


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (5): 1460-1467.DOI: 10.11772/j.issn.1001-9081.2025050558
• Artificial intelligence • Previous Articles
Yuqian HUANG1,2,3, Hui HUANG1,2,3, Yongbin QIN1,2,3( ), Ruizhang HUANG1,2,3, Yanping CHEN1,2,3, Yulin ZHOU1,2,3, Qian SUN4
), Ruizhang HUANG1,2,3, Yanping CHEN1,2,3, Yulin ZHOU1,2,3, Qian SUN4
Received:2025-05-21
Revised:2025-06-16
Accepted:2025-06-26
Online:2025-07-10
Published:2026-05-10
Contact:
Yongbin QIN
About author:HUANG Yuqian, born in 2001, M. S. candidate. Her research interests include natural language processing, information extraction.Supported by:
黄雨倩1,2,3, 黄辉1,2,3, 秦永彬1,2,3(), 黄瑞章1,2,3, 陈艳平1,2,3, 周裕林1,2,3, 孙倩4
通讯作者:
秦永彬
作者简介:黄雨倩(2001—),女,湖北武汉人,硕士研究生,主要研究方向:自然语言处理、信息抽取基金资助:CLC Number:
Yuqian HUANG, Hui HUANG, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Yulin ZHOU, Qian SUN. Judicial element extraction method by integrating global and local semantics[J]. Journal of Computer Applications, 2026, 46(5): 1460-1467.
黄雨倩, 黄辉, 秦永彬, 黄瑞章, 陈艳平, 周裕林, 孙倩. 融合全局和局部语义的司法要素抽取方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1460-1467.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050558
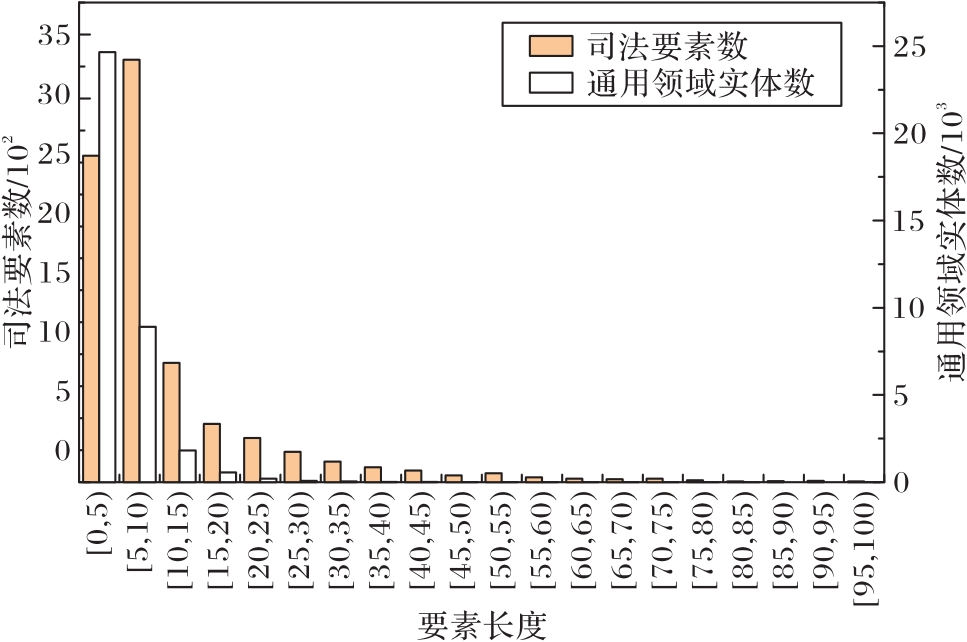
Fig. 1 Comparison of length distribution of elements in general field and judicial field
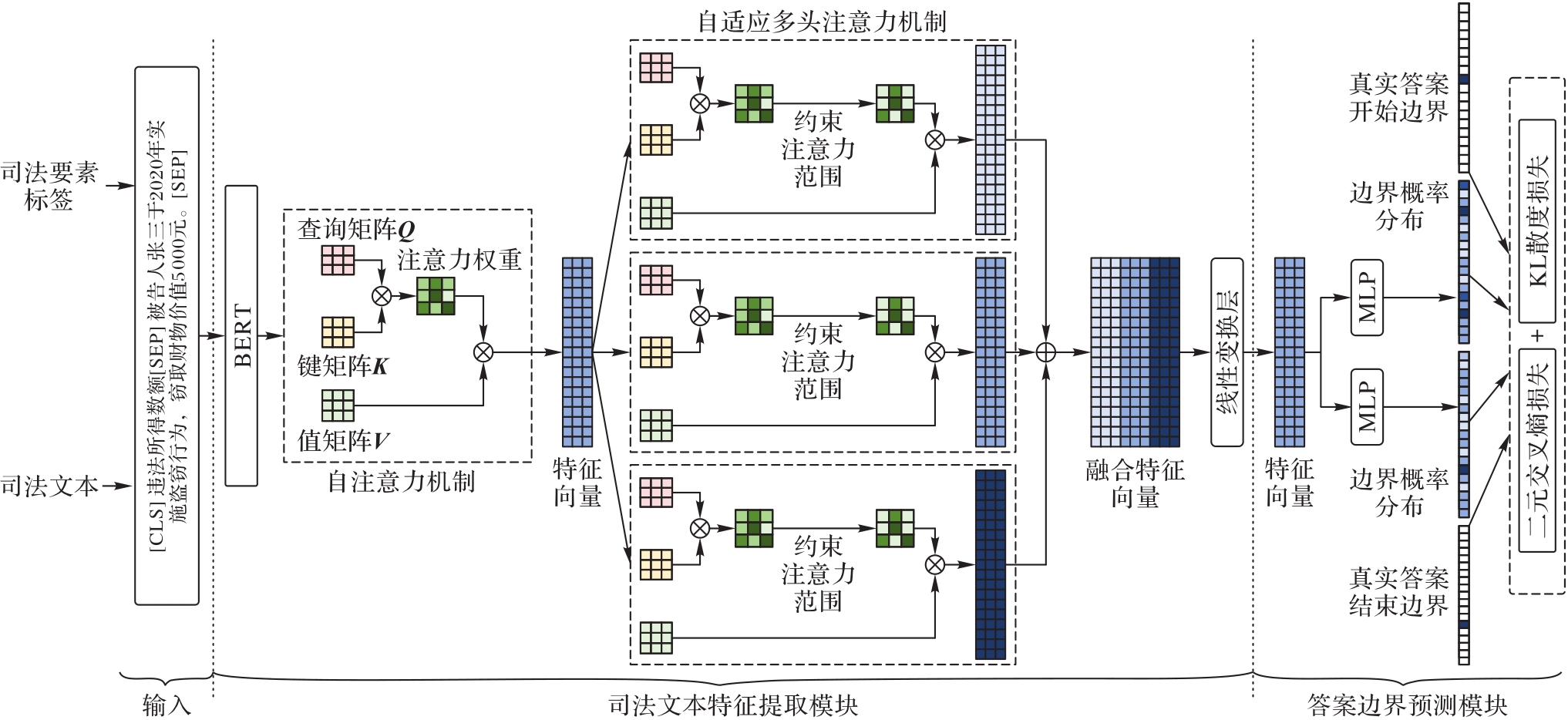
Fig. 2 Framework of judicial element extraction method fusing global and local semantics
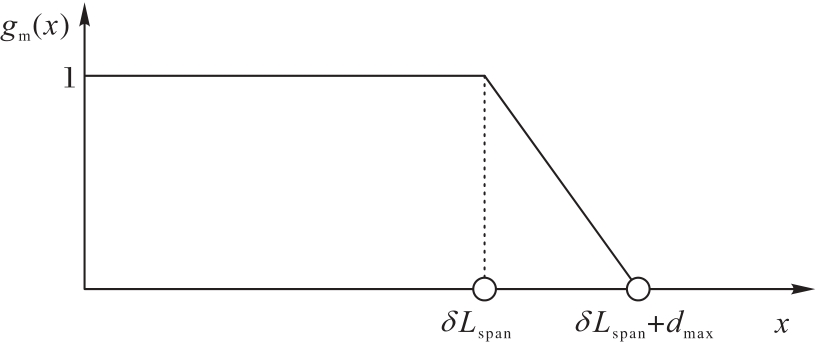
Fig. 3 Attention mask function diagram
| 数据集 | LAIC2023 | CAIL2021 | ||||
|---|---|---|---|---|---|---|
| 样本数 | 字符数 | 实体数 | 样本数 | 字符数 | 实体数 | |
| 训练集 | 1 088 | 1 718 490 | 5 365 | 4 197 | 268 004 | 21 326 |
| 测试集 | 136 | 221 600 | 725 | 525 | 34 158 | 2 726 |
| 验证集 | 136 | 204 453 | 720 | 525 | 32 848 | 2 609 |
Tab. 1 Experimental datasets
| 数据集 | LAIC2023 | CAIL2021 | ||||
|---|---|---|---|---|---|---|
| 样本数 | 字符数 | 实体数 | 样本数 | 字符数 | 实体数 | |
| 训练集 | 1 088 | 1 718 490 | 5 365 | 4 197 | 268 004 | 21 326 |
| 测试集 | 136 | 221 600 | 725 | 525 | 34 158 | 2 726 |
| 验证集 | 136 | 204 453 | 720 | 525 | 32 848 | 2 609 |
| 类型 | 方法 | LAIC2023 | CAIL2021 | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| 基于序列标注的方法 | BERT-BiLSTM-CRF[ | 68.23 | 54.78 | 61.38 | 87.79 | 85.32 | 86.54 |
| Layered[ | 69.13 | 56.25 | 62.03 | 84.30 | 87.34 | 86.01 | |
| Pyramid[ | 71.58 | 55.49 | 62.52 | 88.76 | 87.13 | 87.18 | |
| 基于跨度的方法 | MRC[ | 70.58 | 56.37 | 62.68 | 89.15 | ||
| Boundary Smoothing[ | 70.61 | 55.83 | 62.36 | 87.14 | 86.12 | 86.63 | |
| DiffusionNER[ | 58.90 | 82.33 | 78.61 | 80.43 | |||
| BERT-BiLSTM-SPAN[ | 70.85 | 59.38 | 64.61 | 89.42 | 89.55 | ||
| 其他方法 | CodeIE[ | 52.27 | 53.64 | 52.95 | 50.53 | 55.96 | 53.11 |
| PromptNER[ | 54.38 | 55.69 | 55.03 | 56.52 | 57.91 | 57.21 | |
| Qwen-7b-chat[ | 56.37 | 57.94 | 57.14 | 53.94 | 63.33 | 58.26 | |
| Seq2seq[ | 62.52 | 61.70 | 83.16 | 87.83 | 85.43 | ||
| BiFlaG[ | 50.62 | 52.36 | 51.48 | 63.21 | 71.22 | 66.98 | |
| 基于跨度的方法 | 本文方法 | 74.91 | 62.87 | 68.36 | 91.35 | 90.23 | 90.79 |
Tab. 2 Comparison of model performance across different datasets
| 类型 | 方法 | LAIC2023 | CAIL2021 | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| 基于序列标注的方法 | BERT-BiLSTM-CRF[ | 68.23 | 54.78 | 61.38 | 87.79 | 85.32 | 86.54 |
| Layered[ | 69.13 | 56.25 | 62.03 | 84.30 | 87.34 | 86.01 | |
| Pyramid[ | 71.58 | 55.49 | 62.52 | 88.76 | 87.13 | 87.18 | |
| 基于跨度的方法 | MRC[ | 70.58 | 56.37 | 62.68 | 89.15 | ||
| Boundary Smoothing[ | 70.61 | 55.83 | 62.36 | 87.14 | 86.12 | 86.63 | |
| DiffusionNER[ | 58.90 | 82.33 | 78.61 | 80.43 | |||
| BERT-BiLSTM-SPAN[ | 70.85 | 59.38 | 64.61 | 89.42 | 89.55 | ||
| 其他方法 | CodeIE[ | 52.27 | 53.64 | 52.95 | 50.53 | 55.96 | 53.11 |
| PromptNER[ | 54.38 | 55.69 | 55.03 | 56.52 | 57.91 | 57.21 | |
| Qwen-7b-chat[ | 56.37 | 57.94 | 57.14 | 53.94 | 63.33 | 58.26 | |
| Seq2seq[ | 62.52 | 61.70 | 83.16 | 87.83 | 85.43 | ||
| BiFlaG[ | 50.62 | 52.36 | 51.48 | 63.21 | 71.22 | 66.98 | |
| 基于跨度的方法 | 本文方法 | 74.91 | 62.87 | 68.36 | 91.35 | 90.23 | 90.79 |
| 数据集 | 方法 | P | R | F1 |
|---|---|---|---|---|
| LAIC2023 | -联合嵌入 | 73.58 | 61.36 | 66.92 |
| -注意力特征融合 | 72.12 | 60.35 | 66.07 | |
| -KL散度损失 | 73.36 | 61.47 | 66.89 | |
| 本文模型 | 74.91 | 62.87 | 68.36 | |
| CAIL2021 | -联合嵌入 | 90.24 | 89.63 | 89.93 |
| -注意力特征融合 | 88.91 | 89.03 | 88.97 | |
| -KL散度损失 | 89.42 | 90.33 | 89.87 | |
| 本文模型 | 91.35 | 90.23 | 90.79 |
Tab. 3 Ablation experimental results
| 数据集 | 方法 | P | R | F1 |
|---|---|---|---|---|
| LAIC2023 | -联合嵌入 | 73.58 | 61.36 | 66.92 |
| -注意力特征融合 | 72.12 | 60.35 | 66.07 | |
| -KL散度损失 | 73.36 | 61.47 | 66.89 | |
| 本文模型 | 74.91 | 62.87 | 68.36 | |
| CAIL2021 | -联合嵌入 | 90.24 | 89.63 | 89.93 |
| -注意力特征融合 | 88.91 | 89.03 | 88.97 | |
| -KL散度损失 | 89.42 | 90.33 | 89.87 | |
| 本文模型 | 91.35 | 90.23 | 90.79 |
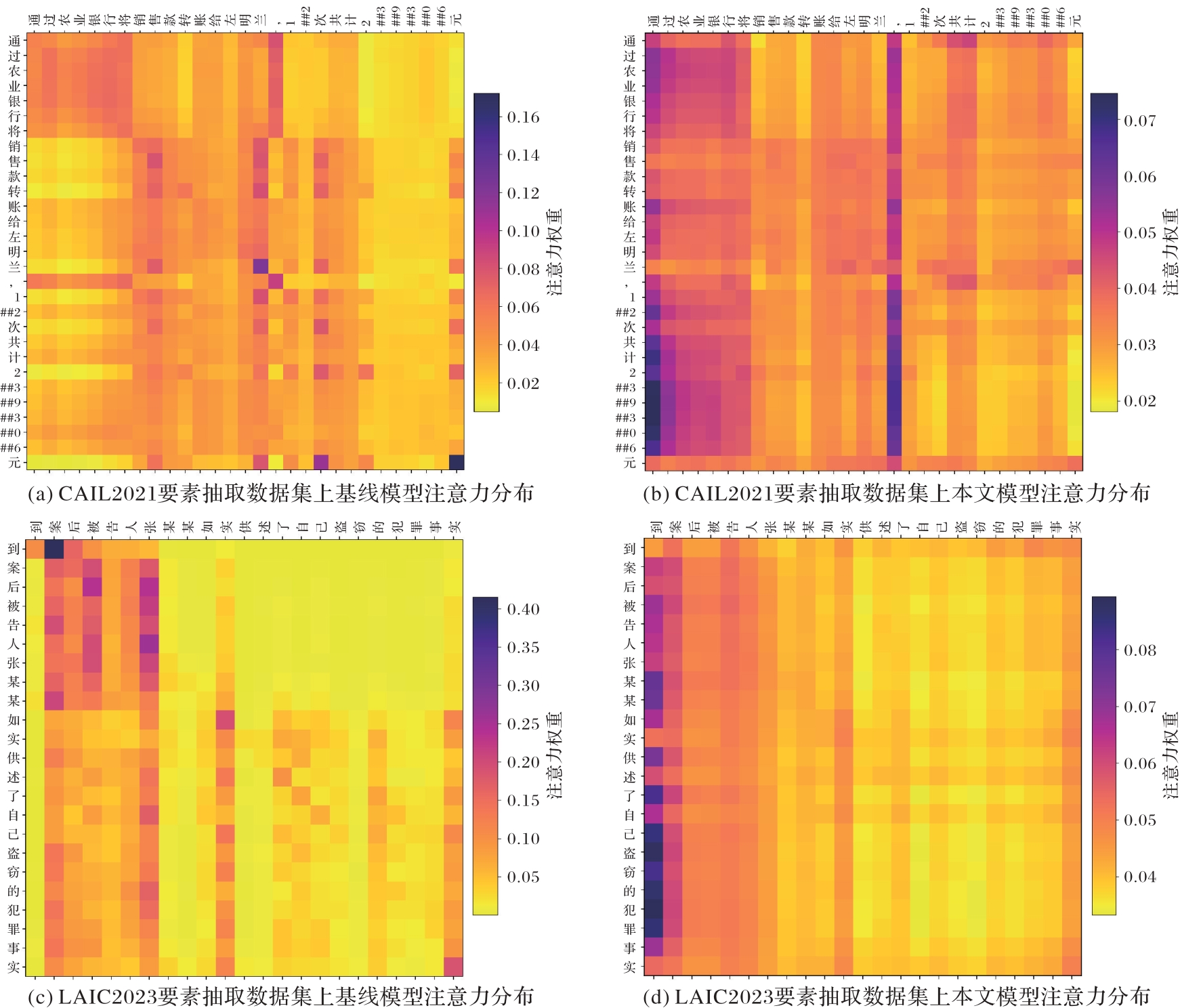
Fig. 4 Attention score heatmaps
| 参数 | 取值 | P/% | R/% | F1/% |
|---|---|---|---|---|
| 12 | 74.91 | 62.87 | 68.36 | |
| 24 | 74.75 | 62.47 | 68.06 | |
| 46 | 74.48 | 62.13 | 67.75 | |
| 12 | 74.91 | 62.87 | 68.36 | |
| 24 | 74.22 | 62.65 | 67.95 | |
| 46 | 74.11 | 62.16 | 67.61 |
Tab. 4 Parameter analysis
| 参数 | 取值 | P/% | R/% | F1/% |
|---|---|---|---|---|
| 12 | 74.91 | 62.87 | 68.36 | |
| 24 | 74.75 | 62.47 | 68.06 | |
| 46 | 74.48 | 62.13 | 67.75 | |
| 12 | 74.91 | 62.87 | 68.36 | |
| 24 | 74.22 | 62.65 | 67.95 | |
| 46 | 74.11 | 62.16 | 67.61 |
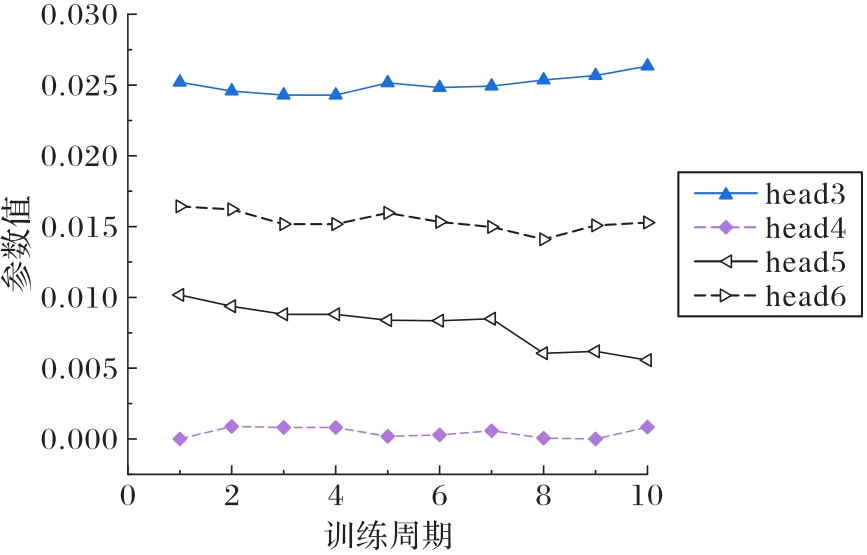
Fig. 5 Adaptive learning trends of parameter δ
| 案例 | 微调Qwen-7b-chat模型抽取结果 | 本文模型 |
|---|---|---|
| 1 | “未经商标注册所有人许可”:“假冒注册商标” | “商标种类=1”:“DANIELWELLINGTON” |
| “伪造、擅自制造 ”:“非法制造的注册商标标识” | “伪造、擅自制造 ”:“制作假冒” | |
| “伪造、擅自制造商标标识数量 ”:“134 800件” | “伪造、擅自制造商标标识数量”:“134 800件” | |
| “他人注册商标标识”:“DANIELWELLINGTON” | “他人注册商标标识”:“假冒注册商标DANIELWELLINGTON的包装盒” | |
| 2 | “销售”: “销售” | “销售”: “销售” |
| “假冒注册商标的商品”:“假冒苹果品牌的手机屏幕、耳机、充电器、手机壳等商品” | “假冒注册商标的商品”: “涉案苹果品牌的手机屏幕、耳机、充电器、手机壳” | |
| “销售金额”: “4.9万余元” | “销售金额”: “4.9万余元” | |
| “货值金额(未销售)”:“17.2万余元” | “货值金额(未销售)”: “17.2万余元” | |
| “故意”: “合伙经营深圳市钰创科技有限公司,对外销售涉案苹果品牌的手机屏幕、耳机、充电器、手机壳等商品” | “故意”: “其中被告人罗创越主要负责涉案苹果品牌的手机屏幕的进货及涉案苹果品牌的商品的对外销售,被告人邹裕炫负责涉案苹果品牌的耳机、充电器、手机壳等商品的进货” |
Tab. 5 Case study
| 案例 | 微调Qwen-7b-chat模型抽取结果 | 本文模型 |
|---|---|---|
| 1 | “未经商标注册所有人许可”:“假冒注册商标” | “商标种类=1”:“DANIELWELLINGTON” |
| “伪造、擅自制造 ”:“非法制造的注册商标标识” | “伪造、擅自制造 ”:“制作假冒” | |
| “伪造、擅自制造商标标识数量 ”:“134 800件” | “伪造、擅自制造商标标识数量”:“134 800件” | |
| “他人注册商标标识”:“DANIELWELLINGTON” | “他人注册商标标识”:“假冒注册商标DANIELWELLINGTON的包装盒” | |
| 2 | “销售”: “销售” | “销售”: “销售” |
| “假冒注册商标的商品”:“假冒苹果品牌的手机屏幕、耳机、充电器、手机壳等商品” | “假冒注册商标的商品”: “涉案苹果品牌的手机屏幕、耳机、充电器、手机壳” | |
| “销售金额”: “4.9万余元” | “销售金额”: “4.9万余元” | |
| “货值金额(未销售)”:“17.2万余元” | “货值金额(未销售)”: “17.2万余元” | |
| “故意”: “合伙经营深圳市钰创科技有限公司,对外销售涉案苹果品牌的手机屏幕、耳机、充电器、手机壳等商品” | “故意”: “其中被告人罗创越主要负责涉案苹果品牌的手机屏幕的进货及涉案苹果品牌的商品的对外销售,被告人邹裕炫负责涉案苹果品牌的耳机、充电器、手机壳等商品的进货” |
| 模型 | F1/% | ||
|---|---|---|---|
| 短要素 | 中要素 | 长要素 | |
| Pyramid | 62.86 | 57.67 | |
| DiffusionNER | 63.25 | ||
| Seq2seq | 62.52 | 63.74 | 55.75 |
| 本文模型 | 67.46 | 68.51 | 69.39 |
Tab. 6 Analysis of extraction effects at different granularities
| 模型 | F1/% | ||
|---|---|---|---|
| 短要素 | 中要素 | 长要素 | |
| Pyramid | 62.86 | 57.67 | |
| DiffusionNER | 63.25 | ||
| Seq2seq | 62.52 | 63.74 | 55.75 |
| 本文模型 | 67.46 | 68.51 | 69.39 |
| [1] | 李珊.公众法感融入司法裁判的实践路径[J].法律适用,2024(4):144-158. |
| LI S. The practice path of integrating public legal sense into judicial decision[J]. Journal of Law Application, 2024(4): 144-158. | |
| [2] | 王玉薇,张丹丹,赵勇行.人工智能辅助量刑的法律风险及规制路径[J].黑河学院学报,2022,13(3):16-19. |
| WANG Y W, ZHANG D D, ZHAO Y H. Legal risks and regulatory paths of sentencing assisted by artificial intelligence[J]. Journal of Heihe University, 2022, 13(3): 16-19. | |
| [3] | 王燕玲.论命名实体识别技术在司法大数据中的适用[J].政法论坛,2022,40(5):40-52. |
| WANG Y L. On the application of named entity recognition technology in judicial big data[J]. Tribune of Political Science and Law, 2022, 40(5): 40-52. | |
| [4] | CHITICARIU L, KRISHAMURTHY R, LI Y, et al. Domain adaptation of rule-based annotators for named-entity recognition tasks[C]// Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2010: 1002-1012. |
| [5] | TANG P, YANG P, SHI Y, et al. Recognizing Chinese judicial named entity using BiLSTM-CRF[J]. Journal of Physics: Conference Series, 2020, 1592: No.012040. |
| [6] | STRUBELL E, VERGA P, BELANGER D, et al. Fast and accurate entity recognition with iterated dilated convolutions[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 2670-2680. |
| [7] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [8] | SENAY G, SALIN E. Masked ELMo: an evolution of ELMo towards fully contextual RNN language models[EB/OL]. [2024-11-07].. |
| [9] | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[EB/OL]. [2025-03-12].. |
| [10] | DAI Z, WANG X, NI P, et al. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records[C]// Proceedings of the 12th International Congress on Image and Signal Processing. Piscataway: IEEE, 2019: 1-5. |
| [11] | 李春楠,王雷,孙媛媛,等.基于BERT的盗窃罪法律文书命名实体识别方法[J].中文信息学报,2021,35(8):73-81. |
| LI C N, WANG L, SUN Y Y, et al. BERT based named entity recognition for legal texts on theft cases[J]. Journal of Chinese Information Technology, 2021, 35(8): 73-81. | |
| [12] | ZHANG H, GUO J, WANG Y, et al. Judicial nested named entity recognition method with MRC framework[J]. International Journal of Cognitive Computing in Engineering, 2023, 4: 118-126. |
| [13] | 黄辉,秦永彬,陈艳平,等.基于BERT阅读理解框架的司法要素抽取方法[J].大数据,2021,7(6):19-29. |
| HUANG H, QIN Y B, CHEN Y P, et al. Legal element extraction method based on BERT reading comprehension framework[J]. Big Data Research, 2021, 7(6): 19-29. | |
| [14] | 窦文琦,陈艳平,秦永彬,等.基于机器阅读理解的案件要素识别方法[J].计算机工程与设计,2023,44(8):2475-2481. |
| DOU W Q, CHEN Y P, QIN Y B, et al. Method for case element recognition based on machine reading comprehension[J]. Computer Engineering and Design, 2023, 44(8): 2475-2481. | |
| [15] | SOHRAB M G, MIWA M. Deep exhaustive model for nested named entity recognition[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 2843-2849. |
| [16] | YU J, BOHNET B, POESIO M. Named entity recognition as dependency parsing[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6470-6476. |
| [17] | WANG S H, SUN X, LI X, et al. GPT-NER: named entity recognition via large language models[C]// Findings of the Association for Computational Linguistics: NAACL 2025. Stroudsburg: ACL, 2025: 4257-4275. |
| [18] | ZHANG J, LIU X, LAI X, et al. 2INER: instructive and in-context learning on few-shot named entity recognition[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Stroudsburg: ACL, 2023: 3940-3951. |
| [19] | POLAK M P, MORGAN D. Extracting accurate materials data from research papers with conversational language models and prompt engineering[J]. Nature Communications, 2024, 15(1): No.1569. |
| [20] | WEI X, CUI X, CHENG N, et al. ChatIE: zero-shot information extraction via chatting with ChatGPT[EB/OL]. [2025-01-09].. |
| [21] | SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Stroudsburg: ACL, 2018: 464-468. |
| [22] | SUKHBAATAR S, GRAVE E, BOJANOWSKI P, et al. Adaptive attention span in Transformers[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 331-335. |
| [23] | DARJI H, MITROVIĆ J, GRANITZER M. German BERT model for legal named entity recognition[C]// Proceedings of the 15th International Conference on Agents and Artificial Intelligence — Volume 3: ICAART. Setúbal: SciTePress, 2023: 723-728. |
| [24] | JU M, MIWA M, ANANIADOU S. A neural layered model for nested named entity recognition[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018: 1446-1459. |
| [25] | WANG J, SHOU L, CHEN K, et al. Pyramid: a layered model for nested named entity recognition[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5918-5928. |
| [26] | LI X, FENG J, MENG Y, et al. A unified MRC framework for named entity recognition[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5849-5859. |
| [27] | ZHU E, LI J. Boundary smoothing for named entity recognition[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 7096-7108. |
| [28] | SHEN Y, SONG K, TAN X, et al. DiffusionNER: boundary Diffusion for Named Entity Recognition[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 3875-3890. |
| [29] | WENG M, ZHANG W. Named entity recognition based on BERT-BiLSTM-SPAN in low resource scenarios[C]// Proceedings of the 15th International Conference on Computer Research and Development. Piscataway: IEEE, 2023: 32-37. |
| [30] | LI P, SUN T, TANG Q, et al. CodeIE: large code generation models are better few-shot information extractors[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 15339-15353. |
| [31] | BAI J, BAI S, CHU Y, et al. Qwen technical report[EB/OL]. [2025-03-01].. |
| [32] | CHEN L, MOSCHITTI A. Learning to progressively recognize new named entities with sequence to sequence models[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 2181-2191. |
| [33] | LUO Y, ZHAO H. Bipartite flat-graph network for nested named entity recognition[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6408-6418. |
| [1] | Junrui WU, Jiangchuan YANG, Haisheng YU, Sai ZOU, Wenyong WANG. Performance evaluation method for deterministic networks based on complex-enhanced attention graph neural network [J]. Journal of Computer Applications, 2026, 46(2): 505-517. |
| [2] | Yiheng SUN, Maofu LIU. Tender information extraction method based on prompt tuning of knowledge [J]. Journal of Computer Applications, 2025, 45(4): 1169-1176. |
| [3] | Yuelin TIAN, Ruizhang HUANG, Lina REN. Scholar fine-grained information extraction method fused with local semantic features [J]. Journal of Computer Applications, 2023, 43(9): 2707-2714. |
| [4] | Yuxin TUO, Tao XUE. Joint triple extraction model combining pointer network and relational embedding [J]. Journal of Computer Applications, 2023, 43(7): 2116-2124. |
| [5] | Liang XU, Chun ZHANG, Ning ZHANG, Xuetao TIAN. Zero-shot relation extraction model via multi-template fusion in Prompt [J]. Journal of Computer Applications, 2023, 43(12): 3668-3675. |
| [6] | Ping LUO, Ling DING, Xue YANG, Yang XIANG. Chinese event detection based on data augmentation and weakly supervised adversarial training [J]. Journal of Computer Applications, 2022, 42(10): 2990-2995. |
| [7] | CUI Bowen, JIN Tao, WANG Jianmin. Overview of information extraction of free-text electronic medical records [J]. Journal of Computer Applications, 2021, 41(4): 1055-1063. |
| [8] | LUO Ming, HUANG Hailiang. Information extraction method of financial events based on lexical-semantic pattern [J]. Journal of Computer Applications, 2018, 38(1): 84-90. |
| [9] | XIANG Jingjing, GENG Guanggang, LI Xiaodong. Key information extraction algorithm of news Web pages [J]. Journal of Computer Applications, 2016, 36(8): 2082-2086. |
| [10] | ZHANG Zhihua, WANG Jianxiang, TIAN Junfeng, WU Guoshun, LAN Man. Blocked person relation recognition system based on multiple features [J]. Journal of Computer Applications, 2016, 36(3): 751-757. |
| [11] | MA Jianhong, ZHANG Mingyue, ZHAO Yanan. Patent knowledge extraction method for innovation design [J]. Journal of Computer Applications, 2016, 36(2): 465-471. |
| [12] | LI Rujun, ZHANG Jun, ZHANG Xiaomin, GUI Xiaoqing. Web information extraction in health field [J]. Journal of Computer Applications, 2016, 36(1): 163-170. |
| [13] | YANG Yipu, YANG Fan, PAN Guofeng, ZHANG Huimin. River information extraction from high resolution remote sensing image based on homomorphic system filtering [J]. Journal of Computer Applications, 2016, 36(1): 248-253. |
| [14] | ZHAO Jiapeng, LIN Min. Information extraction of history evolution based on Wikipedia [J]. Journal of Computer Applications, 2015, 35(4): 1021-1025. |
| [15] | DU Yuanwei, SHI Fangyuan, YANG Na. Construction method for Bayesian network based on Dempster-Shafer/analytic hierarchy process [J]. Journal of Computer Applications, 2015, 35(1): 140-146. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||