


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (12): 3790-3798.DOI: 10.11772/j.issn.1001-9081.2022121831
所属专题: 网络空间安全
陈谦, 柴政, 王子龙( ), 陈嘉伟
), 陈嘉伟
收稿日期:2022-12-13
修回日期:2023-05-09
接受日期:2023-05-10
发布日期:2023-05-25
出版日期:2023-12-10
通讯作者:
王子龙
作者简介:陈谦(1993—),男,陕西西安人,博士研究生,主要研究方向:隐私保护、机器学习、联邦学习基金资助:
Qian CHEN, Zheng CHAI, Zilong WANG(), Jiawei CHEN
Received:2022-12-13
Revised:2023-05-09
Accepted:2023-05-10
Online:2023-05-25
Published:2023-12-10
Contact:
Zilong WANG
About author:CHEN Qian, born in 1993, Ph. D. candidate. His research interests include privacy preservation, machine learning, federated learning.Supported by:摘要:
联邦学习(FL)是一种新兴的隐私保护机器学习(ML)范式,然而它的分布式的训练结构更易受到投毒攻击的威胁:攻击者通过向中央服务器上传投毒模型以污染全局模型,减缓全局模型收敛并降低全局模型精确度。针对上述问题,提出一种基于生成对抗网络(GAN)的投毒攻击检测方案。首先,将良性本地模型输入GAN产生检测样本;其次,使用生成的检测样本检测客户端上传的本地模型;最后,根据检测指标剔除投毒模型。同时,所提方案定义了F1值损失和精确度损失这两项检测指标检测投毒模型,将检测范围从单一类型的投毒攻击扩展至全部两种类型的投毒攻击;设计阈值判定方法处理误判问题,确保误判鲁棒性。实验结果表明,在MNIST和Fashion-MNIST数据集上,所提方案能够生成高质量检测样本,并有效检测与剔除投毒模型;与使用收集测试数据和使用生成测试数据但仅使用精确度作为检测指标的两种检测方案相比,所提方案的全局模型精确度提升了2.7~12.2个百分点。
中图分类号:
陈谦, 柴政, 王子龙, 陈嘉伟. 基于生成对抗网络的联邦学习中投毒攻击检测方案[J]. 计算机应用, 2023, 43(12): 3790-3798.
Qian CHEN, Zheng CHAI, Zilong WANG, Jiawei CHEN. Poisoning attack detection scheme based on generative adversarial network for federated learning[J]. Journal of Computer Applications, 2023, 43(12): 3790-3798.

图1 FL与投毒攻击
Fig.1 FL with poisoning attacks
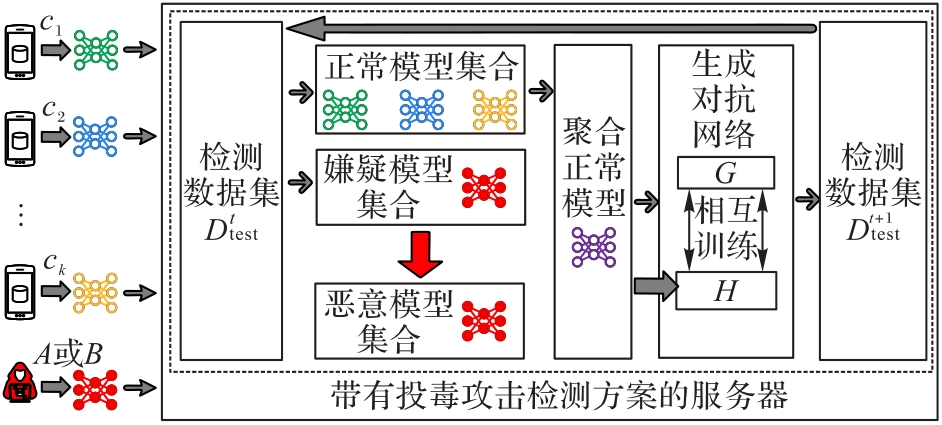
图2 基于GAN的投毒攻击检测方案
Fig.2 Poisoning attack detection scheme based on GAN

图3 MNIST数据集和Fashion-MNIST数据集的3种检测数据
Fig.3 Three types of detection data of MNIST dataset and Fashion-MNIST dataset

图4 MNIST数据集和Fashion-MNIST数据集上的全局模型性能
Fig.4 Global model performance on MNIST dataset and Fashion-MNIST dataset

图5 Fashion-MNIST数据集上不同方案检测并剔除投毒模型性能
Fig.5 Different scheme performance to detect and eliminate poisoning models on Fashion-MNIST dataset

图6 阈值判定方法对所提方案性能的影响
Fig.6 Influence of threshold determination method on performance of proposed scheme

图7 检测指标的判定阈值对所提方案性能的影响
Fig.7 Influence of detection index determination threshold on performance of proposed scheme
| 方案 | 全局模型损失值 | 全局模型 精确度/% | 曲线下面积 | |||
|---|---|---|---|---|---|---|
随机 攻击 | 有目标攻击 | 随机攻击 | 有目标攻击 | 随机 攻击 | 有目标攻击 | |
| 无攻击 | 0.058 6 | 98.2 | 0.959 0 | |||
| 无抵御机制 | 0.654 1 | 0.112 1 | 74.3 | 94.6 | 0.891 6 | 0.946 6 |
| 本文方案 | 0.062 5 | 0.060 9 | 97.4 | 98.0 | 0.949 9 | 0.954 7 |
表1 不同方案对MNIST数据集的全局模型性能
Tab.1 Global model performance of different schemes on MNIST dataset
| 方案 | 全局模型损失值 | 全局模型 精确度/% | 曲线下面积 | |||
|---|---|---|---|---|---|---|
随机 攻击 | 有目标攻击 | 随机攻击 | 有目标攻击 | 随机 攻击 | 有目标攻击 | |
| 无攻击 | 0.058 6 | 98.2 | 0.959 0 | |||
| 无抵御机制 | 0.654 1 | 0.112 1 | 74.3 | 94.6 | 0.891 6 | 0.946 6 |
| 本文方案 | 0.062 5 | 0.060 9 | 97.4 | 98.0 | 0.949 9 | 0.954 7 |
| 方案 | 全局模型损失值 | 全局模型精确度/% | ||
|---|---|---|---|---|
随机 攻击 | 有目标 攻击 | 随机 攻击 | 有目标攻击 | |
| 无攻击 | 0.296 8 | 90.3 | ||
| 无抵御机制 | 2.029 8 | 0.411 0 | 52.1 | 84.9 |
| 本文方案 | 0.376 8 | 0.317 6 | 87.7 | 89.4 |
| 收集检测数据方案[ | 0.736 2 | 0.412 0 | 75.5 | 84.9 |
| 精确度方案[ | 0.549 2 | 0.388 1 | 82.7 | 86.7 |
表2 Fashion-MNIST数据集上不同方案的全局模型性能
Tab.2 Global model performance on Fashion-MNIST dataset ofdifferent schemes
| 方案 | 全局模型损失值 | 全局模型精确度/% | ||
|---|---|---|---|---|
随机 攻击 | 有目标 攻击 | 随机 攻击 | 有目标攻击 | |
| 无攻击 | 0.296 8 | 90.3 | ||
| 无抵御机制 | 2.029 8 | 0.411 0 | 52.1 | 84.9 |
| 本文方案 | 0.376 8 | 0.317 6 | 87.7 | 89.4 |
| 收集检测数据方案[ | 0.736 2 | 0.412 0 | 75.5 | 84.9 |
| 精确度方案[ | 0.549 2 | 0.388 1 | 82.7 | 86.7 |
| 1 | JORDAN M I, MITCHELL T M. Machine learning: trends, perspectives, and prospects[J]. Science, 2015, 349(6245): 255-260. 10.1126/science.aaa8415 |
| 2 | VOIGT P, VON DEM BUSSCHE A. The EU General Data Protection Regulation (GDPR) [S]. Cham: Springer, 2017. 10.1007/978-3-319-57959-7 |
| 3 | MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. Brookline: Microtome Publishing, 2017: 1273-1282. |
| 4 | XU J, GLICKSBERG B S, SU C, et al. Federated learning for healthcare informatics[J]. Journal of Healthcare Informatics Research, 2021, 5(1): 1-19. 10.1007/s41666-020-00082-4 |
| 5 | CHEN Q, WANG Z L, LIN X D. PPT: a privacy-preserving global model training protocol for federated learning in P2P networks [J]. Computers & Security, 2023, 124: 102966. 10.1016/j.cose.2022.102966 |
| 6 | TIAN Z, CUI L, LIANG J, et al. A comprehensive survey on poisoning attacks and countermeasures in machine learning[J]. ACM Computing Surveys, 2022, 55(8): 1-35. 10.1145/3551636 |
| 7 | KAIROUZ P, MCMAHAN H B, AVENT B, et al. Advances and open problems in federated learning [J]. Foundations and Trends® in Machine Learning, 2021, 14(1/2): 1-210. 10.1561/2200000083 |
| 8 | TOLPEGIN V, TRUEX S, GURSOY M E, et al. Data poisoning attacks against federated learning systems [C]// Proceedings of the 25th European Symposium on Research in Computer Security. Cham: Springer, 2020: 480-501. 10.1007/978-3-030-58951-6_24 |
| 9 | FANG M H, CAO X Y, JIA J Y, et al. Local model poisoning attacks to Byzantine-robust federated learning [C]// Proceedings of the 29th USENIX Security Symposium. Berkeley: USENIX Association, 2020: 1605-1622. |
| 10 | TAHMASEBIAN F, XIONG L, SOTOODEH M, et al. Crowdsourcing under data poisoning attacks: a comparative study[C]// Proceedings of the 2020 IFIP Annual Conference on Data and Applications Security and Privacy. Cham: Springer, 2020: 310-332. 10.1007/978-3-030-49669-2_18 |
| 11 | YIN D, CHEN Y, KANNAN R, Byzantine-robust distributed learning: towards optimal statistical rates [C]// Proceedings of the 35th International Conference on Machine Learning. San Diego: JMLR, 2018: 5650-5659. |
| 12 | BLANCHARD P, MHAMDI E M EL, GUERRAOUI R, et al. Machine learning with adversaries: byzantine tolerant gradient descent [C]// Proceedings of the 31st International Conference on Neural Information Proceedings Systems. La Jolla: NIPS, 2017: 118-128. |
| 13 | MUÑOZ-GONZÁLEZ L, CO K T, LUPU E C. Byzantine-robust federated machine learning through adaptive model averaging [EB/OL]. (2019-09-11) [2022-04-25]. . |
| 14 | 陈宛桢, 张恩, 秦磊勇, 等 .边缘计算下基于区块链的隐私保护联邦学习算法[J]. 计算机应用,2023, 43(7): 2209-2216. |
| CHEN W Z, ZHANG E, QIN L Y,et al. Privacy-preserving federated learning algorithm based on block chain in edge computing [J]. Journal of Computer Applications, 2023, 43(7): 2209-2216. | |
| 15 | JAGIELSKI M, OPREA A, BIGGIO B, et al. Manipulating machine learning: poisoning attacks and countermeasures for regression learning [C]// Proceedings of the 39th IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2018: 19-35. 10.1109/sp.2018.00057 |
| 16 | ZHAO Y, CHEN J, ZHANG J, et al. Detecting and mitigating poisoning attacks in federated learning using generative adversarial networks[J]. Concurrency and Computation: Practice and Experience, 2020, 34(7): e5906. 10.1002/cpe.5906 |
| 17 | FENG J, XU H, MANNOR S, et al. Robust logistic regression and classification[C]// Proceedings of the 27th International Conference on Neural Information Proceeding Systems. La Jolla: NIPS, 2014: 253-261. |
| 18 | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J] Communications of the ACM, 2020, 63(11): 139-144. 10.1145/3422622 |
| 19 | BHAGOJI A N, CHAKRABORTY S, MITTAL P, et al. Analyzing federated learning through an adversarial lens[C]// Proceedings of the 36th International Conference on Machine Learning. San Diego: JMLR, 2019: 634-643. |
| 20 | SHEJWALKAR V, HOUMANSADR A. Manipulating the byzantine: optimizing model poisoning attacks and defenses for federated learning [C]// Proceedings of 28th Annual Network and Distributed System Security Symposium. Reston: Internet Society, 2021: 1-19. 10.14722/ndss.2021.24498 |
| 21 | ALKHUNAIZI N, KAMZOLOV D, TAKÁČ M, et al. Suppressing poisoning attacks on federated learning for medical imaging [C]// Proceedings of the 2022 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 13438. Cham: Springer, 2022: 673-683. |
| 22 | SUN J, LI A, DIVALENTIN L, et al. FL-WBC: enhancing robustness against model poisoning attacks in federated learning from a client perspective [C]// Proceedings of the 2021 Advances in Neural Information Proceedings Systems 34. La Jolla: NIPS, 2021:12613-12624. |
| 23 | NGUYEN T D, RIEGER P, MIETTINEN M, et al. Poisoning attacks on federated learning-based IoT intrusion detection system[C]// Proceedings of the 2020 Decentralized IoT Systems and Security Workshop. Washington: Internet Society, 2020: 1-7. 10.14722/diss.2020.23003 |
| 24 | GUERRAOUI R, ROUAULT S. The hidden vulnerability of distributed learning in Byzantium[C]// Proceedings of the 35th International Conference on Machine Learning. San Diego: JMLR, 2018: 3521-3530. |
| 25 | STEINHARDT J, KOH P W, LIANG P. Certified defenses for data poisoning attacks[C]// Proceedings of the 31st International Conference on Neural Information Proceedings Systems. La Jolla: NIPS, 2017: 3520-3532. |
| 26 | LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4681-4690. 10.1109/cvpr.2017.19 |
| 27 | CHEN Z, ZHU T, XIONG P, et al. Privacy preservation for image data: a GAN‐based method [J]. International Journal of Intelligent Systems, 2021, 36(4): 1668-1685. 10.1002/int.22356 |
| 28 | WANG Z, SONG M, ZHANG Z, et al. Beyond inferring class representatives: user-level privacy leakage from federated learning[C]// Proceedings of the 2019 IEEE Conference on Computer Communications. Piscataway: IEEE, 2019: 2512-2520. 10.1109/infocom.2019.8737416 |
| 29 | TRUEX S, BARACALDO N, ANWAR A, et al. A hybrid approach to privacy-preserving federated learning[C]// Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security. New York: ACM, 2019: 1-11. 10.1145/3338501.3357370 |
| 30 | TOLPEGIN V, TRUEX S, GURSOY M E, et al. Data poisoning attacks against federated learning systems [C]// Proceedings of the 2020 European Symposium on Research in Computer Security, LNCS 12308. Cham: Springer, 2022: 480-501. |
| 31 | LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. 10.1109/5.726791 |
| 32 | XIAO H, RASUL K, VOLLGRAF R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2022-10-28].. |
| [1] | 陈廷伟, 张嘉诚, 王俊陆. 面向联邦学习的随机验证区块链构建[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2770-2776. |
| [2] | 沈哲远, 杨珂珂, 李京. 基于双流神经网络的个性化联邦学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2319-2325. |
| [3] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [4] | 罗玮, 刘金全, 张铮. 融合秘密分享技术的双重纵向联邦学习框架[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1872-1879. |
| [5] | 陈学斌, 任志强, 张宏扬. 联邦学习中的安全威胁与防御措施综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1663-1672. |
| [6] | 王昊冉, 于丹, 杨玉丽, 马垚, 陈永乐. 面向工控系统未知攻击的域迁移入侵检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1158-1165. |
| [7] | 郑毅, 廖存燚, 张天倩, 王骥, 刘守印. 面向城区的基于图去噪的小区级RSRP估计方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 855-862. |
| [8] | 余孙婕, 曾辉, 熊诗雨, 史红周. 基于生成式对抗网络的联邦学习激励机制[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 344-352. |
| [9] | 张祖篡, 陈学斌, 高瑞, 邹元怀. 基于标签分类的联邦学习客户端选择方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3759-3765. |
| [10] | 巫婕, 钱雪忠, 宋威. 基于相似度聚类和正则化的个性化联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3345-3353. |
| [11] | 陈学斌, 屈昌盛. 面向联邦学习的后门攻击与防御综述[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3459-3469. |
| [12] | 张帅华, 张淑芬, 周明川, 徐超, 陈学斌. 基于半监督联邦学习的恶意流量检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3487-3494. |
| [13] | 尹春勇, 周永成. 双端聚类的自动调整聚类联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3011-3020. |
| [14] | 周辉, 陈玉玲, 王学伟, 张洋文, 何建江. 基于生成对抗网络的联邦学习深度影子防御方案[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 223-232. |
| [15] | 刘安阳, 赵怀慈, 蔡文龙, 许泽超, 解瑞灯. 基于主动判别机制的自适应生成对抗网络图像去模糊算法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2288-2294. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||