


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (2): 386-394.DOI: 10.11772/j.issn.1001-9081.2025030275
• Artificial intelligence • Previous Articles
Yixin LIU1, Xianggen LIU1, Wen LIU2, Hongbo DENG2, Ziye ZHANG1, Hua MU3( )
)
Received:2025-03-17
Revised:2025-06-02
Accepted:2025-06-04
Online:2025-08-06
Published:2026-02-10
Contact:
Hua MU
About author:LIU Yixin, born in 1999, M. S. candidate. Her research interests include natural language processing, artificial intelligence.Supported by:
刘宜欣1, 刘祥根1, 刘文2, 邓洪波2, 张子野1, 穆骅3()
通讯作者:
穆骅
作者简介:刘宜欣(1999—),女,四川德阳人,硕士研究生,主要研究方向:自然语言处理、人工智能基金资助:CLC Number:
Yixin LIU, Xianggen LIU, Wen LIU, Hongbo DENG, Ziye ZHANG, Hua MU. Benchmark dataset for retrieval-augmented generation on long documents[J]. Journal of Computer Applications, 2026, 46(2): 386-394.
刘宜欣, 刘祥根, 刘文, 邓洪波, 张子野, 穆骅. 面向长文档检索增强生成的基准数据集[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 386-394.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025030275
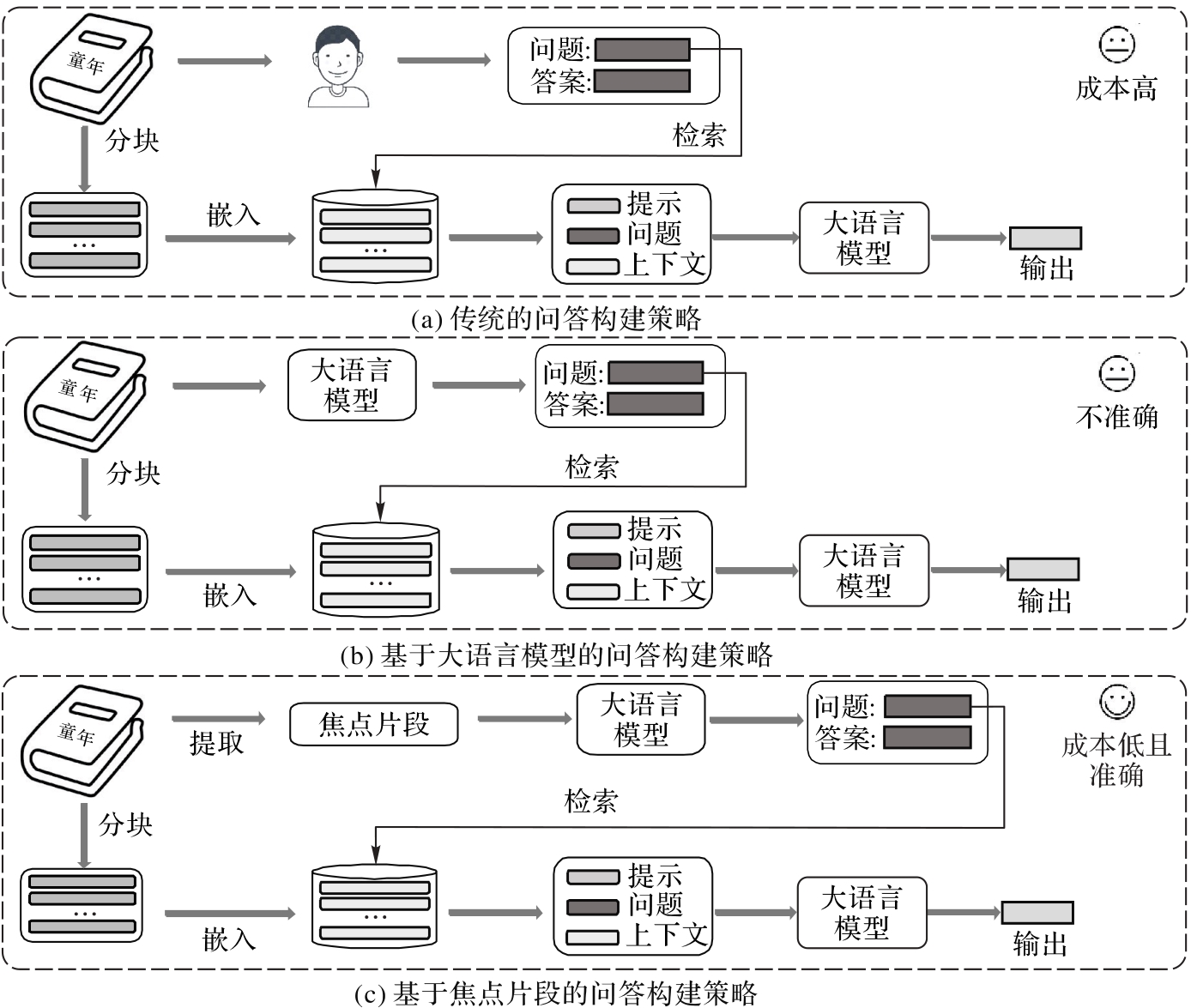
Fig. 1 Illustration of different question-answering construction strategies
| 知识库 | 词元数 | ||
|---|---|---|---|
| 最小 | 最大 | 平均 | |
| 法律-英文 | 12 000 | 123 000 | 25 000 |
| 金融-英文 | 3 000 | 92 000 | 43 000 |
| 文学-英文 | 6 000 | 524 000 | 100 000 |
| 法律-中文 | 18 000 | 102 000 | 34 000 |
| 金融-中文 | 12 000 | 26 000 | 19 000 |
| 文学-中文 | 23 000 | 933 000 | 197 000 |
Tab. 1 Statistics of number of tokens in knowledge base
| 知识库 | 词元数 | ||
|---|---|---|---|
| 最小 | 最大 | 平均 | |
| 法律-英文 | 12 000 | 123 000 | 25 000 |
| 金融-英文 | 3 000 | 92 000 | 43 000 |
| 文学-英文 | 6 000 | 524 000 | 100 000 |
| 法律-中文 | 18 000 | 102 000 | 34 000 |
| 金融-中文 | 12 000 | 26 000 | 19 000 |
| 文学-中文 | 23 000 | 933 000 | 197 000 |

Fig. 2 Automatic question-answering construction strategy based on focused segments
| 数据集 | 文档数 | 问答对实例数 | 数据集 | 文档数 | 问答对实例数 |
|---|---|---|---|---|---|
| 法律-英文 | 112 | 2 299 | 法律-中文 | 125 | 1 598 |
| 金融-英文 | 55 | 593 | 金融-中文 | 95 | 1 338 |
| 文学-英文 | 103 | 1 815 | 文学-中文 | 88 | 1 864 |
| 核心-英文 | 200 | 200 | 核心-中文 | 263 | 263 |
Tab. 2 Statistics of question-answering pair instances
| 数据集 | 文档数 | 问答对实例数 | 数据集 | 文档数 | 问答对实例数 |
|---|---|---|---|---|---|
| 法律-英文 | 112 | 2 299 | 法律-中文 | 125 | 1 598 |
| 金融-英文 | 55 | 593 | 金融-中文 | 95 | 1 338 |
| 文学-英文 | 103 | 1 815 | 文学-中文 | 88 | 1 864 |
| 核心-英文 | 200 | 200 | 核心-中文 | 263 | 263 |
| 数据集 | 嵌入模型 | 无重排序模型 | 有重排序模型 bge-reranker-v2-m3 | ||
|---|---|---|---|---|---|
| MRR@10 | MAP@10 | MRR@10 | MAP@10 | ||
| 核心-英文 | bge-large-en-v1.5 | 0.458 | 0.518 | 0.547 | 0.672 |
| text-embedding-ada-002 | 0.521 | 0.606 | 0.602 | 0.741 | |
| Multilingual-E5-large-instruct | 0.509 | 0.551 | 0.564 | 0.662 | |
| bge-m3 | 0.537 | 0.615 | 0.595 | 0.190 | |
| 核心-中文 | bge-large-zh-v1.5 | 0.452 | 0.518 | 0.549 | 0.676 |
| text-embedding-ada-002 | 0.515 | 0.584 | 0.597 | 0.730 | |
| Multilingual-E5-large-instruct | 0.508 | 0.545 | 0.566 | 0.667 | |
| bge-m3 | 0.539 | 0.614 | 0.584 | 0.701 | |
Tab. 3 Results of different embedding models on MRR@K and MAP@K indicators
| 数据集 | 嵌入模型 | 无重排序模型 | 有重排序模型 bge-reranker-v2-m3 | ||
|---|---|---|---|---|---|
| MRR@10 | MAP@10 | MRR@10 | MAP@10 | ||
| 核心-英文 | bge-large-en-v1.5 | 0.458 | 0.518 | 0.547 | 0.672 |
| text-embedding-ada-002 | 0.521 | 0.606 | 0.602 | 0.741 | |
| Multilingual-E5-large-instruct | 0.509 | 0.551 | 0.564 | 0.662 | |
| bge-m3 | 0.537 | 0.615 | 0.595 | 0.190 | |
| 核心-中文 | bge-large-zh-v1.5 | 0.452 | 0.518 | 0.549 | 0.676 |
| text-embedding-ada-002 | 0.515 | 0.584 | 0.597 | 0.730 | |
| Multilingual-E5-large-instruct | 0.508 | 0.545 | 0.566 | 0.667 | |
| bge-m3 | 0.539 | 0.614 | 0.584 | 0.701 | |
| 数据集 | 嵌入模型 | 无重排序模型 | 有重排序模型 bge-reranker-v2-m3 | ||||
|---|---|---|---|---|---|---|---|
| Hits@1 | Hits@3 | Hits@10 | Hits@1 | Hits@3 | Hits@10 | ||
| 核心-英文 | bge-large-en-v1.5 | 0.378 | 0.463 | 0.625 | 0.503 | 0.585 | 0.628 |
| text-embedding-ada-002 | 0.418 | 0.501 | 0.719 | 0.530 | 0.651 | 0.731 | |
| Multilingual-E5-large-instruct | 0.415 | 0.564 | 0.663 | 0.506 | 0.617 | 0.669 | |
| bge-m3 | 0.422 | 0.597 | 0.689 | 0.531 | 0.648 | 0.690 | |
| 核心-中文 | bge-large-zh-v1.5 | 0.366 | 0.463 | 0.619 | 0.468 | 0.584 | 0.635 |
| text-embedding-ada-002 | 0.401 | 0.478 | 0.712 | 0.545 | 0.656 | 0.729 | |
| Multilingual-E5-large-instruct | 0.409 | 0.556 | 0.657 | 0.495 | 0.608 | 0.657 | |
| bge-m3 | 0.427 | 0.613 | 0.686 | 0.533 | 0.656 | 0.686 | |
Tab. 4 Results of different embedding models on Hits@K indicators
| 数据集 | 嵌入模型 | 无重排序模型 | 有重排序模型 bge-reranker-v2-m3 | ||||
|---|---|---|---|---|---|---|---|
| Hits@1 | Hits@3 | Hits@10 | Hits@1 | Hits@3 | Hits@10 | ||
| 核心-英文 | bge-large-en-v1.5 | 0.378 | 0.463 | 0.625 | 0.503 | 0.585 | 0.628 |
| text-embedding-ada-002 | 0.418 | 0.501 | 0.719 | 0.530 | 0.651 | 0.731 | |
| Multilingual-E5-large-instruct | 0.415 | 0.564 | 0.663 | 0.506 | 0.617 | 0.669 | |
| bge-m3 | 0.422 | 0.597 | 0.689 | 0.531 | 0.648 | 0.690 | |
| 核心-中文 | bge-large-zh-v1.5 | 0.366 | 0.463 | 0.619 | 0.468 | 0.584 | 0.635 |
| text-embedding-ada-002 | 0.401 | 0.478 | 0.712 | 0.545 | 0.656 | 0.729 | |
| Multilingual-E5-large-instruct | 0.409 | 0.556 | 0.657 | 0.495 | 0.608 | 0.657 | |
| bge-m3 | 0.427 | 0.613 | 0.686 | 0.533 | 0.656 | 0.686 | |
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 |
|---|---|---|---|---|---|---|---|---|
| Vicuna-13B | 0.10 | 0.17 | 0.12 | 0.13 | 0.22 | 0.22 | 0.04 | 0.12 |
| ChatGLM2-6B | 0.14 | 0.14 | 0.11 | 0.15 | 0.20 | 0.18 | 0.05 | 0.13 |
| Llama2-7B | 0.17 | 0.12 | 0.15 | 0.16 | 0.17 | 0.31 | 0.08 | 0.18 |
| Cluade2 | 0.08 | 0.05 | 0.03 | 0.12 | 0.19 | 0.10 | 0.01 | 0.19 |
Tab. 5 Results of BLEU evaluation
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 |
|---|---|---|---|---|---|---|---|---|
| Vicuna-13B | 0.10 | 0.17 | 0.12 | 0.13 | 0.22 | 0.22 | 0.04 | 0.12 |
| ChatGLM2-6B | 0.14 | 0.14 | 0.11 | 0.15 | 0.20 | 0.18 | 0.05 | 0.13 |
| Llama2-7B | 0.17 | 0.12 | 0.15 | 0.16 | 0.17 | 0.31 | 0.08 | 0.18 |
| Cluade2 | 0.08 | 0.05 | 0.03 | 0.12 | 0.19 | 0.10 | 0.01 | 0.19 |
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Vicuna-13B | 0.87 | 0.89 | 0.88 | 0.87 | 0.89 | 0.88 | 0.87 | 0.88 | 0.88 | 0.86 | 0.90 | 0.88 |
| ChatGLM2-6B | 0.84 | 0.92 | 0.88 | 0.86 | 0.90 | 0.88 | 0.86 | 0.89 | 0.87 | 0.84 | 0.91 | 0.87 |
| Llama2-7B | 0.84 | 0.92 | 0.88 | 0.85 | 0.90 | 0.87 | 0.86 | 0.90 | 0.88 | 0.84 | 0.92 | 0.88 |
| Cluade2 | 0.82 | 0.91 | 0.86 | 0.83 | 0.91 | 0.87 | 0.83 | 0.89 | 0.86 | 0.82 | 0.91 | 0.86 |
| 模型 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Vicuna-13B | 0.77 | 0.78 | 0.77 | 0.73 | 0.68 | 0.70 | 0.60 | 0.58 | 0.59 | 0.61 | 0.68 | 0.68 |
| ChatGLM2-6B | 0.70 | 0.75 | 0.72 | 0.67 | 0.73 | 0.73 | 0.62 | 0.66 | 0.64 | 0.62 | 0.69 | 0.69 |
| Llama2-7B | 0.67 | 0.72 | 0.69 | 0.73 | 0.74 | 0.73 | 0.63 | 0.71 | 0.67 | 0.64 | 0.72 | 0.71 |
| Claude2 | 0.68 | 0.81 | 0.74 | 0.70 | 0.61 | 0.81 | 0.75 | 0.59 | 0.73 | 0.65 | 0.73 | 0.70 |
Tab. 6 Results of BERTScore evaluation
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Vicuna-13B | 0.87 | 0.89 | 0.88 | 0.87 | 0.89 | 0.88 | 0.87 | 0.88 | 0.88 | 0.86 | 0.90 | 0.88 |
| ChatGLM2-6B | 0.84 | 0.92 | 0.88 | 0.86 | 0.90 | 0.88 | 0.86 | 0.89 | 0.87 | 0.84 | 0.91 | 0.87 |
| Llama2-7B | 0.84 | 0.92 | 0.88 | 0.85 | 0.90 | 0.87 | 0.86 | 0.90 | 0.88 | 0.84 | 0.92 | 0.88 |
| Cluade2 | 0.82 | 0.91 | 0.86 | 0.83 | 0.91 | 0.87 | 0.83 | 0.89 | 0.86 | 0.82 | 0.91 | 0.86 |
| 模型 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Vicuna-13B | 0.77 | 0.78 | 0.77 | 0.73 | 0.68 | 0.70 | 0.60 | 0.58 | 0.59 | 0.61 | 0.68 | 0.68 |
| ChatGLM2-6B | 0.70 | 0.75 | 0.72 | 0.67 | 0.73 | 0.73 | 0.62 | 0.66 | 0.64 | 0.62 | 0.69 | 0.69 |
| Llama2-7B | 0.67 | 0.72 | 0.69 | 0.73 | 0.74 | 0.73 | 0.63 | 0.71 | 0.67 | 0.64 | 0.72 | 0.71 |
| Claude2 | 0.68 | 0.81 | 0.74 | 0.70 | 0.61 | 0.81 | 0.75 | 0.59 | 0.73 | 0.65 | 0.73 | 0.70 |
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 |
|---|---|---|---|---|---|---|---|---|
| Vicuna-13B | 1.89 | 2.42 | 2.06 | 2.06 | 2.92 | 1.68 | 1.77 | 1.97 |
| ChatGLM2-6B | 1.58 | 2.38 | 1.87 | 2.19 | 2.54 | 2.58 | 2.20 | 2.30 |
| Llama2-7B | 4.30 | 4.02 | 3.45 | 3.92 | 2.37 | 2.12 | 2.98 | 2.60 |
| Cluade2 | 4.51 | 4.14 | 4.56 | 4.52 | 4.62 | 4.10 | 4.76 | 4.65 |
Tab. 7 Results of LLM evaluation
| 模型 | 法律-英文 | 金融-英文 | 文学-英文 | 核心-英文 | 法律-中文 | 金融-中文 | 文学-中文 | 核心-中文 |
|---|---|---|---|---|---|---|---|---|
| Vicuna-13B | 1.89 | 2.42 | 2.06 | 2.06 | 2.92 | 1.68 | 1.77 | 1.97 |
| ChatGLM2-6B | 1.58 | 2.38 | 1.87 | 2.19 | 2.54 | 2.58 | 2.20 | 2.30 |
| Llama2-7B | 4.30 | 4.02 | 3.45 | 3.92 | 2.37 | 2.12 | 2.98 | 2.60 |
| Cluade2 | 4.51 | 4.14 | 4.56 | 4.52 | 4.62 | 4.10 | 4.76 | 4.65 |
| 模型 | 核心-英文 | 核心-中文 | ||||
|---|---|---|---|---|---|---|
| 流利度 | 精炼性 | 相关性 | 流利度 | 精炼性 | 相关性 | |
| Vicuna-13B | 4.78 | 3.78 | 2.72 | 4.66 | 4.37 | 1.60 |
| ChatGLM2-6B | 4.46 | 3.19 | 3.11 | 4.80 | 4.01 | 1.97 |
| Llama2-7B | 4.85 | 3.06 | 4.06 | 4.74 | 3.51 | 2.70 |
| Cluade2 | 4.79 | 2.90 | 4.36 | 4.86 | 2.96 | 4.35 |
Tab. 8 Results of human evaluation
| 模型 | 核心-英文 | 核心-中文 | ||||
|---|---|---|---|---|---|---|
| 流利度 | 精炼性 | 相关性 | 流利度 | 精炼性 | 相关性 | |
| Vicuna-13B | 4.78 | 3.78 | 2.72 | 4.66 | 4.37 | 1.60 |
| ChatGLM2-6B | 4.46 | 3.19 | 3.11 | 4.80 | 4.01 | 1.97 |
| Llama2-7B | 4.85 | 3.06 | 4.06 | 4.74 | 3.51 | 2.70 |
| Cluade2 | 4.79 | 2.90 | 4.36 | 4.86 | 2.96 | 4.35 |
| 模型 | 中文 | 英文 |
|---|---|---|
| Vicuna-13B | 96.41 | 75.33 |
| ChatGLM2-6B | 148.48 | 126.04 |
| Llama2-7B | 183.20 | 126.24 |
| Cluade2 | 314.66 | 137.44 |
Tab. 9 Statistics of response lengths of different baseline models on English and Chinese datasets
| 模型 | 中文 | 英文 |
|---|---|---|
| Vicuna-13B | 96.41 | 75.33 |
| ChatGLM2-6B | 148.48 | 126.04 |
| Llama2-7B | 183.20 | 126.24 |
| Cluade2 | 314.66 | 137.44 |
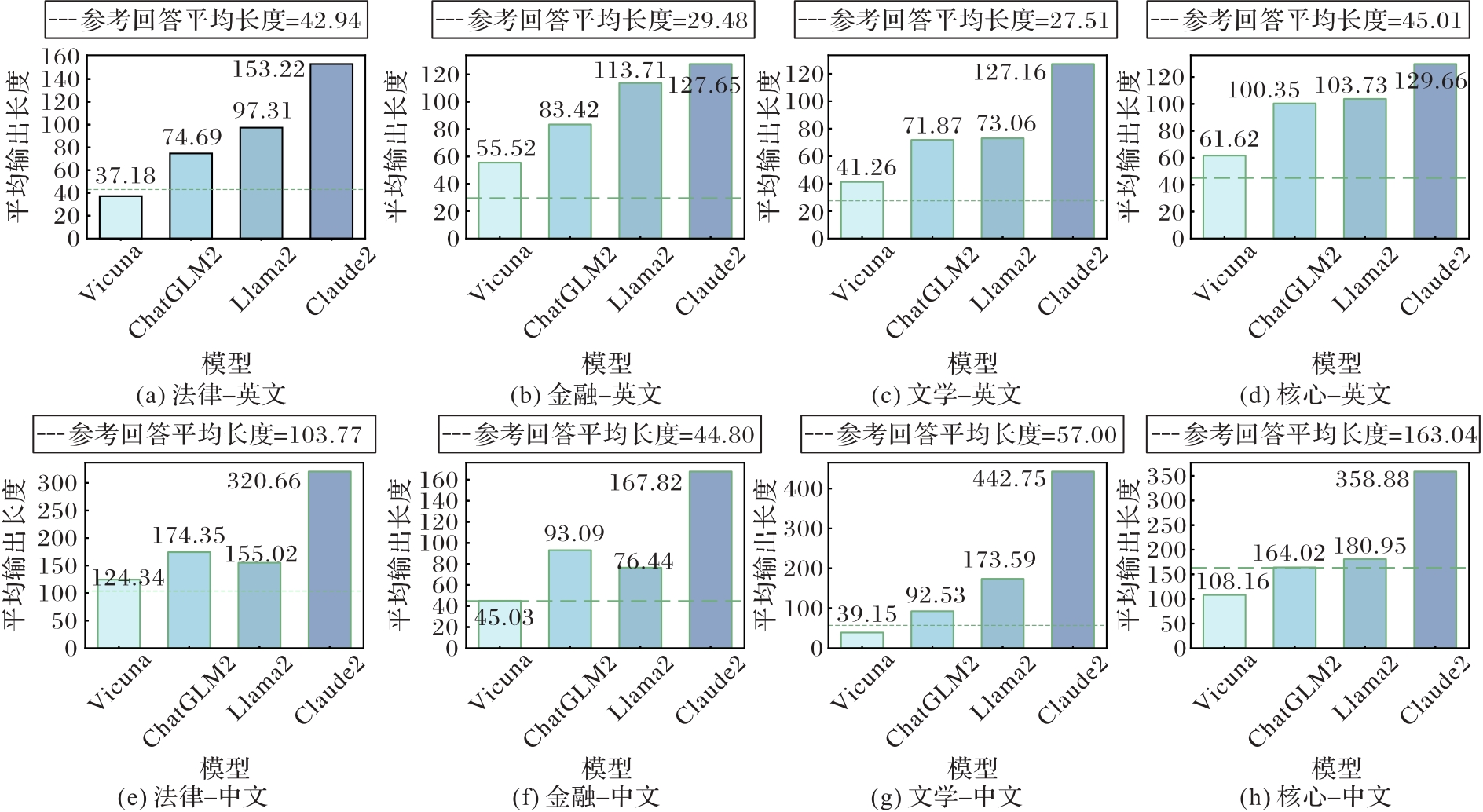
Fig. 3 Statistics of response lengths of different baseline models on eight sub-datasets
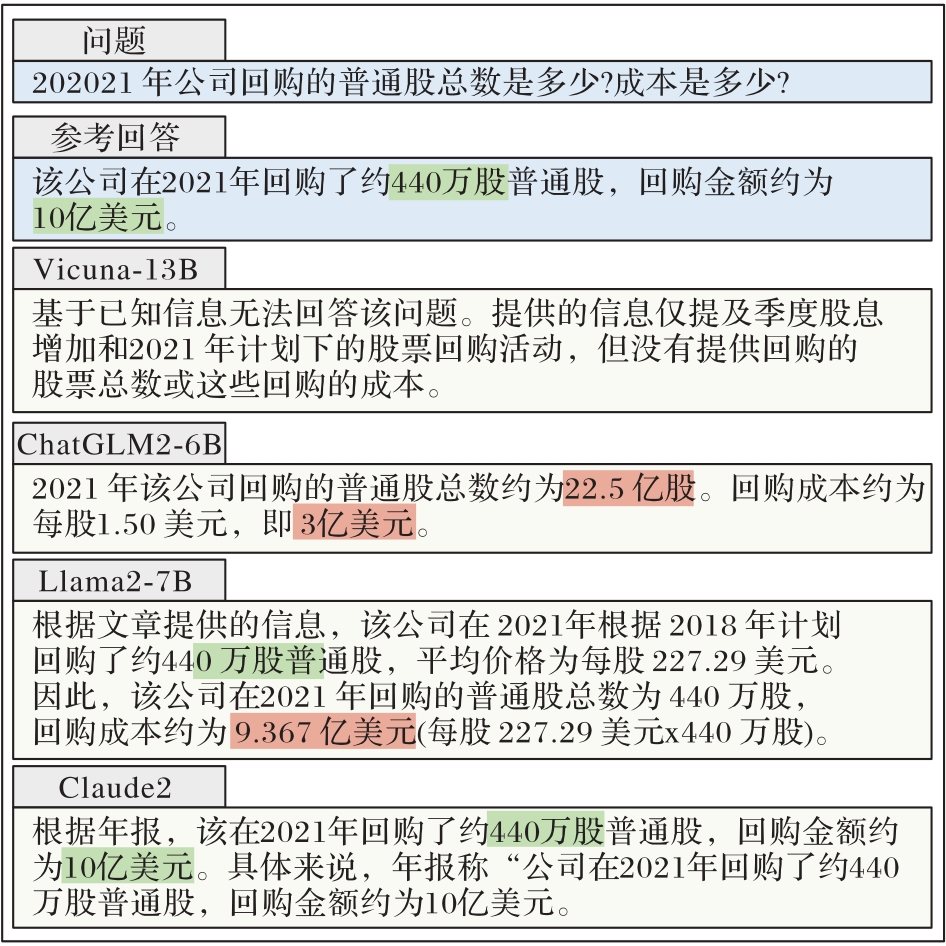
Fig. 4 Case study
| [1] | Meta AI. Llama3[EB/OL]. [2025-02-12].. |
| [2] | Anthropic. Introducing the next generation of Claude[EB/OL]. [2025-02-12].. |
| [3] | OpenAI. GPT-4 technical report[R/OL]. [2024-10-14].. |
| [4] | GUU K, LEE K, TUNG Z, et al. Retrieval augmented language model pre-training[C]// Proceedings of the 37th International Conference On Machine Learning. New York: JMLR.org, 2020: 3929-3938. |
| [5] | IZACARD G, LEWIS P, LOMELI M, et al. Atlas: few-shot learning with retrieval augmented language models[J]. Journal of Machine Learning Research, 2023, 24: 1-43. |
| [6] | LEWIS P, PEREZ E, PIKTUS A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 9459-9474. |
| [7] | CHEN J, LIN H, HAN X, et al. Benchmarking large language models in retrieval-augmented generation[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 17754-17762. |
| [8] | TANG Y, YANG Y. MultiHop-RAG: benchmarking retrieval-augmented generation for multi-hop queries[EB/OL]. [2024-12-03].. |
| [9] | PETRONI F, PIKTUS A, FAN A, et al. KILT: a benchmark for knowledge intensive language tasks[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 2523-2544. |
| [10] | IZACARD G, GRAVE E. Leveraging passage retrieval with generative models for open domain question answering[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 874-880. |
| [11] | IZACARD G, GRAVE E. Distilling knowledge from reader to retriever for question answering[EB/OL]. [2024-12-03].. |
| [12] | SACHAN D S, REDDY S, HAMILTON W, et al. End-to-end training of multi-document reader and retriever for open-domain question answering[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 25968-25981. |
| [13] | RAM O, LEVINE Y, DALMEDIGOS I, et al. In-context retrieval-augmented language models[J]. Transactions of the Association for Computational Linguistics, 2023, 11: 1316-1331. |
| [14] | SHI W, MIN S, YASUNAGA M, et al. REPLUG: retrieval-augmented black-box language models[C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 8371-8384. |
| [15] | ASAI A, WU Z, WANG Y, et al. Self-RAG: learning to retrieve, generate, and critique through self-reflection[EB/OL]. [2024-12-03].. |
| [16] | JEONG S, BAEK J, CHO S, et al. Adaptive-RAG: learning to adapt retrieval-augmented large language models through question complexity[C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 7036-7050. |
| [17] | YU W, ZHANG H, PAN X, et al. Chain-of-Note: enhancing robustness in retrieval-augmented language models[C]// Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2024: 14672-14685. |
| [18] | WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 24824-24837. |
| [19] | ES S, JAMES J, ESPINOSA-ANKE L, et al. RAGAs: automated evaluation of retrieval augmented generation[C]// Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Stroudsburg: ACL, 2024: 150-158. |
| [20] | SAAD-FALCON J, KHATTAB O, POTTS C, et al. ARES: an automated evaluation framework for retrieval-augmented generation systems[C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 338-354. |
| [21] | LYU Y, LI Z, NIU S, et al. CRUD-RAG: a comprehensive Chinese benchmark for retrieval-augmented generation of large language models[J]. ACM Transactions on Information Systems, 2025, 43(2): No.41. |
| [22] | BAI Y, LV X, ZHANG J, et al. LongBench: a bilingual, multitask benchmark for long context understanding[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 3119-3137. |
| [23] | AN C, GONG S, ZHONG M, et al. L-Eval: instituting standardized evaluation for long context language models[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 14388-14411. |
| [24] | LI J, WANG M, ZHENG Z, et al. LooGLE: can long-context language models understand long contexts?[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 16304-16333. |
| [25] | LI T, ZHANG G, DO Q D, et al. Long-context LLMs struggle with long in-context learning[EB/OL]. [2024-10-14].. |
| [26] | OpenAI. text-embedding-ada-002[EB/OL]. [2024-10-14].. |
| [27] | ZHANG P, XIAO S, LIU Z, et al. Retrieve anything to augment large language models[EB/OL]. [2024-10-14].. |
| [28] | CHEN J, XIAO S, ZHANG P, et al. M3-Embedding: multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation[C]// Findings of the Association for Computational Linguistics: ACL 2024. Stroudsburg: ACL, 2024: 2318-2335. |
| [29] | WANG L, YANG N, HUANG X, et al. Multilingual E5 text embeddings: a technical report[EB/OL]. [2024-10-14].. |
| [30] | The Vicuna Team. Vicuna: an open-source chatbot impressing GPT-4 with 90%* ChatGPT quality[EB/OL]. [2024-10-14].. |
| [31] | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| [32] | GenAI, Meta. Llama 2: open foundation and fine-tuned chat models[EB/OL]. [2024-10-14].. |
| [33] | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| [34] | ZHANG T, KISHORE V, WU F, et al. BERTscore: evaluating text generation with BERT[EB/OL]. [2024-11-05].. |
| [35] | LangChain. Homepage of LangChain[EB/OL]. [2024-10-13].. |
| [1] | Yi LIN, Bing XIA, Yong WANG, Shunda MENG, Juchong LIU, Shuqin ZHANG. AI-Agent based method for hidden RESTful API discovery and vulnerability detection [J]. Journal of Computer Applications, 2026, 46(1): 135-143. |
| [2] | Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension [J]. Journal of Computer Applications, 2026, 46(1): 60-68. |
| [3] | Binbin ZHANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN. Judgment document summarization method combining large language model and dynamic prompts [J]. Journal of Computer Applications, 2025, 45(9): 2783-2789. |
| [4] | Tao FENG, Chen LIU. Dual-stage prompt tuning method for automated preference alignment [J]. Journal of Computer Applications, 2025, 45(8): 2442-2447. |
| [5] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [6] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [7] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [8] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [9] | Can MA, Ruizhang HUANG, Lina REN, Ruina BAI, Yaoyao WU. Chinese spelling correction method based on LLM with multiple inputs [J]. Journal of Computer Applications, 2025, 45(3): 849-855. |
| [10] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [11] | Yanping ZHANG, Meifang CHEN, Changhai TIAN, Zibo YI, Wenpeng HU, Wei LUO, Zhunchen LUO. Multi-strategy retrieval-augmented generation method for military domain knowledge question answering systems [J]. Journal of Computer Applications, 2025, 45(3): 746-754. |
| [12] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [13] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [14] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [15] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||