


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (12): 3899-3906.DOI: 10.11772/j.issn.1001-9081.2023121857
• Multimedia computing and computer simulation • Previous Articles Next Articles
Received:2024-01-05
Revised:2024-03-12
Accepted:2024-03-15
Online:2024-03-28
Published:2024-12-10
Contact:
Shanshan YAO
About author:WANG Chao, born in 1995, M. S. candidate, His research interests include voiceprint recognition.
Supported by:
王超, 姚姗姗( )
)
通讯作者:
姚姗姗
作者简介:王超(1995—),男,山西大同人,硕士研究生,主要研究方向:声纹识别;基金资助:CLC Number:
Chao WANG, Shanshan YAO. Speaker verification method based on speech quality adaptation and triplet-like idea[J]. Journal of Computer Applications, 2024, 44(12): 3899-3906.
王超, 姚姗姗. 基于语音质量自适应和类三元组思想的说话人确认方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3899-3906.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121857
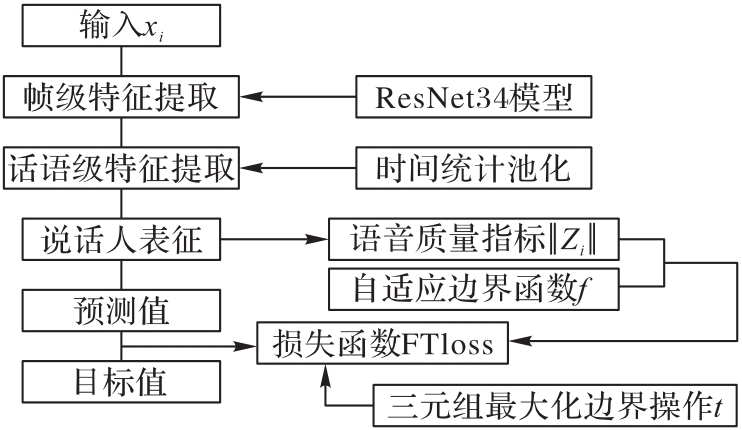
Fig.1 Overall framework of QATM
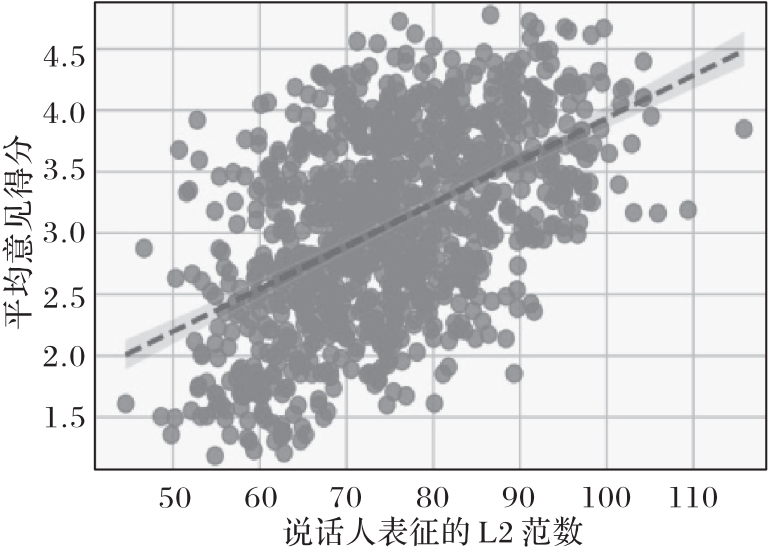
Fig. 2 Relationship between L2 norm of speaker embedding and mean opinion score
| 数据集 | 说话人数 | 音频数 | 验证对数 |
|---|---|---|---|
| VoxCeleb2-dev | 5 944 | 1 092 009 | — |
| VoxCeleb1-dev | 1 211 | 148 642 | — |
| VoxCeleb1-O | 40 | 4 708 | 37 611 |
| VoxCeleb1-E | 1 251 | 145 160 | 579 818 |
| VoxCeleb1-H | 1 190 | 137 924 | 550 894 |
| Cn-Celeb.Train | 2 800 | 632 740 | — |
| Cn-Celeb.Eval | 200 | 26 854 | 3 482 293 |
Tab. 1 VoxCeleb and Cn-Celeb: training set and evaluation set
| 数据集 | 说话人数 | 音频数 | 验证对数 |
|---|---|---|---|
| VoxCeleb2-dev | 5 944 | 1 092 009 | — |
| VoxCeleb1-dev | 1 211 | 148 642 | — |
| VoxCeleb1-O | 40 | 4 708 | 37 611 |
| VoxCeleb1-E | 1 251 | 145 160 | 579 818 |
| VoxCeleb1-H | 1 190 | 137 924 | 550 894 |
| Cn-Celeb.Train | 2 800 | 632 740 | — |
| Cn-Celeb.Eval | 200 | 26 854 | 3 482 293 |
| 数据集 | 语言 | 场景 类型数 | 媒体源数 | 说话人数 | 语音 条数 | 语音 时长/h | 多场景 说话人数 |
|---|---|---|---|---|---|---|---|
| Cn-Celeb1 | 中文 | 11 | 1 | 1 000 | 130 109 | 274 | 745 |
| Cn-Celeb2 | 中文 | 11 | 5 | 2 000 | 529 485 | 1 090 | 658 |
Tab. 2 Basic information of Cn-Celeb1 and Cn-Celeb2
| 数据集 | 语言 | 场景 类型数 | 媒体源数 | 说话人数 | 语音 条数 | 语音 时长/h | 多场景 说话人数 |
|---|---|---|---|---|---|---|---|
| Cn-Celeb1 | 中文 | 11 | 1 | 1 000 | 130 109 | 274 | 745 |
| Cn-Celeb2 | 中文 | 11 | 5 | 2 000 | 529 485 | 1 090 | 658 |
| 层 | 结构 | 特征图输出尺寸 |
|---|---|---|
| 输入 | — | 1 |
| 阶段1 | {ResBlock,32,1} | 32 |
| 阶段2 | {ResBlock,64,1} | 64 |
| 阶段3 | {ResBlock,128,1} | 128 |
| 阶段4 | {ResBlock,256,1} | 256 |
| 特征聚合 | 时间统计池化 | 64F |
| 输出头 | 256 |
Tab.3 Half-ResNet34 structure
| 层 | 结构 | 特征图输出尺寸 |
|---|---|---|
| 输入 | — | 1 |
| 阶段1 | {ResBlock,32,1} | 32 |
| 阶段2 | {ResBlock,64,1} | 64 |
| 阶段3 | {ResBlock,128,1} | 128 |
| 阶段4 | {ResBlock,256,1} | 256 |
| 特征聚合 | 时间统计池化 | 64F |
| 输出头 | 256 |
| 网络结构 | 损失函数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | SITW.Eval.Core | Cn-Celeb.eval | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | ||
| Half-ResNet34+TSP | AAM-Softmax | 1.56 | 0.179 | 2.55 | 0.237 | 1.54 | 0.170 | 3.18 | 0.278 | 12.25 | 0.693 |
| FTloss | 1.46 | 0.125 | 2.47 | 0.232 | 1.50 | 0.163 | 3.00 | 0.270 | 12.21 | 0.654 | |
| ResNet34+ASP | AAM-Softmax | 1.03 | 0.128 | 2.18 | 0.234 | 1.12 | 0.136 | 2.59 | 0.434 | 10.23 | 0.553 |
| FTloss | 0.99 | 0.120 | 2.14 | 0.224 | 1.11 | 0.134 | 2.54 | 0.436 | 10.17 | 0.551 | |
| ECAPA-TDNN+ASP | AAM-Softmax | 1.10 | 0.158 | 2.44 | 0.260 | 1.29 | 0.156 | 2.82 | 0.493 | 10.29 | 0.558 |
| FTloss | 1.02 | 0.124 | 2.42 | 0.257 | 1.26 | 0.145 | 2.73 | 0.487 | 10.24 | 0.552 | |
Tab.4 Results on VoxCeleb2 dataset
| 网络结构 | 损失函数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | SITW.Eval.Core | Cn-Celeb.eval | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | ||
| Half-ResNet34+TSP | AAM-Softmax | 1.56 | 0.179 | 2.55 | 0.237 | 1.54 | 0.170 | 3.18 | 0.278 | 12.25 | 0.693 |
| FTloss | 1.46 | 0.125 | 2.47 | 0.232 | 1.50 | 0.163 | 3.00 | 0.270 | 12.21 | 0.654 | |
| ResNet34+ASP | AAM-Softmax | 1.03 | 0.128 | 2.18 | 0.234 | 1.12 | 0.136 | 2.59 | 0.434 | 10.23 | 0.553 |
| FTloss | 0.99 | 0.120 | 2.14 | 0.224 | 1.11 | 0.134 | 2.54 | 0.436 | 10.17 | 0.551 | |
| ECAPA-TDNN+ASP | AAM-Softmax | 1.10 | 0.158 | 2.44 | 0.260 | 1.29 | 0.156 | 2.82 | 0.493 | 10.29 | 0.558 |
| FTloss | 1.02 | 0.124 | 2.42 | 0.257 | 1.26 | 0.145 | 2.73 | 0.487 | 10.24 | 0.552 | |
| 超参数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | SITW.Dev.Core | SITW.Eval.Core | Cn-Celeb.eval | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | |
| m=0.20,s=30 | 1.75 | 0.188 | 2.87 | 0.255 | 1.76 | 0.190 | 3.42 | 0.249 | 3.253 | 0.282 | 12.24 | 0.691 |
| m=0.30,s=30 | 1.46 | 0.125 | 2.47 | 0.232 | 1.50 | 0.163 | 2.92 | 0.222 | 2.952 | 0.253 | 12.21 | 0.654 |
| m=0.40,s=30 | 1.59 | 0.145 | 2.64 | 0.242 | 1.60 | 0.172 | 2.61 | 0.221 | 2.835 | 0.246 | 12.19 | 0.620 |
Tab.5 Experimental results of parameters on VoxCeleb2 dataset
| 超参数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | SITW.Dev.Core | SITW.Eval.Core | Cn-Celeb.eval | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | EER | minDCF | |
| m=0.20,s=30 | 1.75 | 0.188 | 2.87 | 0.255 | 1.76 | 0.190 | 3.42 | 0.249 | 3.253 | 0.282 | 12.24 | 0.691 |
| m=0.30,s=30 | 1.46 | 0.125 | 2.47 | 0.232 | 1.50 | 0.163 | 2.92 | 0.222 | 2.952 | 0.253 | 12.21 | 0.654 |
| m=0.40,s=30 | 1.59 | 0.145 | 2.64 | 0.242 | 1.60 | 0.172 | 2.61 | 0.221 | 2.835 | 0.246 | 12.19 | 0.620 |
| 超参数 | Cn-Celeb.eval | |
|---|---|---|
| EER | minDCF | |
| m=0.10,s=30 | 10.11 | 0.556 |
| m=0.15,s=30 | 10.37 | 0.546 |
| m=0.20,s=30 | 10.27 | 0.554 |
| m=0.25,s=30 | 10.97 | 0.561 |
| m=0.30,s=30 | 11.78 | 0.568 |
Tab.6 Experimental results of parameters on Cn-Celeb dataset
| 超参数 | Cn-Celeb.eval | |
|---|---|---|
| EER | minDCF | |
| m=0.10,s=30 | 10.11 | 0.556 |
| m=0.15,s=30 | 10.37 | 0.546 |
| m=0.20,s=30 | 10.27 | 0.554 |
| m=0.25,s=30 | 10.97 | 0.561 |
| m=0.30,s=30 | 11.78 | 0.568 |
| 损失函数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | |||
|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | |
| AM-Softmax | 1.63 | 0.177 | 2.86 | 0.267 | 1.68 | 0.189 |
| TAM-Softmax | 1.53 | 0.142 | 2.48 | 0.231 | 1.51 | 0.163 |
| AAM-Softmax | 1.61 | 0.174 | 2.82 | 0.258 | 1.63 | 0.183 |
| TAAM-Softmax | 1.53 | 0.161 | 2.58 | 0.243 | 1.58 | 0.174 |
| Adaptive Margin | 1.58 | 0.145 | 2.51 | 0.231 | 1.52 | 0.166 |
| Adaptive Margin-A | 1.56 | 0.168 | 2.49 | 0.238 | 1.54 | 0.165 |
| Adaptive Margin-B | 1.52 | 0.165 | 2.49 | 0.236 | 1.49 | 0.173 |
| FTloss | 1.46 | 0.126 | 2.47 | 0.233 | 1.50 | 0.163 |
Tab.7 Results of ablation experiments
| 损失函数 | VoxCeleb1-O | VoxCeleb1-H | VoxCeleb1-E | |||
|---|---|---|---|---|---|---|
| EER | minDCF | EER | minDCF | EER | minDCF | |
| AM-Softmax | 1.63 | 0.177 | 2.86 | 0.267 | 1.68 | 0.189 |
| TAM-Softmax | 1.53 | 0.142 | 2.48 | 0.231 | 1.51 | 0.163 |
| AAM-Softmax | 1.61 | 0.174 | 2.82 | 0.258 | 1.63 | 0.183 |
| TAAM-Softmax | 1.53 | 0.161 | 2.58 | 0.243 | 1.58 | 0.174 |
| Adaptive Margin | 1.58 | 0.145 | 2.51 | 0.231 | 1.52 | 0.166 |
| Adaptive Margin-A | 1.56 | 0.168 | 2.49 | 0.238 | 1.54 | 0.165 |
| Adaptive Margin-B | 1.52 | 0.165 | 2.49 | 0.236 | 1.49 | 0.173 |
| FTloss | 1.46 | 0.126 | 2.47 | 0.233 | 1.50 | 0.163 |
| 损失函数 | Cn-Celeb.eval | |
|---|---|---|
| EER | minDCF | |
| AM-Softmax | 10.50 | 0.545 |
| AAM-Softmax | 10.67 | 0.552 |
| FTloss | 10.11 | 0.556 |
Tab.8 Results on Cn-Celeb dataset
| 损失函数 | Cn-Celeb.eval | |
|---|---|---|
| EER | minDCF | |
| AM-Softmax | 10.50 | 0.545 |
| AAM-Softmax | 10.67 | 0.552 |
| FTloss | 10.11 | 0.556 |
| 损失函数 | 信噪比/dB | EER | minDCF |
|---|---|---|---|
| AAM-Softmax | 10 | 13.04 | 0.967 |
| 20 | 9.76 | 0.807 | |
| 30 | 7.63 | 0.652 | |
| 40 | 7.42 | 0.637 | |
| FTloss | 10 | 12.13 | 0.880 |
| 20 | 9.11 | 0.715 | |
| 30 | 7.42 | 0.633 | |
| 40 | 7.32 | 0.630 |
Tab.9 Experimental results on VoxCeleb1 dataset with different noise ratios
| 损失函数 | 信噪比/dB | EER | minDCF |
|---|---|---|---|
| AAM-Softmax | 10 | 13.04 | 0.967 |
| 20 | 9.76 | 0.807 | |
| 30 | 7.63 | 0.652 | |
| 40 | 7.42 | 0.637 | |
| FTloss | 10 | 12.13 | 0.880 |
| 20 | 9.11 | 0.715 | |
| 30 | 7.42 | 0.633 | |
| 40 | 7.32 | 0.630 |
| 1 | McLAUGHLIN J, REYNOLDS D A, GLEASON T. A study of computation speed-ups of the GMM-UBM speaker recognition system[C]// Proceedings of the 6th European Conference on Speech Communication and Technology. [S.l.]: International Speech Communication Association, 1999: 1215-1218. |
| 2 | 何亮,杨毅,刘加. 基于TLS-NAP的文本无关说话人识别算法[J]. 模式识别与人工智能, 2012, 25(6):916-921. |
| HE L, YANG Y, LIU J. TLS-NAP algorithm for text-independent speaker recognition[J]. Pattern Recognition and Artificial Intelligence, 2012, 25(6):916-921. | |
| 3 | WANG Q, MUCKENHIRN H, WILSON K, et al. VoiceFilter: targeted voice separation by speaker-conditioned spectrogram masking[EB/OL]. [2018-10-11].. |
| 4 | ŽMOLÍKOVÁ K, DELCROIX M, KINOSHITA K, et al. Speaker-aware neural network based beamformer for speaker extraction in speech mixtures [C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 2655-2659. |
| 5 | SNYDER D, GARCIA-ROZEMO D, SELL G, et al. X-vectors: robust DNN embeddings for speaker recognition [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5329-5333. |
| 6 | ZHOU D, WANG L, LEE K A, et al. Dynamic margin softmax loss for speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3800-3804. |
| 7 | VAŇKOVÁ J, SKSRNITZL R. Within- and between-speaker variability of parameters expressing short-term voice quality[C]// Proceedings of the Speech Prosody 2014. [S.l.]: International Speech Communication Association, 2014: 1081-1085. |
| 8 | KREIMAN J, PARK S J, KEATING P A, et al. The relationship between acoustic and perceived intraspeaker variability in voice quality [C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 2357-2360. |
| 9 | LIU Q, ZHANG X, LIANG X, et al. AWLloss: speaker verification based on the quality and difficulty of speech [J]. IEEE Signal Processing Letters, 2023, 30:1337-1341. |
| 10 | HAJIBABAEI M, DAI D. Unified hypersphere embedding for speaker recognition [EB/OL]. [2023-07-22].. |
| 11 | WANG F, CHENG J, LIU W, et al. Additive margin softmax for face verification[J]. IEEE Signal Processing Letters, 2018, 25(7): 926-930. |
| 12 | XIANG X, WANG S, HUANG H, et al. Margin matters: towards more discriminative deep neural network embeddings for speaker recognition [C]// Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2019: 1652-1656. |
| 13 | ZHOU T, ZHAO Y, WU J. ResNeXt and Res2Net structures for speaker verification[C]// Proceedings of the 2021 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2021: 301-307. |
| 14 | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3830-3834. |
| 15 | ZHANG Y, LV Z, WU H, et al. MFA-Conformer: multi-scale feature aggregation Conformer for automatic speaker verification[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 306-310. |
| 16 | SUN M, SONG Z, JIANG X, et al. Learning pooling for convolutional neural network[J]. Neurocomputing, 2017, 224: 96-104. |
| 17 | OKABE K, KOSHINAKA T, SHINODA K. Attentive statistics pooling for deep speaker embedding[C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 2252-2256. |
| 18 | ZHANG Z, SABUNCU M R. Generalized cross entropy loss for training deep neural networks with noisy labels [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 8792-8802. |
| 19 | LI Y, GAO F, QU Z, et al. Angular softmax loss for end-to-end speaker verification[C]// Proceedings of the 11th International Symposium on Chinese Spoken Language Processing. Piscataway: IEEE, 2018: 190-194. |
| 20 | LI L, WANG D, XING C, et al. Max-margin metric learning for speaker recognition[C]// Proceedings of the 10th International Symposium on Chinese Spoken Language Processing. Piscataway: IEEE, 2016: 1-4. |
| 21 | BREDIN H. TristouNet: triplet loss for speaker turn embedding[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 5430-5434. |
| 22 | RYBICKA M, KOWALCZYK K. On parameter adaptation in softmax-based cross-entropy loss for improved convergence speed and accuracy in DNN-based speaker recognition [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3805-3809. |
| 23 | LI L, NAI R, WANG D. Real additive margin softmax for speaker verification[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7527-7531. |
| 24 | KIM M, JAIN A K, LIU X. AdaFace: quality adaptive margin for face recognition[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18729-18738. |
| 25 | REED S, LEE H, ANGUELOV D, et al. Training deep neural networks on noisy labels with bootstrapping [EB/OL]. [2015-05-27]. . |
| 26 | LEE K H, HE X, ZHANG L, et al. CleanNet: transfer learning for scalable image classifier training with label noise[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5447-5456. |
| 27 | WANG X, KAPANIPATHI P, MUSA R, et al. Improving natural language inference using external knowledge in the science questions domain [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 7208-7215. |
| 28 | ZHONG P, GONG Z, LI S, et al. Learning to diversify deep belief networks for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(6): 3516-3530. |
| 29 | KIM Y, YUN J, SHON H, et al. Joint negative and positive learning for noisy labels [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9437-9446. |
| 30 | GUPTA N, PATEL H, AFZAL S, et al. Data Quality Toolkit: automatic assessment of data quality and remediation for machine learning datasets [EB/OL]. [2023-11-05].. |
| 31 | ZEINALI H, WANG S, SILNOVA A, et al. BUT system description to VoxCeleb speaker recognition challenge 2019[EB/OL]. [2013-10-16].. |
| 32 | CORTES C, VAPNIK V. Support-vector networks [J]. Machine Learning, 1995, 20(3):273-297. |
| 33 | NAGRANI A, CHUNG J S, XIE W, et al. VoxCeleb: large scale speaker verification in the wild[J]. Computer Speech and Language, 2020, 60: No.101027. |
| 34 | McLAREN M, FERRER L, CASTAN D, et al. The Speakers In The Wild (SITW) speaker recognition database [C]// Proceedings of the INTERSPEECH 2016. [S.l.]: International Speech Communication Association, 2016: 818-822. |
| 35 | LI L, LIU R, KANG J, et al. CN-Celeb: multi-genre speaker recognition [J]. Speech Communication, 2022, 137: 77-91. |
| 36 | DODDINGTON G R, PRZYBOCKI M A, MARTIN A F, et al. The NIST speaker recognition evaluation — overview, methodology, systems, results, perspective [J]. Speech Communication, 2000, 31(2/3): 225-254. |
| [1] | Xuan CAO, Tianjian LUO. Dynamic multi-domain adversarial learning method for cross-subject motor imagery EEG signals [J]. Journal of Computer Applications, 2024, 44(2): 645-653. |
| [2] | Yusheng LIU, Xuezhong XIAO. High-fidelity image editing based on fine-tuning of diffusion model [J]. Journal of Computer Applications, 2024, 44(11): 3574-3580. |
| [3] | Yang WANG, Hongliang FU, Huawei TAO, Jing YANG, Yue XIE, Li ZHAO. Cross-corpus speech emotion recognition based on decision boundary optimized domain adaptation [J]. Journal of Computer Applications, 2023, 43(2): 374-379. |
| [4] | Yuntao ZHAO, Wanqi XIE, Weigang LI, Jiaming HU. Robot hand-eye calibration algorithm based on covariance matrix adaptation evolutionary strategy [J]. Journal of Computer Applications, 2023, 43(10): 3225-3229. |
| [5] | Jian ZHANG, Peiyuan CHENG, Siyu SHAO. Rotary machine fault diagnosis based on improved residual convolutional auto-encoding network and class adaptation [J]. Journal of Computer Applications, 2022, 42(8): 2440-2449. |
| [6] | Daili CHEN, Guoliang XU. Cross-domain person re-identification method based on attention mechanism with learning intra-domain variance [J]. Journal of Computer Applications, 2022, 42(5): 1391-1397. |
| [7] | CAI Ruiguang, ZHANG Desheng, XIAO Yanting. Parameter independent weighted local mean-based pseudo nearest neighbor classification algorithm [J]. Journal of Computer Applications, 2021, 41(6): 1694-1700. |
| [8] | Xiaolong LIU, Shitong WANG. Open set fuzzy domain adaptation algorithm via progressive separation [J]. Journal of Computer Applications, 2021, 41(11): 3127-3131. |
| [9] | HUANG Xueyu, XU Haote, TAO Jianwen. Multi-source adaptation classification framework with feature selection [J]. Journal of Computer Applications, 2020, 40(9): 2499-2506. |
| [10] | YUAN Yuan, WU Wen, WAN Yi. Single image shadow detection method based on entropy driven domain adaptive learning [J]. Journal of Computer Applications, 2020, 40(7): 2131-2136. |
| [11] | XIAO He, LIU Zhiqin, WANG Qingfeng, HUANG Jun, ZHOU Ying, LIU Qiyu, XU Weiyun. Mass and calcification classification method in mammogram based on multi-view transfer learning [J]. Journal of Computer Applications, 2020, 40(5): 1460-1464. |
| [12] | LUO Chiwei, QU Tao, DENG Dexiang. Rate adaption algorithm for embedded multi-channel wireless video transmission [J]. Journal of Computer Applications, 2020, 40(4): 1119-1126. |
| [13] | ZHENG Zongsheng, HU Chenyu, JIANG Xiaoyi. Deep transfer adaptation network based on improved maximum mean discrepancy algorithm [J]. Journal of Computer Applications, 2020, 40(11): 3107-3112. |
| [14] | TU Daxi, JIANG Yuhao, XU Cheng, YU Linchen. Dynamic adaptive step-wise bitrate switching algorithm for HTTP streaming [J]. Journal of Computer Applications, 2019, 39(4): 1127-1132. |
| [15] | YANG Zhen, WANG Hongjun. Location prediction method of mobile user based on Adaboost-Markov model [J]. Journal of Computer Applications, 2019, 39(3): 675-680. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||