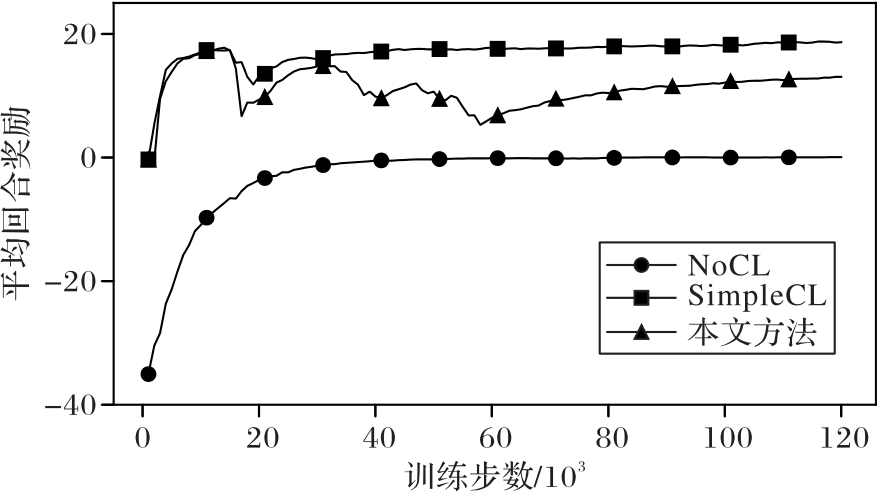
Fig. 9 Learning curves of three methods
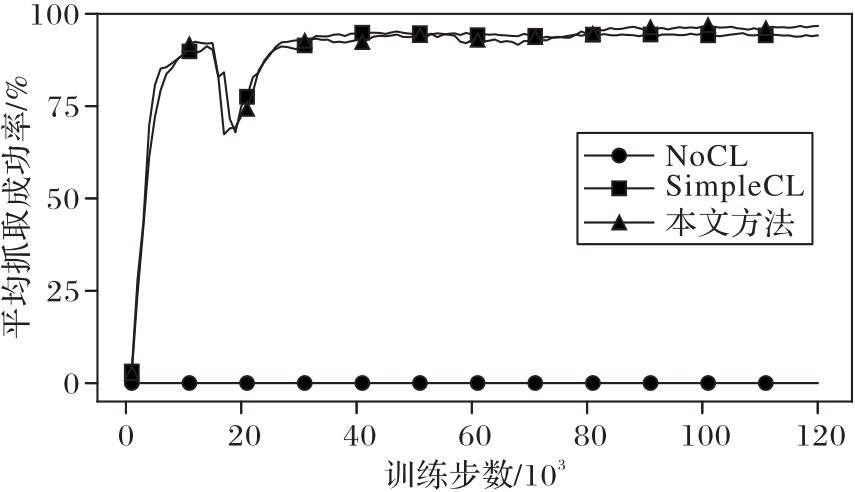
Fig. 10 Average grasping success rates of three methods during training
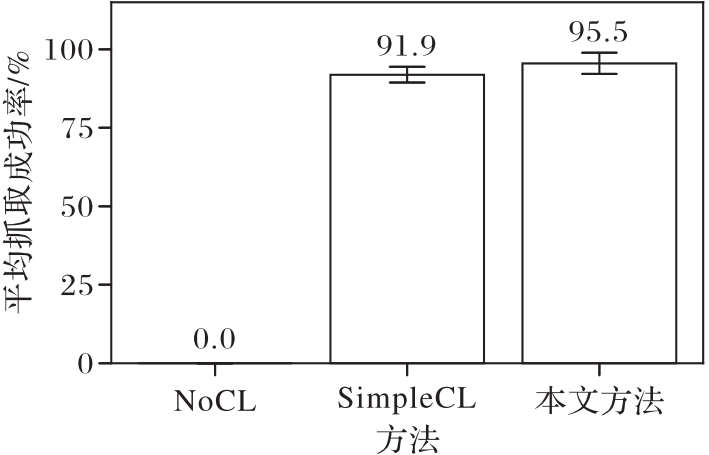
Fig. 11 Average grasping success rates of three methods during test
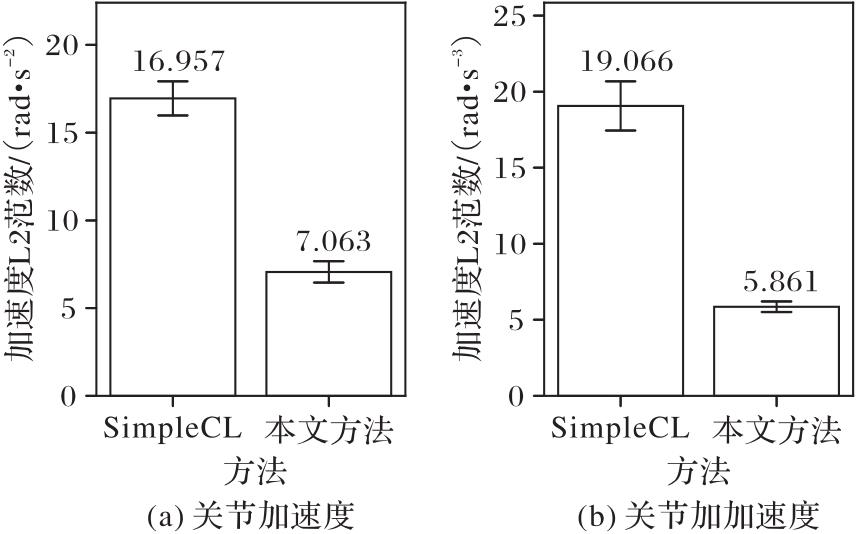
Fig. 12 Motion smoothness of two methods
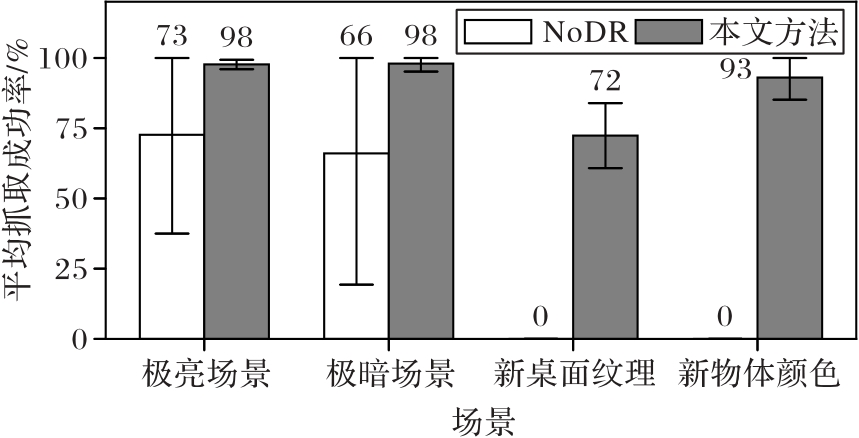
Fig. 13 Average grasping success rates of two methods under four scenes

Fig. 14 Physical experimental platform

Fig. 15 Grasping process keyframes in physical environment
| 物体运动模式 | 物体速度/(m·s-1) | 尝试次数 | 成功次数 | 成功率/% | 平均耗时/s |
|---|---|---|---|---|---|
| 总体 | — | 40 | 35 | 87.5 | 15.57 |
| 静止 | 0.00 | 20 | 19 | 95.0 | 12.45 |
| 右→左 | 约0.05 | 10 | 9 | 90.0 | 17.91 |
| 左→右 | 约0.05 | 10 | 7 | 70.0 | 20.98 |
Tab. 6 Grasping performance under different scenes
| 物体运动模式 | 物体速度/(m·s-1) | 尝试次数 | 成功次数 | 成功率/% | 平均耗时/s |
|---|---|---|---|---|---|
| 总体 | — | 40 | 35 | 87.5 | 15.57 |
| 静止 | 0.00 | 20 | 19 | 95.0 | 12.45 |
| 右→左 | 约0.05 | 10 | 9 | 90.0 | 17.91 |
| 左→右 | 约0.05 | 10 | 7 | 70.0 | 20.98 |
| [1] | Keshvarparast A, Battini D, Battaia O, et al. Collaborative robots in manufacturing and assembly systems: literature review and future research agenda [J]. Journal of Intelligent Manufacturing, 2024, 35(5): 2065-2118. |
| [2] | Duan J, Yu S, Tan H L, et al. A survey of embodied AI: from simulators to research tasks [J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2022, 6(2): 230-244. |
| [3] | Elguea-Aguinaco Í, Serrano-Muñoz A, Chrysostomou D, et al. A review on reinforcement learning for contact-rich robotic manipulation tasks [J]. Robotics and Computer-Integrated Manufacturing, 2023, 81: No.102517. |
| [4] | Xie P, Chen S, Chen Q, et al. GAP-RL: grasps as points for RL towards dynamic object grasping [J]. IEEE Robotics and Automation Letters, 2025, 10(1): 40-47. |
| [5] | Bohg J, Morales A, Asfour T, et al. Data-driven grasp synthesis — a survey [J]. IEEE Transactions on Robotics, 2014, 30(2): 289-309. |
| [6] | Asif U, Tang J, Harrer S. GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices [C]// IJCAI 2018. California: ijcai.org, 2018: 4875-4882. |
| [7] | 李淦,牛洺第,陈路,等.融合视觉特征增强机制的机器人弱光环境抓取检测[J].计算机应用, 2023, 43(8): 2564-2571. |
| Li Gan, Niu Mindi, Chen Lu, et al. Robotic grasp detection in low-light environment by incorporating visual feature enhancement mechanism [J]. Journal of Computer Applications, 2023, 43(8): 2564-2571. | |
| [8] | 陈路,王怀瑶,刘京阳,等.融合空间-傅里叶域信息的机器人低光环境抓取检测[J].计算机应用, 2025, 45(5): 1686-1693. |
| Chen Lu, Wang Huaiyao, Liu Jingyang, et al. Robotic grasp detection with feature fusion of spatial-Fourier domain information under low-light environments [J]. Journal of Computer Applications, 2025, 45(5): 1686-1693. | |
| [9] | Kalashnikov D, Irpan A, Pastor P, et al. Scalable deep reinforcement learning for vision-based robotic manipulation [C]// CoRL 2018. New York: JMLR.org, 2018: 651-673. |
| [10] | 余家宸,杨晔.基于裁剪近端策略优化算法的软机械臂不规则物体抓取[J].计算机应用, 2024, 44(11): 3629-3638. |
| Yu Jiachen, Yang Ye. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. | |
| [11] | Huang B, Yu J, Jain S. EARL: eye-on-hand reinforcement learner for dynamic grasping with active pose estimation [C]// IROS 2023. Piscataway: IEEE, 2023: 2963-2970. |
| [12] | Huang Y, Liu D, Liu Z, et al. A novel robotic grasping method for moving objects based on multi-agent deep reinforcement learning [J]. Robotics and Computer-Integrated Manufacturing, 2024, 86: No.102644. |
| [13] | Chen P, Lu W. Deep reinforcement learning based moving object grasping [J]. Information Sciences, 2021, 565: 62-76. |
| [14] | Morrison D, Corke P, Leitner J. Learning robust, real-time, reactive robotic grasping [J]. The International Journal of Robotics Research, 2020, 39(2/3): 183-201. |
| [15] | Ibarz J, Tan J, Finn C, et al. How to train your robot with deep reinforcement learning: lessons we have learned [J]. The International Journal of Robotics Research, 2021, 40(4/5): 698-721. |
| [16] | Du G, Wang K, Lian S, et al. Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: a review [J]. Artificial Intelligence Review, 2021, 54(3): 1677-1734. |
| [17] | Liu J, Zhang R, Fang H S, et al. Target-referenced reactive grasping for dynamic objects [C]// CVPR 2023. Piscataway: IEEE, 2023: 8824-8833. |
| [18] | Marturi N, Kopicki M, Rastegarpanah A, et al. Dynamic grasp and trajectory planning for moving objects [J]. Autonomous Robots, 2019, 43(5): 1241-1256. |
| [19] | 陈佳盼,郑敏华.基于深度强化学习的机器人操作行为研究综述[J].机器人, 2022, 44(2): 236-256. |
| Chen Jiapan, Zheng Minhua. A survey of robot manipulation behavior research based on deep reinforcement learning [J]. Robot, 2022, 44(2): 236-256. | |
| [20] | Wu T, Zhong F, Geng Y, et al. GraspARL: dynamic grasping via adversarial reinforcement learning [PP/OL]. V2. arXiv (2022-03-14) [2025-01-23]. . |
| [21] | Christen S, Kocabas M, Aksan E, et al. D-Grasp: physically plausible dynamic grasp synthesis for hand-object interactions [C]// CVPR 2022. Piscataway: IEEE, 2022: 20545-20554. |
| [22] | Soviany P, Ionescu R T, Rota P, et al. Curriculum learning: a survey [J]. International Journal of Computer Vision, 2022, 130(6): 1526-1565. |
| [23] | Höfer S, Bekris K, Ankur H, et al. Sim2Real in robotics and automation: applications and challenges [J]. IEEE Transactions on Automation Science and Engineering, 2021, 18(2): 398-400. |
| [24] | Song S, Zeng A, Lee J, et al. Grasping in the wild: learning 6DoF closed-loop grasping from low-cost demonstrations [J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4978-4985. |
| [25] | Zimmermann S, Poranne R, Coros S. Go fetch! — dynamic grasps using boston dynamics spot with external robotic arm [C]// ICRA 2021. Piscataway: IEEE, 2021: 4488-4494. |
| [26] | Tobin J, Fong R, Ray A, et al. Domain randomization for transferring deep neural networks from simulation to the real world [C]// IROS 2017. Piscataway: IEEE, 2017: 23-30. |
| [27] | Tobin J, Biewald L, Duan R, et al. Domain randomization and generative models for robotic grasping [C]// IROS 2018. Piscataway: IEEE, 2018: 3482-3489. |
| [28] | Muratore F, Ramos F, Turk G, et al. Robot learning from randomized simulations: a review [J]. Frontiers in Robotics and AI, 2022, 9: No.799893. |
| [29] | Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms [PP/OL]. V2. arXiv (2017-08-28) [2025-06-06]. . |
| [30] | Shakya A K, Pillai G, Chakrabarty S. Reinforcement learning algorithms: a brief survey [J]. Expert Systems with Applications, 2023, 231: No.120495. |
| [31] | Schulman J, Moritz P, Levine S, et al. High-dimensional continuous control using generalized advantage estimation [PP/OL]. V6. arXiv (2018-10-20) [2025-06-17]. . |
| [32] | Mittal M, Yu C, Yu Q, et al. Orbit: a unified simulation framework for interactive robot learning environments [J]. IEEE Robotics and Automation Letters, 2023, 8(6): 3740-3747. |
| [33] | Serrano-Muñoz A, Chrysostomou D, Bøgh S, et al. skrl: Modular and flexible library for reinforcement learning [J]. Journal of Machine Learning Research, 2023, 24: 1-9. |
| [1] | Xiayu WU, Hong ZHANG. Review of evolution and changes in crowd evacuation calculation methods [J]. Journal of Computer Applications, 2026, 46(4): 1309-1322. |
| [2] | Tianyu XUE, Aiping LI, Liguo DUAN. Vehicular edge computing scheme with task offloading and resource optimization [J]. Journal of Computer Applications, 2025, 45(6): 1766-1775. |
| [3] | Pengcheng XU, Lei HE, Chuan LI, Weiqi QIAN, Tun ZHAO. Deep symbolic regression method based on Transformer [J]. Journal of Computer Applications, 2025, 45(5): 1455-1463. |
| [4] | Huahua WANG, Liang HUANG, Jiajie CHEN, Jiening FANG. Dynamic allocation algorithm for multi-beam subcarriers of low orbit satellites based on deep reinforcement learning [J]. Journal of Computer Applications, 2025, 45(2): 571-577. |
| [5] | Jing WANG, Xuming FANG. Intelligent joint power and channel allocation algorithm for Wi-Fi7 multi-link integrated communication and sensing [J]. Journal of Computer Applications, 2025, 45(2): 563-570. |
| [6] | Xiang KUANG, Zhen MA, Wanchun ZHU, Zhi ZHANG, Yunfei CUI. Secure and reliable service function chain deployment based on encoder-decoder structured reinforcement learning [J]. Journal of Computer Applications, 2025, 45(12): 3947-3956. |
| [7] | Chengyi WANG, Lei XU, Jinyin CHEN, Hongjun QIU. Cyber anti-mapping method based on adaptive perturbation [J]. Journal of Computer Applications, 2025, 45(12): 3896-3908. |
| [8] | Xiaojuan CHEN, Wei ZHANG. Task allocation of unmanned aerial vehicle for rural last-mile delivery based on reinforcement learning [J]. Journal of Computer Applications, 2025, 45(12): 4055-4063. |
| [9] | Jun ZENG, Yinghua TONG, Defang WANG. Anomaly detection method based on cumulative probability fluctuation and automated clustering [J]. Journal of Computer Applications, 2025, 45(12): 3864-3871. |
| [10] | Haoxiang XU, Dunhui YU, Yichen DENG, Kui XIAO. Knowledge graph constrained question answering model based on hierarchical reinforcement learning [J]. Journal of Computer Applications, 2025, 45(12): 3764-3770. |
| [11] | Lin WEI, Shihao ZHANG, Mengyang HE. Workflow task optimization and energy-efficient offloading method for computing power network [J]. Journal of Computer Applications, 2025, 45(12): 3916-3924. |
| [12] | Lin WEI, Jinyang LI, Yajie WANG, Mengyang HE. Highly reliable matching method based on multi-dimensional resource measurement and rescheduling in computing power network [J]. Journal of Computer Applications, 2025, 45(11): 3632-3641. |
| [13] | Shuai ZHOU, Hao FU, Wei LIU. Spatial-temporal Transformer-based hybrid return implicit Q-learning for crowd navigation [J]. Journal of Computer Applications, 2025, 45(11): 3666-3673. |
| [14] | Yanpeng ZHANG, Yuqian ZHAO, Fan ZHANG, Tenghai QIU, Gui GUI, Lingli YU. Capacitated vehicle routing problem solving method based on improved MAML and GVAE [J]. Journal of Computer Applications, 2025, 45(11): 3642-3648. |
| [15] | Jinghua ZHAO, Zhu ZHANG, Xiting LYU, Huidan LIN. Multiscale information diffusion prediction model based on hypergraph neural network [J]. Journal of Computer Applications, 2025, 45(11): 3529-3539. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||