


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (1): 207-215.DOI: 10.11772/j.issn.1001-9081.2025010074
• Multimedia computing and computer simulation • Previous Articles Next Articles
Shuwen HUANG1, Keyu GUO1, Xiangyu SONG2( ), Feng HAN1, Shijie SUN2, Huansheng SONG1
), Feng HAN1, Shijie SUN2, Huansheng SONG1
Received:2025-01-20
Revised:2025-03-05
Accepted:2025-03-12
Online:2026-01-10
Published:2026-01-10
Contact:
Xiangyu SONG
About author:HUANG Shuwen, born in 2001, M. S. candidate. Her research interests include computer vision, 3D visual grounding.Supported by:
黄舒雯1, 郭柯宇1, 宋翔宇2(), 韩锋1, 孙士杰2, 宋焕生1
通讯作者:
宋翔宇
作者简介:黄舒雯(2001—),女,广西桂平人,硕士研究生, CCF会员,主要研究方向:计算机视觉、三维视觉定位基金资助:CLC Number:
Shuwen HUANG, Keyu GUO, Xiangyu SONG, Feng HAN, Shijie SUN, Huansheng SONG. Multi-target 3D visual grounding method based on monocular images[J]. Journal of Computer Applications, 2026, 46(1): 207-215.
黄舒雯, 郭柯宇, 宋翔宇, 韩锋, 孙士杰, 宋焕生. 基于单目图像的多目标三维视觉定位方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 207-215.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025010074

Fig. 1 Comparative analysis of monocular multi-target 3D visual grounding task and other tasks
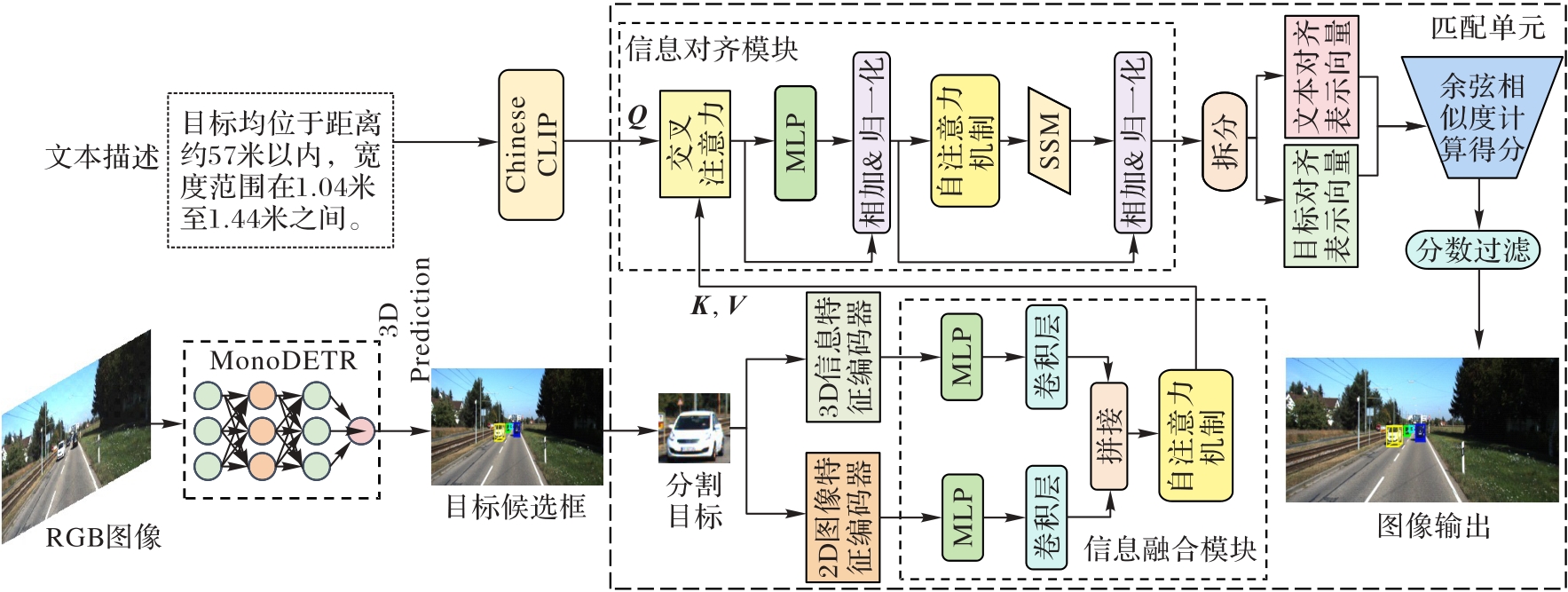
Fig. 2 Overall framework of TextVizNet
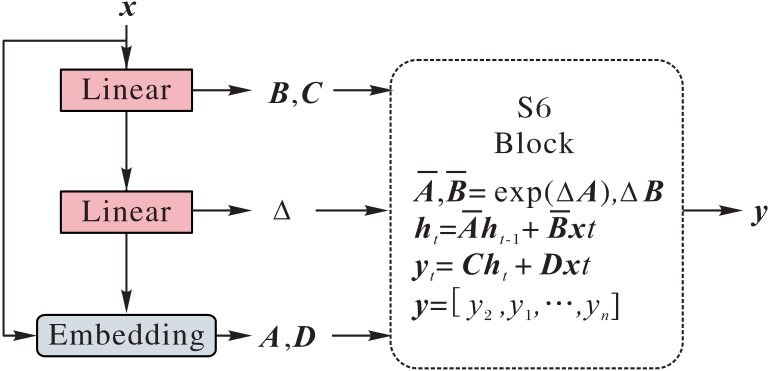
Fig. 3 Structure of SSM
| 数据集 | 样本数 | 表达数 | 范围/m | 视觉形式 | 标注类型 | 场景 | 目标类型 |
|---|---|---|---|---|---|---|---|
| ScanRefer | 11 046 | 51 583 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Sr3D | 8 863 | 83 572 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Nr3D | 5 879 | 41 503 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| SUNRefer | 7 699 | 38 495 | — | RGB-D图像 | 3D框 | 室内 | 单目标 |
| STRefer | 3 581 | 5 458 | 30 | 点云、RGB图像 | 3D框 | 室外 | 单目标 |
| Mono3DRefer | 8 228 | 41 140 | 102 | RGB | 2D/3D框 | 室外 | 单目标 |
| Mmo3DRefer | 12 763 | 6 075 | 103 | RGB | 2D/3D框 | 室外 | 多目标 |
Tab. 1 Comparison analysis of visual grounding datasets in 3D scenes
| 数据集 | 样本数 | 表达数 | 范围/m | 视觉形式 | 标注类型 | 场景 | 目标类型 |
|---|---|---|---|---|---|---|---|
| ScanRefer | 11 046 | 51 583 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Sr3D | 8 863 | 83 572 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Nr3D | 5 879 | 41 503 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| SUNRefer | 7 699 | 38 495 | — | RGB-D图像 | 3D框 | 室内 | 单目标 |
| STRefer | 3 581 | 5 458 | 30 | 点云、RGB图像 | 3D框 | 室外 | 单目标 |
| Mono3DRefer | 8 228 | 41 140 | 102 | RGB | 2D/3D框 | 室外 | 单目标 |
| Mmo3DRefer | 12 763 | 6 075 | 103 | RGB | 2D/3D框 | 室外 | 多目标 |
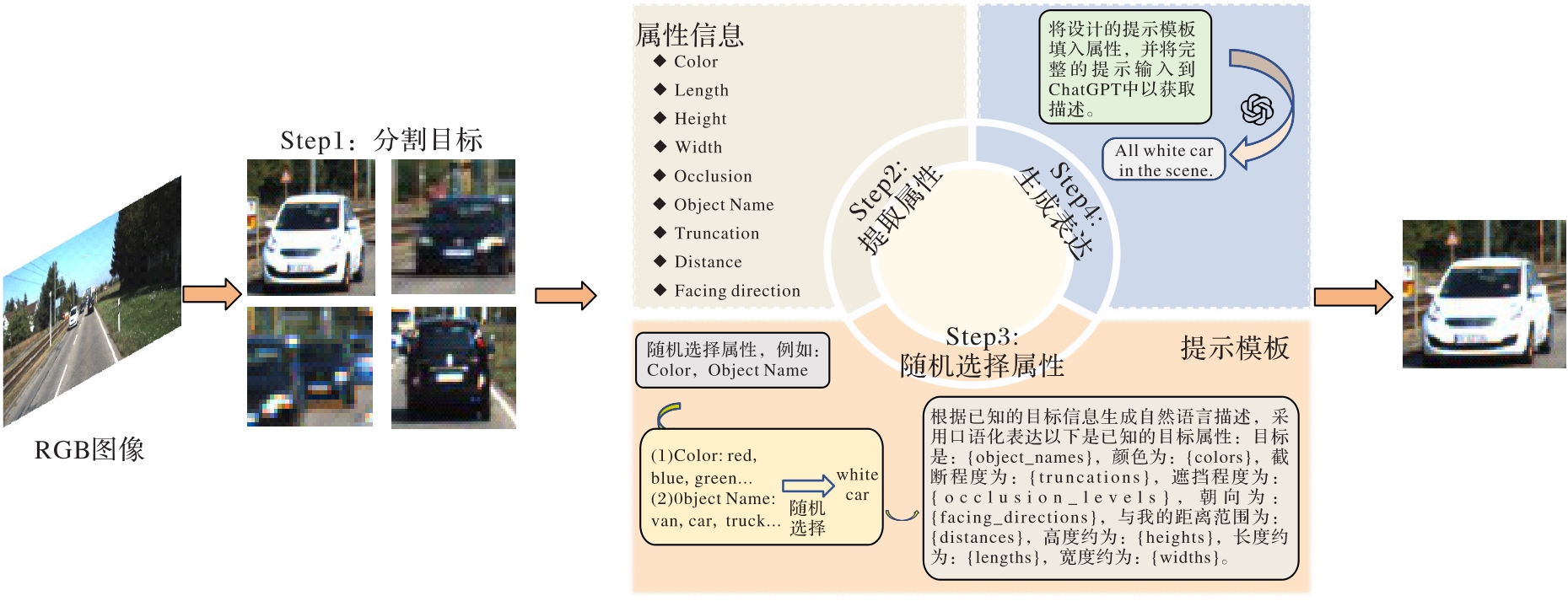
Fig. 4 Dataset construction process
| 数据集 | 单样本描述数 | 多样本描述数 | 总计 |
|---|---|---|---|
| ScanRefer | 51 583 | — | 51 583 |
| Sr3D | 83 572 | — | 83 572 |
| Nr3D | 41 503 | — | 41 503 |
| SUNRefer | 38 495 | — | 38 495 |
| STRefer | 5 458 | — | 5 458 |
| Mono3DRefer | 8 228 | — | 8 228 |
| Mmo3DRefer | 2 846 | 3 229 | 6 075 |
Tab. 2 Descriptive statistics of visual grounding datasets in 3D scenes
| 数据集 | 单样本描述数 | 多样本描述数 | 总计 |
|---|---|---|---|
| ScanRefer | 51 583 | — | 51 583 |
| Sr3D | 83 572 | — | 83 572 |
| Nr3D | 41 503 | — | 41 503 |
| SUNRefer | 38 495 | — | 38 495 |
| STRefer | 5 458 | — | 5 458 |
| Mono3DRefer | 8 228 | — | 8 228 |
| Mmo3DRefer | 2 846 | 3 229 | 6 075 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 43.03 | 37.92 | 49.72 | 2 449 | 1 513 | 1 496 |
| CORE-3DVG | 47.14 | 42.41 | 53.06 | 2 200 | 1 433 | |
| 3DVG-Transformer | 47.98 | 47.66 | 48.83 | 1 700 | 1 622 | 1 548 |
| Cross3DVG | 44.13 | 46.98 | 41.61 | 1 485 | 1 847 | 1 316 |
| Multi3DRefer | 1 459 | |||||
| TextVizNet | 58.09 | 53.45 | 63.62 | 1 566 | 1028 | 1798 |
Tab. 3 Performance comparison of TextVizNet with other methods on Mmo3DRefer test set
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 43.03 | 37.92 | 49.72 | 2 449 | 1 513 | 1 496 |
| CORE-3DVG | 47.14 | 42.41 | 53.06 | 2 200 | 1 433 | |
| 3DVG-Transformer | 47.98 | 47.66 | 48.83 | 1 700 | 1 622 | 1 548 |
| Cross3DVG | 44.13 | 46.98 | 41.61 | 1 485 | 1 847 | 1 316 |
| Multi3DRefer | 1 459 | |||||
| TextVizNet | 58.09 | 53.45 | 63.62 | 1 566 | 1028 | 1798 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 54.41 | 49.83 | 59.92 | 4 690 | 3 116 | 4 658 |
| CORE-3DVG | 58.21 | 54.05 | 63.06 | 2 902 | 4 953 | |
| 3DVG-Transformer | 60.47 | 65.76 | 4063 | 2 689 | ||
| Cross3DVG | 58.27 | 51.93 | 66.37 | 5 006 | 2 740 | 5 407 |
| Multi3DRefer | 54.73 | 4 430 | 5 355 | |||
| TextVizNet | 64.46 | 57.05 | 74.08 | 4 551 | 2 115 | 6 046 |
Tab. 4 Performance comparison of TextVizNet with other methods on Mono3DRefer test set
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 54.41 | 49.83 | 59.92 | 4 690 | 3 116 | 4 658 |
| CORE-3DVG | 58.21 | 54.05 | 63.06 | 2 902 | 4 953 | |
| 3DVG-Transformer | 60.47 | 65.76 | 4063 | 2 689 | ||
| Cross3DVG | 58.27 | 51.93 | 66.37 | 5 006 | 2 740 | 5 407 |
| Multi3DRefer | 54.73 | 4 430 | 5 355 | |||
| TextVizNet | 64.46 | 57.05 | 74.08 | 4 551 | 2 115 | 6 046 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 30.09 | 28.76 | 31.55 | 2 715 | 2 378 | 1 096 |
| CORE-3DVG | 32.44 | 31.90 | 33.01 | 2 541 | 2 415 | 1 190 |
| 3DVG-Transformer | 35.04 | 2 314 | ||||
| Cross3DVG | 28.63 | 26.89 | 30.63 | 2 490 | 2 075 | 916 |
| Multi3DRefer | 32.50 | 28.51 | 2 655 | 1 059 | ||
| TextVizNet | 43.11 | 38.76 | 48.56 | 2 130 | 1 428 | 1 348 |
Tab. 5 Performance comparison of TextVizNet with other methods on Mmo3DRefer test set (added Gaussian noise)
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 30.09 | 28.76 | 31.55 | 2 715 | 2 378 | 1 096 |
| CORE-3DVG | 32.44 | 31.90 | 33.01 | 2 541 | 2 415 | 1 190 |
| 3DVG-Transformer | 35.04 | 2 314 | ||||
| Cross3DVG | 28.63 | 26.89 | 30.63 | 2 490 | 2 075 | 916 |
| Multi3DRefer | 32.50 | 28.51 | 2 655 | 1 059 | ||
| TextVizNet | 43.11 | 38.76 | 48.56 | 2 130 | 1 428 | 1 348 |
| 信息对齐模块 | 信息融合模块 | P | R | F1-score |
|---|---|---|---|---|
| × | × | 44.39 | 50.04 | 47.05 |
| √ | × | 51.48 | 61.24 | 55.94 |
| √ | √ | 53.45 | 63.74 | 58.14 |
Tab. 6 Ablation study results for each module of TextVizNet on Mmo3DRefer test set
| 信息对齐模块 | 信息融合模块 | P | R | F1-score |
|---|---|---|---|---|
| × | × | 44.39 | 50.04 | 47.05 |
| √ | × | 51.48 | 61.24 | 55.94 |
| √ | √ | 53.45 | 63.74 | 58.14 |
| 3D IoU阈值 | P/% | R/% | F1-score/% |
|---|---|---|---|
| 0.25 | 56.27 | 68.24 | 61.68 |
| 0.50 | 53.45 | 63.74 | 58.14 |
| 0.60 | 49.33 | 57.42 | 53.07 |
| 0.75 | 36.89 | 45.31 | 40.67 |
Tab. 7 Model performance comparison with different 3D IoU thresholds on Mmo3DRefer test set
| 3D IoU阈值 | P/% | R/% | F1-score/% |
|---|---|---|---|
| 0.25 | 56.27 | 68.24 | 61.68 |
| 0.50 | 53.45 | 63.74 | 58.14 |
| 0.60 | 49.33 | 57.42 | 53.07 |
| 0.75 | 36.89 | 45.31 | 40.67 |

Fig. 5 Visualization results on Mmo3DRefer dataset
| [1] | DENG C, WU Q, WU Q, et al. Visual grounding via accumulated attention [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7746-7755. |
| [2] | ZHANG Y, CHEN X, JIA J, et al. Text-visual prompting for efficient 2D temporal video grounding [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 14794-14804. |
| [3] | DENG J, YANG Z, CHEN T, et al. TransVG: end-to-end visual grounding with Transformers [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1749-1759. |
| [4] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [5] | CHEN Y C, LI L, YU L, et al. UNITER: UNiversal Image-TExt Representation learning [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 104-120. |
| [6] | HUANG S, CHEN Y, JIA J, et al. Multi-View Transformer for 3D visual grounding [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15503-15512. |
| [7] | LIU Y, SUN B, WANG Y, et al. Talk to parallel LiDARs: a human-LiDAR interaction method based on 3D visual grounding [C]// Proceedings of the 2024 European Conference on Computer Vision Workshops, LNCS 15629. Cham: Springer, 2025: 305-321. |
| [8] | LU Z, PEI Y, WANG G, et al. ScanERU: interactive 3D visual grounding based on embodied reference understanding [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 3936-3944. |
| [9] | ZHU Z, ZHANG Z, MA X, et al. Unifying 3D vision-language understanding via promptable queries [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15102. Cham: Springer, 2025: 188-206. |
| [10] | YANG L, YUAN C, ZHANG Z, et al. Exploiting contextual objects and relations for 3D visual grounding [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 49542-49554. |
| [11] | CUI K, SHEN L, ZHENG Y, et al. Talk2Radar: talking to mmWave radars via smartphone speaker [C]// Proceedings of the 2024 IEEE Conference on Computer Communications. Piscataway: IEEE, 2024: 2358-2367. |
| [12] | YANG S, LIU J, ZHANG R, et al. LiDAR-LLM: exploring the potential of large language models for 3D LiDAR understanding [C]// Proceedings of the 39th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2025: 9247-9255. |
| [13] | LI M, WANG C, FENG W, et al. Iterative robust visual grounding with masked reference based centerpoint supervision [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 4653-4658. |
| [14] | YANG L, XU Y, YUAN C, et al. Improving visual grounding with visual-linguistic verification and iterative reasoning [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 9489-9498. |
| [15] | CHEN S, LI B. Multi-modal dynamic graph transformer for visual grounding [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15513-15522. |
| [16] | ZHANG Q, YUAN J. Semantic-aligned cross-modal visual grounding network with Transformers [J]. Applied Sciences, 2023, 13(9): No.5649. |
| [17] | 陆庆阳,袁广林,朱虹,等.一种基于对比学习大模型的视觉定位方法[J].电子学报, 2024, 52(10): 3448-3458. |
| LU Q Y, YUAN G L, ZHU H, et al. A visual grounding method with contrastive learning large model [J]. Acta Electronica Sinica, 2024, 52(10): 3448-3458. | |
| [18] | BIANCHI F, ATTANASIO G, PISONI R, et al. Contrastive language-image pre-training for the Italian language [C]// Proceedings of the 2023 Italian Conference on Computational Linguistics. Aachen: CEUR-WS.org, 2023: 78-85. |
| [19] | LI Y, YU A W, MENG T, et al. DeepFusion: lidar-camera deep fusion for multi-modal 3D object detection [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17161-17170. |
| [20] | 谢凌芙.单视角RGBD图的三维视觉文本定位算法研究[D].西安:西安理工大学, 2024. |
| XIE L F. Research on 3D visual grounding based on single-vision RGBD images [D]. Xi'an: Xi'an University of Technology, 2024. | |
| [21] | ZHAO L, CAI D, SHENG L, et al. 3DVG-Transformer: relation modeling for visual grounding on point clouds [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2908-2917. |
| [22] | ZHANG Y, GONG Z, CHANG A X. Multi3DRefer: grounding text description to multiple 3D objects [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 15179-15190. |
| [23] | MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5632-5640. |
| [24] | BAO W, XU B, CHEN Z. MonoFENet: monocular 3D object detection with feature enhancement networks [J]. IEEE Transactions on Image Processing, 2020, 29: 2753-2765. |
| [25] | 柳长源,高阁君,刘金凤.采用深度感知Swin Transformer的单目三维目标检测方法[J/OL].北京工业大学学报[2025-03-03]. . |
| LIU C Y, GAO G J, LIU J F. Monocular three-dimensional object detection based on depth perception Swin Transformer [J]. Journal of Beijing University of Technology[2025-03-03]. . | |
| [26] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [27] | ZHANG R, QIU H, WANG T, et al. MonoDETR: depth-guided transformer for monocular 3D object detection [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 9121-9132. |
| [28] | YANG A, PAN J, LIN J, et al. Chinese CLIP: contrastive vision-language pretraining in Chinese [EB/OL]. [2025-01-15]. . |
| [29] | GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [EB/OL]. [2025-01-15]. . |
| [30] | HO Y, WOOKEY S. The real-world-weight cross-entropy loss function: modeling the costs of mislabeling [J]. IEEE Access, 2020, 8: 4806-4813. |
| [31] | CHEN D Z, CHANG A X, NIEẞNER M. ScanRefer: 3D object localization in RGB-D scans using natural language [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12365. Cham: Springer, 2020: 202-221. |
| [32] | ACHLIOPTAS P, ABDELREHEEM A, XIA F, et al. ReferIt3D: neural listeners for fine-grained 3D object identification in real-world scenes [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 422-440. |
| [33] | LIU H, LIN A, HAN X, et al. Refer-it-in-RGBD: a bottom-up approach for 3D visual grounding in RGBD images [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6028-6037. |
| [34] | LIN Z, PENG X, CONG P, et al. WildRefer: 3D object localization in large-scale dynamic scenes with multi-modal visual data and natural language [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15104. Cham: Springer, 2025: 456-473. |
| [35] | ZHAN Y, YUAN Y, XIONG Z. Mono3DVG: 3D visual grounding in monocular images [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6988-6996. |
| [36] | GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset [J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237. |
| [37] | CAI D, ZHAO L, ZHANG J, et al. 3DJCG: a unified framework for joint dense captioning and visual grounding on 3D point clouds [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16443-16452. |
| [38] | MIYANISHI T, AZUMA D, KURITA S, et al. Cross3DVG: cross-dataset 3D visual grounding on different RGB-D scans [C]// Proceedings of the 2024 International Conference on 3D Vision. Piscataway: IEEE, 2024: 717-727. |
| [1] | Binhong XIE, Rui WANG, Rui ZHANG, Yingjun ZHANG. Agent prototype distillation algorithm for few-shot object detection [J]. Journal of Computer Applications, 2026, 46(1): 233-241. |
| [2] | Shiwei LI, Yufeng ZHOU, Pengfei SUN, Weisong LIU, Zhuxuan MENG, Haojie LIAN. Point cloud data augmentation method based on scattering and absorption effects of coal dust on LiDAR electromagnetic waves [J]. Journal of Computer Applications, 2026, 46(1): 331-340. |
| [3] | Yu SANG, Tong GONG, Chen ZHAO, Bowen YU, Siman LI. Domain-adaptive nighttime object detection method with photometric alignment [J]. Journal of Computer Applications, 2026, 46(1): 242-251. |
| [4] | Jiaxiang ZHANG, Xiaoming LI, Jiahui ZHANG. Few-shot object detection algorithm based on new category feature enhancement and metric mechanism [J]. Journal of Computer Applications, 2025, 45(9): 2984-2992. |
| [5] | Lili WEI, Lirong YAN, Xiaofen TANG. Contextual semantic representation and pixel relationship correction for few-shot object detection [J]. Journal of Computer Applications, 2025, 45(9): 2993-3002. |
| [6] | Binhong XIE, Yingkun LA, Yingjun ZHANG, Rui ZHANG. Semi-supervised object detection framework guided by self-paced learning [J]. Journal of Computer Applications, 2025, 45(8): 2546-2554. |
| [7] | Chengzhi YAN, Ying CHEN, Kai ZHONG, Han GAO. 3D object detection algorithm based on multi-scale network and axial attention [J]. Journal of Computer Applications, 2025, 45(8): 2537-2545. |
| [8] | Liang CHEN, Xuan WANG, Kun LEI. Helmet wearing detection algorithm for complex scenarios based on cross-layer multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(7): 2333-2341. |
| [9] | Zimo ZHANG, Xuezhuan ZHAO. Multi-scale sparse graph guided vision graph neural networks [J]. Journal of Computer Applications, 2025, 45(7): 2188-2194. |
| [10] | Pingping YU, Yuting YAN, Xinliang TANG, He SU, Jianchao WANG. Multi-object tracking algorithm for construction machinery in transmission line scenarios [J]. Journal of Computer Applications, 2025, 45(7): 2351-2360. |
| [11] | Yingjun ZHANG, Weiwei YAN, Binhong XIE, Rui ZHANG, Wangdong LU. Gradient-discriminative and feature norm-driven open-world object detection [J]. Journal of Computer Applications, 2025, 45(7): 2203-2210. |
| [12] | Peiyu JIANG, Yongguang WANG, Yating REN, Shuochen LI, Huobin TAN. Object detection uncertainty measurement scheme based on guide to the expression of uncertainty in measurement [J]. Journal of Computer Applications, 2025, 45(7): 2162-2168. |
| [13] | Qingqing ZHAO, Bin HU. Moving pedestrian detection neural network with invariant global sparse contour point representation [J]. Journal of Computer Applications, 2025, 45(4): 1271-1284. |
| [14] | Liwei ZHANG, Quan LIANG, Yutao HU, Qiaole ZHU. Channel shuffle attention mechanism based on group convolution [J]. Journal of Computer Applications, 2025, 45(4): 1069-1076. |
| [15] | Yang HOU, Qiong ZHANG, Zixuan ZHAO, Zhengyu ZHU, Xiaobo ZHANG. YOLOv5s-MRD: efficient fire and smoke detection algorithm for complex scenarios based on YOLOv5s [J]. Journal of Computer Applications, 2025, 45(4): 1317-1324. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||