


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (3): 758-766.DOI: 10.11772/j.issn.1001-9081.2025040509
• Artificial intelligence • Previous Articles Next Articles
Zuxi ZHANG, Zhancheng ZHANG( ), Fuyuan HU
), Fuyuan HU
Received:2025-05-09
Revised:2025-07-14
Accepted:2025-07-17
Online:2026-03-16
Published:2026-03-10
Contact:
Zhancheng ZHANG
About author:ZHANG Zuxi, born in 1998, M. S. candidate. His research interests include computer vision, video action recognition.Supported by:
张祖习, 张战成(), 胡伏原
通讯作者:
张战成
作者简介:张祖习(1998—),男,江西九江人,硕士研究生,CCF会员,主要研究方向:计算机视觉、视频动作识别基金资助:CLC Number:
Zuxi ZHANG, Zhancheng ZHANG, Fuyuan HU. Local and long-range temporal complementary modeling for video action recognition[J]. Journal of Computer Applications, 2026, 46(3): 758-766.
张祖习, 张战成, 胡伏原. 局部与长程时序互补建模的视频动作识别[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 758-766.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025040509
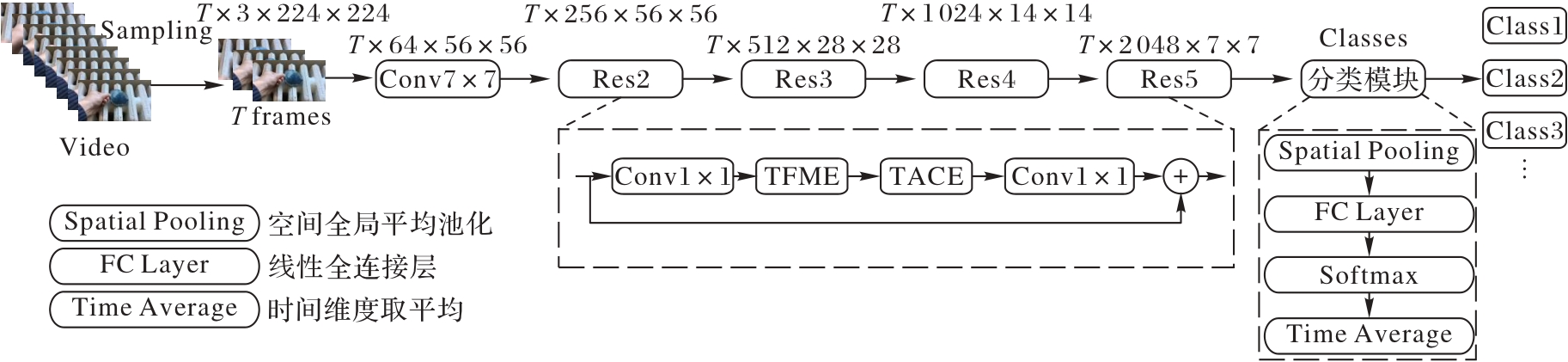
Fig. 1 Overall architecture of proposed network

Fig. 2 Structure of TFME module

Fig. 3 Structure of TACE module

Fig. 4 Action examples in Something-Something dataset
| 方法 | 骨干网络 | 预训练 | 帧数 | 浮点运算量(GFLOPs) | V1-Top1/% | V2-Top1/% |
|---|---|---|---|---|---|---|
| NL-I3D | 3DRes50 | ImgNet+K400 | 32×3×2 | 153×3×2 | 41.6 | — |
| NL-I3D+GCN | 3DRes50+GCN | ImgNet+K400 | 32×3×2 | 303×3×2 | 46.1 | — |
| ECOEn-RGB | BNIncep+3DRes18 | K400 | 92×1×1 | 267×1×1 | 46.4 | — |
| TSN-RGB | ResNet-50 | ImageNet | 8×1×1 | 16×1×1 | 19.5 | 30.0 |
| TSN-RGB | ResNet-50 | ImageNet | 16×1×1 | 33×1×1 | 19.7 | — |
| TSM-RGB | ResNet-50 | ImageNet | 8×1×1 | 33×1×1 | 43.4 | 55.6 |
| TSM-RGB | ResNet-50 | ImageNet | 16×1×1 | 65×1×1 | 44.8 | — |
| bLVNet-TAM | bLResNet-50 | ImageNet | 8×1×1 | 24×1×1 | 46.4 | 59.1 |
| bLVNet-TAM | bLResNet-50 | SSV1/SSV2 | 16×1×1 | 48×1×1 | 48.4 | 61.7 |
| STM | ResNet-50 | ImageNet | 8×3×10 | 33×3×10 | 49.2 | 62.3 |
| STM | ResNet-50 | ImageNet | 16×3×10 | 67×3×10 | 50.7 | 64.2 |
| TEA | ResNet-50 | ImageNet | 8×1×1 | 35×1×1 | 48.9 | — |
| TEA | ResNet-50 | ImageNet | 16×1×1 | 70×1×1 | 51.9 | — |
| TANet | ResNet-50 | ImageNet | 8×1×1 | 33×1×1 | 47.3 | 60.5 |
| TANet | ResNet-50 | ImageNet | 16×1×1 | 66×1×1 | 47.6 | 62.5 |
| TDN | ResNet-50 | ImageNet | 8×3×10 | 36×3×10 | 52.3 | 64.0 |
| TDN | ResNet-50 | ImageNet | 16×3×10 | 72×3×10 | 53.9 | 65.3 |
| Uni-AdaFocus-TSM(962) | MN2+R50 | ImageNet | (8+12)×1×1 | 9×1×1 | 48.9 | 62.5 |
| Uni-AdaFocus-TSM(1282) | MN2+R50 | ImageNet | (8+16)×1×1 | 19×1×1 | 51.0 | 64.2 |
| JCFG-STM | ResNet-50 | ImageNet | 8×3×10 | 35×3×10 | — | 62.0 |
| JCFG-STM | ResNet-50 | ImageNet | 16×3×10 | 70×3×10 | — | 62.2 |
| 本文方法 | ResNet-50 | ImageNet | 8×1×1 | 35×1×1 | 50.6 | 61.9 |
| ResNet-50 | ImageNet | 16×1×1 | 70×1×1 | 52.7 | 63.2 | |
| ResNet-50 | ImageNet | 16×3×10 | 70×3×10 | 54.1 | 65.6 |
Tab. 1 Action recognition result comparison of different methods on Something-SomethingV1 and V2 datasets
| 方法 | 骨干网络 | 预训练 | 帧数 | 浮点运算量(GFLOPs) | V1-Top1/% | V2-Top1/% |
|---|---|---|---|---|---|---|
| NL-I3D | 3DRes50 | ImgNet+K400 | 32×3×2 | 153×3×2 | 41.6 | — |
| NL-I3D+GCN | 3DRes50+GCN | ImgNet+K400 | 32×3×2 | 303×3×2 | 46.1 | — |
| ECOEn-RGB | BNIncep+3DRes18 | K400 | 92×1×1 | 267×1×1 | 46.4 | — |
| TSN-RGB | ResNet-50 | ImageNet | 8×1×1 | 16×1×1 | 19.5 | 30.0 |
| TSN-RGB | ResNet-50 | ImageNet | 16×1×1 | 33×1×1 | 19.7 | — |
| TSM-RGB | ResNet-50 | ImageNet | 8×1×1 | 33×1×1 | 43.4 | 55.6 |
| TSM-RGB | ResNet-50 | ImageNet | 16×1×1 | 65×1×1 | 44.8 | — |
| bLVNet-TAM | bLResNet-50 | ImageNet | 8×1×1 | 24×1×1 | 46.4 | 59.1 |
| bLVNet-TAM | bLResNet-50 | SSV1/SSV2 | 16×1×1 | 48×1×1 | 48.4 | 61.7 |
| STM | ResNet-50 | ImageNet | 8×3×10 | 33×3×10 | 49.2 | 62.3 |
| STM | ResNet-50 | ImageNet | 16×3×10 | 67×3×10 | 50.7 | 64.2 |
| TEA | ResNet-50 | ImageNet | 8×1×1 | 35×1×1 | 48.9 | — |
| TEA | ResNet-50 | ImageNet | 16×1×1 | 70×1×1 | 51.9 | — |
| TANet | ResNet-50 | ImageNet | 8×1×1 | 33×1×1 | 47.3 | 60.5 |
| TANet | ResNet-50 | ImageNet | 16×1×1 | 66×1×1 | 47.6 | 62.5 |
| TDN | ResNet-50 | ImageNet | 8×3×10 | 36×3×10 | 52.3 | 64.0 |
| TDN | ResNet-50 | ImageNet | 16×3×10 | 72×3×10 | 53.9 | 65.3 |
| Uni-AdaFocus-TSM(962) | MN2+R50 | ImageNet | (8+12)×1×1 | 9×1×1 | 48.9 | 62.5 |
| Uni-AdaFocus-TSM(1282) | MN2+R50 | ImageNet | (8+16)×1×1 | 19×1×1 | 51.0 | 64.2 |
| JCFG-STM | ResNet-50 | ImageNet | 8×3×10 | 35×3×10 | — | 62.0 |
| JCFG-STM | ResNet-50 | ImageNet | 16×3×10 | 70×3×10 | — | 62.2 |
| 本文方法 | ResNet-50 | ImageNet | 8×1×1 | 35×1×1 | 50.6 | 61.9 |
| ResNet-50 | ImageNet | 16×1×1 | 70×1×1 | 52.7 | 63.2 | |
| ResNet-50 | ImageNet | 16×3×10 | 70×3×10 | 54.1 | 65.6 |

Fig. 5 Different residual blocks
| 方法 | 参数量/106 | V1-Top1/% |
|---|---|---|
| TEA block | 24.30 | 48.9 |
| TFME+MTA block | 24.51 | 49.6 |
Tab. 2 Performance comparison of local temporal modeling
| 方法 | 参数量/106 | V1-Top1/% |
|---|---|---|
| TEA block | 24.30 | 48.9 |
| TFME+MTA block | 24.51 | 49.6 |
| 方法 | 参数量/106 | V1-Top1/% |
|---|---|---|
| TEA block | 24.30 | 48.9 |
| ME+TACE block | 24.75 | 49.8 |
| TFME+TACE block | 24.96 | 50.6 |
Tab. 3 Performance comparison of long-range temporal modeling
| 方法 | 参数量/106 | V1-Top1/% |
|---|---|---|
| TEA block | 24.30 | 48.9 |
| ME+TACE block | 24.75 | 49.8 |
| TFME+TACE block | 24.96 | 50.6 |
| [1] | 倪苒岩,张轶. 基于视频时空特征的行为识别方法[J]. 计算机应用, 2023, 43(2): 521-528. |
| NI R Y, ZHANG Y. Action recognition method based on video spatio-temporal features [J]. Journal of Computer Applications, 2023, 43(2): 521-528. | |
| [2] | ZHANG M, TIAN G, ZHANG Y, et al. Service skill improvement for home robots: autonomous generation of action sequence based on reinforcement learning [J]. Knowledge-Based Systems, 2021, 212: No.106605. |
| [3] | WANG H, SCHMID C. Action recognition with improved trajectories [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 3551-3558. |
| [4] | MORSHED M G, SULTANA T, ALAM A, et al. Human action recognition: a taxonomy-based survey, updates, and opportunities[J]. Sensors, 2023, 23(4): No.2182. |
| [5] | TANG Z, ZHAO Y, WEN Y, et al. A survey on backbones for deep video action recognition [C]// Proceedings of the 2024 International Conference on Multimedia and Expo Workshops. Piscataway: IEEE, 2024: 1-6. |
| [6] | 王丽芳,吴荆双,尹鹏亮,等. 基于注意力机制和能量函数的动作识别算法[J]. 计算机应用, 2025, 45(1): 234-239. |
| WANG L F, WU J S, YIN P L, et al. Action recognition algorithm based on attention mechanism and energy function [J]. Journal of Computer Applications, 2025, 45(1): 234-239. | |
| [7] | WANG Z, SHE Q, SMOLIC A. ACTION-Net: multipath excitation for action recognition [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13209-13218. |
| [8] | JIANG Z, ZHANG Y, HU S. ESTI: an action recognition network with enhanced spatio-temporal information [J]. International Journal of Machine Learning and Cybernetics, 2023, 14(9): 3059-3070. |
| [9] | LIU T, MA Y, YANG W, et al. Spatial-temporal interaction learning based two-stream network for action recognition [J]. Information Sciences, 2022, 606: 864-876. |
| [10] | WANG Z, LU H, JIN J, et al. Human action recognition based on improved two-stream convolution network [J]. Applied Sciences, 2022, 12(12): No.5784. |
| [11] | LIN J, GAN C, HAN S. TSM: temporal shift module for efficient video understanding [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 7082-7092. |
| [12] | CAI Z. A novel spatio-temporal-wise network for action recognition[J]. IEEE Access, 2023, 11: 49071-49080. |
| [13] | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4724-4733. |
| [14] | CHEN B, MENG F, TANG H, et al. Two-level attention module based on spurious-3D residual networks for human action recognition [J]. Sensors, 2023, 23(3): No.1707. |
| [15] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2025-03-12].. |
| [16] | ARNAB A, DEHGHANI M, HEIGOLD G, et al. ViViT: a video Vision Transformer [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 6816-6826. |
| [17] | WANG L, HUANG B, ZHAO Z, et al. VideoMAE V2: scaling video masked autoencoders with dual masking [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 14549-14560. |
| [18] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [19] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1. Cambridge: MIT Press, 2014: 568-576. |
| [20] | WANG L, XIONG Y, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 20-36. |
| [21] | LI Y, JI B, SHI X, et al. TEA: temporal excitation and aggregation for action recognition [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 906-915. |
| [22] | WANG L, TONG Z, JI B, et al. TDN: temporal difference networks for efficient action recognition [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1895-1904. |
| [23] | CHEN Y, GE H, LIU Y, et al. AGPN: action granularity pyramid network for video action recognition [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(8): 3912-3923. |
| [24] | LI C, CHENG C, YU M, et al. Joint coarse to fine-grained spatio-temporal modeling for video action recognition [J]. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2025, 7(3): 444-457. |
| [25] | LI K, LI X, WANG Y, et al. CT-Net: channel tensorization network for video classification [EB/OL]. [2025-04-09].. |
| [26] | WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7794-7803. |
| [27] | XIONG X, MIN W, HAN Q, et al. Action recognition using action sequences optimization and two-stream 3D dilated neural network [J]. Computational Intelligence and Neuroscience, 2022, 2022: No.6608448. |
| [28] | TAO Y, TAO H, ZHUANG Z, et al. Quantized iterative learning control of communication-constrained systems with encoding and decoding mechanism [J]. Transactions of the Institute of Measurement and Control, 2024, 46(10): 1943-1954. |
| [29] | SONG X, PENG Z, SONG S, et al. Anti-disturbance state estimation for PDT-switched RDNNs utilizing time-sampling and space-splitting measurements [J]. Communications in Nonlinear Science and Numerical Simulation, 2024, 132: No.107945. |
| [30] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141. |
| [31] | WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. |
| [32] | LI Z, LI J, MA Y, et al. Spatio-temporal adaptive network with bidirectional temporal difference for action recognition [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 5174-5185. |
| [33] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [34] | JIANG B, WANG M, GAN W, et al. STM: spatiotemporal and motion encoding for action recognition [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2000-2009. |
| [35] | GAO S H, CHENG M M, ZHAO K, et al. Res2Net: a new multi-scale backbone architecture [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652-662. |
| [36] | GAO H, WANG Z, JI S. ChannelNets: compact and efficient convolutional neural networks via channel-wise convolutions [C]// Proceedings of the 32nd Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 5203-5211. |
| [37] | GOYAL R, EBRAHIMI KAHOU S, MICHALSKI V, et al. The “something something” video database for learning and evaluating visual common sense [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 5843-5851. |
| [38] | KAY W, CARREIRA J, SIMONYAN K, et al. The kinetics human action video dataset [EB/OL]. [2025-04-26].. |
| [39] | WANG X, GUPTA A. Videos as space-time region graphs [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11209. Cham: Springer, 2018: 413-431. |
| [40] | ZOLFAGHARI M, SINGH K, BROX T. ECO: efficient convolutional network for online video understanding [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11206. Cham: Springer, 2018: 713-730. |
| [41] | FAN Q, CHEN C F R, KUEHNE H, et al. More is less: learning efficient video representations by big-little network and depthwise temporal aggregation [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 2264-2273. |
| [42] | LIU Z, WANG L, WU W, et al. TAM: temporal adaptive module for video recognition [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13688-13698. |
| [43] | WANG Y, ZHANG H, YUE Y, et al. Uni-AdaFocus: spatial-temporal dynamic computation for video recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(3): 1782-1799. |
| [1] | Peirong SHAO, Suzhen LIN, Yanbo WANG. Human-centric detail-enhanced virtual try-on method [J]. Journal of Computer Applications, 2026, 46(3): 915-923. |
| [2] | Xiaoxia LIU, Liqun KUANG, Song WANG, Shichao JIAO, Huiyan HAN, Fengguang XIONG. Multi-scale spatio-temporal decoupling for contrastive learning of skeleton action recognition [J]. Journal of Computer Applications, 2026, 46(3): 767-774. |
| [3] | Jinjiao LIN, Canshun ZHANG, Shuya CHEN, Tianxin WANG, Jian LIAN, Yonghui XU. Vehicle insurance fraud detection method based on improved graph attention network [J]. Journal of Computer Applications, 2026, 46(2): 437-444. |
| [4] | Rifeng ZHANG, Guangming LI, Yurong OUYANG. Low-light image enhancement network guided by reflection prior map [J]. Journal of Computer Applications, 2026, 46(2): 546-554. |
| [5] | Qianhui XU, Ke NIU, Shunzhe ZHU, Lin SHI, Jun LI. GAB3D-SEVSN: enhanced video steganography model via invertible neural network [J]. Journal of Computer Applications, 2026, 46(2): 467-474. |
| [6] | Hu LUO, Mingshu ZHANG. Rumor detection method based on cross-modal attention mechanism and contrastive learning [J]. Journal of Computer Applications, 2026, 46(2): 361-367. |
| [7] | Feng HAN, Yongfeng BU, Haoxiang LIANG, Shuwen HUANG, Zhaoyang ZHANG, Shijie SUN. Vehicle trajectory anomaly detection based on multi-level spatio-temporal interaction dependency [J]. Journal of Computer Applications, 2026, 46(2): 604-612. |
| [8] | Junrui WU, Jiangchuan YANG, Haisheng YU, Sai ZOU, Wenyong WANG. Performance evaluation method for deterministic networks based on complex-enhanced attention graph neural network [J]. Journal of Computer Applications, 2026, 46(2): 505-517. |
| [9] | Ming LI, Mengqi WANG, Aili ZHANG, Hua REN, Yuqiang DOU. Image steganography method based on conditional generative adversarial networks and hybrid attention mechanism [J]. Journal of Computer Applications, 2026, 46(2): 475-484. |
| [10] | Sizhong ZHANG, Jianyang LIU, Linfeng LI. Action quality assessment model based on trajectory-guided perceptual learning with X3D [J]. Journal of Computer Applications, 2026, 46(2): 555-563. |
| [11] | Yingjie MA, Jingying QIN, Geng ZHAO, Jing XIAO. Deep compressive sensing network for IoT images and its chaotic encryption protection method [J]. Journal of Computer Applications, 2026, 46(1): 144-151. |
| [12] | Lifang WANG, Wenjing REN, Xiaodong GUO, Rongguo ZHANG, Lihua HU. Trident generative adversarial network for low-dose CT image denoising [J]. Journal of Computer Applications, 2026, 46(1): 270-279. |
| [13] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| [14] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [15] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||