


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (6): 2034-2042.DOI: 10.11772/j.issn.1001-9081.2024060748
• Multimedia computing and computer simulation • Previous Articles
Linjia SUN, Lei QIN, Meijin KANG, Yinglin WANG
Received:2024-06-06
Revised:2024-09-25
Accepted:2024-09-27
Online:2024-10-12
Published:2025-06-10
Contact:
Linjia SUN
About author:SUN Linjia, born in 1983, Ph. D., assistant research fellow. His research interests include language resource construction, speech processing.Supported by:孙林嘉, 秦磊, 康美金, 王莹琳
通讯作者:
孙林嘉
作者简介:孙林嘉(1983—),男,山西朔州人,助理研究员,博士,主要研究方向:语言资源建设、语音处理 sunlinjia@Blcu.edu.cn基金资助:CLC Number:
Linjia SUN, Lei QIN, Meijin KANG, Yinglin WANG. Automatic speech segmentation algorithm based on syllable type recognition[J]. Journal of Computer Applications, 2025, 45(6): 2034-2042.
孙林嘉, 秦磊, 康美金, 王莹琳. 基于音节类型识别的自动语音分割算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2034-2042.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024060748
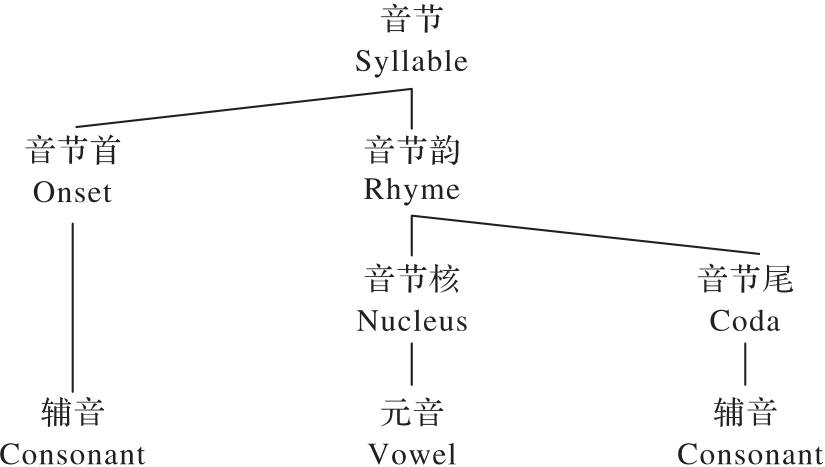
Fig. 1 Syllable structure
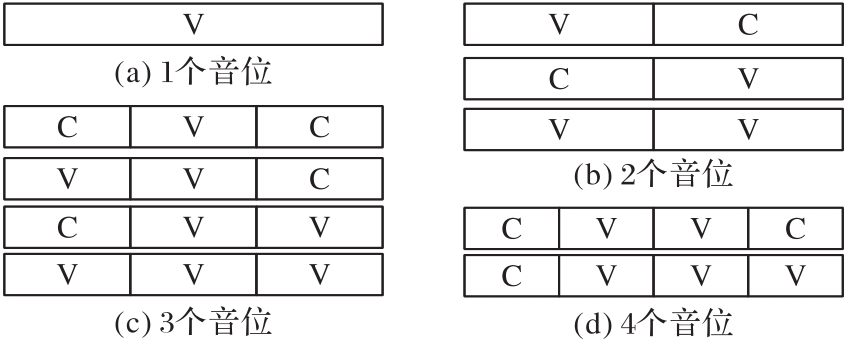
Fig. 2 Schematic diagrams of syllable types
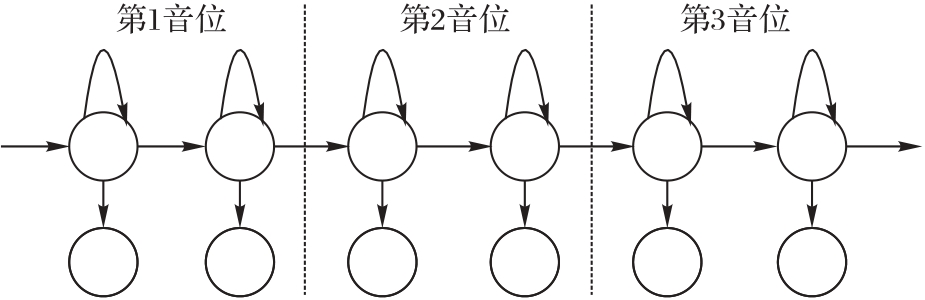
Fig.3 Example of acoustic model of syllable type with three phonemes, each containing two states
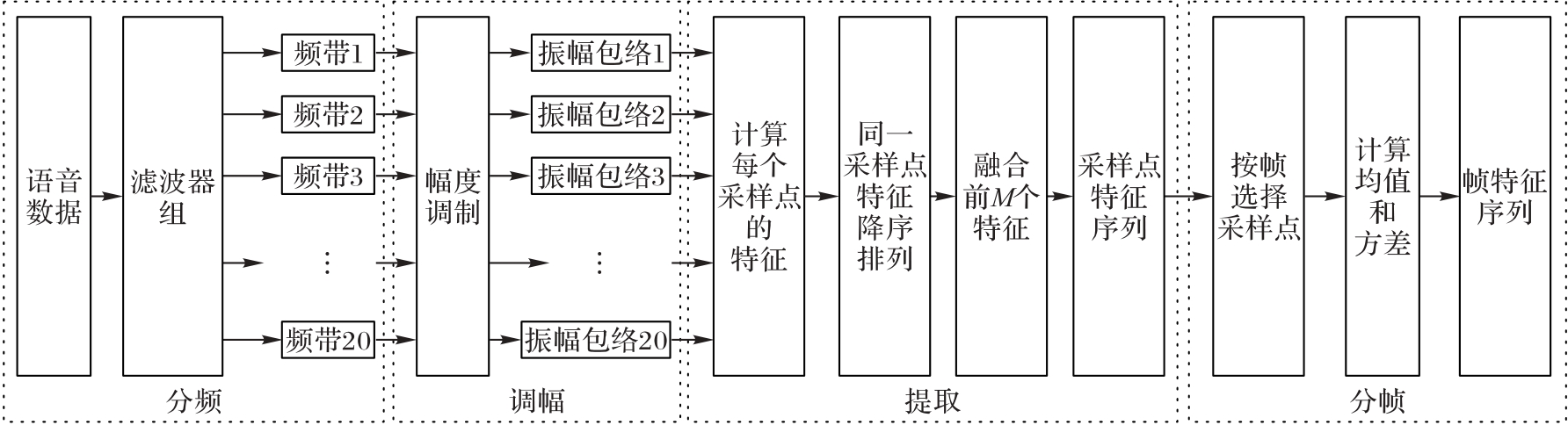
Fig. 4 Flow of extracting visual feature vectors
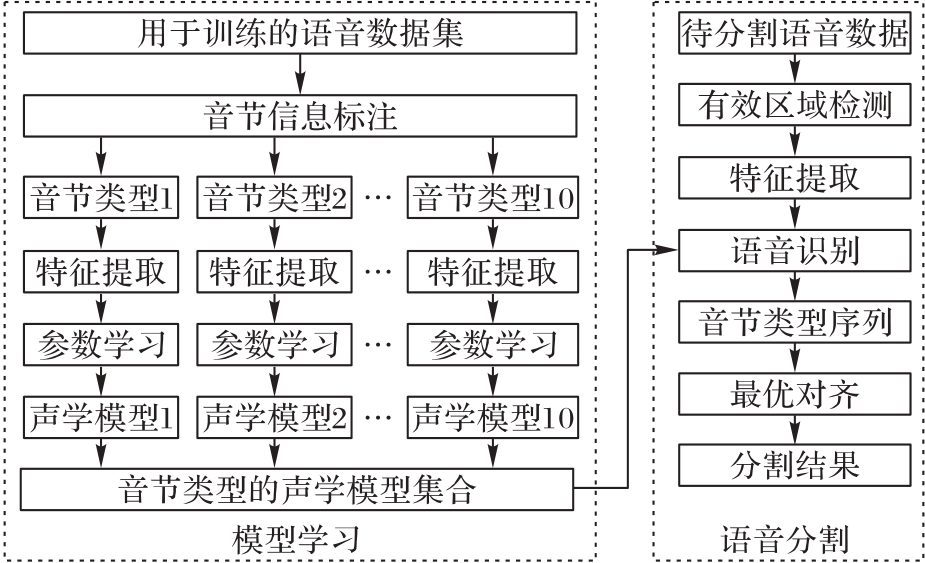
Fig. 5 Framework of proposed algorithm
语言和 方言 | 数据 来源 | 文件数 | 文件 时长/h | 分布占比/% | |
|---|---|---|---|---|---|
模型 学习 | 语音 分割 | ||||
| 英语 | TIMIT | 6 300 | 5 | 60 | 40 |
| 法语 | MediaSpeech | 2 498 | 10 | 60 | 40 |
| 西班牙语 | MediaSpeech | 2 507 | 10 | 0 | 100 |
| 汉语普通话 | THCHS | 10 000 | 40 | 60 | 40 |
| 汉语晋方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
| 汉语吴方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
Tab. 1 Summary information of speech data used in experiments and its distribution
语言和 方言 | 数据 来源 | 文件数 | 文件 时长/h | 分布占比/% | |
|---|---|---|---|---|---|
模型 学习 | 语音 分割 | ||||
| 英语 | TIMIT | 6 300 | 5 | 60 | 40 |
| 法语 | MediaSpeech | 2 498 | 10 | 60 | 40 |
| 西班牙语 | MediaSpeech | 2 507 | 10 | 0 | 100 |
| 汉语普通话 | THCHS | 10 000 | 40 | 60 | 40 |
| 汉语晋方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
| 汉语吴方言 | 调查采集 | 8 000 | 11 | 0 | 100 |
音节 类型 | 第1音位 状态数 | 第2音位 状态数 | 第3音位 状态数 | 第4音位 状态数 |
|---|---|---|---|---|
| V | 4 | 0 | 0 | 0 |
| CV | 5 | 4 | 0 | 0 |
| VC | 4 | 4 | 0 | 0 |
| VV | 3 | 3 | 0 | 0 |
| CVC | 5 | 4 | 4 | 0 |
| CVV | 5 | 3 | 3 | 0 |
| VVC | 3 | 3 | 4 | 0 |
| VVV | 3 | 3 | 3 | 0 |
| CVVC | 5 | 3 | 3 | 4 |
| CVVV | 5 | 3 | 3 | 3 |
Tab.2 Optimal state structure of acoustic models for different syllable types
音节 类型 | 第1音位 状态数 | 第2音位 状态数 | 第3音位 状态数 | 第4音位 状态数 |
|---|---|---|---|---|
| V | 4 | 0 | 0 | 0 |
| CV | 5 | 4 | 0 | 0 |
| VC | 4 | 4 | 0 | 0 |
| VV | 3 | 3 | 0 | 0 |
| CVC | 5 | 4 | 4 | 0 |
| CVV | 5 | 3 | 3 | 0 |
| VVC | 3 | 3 | 4 | 0 |
| VVV | 3 | 3 | 3 | 0 |
| CVVC | 5 | 3 | 3 | 4 |
| CVVV | 5 | 3 | 3 | 3 |
语言和 方言 | 不同时长 | 引入 噪声 | 使用MFCC | ||
|---|---|---|---|---|---|
| 1.5 s | 4.0 s | 7.0 s | |||
| 英语 | 94.02 | 93.69 | 93.28 | 92.86 | 70.21 |
| 法语 | 94.17 | 94.06 | 94.23 | 92.37 | 72.35 |
| 汉语普通话 | 93.89 | 93.17 | 93.54 | 92.63 | 70.36 |
| 均值1 | 94.03 | 93.64 | 93.68 | 92.62 | 70.97 |
| 西班牙语 | 89.61 | 89.75 | 89.27 | 87.29 | 54.89 |
| 汉语吴方言 | 90.98 | 90.24 | 90.36 | 88.08 | 56.03 |
| 汉语晋方言 | 90.23 | 90.71 | 90.92 | 88.85 | 55.27 |
| 均值2 | 90.27 | 90.23 | 90.18 | 88.07 | 55.40 |
| 均值3 | 92.15 | 91.94 | 91.93 | 90.35 | 63.19 |
Tab. 3 Average recognition accuracies under different durations, added noise, and MFCC
语言和 方言 | 不同时长 | 引入 噪声 | 使用MFCC | ||
|---|---|---|---|---|---|
| 1.5 s | 4.0 s | 7.0 s | |||
| 英语 | 94.02 | 93.69 | 93.28 | 92.86 | 70.21 |
| 法语 | 94.17 | 94.06 | 94.23 | 92.37 | 72.35 |
| 汉语普通话 | 93.89 | 93.17 | 93.54 | 92.63 | 70.36 |
| 均值1 | 94.03 | 93.64 | 93.68 | 92.62 | 70.97 |
| 西班牙语 | 89.61 | 89.75 | 89.27 | 87.29 | 54.89 |
| 汉语吴方言 | 90.98 | 90.24 | 90.36 | 88.08 | 56.03 |
| 汉语晋方言 | 90.23 | 90.71 | 90.92 | 88.85 | 55.27 |
| 均值2 | 90.27 | 90.23 | 90.18 | 88.07 | 55.40 |
| 均值3 | 92.15 | 91.94 | 91.93 | 90.35 | 63.19 |
语言和 方言 | 不同容差阈值 | 不同先验知识 (容差阈值=20 ms) | |||
|---|---|---|---|---|---|
| 20 ms | 30 ms | 40 ms | 音节数 | 类型序列 | |
| 均值 | 90.70 | 91.12 | 91.55 | 91.20 | 91.43 |
| 英语 | 92.54 | 92.96 | 93.35 | 93.06 | 93.13 |
| 法语 | 91.71 | 92.44 | 93.27 | 92.56 | 92.87 |
| 汉语普通话 | 93.03 | 93.76 | 94.15 | 93.47 | 93.84 |
| 西班牙语 | 88.14 | 88.34 | 88.77 | 88.57 | 88.82 |
| 汉语吴方言 | 89.32 | 89.51 | 89.92 | 89.72 | 89.96 |
| 汉语晋方言 | 89.48 | 89.68 | 89.85 | 89.81 | 89.93 |
Tab. 4 Average segmentation accuracies under different tolerance thresholds and prior knowledge
语言和 方言 | 不同容差阈值 | 不同先验知识 (容差阈值=20 ms) | |||
|---|---|---|---|---|---|
| 20 ms | 30 ms | 40 ms | 音节数 | 类型序列 | |
| 均值 | 90.70 | 91.12 | 91.55 | 91.20 | 91.43 |
| 英语 | 92.54 | 92.96 | 93.35 | 93.06 | 93.13 |
| 法语 | 91.71 | 92.44 | 93.27 | 92.56 | 92.87 |
| 汉语普通话 | 93.03 | 93.76 | 94.15 | 93.47 | 93.84 |
| 西班牙语 | 88.14 | 88.34 | 88.77 | 88.57 | 88.82 |
| 汉语吴方言 | 89.32 | 89.51 | 89.92 | 89.72 | 89.96 |
| 汉语晋方言 | 89.48 | 89.68 | 89.85 | 89.81 | 89.93 |
| 语言和方言 | 本文 算法 | 峰值分类 算法 | 振荡调幅 算法 | 迭代优化 算法 | 多级切分 算法 |
|---|---|---|---|---|---|
| 均值 | 90.70 | 84.97 | 83.36 | 82.45 | 77.62 |
| 英语 | 92.54 | 88.38 | 86.03 | 84.67 | 72.44 |
| 法语 | 91.71 | 87.65 | 85.84 | 83.58 | 71.86 |
| 汉语普通话 | 93.03 | 82.27 | 80.69 | 81.82 | 85.46 |
| 西班牙语 | 88.14 | 87.39 | 85.62 | 83.28 | 71.39 |
| 汉语吴方言 | 89.32 | 81.86 | 80.72 | 80.43 | 81.75 |
| 汉语晋方言 | 89.48 | 82.26 | 81.24 | 80.94 | 82.81 |
Tab. 5 Comparison of average segmentation accuracy between proposed algorithm and four different algorithms with tolerance threshold of 20 ms
| 语言和方言 | 本文 算法 | 峰值分类 算法 | 振荡调幅 算法 | 迭代优化 算法 | 多级切分 算法 |
|---|---|---|---|---|---|
| 均值 | 90.70 | 84.97 | 83.36 | 82.45 | 77.62 |
| 英语 | 92.54 | 88.38 | 86.03 | 84.67 | 72.44 |
| 法语 | 91.71 | 87.65 | 85.84 | 83.58 | 71.86 |
| 汉语普通话 | 93.03 | 82.27 | 80.69 | 81.82 | 85.46 |
| 西班牙语 | 88.14 | 87.39 | 85.62 | 83.28 | 71.39 |
| 汉语吴方言 | 89.32 | 81.86 | 80.72 | 80.43 | 81.75 |
| 汉语晋方言 | 89.48 | 82.26 | 81.24 | 80.94 | 82.81 |
| 1 | 林佳庆,李涓子,张鹏. 中国语言资源采录展示平台的关键技术及其应用[J]. 语言文字应用, 2019(4):26-34. |
| LIN J Q, LI J Z, ZHANG P. The key technologies and the applications for China language resources collection and service platform[J]. Applied Linguistics, 2019(4): 26-34. | |
| 2 | ARDILA R, BRANSON M, DAVIS K, et al. Common voice: a massively-multilingual speech corpus[C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 3118-4222. |
| 3 | 杨健,李振鹏,苏鹏. 语音分割与端点检测研究综述[J]. 计算机应用, 2020, 40(1):1-7. |
| YANG J, LI Z P, SU P. Review of speech segmentation and endpoint detection[J]. Journal of Computer Applications, 2020, 40(1):1-7. | |
| 4 | BOERSMA P, WEENINK D. Praat: doing phonetics by computer[EB/OL]. [2024-05-02].. |
| 5 | GOLDMAN J P. EasyAlign: an automatic phonetic alignment tool under Praat[C]// Proceedings of the INTERSPEECH 2011. [S.l.]: International Speech Communication Association, 2011: 3233-3236. |
| 6 | 张扬,赵晓群,王缔罡. 基于时频二维能量特征的汉语音节切分方法[J]. 计算机应用, 2016, 36(11):3222-3228. |
| ZHANG Y, ZHAO X Q, WANG D G. Chinese speech segmentation into syllables based on energies in different times and frequencies [J]. Journal of Computer Applications, 2016, 36(11): 3222-3228. | |
| 7 | BROGNAUX S, DRUGMAN T. HMM-based speech segmentation: improvements of fully automatic approaches[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(1): 5-15. |
| 8 | McAULIFFE M, SOCOLOF M, MIHUC S, et al. Montreal forced aligner: trainable text-speech alignment using Kaldi[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 498-502. |
| 9 | TEYTAUT Y, ROEBEL A. Phoneme-to-audio alignment with recurrent neural networks for speaking and singing voice[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 61-65. |
| 10 | LANDSIEDEL C, EDLUND J, EYBEN F, et al. Syllabification of conversational speech using bidirectional long-short-term memory neural networks [C]// Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2011: 5256-5259. |
| 11 | PANDIA K, MURTHY H A. Acoustic unit discovery using transient and steady-state regions in speech and its applications[J]. Journal of Phonetics, 2021, 88: No.101081. |
| 12 | HYAFIL A, CERNAK M. Neuromorphic based oscillatory device for incremental syllable boundary detection[C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 1191-1195. |
| 13 | KREUK F, SHEENA Y, KESHET J, et al. Phoneme boundary detection using learnable segmental features [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 8089-8093. |
| 14 | WANG D, NARAYANAN S S. Robust speech rate estimation for spontaneous speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2007, 15(8): 2190-2201. |
| 15 | SHANKAR R, VENKATARAMAN A. Weakly supervised syllable segmentation by vowel-consonant peak classification[C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 644-648. |
| 16 | OBIN N, LAMARE F, ROEBEL A. Syll-O-Matic: an adaptive time-frequency representation for the automatic segmentation of speech into syllables[C]// Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2013: 6699-6703. |
| 17 | RÄSÄNEN O, DOYLE G, FRANK M C. Pre-linguistic segmentation of speech into syllable-like units[J]. Cognition, 2018, 171: 130-150. |
| 18 | 李洺宇,金小峰. 朝鲜语语音音节自动切分算法的研究[J]. 延边大学学报(自然科学版), 2019, 45(2): 128-135. |
| LI M Y, JIN X F. Research on automatic segmentation algorithm of Korean speech syllable[J]. Journal of Yanbian University (Natural Science Edition), 2019, 45(2): 128-135. | |
| 19 | 王彤,易绵竹. 基于元音检测的俄语语音音节端点检测[J]. 郑州大学学报(理学版), 2017, 49(4):34-39. |
| WANG T, YI M Z. Syllable endpoint detection in Russian speech based on vowel segmentation[J]. Journal of Zhengzhou University (Natural Science Edition), 2017, 49(4):34-39. | |
| 20 | KUMARI R, DEV A, KUMAR A. An efficient syllable-based speech segmentation model using fuzzy and threshold-based boundary detection[J]. International Journal of Computational Intelligence and Applications, 2022, 21(2): No.2250007. |
| 21 | 李琦,张二华. 连续汉语语音的自动切分研究[J]. 计算机与数字工程, 2023, 51(4):959-964. |
| LI Q, ZHANG E H. Research on automatic segmentation of continuous Chinese speech[J]. Computer and Digital Engineering, 2023, 51(4):959-964. | |
| 22 | LALEYE F A A, EZIN E C, MOTAMED C. Automatic text-independent syllable segmentation using singularity exponents and Rényi entropy[J]. Journal of Signal Processing Systems, 2017, 88(3): 439-451. |
| 23 | LALEYE F A A, EZIN E C, MOTAMED C. Automatic boundary detection based on entropy measures for text-independent syllable segmentation[J]. Multimedia Tools and Applications, 2017, 76(15): 16347-16368. |
| 24 | HE S, ZHAO H. Automatic syllable segmentation algorithm of Chinese speech based on MF-DFA[J]. Speech Communication, 2017, 92: 42-51. |
| 25 | PANDA S P, NAYAK A K. Automatic speech segmentation in syllable centric speech recognition system[J]. International Journal of Speech Technology, 2016, 19(1): 9-18. |
| 26 | GEETHA K, VADIVEL R. Syllable segmentation of Tamil speech signals using vowel onset point and spectral transition measure [J]. Automatic Control and Computer Sciences, 2018, 52(1):25-31. |
| 27 | KARIM R M, SUYANTO. Optimizing parameters of automatic speech segmentation into syllable units[J]. International Journal of Intelligent Systems and Applications, 2019, 11(5):9-17. |
| 28 | 北京语言大学. 一种无监督的音频与文本自动对齐方法及装置: 202310855904.1[P]. 2023-11-07. |
| Beijing Language and Culture University. An unsupervised method and device for automatic alignment of audio and text: 202310855904.1[P]. 2023-11-07. | |
| 29 | 张雪,袁佩君,王莹,等. 知觉相关的神经振荡-外界节律同步化现象[J]. 生物化学与生物物理进展, 2016, 43(4):308-315. |
| ZHANG X, YUAN P J, WANG Y, et al. Neural entrainment and perception[J]. Progress in Biochemistry and Biophysics, 2016, 43(4):308-315. | |
| 30 | 端木三. 英汉音节分析及数量对比[J]. 语言科学, 2021, 20(6):561-588. |
| DUANMU S. Syllable analysis and syllable inventories in English and Chinese[J]. Linguistic Sciences, 2021, 20(6):561-588. | |
| 31 | MADDIESON I. Syllable structure[EB/OL]. [2024-03-15].. |
| 32 | WESTER M. Syllable classification using articulatory-acoustic features[C]// Proceedings of the 8th European Conference on Speech Communication and Technology. [S.l.]: International Speech Communication Association, 2003: 233-236. |
| 33 | Team HTK. Hidden Markov model toolkit[EB/OL]. [2024-03-15].. |
| 34 | MA N. An efficient implementation of gammatone filters [EB/OL]. [2024-03-19].. |
| 35 | GROSS J, HOOGENBOOM N, THUT G, et al. Speech rhythms and multiplexed oscillatory sensory coding in the human brain [J]. PLoS Biology, 2013, 11(12): No.e1001752. |
| 36 | HYAFIL A, FONTOLAN L, KABDEBON C, et al. Speech encoding by coupled cortical theta and gamma oscillations[J]. eLife, 2015, 4: No.e06213. |
| 37 | OBIN N. Cries and whispers classification of vocal effort in expressive speech[C]// Proceedings of the INTERSPEECH 2012. [S.l.]: International Speech Communication Association, 2012: 2234-2237. |
| 38 | GAROFOLO J S, LAMEL L F, FISHER W M, et al. TIMIT acoustic-phonetic continuous speech corpus[DS/OL]. [2024-02-17]. . |
| 39 | KOLOBOV R, OKHAPKINA O, OMELCHISHINA O, et al. MediaSpeech: multilanguage ASR benchmark and dataset[EB/OL]. [2024-03-18].. |
| 40 | WANG D, ZHANG X. THCHS-30: a free Chinese speech corpus[EB/OL]. [2024-03-20].. |
| [1] | Xiang WANG, Qianqian CUI, Xiaoming ZHANG, Jianchao WANG, Zhenzhou WANG, Jialin SONG. Wireless capsule endoscopy image classification model based on improved ConvNeXt [J]. Journal of Computer Applications, 2025, 45(6): 2016-2024. |
| [2] | Zonghang WU, Dong ZHANG, Guanyu LI. Multimodal fusion recommendation algorithm based on joint self-supervised learning [J]. Journal of Computer Applications, 2025, 45(6): 1858-1868. |
| [3] | Ying HUANG, Shengmei GAO, Guang CHEN, Su LIU. Low-light image enhancement network combining signal-to-noise ratio guided dual-branch structure and histogram equalization [J]. Journal of Computer Applications, 2025, 45(6): 1971-1979. |
| [4] | Yali YANG, Ying LI, Yutao ZHANG, Peihua SONG. Review of multi-modal research methods for face recognition [J]. Journal of Computer Applications, 2025, 45(5): 1645-1657. |
| [5] | Yang ZHOU, Hui LI. Remote sensing image building extraction network based on dual promotion of semantic and detailed features [J]. Journal of Computer Applications, 2025, 45(4): 1310-1316. |
| [6] | Shiyue GUO, Jianwu DANG, Yangping WANG, Jiu YONG. 3D hand pose estimation combining attention mechanism and multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(4): 1293-1299. |
| [7] | Yiding WANG, Zehao WANG, Yaoli LI, Shaoqing CAI, Yuan YUAN. Multi-scale 2D-Adaboost microscopic image recognition algorithm of Chinese medicinal materials powder [J]. Journal of Computer Applications, 2025, 45(4): 1325-1332. |
| [8] | Zhongwei ZHANG, Jun WANG, Shudong LIU, Zhiheng WANG. Object detection in remote sensing image based on multi-scale feature fusion and weighted boxes fusion [J]. Journal of Computer Applications, 2025, 45(2): 633-639. |
| [9] | Qiurun HE, Jie HU, Bo PENG, Tianyuan LI. Fabric defect detection algorithm based on context information and multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(2): 640-646. |
| [10] | Handa MA, Yadong WU. Multi-domain spatiotemporal hierarchical graph neural network for air quality prediction [J]. Journal of Computer Applications, 2025, 45(2): 444-452. |
| [11] | Rui LI, Guanfeng LI, Dezhou HU, Wenxin GAO. Knowledge graph multi-hop reasoning model fusing path and subgraph features [J]. Journal of Computer Applications, 2025, 45(1): 32-39. |
| [12] | Pengcheng SONG, Lijun GUO, Rong ZHANG. Weakly supervised video anomaly detection with local-global temporal dependency [J]. Journal of Computer Applications, 2025, 45(1): 240-246. |
| [13] | Shang LIU, Yuwei ZHOU, Rao DAI, Linfang DONG, Meng LIU. Small target detection algorithm in remote sensing images integrating attention and contextual information [J]. Journal of Computer Applications, 2025, 45(1): 292-300. |
| [14] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [15] | Ruihua LIU, Zihe HAO, Yangyang ZOU. Gait recognition algorithm based on multi-layer refined feature fusion [J]. Journal of Computer Applications, 2024, 44(7): 2250-2257. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||