


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (6): 1663-1672.DOI: 10.11772/j.issn.1001-9081.2023060832
所属专题: 综述; CCF第38届中国计算机应用大会 (CCF NCCA 2023)
• CCF第38届中国计算机应用大会 (CCF NCCA 2023) • 上一篇 下一篇
陈学斌1,2,3, 任志强1,2,3( ), 张宏扬1,2,3
), 张宏扬1,2,3
收稿日期:2023-07-04
修回日期:2023-07-15
接受日期:2023-07-25
发布日期:2023-08-03
出版日期:2024-06-10
通讯作者:
任志强
作者简介:陈学斌(1970 —),男,河北唐山人,教授,博士,CCF杰出会员,主要研究方向:大数据安全、物联网安全、网络安全基金资助:
Xuebin CHEN1,2,3, Zhiqiang REN1,2,3(), Hongyang ZHANG1,2,3
Received:2023-07-04
Revised:2023-07-15
Accepted:2023-07-25
Online:2023-08-03
Published:2024-06-10
Contact:
Zhiqiang REN
About author:CHEN Xuebin, born in 1970, Ph. D., professor. His research interests include big data security, IoT security, network security.Supported by:摘要:
联邦学习是一种用于解决机器学习中数据共享问题和隐私保护问题的分布式学习方法,旨在多方共同训练一个机器学习模型并保护数据的隐私;但是,联邦学习本身存在安全威胁,这使得联邦学习在实际应用中面临巨大的挑战,因此,分析联邦学习面临的攻击和相应的防御措施对联邦学习的发展和应用至关重要。首先,介绍联邦学习的定义、流程和分类,联邦学习中的攻击者模型;其次,从联邦学习系统的鲁棒性和隐私性两方面介绍可能遭受的攻击,并介绍不同攻击相应的防御措施,同时也指出防御方案的不足;最后,展望安全的联邦学习系统。
中图分类号:
陈学斌, 任志强, 张宏扬. 联邦学习中的安全威胁与防御措施综述[J]. 计算机应用, 2024, 44(6): 1663-1672.
Xuebin CHEN, Zhiqiang REN, Hongyang ZHANG. Review on security threats and defense measures in federated learning[J]. Journal of Computer Applications, 2024, 44(6): 1663-1672.
| 系统安全威胁 | 攻击者模型 | 攻击者来源 | 攻击类型 | 文献序号(攻击) | 防御措施 | 文献序号(防御) |
|---|---|---|---|---|---|---|
| 鲁棒性威胁 | 恶意攻击 | 参与方 | 数据投毒 | [ | 检查更新的可信性 | [ |
| 后门攻击 | ||||||
| 模型攻击 | ||||||
| 隐私性威胁 | 诚实但好奇 攻击 | 参与方/服务端 | 推理攻击 | [ | 加密机制和加噪机制 | [ |
| 重构攻击 | ||||||
| 系统外部 | 窃取攻击 |
表1 联邦学习系统安全威胁和防御措施
Tab. 1 Security threats and defense measures for federal learning system
| 系统安全威胁 | 攻击者模型 | 攻击者来源 | 攻击类型 | 文献序号(攻击) | 防御措施 | 文献序号(防御) |
|---|---|---|---|---|---|---|
| 鲁棒性威胁 | 恶意攻击 | 参与方 | 数据投毒 | [ | 检查更新的可信性 | [ |
| 后门攻击 | ||||||
| 模型攻击 | ||||||
| 隐私性威胁 | 诚实但好奇 攻击 | 参与方/服务端 | 推理攻击 | [ | 加密机制和加噪机制 | [ |
| 重构攻击 | ||||||
| 系统外部 | 窃取攻击 |
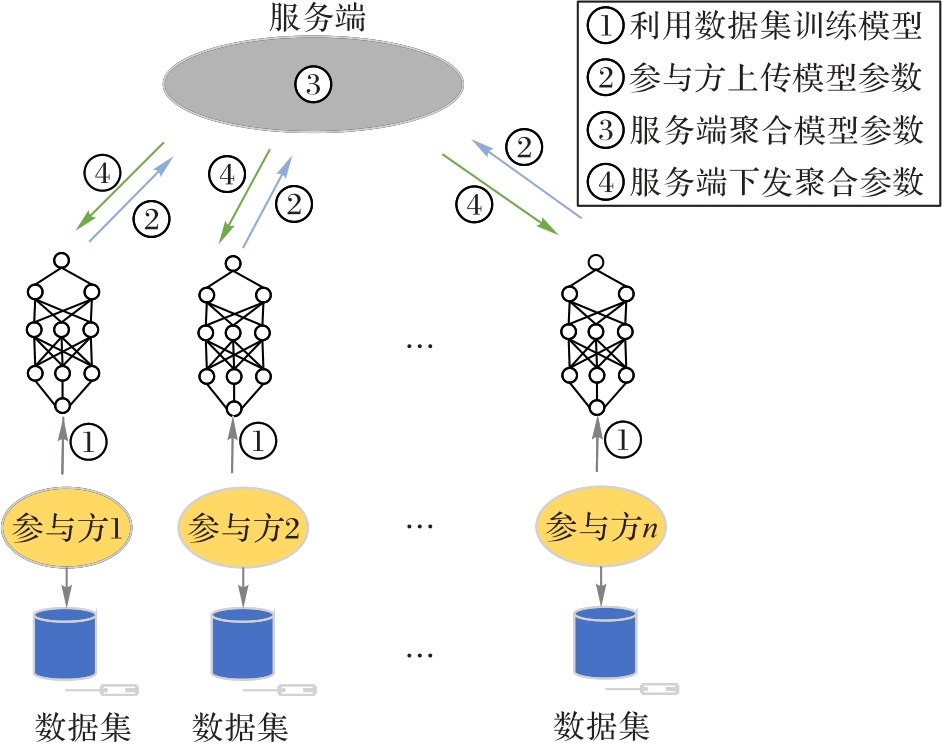
图1 联邦学习系统的体系结构
Fig. 1 Architecture of federated learning system
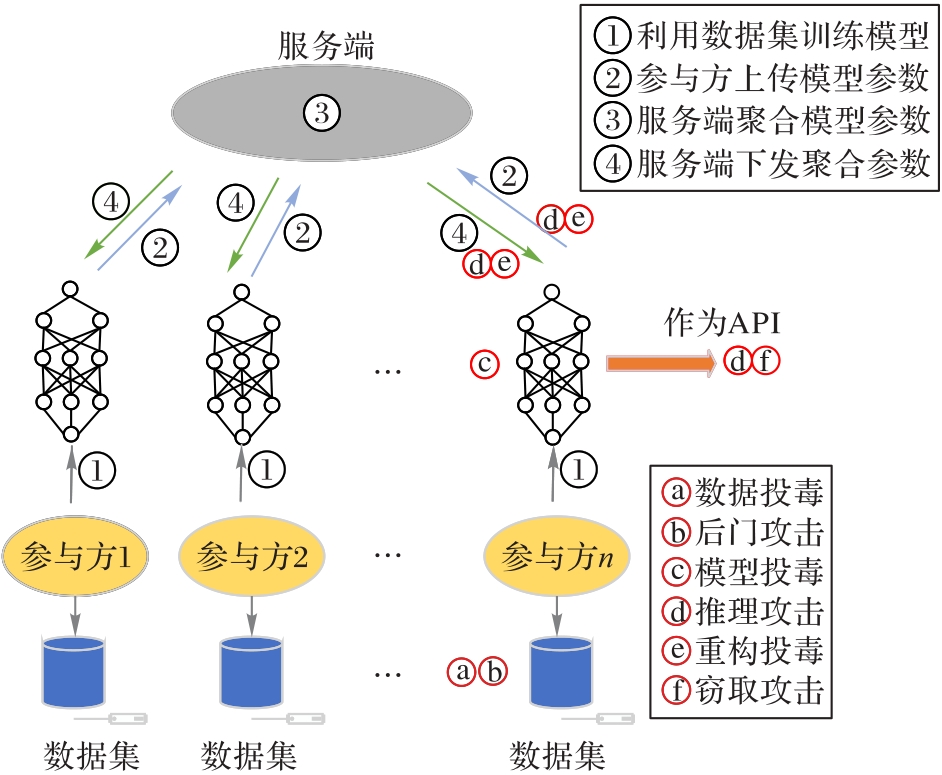
图2 联邦学习系统各阶段存在的攻击
Fig. 2 Attacks at all stages of federated learning system
鲁棒性 威胁 | 数据 分布 | 攻击类型 | 文献 序号 | 攻击方法论 | 补充说明 |
|---|---|---|---|---|---|
数据 投毒 | 非独立 同分布 | 无目标 投毒 | [ | 利用投影随机梯度上升算法最大限度地增加了目标节点的经验损失 | |
独立 同分布 | [ | 预测由恶意输入引起的SVM决策函数的变化,并利用这种能力 构造恶意数据 | |||
独立 同分布 | 有目标 投毒 | [ | 力求最后几轮中成功投毒,并选择合适的标签翻转对象 | 未考虑参与方数据是 非独立同分布的情况 | |
非独立 同分布 | [ | 利用GAN技术生成数据并实施标签翻转 | 攻击效果依赖攻击者选择的 攻击时机 | ||
模型 投毒 | 独立 同分布 或 非独立 同分布 | 无目标 模型投毒 | [ | 向局部模型添加随机噪声 | |
有目标 模型投毒 | [ | 根据安全聚合算法,修改局部模型参数使全局模型向相反方向更新 | |||
| [ | 最大化恶意模型的更新,同时限制更新避免被检测 | ||||
| [ | 放大恶意模型更新,使得一次攻击留下足够强的后门 | 需要人工估计局部模型的 放大因子 | |||
| [ | 利用全局模型的历史更新推出反向更新的方向,并提交大量放大后的攻击模型更新 | ||||
后门 攻击 | 非独立 同分布 | 标记后门 | [ | 多个攻击者分布式地植入后门 | |
| 语义后门 | [ | 选择诚实参与者数据集中较少的特征作为后门特征 | 假设攻击者已知异常检测策略 | ||
| [ | 增大攻击者比例,降低后门任务的复杂性,限制恶意更新 | ||||
| [ | 利用数据集的分布特点,挑选边缘数据实施后门攻击,并限制恶意更新 | ||||
| 后门攻击 | [ | 后门模型和主任务模型分开训练,再优化结合为一个模型 |
表2 联邦学习系统鲁棒性威胁的攻击
Tab. 2 Robustness threat attacks in federated learning system
鲁棒性 威胁 | 数据 分布 | 攻击类型 | 文献 序号 | 攻击方法论 | 补充说明 |
|---|---|---|---|---|---|
数据 投毒 | 非独立 同分布 | 无目标 投毒 | [ | 利用投影随机梯度上升算法最大限度地增加了目标节点的经验损失 | |
独立 同分布 | [ | 预测由恶意输入引起的SVM决策函数的变化,并利用这种能力 构造恶意数据 | |||
独立 同分布 | 有目标 投毒 | [ | 力求最后几轮中成功投毒,并选择合适的标签翻转对象 | 未考虑参与方数据是 非独立同分布的情况 | |
非独立 同分布 | [ | 利用GAN技术生成数据并实施标签翻转 | 攻击效果依赖攻击者选择的 攻击时机 | ||
模型 投毒 | 独立 同分布 或 非独立 同分布 | 无目标 模型投毒 | [ | 向局部模型添加随机噪声 | |
有目标 模型投毒 | [ | 根据安全聚合算法,修改局部模型参数使全局模型向相反方向更新 | |||
| [ | 最大化恶意模型的更新,同时限制更新避免被检测 | ||||
| [ | 放大恶意模型更新,使得一次攻击留下足够强的后门 | 需要人工估计局部模型的 放大因子 | |||
| [ | 利用全局模型的历史更新推出反向更新的方向,并提交大量放大后的攻击模型更新 | ||||
后门 攻击 | 非独立 同分布 | 标记后门 | [ | 多个攻击者分布式地植入后门 | |
| 语义后门 | [ | 选择诚实参与者数据集中较少的特征作为后门特征 | 假设攻击者已知异常检测策略 | ||
| [ | 增大攻击者比例,降低后门任务的复杂性,限制恶意更新 | ||||
| [ | 利用数据集的分布特点,挑选边缘数据实施后门攻击,并限制恶意更新 | ||||
| 后门攻击 | [ | 后门模型和主任务模型分开训练,再优化结合为一个模型 |
文献 序号 | 攻击评价 指标 | 数据集 | 训练设置 | 结果/% | 说明 |
|---|---|---|---|---|---|
| [ | 模型错误率 | EndAD | 6:*:no-iid | base:6.881±0.52 result:28.588±3.74 | |
| Human Activity | 30:*:no-iid | base:2.586±0.84 result:29.422±2.96 | |||
| Landmine | 29:*:no-iid | base:5.682±0.28 result:13.648±0.54 | |||
| [ | 模型错误率 | MNIST | *:*:* | base:2-5 result:15-20 | |
| [ | 最大召回率 损失 | CIFAR-10 | 50:*:iid | base:0 result:2:1.42; 20:25.4 | 随不同恶意参与者百分比 (a: b,a表示百分比,b表示损失) |
| Fashion-MNIST | 50:*:iid | base:0 result:2:0.61; 20:29.2 | |||
| [ | 中毒任务 准确率 | MNIST | 10:*:no-iid | base:0 result:20:60±;40:80±;60:85± | 随不同放大因子 (a:b,a表示放大因子,b表示准确率) |
| AT&T | 10:*:no-iid | base:0 result:20:70±;40:85±;60:90± | |||
| [ | 最大准确度 损失 | CIFAR10 (Alexnet) | 50:1 000:* | base:0 result:Krum:43.6; Mkrum:36.8; Bulyan:45.6; TrMean:45.8; Median:40.9; AFA:47.0; FangTrmean:56.3 | 在不同聚合算法下 (a:b,a表示聚合算法,b表示损失) |
| [ | 后门任务 准确率 | CIFAR10 | 100:*:no-iid | base:0 result:95:30±,75± | 一次攻击、随全局迭代 (a:b,c,a表示轮次,b代表最低 准确度,c代表最高准确率) |
| Reddit dataset | 83 293:247:no-iid | base:0 result:95:0±,60± | |||
| CIFAR10 | 100:*:no-iid | base:0 result:1:30±,50±;5:80±,80± | 持续攻击、随恶意参与者百分比 (a:b,c,a表示恶意参与者占比,b代表最低准确度,c代表最高准确率) | ||
| Reddit dataset | 83 293:247:no-iid | base:0 result:0.01:30±,65±;0.1:80±,90± | |||
| [ | 模型准确率 | MNIST | 1 000:*:no-iid | base:99± result:FedAvg:1-25:10±; Median:1:90±; Median:25:60±; Trimmed-mean:1:95±; Trimmed-mean:1:50± | 随恶意参与者百分比 (a:b:c,a表示聚合算法,b表示恶意 参与者占比,c表示准确率) |
| [ | 攻击成功率 | LOAN | 51:*:no-iid | base: 0 result:8:99± | 随全局迭代 (a:b,a表示迭代数,b表示成功率) |
| MNIST | 100:*:no-iid | base: 0 result:20:99± | |||
| CIFAR | 100:*:no-iid | base: 0 result:350:80± | |||
| Tiny-imagenet | 100:*:no-iid | base: 0 result:80:80± | |||
| [ | 后门任务 准确率 | MNIST | *:*:no-iid | base:0 result:10:120:95±;50:300:70± | 固定任务数、随全局迭代 (a:b:c,a表示任务数,b表示迭代数, c表示准确率) |
| [ | 后门任务 准确率 | CIFAR-10 | 200:*:no-iid | base:0 result:100:400:55±;10:400:15± | (a:b:c,a表示攻击资源占比,b表示迭代数,c表示准确率) |
| MNIST | 20:*:* | base:0 result:10:80±;20:90± | (a:b,a表示迭代数,b表示准确率) | ||
| CIFAR-10 | 50:*:* | base:0 result:300:40±;400:90± |
表3 联邦学习系统鲁棒性威胁的攻击效果
Tab.3 Attack effects of robustness threats in federated learning system
文献 序号 | 攻击评价 指标 | 数据集 | 训练设置 | 结果/% | 说明 |
|---|---|---|---|---|---|
| [ | 模型错误率 | EndAD | 6:*:no-iid | base:6.881±0.52 result:28.588±3.74 | |
| Human Activity | 30:*:no-iid | base:2.586±0.84 result:29.422±2.96 | |||
| Landmine | 29:*:no-iid | base:5.682±0.28 result:13.648±0.54 | |||
| [ | 模型错误率 | MNIST | *:*:* | base:2-5 result:15-20 | |
| [ | 最大召回率 损失 | CIFAR-10 | 50:*:iid | base:0 result:2:1.42; 20:25.4 | 随不同恶意参与者百分比 (a: b,a表示百分比,b表示损失) |
| Fashion-MNIST | 50:*:iid | base:0 result:2:0.61; 20:29.2 | |||
| [ | 中毒任务 准确率 | MNIST | 10:*:no-iid | base:0 result:20:60±;40:80±;60:85± | 随不同放大因子 (a:b,a表示放大因子,b表示准确率) |
| AT&T | 10:*:no-iid | base:0 result:20:70±;40:85±;60:90± | |||
| [ | 最大准确度 损失 | CIFAR10 (Alexnet) | 50:1 000:* | base:0 result:Krum:43.6; Mkrum:36.8; Bulyan:45.6; TrMean:45.8; Median:40.9; AFA:47.0; FangTrmean:56.3 | 在不同聚合算法下 (a:b,a表示聚合算法,b表示损失) |
| [ | 后门任务 准确率 | CIFAR10 | 100:*:no-iid | base:0 result:95:30±,75± | 一次攻击、随全局迭代 (a:b,c,a表示轮次,b代表最低 准确度,c代表最高准确率) |
| Reddit dataset | 83 293:247:no-iid | base:0 result:95:0±,60± | |||
| CIFAR10 | 100:*:no-iid | base:0 result:1:30±,50±;5:80±,80± | 持续攻击、随恶意参与者百分比 (a:b,c,a表示恶意参与者占比,b代表最低准确度,c代表最高准确率) | ||
| Reddit dataset | 83 293:247:no-iid | base:0 result:0.01:30±,65±;0.1:80±,90± | |||
| [ | 模型准确率 | MNIST | 1 000:*:no-iid | base:99± result:FedAvg:1-25:10±; Median:1:90±; Median:25:60±; Trimmed-mean:1:95±; Trimmed-mean:1:50± | 随恶意参与者百分比 (a:b:c,a表示聚合算法,b表示恶意 参与者占比,c表示准确率) |
| [ | 攻击成功率 | LOAN | 51:*:no-iid | base: 0 result:8:99± | 随全局迭代 (a:b,a表示迭代数,b表示成功率) |
| MNIST | 100:*:no-iid | base: 0 result:20:99± | |||
| CIFAR | 100:*:no-iid | base: 0 result:350:80± | |||
| Tiny-imagenet | 100:*:no-iid | base: 0 result:80:80± | |||
| [ | 后门任务 准确率 | MNIST | *:*:no-iid | base:0 result:10:120:95±;50:300:70± | 固定任务数、随全局迭代 (a:b:c,a表示任务数,b表示迭代数, c表示准确率) |
| [ | 后门任务 准确率 | CIFAR-10 | 200:*:no-iid | base:0 result:100:400:55±;10:400:15± | (a:b:c,a表示攻击资源占比,b表示迭代数,c表示准确率) |
| MNIST | 20:*:* | base:0 result:10:80±;20:90± | (a:b,a表示迭代数,b表示准确率) | ||
| CIFAR-10 | 50:*:* | base:0 result:300:40±;400:90± |
防御 类型 | 数据分布 | 文献 序号 | 针对攻击类型 | 防御思想 | 防御方式 | 补充说明 |
|---|---|---|---|---|---|---|
数据 投毒 | 独立同分布 | [ | 无目标投毒或有目标投毒 | 基于行为 | 利用鲁棒性的分布式梯度下降算法聚合模型 | |
| [ | 有目标投毒 | 基于聚类 | 利用聚类算法鉴别恶意模型 | |||
| 独立同分布 | [ | 有目标投毒 | 基于行为 | 根据局部模型与全局模型的余弦相似度判断恶意模型 | 存在超参数 | |
独立同分布或 非独立同分布 | [ | 有目标投毒 | 根据局部模型与全局模型的余弦相似度并结合信誉机制共同判断恶意模型 | |||
模型 投毒 | 独立同分布或 非独立同分布 | [ | 无目标模型投毒 | 基于行为 | 利用拜占庭鲁棒性算法 | |
| [ | 基于局部更新与全局更新的余弦相似度去除恶意梯度 | |||||
| [ | 有目标模型投毒 | 基于行为 | 基于错误率和基于损失函数的评价指标并结合拜占庭鲁棒性聚合算法防御 | |||
| [ | 基于奇异值分解(SVD)的谱方法检测和去除异常值 | |||||
后门 攻击 | 非独立同分布 | [ | 标记后门攻击 | 基于行为 | 设置一个阈值,对每一轮中更新的每个维度进行投票,根据投票值是否超过阈值,动态调节该维度的学习率 | 存在超参数 |
| 独立同分布或非独立同分布 | [ | 标记后门攻击 | 针对机器学习 模型本身 | 剪裁异常神经元,约束神经元权重,微调模型 | 微调可能 导致后门 加深 | |
独立同分布或 部分非独立 同分布 | [ | 语义后门攻击 | 混合策略 (基于聚类、 基于行为) | 结合聚类和分类综合判定一个模型是否有害, 通过剪裁策略削弱绕过检测的有毒模型的影响 |
表4 防御鲁棒性威胁的措施
Tab. 4 Measures to defend against robustness threats
防御 类型 | 数据分布 | 文献 序号 | 针对攻击类型 | 防御思想 | 防御方式 | 补充说明 |
|---|---|---|---|---|---|---|
数据 投毒 | 独立同分布 | [ | 无目标投毒或有目标投毒 | 基于行为 | 利用鲁棒性的分布式梯度下降算法聚合模型 | |
| [ | 有目标投毒 | 基于聚类 | 利用聚类算法鉴别恶意模型 | |||
| 独立同分布 | [ | 有目标投毒 | 基于行为 | 根据局部模型与全局模型的余弦相似度判断恶意模型 | 存在超参数 | |
独立同分布或 非独立同分布 | [ | 有目标投毒 | 根据局部模型与全局模型的余弦相似度并结合信誉机制共同判断恶意模型 | |||
模型 投毒 | 独立同分布或 非独立同分布 | [ | 无目标模型投毒 | 基于行为 | 利用拜占庭鲁棒性算法 | |
| [ | 基于局部更新与全局更新的余弦相似度去除恶意梯度 | |||||
| [ | 有目标模型投毒 | 基于行为 | 基于错误率和基于损失函数的评价指标并结合拜占庭鲁棒性聚合算法防御 | |||
| [ | 基于奇异值分解(SVD)的谱方法检测和去除异常值 | |||||
后门 攻击 | 非独立同分布 | [ | 标记后门攻击 | 基于行为 | 设置一个阈值,对每一轮中更新的每个维度进行投票,根据投票值是否超过阈值,动态调节该维度的学习率 | 存在超参数 |
| 独立同分布或非独立同分布 | [ | 标记后门攻击 | 针对机器学习 模型本身 | 剪裁异常神经元,约束神经元权重,微调模型 | 微调可能 导致后门 加深 | |
独立同分布或 部分非独立 同分布 | [ | 语义后门攻击 | 混合策略 (基于聚类、 基于行为) | 结合聚类和分类综合判定一个模型是否有害, 通过剪裁策略削弱绕过检测的有毒模型的影响 |
| 防御指标 | 文献 序号 | 防御结果/% | 说明 |
|---|---|---|---|
| 模型错误率 | [ | base:0.12 attack:* after:0.12 | 随着全局迭代的最终结果 |
| [ | base:2.80±0.12 attack:* after:2.99±0.12±、2.96±0.15、3.04±0.14 | 随着全局迭代的最终结果,“after”中分别对应拜占庭、标签翻转和噪声攻击下的结果 | |
| [ | base:10± attack:60± after:10± | 随着全局迭代的最终结果 | |
| 模型准确率 | [ | base:94.3± attack:77.3± after:90.7± | 随着全局迭代的最终结果 |
| [ | base:78± attack:76±、74.5± after:78±、77.5± | 随着全局迭代的最终结果,“attack”和“after”中分别 对应20%和30%的恶意参与者占比 | |
| [ | base:* attack:* after:83.11、81.23 | 随着全局迭代的最终结果,“after”中分别对应5%和50%的恶意参与者占比 | |
模型准确率 损失 | [ | base:0 attack:* after:4.3 | 随着全局迭代的最终结果 |
后门任务 准确率 | [ | base:6.6 attack:88.6 after:9.0 | 随着全局迭代的最终结果 |
| [ | base:* attack:85.5 after:4.8 | ||
| [ | base:* attack:100 after:0 |
表5 防御鲁棒性威胁措施的效果
Tab.5 Effectiveness of measures to defend against robustness threats
| 防御指标 | 文献 序号 | 防御结果/% | 说明 |
|---|---|---|---|
| 模型错误率 | [ | base:0.12 attack:* after:0.12 | 随着全局迭代的最终结果 |
| [ | base:2.80±0.12 attack:* after:2.99±0.12±、2.96±0.15、3.04±0.14 | 随着全局迭代的最终结果,“after”中分别对应拜占庭、标签翻转和噪声攻击下的结果 | |
| [ | base:10± attack:60± after:10± | 随着全局迭代的最终结果 | |
| 模型准确率 | [ | base:94.3± attack:77.3± after:90.7± | 随着全局迭代的最终结果 |
| [ | base:78± attack:76±、74.5± after:78±、77.5± | 随着全局迭代的最终结果,“attack”和“after”中分别 对应20%和30%的恶意参与者占比 | |
| [ | base:* attack:* after:83.11、81.23 | 随着全局迭代的最终结果,“after”中分别对应5%和50%的恶意参与者占比 | |
模型准确率 损失 | [ | base:0 attack:* after:4.3 | 随着全局迭代的最终结果 |
后门任务 准确率 | [ | base:6.6 attack:88.6 after:9.0 | 随着全局迭代的最终结果 |
| [ | base:* attack:85.5 after:4.8 | ||
| [ | base:* attack:100 after:0 |
隐私性 威胁 | 攻击者 来源 | 文献 序号 | 攻击者知识 |
|---|---|---|---|
成员 推理 攻击 | 系统内部 | [26, 28-29] | 无需额外知识 |
| 系统外部 | [ | 模型API,模型的训练数据的背景知识 | |
| [ | 模型损失函数,损失范围 | ||
重构 攻击 | 系统内部 | [30-31, 33-34] | 无需额外知识 |
系统内部 服务端 | [ | 无需额外知识 | |
窃取 攻击 | 系统外部 | [ | 输出置信度的模型API,模型架构 |
| [ | 输出标签的模型API,模型架构 | ||
| [ | 输出置信度的模型API |
表6 联邦学习系统隐私性威胁的攻击
Tab. 6 Privacy threat attacks on federal learning system
隐私性 威胁 | 攻击者 来源 | 文献 序号 | 攻击者知识 |
|---|---|---|---|
成员 推理 攻击 | 系统内部 | [26, 28-29] | 无需额外知识 |
| 系统外部 | [ | 模型API,模型的训练数据的背景知识 | |
| [ | 模型损失函数,损失范围 | ||
重构 攻击 | 系统内部 | [30-31, 33-34] | 无需额外知识 |
系统内部 服务端 | [ | 无需额外知识 | |
窃取 攻击 | 系统外部 | [ | 输出置信度的模型API,模型架构 |
| [ | 输出标签的模型API,模型架构 | ||
| [ | 输出置信度的模型API |
| 防御措施 | 防御技术 | 防御思想 | 缺点 | 文献序号 |
|---|---|---|---|---|
| 加噪机制 | 客户级 差分隐私 | 掩盖原始梯度 信息 | 服务端必须可信 | [ |
本地级 差分隐私 | 掩盖原始梯度 信息 | 较大地影响模型性能 | [ | |
| 加密机制 | 同态加密 | 在密文上 进行计算 | 加密效率低、密文的 膨胀率高 | [ |
| 秘密分享 | 将秘密信息 划分多份 | 增加计算成本和 通信成本 | [ |
表7 防御隐私性威胁的措施
Tab.7 Measures to defend against privacy threats
| 防御措施 | 防御技术 | 防御思想 | 缺点 | 文献序号 |
|---|---|---|---|---|
| 加噪机制 | 客户级 差分隐私 | 掩盖原始梯度 信息 | 服务端必须可信 | [ |
本地级 差分隐私 | 掩盖原始梯度 信息 | 较大地影响模型性能 | [ | |
| 加密机制 | 同态加密 | 在密文上 进行计算 | 加密效率低、密文的 膨胀率高 | [ |
| 秘密分享 | 将秘密信息 划分多份 | 增加计算成本和 通信成本 | [ |
| 1 | JORDAN M I, MITCHELL T M. Machine learning: trends, perspectives, and prospects[J]. Science, 2015, 349(6245): 255-260. |
| 2 | ZHANG C, XIE Y, BAI H, et al. A survey on federated learning[J]. Knowledge-Based Systems, 2021, 216: 106775. |
| 3 | McMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: PMLR, 2017, 54: 1273-1282. |
| 4 | ALBRECHT J P. How the GDPR will change the world[J]. European Data Protection Law Review, 2016, 2: 287-289. |
| 5 | BIGGIO B, NELSON B, LASKOV P. Poisoning attacks against support vector machines[EB/OL]. (2013-03-25) [2023-07-09]. . |
| 6 | SUN G, CONG Y, DONG J, et al. Data poisoning attacks on federated machine learning[J]. IEEE Internet of Things Journal, 2021, 9(13): 11365-11375. |
| 7 | TOLPEGIN V, TRUEX S, GURSOY M E, et al. Data poisoning attacks against federated learning systems[C]// Proceedings of the 2020 European Symposium on Research in Computer Security. Cham: Springer, 2020: 480-501. |
| 8 | ZHANG J, CHEN J, WU D, et al. Poisoning attack in federated learning using generative adversarial nets[C]// Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering. Piscataway: IEEE, 2019: 374-380. |
| 9 | FANG M, CAO X, JIA J, et al. Local model poisoning attacks to Byzantine-robust federated learning[C]// Proceedings of the 29th USENIX Conference on Security Symposium. Berkeley: USENIX Association, 2020: 1623-1640. |
| 10 | SHEJWALKAR V, HOUMANSADR A. Manipulating the Byzantine: optimizing model poisoning attacks and defenses for federated learning [C/OL]// Proceedings of the 2021 Network and Distributed System Security Symposium [2023-05-30]. . |
| 11 | MUÑOZ-GONZÁLEZ L, CO K T, LUPU E C. Byzantine-robust federated machine learning through adaptive model averaging [EB/OL]. (2019-09-11) [2023-07-09]. . |
| 12 | BAGDASARYAN E, VEIT A, HUA Y, et al. How to backdoor federated learning[C]// Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. New York: PMLR, 2020, 108: 2938-2948. |
| 13 | CAO X, GONG N Z. MPAF: model poisoning attacks to federated learning based on fake clients [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 3395-3403. |
| 14 | XIE C, HUANG K, CHEN P Y, et al. DBA: distributed backdoor attacks against federated learning [C/OL]// Proceedings of the 2020 International Conference on Learning Representations ( 2020-12-19)[2023-05-30]. . |
| 15 | OZDAYI M S, KANTARCIOGLU M, GEL Y R. Defending against backdoors in federated learning with robust learning rate[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(10): 9268-9276. |
| 16 | WU C, YANG X, ZHU S, et al. Mitigating backdoor attacks in federated learning[EB/OL]. (2021-01-14) [2023-07-09]. . |
| 17 | SUN Z, KAIROUZ P, SURESH A T, et al. Can you really backdoor federated learning? [EB/OL]. (2019-12-02) [2023-07-09]. . |
| 18 | WANG H, SREENIVASAN K, RAJPUT S, et al. Attack of the tails: yes, you really can backdoor federated learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 16070-16084. |
| 19 | ZHOU X, XU M, WU Y, et al. Deep model poisoning attack on federated learning [J]. Future Internet, 2021, 13(3): 73. |
| 20 | BLANCHARD P, MHAMDI E M EL, GUERRAOUI R, et al. Machine learning with adversaries: Byzantine tolerant gradient descent [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 118-128. |
| 21 | YIN D, CHEN Y, KANNAN R, et al. Byzantine-robust distributed learning: towards optimal statistical rates[C]// Proceedings of the 35th International Conference on Machine Learning. New York: PMLR, 2018, 80: 5650-5659. |
| 22 | LI D, WONG W E, WANG W, et al. Detection and mitigation of label-flipping attacks in federated learning systems with KPCA and K-means[C]// Proceedings of the 2021 8th International Conference on Dependable Systems and Their Applications. Piscataway: IEEE, 2021: 551-559. |
| 23 | AWAN S, LUO B, LI F. CONTRA: defending against poisoning attacks in federated learning[C]// Proceedings of the 26th European Symposium on Research in Computer Security. Cham: Springer, 2021: 455-475. |
| 24 | RIEGER P, NGUYEN T D, MIETTINEN M, et al. DeepSight: mitigating backdoor attacks in federated learning through deep model inspection [EB/OL]. (2022-01-03) [2023-07-09]. . |
| 25 | CARLINI N, LIU C, ERLINGSSON Ú, et al. The secret sharer: evaluating and testing unintended memorization in neural networks[C]// Proceedings of the 28th USENIX Security Symposium. Berkeley: USENIX Association, 2019: 267-284. |
| 26 | SHOKRI R, STRONATI M, SONG C, et al. Membership inference attacks against machine learning models[C]//Proceedings of the 2017 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2017: 3-18. |
| 27 | MALEKZADEH M, BOROVYKH A, GÜNDÜZ D. Honest-but-curious nets: sensitive attributes of private inputs can be secretly coded into the classifiers’ outputs[C]// Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2021: 825-844. |
| 28 | YEOM S, GIACOMELLI I, FREDRIKSON M, et al. Privacy risk in machine learning: analyzing the connection to overfitting[C]// Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium. Piscataway: IEEE, 2018: 268-282. |
| 29 | NASR M, SHOKRI R, HOUMANSADR A. Comprehensive privacy analysis of deep learning: passive and active white-box inference attacks against centralized and federated learning[C]// Proceedings of the 2019 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2019: 739-753. |
| 30 | FREDRIKSON M, JHA S, RISTENPART T. Model inversion attacks that exploit confidence information and basic countermeasures[C]// Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2015: 1322-1333. |
| 31 | HITAJ B, ATENIESE G, PEREZ-CRUZ F. Deep models under the GAN: information leakage from collaborative deep learning[C]// Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 603-618. |
| 32 | WANG Z, SONG M, ZHANG Z, et al. Beyond inferring class representatives: user-level privacy leakage from federated learning[C]// Proceedings of the 2019 IEEE Conference on Computer Communications. Piscataway: IEEE, 2019: 2512-2520. |
| 33 | ZHU L, LIU Z, HAN S. Deep leakage from gradients[EB/OL]. (2019-12-19) [2023-07-09]. . |
| 34 | ZHAO B, MOPURI K R, BILEN H. iDLG: improved deep leakage from gradients[EB/OL]. (2020-01-08) [2023-07-09]. . |
| 35 | TRAMÈR F, ZHANG F, JUELS A, et al. Stealing machine learning models via prediction APIs [C]// Proceedings of the 25th USENIX Conference on Security Symposium. Berkeley: USENIX Association, 2016: 601-618. |
| 36 | PAPERNOT N, McDANIEL P, GOODFELLOW I, et al. Practical black-box attacks against machine learning[C]// Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security. New York: ACM, 2017: 506-519. |
| 37 | JUUTI M, SZYLLER S, MARCHAL S, et al. PRADA: protecting against DNN model stealing attacks [C]// Proceedings of the 2019 IEEE European Symposium on Security and Privacy. Piscataway: IEEE, 2019: 512-527. |
| 38 | OREKONDY T, SCHIELE B, FRITZ M. Knockoff nets: stealing functionality of black-box models[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 4954-4963. |
| 39 | DWORK C. Differential privacy[C]// Proceedings of the 33rd International Conference on Automata, Languages, and Programming. Berlin: Springer, 2006: 1-12. |
| 40 | GEYER R C, KLEIN T, NABI M. Differentially private federated learning: a client level perspective[EB/OL]. (2018-03-01) [2023-07-09]. . |
| 41 | WEI K, LI J, DING M, et al. Federated learning with differential privacy: algorithms and performance analysis[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 3454-3469. |
| 42 | TRUEX S, LIU L, K-H CHOW, et al. LDP-Fed: federated learning with local differential privacy[C]// Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking. New York: ACM, 2020: 61-66. |
| 43 | ZHAO Y, ZHAO J, YANG M, et al. Local differential privacy-based federated learning for internet of things [J]. IEEE Internet of Things Journal, 2020, 8(11): 8836-8853. |
| 44 | GOLDREICH O. Secure multi-party computation[EB/OL]. (1998-06-11) [2023-07-09]. . |
| 45 | OGBURN M, TURNER C, DAHAL P. Homomorphic encryption[J]. Procedia Computer Science, 2013, 20: 502-509. |
| 46 | GENTRY C. Fully homomorphic encryption using ideal lattices[C]// Proceedings of the 41st Annual ACM Symposium on Theory of Computing. New York: ACM, 2009: 169-178. |
| 47 | LONGO D L, DRAZEN J M. Data sharing[J]. New England Journal of Medicine, 2016, 374(3): 276-277. |
| 48 | FANG H, QIAN Q. Privacy preserving machine learning with homomorphic encryption and federated learning[J]. Future Internet, 2021, 13(4): 94. |
| 49 | ZHANG C, LI S, XIA J, et al. BatchCrypt: efficient homomorphic encryption for cross-silo federated learning[C]// Proceedings of the 2020 USENIX Annual Technical Conference. Berkeley: USENIX Association, 2020: 493-506. |
| 50 | MA J, S-A NAAS, SIGG S, et al. Privacy-preserving federated learning based on multi-key homomorphic encryption[J]. International Journal of Intelligent Systems, 2022, 37(9): 5880-5901. |
| 51 | 陈宛桢,张恩,秦磊勇, 等. 边缘计算下基于区块链的隐私保护联邦学习算法[J]. 计算机应用, 2023, 43(7): 2209-2216. |
| CHEN W Z, ZHANG E, QIN L Y, et al. Privacy-preserving federated learning algorithm based on blockchain in edge computing [J]. Journal of Computer Applications, 2023, 43(7): 2209-2216. | |
| 52 | 周炜,王超,徐剑,等. 基于区块链的隐私保护去中心化联邦学习模型[J]. 计算机研究与发展, 2022,59(11): 2423-2436. |
| ZHOU W, WANG C, XU J, et.al. Privacy-preserving and decentralized federated learning model based on the blockchain[J]. Journal of Computer Research and Development, 2022, 59(11): 2423-2436. | |
| 53 | YANG Q, LIU Y, CHEN T, et al. Federated machine learning: concept and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019, 10(2): No. 12. |
| 54 | KAIROUZ P, McMAHAN H B, AVENT B, et al. Advances and open problems in federated learning [J]. Foundations and Trends® in Machine Learning, 2021, 14(1/2): 1-210. |
| [1] | 陈廷伟, 张嘉诚, 王俊陆. 面向联邦学习的随机验证区块链构建[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2770-2776. |
| [2] | 沈哲远, 杨珂珂, 李京. 基于双流神经网络的个性化联邦学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2319-2325. |
| [3] | 姚梓豪, 栗远明, 马自强, 李扬, 魏良根. 基于机器学习的多目标缓存侧信道攻击检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1862-1871. |
| [4] | 罗玮, 刘金全, 张铮. 融合秘密分享技术的双重纵向联邦学习框架[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1872-1879. |
| [5] | 刘沛骞, 王水莲, 申自浩, 王辉. 基于轨迹扰动和路网匹配的位置隐私保护算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1546-1554. |
| [6] | 佘维, 李阳, 钟李红, 孔德锋, 田钊. 基于改进实数编码遗传算法的神经网络超参数优化[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 671-676. |
| [7] | 高改梅, 张瑾, 刘春霞, 党伟超, 白尚旺. 基于区块链与CP-ABE策略隐藏的众包测试任务隐私保护方案[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 811-818. |
| [8] | 郑毅, 廖存燚, 张天倩, 王骥, 刘守印. 面向城区的基于图去噪的小区级RSRP估计方法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 855-862. |
| [9] | 马海峰, 李玉霞, 薛庆水, 杨家海, 高永福. 用于实现区块链隐私保护的属性基加密方案[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 485-489. |
| [10] | 余孙婕, 曾辉, 熊诗雨, 史红周. 基于生成式对抗网络的联邦学习激励机制[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 344-352. |
| [11] | 王一帆, 林绍福, 李云江. 基于区块链和零知识证明的高速公路自由流收费方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3741-3750. |
| [12] | 王伊婷, 万武南, 张仕斌, 张金全, 秦智. 基于SM9算法的可链接环签名方案[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3709-3716. |
| [13] | 梁静, 万武南, 张仕斌, 张金全, 秦智. 面向主从链的慈善系统溯源存储模型[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3751-3758. |
| [14] | 李博, 黄建强, 黄东强, 王晓英. 基于异构平台的稀疏矩阵向量乘自适应计算优化[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3867-3875. |
| [15] | 方鹏, 赵凡, 王保全, 王轶, 蒋同海. 区块链3.0的发展、技术与应用[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3647-3657. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||